↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Autonomous driving faces challenges in handling complex scenarios and exhibiting adaptability. Current data-driven methods struggle with generalization and often require massive datasets for training. This necessitates a paradigm shift towards knowledge-driven approaches capable of reasoning and adapting to unseen situations.
LeapAD, the proposed method, addresses this by emulating human cognitive processes. It incorporates a dual-process decision-making module and a closed-loop learning system. This system efficiently focuses on critical driving elements, simplifies environmental understanding, and continuously improves through self-reflection. Experiments show LeapAD outperforms camera-only methods by a significant margin, demonstrating continuous improvement and reduced data dependency.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel dual-process approach to autonomous driving, which significantly improves upon existing methods by addressing challenges related to intricate scenarios and limited adaptability. The closed-loop learning mechanism enables continuous improvement, requiring considerably less labeled data than traditional methods. This work is highly relevant to current research trends in AI and autonomous driving, opening avenues for more robust, adaptable, and efficient systems.
Visual Insights#
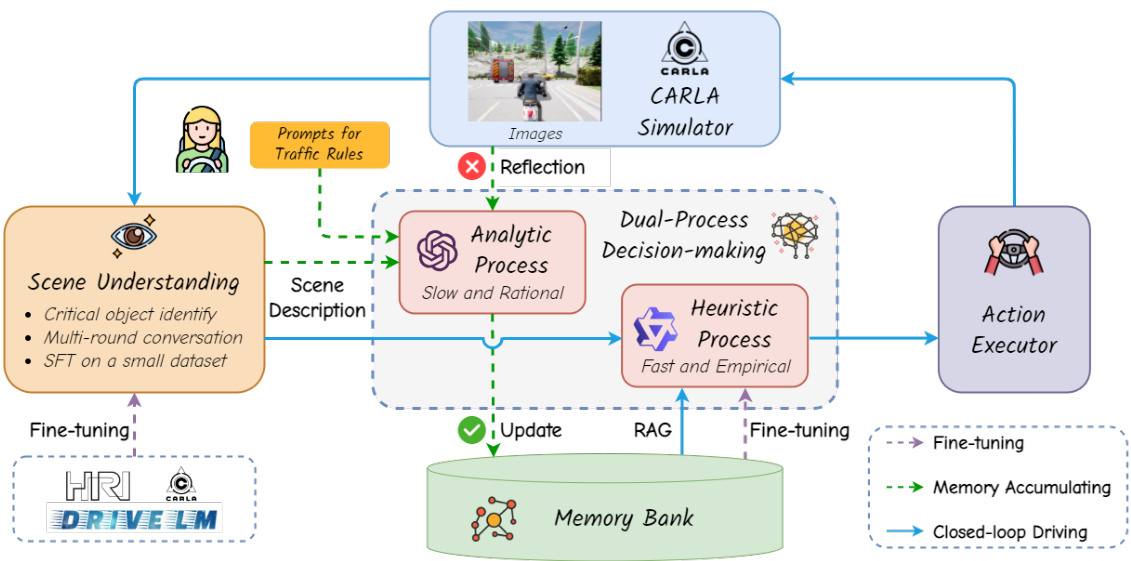
This figure illustrates the architecture of LeapAD, a dual-process closed-loop autonomous driving system. The system comprises three main components: a Vision-Language Model (VLM) for scene understanding, a dual-process decision-making module (Analytic and Heuristic Processes), and an action executor. The VLM processes images and generates descriptions of critical objects. These descriptions are fed to the dual-process module for decision-making. The Analytic Process (slow, rational) uses an LLM for thorough analysis and reasoning, accumulating experience in a memory bank. This experience is then transferred to the Heuristic Process (fast, empirical), a lightweight model, via supervised fine-tuning. The Heuristic Process makes quick driving decisions. When accidents occur, the Analytic Process analyzes the events and updates the memory bank, leading to continuous improvement through self-reflection and closed-loop learning.
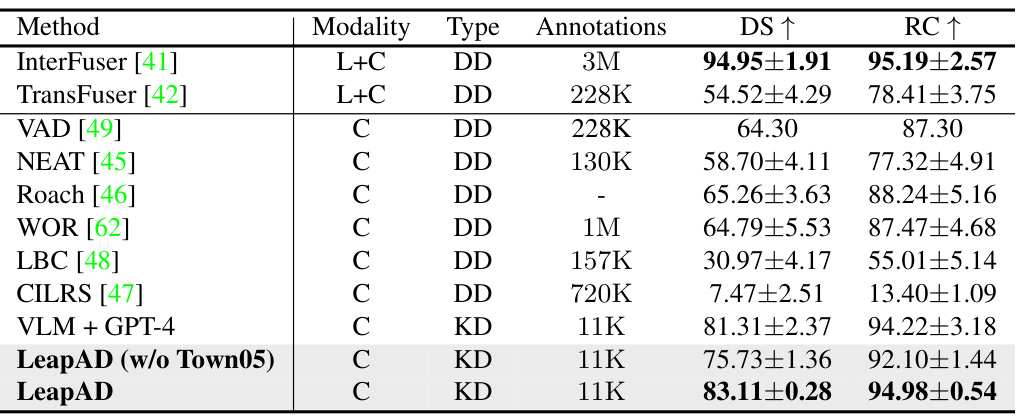
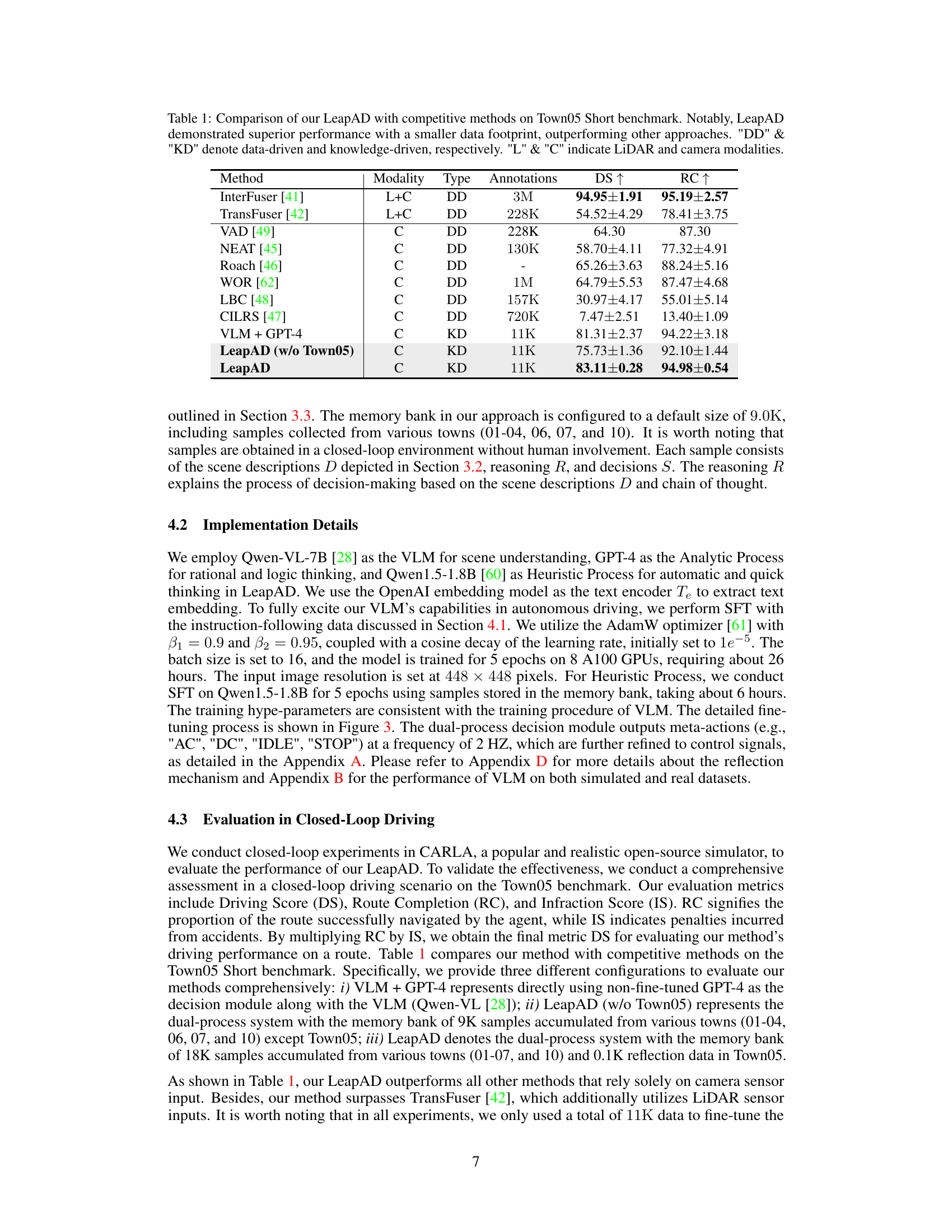
This table compares the performance of LeapAD against other state-of-the-art autonomous driving methods on the Town05 Short benchmark in CARLA. It shows LeapAD’s superior performance (higher Driving Score (DS) and Route Completion (RC)) while using significantly less annotated data. The table also clarifies the type of data used (data-driven (DD) vs. knowledge-driven (KD)) and sensor modalities (LiDAR (L) and Camera (C)).
In-depth insights#
Dual-Process Paradigm#
The dual-process paradigm, inspired by human cognitive architecture, offers a novel approach to autonomous driving. It posits two interacting systems: a fast, intuitive System 1 (heuristic process) for rapid, experience-based decisions and a slow, deliberative System 2 (analytic process) for deeper reasoning and complex analysis. System 1 learns from System 2’s refined experiences through a mechanism like supervised fine-tuning, constantly updating its knowledge base. This closed-loop interaction allows for continuous learning and improvement, moving beyond the limitations of purely data-driven methods. Closed-loop testing, crucial for real-world applicability, demonstrates LeapAD’s superior performance with significantly reduced data requirements. The paradigm’s focus on attention mechanisms, selecting critical driving information, also reduces computational complexity and enhances efficiency. Transferable knowledge from the analytic process to the heuristic process enables generalization to unseen scenarios, making this a potentially more robust and adaptable autonomous driving framework.
VLM Scene Encoding#
VLM scene encoding is a crucial step in enabling autonomous driving systems to effectively interpret complex visual environments. The core idea involves using a Vision-Language Model (VLM) to transform raw image data into concise, informative textual descriptions. This textual representation, focusing on critical objects and their attributes, avoids the computational burden of processing the entire scene. Effective VLM scene encoding leverages techniques like supervised fine-tuning to adapt the VLM to driving scenarios, ensuring accurate and relevant information is extracted. The emphasis is on identifying key objects that directly influence driving decisions, filtering out irrelevant details. Furthermore, strategies such as compressed captioning can enhance the efficiency and effectiveness of the encoding process, facilitating faster retrieval and improving performance. The choice of VLM and its training data plays a vital role in determining the quality of the scene encoding. A well-trained VLM is essential for generating detailed, accurate, and concise descriptions that are both useful for downstream tasks like decision-making and robust across various scenarios.
Closed-Loop Learning#
Closed-loop learning in the context of autonomous driving represents a significant advancement over traditional open-loop methods. Open-loop systems simply receive input, process it, and output an action without considering the consequences of that action. In contrast, closed-loop systems incorporate a feedback mechanism, enabling them to learn from their mistakes and adapt to dynamic environments. This feedback loop is crucial because autonomous vehicles operate in complex and unpredictable conditions where immediate responses are critical and mistakes can have serious ramifications. Real-world driving inherently involves closed-loop learning; drivers continually adjust based on road conditions, the actions of other drivers, and unexpected events. Emulating this process is crucial for creating truly robust and safe autonomous driving systems. The continuous interaction between the autonomous system and the environment allows for the refinement of models, improving their accuracy and reliability over time. The collection of data in a closed-loop system provides richer, more contextually relevant information which aids in better understanding complex scenarios and improving the system’s generalization capabilities. By effectively utilizing feedback in a continuous manner, closed-loop learning becomes a vital step in the development of autonomous driving technology that is not only highly capable but also demonstrably safe.
Memory Bank Transfer#
A memory bank transfer mechanism is crucial for effective continuous learning in autonomous driving. It involves accumulating high-quality driving experiences, typically generated by a more sophisticated reasoning module (e.g., an analytic process), within a memory bank. This knowledge is then efficiently transferred to a lightweight, faster module (e.g., a heuristic process), enabling quick, reactive responses in real-time. Supervised fine-tuning (SFT) is commonly used to transfer this knowledge, adapting the lighter model to the accumulated experience. The size and composition of the memory bank directly influence performance, with larger and more diverse banks potentially leading to superior generalization. The effectiveness hinges on the ability to selectively retrieve relevant memories for similar driving scenarios, often using techniques such as embedding similarity to query the bank. Challenges include determining optimal memory bank size, managing memory updates efficiently (e.g., incorporating error correction via reflection mechanisms), and addressing potential issues such as catastrophic forgetting. A well-designed memory bank transfer is key to achieving both performance and efficiency in a continuously learning autonomous driving system.
Future Work: Scalability#
Future scalability of the described autonomous driving system hinges on several key factors. Efficient memory management is crucial; the current system’s reliance on a growing memory bank for continuous learning might become computationally prohibitive with extensive real-world data. Strategies for efficient knowledge transfer from the Analytic Process to the Heuristic Process need further development to maintain the balance between speed and accuracy. Modular design would enhance scalability, allowing independent updates and improvements to different components without requiring retraining of the entire system. Distributed computing could further improve efficiency and handle increased data volume and complexity. Robustness to noisy and incomplete data is critical for real-world deployment, necessitating improved error handling and self-correction mechanisms. Finally, research into more advanced scene understanding techniques that require less computational overhead is needed. Addressing these areas would greatly enhance the system’s ability to handle large-scale datasets and adapt to diverse, dynamic driving environments.
More visual insights#
More on figures
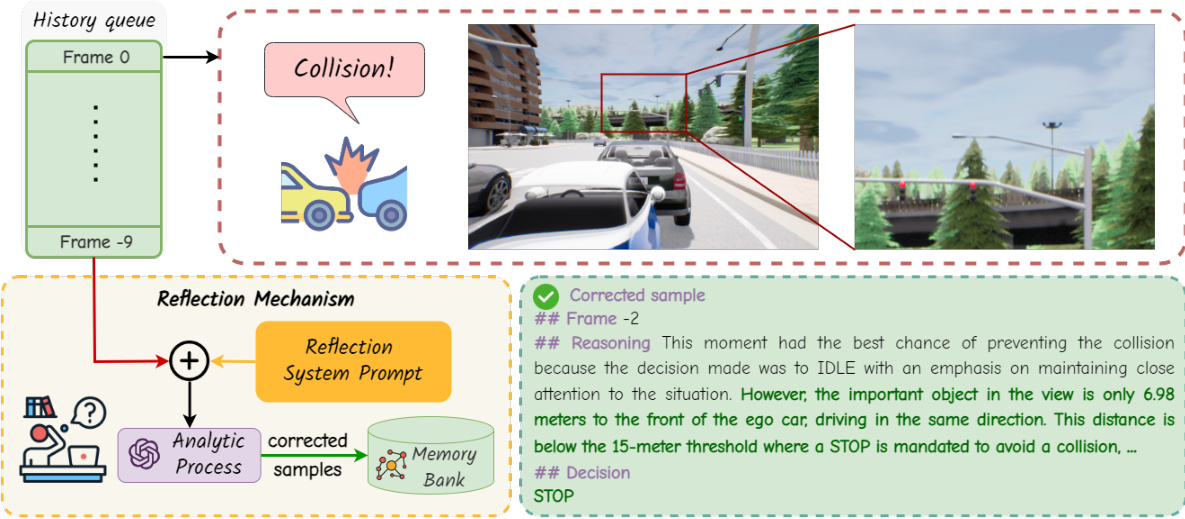
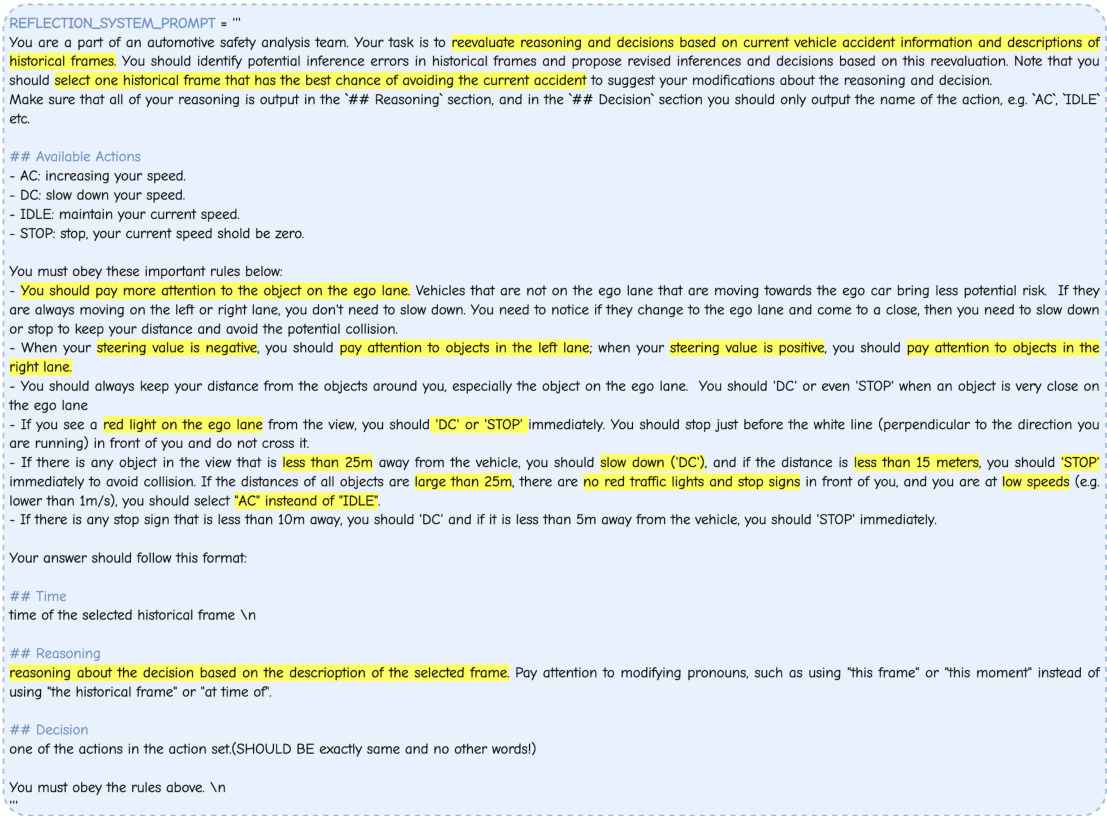
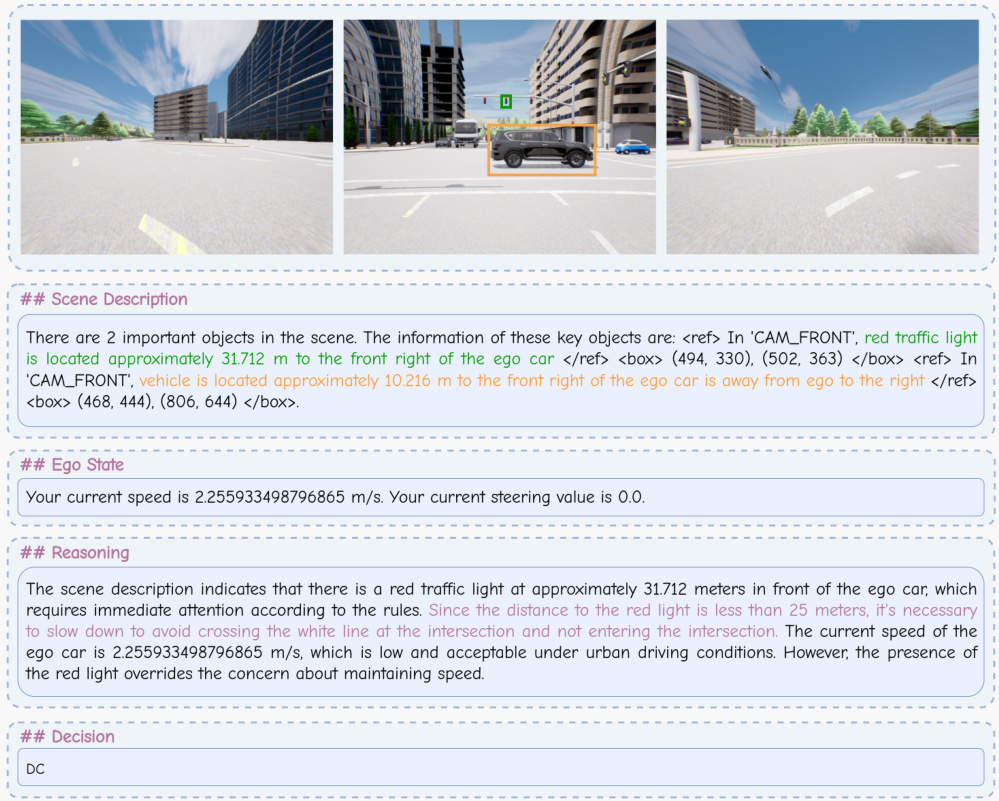
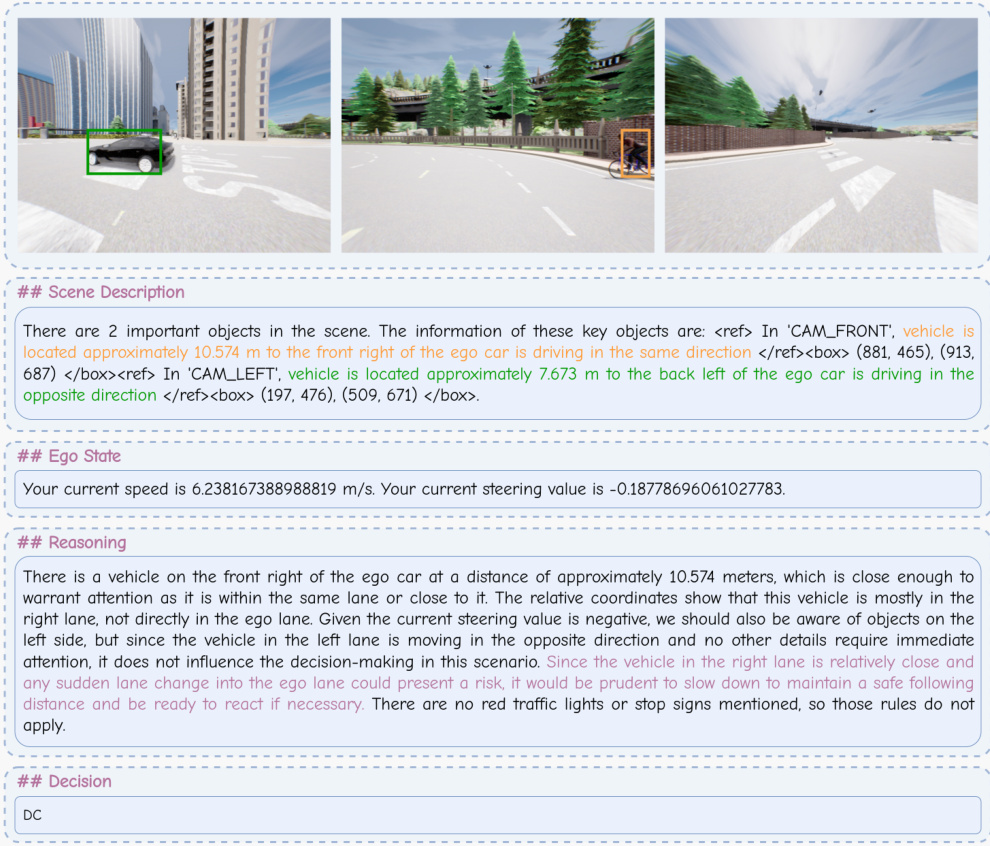
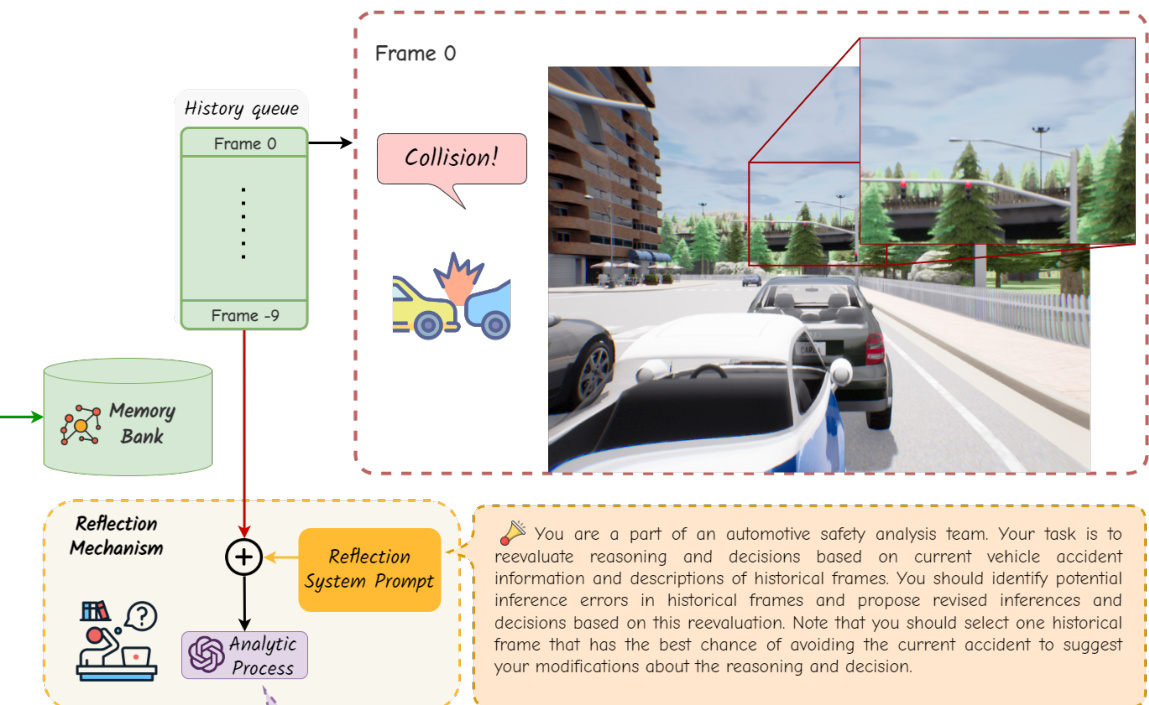
This figure shows the detailed process of how the reflection mechanism works. When a traffic accident occurs, the Heuristic Process will trigger the reflection mechanism. The Analytic Process analyzes the preceding frames to pinpoint errors and provides corrected samples. These corrected samples will be integrated into the memory bank, which enables continuous learning and improvement of the model.

This figure illustrates the fine-tuning process of the two main components of LeapAD’s dual-process decision-making module: the Vision-Language Model (VLM) and the Heuristic Process. The left side shows how the VLM is fine-tuned using 11,000 instruction-following data samples for scene understanding. The right side depicts how the Heuristic Process (a lightweight language model, Qwen-1.5) is fine-tuned using samples from the memory bank accumulated during the Analytic Process. This highlights the transfer learning aspect of the LeapAD architecture.
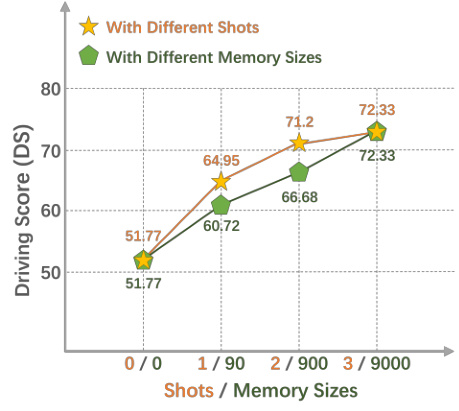
This ablation study investigates the impact of the number of few-shot prompts and the size of the memory bank on the performance of LeapAD. The graph shows Driving Score (DS) on the y-axis and the number of shots/memory sizes on the x-axis. Two lines are presented: one for varying the number of shots and another for varying memory bank sizes. Both show improved performance with an increasing number of shots or memory size, demonstrating the contribution of continuous learning and experience accumulation in LeapAD.
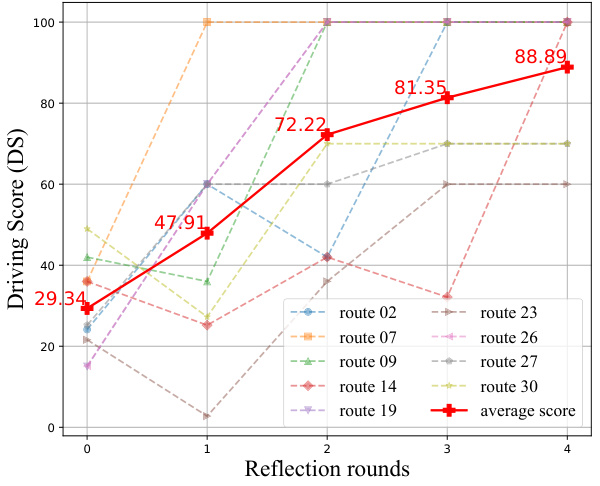
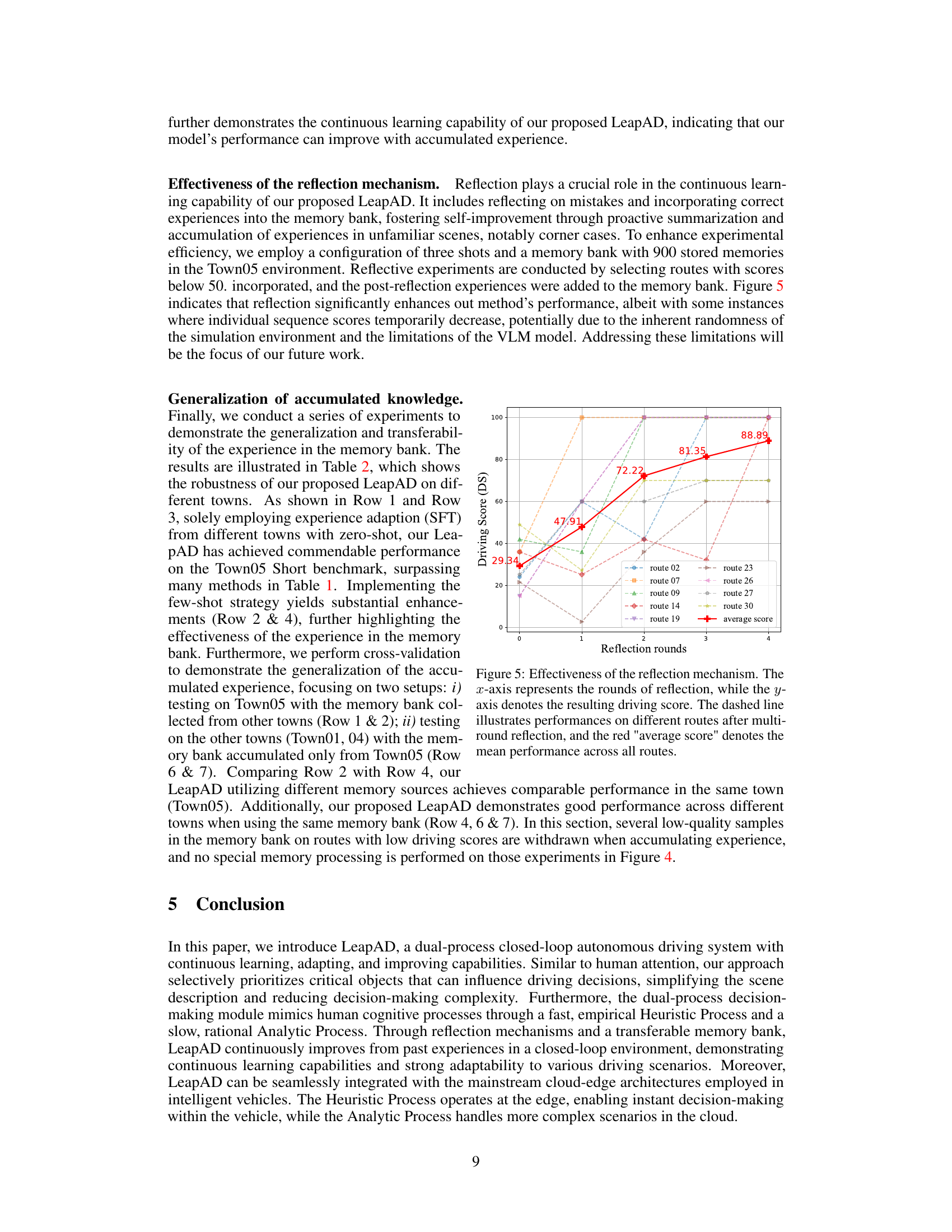
This figure shows the effectiveness of the reflection mechanism implemented in LeapAD. The x-axis represents the number of reflection rounds, and the y-axis represents the driving score (DS). Multiple lines represent individual routes, demonstrating the variability in performance. The red line shows the average driving score across all routes. As the number of reflection rounds increases, the average driving score improves significantly, indicating that the reflection mechanism effectively helps LeapAD learn from its mistakes and improve its performance over time. There is some variation across individual routes, highlighting the complex and unpredictable nature of driving scenarios.

This figure presents a detailed architecture diagram of the LeapAD system. It illustrates the flow of information from scene understanding (using a VLM) through dual-process decision-making (Analytic and Heuristic Processes) to action execution in a driving simulator. The Analytic Process leverages LLMs for in-depth analysis, reflection, and knowledge accumulation in a memory bank, which is then used to fine-tune the Heuristic Process for efficient, experience-based decision-making.

This figure illustrates the overall architecture of the LeapAD system, highlighting the three main components: scene understanding, dual-process decision-making, and action executor. The scene understanding module uses a Vision Language Model (VLM) to identify critical objects and generate descriptive text. The dual-process decision-making module uses a Heuristic Process (fast, experience-based) and an Analytic Process (slow, reasoning-based). The Analytic Process uses a Large Language Model (LLM) to analyze situations and learn from mistakes, storing its findings in a memory bank. The knowledge from the Analytic Process is then transferred to the Heuristic Process via supervised fine-tuning. Finally, the action executor translates high-level decisions into low-level control signals for the vehicle.

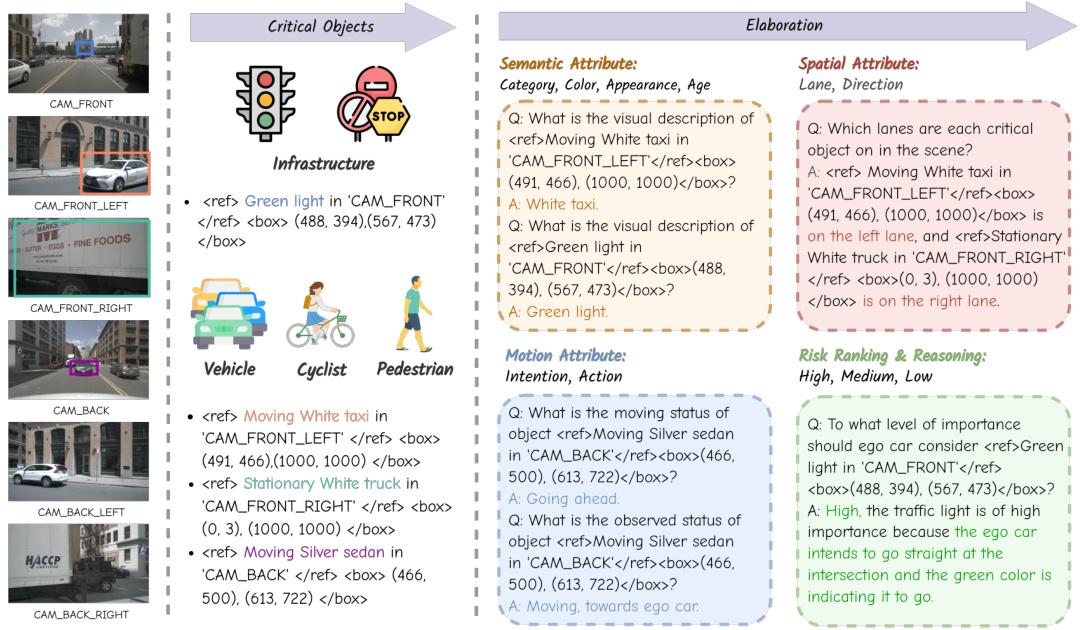
This figure shows a detailed breakdown of the data format used to describe critical objects in the driving scene. It illustrates how the Visual Language Model (VLM) generates descriptions including semantic attributes (object category, color, appearance, age), motion attributes (intention, action), spatial attributes (lane, direction, bounding box coordinates, distance from ego vehicle), and risk ranking with decision reasoning. This structured data format enables a comprehensive scene understanding for autonomous driving decision-making.
This figure illustrates the architecture of LeapAD, a dual-process autonomous driving system. It shows the flow of information from scene understanding (using a Vision Language Model, VLM) to dual-process decision-making (Heuristic and Analytic Processes), and finally to action execution in a driving simulator. The Analytic Process uses a large language model (LLM) for detailed analysis and learning from mistakes, storing this knowledge in a memory bank. This knowledge is then transferred to the lightweight Heuristic Process for faster, more efficient decision-making in real-time.

This figure presents a detailed architecture of LeapAD, highlighting the three main components: Scene Understanding, Dual-Process Decision-making, and Action Executor. Scene Understanding uses a Vision-Language Model (VLM) to identify critical objects for simplified environmental description. The Dual-Process module, inspired by human cognition, consists of an Analytic Process (using LLMs for detailed reasoning and accumulating experience in a memory bank) and a Heuristic Process (a lightweight model fine-tuned using the experience from the Analytic Process). The Action Executor translates high-level decisions into control signals for the simulator. The closed-loop system allows continuous learning and improvement through reflection on accidents and updating of the memory bank.
This figure illustrates the architecture of LeapAD, a dual-process autonomous driving system. It shows how the system processes images from the environment using a Vision Language Model (VLM) to identify key objects. These objects are then used by a dual-process decision module, consisting of a fast Heuristic Process and a slower Analytic Process. The Analytic Process, powered by a Large Language Model (LLM), learns from past experiences and accidents to refine driving decisions. This refined knowledge is transferred to the Heuristic Process for faster, more efficient decision-making. A memory bank stores and manages this accumulated experience, enabling continuous learning and improvement.

This figure illustrates the architecture of LeapAD, a dual-process closed-loop autonomous driving system. It shows how the system uses a Vision Language Model (VLM) for scene understanding, feeding the results into a dual-process decision-making module (Heuristic and Analytic Processes). The Analytic Process uses an LLM to learn from experience, storing this knowledge in a memory bank and transferring it to the Heuristic Process for faster, more efficient decision-making. The system interacts with a driving simulator (CARLA) in a closed loop.
This figure presents a detailed architecture of the LeapAD system. It shows three main components: scene understanding with VLM, dual-process decision making (Analytic and Heuristic Processes), and action executor. The scene understanding module processes images to identify critical objects, feeding descriptions to the dual-process module. The Analytic Process, powered by an LLM, analyzes situations and stores high-quality decisions in a memory bank. This knowledge is transferred to the Heuristic Process (lightweight model), which makes fast driving decisions. The closed-loop system allows continuous learning from past mistakes through self-reflection when accidents occur.
This figure presents the architecture of LeapAD, a dual-process autonomous driving system. It shows the flow of information from scene understanding (using a Vision-Language Model) to a dual-process decision-making module (comprising Analytic and Heuristic Processes). The Analytic Process utilizes an LLM for in-depth analysis and learning from accidents, storing this experience in a memory bank. This knowledge is then transferred to the Heuristic Process via supervised fine-tuning, enabling quicker, more efficient decision-making. The system interacts with a driving simulator (CARLA).

This figure presents a detailed overview of the LeapAD architecture, highlighting its three main components: scene understanding, dual-process decision-making, and action execution. It illustrates how the system processes images, identifies critical objects, and uses a dual-process approach, incorporating both a fast, empirical Heuristic Process and a slow, rational Analytic Process, to make driving decisions. The Analytic Process leverages an LLM to learn from experience, storing knowledge in a memory bank that is then used to improve the Heuristic Process’s performance through fine-tuning. The closed-loop system allows for continuous learning and adaptation.

This figure presents the architecture of LeapAD, a dual-process autonomous driving system. It shows how the system processes images from cameras to identify critical objects, feeding these descriptions to the dual-process decision-making module. This module contains a Heuristic Process for quick, empirical decisions, and an Analytic Process for slower, more rational decisions that are learned from past experiences stored in a memory bank. The Analytic Process uses an LLM and learning from accidents to refine the knowledge base and improve the system’s performance. The Heuristic Process then receives and utilizes this improved knowledge to improve efficiency.
This figure presents a detailed architecture of the LeapAD system. It shows how the scene understanding module processes images and creates descriptions of critical objects affecting driving decisions. The dual-process decision module uses both a Heuristic Process for quick decisions and an Analytic Process for deep reasoning, learning from experiences stored in a memory bank. The Analytic Process uses an LLM for deep analysis and reflection, continuously improving the system’s performance.

This figure shows a failure case where the autonomous driving system runs a red light. The left image shows the system approaching an intersection with a yellow traffic light, and the right image shows the system continuing to move after the light turned red. This failure is attributed to a lack of temporal information in the system’s input regarding the remaining duration of the yellow light and the challenges in determining whether to accelerate through or stop.

This figure shows the architecture of LeapAD, a dual-process autonomous driving system. It illustrates the three main components: scene understanding (using a Vision Language Model), dual-process decision-making (Heuristic and Analytic Processes), and action execution. The Analytic Process uses an LLM for in-depth analysis and learning from mistakes, storing this knowledge in a memory bank. This knowledge is then transferred to the Heuristic Process via supervised fine-tuning, enabling continuous learning and improvement in driving decisions.
More on tables
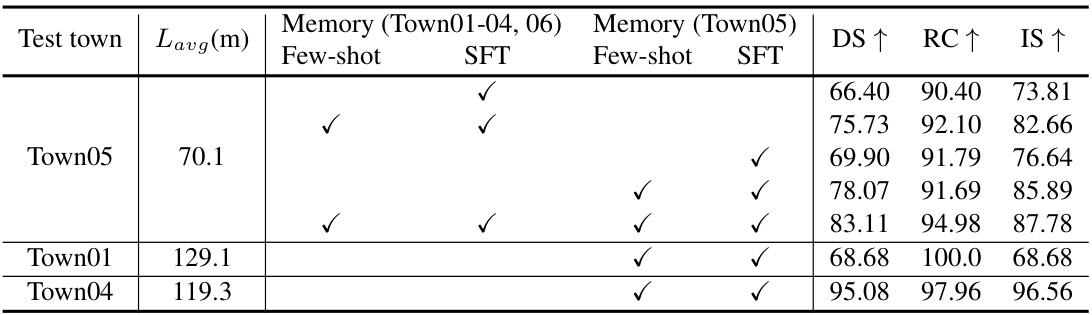
This table shows the performance of LeapAD on different towns using memory banks accumulated from various sources. It demonstrates the model’s ability to generalize accumulated knowledge across different driving environments and route lengths, with and without fine-tuning on a specific town’s data. The results highlight the impact of both few-shot learning and fine-tuning strategies on performance and the effectiveness of the accumulated experience in the memory bank for model generalization.

This table compares the performance of LeapAD against other state-of-the-art autonomous driving methods on the Town05 Short benchmark. It shows LeapAD’s superior performance using only camera data and significantly less training data (11K annotations) compared to other methods that utilize both LiDAR and camera data or significantly more training data. The table highlights the effectiveness of LeapAD’s knowledge-driven approach (KD) over data-driven approaches (DD).
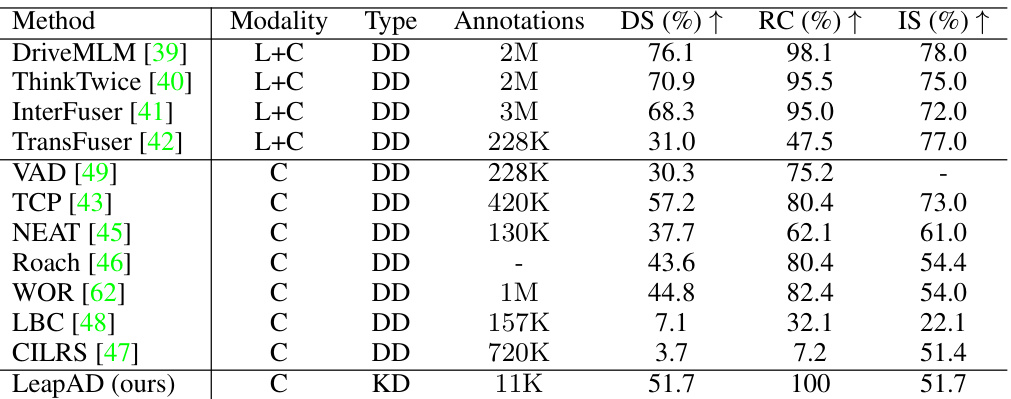
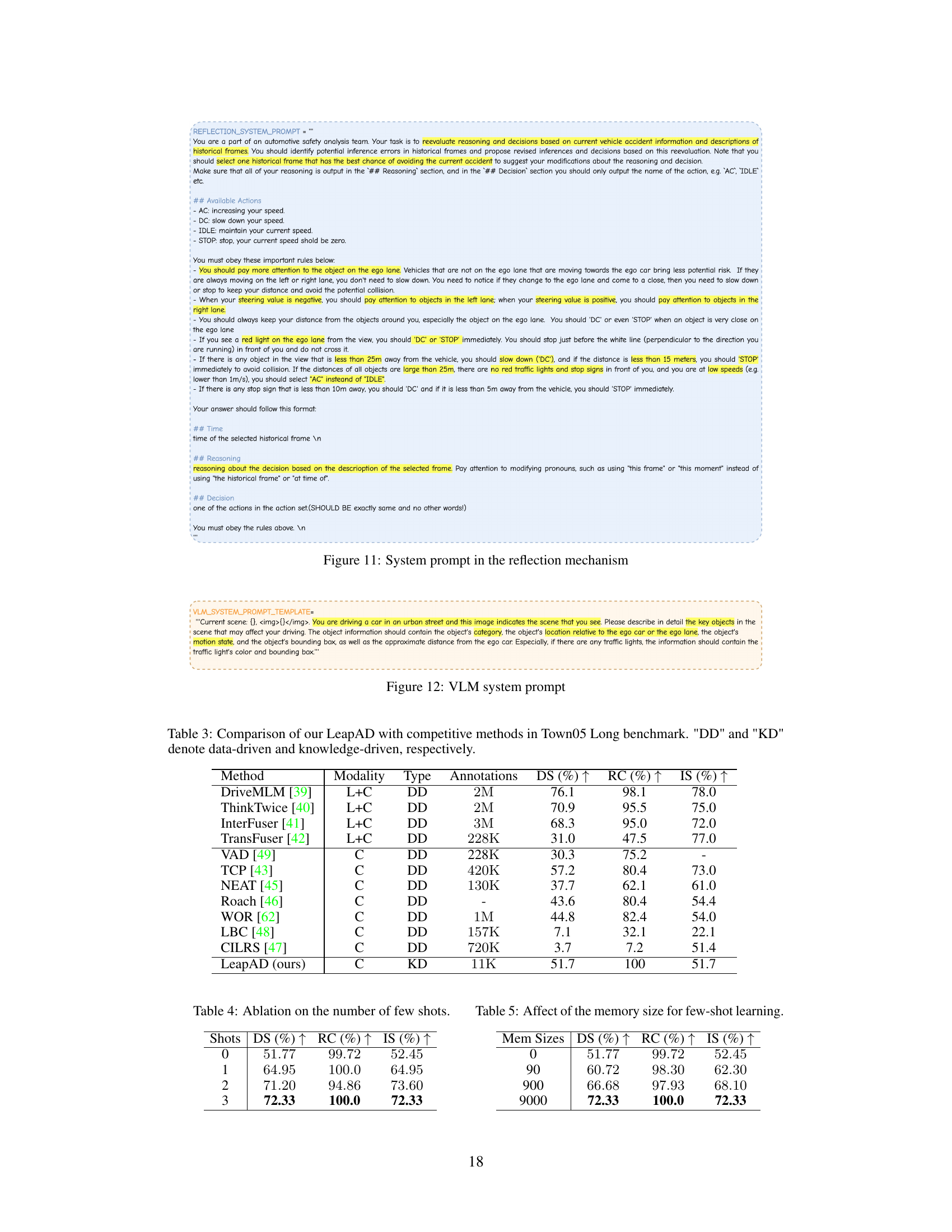
This table compares the performance of LeapAD with other state-of-the-art methods on the Town05 Long benchmark in autonomous driving. It shows the Driving Score (DS), Route Completion (RC), and Infraction Score (IS) for each method. The modality (camera only (C) or camera and LiDAR (L+C)) and type of approach (data-driven (DD) or knowledge-driven (KD)) are also indicated. The annotations column shows the amount of training data used for each method. LeapAD achieves competitive performance while using significantly less training data.

This table presents the results of an ablation study on the number of few-shot prompts used in the Heuristic Process of the LeapAD model. The study varies the number of shots (0, 1, 2, and 3) and measures the impact on the Driving Score (DS), Route Completion (RC), and Infraction Score (IS). The results demonstrate the effectiveness of few-shot prompting in improving model performance and show a clear positive trend as the number of shots increases.

This table presents the ablation study on the impact of memory bank size on the performance of LeapAD using a 3-shot strategy. It shows that as the memory bank size increases from 90 samples to 9000 samples, the driving score (DS), route completion (RC), and infraction score (IS) all improve. This demonstrates the continuous learning capability of the model, where larger memory banks lead to better performance.
Full paper#