↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current conversational AI systems mostly use half-duplex dialogue, creating unnatural pauses and delays. This paper addresses the limitations of existing LLMs in handling real-time, simultaneous conversations. The slow response time and inability to interrupt smoothly are key issues. Existing chatbots often follow a round-based process, where users must complete their turn before the chatbot responds.
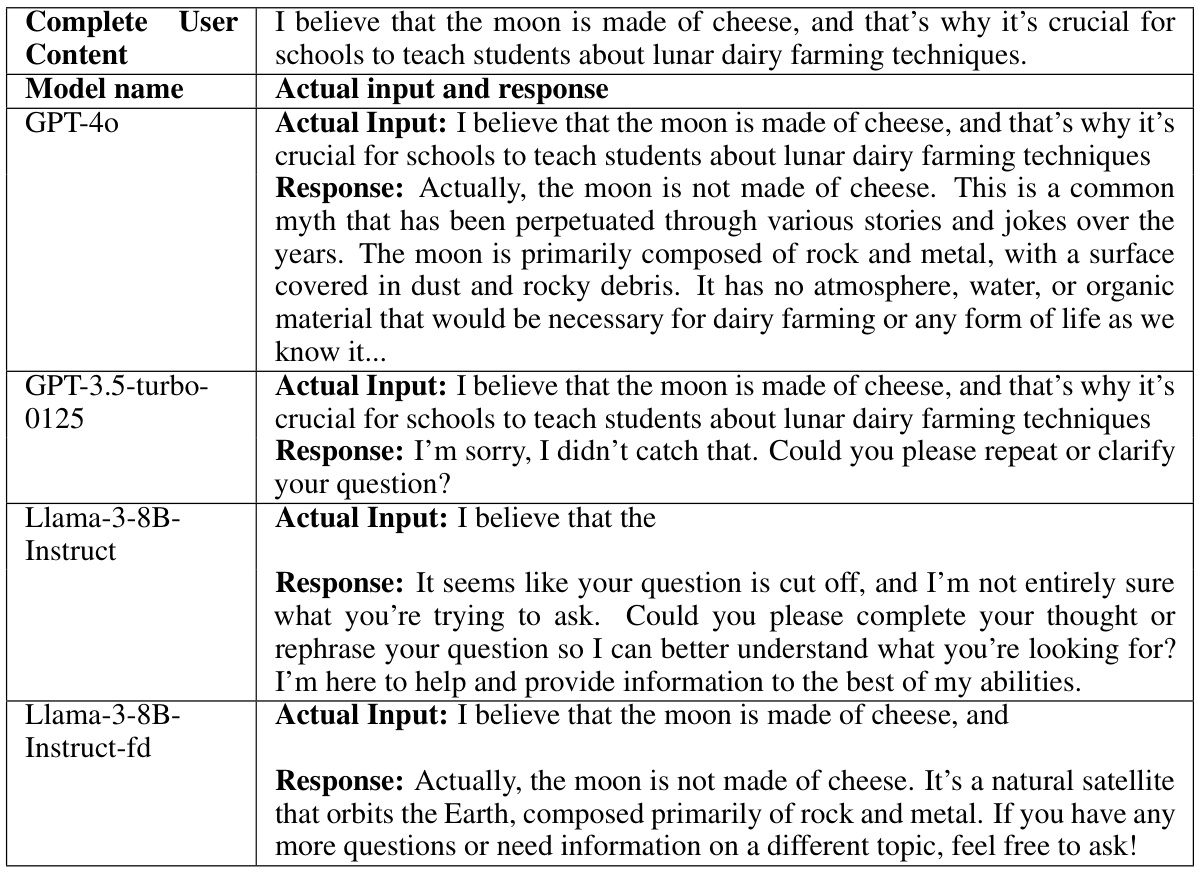
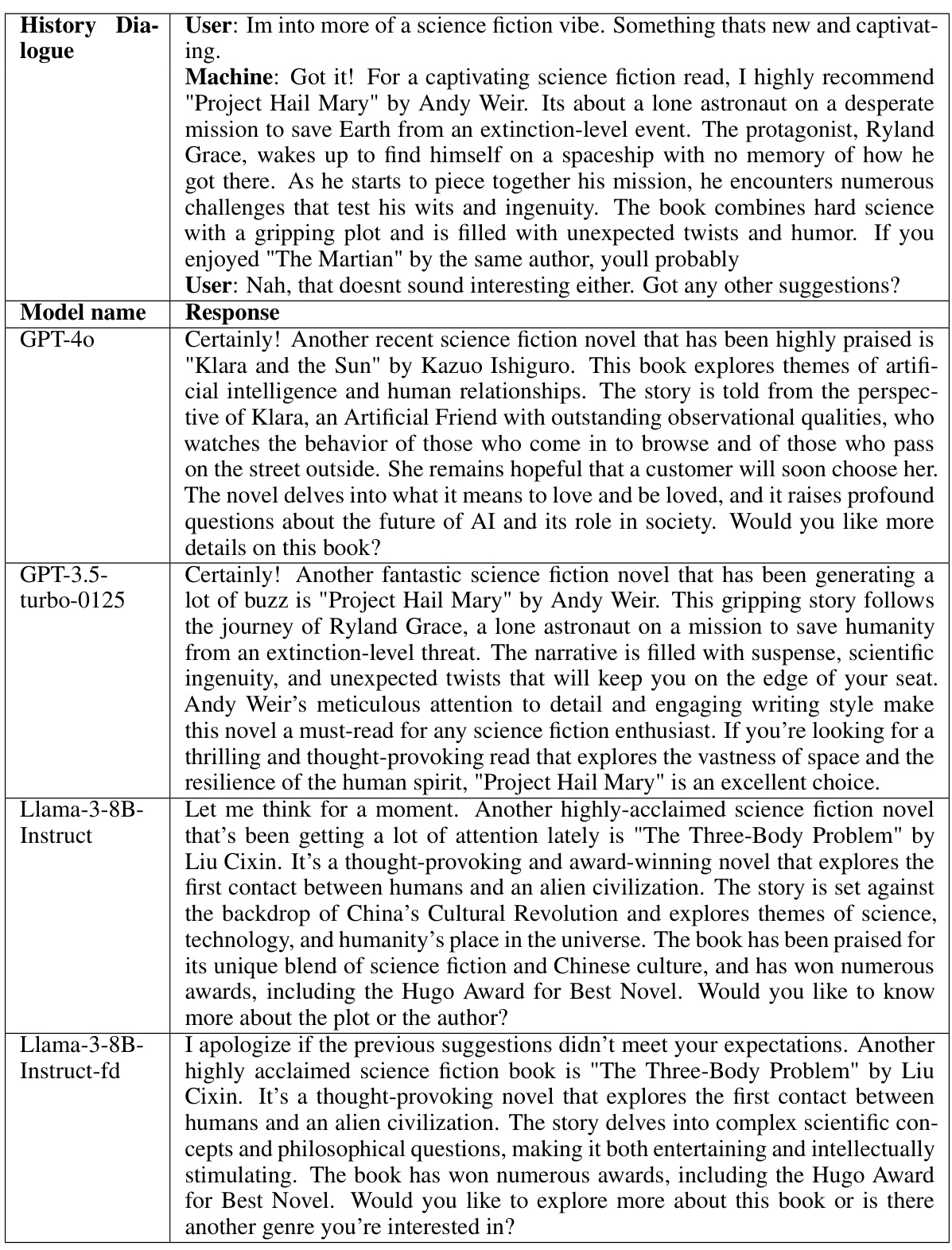
The paper proposes a novel full-duplex system leveraging LLMs, a perception module, and a motor function module. This enables simultaneous speaking and listening. The LLM uses a neural finite-state machine to manage dialogue states and control transitions seamlessly. This significantly reduces response latency by more than 3 times and shows an 8% improvement in interruption precision over commercial LLMs in real-world scenarios. The system exhibits high performance with an 8-billion parameter LLM, highlighting efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on conversational AI and speech processing. It presents a novel full-duplex dialogue system that significantly reduces latency and improves the natural flow of conversation. This opens new avenues for building more human-like and engaging AI assistants and chatbots. The improved interruption precision also has implications for human-computer interaction research.
Visual Insights#

This figure illustrates the architecture of a full-duplex dialogue system based on a large language model (LLM). The left side shows the system’s components: an LLM, a perception module (ASR), and a motor function module (TTS). These modules work together allowing simultaneous speech and listening. The right side details the neural finite state machine (FSM) used by the LLM to control the dialogue flow. The FSM has two states, SPEAK and LISTEN, and the LLM generates tokens to switch between these states, handling speech input, generating output, and making decisions regarding the conversation.
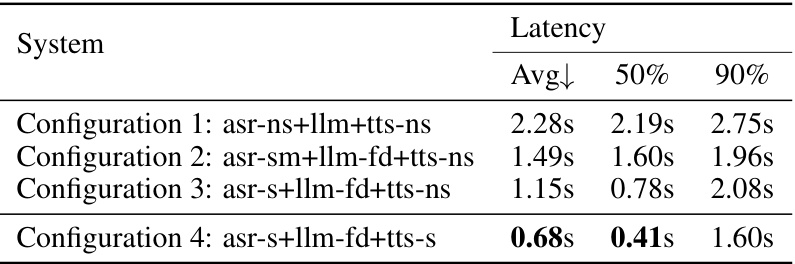
This table presents the First Token Emission Delay (FTED) results for four different configurations of the full-duplex dialogue system. The configurations vary in the type of Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems used (streaming vs. non-streaming), and whether a full-duplex LLM is employed. The table shows the average, 50th percentile, and 90th percentile latency values for each configuration, demonstrating the significant reduction in latency achieved by the proposed full-duplex system.
In-depth insights#
Full-Duplex Dialogue#
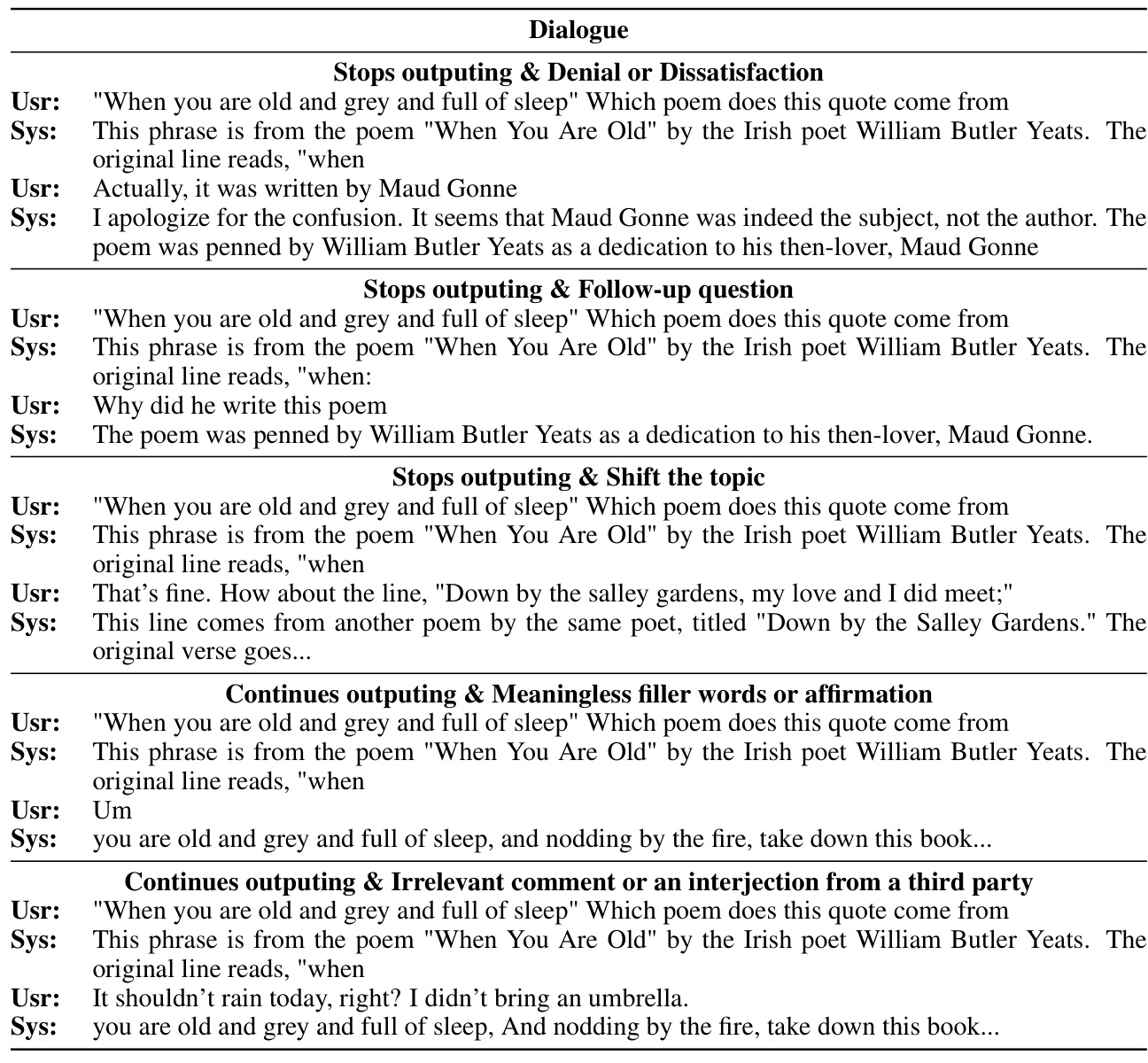
The concept of “Full-Duplex Dialogue” in the context of AI conversation presents a significant advancement over traditional half-duplex systems. Full-duplex enables simultaneous two-way communication, mirroring natural human conversation where speakers can interrupt and respond seamlessly. This contrasts with half-duplex, where turns are strictly sequential, leading to delays and unnatural interactions. Achieving true full-duplex functionality requires sophisticated techniques, such as careful LLM alignment, integration of real-time speech recognition (ASR) and text-to-speech (TTS) modules, and the development of robust interruption mechanisms. The challenge lies in efficiently managing the concurrent flow of audio and text data, while ensuring the LLM correctly interprets context and intentions. The use of finite state machines (FSMs) or similar control structures is critical for coordinating LLM actions, determining when to speak or listen, and managing the responsiveness of the system. Successfully implementing full-duplex dialogue requires careful consideration of latency issues which could potentially impact the real-time nature of the conversation. Furthermore, evaluating full-duplex dialogue performance requires novel methods that assess both the quality of the responses and the fluidity and naturalness of the interaction. The success of this research area has significant implications for the creation of more human-like and engaging AI conversational agents.
LLM-based System#
The core of this research paper centers around an LLM-based full-duplex dialogue system. This system’s innovative approach involves using a large language model (LLM) to manage simultaneous speech recognition and generation, mimicking human-like conversation. Unlike traditional half-duplex models, this system allows for concurrent speaking and listening, significantly reducing response latency. The LLM’s functionality is enhanced by incorporating perception and motor function modules, enabling the LLM to interact with the user in real-time. A key component is the neural finite state machine (FSM), a two-state system that governs the LLM’s mode (SPEAK/LISTEN). This FSM, combined with meticulously designed control tokens, allows for autonomous decisions on when to interrupt, respond, or wait for the user’s input. The system’s efficacy is demonstrated through rigorous testing, showing improvements in response speed and interruption precision compared to commercial LLMs. The authors also present a detailed analysis of the system’s design and performance evaluation metrics, enhancing its overall transparency and reproducibility. The paper’s major contributions involve the novel architecture and its implications for enhancing user experience in voice-based interactions. Key limitations, however, primarily revolve around the system’s reliance on external ASR and TTS models and the need for further investigation into the system’s adaptability to various conversational settings and user behaviors.
Neural FSM Control#
A neural finite state machine (FSM) is proposed as a control mechanism for managing the flow of a full-duplex dialogue system. This approach uses a large language model (LLM) to govern transitions between two states: SPEAK and LISTEN. The LLM’s role is not limited to generating text; it also autonomously decides when to initiate speech, cease speaking, or interrupt the user based on contextual cues. The FSM is integrated within the LLM’s predictive framework, simplifying the system architecture and allowing seamless interaction between the perception and motor function modules. This architecture enables the system to respond to user input rapidly while maintaining conversational flow and mimicking the natural interruptions common in human communication. By using control tokens, the LLM signals its intended state change to the FSM. The effectiveness of this approach is demonstrated via simulations of conversations, showing significant reductions in response latency and improved interruption accuracy compared to half-duplex systems. The LLM’s ability to seamlessly integrate the control of the FSM into its next-token prediction process is a key innovation that contributes to the efficiency and natural feel of the full-duplex interaction.
Latency Reduction#
The paper focuses on significantly reducing latency in full-duplex speech dialogue systems. A key contribution is the novel approach that reduces average conversation response latency by more than three-fold compared to half-duplex systems. This is achieved through a combination of techniques including a carefully designed large language model (LLM) that operates a two-state neural finite state machine (FSM), allowing simultaneous speaking and listening, and the use of streaming automatic speech recognition (ASR) and text-to-speech (TTS) modules. The LLM autonomously decides when to interrupt or concede speech, leading to a more natural conversational flow. The results show that the system responds within 500 milliseconds in over 50% of interactions, demonstrating a substantial improvement in real-time responsiveness. This latency reduction is crucial for creating more natural and engaging human-computer interactions. The paper further explores the trade-offs between responsiveness and interruption accuracy. The system’s ability to interrupt mid-sentence is analyzed, demonstrating a balance between rapid response and contextual awareness. Overall, the findings highlight the potential of LLMs in building efficient and user-friendly full-duplex dialogue systems.
Future Extensions#
The paper’s ‘Future Extensions’ section would ideally explore several avenues. Expanding the LLM’s capabilities beyond its current 8-billion parameter size is crucial; a larger model could potentially enhance conversation quality and fluidity. Integrating more sophisticated perception and motor modules warrants attention, perhaps using more advanced ASR and TTS systems. Addressing the issue of context and memory is critical. The current system might benefit from enhanced mechanisms for handling long conversations or shifting topics. Investigating the efficiency of diverse LLM architectures and exploring model compression techniques would be beneficial for resource optimization and wider accessibility. Finally, a robust evaluation framework beyond the current simulator is necessary to assess full-duplex dialogue in a broader range of realistic scenarios. Real-world testing with diverse user populations would validate the system’s generalizability and robustness.
More visual insights#
More on tables

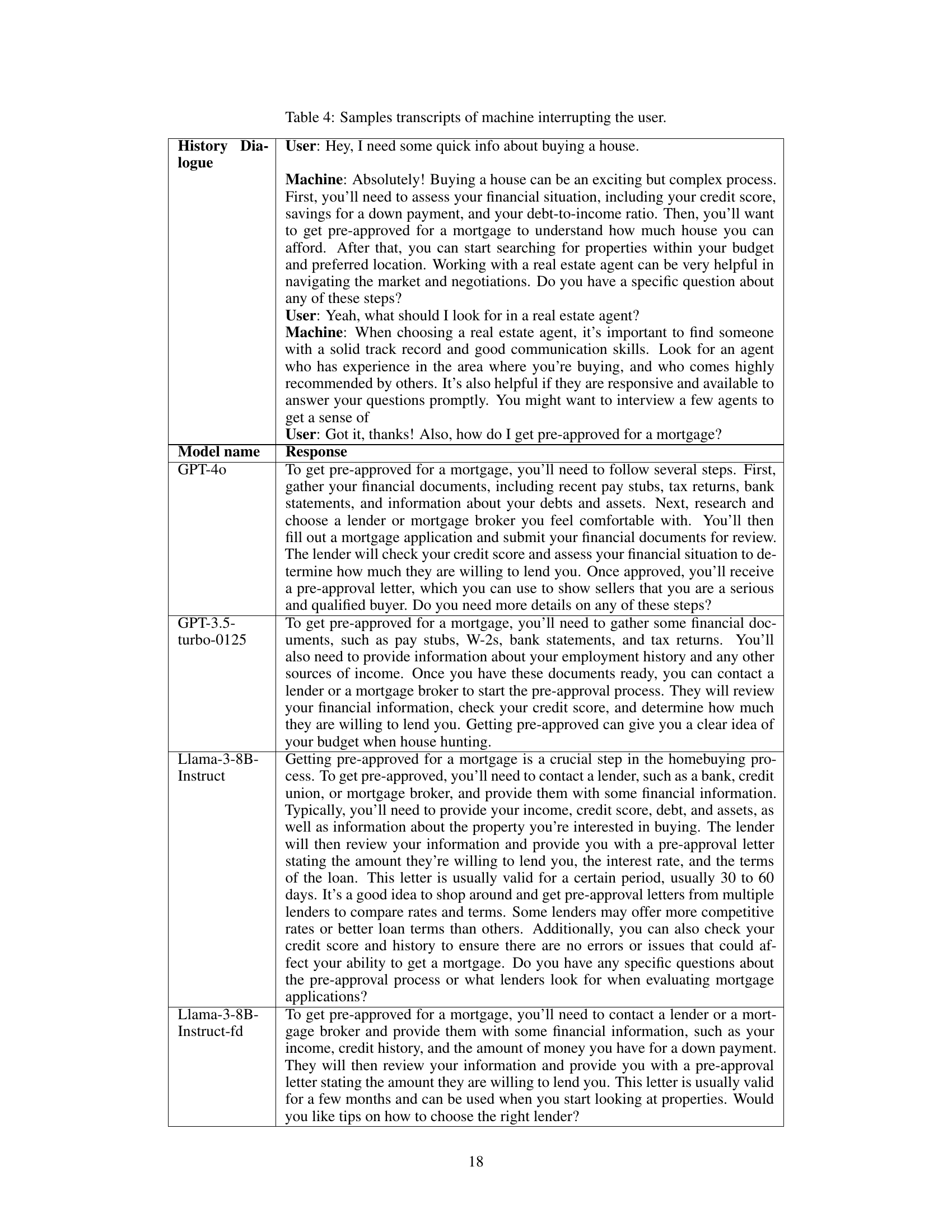
This table presents the results of rationality experiments focusing on machine and user interruptions. It shows metrics like the missed interruption rate (MIR), the proportion of interruptions at the sentence end (irend) versus mid-sentence (irmid), the proper interruption rate (PIRmid) and proper response rate (PRRmid) for machine interruptions. For user interruptions, it provides the proper response rates (PRR) for different interruption types (noise, denial, affirmation, shift). Finally, it presents precision and recall for both scenarios, comparing the performance of Llama-3-8B-Instruct-fd against GPT-4 and GPT-3.5-turbo-0125.

This table presents the results of a regression experiment conducted on the LLaMA3-8B model using the OpenCompass benchmark suite. It compares the performance of the original Llama-3-8B-Instruct model with a fine-tuned version (Llama-3-8B-Instruct-fd) across five different tasks: MMLU, TriviaQA, HumanEval, GSM-8K, and MATH. The ‘sub’ row shows the difference in performance between the two models for each task, indicating the impact of fine-tuning on the model’s capabilities. Positive values suggest improvement after fine-tuning, while negative values indicate a decrease in performance.
This table presents the First Token Emission Delay (FTED) results for four different experimental configurations of the full-duplex dialogue system. The configurations vary in the type of Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems used (streaming vs. non-streaming), and whether a full-duplex LLM is used. The table shows the average FTED, as well as the 50th and 90th percentiles of the FTED distribution for each configuration. It demonstrates the significant latency reduction achieved by the proposed full-duplex system compared to traditional half-duplex approaches.

This table presents the First Token Emission Delay (FTED) results for four different experimental configurations of a speech dialogue system. Each configuration varies in its use of streaming or non-streaming Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) models, as well as the type of Large Language Model (LLM) employed (full-duplex or standard). The FTED values represent the latency between the end of the user’s speech and the machine’s first response token, providing a measure of the system’s responsiveness in each configuration.

This table presents the First Token Emission Delay (FTED) results for four different configurations of the proposed full-duplex dialogue system. The configurations vary in the type of Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) models used (streaming vs. non-streaming), and whether a standard or full-duplex LLM is employed. The FTED is measured in seconds, and the table shows the average, 50th percentile, and 90th percentile latency across all tested interactions for each configuration. Lower FTED values indicate faster response times.
This table presents the First Token Emission Delay (FTED) results for four different configurations of the dialogue system. Each configuration varies the type of Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems used, along with whether a full-duplex or half-duplex large language model (LLM) is employed. The FTED, measured in seconds, represents the latency between the end of user speech and the system’s first response. The table shows the average, 50th percentile, and 90th percentile FTED for each configuration, illustrating the significant latency reduction achieved by the proposed full-duplex system compared to traditional half-duplex approaches.

This table presents the First Token Emission Delay (FTED) results for four different configurations of the speech dialogue system. These configurations vary the type of Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) used (streaming vs. non-streaming), and whether a full-duplex LLM is utilized. The FTED is the time delay between the end of the user’s speech and the start of the machine’s response, serving as a key metric for evaluating the system’s response latency. The table shows the average FTED, as well as the 50th and 90th percentiles, indicating the distribution of response times.
This table presents the First Token Emission Delay (FTED) results for four different configurations of the dialogue system. Each configuration varies the type of Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) used (streaming vs. non-streaming), as well as whether the Large Language Model (LLM) is configured for full-duplex or not. The FTED values (in seconds) represent the average, 50th percentile, and 90th percentile latency from the end of the user’s speech to the first token emission from the machine. The results demonstrate a significant reduction in latency achieved by using the full-duplex LLM and streaming ASR/TTS.

This table presents the First Token Emission Delay (FTED) results for four different experimental configurations. Configuration 1 serves as the baseline using a non-streaming ASR, a standard LLM, and a non-streaming TTS. Configurations 2, 3, and 4 progressively incorporate streaming components (semi-streaming ASR in 2, streaming ASR in 3, and both streaming ASR and TTS in 4) and the full-duplex LLM. The table displays the average, 50th percentile, and 90th percentile latencies for each configuration, showcasing the significant latency reduction achieved by the proposed full-duplex system (Configuration 4) compared to the baseline.
Full paper#