↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Linear transformers offer a faster alternative to traditional transformers, but they often underperform, especially on tasks requiring memory and associative recall. DeltaNet, a variant using the delta rule, is more effective for associative recall but lacks efficient training algorithms that scale with modern hardware. This is a significant hurdle, limiting the model’s ability to compete with established transformer models.
This research tackles this challenge by developing a hardware-efficient algorithm for training DeltaNet. This algorithm cleverly exploits a memory-efficient representation for computing products of Householder matrices, enabling parallelization across sequence length. The researchers successfully trained a 1.3B parameter DeltaNet model on 100B tokens, demonstrating superior performance to previous linear-time alternatives. Furthermore, experiments with hybrid models that combine DeltaNet with other attention mechanisms show even stronger results, surpassing standard transformer baselines.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient transformer models and long sequence processing. It introduces a novel, hardware-efficient algorithm for training DeltaNet, a linear transformer variant that excels in associative recall. This opens avenues for scaling up linear transformers to handle large language models and complex datasets, addressing a key limitation of previous linear-time alternatives. The findings also have broader implications for hybrid model development, combining the strengths of linear and softmax attention mechanisms.
Visual Insights#

This figure shows the speedup achieved by using the chunkwise parallel form of the algorithm compared to the recurrent form. The speedup is plotted against the sequence length for three different head dimensions (64, 128, and 256). As sequence length increases, the speedup achieved by the chunkwise parallel form becomes more significant, especially for larger head dimensions. This highlights the effectiveness of the chunkwise parallel approach in improving training efficiency for longer sequences.

This table presents the results of different models on the MAD benchmark, a suite of synthetic token manipulation tasks designed to test various aspects of model architectures, including recall ability, compression, and noise robustness. The table compares the performance of DeltaNet against several strong baselines, notably highlighting the use of convolutions in some models but not others. It shows DeltaNet’s competitive performance, particularly excelling in Fuzzy Recall, while indicating areas where it may underperform others.
In-depth insights#
DeltaNet Parallelization#
The core challenge addressed in DeltaNet parallelization is the inherent sequential nature of the Delta rule update within linear transformers. The standard DeltaNet algorithm processes the sequence serially, which severely limits scalability on modern hardware. This paper introduces a novel, hardware-efficient training algorithm that overcomes this bottleneck by leveraging a memory-efficient representation of Householder matrices. This clever reparameterization enables parallelization across the sequence length, drastically accelerating training. The technique is not a simple parallelization of the existing algorithm but involves a significant reworking of the update mechanism, reducing memory requirements and allowing for chunkwise parallel processing. This approach effectively bridges the gap between the speed and parallelization of standard linear transformers and the improved performance on associative recall tasks offered by DeltaNet, making it suitable for large-scale language modelling.
WY Representation#
The concept of “WY Representation” likely refers to a memory-efficient method for representing products of Householder matrices. In the context of parallelizing linear transformers, this is crucial for scaling to larger models and datasets. Householder matrices are fundamental to the DeltaNet algorithm’s reparameterization, allowing for efficient computation of updates without materializing large intermediate state matrices which would be computationally expensive and memory-intensive. The WY representation likely enables chunkwise parallelization of the DeltaNet training process, trading off the need for fewer sequential computations in exchange for enhanced sequence-level parallelism. This is critical for leveraging modern hardware and achieving high GPU occupancy, thus enabling significant speedups in training compared to sequential approaches. The memory efficiency offered by this technique likely overcomes limitations in the original DeltaNet algorithm, which hindered its scalability. Overall, the WY representation is a clever algorithmic innovation that enables efficient large-scale training of the DeltaNet model, ultimately improving its performance in language modeling tasks.
Hybrid Model Designs#
The exploration of hybrid models represents a significant advancement in the field of sequence modeling. By combining the strengths of linear transformers and traditional attention mechanisms, these models aim to address inherent limitations. The integration of DeltaNet layers with sliding-window attention or global attention layers offers a compelling approach to improve performance. This hybrid strategy leverages DeltaNet’s efficiency for long sequences while mitigating its weaknesses in local context processing using softmax attention. The results demonstrate enhanced performance over traditional Transformers and strong linear baselines on tasks that demand both long-range context understanding and precise local analysis. This combination demonstrates a synergistic effect, where the complementary strengths of both components yield a more robust and powerful model. The design principles are of particular interest because they highlight the potential benefits of merging different architectures with distinct strengths, leading to novel hybrid architectures that surpass the capabilities of their individual constituents.
Recall Enhancement#
The concept of ‘Recall Enhancement’ in the context of transformer-based language models is crucial. Standard softmax attention, while powerful, suffers from quadratic complexity with sequence length, limiting long-context understanding. Linear attention mechanisms aim to address this, achieving linear time complexity, but often underperform softmax attention, particularly in recall-intensive tasks. The Delta Rule, as employed in DeltaNet, is a promising approach to boost recall capabilities. By selectively updating memory with new key-value associations instead of purely additive updates, DeltaNet avoids key collisions and improves associative recall. However, existing DeltaNet training algorithms lack sequence-level parallelization, hindering scalability. This paper’s contribution is a memory-efficient algorithm enabling such parallelization, significantly improving DeltaNet’s efficiency and performance on language modeling tasks. The hybrid models incorporating DeltaNet layers with sliding window or global attention further demonstrates the potential of the Delta Rule for enhanced recall, surpassing traditional transformer baselines on various benchmarks. The combination of linear attention and the Delta Rule thus emerges as a key strategy in overcoming the limitations of linear attention and achieving significant recall enhancement.
Future Work#
The paper’s discussion on future work highlights several key areas for improvement. Addressing the training speed limitation of DeltaNet compared to GLA is crucial, potentially involving exploring block-diagonal generalized Householder matrices to optimize memory usage and parallelism. Extending DeltaNet’s ability to generalize beyond the training length is another significant goal, which suggests incorporating a gating mechanism for better length extrapolation. Exploring more general matrix parameterizations within the DeltaNet framework beyond the current I-βtktkt+ structure could unlock further performance gains. Finally, exploring the theoretical limitations of DeltaNet by examining the trade-off between parallelism and expressiveness of linear autoregressive models is suggested, pointing to the need for a unifying framework of efficient autoregressive sequence transformations. This could encompass models utilizing continuous state-space representations or employing structured matrix multiplications.
More visual insights#
More on figures
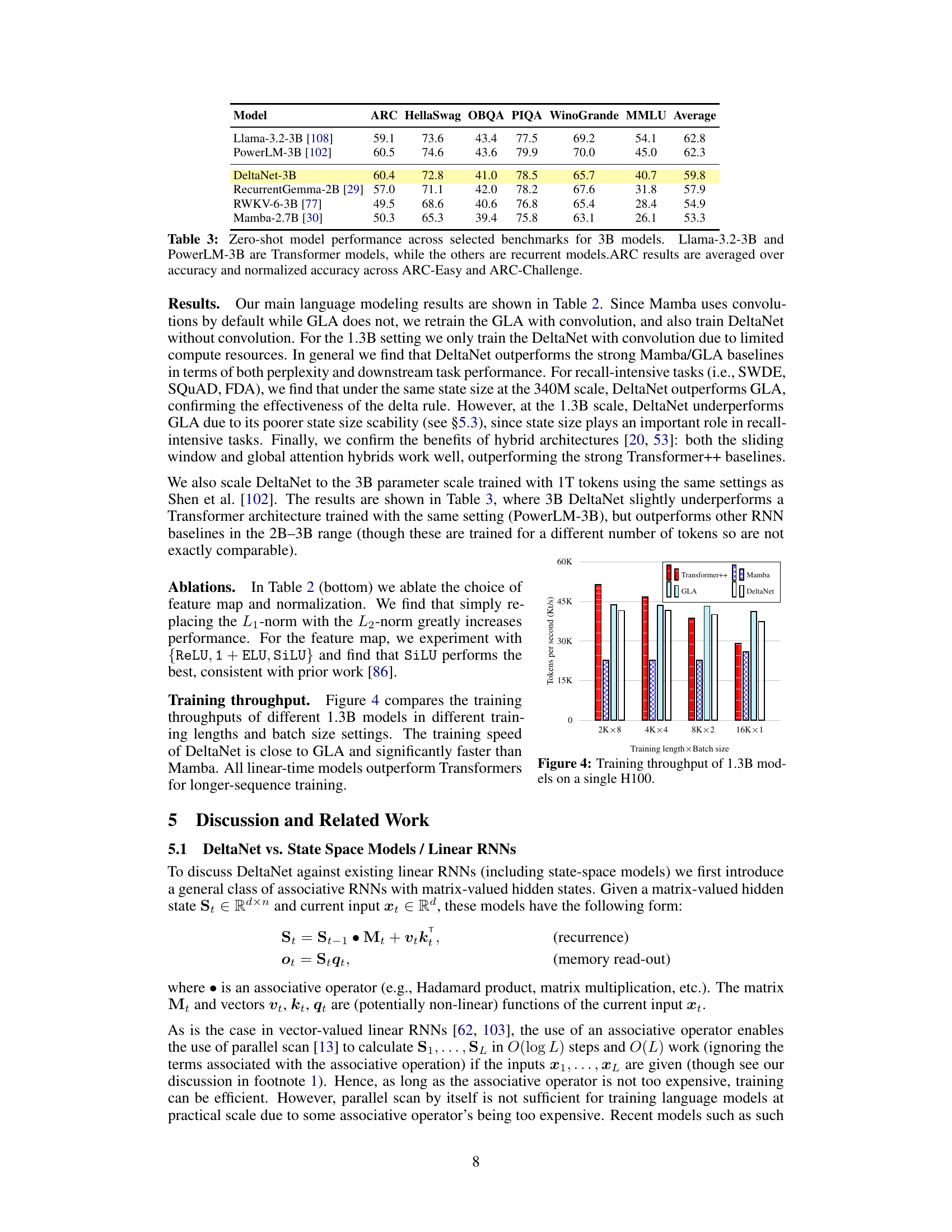
The figure shows the accuracy of different models (DeltaNet, Mamba, GLA, RetNet, RWKV4, and Hyena) on the Multi-query associative recall (MQAR) task. The x-axis represents the model dimension, and the y-axis represents the accuracy. The sequence length is 512, and the number of key-value pairs is 64. DeltaNet achieves perfect accuracy in most model dimensions.

This figure shows the accuracy of different models on the Regbench dataset as a function of the number of training examples. The models compared include Transformer++, DeltaNet (with and without convolution), GLA (with and without convolution), and Mamba (with and without convolution). The figure demonstrates the performance of these various models on a synthetic in-context learning benchmark, illustrating their ability to learn and generalize from a limited number of examples.
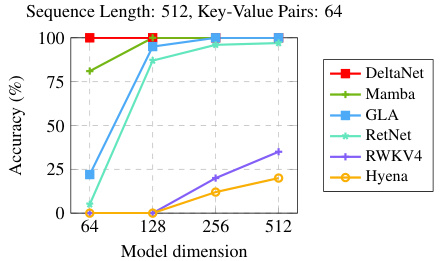
This figure compares the training throughputs of different 1.3B parameter models on a single H100 GPU across various training lengths and batch sizes. The models compared are Transformer++, Mamba, GLA, and DeltaNet. The x-axis represents different combinations of training length and batch size (e.g., 2K samples * batch size 8). The y-axis shows the training throughput measured in thousands of tokens per second (Kt/s). The figure demonstrates that DeltaNet achieves comparable speed to GLA and significantly outperforms the Transformer++ and Mamba baselines for longer sequence lengths.

This figure compares the speed-up achieved by using the chunkwise parallel form of the algorithm over the recurrent form. The x-axis represents the sequence length (K), and the y-axis shows the speed-up factor (x). Multiple lines are presented, each corresponding to a different head dimension (64, 128, and 256). The plot demonstrates that the chunkwise parallel approach provides significantly greater speed improvements as both sequence length and head dimension increase, highlighting the benefits of the algorithm for larger models and longer sequences.
More on tables
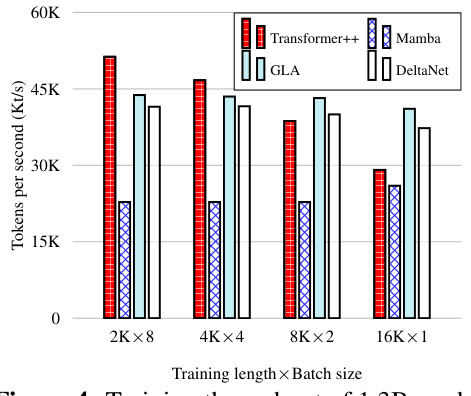
This table presents the main language modeling results, comparing DeltaNet against several strong baselines including Transformer++, RetNet, Mamba, and GLA. It shows perplexity and zero-shot performance on various downstream tasks for two model sizes (340M and 1.3B parameters). The table also includes results for hybrid models incorporating sliding-window or global attention layers, highlighting the impact of these additions. Finally, ablation studies on DeltaNet are included, varying normalization and activation functions.
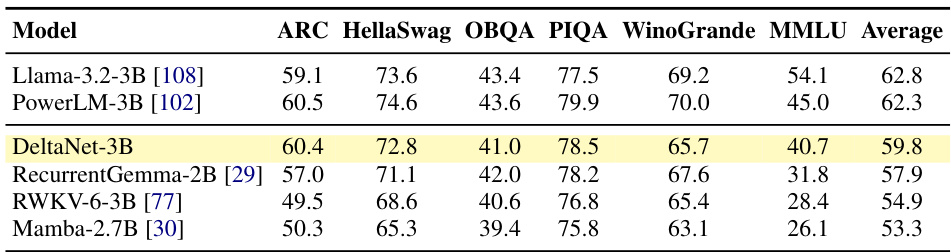
This table compares the zero-shot performance of several 3B parameter language models on various benchmark tasks. The benchmarks assess different capabilities including commonsense reasoning, question answering, and knowledge-intensive tasks. The models compared include both transformer-based architectures and recurrent neural network (RNN)-based models. The table highlights the relative strengths and weaknesses of different architectural approaches in zero-shot settings.

This table summarizes different linear recurrent models used for autoregressive language modeling. It compares the recurrence relation and memory read-out mechanism for each model, highlighting the use of matrix-valued hidden states and associative operators. The table also notes the inclusion of kernels and normalization in some models, indicating variations in implementation details.
Full paper#