↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many machine learning applications demand explainable AI, requiring models to provide understandable justifications for their decisions. However, malicious actors might manipulate explanations to hide bias or unfairness. This paper investigates how a third party can audit local explanations (explanations for individual decisions) to detect this manipulation. A key challenge is the limited information available to the auditor, who only sees individual decisions and their explanations, without full access to the model or training data.
The paper proposes a rigorous auditing framework and studies how much data an auditor needs to reliably detect manipulated explanations. It introduces a key factor in this: the “locality” of the explanations. This describes the size of the region around a data point for which an explanation is valid. The main finding is that auditing local explanations is computationally very hard, particularly in high-dimensional settings where local regions are small. The required data increases dramatically as the dimensionality grows, rendering auditing impractical with current methods. The analysis highlights that using only pointwise explanations could be insufficient. This provides vital insights for the design of more robust and reliable explainable AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals the inherent difficulty in verifying the trustworthiness of local explanations in complex machine learning models. This challenges the current reliance on explanations for ensuring transparency and fairness in AI, particularly in high-stakes decision-making scenarios. The findings highlight the need for new approaches to AI auditing and explainability that go beyond simple pointwise explanations.
Visual Insights#

This figure compares two scenarios of local explanations. Panel (a) shows insufficient data points to verify the accuracy of local linear explanations against the true classifier. Panel (b) shows a sufficient number of data points within the local regions, enabling a more accurate assessment of the explanations’ fidelity.
In-depth insights#
Explainability Audit#
Explainability audits aim to verify the trustworthiness of machine learning model explanations. This is crucial because, in sensitive applications (like loan applications or hiring decisions), users need to trust the AI’s reasoning. Audits often involve a third party (or group of users) who query the model’s predictions and explanations to check for inconsistencies. A key challenge lies in the “locality” of explanations, meaning how focused an explanation is on a single data point. Highly local explanations are difficult to audit reliably because they require a huge amount of data to verify their accuracy. Successful auditing needs to balance data requirements with the practicality of obtaining enough data for robust verification, especially in high-dimensional datasets. Future research should explore methods for assessing global consistency of explanations, as well as alternative approaches that improve transparency without requiring full model disclosure.
Locality Limits#
The concept of Locality Limits in the context of auditing local explanations for machine learning models is crucial. It highlights the inherent challenge in verifying the fidelity of explanations when limited to local regions around data points. Smaller local regions, as often produced by popular explanation methods, severely hinder the auditor’s ability to assess accuracy. This is because insufficient data points may fall within these limited regions, making it difficult to distinguish between genuine and fabricated explanations. High-dimensional data exacerbates this problem, leading to exponentially smaller local regions and requiring an impractical amount of data for effective auditing. Therefore, locality is a key factor influencing the feasibility of auditing local explanations. The findings emphasize the need for novel techniques that move beyond pointwise explanations or enhance the size of the locality regions to ensure verifiable trustworthiness, especially in high-stakes applications.
Data Dependency#
The concept of ‘Data Dependency’ in machine learning model explainability is crucial. It highlights how the quality and quantity of data directly impact the reliability of local explanations. Insufficient data within a local region, especially in high-dimensional settings, makes it difficult to verify the accuracy of explanations. This ’locality’ problem is a key challenge, as it limits the ability to audit explanations effectively without full model access. The trade-off between locality and data dependency is highlighted, where highly localized explanations (as produced by many popular methods) might offer concise interpretations, but are significantly harder to verify. Sufficient data is necessary to observe how well local explanations match global behavior. The findings underscore the need for methods that balance detailed explanations with verifiable data requirements, perhaps incorporating global model properties or alternative explanation strategies that address this data dependency limitation.
High-D Challenges#
The section ‘High-D Challenges’ would likely delve into the difficulties encountered when applying the proposed auditing framework to high-dimensional data. A key challenge is the locality of explanations; in high dimensions, local regions become exponentially small, making it practically impossible to gather enough data points within those regions to accurately assess the fidelity of local explanations. This phenomenon significantly increases the amount of data required for successful auditing and renders the method computationally expensive and potentially infeasible. The analysis might highlight how the curse of dimensionality affects the reliability of verifying locally-accurate explanations against global classifier behavior, making it exceptionally hard to distinguish genuinely trustworthy explanations from fabricated ones. The inherent difficulty of evaluating the accuracy of local models in high-dimensional data, along with the computational demands, are critical aspects to address. The discussion would likely conclude by emphasizing the need for alternative approaches or modifications to the auditing framework when handling high-dimensional datasets, potentially suggesting more global or less computationally intensive validation strategies.
Future Auditing#
Future auditing of local explanations necessitates addressing the limitations of current methods. High dimensionality poses a significant hurdle, requiring exponentially more queries for effective auditing. Focusing on the “locality” of explanations is crucial, as smaller regions make verification far more challenging. Increased transparency from model providers, perhaps through partial model disclosure or verifiable explanation generation techniques, may be necessary for reliable auditing. Further research should explore alternative auditing strategies that move beyond pointwise verification, potentially leveraging ensemble methods or focusing on broader model properties rather than individual predictions. Developing practical metrics for quantifying and evaluating explanation faithfulness is also essential. Ultimately, trustworthy AI requires both robust explanation methods and effective auditing procedures that can adapt to the complexities of high-dimensional data and the inherent challenges of verifying the validity of explanations.
More visual insights#
More on figures
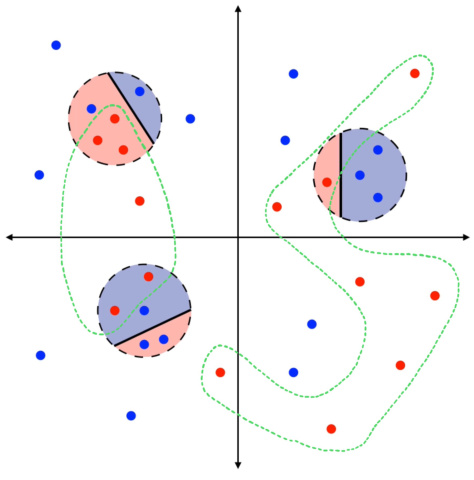
This figure shows two scenarios for auditing local explanations. The left panel (a) shows insufficient data points within each local region to assess whether the local linear classifier accurately approximates the true classifier. In contrast, the right panel (b) shows sufficient data points to enable accurate assessment. This illustrates the relationship between data quantity, local region size, and the ability to audit the fidelity of local explanations.
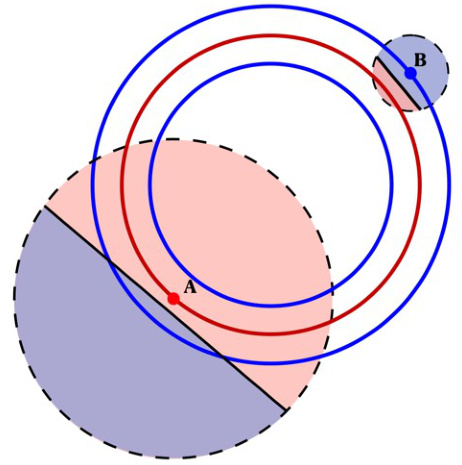
This figure illustrates Theorem 5.1, which shows that for high dimensional data, local linear explanations either have a large loss (meaning that they do not accurately represent the function in the local region), or they have small local mass (meaning that the regions they apply to are very small). The figure shows concentric circles representing datapoints classified into two classes (red and blue). Point A represents an explanation with large local loss because its local linear approximation does not correctly classify many points in the region. Point B represents a small local mass because it only accurately classifies points in a small region. The key takeaway is that high-dimensional settings make verification of explanations based solely on pointwise predictions and explanations very challenging.
Full paper#



















