↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generative diffusion models, especially those using diffusion transformers (DiTs), have shown great promise in image generation. However, current masked-reconstruction training strategies often suffer from insufficient contextual information extraction. This is largely due to the use of noisy-to-noisy reconstruction, where the model reconstructs masked noisy patches from unmasked noisy patches, hindering proper contextual understanding.
The paper introduces MC-DiT, a novel approach that addresses these issues by using clean-to-clean masked reconstruction. Instead of reconstructing noisy patches from other noisy patches, MC-DiT trains the model to reconstruct clean patches from other clean patches. This allows the model to better utilize contextual information and avoids the negative impacts of noise. Through extensive experiments on ImageNet, MC-DiT demonstrates state-of-the-art performance, surpassing previous methods in terms of image quality and training speed.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on generative diffusion models, especially those using diffusion transformers. It challenges existing assumptions about masked reconstruction in diffusion models and proposes a novel, more effective training method. The findings advance the state-of-the-art in unconditional and conditional image generation. This opens up new avenues for improving the efficiency and quality of image generation techniques and inspires further investigation into the role of contextual information in diffusion models.
Visual Insights#
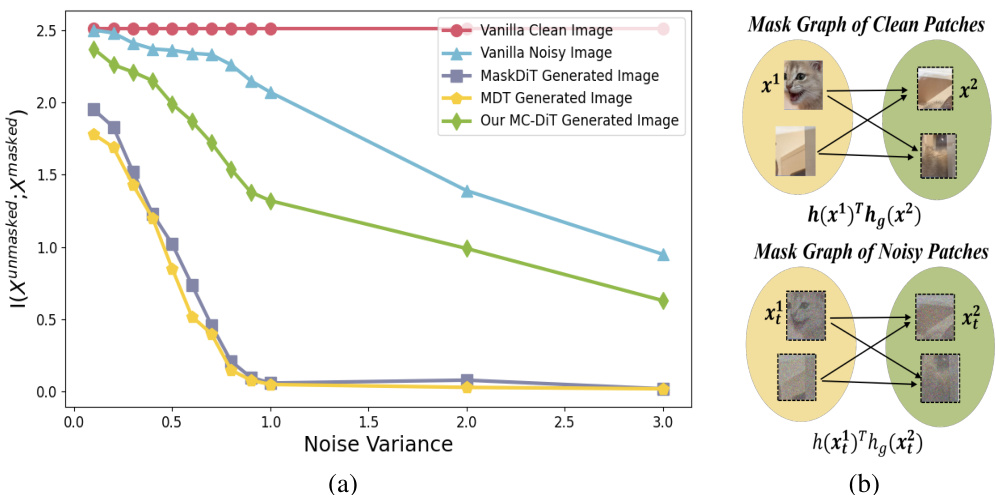
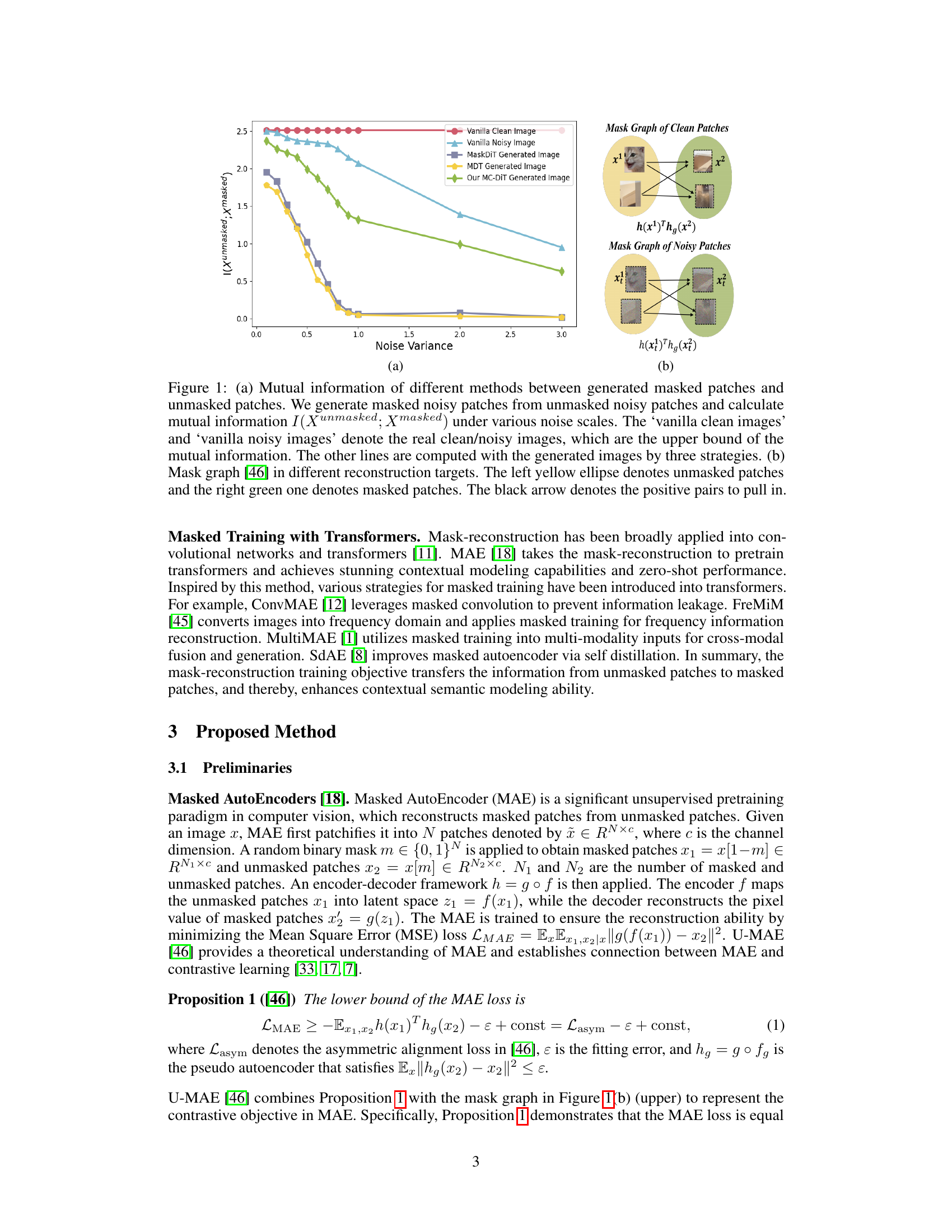
This figure demonstrates the impact of noise variance on the mutual information between unmasked and masked patches for different methods. Subfigure (a) shows that as noise variance increases, the mutual information in noisy patches generated by MDT [13] and MaskDiT [48] decreases sharply, while mutual information in vanilla noisy images decreases slowly. This suggests insufficient contextual information exploitation in noisy-to-noisy mask reconstruction. Subfigure (b) illustrates the mask graph [46] concept, highlighting the difference in reconstruction targets between clean patches and noisy patches.
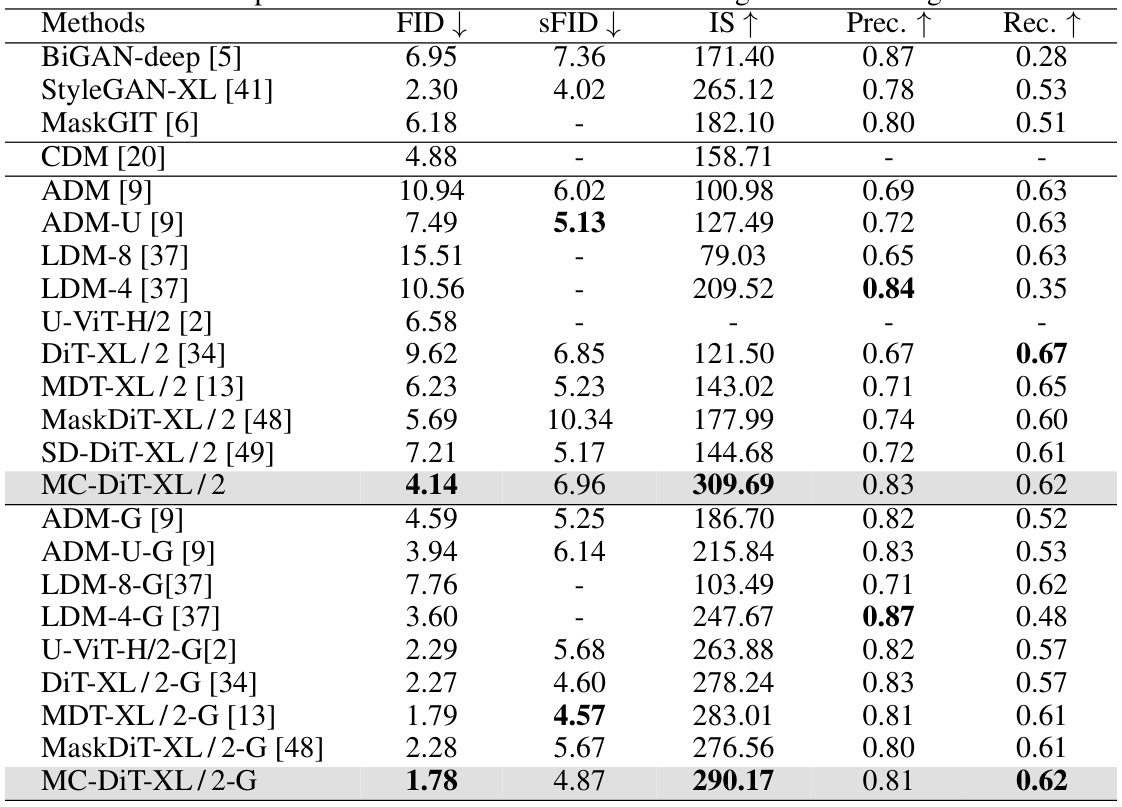
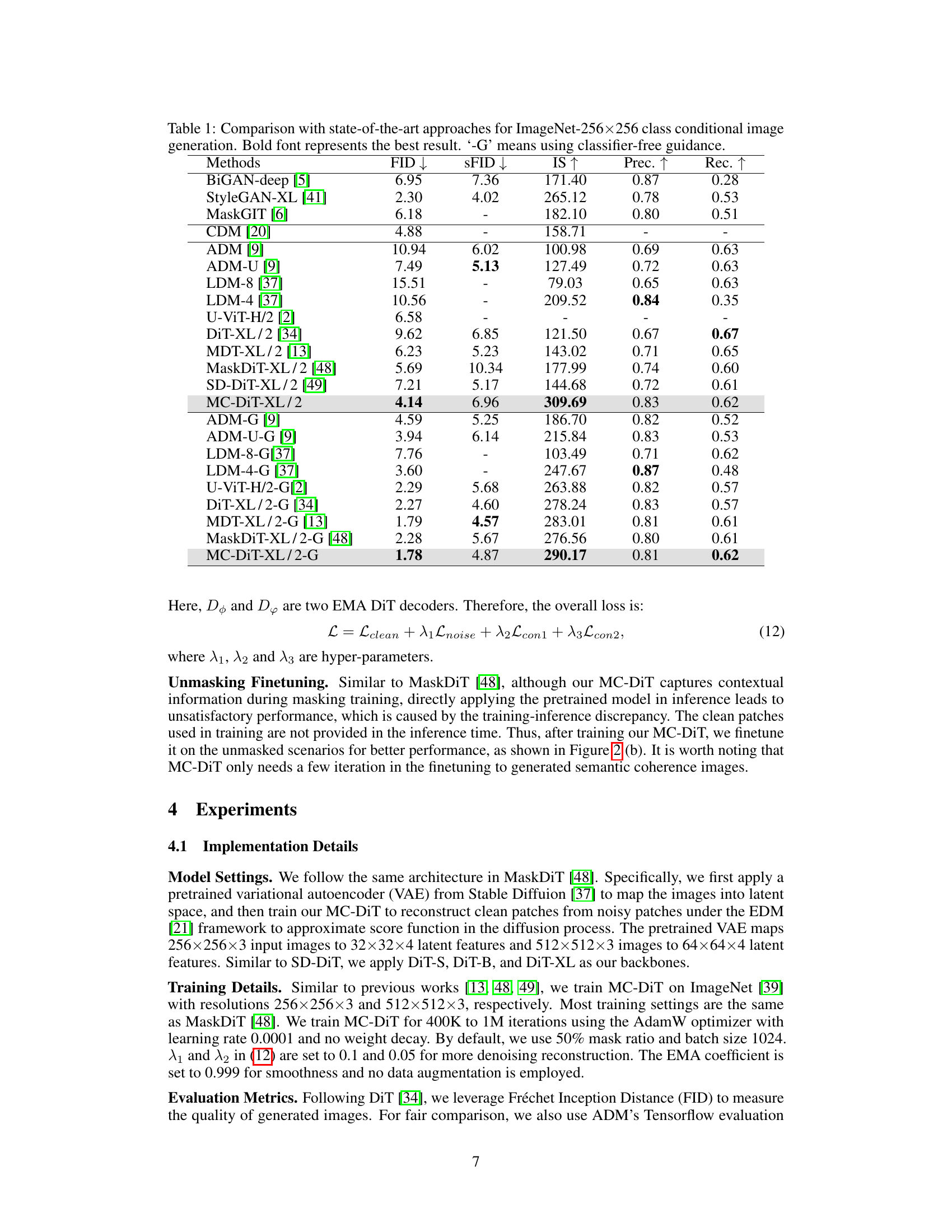
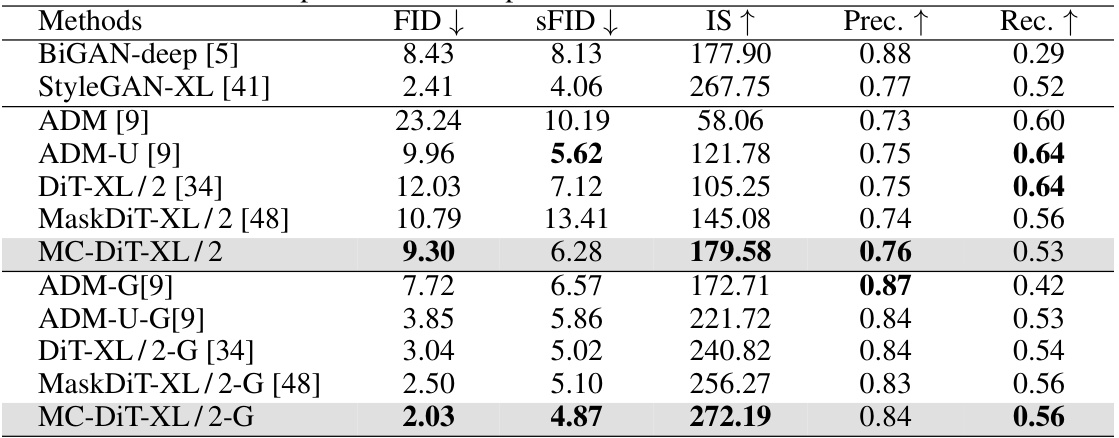
This table compares the performance of the proposed MC-DiT model with other state-of-the-art models on the ImageNet-256x256 dataset for class-conditional image generation. The metrics used for comparison are FID (Fréchet Inception Distance), SFID (a variant of FID), IS (Inception Score), Precision, and Recall. Lower FID and SFID scores indicate better performance, while higher IS, Precision, and Recall scores represent better image quality. The ‘-G’ indicates that classifier-free guidance was used for those particular models. The table highlights the superior performance of the MC-DiT model across various metrics, especially when classifier-free guidance is employed.
In-depth insights#
Clean-to-Clean DiT#
The concept of “Clean-to-Clean DiT” presents a novel approach to masked image modeling within the Diffusion Transformer (DiT) framework. Traditional noisy-to-noisy reconstruction methods, while efficient, hinder the effective utilization of contextual information, particularly at higher noise levels. Clean-to-clean reconstruction addresses this by training the model to reconstruct clean masked patches from clean unmasked patches. This allows the DiT to learn richer contextual relationships across image regions without the interference of added noise. This approach is theoretically justified through analysis of mutual information between masked and unmasked patches, demonstrating the superiority of clean-to-clean reconstruction in capturing contextual dependencies. However, it necessitates a mechanism to prevent model collapse, where the model over-relies on clean patches and neglects the denoising process. The introduction of complementary branches within the DiT decoder, one focusing on noisy patches and the other on clean patches, offers a potential solution to this issue. This dual-branch architecture ensures the model effectively learns both contextual information and denoising capabilities, leading to improved performance and faster convergence. Overall, Clean-to-Clean DiT represents a significant advancement in DiT training, offering a more robust and powerful method for image generation tasks.
Contextual Info Loss#
The concept of “Contextual Info Loss” in the context of masked diffusion models for image generation is crucial. Insufficient utilization of contextual information during training significantly hampers the model’s ability to generate high-quality, semantically consistent images. The paper highlights that existing noisy-to-noisy masked reconstruction methods hinder the effective use of contextual cues because noisy patches contain limited information. This leads to a degradation in performance, especially at higher noise levels, as demonstrated empirically through mutual information analysis. The core insight revolves around leveraging clean-to-clean reconstruction for training, allowing the model to better capture and utilize the relationships between image regions. This strategy directly addresses the issue of contextual information loss, improving the model’s learning process and resulting in more coherent and realistic image outputs. The proposed MC-DiT architecture exemplifies this concept and produces superior results. The core of the issue lies in the quality and quantity of information available for reconstruction; clean data provides much richer contextual clues than noisy data.
MC-DiT Training#
MC-DiT training introduces a novel clean-to-clean reconstruction paradigm for masked diffusion models. This contrasts with prior noisy-to-noisy approaches, which are shown to hinder effective contextual information extraction. The clean-to-clean strategy allows the model to learn richer contextual relationships at various noise levels during the diffusion process. To prevent model collapse, where the network over-relies on clean patches, MC-DiT incorporates two complementary decoder branches. One branch focuses on reconstructing noisy patches, while the other concentrates on clean patch reconstruction. This dual-branch architecture enhances the model’s robustness and ensures effective learning from both clean and noisy information. The training procedure leverages the strengths of masked autoencoders and diffusion models, enabling efficient and effective learning of complex image structures. The results demonstrate that MC-DiT achieves superior performance in image generation tasks compared to existing methods, showcasing the benefits of the proposed training strategy.
Model Collapse Issue#
The Model Collapse Issue is a critical challenge in training masked diffusion models like the one presented. Model collapse occurs when the model over-relies on shortcuts, such as reconstructing masked patches solely from easily accessible information in the unmasked regions, instead of learning the complex relationships needed for accurate and diverse image generation. This leads to poor generalization, as the model fails to produce novel or varied outputs. The authors address this issue by introducing two complementary decoders: one focused on denoising, the other on contextual enhancement via clean-to-clean reconstruction. This dual-branch approach is crucial as it helps to mitigate the model’s overreliance on clean patches while still leveraging their valuable contextual information. The strategy’s success hinges on a careful balance between these two branches, thereby preventing the model from collapsing into producing repetitive outputs and promoting more robust and diverse image generation.
Future Work#
Future work in this research area could explore several promising directions. Improving the efficiency of the MC-DiT training process is crucial, possibly by exploring alternative optimization strategies or architectural modifications. Investigating the generalizability of MC-DiT to other image datasets and modalities would validate its robustness and broaden its applicability. A further research area would involve a deeper analysis of the model collapse phenomenon and developing more effective strategies to mitigate it beyond the dual EMA branch approach, which may include architectural changes or novel training objectives. Expanding the conditional image generation capabilities of MC-DiT by incorporating more diverse conditioning information such as text or other modalities would also be valuable. Finally, exploring the theoretical underpinnings of clean-to-clean reconstruction in the context of diffusion models could lead to a more principled understanding of the effectiveness of this approach and potentially inspire novel training paradigms for generative models.
More visual insights#
More on figures
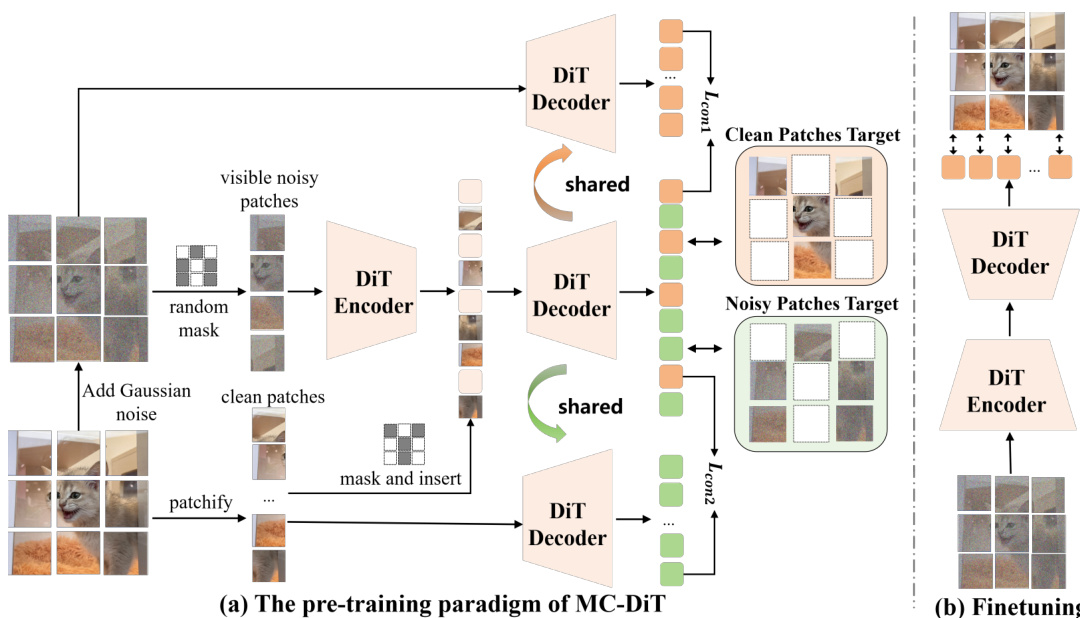
This figure illustrates the architecture of the proposed MC-DiT model for image generation. Panel (a) shows the pre-training stage, where the model learns contextual information by reconstructing unmasked clean image patches from masked clean patches. This process is enhanced by two parallel branches (EMA branches) to mitigate model collapse. Panel (b) depicts the fine-tuning stage, where the pre-trained model is further trained on unmasked patches to improve its performance in denoising and image generation.
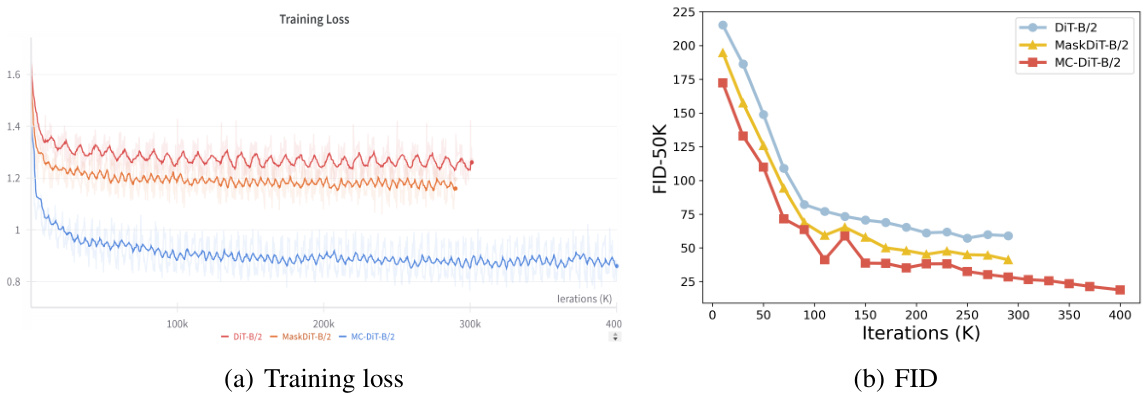
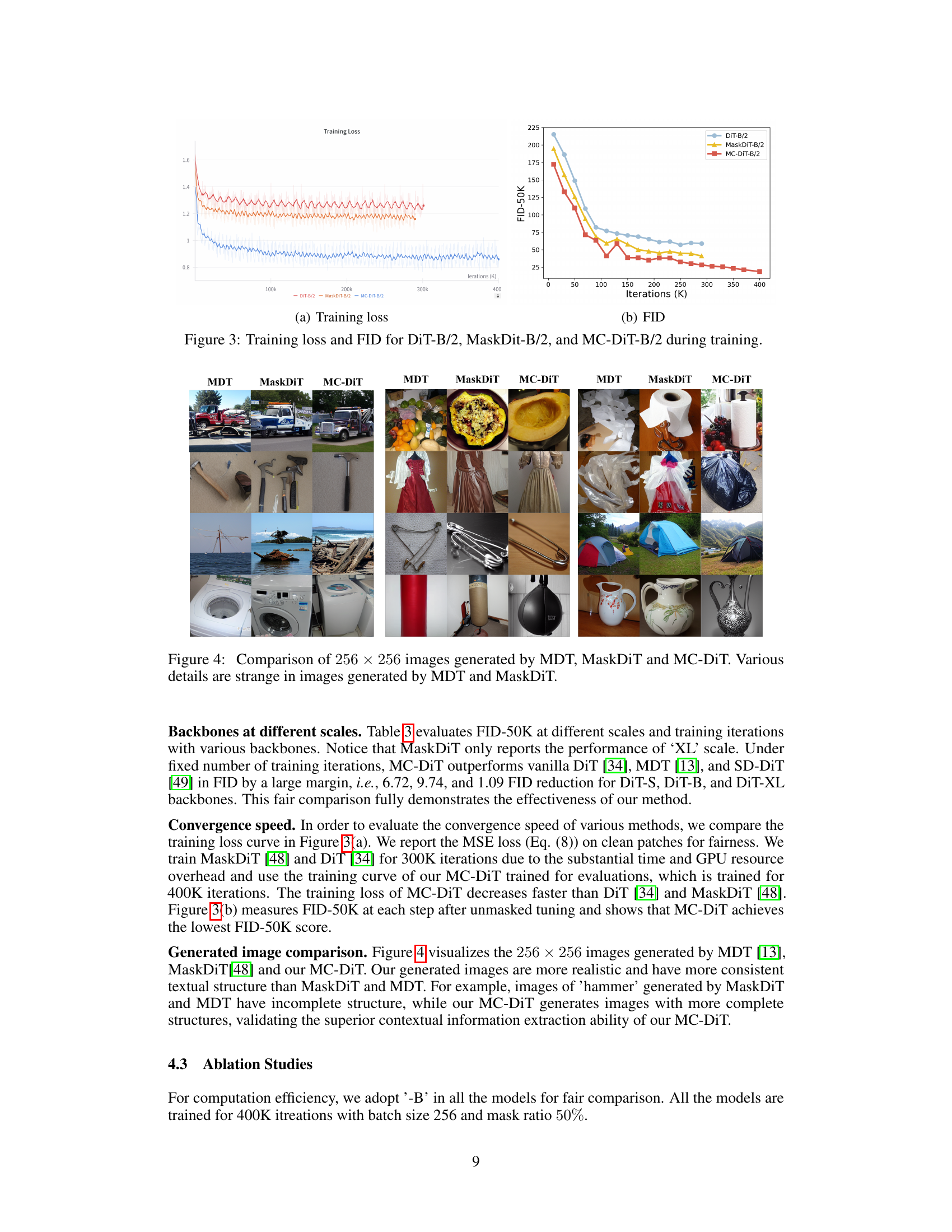
This figure shows two sub-figures: (a) Training loss and (b) FID (Fréchet Inception Distance) scores. Both sub-figures plot the training curves of three different models: DiT-B/2, MaskDiT-B/2, and MC-DiT-B/2. Sub-figure (a) illustrates the training loss over iterations, indicating that MC-DiT-B/2 converges faster than the other two. Sub-figure (b) displays the FID scores during training, which represent the quality of the generated images. Lower FID scores are better, and this sub-figure demonstrates that MC-DiT-B/2 achieves significantly lower FID scores, indicating better image quality, after around 100k iterations.

This figure is a comparison of images generated by three different methods: MDT, MaskDiT, and MC-DiT. Each column represents a different method. Each row contains four images generated using the same method. The images show that the MC-DiT method generates more realistic and coherent images compared to MDT and MaskDiT. The images generated by MDT and MaskDiT often have strange or unnatural details.
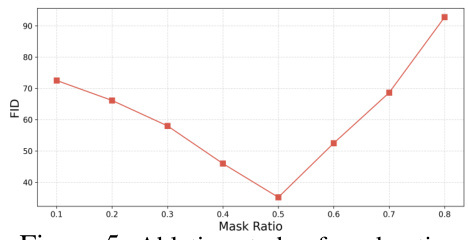
The figure shows the impact of varying mask ratios on the FID score. A mask ratio of 0.5 shows the lowest FID score, indicating an optimal balance between masked and unmasked patches for training the model. Increasing or decreasing the mask ratio from this optimum leads to a higher FID score and therefore poorer image generation quality.

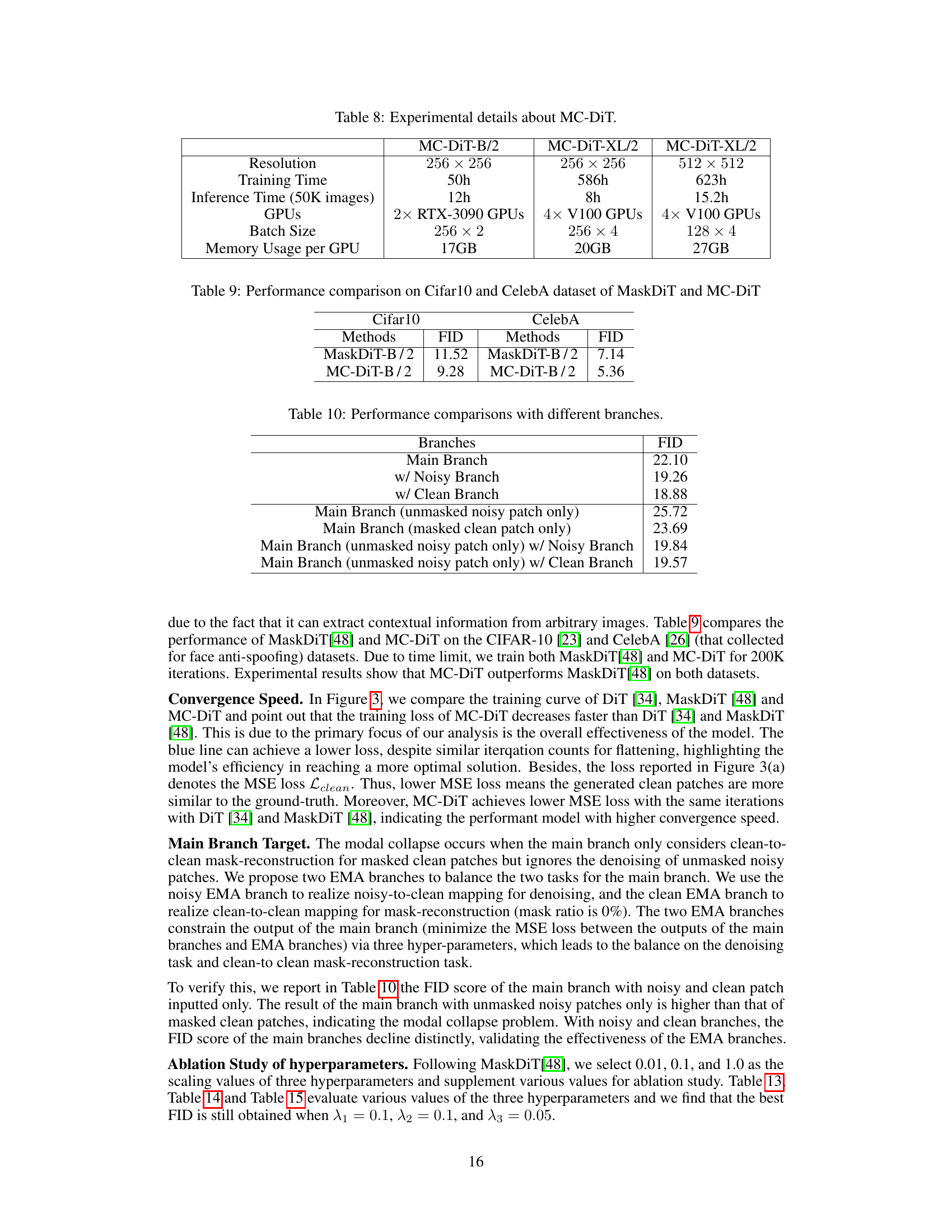
This figure visualizes the attention maps of MaskDiT and MC-DiT at different noise variances. The left side shows MC-DiT, and the right side shows MaskDiT. Three noise levels are shown (variance of 0.9, 0.5, and 0.1). A lower noise variance means that less noise has been added. The bottom row displays the original clean image patches that the noisy patches are trying to reconstruct. The purpose is to demonstrate the difference in feature extraction between the two methods at varying noise levels, showing that MC-DiT is better at extracting relevant features even in the presence of high noise.

This figure visualizes the attention maps of MaskDiT and MC-DiT at different noise variance levels using the CIFAR-10 dataset. The visualization shows that as noise variance increases (moving from right to left), MaskDiT’s attention maps become increasingly noisy and less focused, while MC-DiT maintains a more coherent and focused attention even at higher noise levels. This demonstrates MC-DiT’s improved ability to extract contextual information from noisy images compared to MaskDiT.

This figure showcases a 4x4 grid of 16 images generated by the MC-DiT model at a resolution of 512x512 pixels. Each image depicts a different object, showcasing the model’s ability to generate diverse and detailed images of various subjects, including animals, objects, and insects.
More on tables
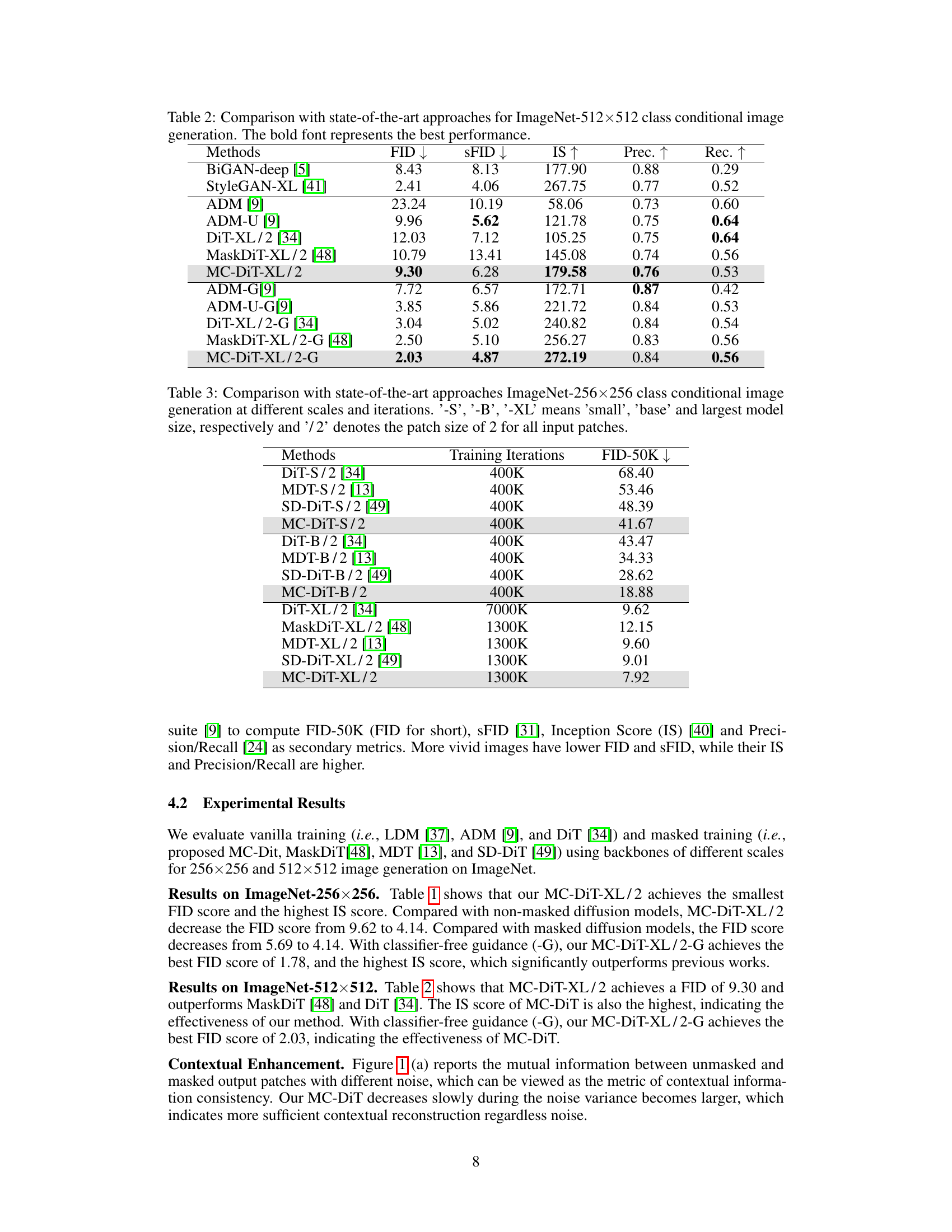
This table compares the performance of the proposed MC-DiT model with other state-of-the-art approaches on the ImageNet dataset with 512x512 resolution for class conditional image generation. The metrics used for comparison include FID (Fréchet Inception Distance), SFID (modified FID), IS (Inception Score), Precision, and Recall. Lower FID and SFID scores indicate better image quality, while higher IS scores, Precision, and Recall values are preferred. The table showcases the performance with and without classifier-free guidance (-G).
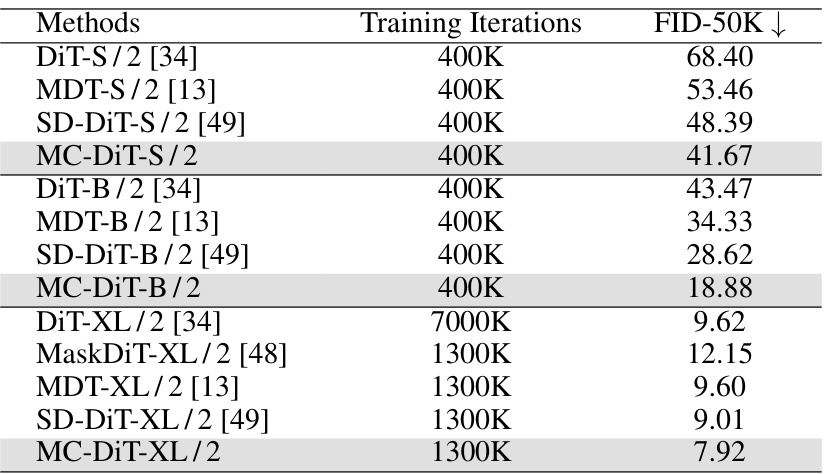
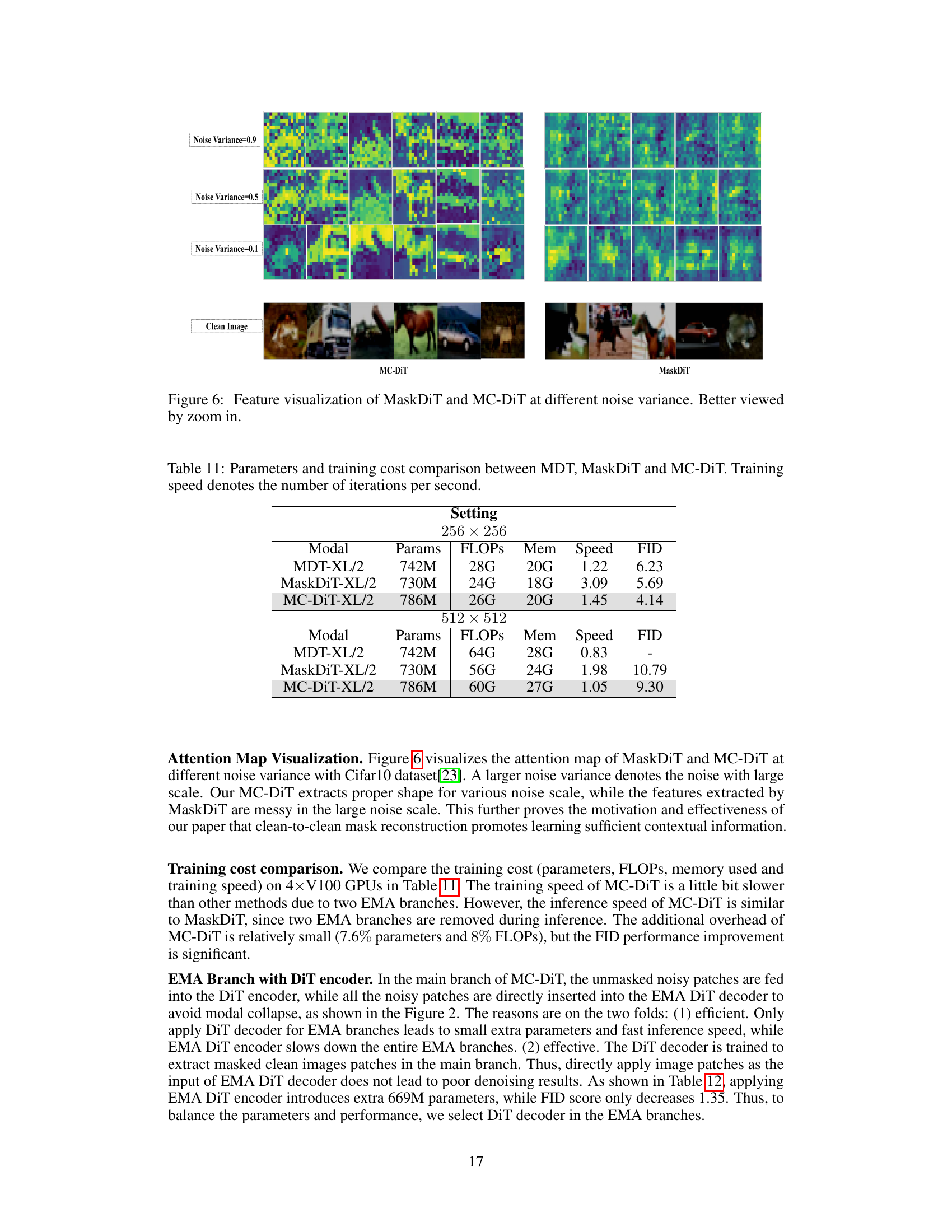
This table compares the performance of various diffusion models (DiT, MDT, SD-DiT, and MC-DiT) across different scales (small, base, and extra-large) and training iterations on the ImageNet dataset for 256x256 image generation. The FID-50K (Fréchet Inception Distance) score is used to evaluate the image quality, with lower scores indicating better performance. The results demonstrate the impact of model size, training time, and the proposed MC-DiT method on FID-50K.
This table compares the proposed MC-DiT model’s performance against other state-of-the-art models on the ImageNet dataset for 256x256 image generation. Metrics include FID (Fréchet Inception Distance), SFID (Structural FID), IS (Inception Score), Precision, and Recall. The results are shown for both conditional image generation and conditional image generation with classifier-free guidance (-G). Lower FID and SFID values and higher IS, Precision, and Recall values indicate better performance.

This table compares the FID-50K scores achieved when using different reconstruction targets in the MC-DiT model. The targets compared are: using all clean patches, using only clean patches, and using both clean and noisy patches. The results show that using both clean and noisy patches yields the best performance, as measured by the lowest FID-50K score, indicating the importance of incorporating noisy patches for effective reconstruction in the proposed MC-DiT model.
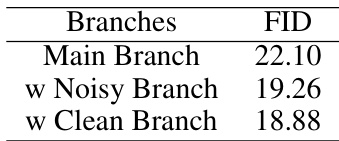
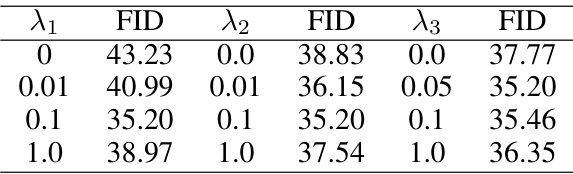
This table presents the results of an ablation study evaluating the impact of including two additional EMA (Exponential Moving Average) branches in the MC-DiT model. These branches, a noisy branch and a clean branch, are designed to help mitigate model collapse by balancing the focus on mask reconstruction and denoising. The table shows the FID (Fréchet Inception Distance) scores achieved with different combinations of these branches, demonstrating the effectiveness of each branch in improving performance. The lower FID score indicates better performance.

This table compares the performance of the proposed MC-DiT model with other state-of-the-art models on the ImageNet-256x256 dataset for class conditional image generation. The metrics used for comparison are FID (Fréchet Inception Distance), SFID (a variant of FID), IS (Inception Score), Precision, and Recall. Lower FID and SFID scores indicate better performance, while higher IS, Precision, and Recall scores are desirable. The results are shown for both standard training and classifier-free guidance (-G) training methods.

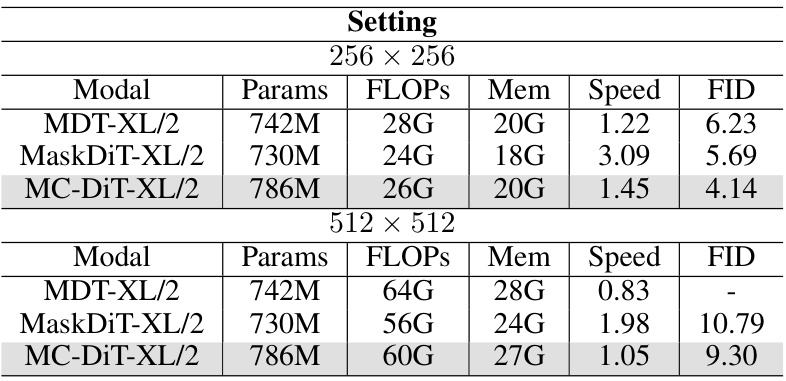
This table details the experimental setup used for training and inference of the MC-DiT model with different backbone sizes (B/2 and XL/2) and image resolutions (256x256 and 512x512). It specifies the training time, inference time for 50k images, the number of GPUs used, batch size, and memory usage per GPU. This provides context for understanding the computational requirements and resources needed to replicate the experiments reported in the paper.
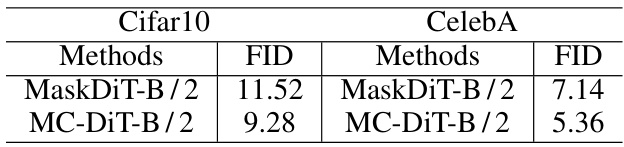
This table compares the performance of MaskDiT and MC-DiT on two datasets: CIFAR-10 and CelebA. The Fréchet Inception Distance (FID) score, a metric evaluating the quality of generated images, is reported for both models on each dataset. Lower FID scores indicate better image generation quality. The table allows for comparison of the methods’ performance across different datasets.

This table presents the Fréchet Inception Distance (FID) scores achieved by different configurations of the MC-DiT model. Specifically, it compares the performance of the main branch alone against versions that include additional noisy and clean branches. It also shows FID scores for the main branch trained only on unmasked noisy patches or masked clean patches, with and without the added branches. The results illustrate the impact of the additional branches on model performance and the avoidance of model collapse.
This table compares the performance of MC-DiT with other state-of-the-art models on the ImageNet-256x256 dataset for class-conditional image generation. The metrics used are FID (Fréchet Inception Distance), SFID (Studied FID), IS (Inception Score), Precision, and Recall. Lower FID and SFID values indicate better image quality, while higher IS, Precision, and Recall values are desirable. The ‘-G’ suffix indicates that classifier-free guidance was used during generation.

This table compares the performance (FID) and the number of parameters of two different configurations for the EMA branches in the MC-DiT model. One configuration uses only the DiT decoder, while the other configuration uses both the DiT decoder and the DiT encoder. The results show that adding the DiT encoder increases the number of parameters significantly but only slightly improves performance.
Full paper#