↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Sparse Mixture of Experts (SMoE) models, while efficient in handling large datasets, suffer from unstable training and lack robustness. This instability stems from the inherent challenges in coordinating multiple expert networks, leading to difficulties in adapting to new data distributions and vulnerability to noise. The unstable training often results in suboptimal performance and limits the applicability of SMoE in real-world scenarios.
To overcome these limitations, the researchers propose MomentumSMoE, a novel approach that incorporates momentum into the SMoE framework. This integration enhances the stability and robustness of the model by smoothing the training dynamics and improving its ability to generalize to unseen data. Experiments on ImageNet and WikiText demonstrate MomentumSMoE’s superior performance compared to traditional SMoE. The code’s public availability further encourages wider adoption and contributes to the advancement of large-scale deep learning model development. MomentumSMoE provides a significant improvement in the stability and robustness of SMoE, which is of considerable importance in developing efficient and reliable large models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large-scale deep learning models. It directly addresses the instability and robustness issues of Sparse Mixture of Experts (SMoE), a vital technique for scaling model size. By introducing momentum-based optimization, the paper offers a practical solution to improve the training stability and performance of SMoE models, opening new avenues for developing more robust and efficient large-scale models. Its broad applicability across various SMoE architectures and its readily available codebase significantly benefits the research community.
Visual Insights#
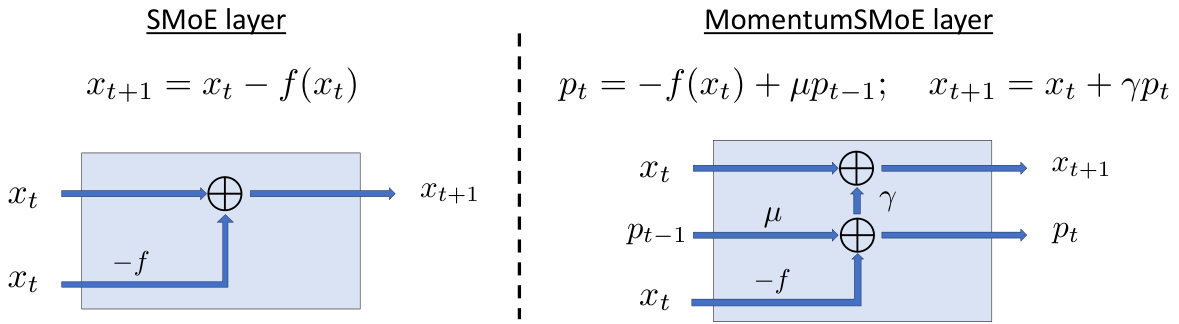
This figure illustrates the architecture of both the standard Sparse Mixture of Experts (SMoE) layer and the proposed MomentumSMoE layer. The SMoE layer shows a simple residual connection where the output is the input plus the output of the expert network. The MomentumSMoE layer extends this by adding a momentum term to stabilize and accelerate convergence. The momentum term is calculated from the negative gradient and the previous momentum, and is then added to the input to generate the next layer’s input. This illustrates how momentum is integrated into the SMoE framework.
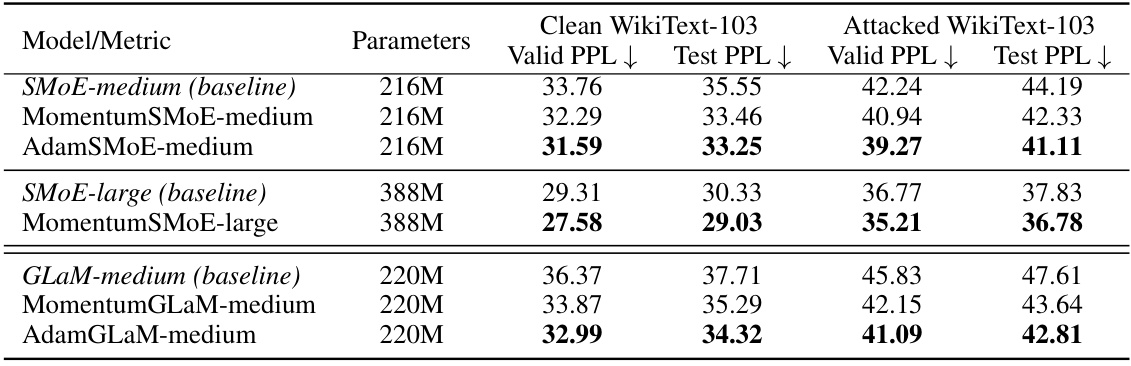
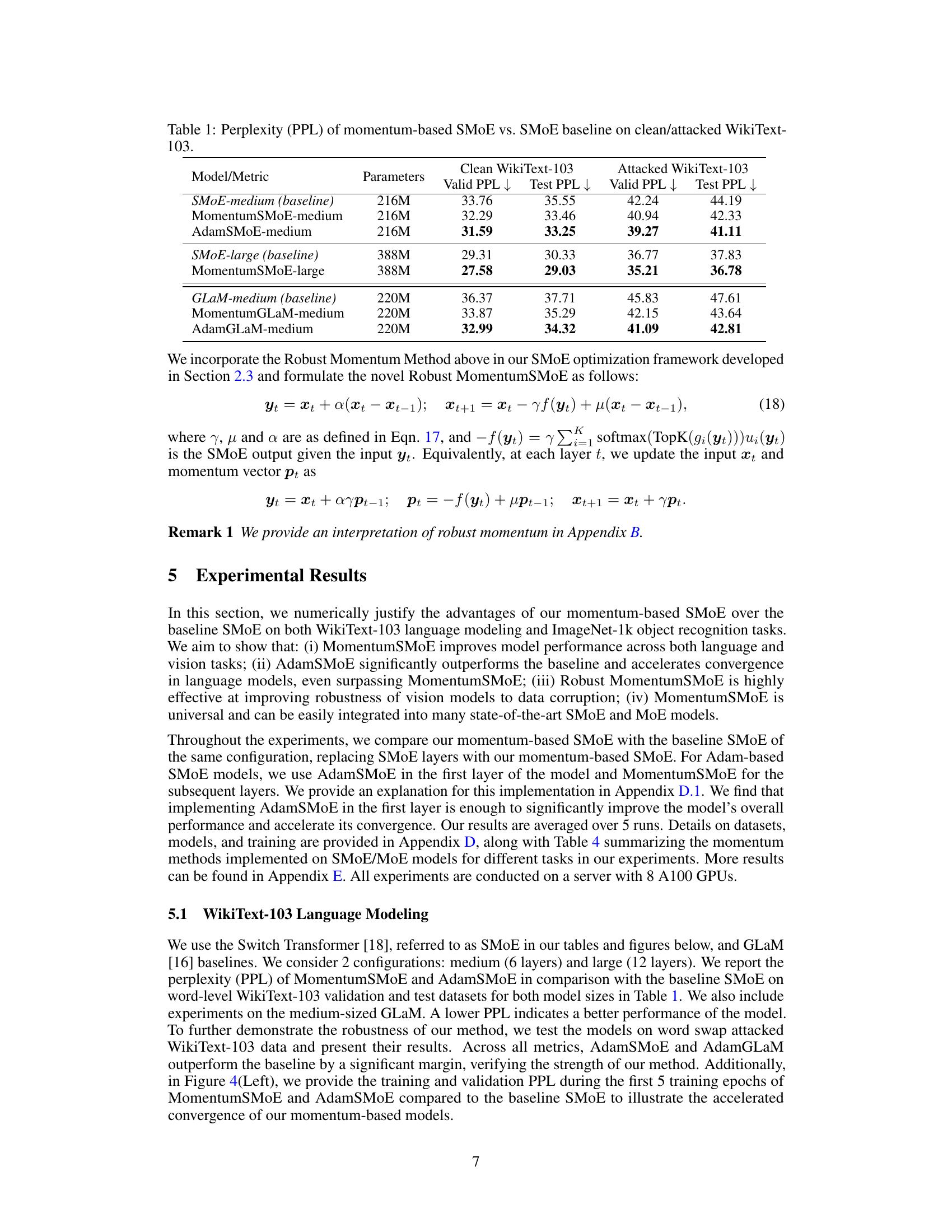
This table presents the perplexity (PPL) scores, a measure of language model performance, for different models on the WikiText-103 dataset. It compares the performance of standard Sparse Mixture of Experts (SMoE) models with three variations incorporating momentum: MomentumSMoE, AdamSMoE, and Robust MomentumSMoE. Results are shown for both clean and attacked (word-swap) versions of the WikiText-103 dataset, indicating model robustness. The table includes two sizes of SMoE models and also compares with a GLaM model to demonstrate the applicability of the proposed methods across different model architectures.
In-depth insights#
Momentum’s Role#
The paper explores momentum’s crucial role in stabilizing and improving the robustness of Sparse Mixture of Experts (SMoE) models. It theoretically connects the dynamics of expert representations in SMoEs to gradient descent on a multi-objective optimization problem, providing a novel framework for understanding SMoE behavior. By integrating heavy-ball momentum, the proposed MomentumSMoE architecture demonstrates enhanced stability and robustness compared to traditional SMoEs. This improvement is theoretically supported by showing that MomentumSMoE has a better-structured spectrum than SMoE, leading to improved convergence and robustness. The approach extends beyond heavy-ball momentum, incorporating other advanced methods like Adam and robust momentum for further performance gains. Empirical validation across various tasks, including ImageNet and WikiText, confirms the effectiveness of the proposed MomentumSMoE family, highlighting its broader applicability and potential to unlock greater scalability in deep learning.
SMoE Enhancements#
The paper explores enhancements to Sparse Mixture of Experts (SMoE) models, focusing on addressing their instability and lack of robustness. Momentum, a key concept in optimization, is integrated into SMoE, resulting in MomentumSMoE, which demonstrates improved stability and robustness. The authors theoretically justify this improvement by analyzing the spectrum of the modified model, showing a better-structured spectrum compared to the original SMoE. Beyond heavy-ball momentum, the framework is extended to incorporate more sophisticated methods like Adam and Robust Momentum, further enhancing performance and robustness. The results indicate that these MomentumSMoE variants outperform the baseline SMoE across various tasks, highlighting their practical value and generalizability. The simplicity of implementation is a significant advantage, enabling easy integration into existing SMoE models with minimal computational overhead. The findings underscore the potential of integrating advanced optimization techniques into SMoE to improve model stability and robustness while maintaining computational efficiency. This work suggests that momentum-based enhancements offer a significant step forward in developing more stable, reliable, and efficient SMoE models.
Stability Analysis#
The heading ‘Stability Analysis’ in a research paper would typically involve a rigorous examination of a model’s or algorithm’s stability. This would likely encompass theoretical analysis, potentially using mathematical tools to prove stability under certain conditions, and empirical analysis, using simulations or experiments on various datasets to assess the robustness of the model in practice. Key aspects often explored include the sensitivity of model behavior to variations in input data or parameters. The goal is to demonstrate the reliability and predictability of the model’s performance, showing it consistently produces accurate and consistent results across different situations and not easily affected by noise or perturbations. Convergence properties are also crucial; a stable model should converge reliably to a solution. The analysis section would compare the model’s stability against baseline models or existing approaches, highlighting any improvements or advantages. Specific metrics demonstrating stability would be used, such as the range of parameter values maintaining stability or bounds on error growth over time. Ultimately, a robust stability analysis builds confidence in a model’s reliability and suitability for practical applications.
Vision Model Tests#
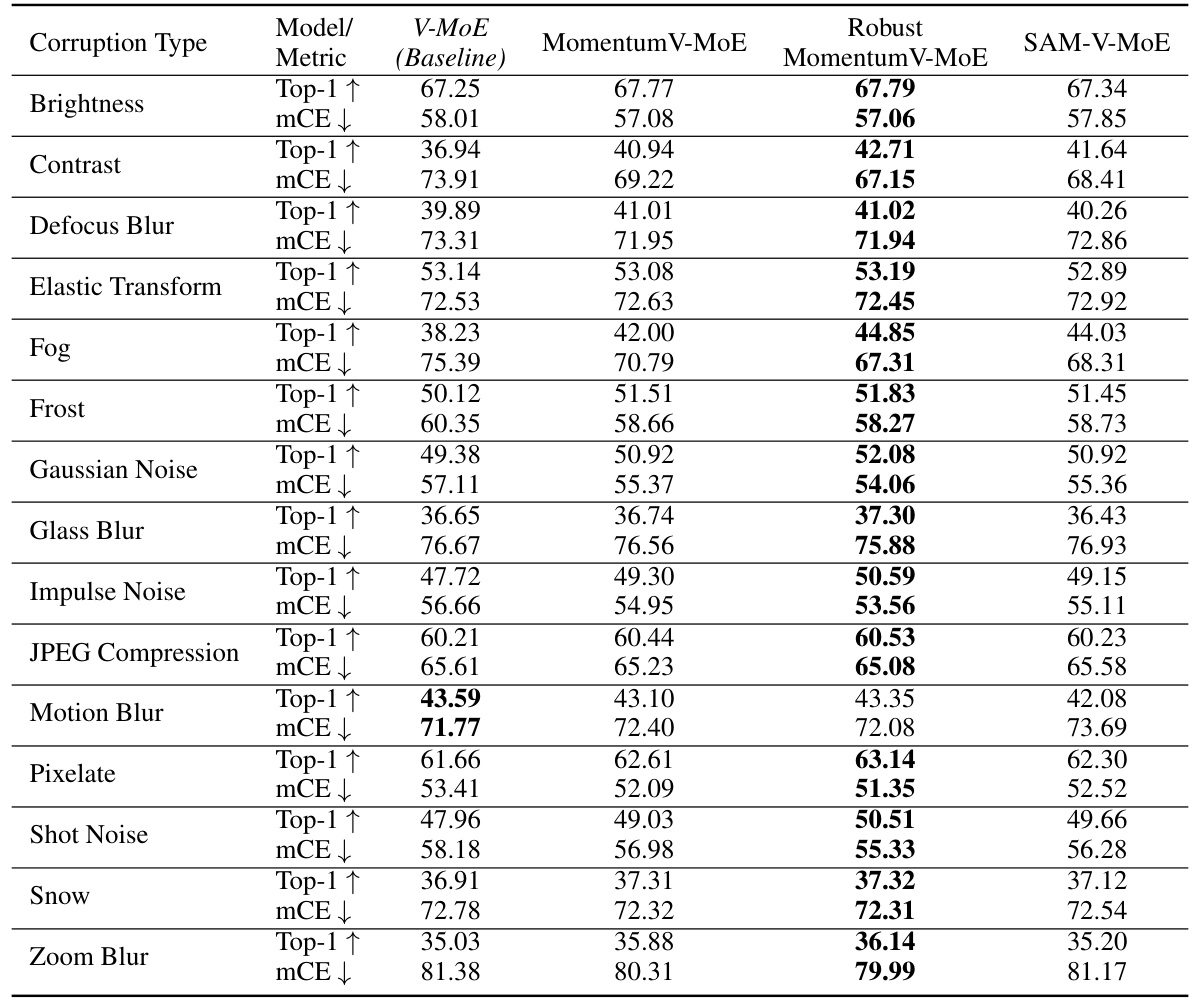
A section titled ‘Vision Model Tests’ in a research paper would likely detail experiments evaluating the performance of a vision model on various image datasets. It would likely include a description of the models used (e.g., Vision Mixture of Experts (V-MoE), Soft MoE), the datasets employed (ImageNet-1k, ImageNet-A, ImageNet-C, ImageNet-R), and the metrics used to assess performance (e.g., top-1 accuracy, mean corruption error). A key aspect would be a discussion of the model’s robustness to image corruptions and variations. The results would compare the performance of the vision model against existing baselines, showing the impact of proposed techniques on accuracy and robustness. Furthermore, this section would likely include details on the experimental setup, including hyperparameter choices and the training process. Detailed analysis of the results would aim to draw conclusions about the effectiveness and limitations of the vision model in different scenarios, providing valuable insights into its real-world applicability.
Future Directions#
Future research could explore several promising avenues. Extending MomentumSMoE’s applicability to diverse model architectures beyond those tested (e.g., transformers, CNNs) is crucial. Investigating the impact of MomentumSMoE on different routing mechanisms and exploring ways to mitigate load imbalance more effectively would enhance robustness. Theoretical analysis to explain the observed stability improvements and the generalizability of momentum to other optimization methods within the SMoE framework warrants further investigation. Finally, empirical validation on a broader range of large-scale tasks and datasets will solidify its effectiveness and highlight its potential across various domains.
More visual insights#
More on figures

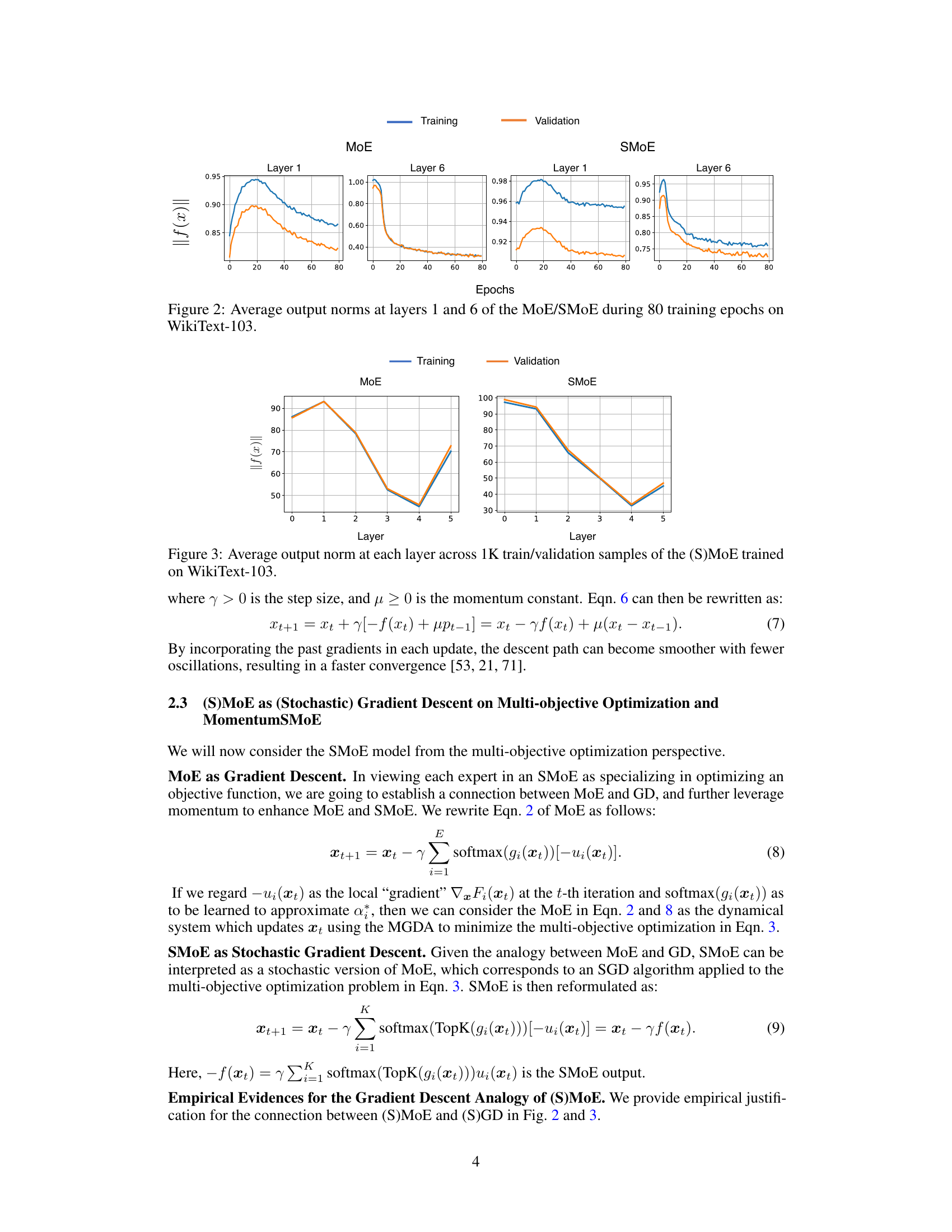
This figure displays the average output norms at layers 1 and 6 of both the MoE and SMoE models during the training process on the WikiText-103 dataset. The x-axis represents the training epochs (iterations), and the y-axis represents the average output norm. The plot shows the trend of the norms for both models across the training epochs for both the training and validation datasets. It visually demonstrates differences between MoE and SMoE in terms of their output norm behavior throughout training, which may offer insights into their convergence characteristics.
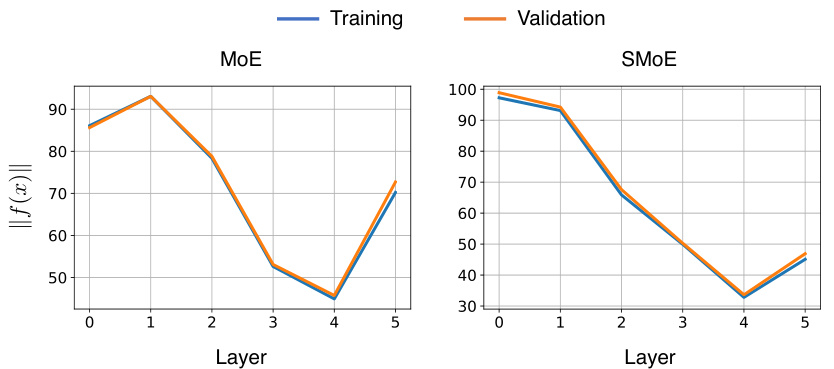
This figure shows the average output norm at each layer of both MoE and SMoE models trained on the WikiText-103 dataset. The x-axis represents the layer number (1 through 5), and the y-axis represents the average output norm. Separate lines show the training and validation data for each model. The figure is used to empirically demonstrate the connection between the dynamics of the expert representations in SMoEs and gradient descent on a multi-objective optimization problem.

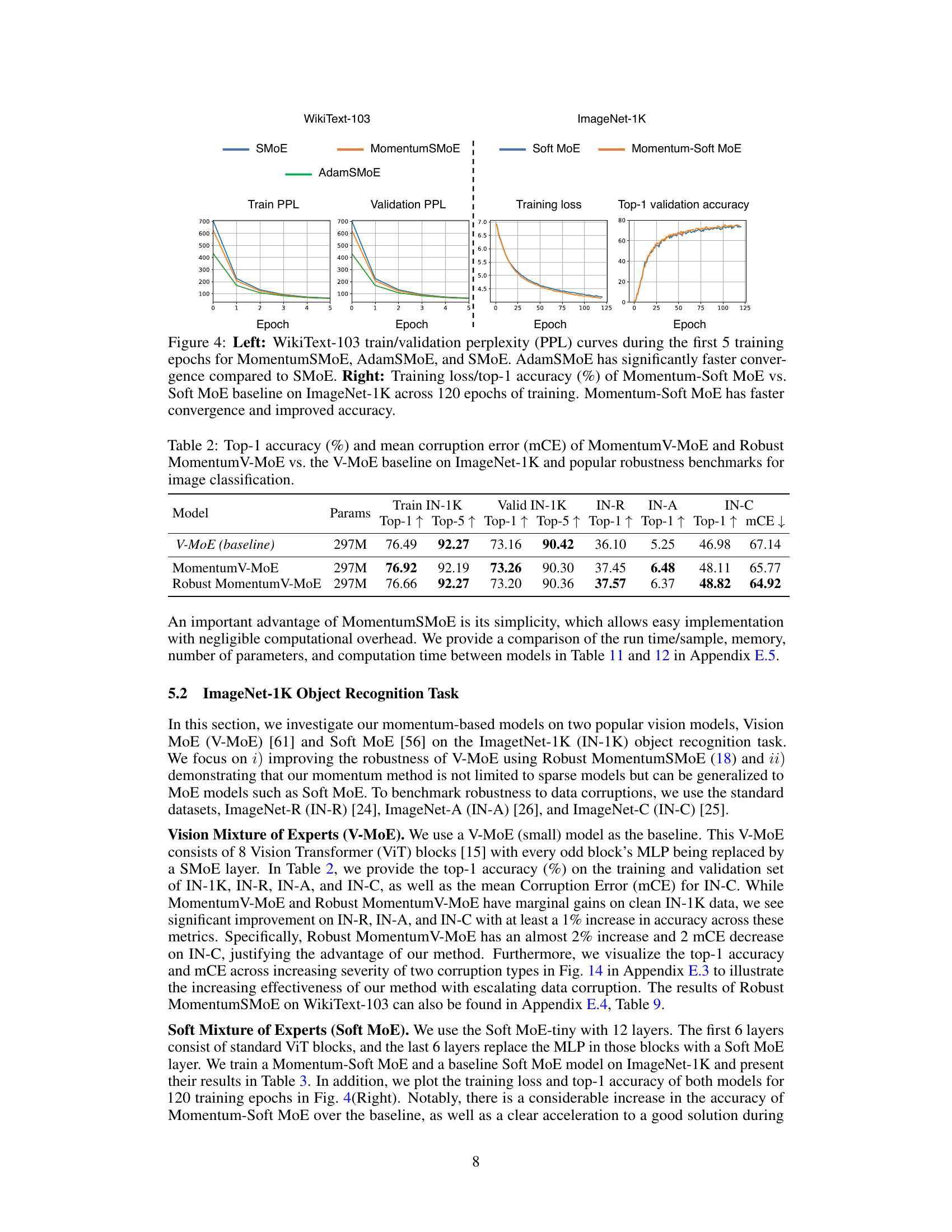
This figure compares the performance of MomentumSMoE and AdamSMoE with the baseline SMoE model on two different tasks: WikiText-103 language modeling and ImageNet-1K image classification. The left panel shows the training and validation perplexity (PPL) curves for the three models during the first five epochs on the WikiText-103 dataset, highlighting the faster convergence of AdamSMoE. The right panel displays the training loss and top-1 validation accuracy for Momentum-Soft MoE and the baseline Soft MoE model over 120 epochs on the ImageNet-1K dataset, demonstrating the superior performance and faster convergence of Momentum-Soft MoE.

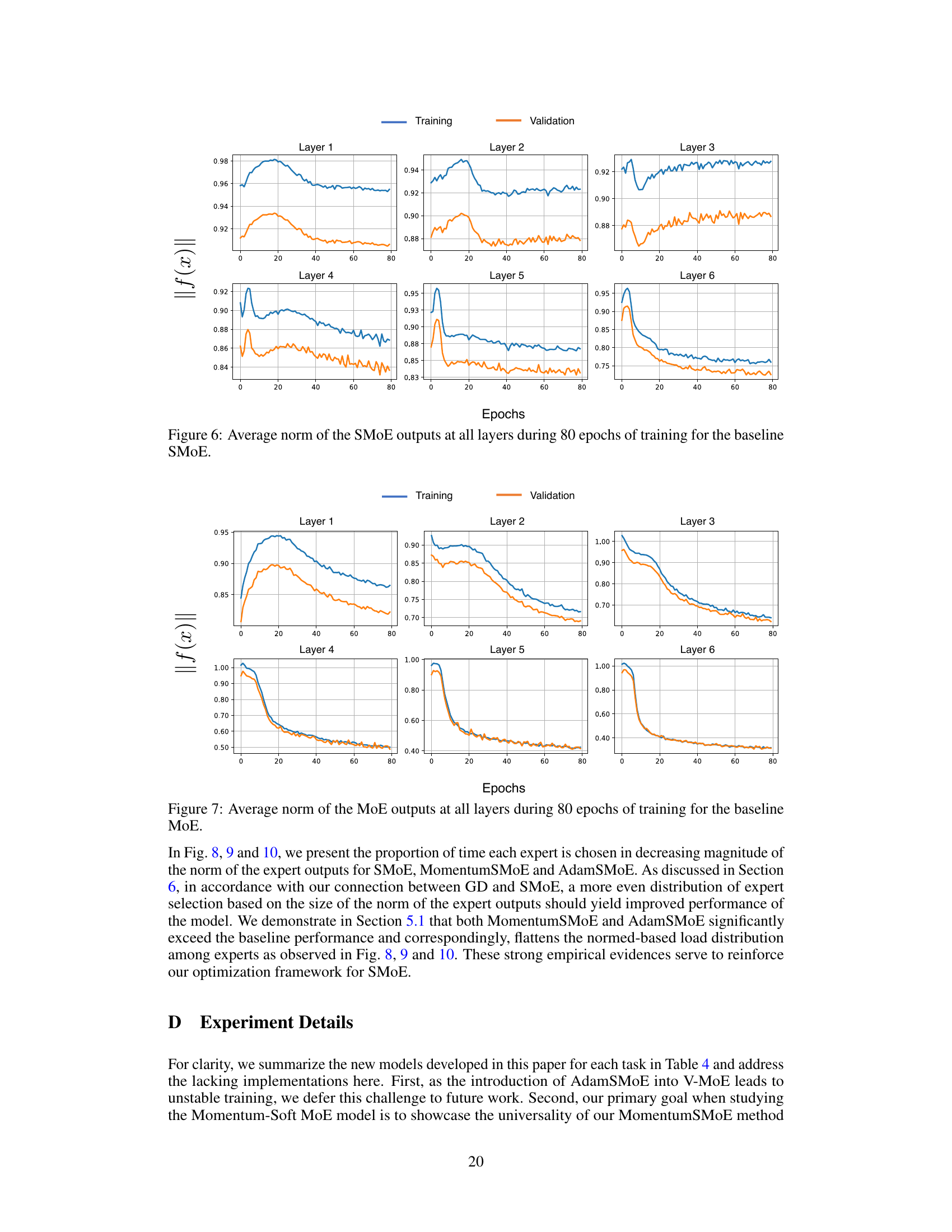
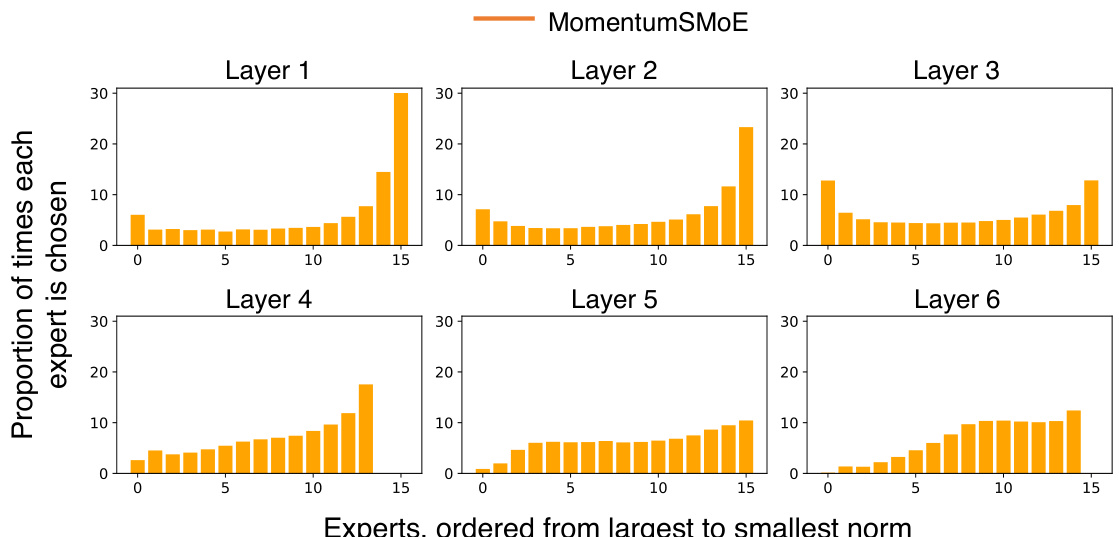
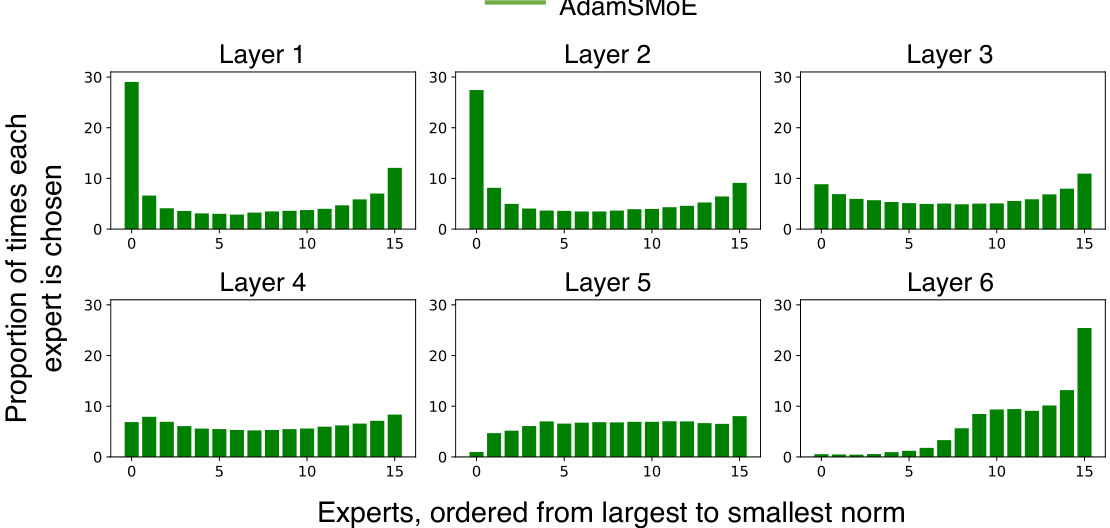
The figure demonstrates the expert selection in SMoE, MomentumSMoE, and AdamSMoE models trained on WikiText-103. The left panel shows the proportion of times each expert is chosen, ordered by the magnitude of its output norm. This illustrates the impact of momentum on load balancing across experts. The right panel shows how the validation perplexity changes during hyperparameter tuning (momentum coefficient μ and step size γ) for the MomentumSMoE model, highlighting the model’s sensitivity to these parameters.
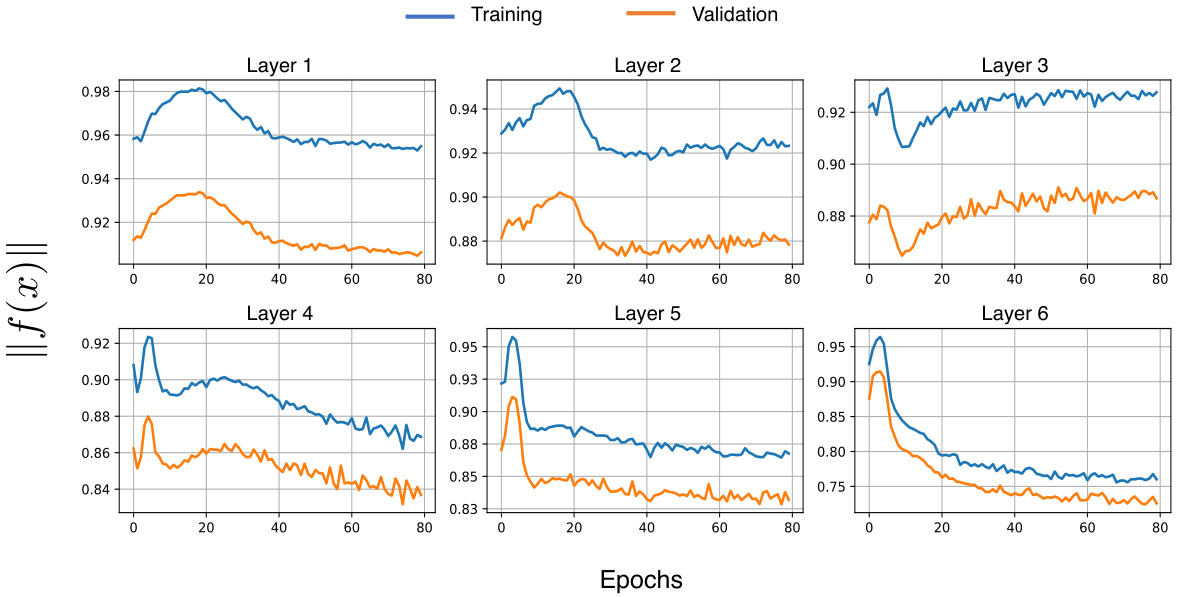
This figure shows the average output norms at layer 1 and layer 6 of the MoE and SMoE models during training on the WikiText-103 dataset. The x-axis represents the training epoch, and the y-axis represents the average output norm. Separate lines are shown for training and validation data for both the MoE and SMoE models. The figure illustrates the trends in output norms over the course of training, potentially highlighting differences in the training dynamics between MoE and SMoE.
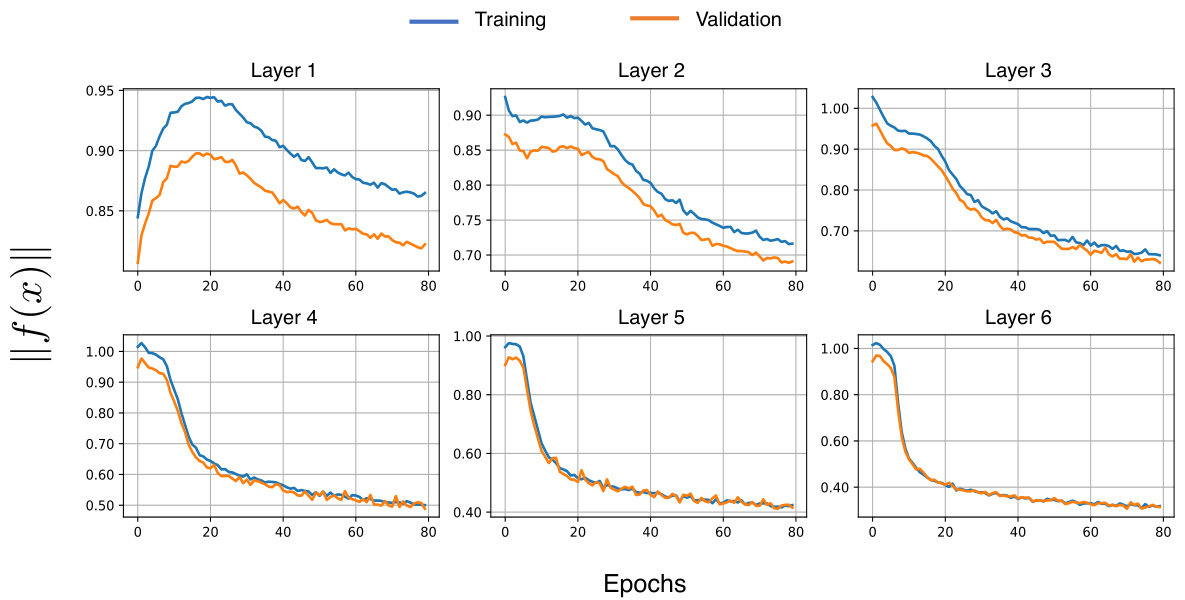
This figure displays the average output norms at layers 1 and 6 of the MoE (Mixture of Experts) and SMoE (Sparse Mixture of Experts) models during 80 training epochs on the WikiText-103 dataset. The plots show the norms for both the training and validation sets, providing a visual representation of how the model’s output changes over time and across different stages of training. This helps to understand the stability and convergence behavior of the two models, where lower norms generally indicate better stability.
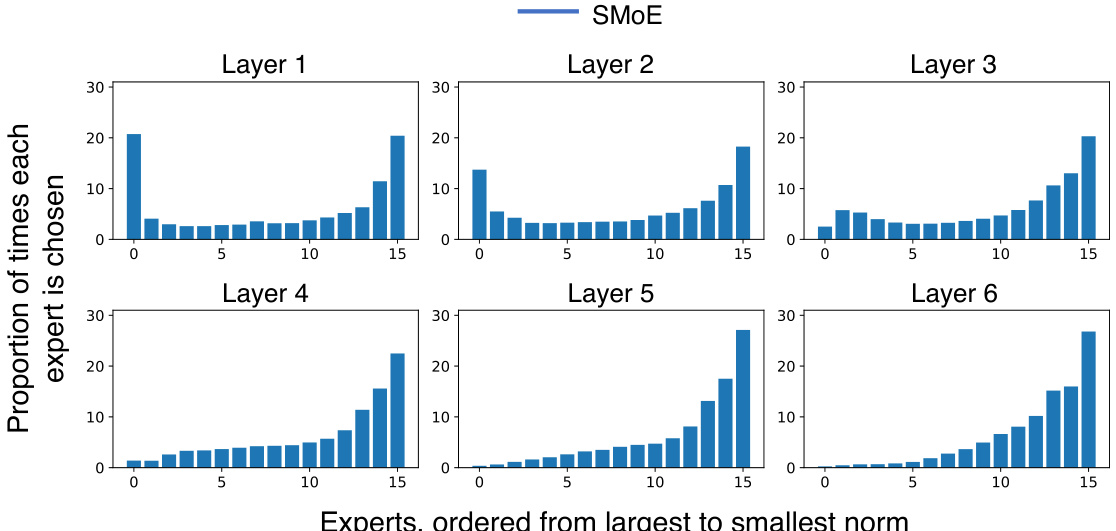
This figure shows the proportion of times each expert in a Sparse Mixture of Experts (SMoE) model is chosen during inference, ordered by the magnitude of the norm of its output. The x-axis represents the experts, ordered from the one with the largest norm to the one with the smallest norm. The y-axis represents the proportion of times each expert was selected across all layers (1-6) of the SMoE model. The figure demonstrates a significant load imbalance, with a small number of experts being selected much more frequently than others.
This figure shows the proportion of times each expert is selected in each layer of the baseline SMoE model. The experts are ordered from the largest to the smallest norm of their output. The visualization helps to understand the load imbalance problem in SMoE, where some experts are chosen much more frequently than others. The uneven distribution is a key characteristic of standard SMoE training.
This figure shows the proportion of times each expert is selected during inference for each layer of the baseline SMoE model. Experts are ordered on the x-axis from the largest to smallest norm of their outputs. The y-axis shows the proportion of times each expert was selected. The figure visually represents the load imbalance among experts in the baseline SMoE model, highlighting those experts that are consistently chosen over others during inference.
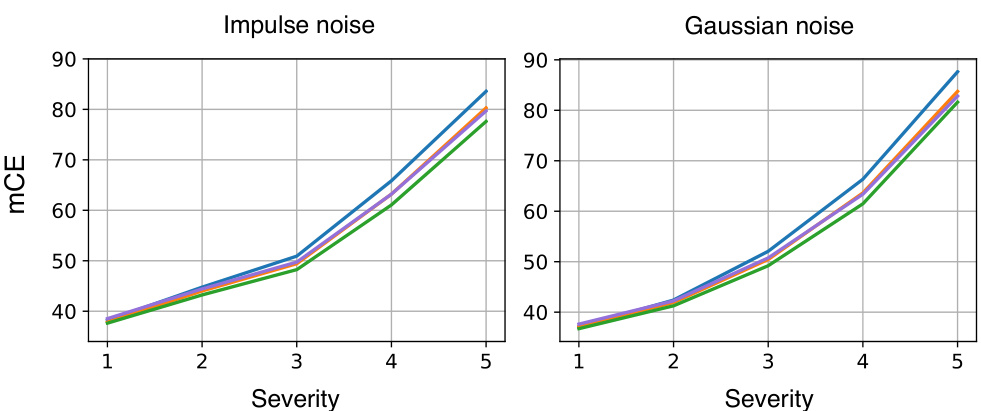
The figure shows the mean corruption error (mCE) for four different vision models (V-MoE, MomentumV-MoE, Robust MomentumV-MoE, and SAM-V-MoE) on ImageNet-C dataset under impulse and Gaussian noise with increasing severity levels. It demonstrates that the incorporation of momentum and robust momentum techniques improves the robustness of the models against these corruptions, especially at higher severity levels.
More on tables

This table presents a comparison of the top-1 accuracy and mean corruption error (mCE) achieved by three different vision models on the ImageNet-1K dataset and several robustness benchmark datasets. The models compared are the baseline V-MoE, MomentumV-MoE (incorporating heavy-ball momentum), and Robust MomentumV-MoE (incorporating robust momentum). The results show the performance of each model on clean ImageNet-1K data, as well as its robustness to various corruptions and adversarial attacks (ImageNet-C, ImageNet-R, and ImageNet-A).
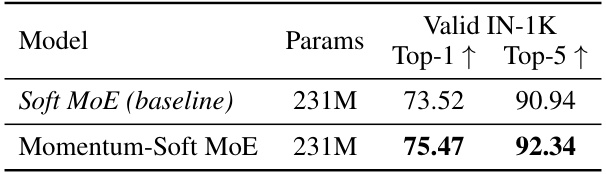
This table presents a comparison of the top-1 and top-5 accuracy results for two models on the ImageNet-1K dataset: a baseline Soft MoE model and a Momentum-Soft MoE model (which incorporates momentum into the Soft MoE architecture). The table shows that the Momentum-Soft MoE model achieves a notable improvement in both top-1 and top-5 accuracy compared to the baseline Soft MoE model, highlighting the benefit of incorporating momentum.
This table presents the results of perplexity (PPL) on both clean and attacked versions of the WikiText-103 dataset. It compares the performance of different momentum-based Sparse Mixture of Experts (SMoE) models against a standard SMoE baseline. The models are categorized by size (medium and large) and type (MomentumSMoE, AdamSMoE). The table shows that the momentum-based models generally achieve lower perplexity scores (indicating better performance) than the baseline, particularly on the attacked dataset. This demonstrates the effectiveness of incorporating momentum in enhancing the stability and robustness of SMoE, especially in dealing with noisy or corrupted data.

This table presents the perplexity (PPL) results of different MomentumSMoE models on the WikiText-103 dataset. It compares the performance of the standard MomentumSMoE model with tuned hyperparameters (μ and γ) to two variations where these hyperparameters are learned during training: one where both are learned, and another where only γ is learned while μ is fixed. The results are shown for both clean and attacked versions of the dataset, allowing for evaluation of model robustness.
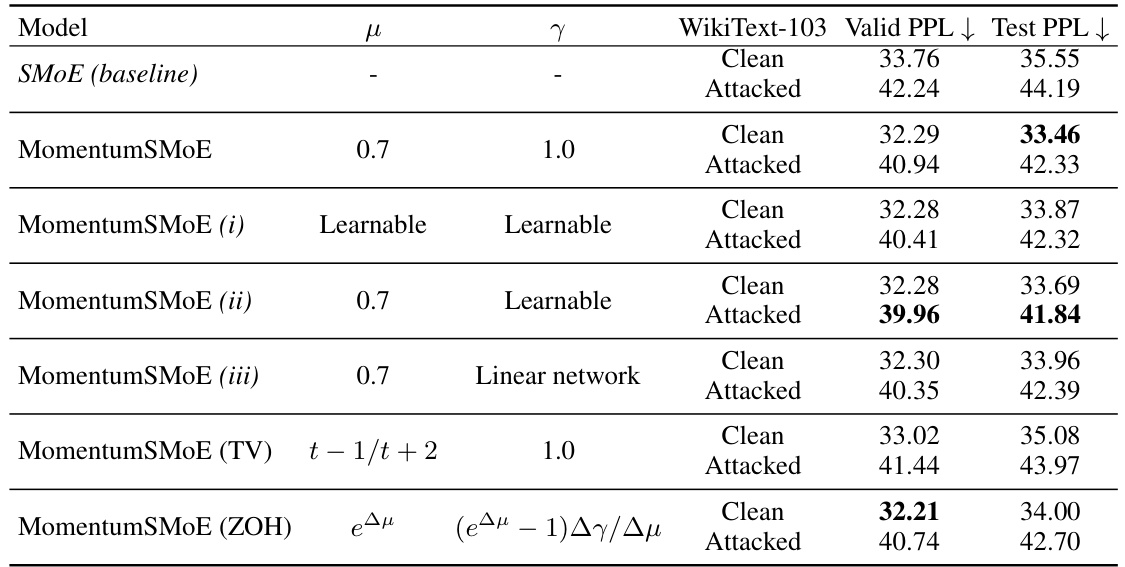
This table shows the perplexity (PPL) results on clean and attacked WikiText-103 validation and test datasets for different versions of the MomentumSMoE model. It compares the performance of the standard MomentumSMoE model with tuned hyperparameters (μ and γ) against MomentumSMoE models where either both or just γ are learned during training, eliminating the need for manual hyperparameter tuning. The results for both clean and attacked datasets are presented to evaluate model robustness.
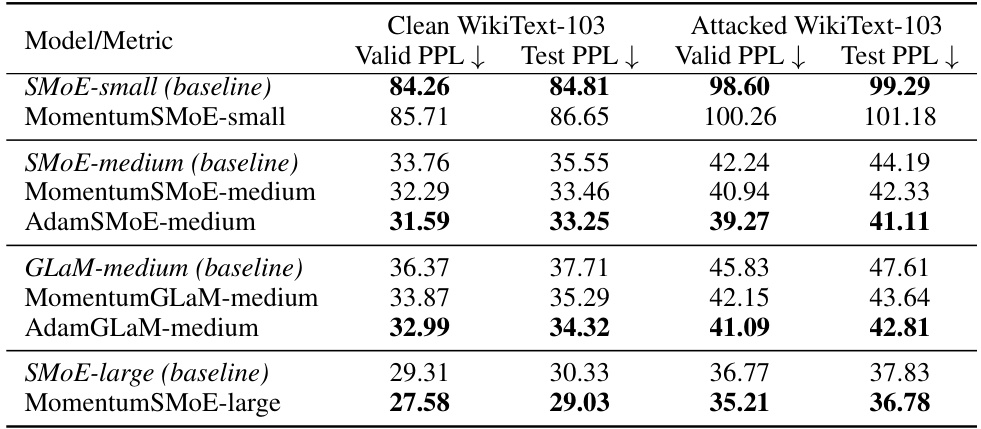
This table presents the perplexity (PPL) scores, a measure of language model performance, for various models on the WikiText-103 dataset. It compares the performance of standard Sparse Mixture of Experts (SMoE) models against versions incorporating momentum (MomentumSMoE), Adam (AdamSMoE), and a medium-sized Generalist Language Model (GLaM) with and without momentum. The results are shown for both clean and ‘attacked’ (word-swapped) versions of the WikiText-103 dataset, providing insight into the models’ robustness to data corruption. Lower PPL values indicate better performance.
This table presents a comparison of the Top-1 accuracy and mean corruption error (mCE) achieved by three different vision models (V-MoE, MomentumV-MoE, and Robust MomentumV-MoE) on the ImageNet-1K dataset and several robustness benchmarks. The benchmarks assess the models’ performance under various image corruptions and perturbations. The table shows that MomentumV-MoE and Robust MomentumV-MoE provide improved accuracy and robustness compared to the baseline V-MoE model.
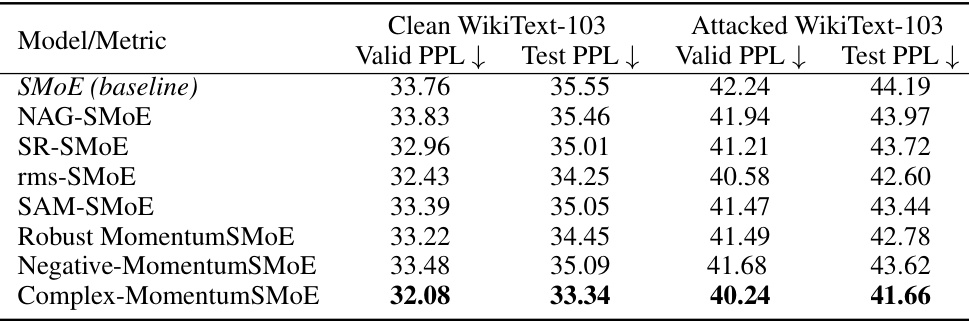
This table presents the perplexity (PPL) results on the WikiText-103 dataset for several variations of the SMoE model, including the baseline model and those incorporating different momentum-based optimization techniques. The results are shown for both clean and attacked (word swap) versions of the dataset, allowing for a comparison of model performance under different conditions. Lower PPL values indicate better performance. The table highlights the impact of various momentum strategies on language modeling performance and robustness against data corruption.
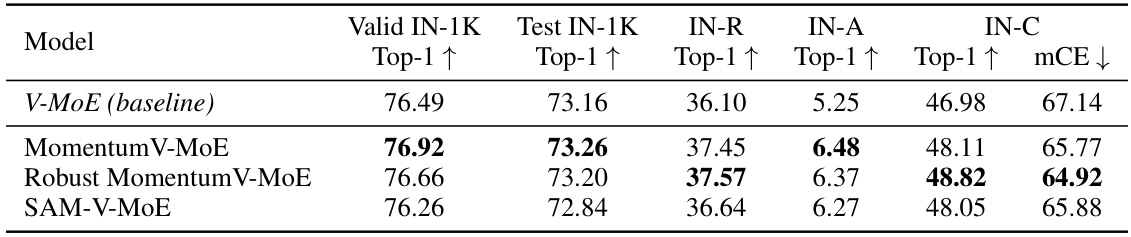
This table presents a comparison of the performance of three different models (V-MoE baseline, MomentumV-MoE, and Robust MomentumV-MoE) on the ImageNet-1K dataset and three robustness benchmarks (ImageNet-C, ImageNet-R, and ImageNet-A). The metrics used are Top-1 accuracy and mean corruption error (mCE). The results demonstrate the improved robustness of the Momentum-enhanced models, particularly the Robust MomentumV-MoE, against various image corruptions and distortions.

This table presents the perplexity (PPL) scores, a metric for evaluating language model performance, for different model variations on the WikiText-103 dataset. It compares the performance of standard Sparse Mixture of Experts (SMoE) models with three momentum-enhanced versions: MomentumSMoE, AdamSMoE, and Robust MomentumSMoE. The results are shown for both clean and ‘attacked’ (adversarially perturbed) versions of the WikiText-103 dataset, providing insights into the models’ robustness to data contamination. Different model sizes (medium and large) are included to analyze the effect of model scale on performance and robustness.
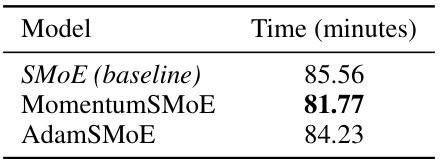
This table presents the total training time in minutes for three different models (SMOE, MomentumSMoE, and AdamSMoE) to achieve a perplexity (PPL) score of 38 on the WikiText-103 validation dataset. It highlights the computational efficiency of the proposed MomentumSMoE model relative to the baseline SMOE and AdamSMoE.
Full paper#