↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Reconstructing 3D scenes from images is a classic computer vision problem. Traditional methods involve multiple complex stages, leading to slow processing and engineering challenges. The main issue is the dependence on accurate camera pose estimations, which are often inaccurate or difficult to obtain, particularly in scenes with limited views or low texture. Existing solutions also typically break down this holistic task into subproblems, and errors in one stage propagate to others. Open-vocabulary methods are desirable for their flexibility but are limited by lack of sufficient labeled 3D data.
The Large Spatial Model (LSM) directly addresses these issues. It uses a unified Transformer-based framework to process unposed images into semantic radiance fields, simultaneously estimating geometry, appearance, and semantics in a single feed-forward pass. By incorporating a pre-trained 2D language-based segmentation model, LSM achieves open-vocabulary capabilities and natural language driven scene manipulation. LSM’s unique design eliminates the need for traditional camera pose estimation and multi-stage processing, resulting in real-time performance. The comprehensive experiments demonstrate the model’s effectiveness across various tasks, showcasing its ability to perform real-time semantic 3D reconstruction from unposed images.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel unified framework for several key 3D vision tasks, achieving real-time semantic 3D reconstruction directly from unposed images. This addresses a major challenge in computer vision by eliminating the need for complex multi-stage pipelines and improving efficiency. The real-time performance opens new avenues for applications like autonomous driving and robotics, while the unified framework simplifies the development of future 3D vision systems. The use of a pre-trained 2D language-based segmentation model further enhances the model’s ability to understand and interact with 3D scenes in a more natural way. The innovative approach of directly processing unposed RGB images into semantic radiance fields without requiring explicit camera parameters is particularly impactful, paving the way for more robust and scalable 3D vision systems. This research paves the way for more efficient and robust 3D scene understanding and manipulation, particularly useful in applications that require real-time interaction, such as autonomous driving, robotics, and virtual/augmented reality.
Visual Insights#
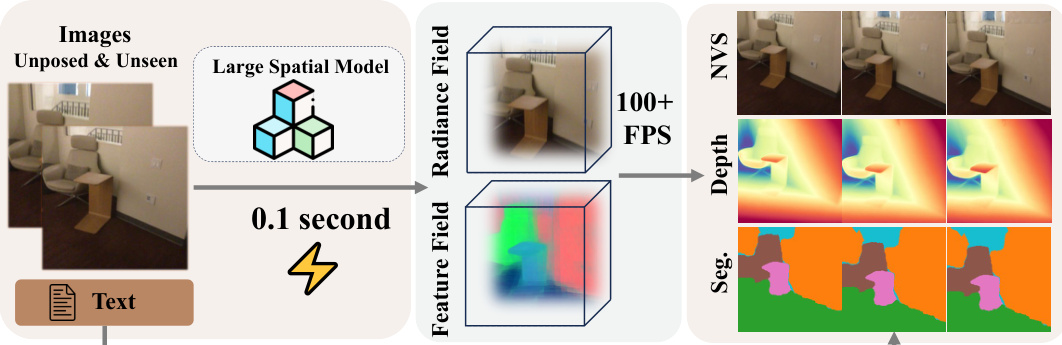
This figure illustrates the Large Spatial Model (LSM) pipeline. Two unposed images are fed into the LSM, which then generates a 3D radiance field in 0.1 seconds. This radiance field represents the scene’s geometry, appearance, and semantics. From this radiance field, the LSM can produce a variety of outputs, including novel views (NVS), depth maps, and semantic segmentations at a speed exceeding 100 FPS. This demonstrates the model’s efficiency and versatility in performing various 3D vision tasks simultaneously.

This table presents a quantitative comparison of the Large Spatial Model (LSM) against other state-of-the-art methods on three key 3D vision tasks: novel-view synthesis, depth estimation, and open-vocabulary segmentation. It highlights LSM’s ability to achieve comparable or better performance without requiring any preprocessing steps such as Structure-from-Motion (SfM), which other methods rely on. The metrics used include mIoU, accuracy, relative depth error, PSNR, SSIM, and LPIPS.
In-depth insights#
Unified 3D Framework#
A unified 3D framework represents a significant advancement in computer vision by integrating multiple 3D vision tasks into a single, streamlined process. Instead of the traditional, multi-stage pipeline (e.g., SfM, sparse reconstruction, dense modeling, task-specific neural networks), this approach directly processes input images to generate a comprehensive 3D representation. This unification significantly reduces processing time and engineering complexity, offering a more efficient and effective workflow. The core of the framework likely involves a powerful neural network architecture, such as a Transformer, capable of simultaneously estimating geometry, appearance, and semantics. The ability to directly handle unposed and uncalibrated images is a key advantage, eliminating the need for preprocessing steps like structure-from-motion (SfM), which are often unreliable or computationally expensive. The framework likely predicts a dense 3D representation (e.g., radiance field, point cloud) that enables various downstream tasks like novel-view synthesis, depth prediction, and open-vocabulary semantic segmentation to be performed directly. This end-to-end learning paradigm facilitates a higher level of integration and accuracy than conventional approaches.
Transformer-Based Model#
A hypothetical ‘Transformer-Based Model’ section in a research paper would likely delve into the architecture and functionality of a deep learning model leveraging the transformer architecture. This would involve a detailed explanation of its components, including the encoder and decoder modules, attention mechanisms, and any unique modifications for the specific application. The discussion should highlight the advantages of using transformers, such as their ability to process sequential or spatial data effectively and capture long-range dependencies. The section might compare the proposed model to other existing architectures, demonstrating its superior performance on relevant benchmarks and tasks. It’s crucial to discuss the training methodology, including the datasets used, loss functions, optimization algorithms, and hyperparameter tuning strategies. A significant portion should cover the model’s interpretability, if possible, offering insights into how it generates predictions and the relationships between input and output. Finally, the section could present analyses of the model’s efficiency and scalability, addressing aspects like training time and computational resource requirements.
Semantic Anisotropy#
Semantic anisotropy, in the context of 3D scene representation, refers to the uneven distribution of semantic information across different spatial orientations. Instead of assuming uniform semantic properties throughout a 3D object or scene, this concept acknowledges that meaning can vary significantly depending on the viewing direction or the specific surface feature. For example, the semantic meaning of a wall might be primarily associated with its vertical extent and surface material, while the semantic label for a chair might be strongly linked to its seating area and leg structure. Modeling semantic anisotropy requires techniques that can capture this directional dependency, perhaps through anisotropic Gaussian distributions or other methods that explicitly incorporate directional features into the semantic representation. This approach promises more accurate and nuanced 3D scene understanding, as it moves beyond simple volumetric labeling towards a representation that better reflects the complex spatial relationship between geometry and semantics.
Real-time Reconstruction#
Real-time 3D reconstruction from images is a challenging computer vision problem with many applications. This capability to generate a 3D model instantaneously is crucial for interactive systems and augmented/virtual reality. The key challenges include efficiently processing large amounts of visual data, accurately estimating camera parameters (often without explicit calibration), robustly handling occlusions, and producing semantically meaningful 3D outputs. Successful real-time reconstruction systems often leverage deep learning models, particularly those based on neural radiance fields (NeRFs) or similar implicit representations. These methods can directly learn mappings from 2D images to 3D scenes. However, computational constraints necessitate efficient architectures and training strategies to achieve real-time performance. The trade-off between accuracy, detail level, and speed also plays a significant role in system design. Future directions in this area will likely focus on improving efficiency through model compression, exploring more sophisticated representation techniques, and further integrating semantic information for enhanced scene understanding.
Scalability Challenges#
Scalability in 3D vision systems faces significant hurdles. Traditional methods, heavily reliant on multi-stage pipelines (e.g., Structure-from-Motion), struggle with increasing computational costs as the number of images grows. These pipelines often suffer from error propagation, where inaccuracies in early stages (like camera pose estimation) severely impact subsequent steps. Further challenges arise from the scarcity of large-scale, high-quality 3D datasets with comprehensive annotations, hindering the training of robust and generalized deep learning models. Data limitations are especially acute for tasks such as open-vocabulary semantic segmentation, where the range of potential labels is vast. Finally, achieving real-time performance remains a major obstacle, particularly for applications demanding high-fidelity 3D reconstruction and rendering at high frame rates. Addressing these scalability challenges requires innovative approaches, such as unified frameworks that integrate multiple tasks, efficient architectures that minimize computational overhead, and strategies to leverage limited data effectively through transfer learning and synthetic data augmentation.
More visual insights#
More on figures
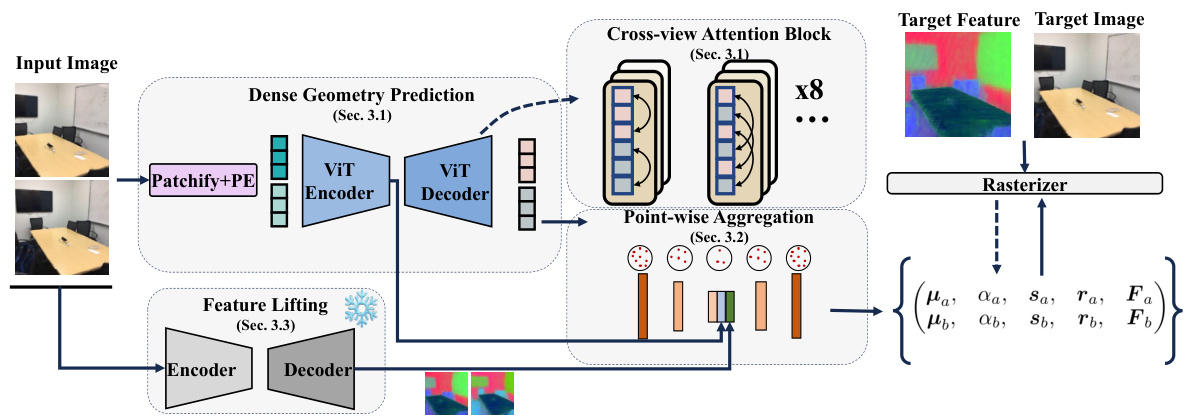
This figure illustrates the architecture of the Large Spatial Model (LSM). It shows the process of taking input images, performing dense geometry prediction using a Transformer, aggregating features at the point level with cross-view and cross-modal attention, and finally using a rasterizer to produce a semantic 3D reconstruction. The model is trained end-to-end, generating pixel-aligned point maps and semantic anisotropic 3D Gaussians, allowing for real-time reconstruction without the need for camera parameters at inference time.

This figure shows the visualization of 3D feature fields rendered from novel viewpoints using PCA. It demonstrates how the model converts 2D image features into a consistent 3D representation, which enables versatile and efficient semantic segmentation.

This figure compares the novel view synthesis results of the proposed Large Spatial Model (LSM) with three other state-of-the-art methods: NeRF-DFF, Feature-3DGS, and pixelSplat. The comparison highlights that LSM achieves comparable visual quality to the other methods, but without requiring a pre-processing step (Structure from Motion) to estimate camera poses, showing the efficiency of the LSM approach.
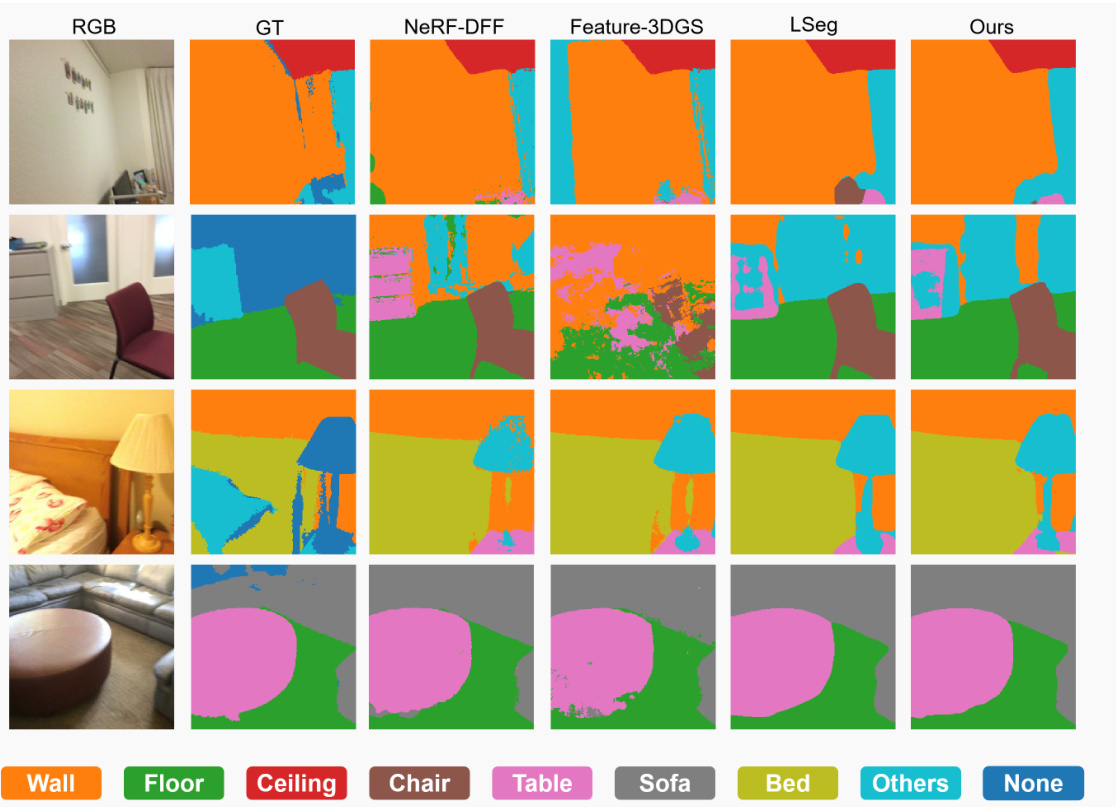
This figure compares the performance of the proposed Large Spatial Model (LSM) against other state-of-the-art methods for language-based 3D semantic segmentation on four unseen scenes. It visually demonstrates the model’s ability to produce accurate and detailed 3D semantic segmentations comparable to other top-performing techniques, highlighting its capacity to effectively translate 2D features into high-quality 3D feature fields for improved semantic understanding.
More on tables

This table presents the results of an ablation study evaluating the impact of different design choices on the Large Spatial Model (LSM). The study investigates the contributions of cross-view attention, cross-modal attention (fusing geometry and semantic features), and multi-scale fusion to the model’s performance on semantic segmentation and novel view synthesis. The baseline model (Exp #1) uses cross-view attention and point-wise aggregation. Subsequent experiments add cross-modal attention and multi-scale fusion, demonstrating their positive effects on model accuracy.

This table breaks down the inference time for each module of the Large Spatial Model (LSM). It shows the time taken for Dense Geometry Prediction, Point-wise Aggregation, and Feature Lifting, as well as the total inference time. This information helps in understanding the computational cost of each module within the overall system.

This table compares the performance of LSM with other methods (pixelSplat and Splatter Image) on the Replica dataset, focusing on metrics such as mIoU (mean Intersection over Union), rel (relative depth error), and PSNR (Peak Signal-to-Noise Ratio). A key aspect highlighted is that LSM does not require offline Structure-from-Motion (SfM) for camera parameter estimation, unlike the other methods. The table demonstrates LSM’s ability to achieve competitive results without this preprocessing step, emphasizing its efficiency and generalizability.
Full paper#

















