↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Diffusion models excel in image generation but suffer from memorizing training data, raising privacy and copyright concerns. Existing solutions, such as input alteration or data removal, are not foolproof, especially with publicly released models. This paper introduces NEMO, a novel method addressing these issues.
NEMO pinpoints memorizing neurons by analyzing activation patterns, allowing for targeted deactivation. This approach effectively prevents verbatim output of training data, increases generated image diversity, and enhances privacy without significant performance reduction. The findings challenge previous assumptions about memorization’s distribution within these models and suggest a new, neuron-level strategy for responsible AI development.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with diffusion models due to its novel approach to mitigating memorization, a significant concern in AI. The method, NEMO, offers a practical solution by identifying and deactivating neurons responsible for memorizing training data, which improves both privacy and model diversity. Its findings inspire new research into responsible AI and privacy-preserving techniques in image generation.
Visual Insights#
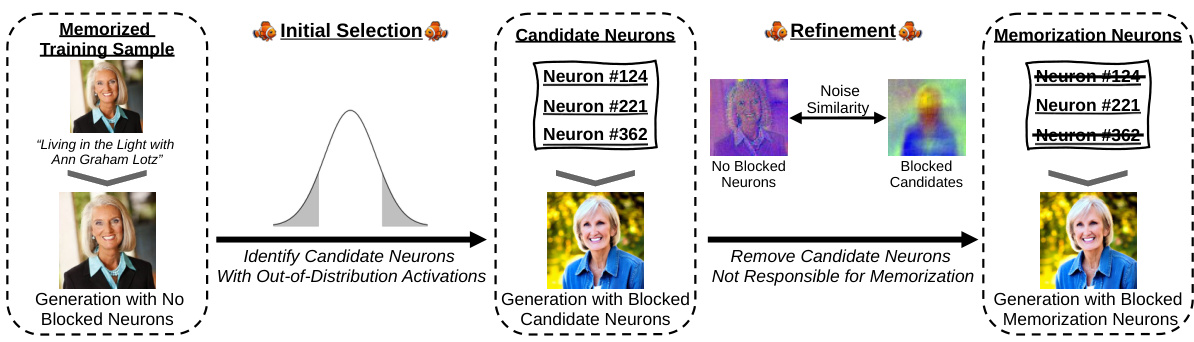
The figure illustrates the workflow of the NEMO method. It starts by identifying candidate neurons potentially responsible for memorizing a training image based on their out-of-distribution activations. A refinement step filters these candidates by using noise similarities in the first denoising step to pinpoint the actual memorization neurons. Finally, deactivating these neurons prevents the replication of the training image and promotes more diverse image generation.
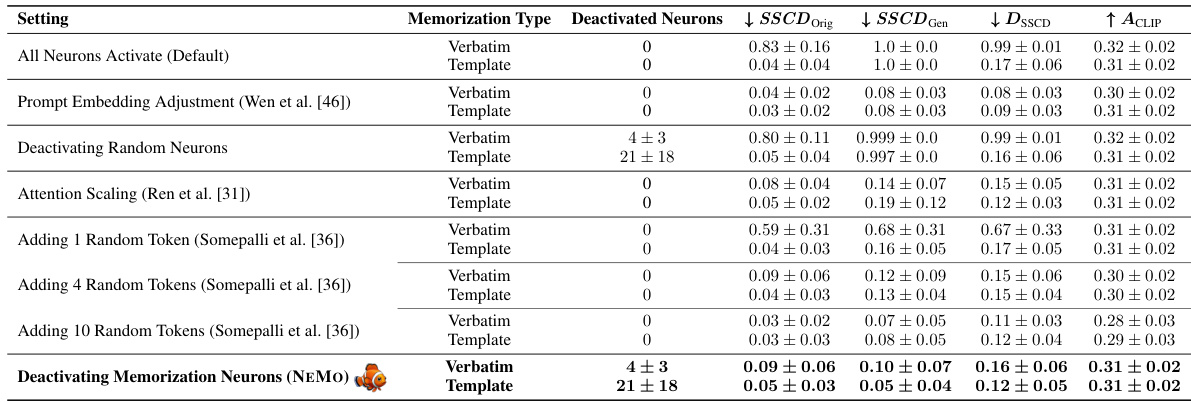
This table compares the memorization, diversity, and quality metrics of different methods for mitigating memorization in diffusion models. The methods compared include: Deactivating all neurons, Deactivating random neurons, Prompt embedding adjustment, Attention scaling, Adding random tokens (1, 4, or 10), and Deactivating memorization neurons using the proposed method NEMO. The table shows that NEMO effectively mitigates memorization while maintaining the quality and prompt alignment of generated images, outperforming other methods.
In-depth insights#
Neuron Memorization#
The phenomenon of neuron memorization in deep learning models, particularly diffusion models, is a critical area of research. Individual neurons, rather than entire layers, appear responsible for memorizing specific training samples. This surprising finding has significant implications for model transparency and security. It suggests that mitigation strategies focused on deactivating these individual neurons could effectively prevent verbatim or template memorization of sensitive data during inference. This neuron-level approach offers a more precise and targeted approach to preserving privacy and intellectual property, as opposed to broader methods that alter inputs or remove data entirely. Further research into the specific mechanisms by which neurons memorize data and the distribution of memorization across neurons within different model layers is warranted. Understanding this process is crucial for developing more responsible and secure deep learning systems.
NEMO’s Localization#
NEMO’s localization method is a significant contribution to responsible diffusion model deployment. The core of the approach lies in its ability to pinpoint memorization of individual training samples down to the level of individual neurons within the model’s cross-attention layers. This granular level of analysis is groundbreaking, revealing that single neurons can be responsible for memorizing entire training images, a surprising finding given the complexity of image data. This precision allows for targeted mitigation strategies that deactivate only the responsible neurons, avoiding broad interventions that might negatively impact the model’s performance. By identifying and deactivating the minimal set of “memorization neurons,” NEMO effectively prevents verbatim reproduction of training data while maintaining the model’s overall image generation capabilities and increasing output diversity. The method’s efficiency is further highlighted by the fact that it does not require model retraining or alterations to the inference process, making it a practical and deployable solution to the memorization problem. The detailed empirical evaluation, particularly concerning the unexpected granularity of memorization, strengthens the impact of this work.
Memorization Mitigated#
The concept of “Memorization Mitigated” in the context of diffusion models centers on addressing the privacy risks associated with these models’ ability to memorize and reproduce training data. Mitigating memorization is crucial because diffusion models often train on vast, publicly available datasets that may contain copyrighted or sensitive information. Strategies to mitigate memorization could include altering the input data to the diffusion process, removing memorized data points from the training set, or modifying the model architecture. The effectiveness of each approach depends on various factors, including the scale and nature of the data, the model’s architecture, and the method of memorization detection. A particularly promising approach involves identifying and deactivating individual neurons within the model’s architecture that are directly responsible for memorization. This targeted approach offers a more precise and effective way to prevent memorization than broader techniques that impact the model’s overall function. Furthermore, understanding the distribution of memorizing neurons within the model, whether concentrated in specific layers or dispersed throughout, is critical for developing efficient and effective mitigation strategies. Future research should focus on creating more robust and generalizable methods for detecting memorization, and developing techniques to effectively eliminate memorizing neurons without negatively impacting model performance.
Method Limitations#
The method’s effectiveness is highly dependent on the type of memorization. While it excels at pinpointing neurons responsible for verbatim memorization (exact replication of training images), its performance diminishes when dealing with template memorization (reproduction of image compositions). The computational cost can also be significant, especially when dealing with highly memorized prompts, requiring more extensive processing. Furthermore, the method’s reliance on a threshold for identifying memorized prompts introduces a degree of subjectivity and potential for misclassification. Finally, the method’s current scope is limited to Stable Diffusion, and its generalizability to other diffusion models remains to be proven. Future work should focus on refining the approach to tackle template memorization more effectively, optimizing computation for efficiency, and exploring its applicability across diverse diffusion models.
Future Research#
Future research directions stemming from this work on neuron memorization in diffusion models are abundant. Improving the efficiency and scalability of NEMO is crucial for wider applicability. Expanding NEMO to other generative models, such as large language models, would significantly broaden its impact and allow for a deeper understanding of memorization across different architectures. Investigating the relationship between memorization and generalization is key, particularly in exploring whether selective neuron deactivation impacts model performance on unseen data. Developing techniques for disentangling memorized concepts would permit targeted removal or modification of specific unwanted elements, leading to more ethical and responsible model deployment. Finally, research into the interplay between different memorization types (verbatim vs. template) promises richer insights and more effective mitigation strategies.
More visual insights#
More on figures

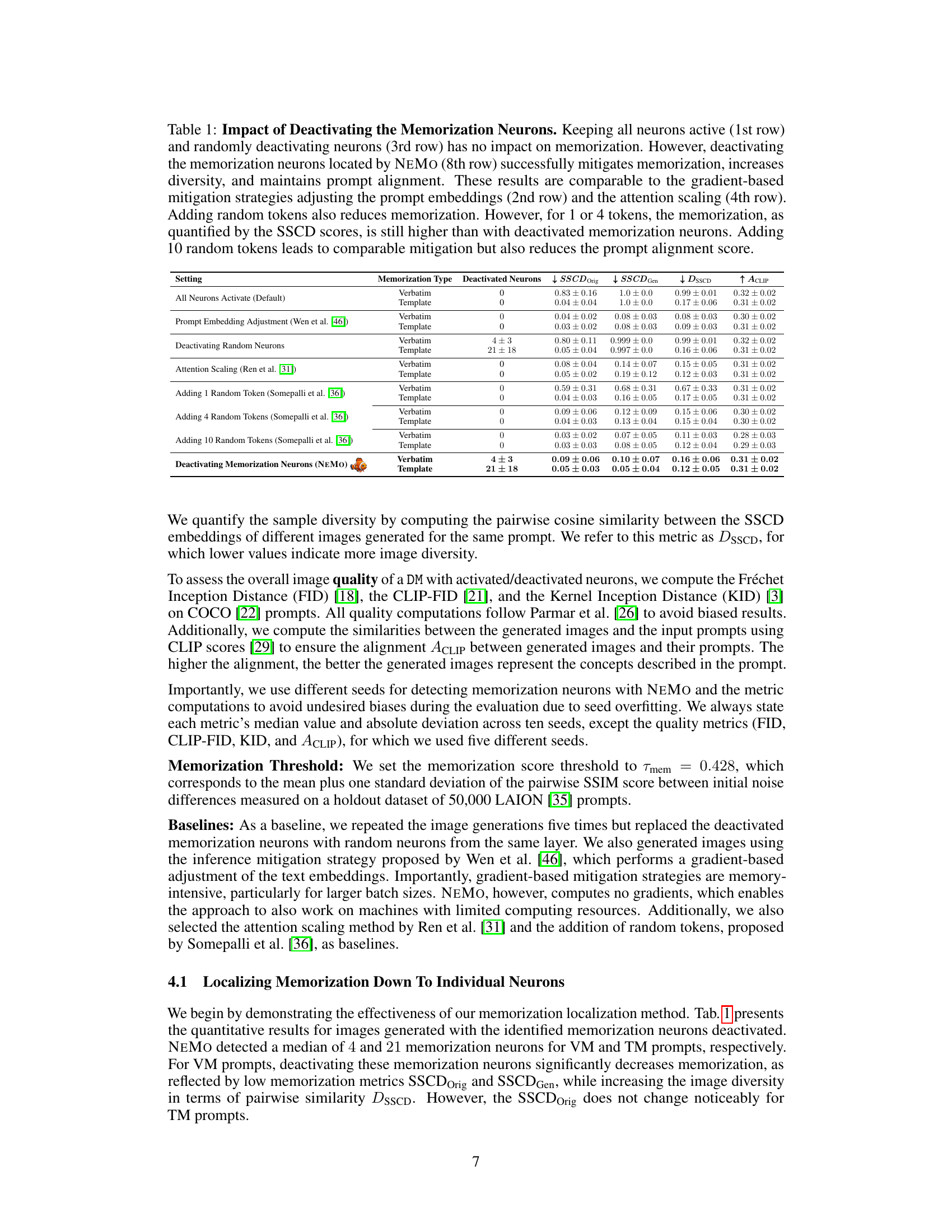
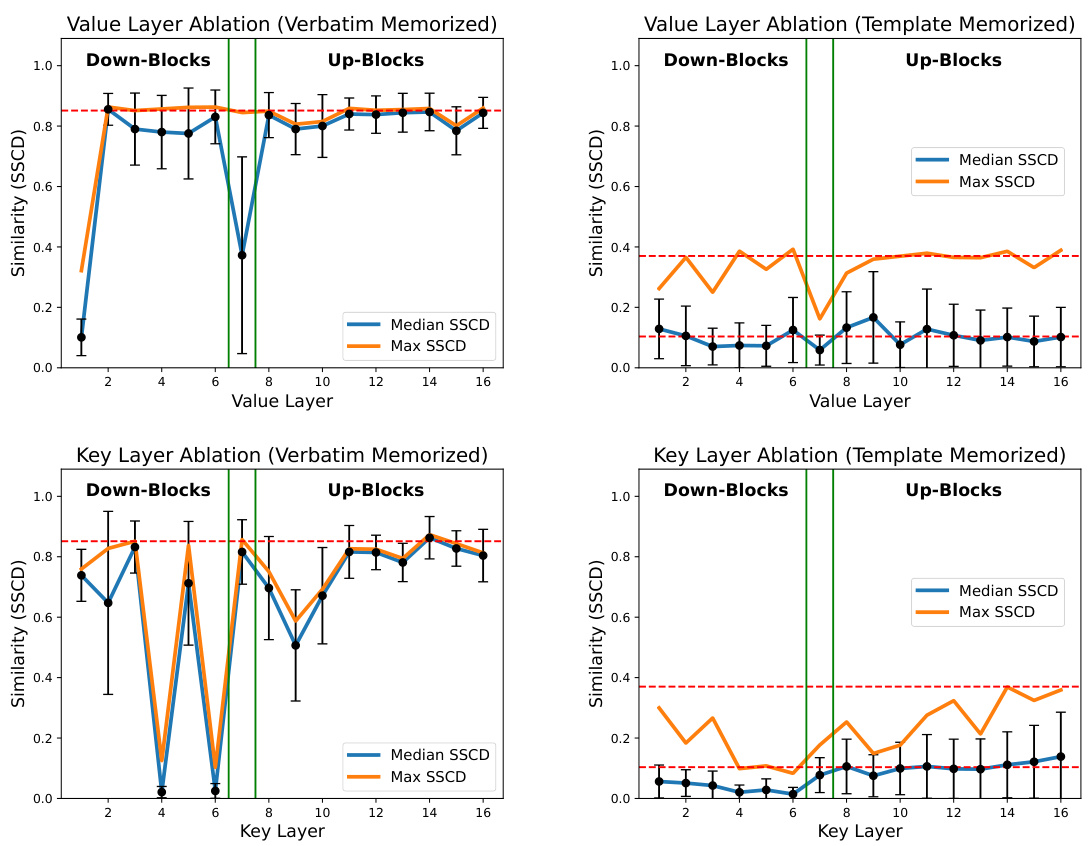
This figure shows two key differences between memorized and non-memorized prompts in diffusion models. Panel (a) uses the Structural Similarity Index (SSIM) to measure the similarity of noise trajectories from different random seeds for the same prompt. Higher SSIM scores indicate that the same noise trajectory is consistently produced, signifying memorization of the prompt. Panel (b) displays the distribution of z-scores (standardized activations) for neurons in the first cross-attention value layer. Memorized prompts show significantly higher activations in specific neurons compared to non-memorized prompts, allowing these ‘memorization neurons’ to be identified.

This figure shows the effect of deactivating neurons identified by NEMO (Finding NEuron MEMORization) on the generation of images from memorized prompts. The top row displays images generated using standard Stable Diffusion, where the model accurately replicates training images due to memorization. The bottom row shows the results after deactivating the identified memorization neurons. The deactivation leads to more diverse generated images that are no longer verbatim copies of the training data, thus mitigating the memorization effect. The numbers in the boxes indicate the number of neurons deactivated for each image.
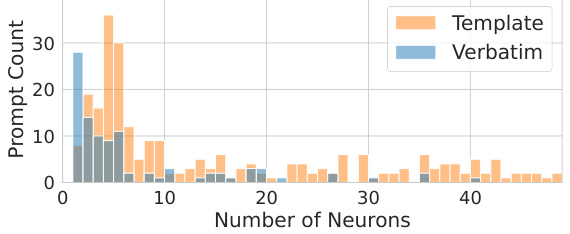
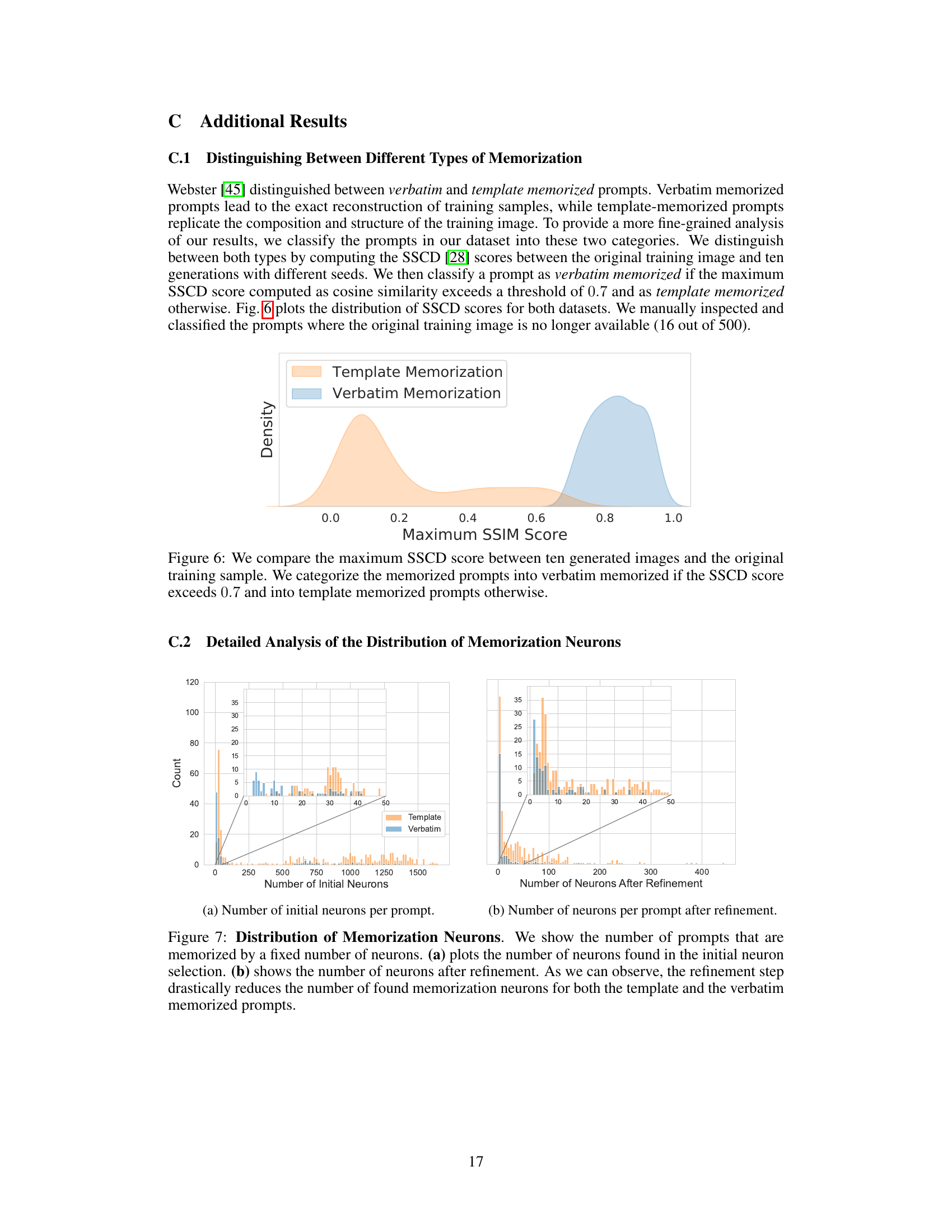
This figure shows the distribution of the number of neurons responsible for memorizing prompts in the diffusion model. Panel (a) is a histogram showing how many prompts are memorized by a given number of neurons. It highlights that a significant number of prompts (especially verbatim memorization) are memorized by only a few neurons, with many memorized by a single neuron. Panel (b) shows the average number of neurons responsible for memorization per layer in the model for both types of memorization (verbatim and template).

This figure shows the distribution of memorization neurons in the diffusion model. Panel (a) is a histogram showing how many prompts are memorized by a certain number of neurons. It highlights that many prompts are memorized by only one or a few neurons. Panel (b) shows the average number of neurons responsible for memorizing a prompt, broken down by layer of the network.

This figure shows that the image quality does not degrade significantly when deactivating neurons identified by NEMO. Part (a) displays FID and KID scores for different numbers of blocked neurons, showing minimal change. Part (b) demonstrates that scaling neuron activations has a limited impact on memorization; only negative scaling provides no additional benefit over complete deactivation.
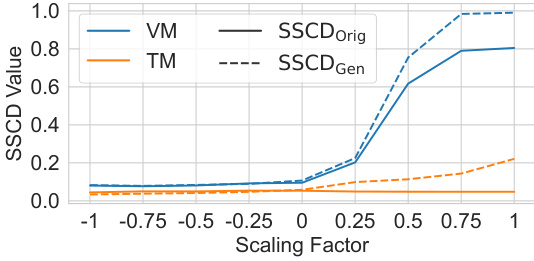
This figure shows the effect of (a) deactivating different numbers of neurons and (b) scaling the activation of memorization neurons. The left plot shows that image quality metrics FID and KID do not significantly change when blocking increasing numbers of neurons found by NEMO, indicating that the identified neurons do not harm the overall generation quality. The right plot shows the sensitivity analysis of scaling these neurons. Scaling above 0 has a limited impact on reducing memorization, and negative scaling does not offer further improvements.

This figure shows the distribution of maximum Structural Similarity Index Measure (SSIM) scores between generated images and their corresponding training images for both template and verbatim memorization. The x-axis represents the maximum SSIM score (ranging from 0 to 1, where 1 indicates perfect similarity), while the y-axis represents the density. The distribution for verbatim memorization is concentrated around higher SSIM scores (closer to 1), indicating higher similarity and thus stronger memorization. The distribution for template memorization is more spread out and concentrated around lower SSIM scores, suggesting less direct similarity to the original training images. This visualization helps to distinguish between the two types of memorization based on the similarity of generated outputs to training samples.

This figure shows the distribution of memorization neurons in the diffusion model. Part (a) is a histogram showing the number of prompts memorized by a given number of neurons. It highlights that a significant portion of prompts are memorized by only a small number of neurons, some even only by a single neuron. Part (b) presents the average number of memorization neurons per layer across all prompts, illustrating the distribution of memorization neurons across the different layers of the model.
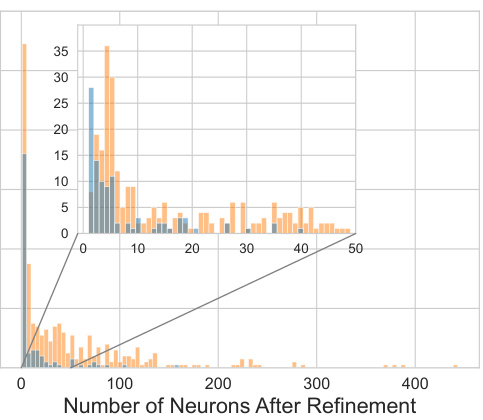
This figure shows the distribution of the number of neurons responsible for memorizing prompts in the diffusion model. The left histogram (a) displays the count of prompts memorized by a specific number of neurons, demonstrating that many prompts are memorized by just one or a few neurons. The right histogram (b) illustrates the average number of memorization neurons per layer across all prompts. This helps to understand the relative memorization load per layer in the network architecture.
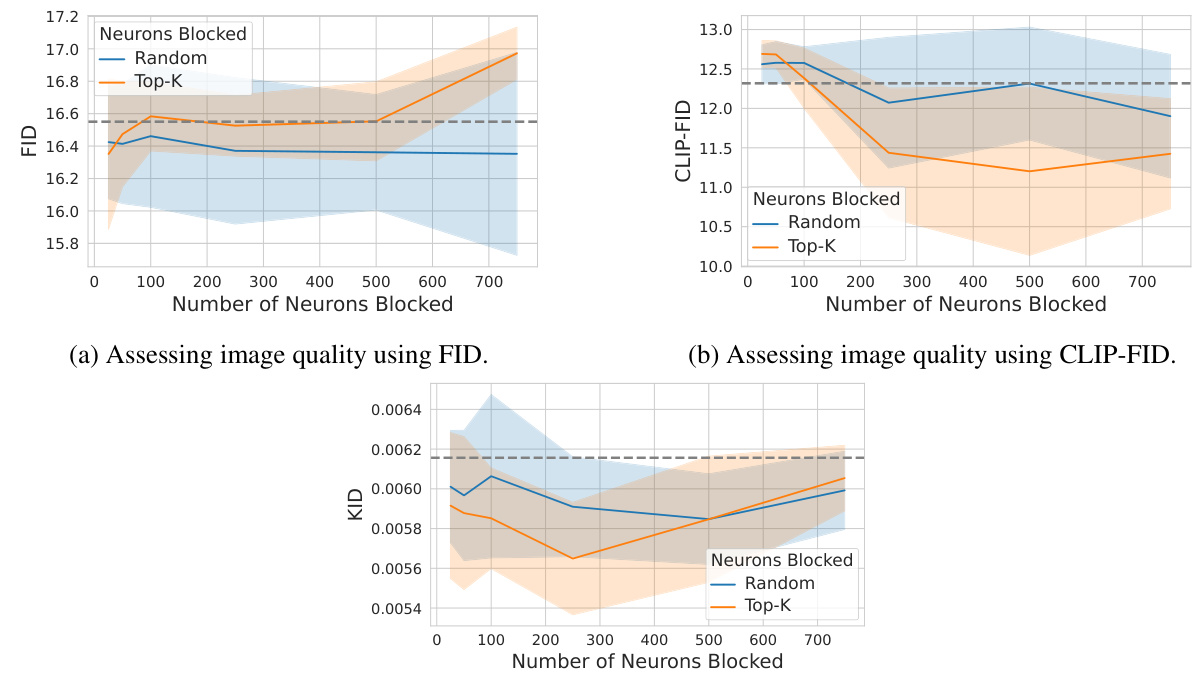
This figure demonstrates that image quality metrics (FID, CLIP-FID, KID) remain largely unchanged even when a significant number of memorization neurons are deactivated. The results suggest that NEMO’s approach effectively mitigates memorization without negatively impacting image quality.

This figure demonstrates the effectiveness of NEMO in mitigating memorization in diffusion models. The top row displays images generated from memorized prompts; these images are nearly identical to the original training images. The bottom row shows the results after deactivating the neurons identified by NEMO as responsible for memorization. The images in the bottom row exhibit greater diversity and a reduced tendency to reproduce training images verbatim. The numbers within the boxes indicate the number of neurons deactivated in each case to achieve this effect, highlighting that only a small number of neurons are often responsible for memorizing a particular training image.

This figure shows the effect of deactivating neurons identified by NEMO as responsible for memorization. The top row displays images generated from memorized prompts, which are almost identical to the original training images. The bottom row shows that by deactivating these specific neurons, the generated images are now diverse and significantly different from the original training images, demonstrating NEMO’s ability to mitigate memorization by selectively disabling specific neurons. The numbers in the boxes indicate how many neurons were deactivated for each prompt.

This figure shows the effect of deactivating memorization neurons identified by NEMO. The top row displays images generated from memorized prompts, which closely resemble the original training images. The bottom row shows the results after deactivating the identified neurons, highlighting increased diversity and reduced memorization. The numbers in the boxes indicate the number of neurons deactivated for each image.

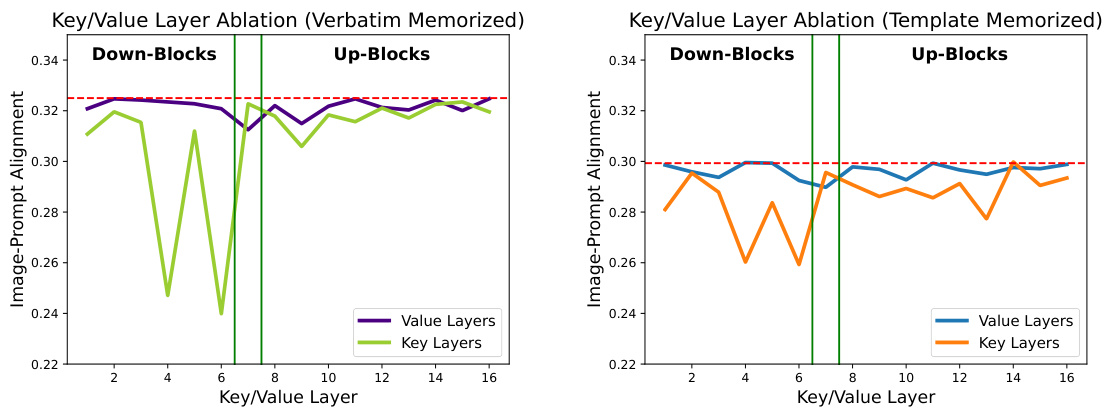
The figure shows the impact of deactivating neurons #507 and #517 in the third cross-attention layer’s value mapping on image generation for prompts related to iPhone cases. Deactivating these neurons reduces the memorization of specific training images and increases the diversity of generated images compared to using all neurons. The experiment was conducted with a fixed seed.

This figure shows the effect of deactivating neurons identified by NEMO (Finding Neuron Memorization) as being responsible for memorizing specific training samples. The top row displays images generated from memorized prompts, where the model closely replicates the training images. The bottom row shows the results after deactivating the identified memorization neurons. Deactivating these neurons leads to increased diversity in the generated images and successfully mitigates memorization. The number of neurons deactivated for each example is shown within the boxes.
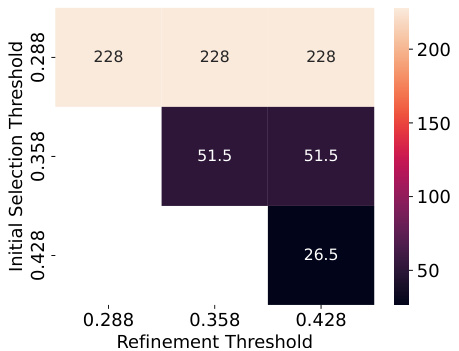
This figure shows heatmaps representing the number of neurons identified by NEMO for different initial and refinement thresholds. The left heatmaps show results for verbatim memorization, and the right for template memorization. Darker colors indicate fewer neurons. The results show that the refinement step significantly reduces the number of neurons selected, with the combination of 0.428 for both initial and refinement thresholds yielding the fewest.
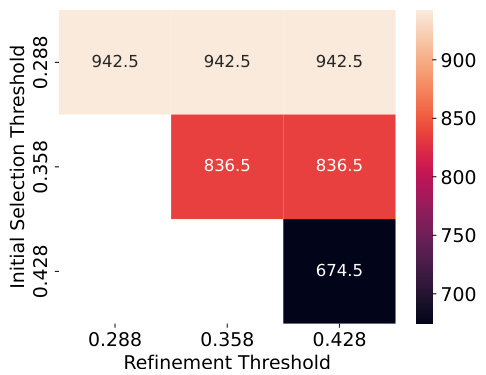
This figure shows the number of neurons detected by NEMO for different combinations of initial and refinement thresholds. The top-left plot shows the number of initial neurons detected for verbatim memorization prompts, with a heatmap showing the relationship between initial and refinement thresholds. The top-right plot mirrors this for template memorization prompts. The bottom-left plot does the same but for the number of refined neurons for verbatim memorization prompts and the bottom-right plot displays the results for template memorization prompts. The key takeaway is that the refinement step significantly reduces the number of neurons, and using a threshold of 0.428 for both initial selection and refinement yields the fewest neurons.
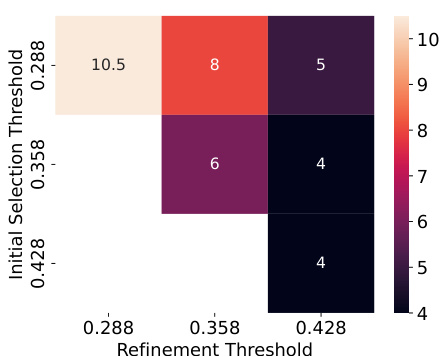
This figure shows the impact of different initial and refinement thresholds (\text{(\theta_{\text{mem}})}) on the number of neurons identified by NEMO for both verbatim and template memorization prompts. The heatmaps illustrate that varying these thresholds significantly alters the number of neurons initially selected and the number remaining after refinement. Lower thresholds result in more neurons, but the refinement step effectively reduces this number regardless of the initial threshold chosen. The optimal balance, resulting in the fewest neurons, is achieved by using a threshold of 0.428 for both the initial selection and refinement processes.

This figure shows heatmaps illustrating the number of neurons identified as responsible for memorization under different initial and refinement threshold settings for both verbatim and template memorization. The initial selection threshold determines the initial set of candidate neurons, and the refinement threshold further filters this set. Lower thresholds generally lead to more initial candidates. Refinement significantly reduces the number of neurons in the final set, irrespective of the initial threshold. Using a threshold of 0.428 for both initial selection and refinement yields the smallest number of identified neurons.
This figure illustrates the workflow of the NEMO method. It starts by identifying candidate neurons potentially responsible for memorizing an image based on their out-of-distribution activations. Then, it refines this set by considering the noise similarities during the first denoising step to pinpoint the actual memorization neurons. Finally, it demonstrates that deactivating these neurons prevents the generation of the memorized image and promotes diversity in the generated outputs.
This figure illustrates the workflow of the NEMO method. It starts by identifying candidate neurons responsible for memorization based on unusual activation patterns. A refinement step then precisely pinpoints the memorization neurons, distinguishing them from false positives. By deactivating these neurons, NEMO prevents the reproduction of training images, thereby enhancing privacy and the diversity of the generated output.
The figure illustrates the workflow of the proposed method NEMO. NEMO first identifies candidate neurons potentially involved in memorization by analyzing their out-of-distribution activation patterns when presented with memorized prompts. A refinement step then isolates the true memorization neurons by utilizing the noise similarity during the initial denoising stage. Deactivating these neurons prevents the generation of verbatim copies of training data at inference time, reducing privacy risks and increasing the diversity of generated outputs.

This figure demonstrates the effectiveness of the NEMO method in mitigating memorization in diffusion models. The top row displays images generated from memorized prompts, showing near-identical replication of the original training images. The bottom row shows the same prompts used to generate images, but this time with the memorization neurons deactivated by NEMO. The resulting images exhibit increased diversity and reduced memorization, indicating that NEMO successfully identifies and disables neurons responsible for memorization, thus improving privacy and copyright protection.

This figure illustrates the workflow of the NEMO algorithm. First, NEMO identifies candidate neurons exhibiting unusual activation patterns when processing memorized prompts. Then it refines this set by analyzing noise similarities during the initial denoising steps. Finally, it demonstrates that deactivating these identified neurons prevents the generation of the original memorized image and promotes diversity in generated images.

This figure shows two subfigures that illustrate the differences between memorized and non-memorized prompts. Subfigure (a) shows the distribution of the Structural Similarity Index Measure (SSIM) scores between the initial noise differences for multiple different random seeds. The higher the SSIM score the more consistent (less diverse) the noise trajectories. Since memorized samples have more consistent noise trajectories, they have higher SSIM scores, indicating a higher degree of memorization. Subfigure (b) shows the z-scores (a measure of how many standard deviations from the mean a value is) of neurons in the first cross-attention value layer for both memorized and non-memorized prompts. The figure shows that memorization neurons have significantly higher z-scores for memorized prompts, making them stand out as outliers that can be easily identified and used for the detection of memorization.
More on tables

This table shows the average runtime of each algorithm used in NEMO for both Verbatim Memorization (VM) and Template Memorization (TM). It highlights that the algorithms are efficient, with most taking less than 10 seconds, even for TM which is more complex and therefore slower.

This table compares the effectiveness of different methods for mitigating memorization in diffusion models. It shows how the SSCD (Self-Supervised Descriptor), DSSCD (diversity of SSCD embeddings), and ACLIP (CLIP alignment) scores change when different methods are used. The methods include: no mitigation, adjusting prompt embeddings, attention scaling, adding random tokens, randomly deactivating neurons, and using NEMO to deactivate memorization neurons. The table demonstrates that NEMO effectively mitigates memorization, achieving comparable results to state-of-the-art techniques while having the additional benefit of permanently mitigating memorization. Randomly deactivating neurons or using fewer tokens is less effective.
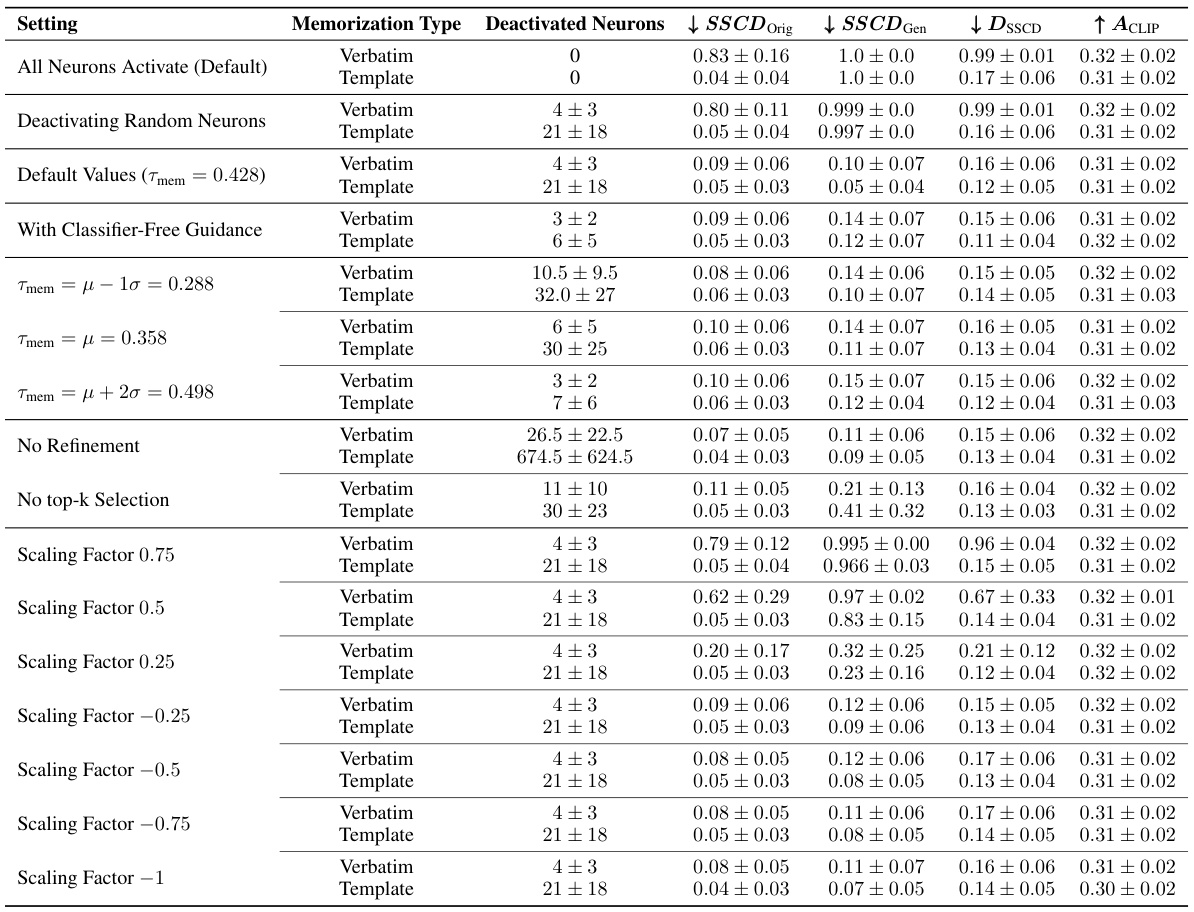
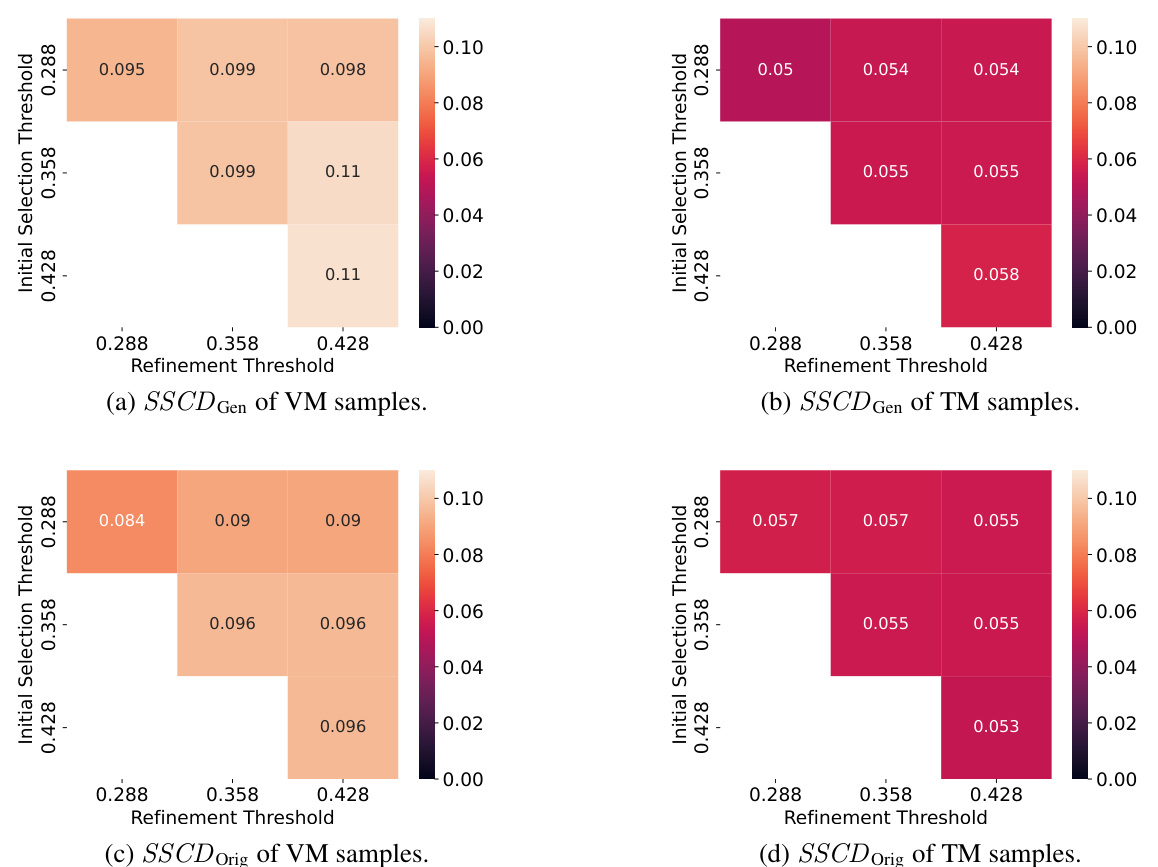
This table presents the results of an ablation study comparing different methods for mitigating memorization in diffusion models. The methods compared include baseline (all neurons active), random neuron deactivation, prompt embedding adjustment, attention scaling, adding random tokens, and the proposed NEMO method. Metrics evaluated include memorization strength (SSCD Orig, SSCD Gen), diversity (DSSCD), and prompt alignment (AClip). The table demonstrates that NEMO effectively reduces memorization without significantly impacting diversity or alignment.

This table compares different methods for mitigating memorization in diffusion models. It shows the effect of deactivating memorization neurons identified by NEMO against baselines such as randomly deactivating neurons, using gradient-based prompt adjustments, attention scaling, and adding random tokens. The metrics used are SSCD Orig, SSCD Gen, Diversity (DssCD), and CLIP alignment (AClip). Lower SSCD scores indicate less memorization, higher DssCD scores indicate more diversity, and higher AClip scores indicate better prompt alignment.

This table presents a comparison of different memorization mitigation techniques. It shows the impact on memorization, diversity, and prompt alignment when various sets of neurons are deactivated. The techniques compared include: doing nothing, using gradient-based prompt embedding adjustment, attention scaling, adding random tokens, randomly deactivating neurons and finally using the NEMO method to deactivate memorization neurons. The results highlight the effectiveness of NEMO in mitigating memorization while preserving prompt alignment and increasing image diversity.
Full paper#