↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-label image recognition struggles with contextual bias, where correlations between labels learned during training mislead the classifier during testing. Existing methods either ignore label correlations or attempt to remove contextual information, often sacrificing performance. This paper introduces a new approach that uses causal intervention to identify and leverage causal label correlations while suppressing spurious ones.
The researchers propose a framework that uses a Transformer decoder to separate label-specific features, clusters spatial features to model confounders (factors causing spurious correlations), and employs a cross-attention module to implement causal intervention, quantifying the causal influence of each category on every other. The final prediction combines predictions from both the decoupled features and the causal correlations. Experiments show that this method is significantly more effective than existing techniques in both common and cross-dataset scenarios, clearly demonstrating the benefit of carefully modeling causal relationships in multi-label image recognition.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-label image recognition because it directly addresses the issue of contextual bias, a major limitation of existing methods. It proposes a novel causal intervention approach to effectively model label correlations, leading to improved accuracy and robustness, particularly in challenging cross-dataset settings. This work opens new avenues for research into causal reasoning and its applications in computer vision, prompting investigations into more sophisticated causal models and their impact on visual recognition tasks. The findings also highlight the importance of considering the training data bias and developing techniques to enhance the generalizability of multi-label image recognition models.
Visual Insights#

The figure shows an example of contextual bias in multi-label image recognition. In the training image, a person, a dog, and a cat are present together. The model learns a strong correlation between these three labels. However, in the testing image, only a person and a dog are present. Because of the learned correlation, the model incorrectly predicts a high probability for ‘cat’, even though a cat isn’t in the image.
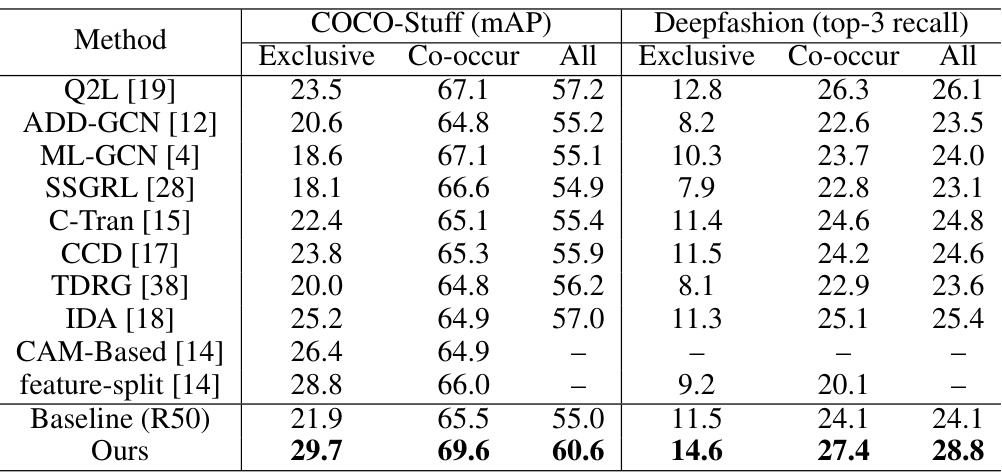
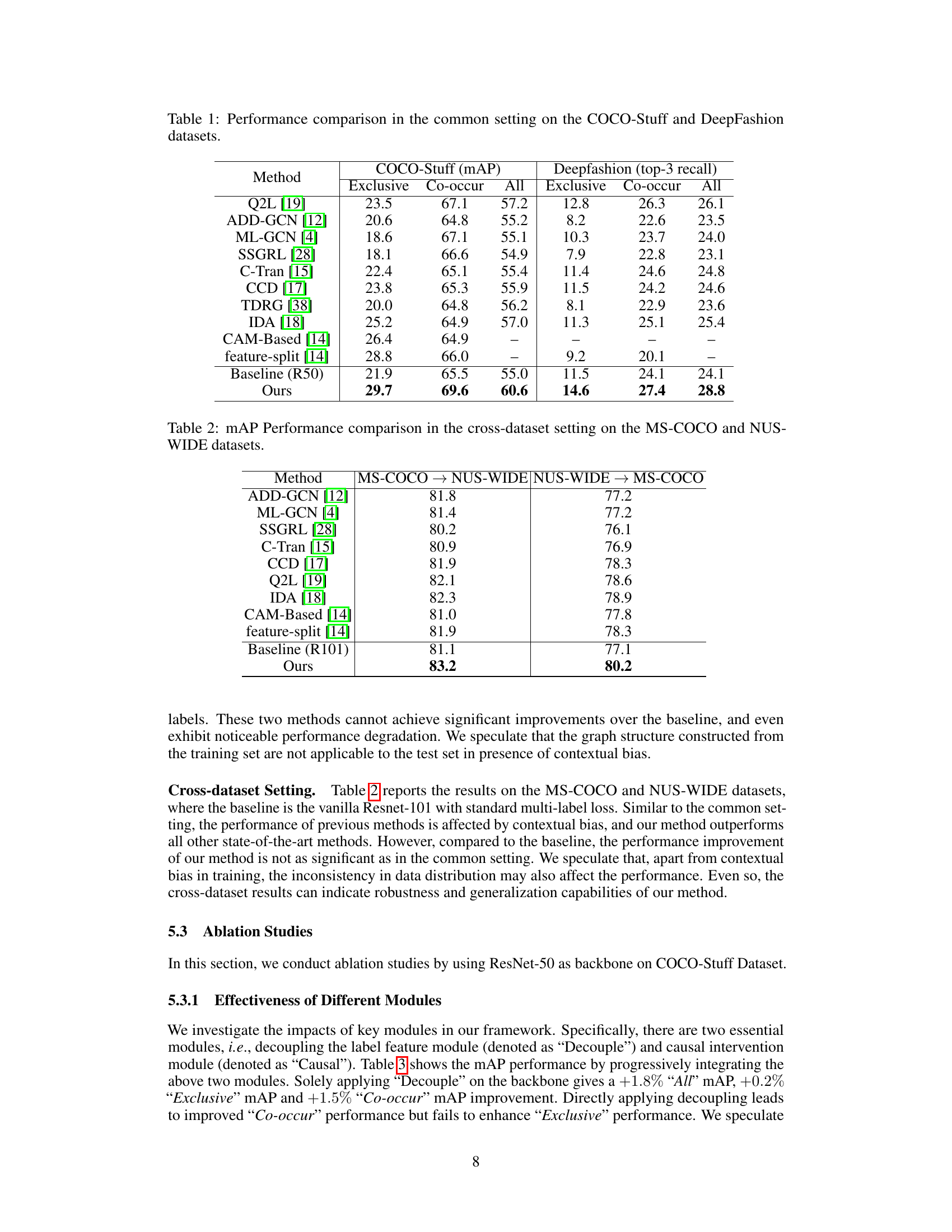
This table presents the performance comparison of different multi-label image recognition methods on the COCO-Stuff and DeepFashion datasets. The performance is evaluated under two different settings: ‘Exclusive’, where labels that co-occur in the training set do not co-occur in the test set; and ‘Co-occur’, where labels co-occur in both the training and test sets. The table shows the mean Average Precision (mAP) for COCO-Stuff and top-3 recall for DeepFashion. The ‘All’ column represents the average performance across all categories.
In-depth insights#
Causal Correlation Hunt#
A ‘Causal Correlation Hunt’ in a research paper would likely involve investigating causal relationships between variables, moving beyond mere correlations. This would necessitate employing causal inference techniques, such as do-calculus or causal diagrams, to disentangle direct causal effects from confounding influences. The hunt would focus on identifying genuine causal links, separating them from spurious correlations arising from shared latent factors or common causes. The process might involve statistical analysis of observational data, potentially supplemented by interventional studies, if feasible, to better isolate causal effects. The ultimate aim would be to establish a clear understanding of cause-and-effect relationships, which is crucial for constructing accurate and predictive models. Challenges in such a hunt include handling confounding variables, dealing with complex interactions, and ensuring sufficient data quality for reliable causal inference. Successfully navigating these complexities would lead to a robust understanding of causal relationships and improved ability to predict and manipulate the system under investigation.
Intervention Approach#
The core of this research lies in its novel causal intervention approach for multi-label image recognition. Instead of simply modeling correlations between labels, which can be misleading due to contextual bias, this method focuses on identifying causal relationships. By decoupling label-specific features and modeling confounders, the approach quantifies causal correlations, effectively separating useful contextual cues from spurious ones. Causal intervention is implemented through a cross-attention mechanism, allowing the model to assess the impact of each object category on the prediction of others, irrespective of confounding factors present in the training data. This results in improved robustness and accuracy, especially in cross-dataset settings where contextual bias is often more pronounced. The use of causal inference represents a significant methodological advance, moving beyond simple correlation analysis to a more nuanced understanding of label relationships, and demonstrating the effectiveness of causal reasoning in tackling challenging computer vision problems. The success hinges on effectively modeling confounders, a key challenge addressed through a clustering approach. The overall design aims for a more robust and generalized system, highlighting a paradigm shift toward causality-based reasoning for advanced multi-label image recognition.
Debiasing Multi-label#
Debiasing multi-label classification tackles the crucial issue of contextual bias, where the co-occurrence of labels in training data misleads models during testing. Standard multi-label approaches often implicitly rely on these spurious correlations, leading to inaccurate predictions. Effective debiasing strategies aim to disentangle true label relationships from these artifacts, improving model generalizability. Causal inference offers a powerful framework by focusing on genuine causal relationships between labels, removing the influence of confounding factors that create spurious associations. Techniques like causal intervention help isolate the direct effects of specific labels, enhancing robustness against misleading contextual information. A key challenge is identifying and mitigating these confounders, which may involve sophisticated data analysis and model design. The success of debiasing ultimately depends on the ability to accurately capture the underlying causal structure, leading to fairer and more reliable multi-label classification systems.
Cross-dataset Results#
Cross-dataset evaluation is crucial for assessing the generalizability of multi-label image recognition models. It reveals how well a model trained on one dataset performs when presented with unseen data from a different source. This is a more realistic scenario than typical within-dataset tests, as real-world applications rarely encounter perfectly matched training and testing distributions. Contextual bias, which arises from correlations between labels, might significantly hinder performance in cross-dataset settings, if the model learns spurious correlations specific to the training dataset. Therefore, observing strong cross-dataset results suggests that the method is robust to dataset variations and has learned transferable features. It is an indicator of the algorithm’s ability to capture generalizable features for objects, rather than relying on dataset-specific contextual cues. The extent of performance drop across datasets reveals the algorithm’s sensitivity to domain shift. A small performance degradation would suggest a very robust model capable of handling unseen distributions effectively. However, a large drop would highlight potential limitations, suggesting that the model has overfit to the specificities of the training data. Careful analysis of cross-dataset results, therefore, is essential for understanding both strengths and weaknesses of proposed multi-label recognition techniques.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the confounder modeling is crucial; current methods rely on clustering spatial features, which may not fully capture the complex interplay of contextual factors. Investigating alternative methods, such as incorporating object relationships or scene graphs, could significantly enhance the accuracy and robustness of causal intervention. Extending the framework to handle imbalanced datasets is another key area; the current approach might not generalize well to scenarios where certain object classes are under-represented. Finally, exploring different causal inference techniques beyond the probability-raising causal intervention, including methods robust to latent confounders, could open up new possibilities for modeling label correlations in multi-label image recognition, potentially leading to more effective and accurate models.
More visual insights#
More on figures
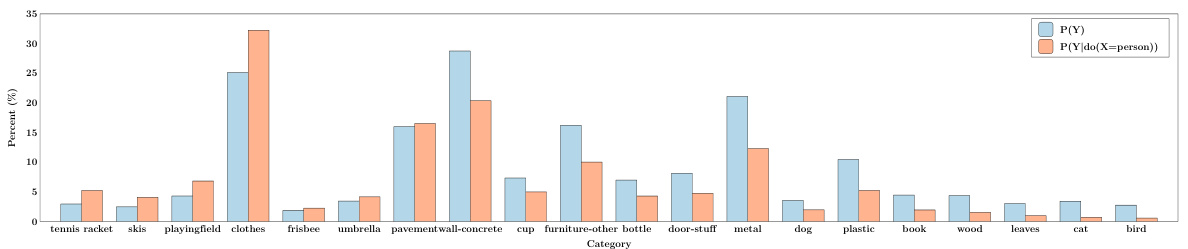
The figure shows the results of causal intervention on a multi-label image recognition task. It compares the probability of predicting different object categories (Y) with and without the presence of a ‘Person’ (X). Bars represent the base probability of each category and the probability of the category given the presence of a person. Categories where the probability increases significantly due to the presence of a person show causal correlation, while categories where the probability remains similar or decreases show spurious correlations. This illustrates the concept of causal intervention used in the proposed method to distinguish useful contextual information from misleading information.

This figure illustrates the difference between causal and spurious correlations using a causal graph. Panel (a) depicts a causal correlation where variable X causally influences variable Y, and this relationship isn’t influenced by a confounder C. In contrast, panel (b) shows a spurious correlation: X and Y appear correlated only because they both share a common cause, the confounder C. This highlights the importance of causal inference in discerning true relationships from mere statistical associations.
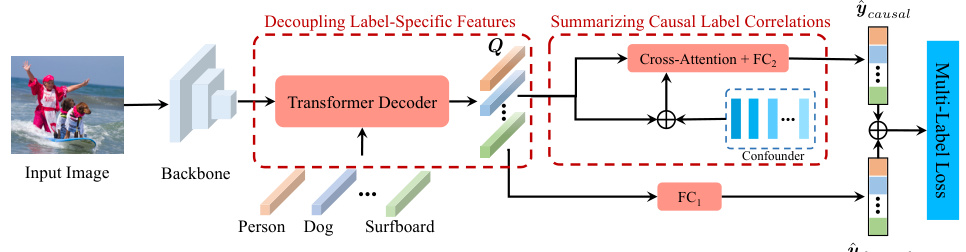
The figure shows the overall framework of the proposed method for multi-label image recognition. It consists of two main branches: the decoupling label-specific features branch and the summarizing causal label correlations branch. The decoupling branch uses a transformer decoder to extract label-specific features from the input image’s spatial features. The causal correlations branch uses a cross-attention module with confounders (representing contextual information) to calculate causal correlations between object categories. Finally, the predictions from both branches are combined to produce the final multi-label prediction.

This figure shows the overall framework of the proposed method, which consists of two main branches: the decoupled label-specific features branch and the causal label correlations branch. The input image is first processed by a backbone network to extract spatial features. These features are then fed into a Transformer decoder to decouple label-specific features. These decoupled features are used to predict image labels based on the objects themselves. In parallel, the spatial features are also used to model confounders, which are then used with the decoupled features in a cross-attention module to implement causal intervention. The predictions from both branches are then combined to generate the final multi-label prediction.

The figure shows the Grad-CAM visualization for baseline and proposed methods on four images. Grad-CAM highlights image regions that are most important for a specific prediction. This figure demonstrates that the proposed method better localizes the relevant object features compared to the baseline, especially when dealing with negative labels (where the object is not present in the image). The baseline tends to highlight spurious correlations, while the proposed method focuses specifically on the target object. In images (a) and (b), the model correctly predicts the presence of objects like ‘cell phone’ and ‘dog’ by focusing on those respective objects only. In images (c) and (d), which contain no baseball bat or spoon, the proposed method suppresses spurious correlations, unlike the baseline method.
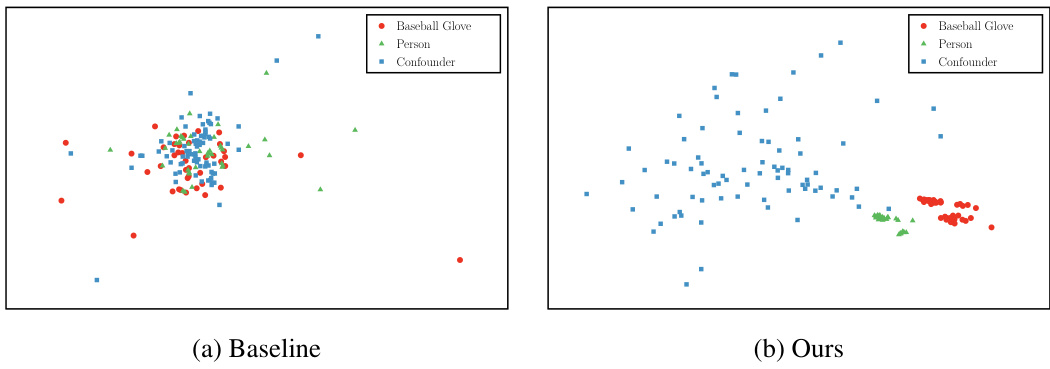
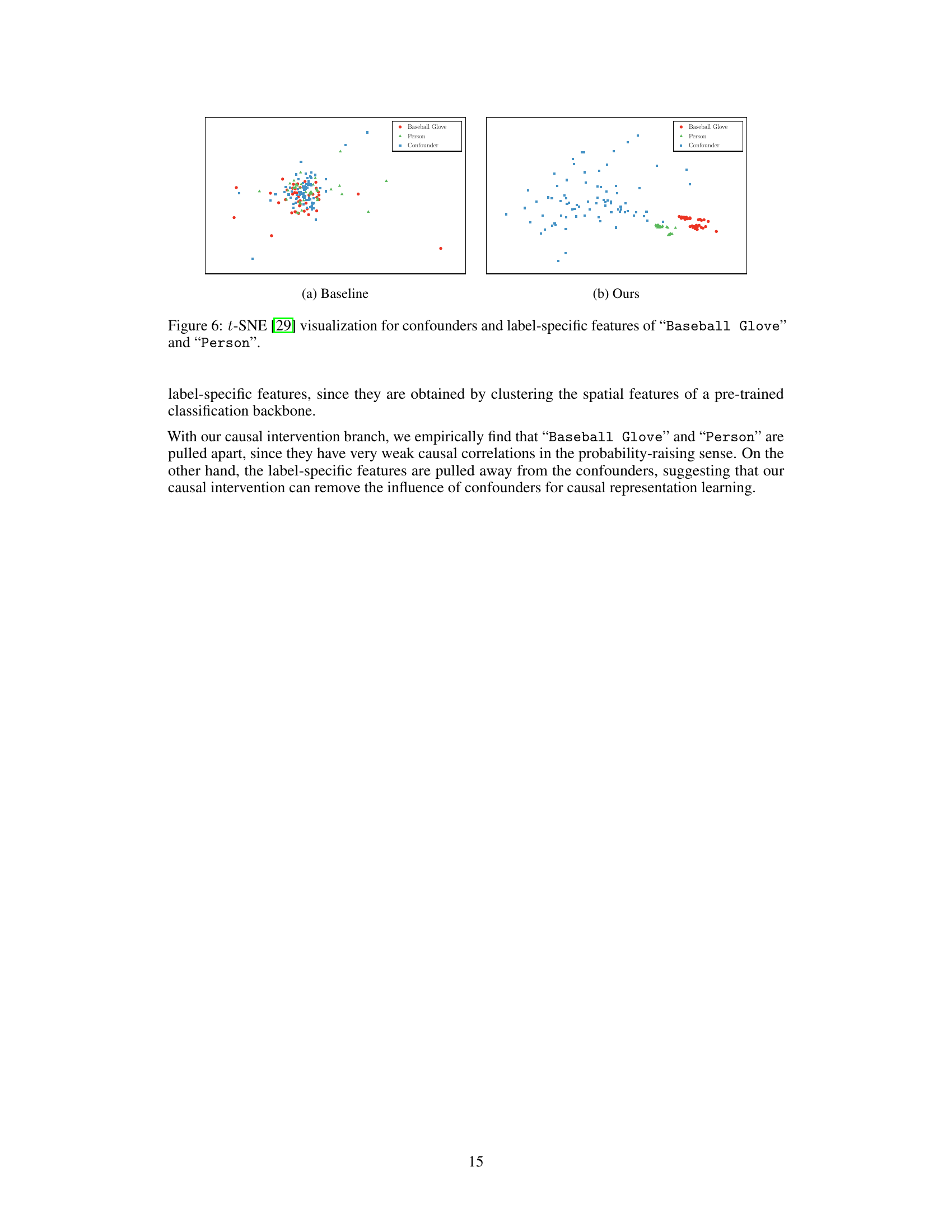
This figure shows the t-SNE visualization of confounders and two typical label-specific features (“Baseball Glove” and “Person”) from the baseline and proposed methods. In the baseline, the label-specific features for ‘Baseball Glove’ and ‘Person’ are mixed with each other and the confounders, indicating a strong correlation between them. In the proposed method, these features are pulled apart and away from the confounders, indicating that causal intervention successfully removes the influence of confounders and captures only causal label correlations.
More on tables
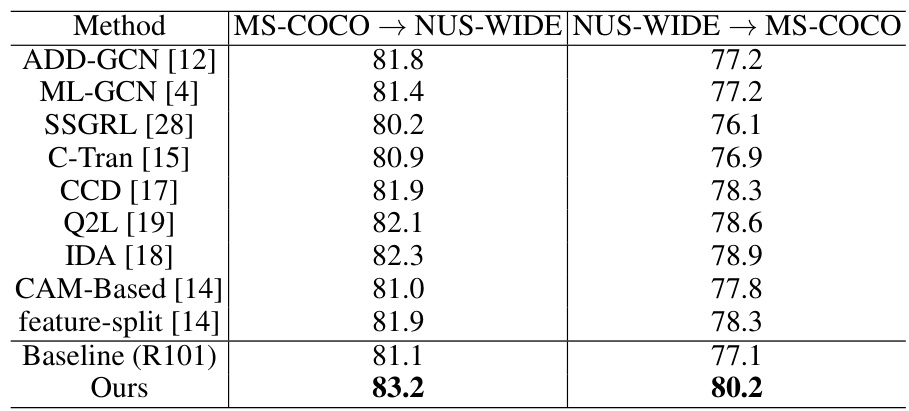
This table presents the results of the cross-dataset experiments, where the training set is from one dataset (either MS-COCO or NUS-WIDE) and the testing set is from the other dataset. The goal is to evaluate the model’s robustness to domain shift and contextual bias present in the cross-dataset setting. The mAP (mean Average Precision) is reported for all common classes across both datasets. Comparing the performance on MS-COCO to NUS-WIDE with the reverse setting demonstrates the generalizability of the model in diverse situations. The baseline is included for comparison to highlight the effectiveness of the proposed approach in handling cross-dataset scenarios.
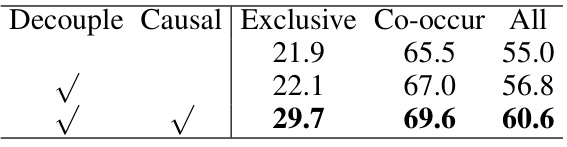
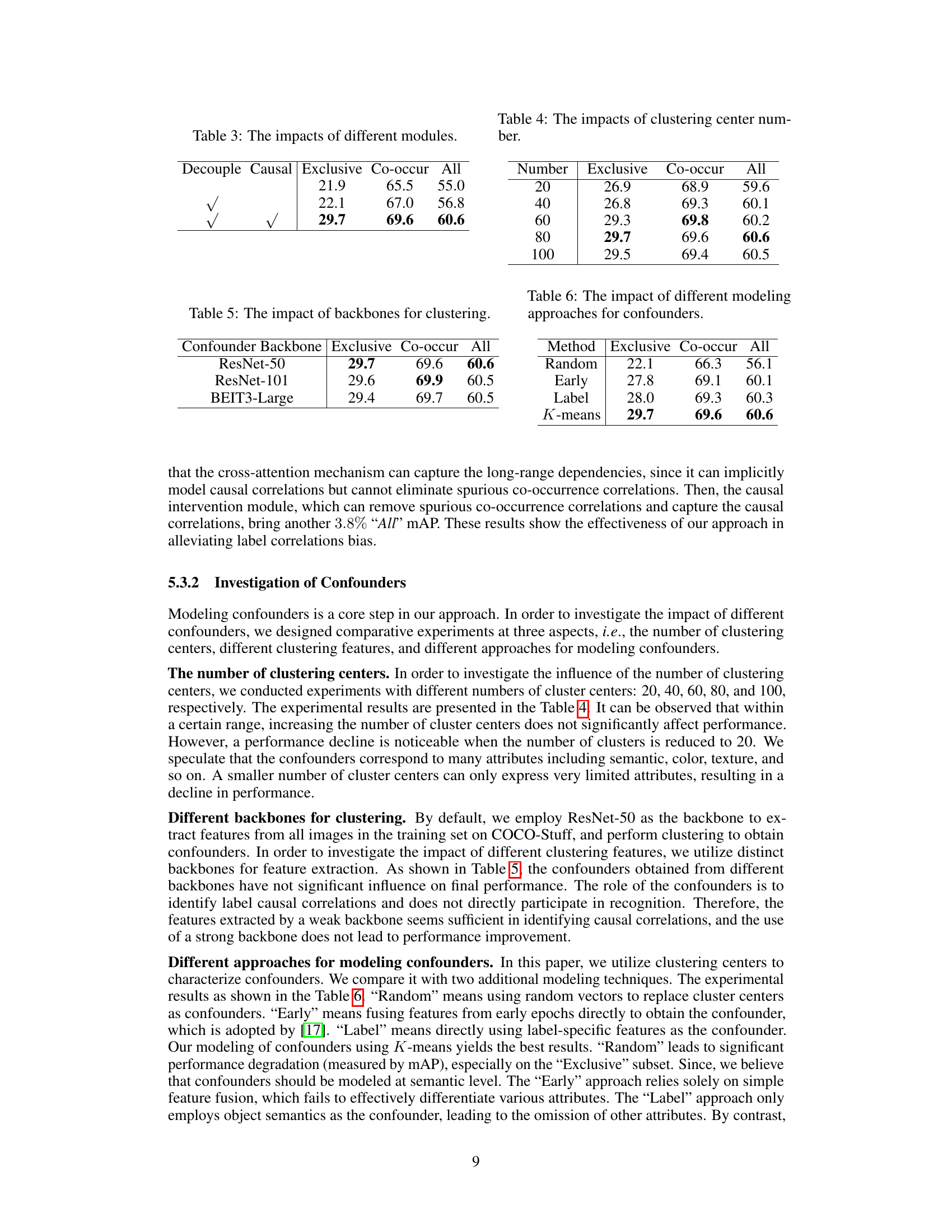
This table presents the ablation study results on the COCO-Stuff dataset by progressively integrating two essential modules: decoupling the label feature module and causal intervention module. It shows the impact of each module on the performance metrics, including ‘Exclusive’, ‘Co-occur’, and ‘All’, demonstrating the effectiveness of the proposed approach in improving multi-label image recognition accuracy.
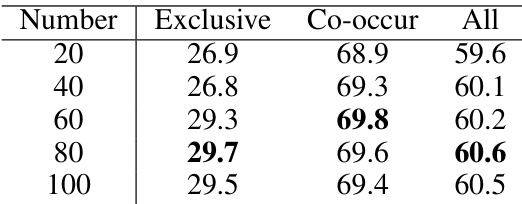
This table shows the performance of the proposed model with different numbers of clustering centers for confounders. The results suggest that there is an optimal number of clusters that balances model performance and computational cost, with diminishing returns for larger cluster counts.
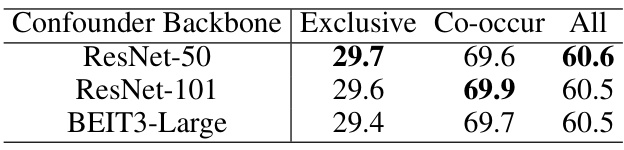
This table presents the results of ablation studies conducted to evaluate the impact of different backbones used for extracting features to model confounders in the causal intervention branch. Three different backbones, ResNet-50, ResNet-101, and BEIT3-Large, are compared. The table shows the performance (Exclusive, Co-occur, and All mAP) achieved using each backbone for the generation of confounders. The results indicate whether selecting a stronger backbone for generating confounders leads to significantly improved performance.
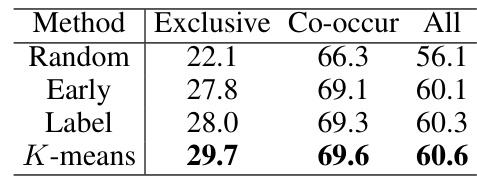
This table presents the results of an ablation study that investigates the impact of different methods for modeling confounders on the performance of the proposed multi-label image recognition model. The study compares four different approaches for modeling confounders: Random, Early, Label, and K-means. The results are reported in terms of mAP (mean Average Precision) for three different test distributions: Exclusive, Co-occur, and All.

This table compares different implementations of equation 7 from the paper, which is about calculating the final prediction confidence by merging predictions from different branches. The table shows that using a linear approach gives comparable results but the proposed approach achieves better performance. This highlights that the proposed cross-attention method in the paper is effective in capturing the long-range dependencies and causal correlations.

This table compares the performance of different multi-label image recognition methods on the COCO-Stuff and DeepFashion datasets. The ‘common setting’ implies that training and testing data come from the same dataset. Results are shown for different test distributions (‘Exclusive’, ‘Co-occur’, ‘All’), reflecting how well the models generalize to cases where label co-occurrences in training and testing sets differ. The metrics used are mAP (mean Average Precision) for COCO-Stuff and top-3 recall for DeepFashion. The table helps illustrate the effectiveness of the proposed approach compared to several state-of-the-art methods.
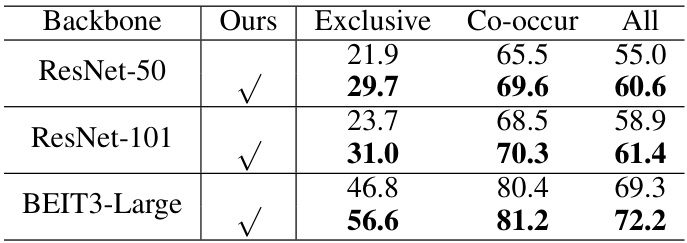
This table shows the performance of the proposed multi-label image recognition method using different backbones (ResNet-50, ResNet-101, and BEIT3-Large) on the COCO-Stuff dataset. The results are broken down by the test set distribution (‘Exclusive’, ‘Co-occur’, and ‘All’) to show the effectiveness under different scenarios. The ‘Ours’ column indicates the performance of the proposed method, which incorporates causal intervention, while the other columns provide baseline ResNet results for comparison.
Full paper#