↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for aligning sequential decision-making agents with human preferences often rely on well-defined reward functions. This is difficult, especially in multi-task scenarios, as it requires substantial human effort and faces challenges in balancing alignment and versatility. Moreover, existing return-conditioned diffusion models often struggle with ensuring consistency between conditions and generated trajectories. This paper addresses these limitations by adopting multi-task preferences as a unified framework.
The proposed method, CAMP, learns preference representations aligned with preference labels, guiding the conditional generation process of diffusion models. It introduces an auxiliary regularization objective to maximize the mutual information between conditions and generated trajectories, effectively improving their alignment with preferences. Experiments demonstrate CAMP’s superior performance in single- and multi-task settings across various benchmarks, showcasing the favorable performance and generalization ability.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the challenge of aligning sequential decision-making agents with human preferences across multiple tasks. This is a significant advancement in offline reinforcement learning, offering a more versatile solution than previous reward-based approaches. The proposed method, with its focus on preference representations and mutual information maximization, opens exciting new avenues for research in both single and multi-task settings.
Visual Insights#
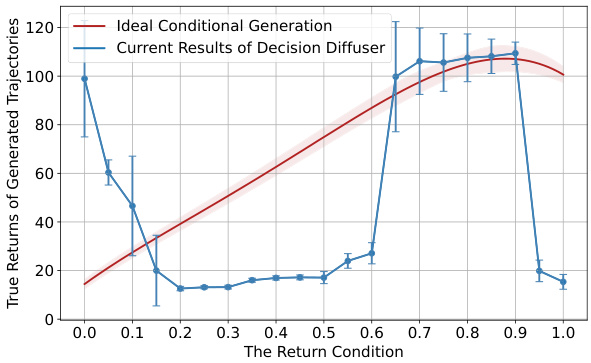
This figure illustrates the shortcomings of existing return-conditioned diffusion models in aligning generated trajectories with the return condition. The Decision Diffuser model’s performance on the hopper-medium-expert task is shown. The blue line with error bars represents the actual true returns of generated trajectories given different return conditions, while the red line shows the ideal relationship – a strong positive correlation between the return condition and the true return of the generated trajectory. The large discrepancy between the blue line and red line highlights the model’s failure to effectively align generated trajectories with the specified return condition.

This table compares the performance of different methods on several D4RL benchmark tasks. The methods include behavior cloning (BC), Implicit Q-learning (IQL), Preference Transformer (PT), Offline Preference-based Reinforcement Learning (OPRL), Offline Preference Optimization via Policy Optimization (OPPO), and the proposed CAMP method. The table shows average performance across different tasks with and without access to the true reward functions. The subscript ◇ denotes baselines using the true reward function. The subscripts and show the performance reported by the original authors and the performance after re-implementation with default settings, respectively. The results highlight the superior performance of CAMP, especially when comparing with preference-based methods.
In-depth insights#
Multi-task Pref Learning#
Multi-task preference learning (MTPL) tackles the challenge of aligning agent behavior with diverse human preferences across multiple tasks. The core difficulty lies in handling the inherent conflict between task-specific optimality and the need for generalization. Traditional reward-based reinforcement learning struggles here, often requiring extensive manual reward engineering for each task. MTPL offers a more versatile solution by directly learning from preference data, which is often easier to obtain than precisely defined reward functions. Key challenges in MTPL include constructing effective preference representations that capture both task identity and relative preference strength, as well as developing algorithms that can effectively utilize these representations to guide the learning process. A promising direction involves representing preferences in a unified embedding space where task-specific optima are well-separated, and similarity between preferences informs generalization. Another crucial aspect is handling inconsistencies inherent in human preferences and developing robust methods for learning from potentially noisy or incomplete preference data. Ultimately, successful MTPL requires a balance between aligning with specific task preferences and maintaining versatile generalization across the multiple tasks.
Diffusion Model Use#
The application of diffusion models in the research paper showcases their versatility in tackling complex sequential decision-making problems. The models are leveraged to generate trajectories, offering a powerful mechanism for planning and policy optimization. A key advantage highlighted is their ability to handle multi-modal action distributions more effectively than other methods, making them especially suitable for tasks with diverse and complex behavior patterns. However, reliance on pre-defined reward functions presents challenges. The paper explores the use of preferences as an alternative, providing more versatile supervision across multiple tasks. This innovation demonstrates the potential of diffusion models to solve problems where reward function engineering presents a major hurdle. The integration of mutual information maximization further enhances the alignment between the model’s generated trajectories and the desired preferences. This technique directly addresses the issue of consistency between conditions and generated outputs, a common weakness in existing classifier-free guidance approaches. Overall, the use of diffusion models within the context of the paper highlights their potential as a powerful tool for addressing complex sequential decision-making problems, particularly in scenarios demanding adaptability and alignment with diverse human preferences.
CAMP Framework#
The CAMP framework, as described in the research paper, presents a novel approach to multi-task preference alignment using a regularized conditional diffusion model. Its core innovation lies in leveraging multi-task preferences, moving beyond traditional reward-based methods that often struggle with the complexities of multiple tasks. The framework learns versatile preference representations that capture both trajectory quality and task-relevance. These representations guide a diffusion model’s trajectory generation process, ensuring alignment with user preferences. A key aspect is the introduction of an auxiliary regularization objective to maximize mutual information between the learned representations and the generated trajectories, thereby improving their alignment. The framework demonstrates effectiveness and generalizability in both single- and multi-task scenarios, highlighting the potential for improved performance in sequential decision-making applications. Future directions could explore extending this to other domains or refining the mutual information regularization strategy for even stronger alignment.
MI Regularization#
The heading ‘MI Regularization’ suggests a method to enhance the alignment between generated outputs and their conditioning inputs in a model. Mutual Information (MI), a measure of the statistical dependence between two variables, is used to quantify this alignment. A regularization term based on MI is added to the model’s loss function. Maximizing this term encourages the model to generate outputs that are strongly correlated with the provided conditions. This is crucial in scenarios where the model’s condition may be a complex representation, like preference embeddings, for example, and directly maximizing the model’s likelihood might fail to achieve proper alignment. By regularizing with MI, the model learns a better mapping between condition space and generated data space, leading to improved performance and more consistent behavior. The effectiveness of this method heavily depends on the quality of the conditional input representation, and ensuring sufficient information is encoded in the conditions for the regularization to be successful. The computational cost of calculating and optimizing the MI term should also be considered.
Future Directions#
Future research directions for this work could explore several promising avenues. Improving the efficiency of the multi-step denoising process in diffusion models is crucial for real-time applications. Investigating alternative sampling methods or approximation techniques could significantly reduce computational costs. Expanding the framework to incorporate more complex preference structures beyond pairwise comparisons, such as incorporating uncertainty or handling ordinal preferences, would enhance its versatility. Further investigation into the impact of different representation space dimensions on performance, particularly in high-dimensional tasks, is needed. Thorough exploration of the generalization capabilities to novel, unseen tasks, and perhaps adapting transfer learning techniques, could demonstrate robustness and expand application domains. Finally, integrating the approach with other reinforcement learning methods or exploring its applicability to different task types, like continuous control tasks, would establish its broader significance and potential.
More visual insights#
More on figures
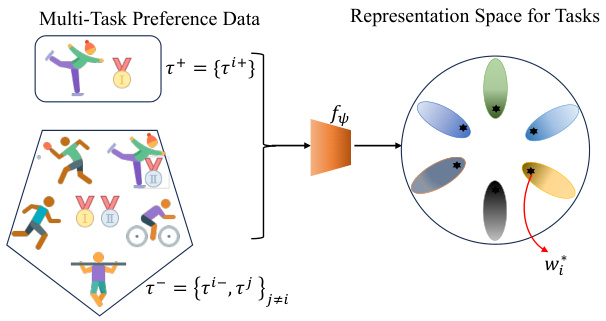
This figure illustrates how the model learns to represent trajectories in a multi-task setting. The input is multi-task preference data, which includes preferred (τ+) and less preferred (τ-) trajectories from multiple tasks. The encoder, fψ, maps these trajectories to a representation space. Importantly, the model aims to separate preferred trajectories within each task and distinguish trajectories across different tasks. The ‘optimal’ representations, wi, represent the best trajectories within each task and are also learned.

This figure illustrates the three main steps of the proposed method, CAMP. First, preference representations (w) are learned using a trajectory encoder (fψ) and a triplet loss, differentiating between preferred and less preferred trajectories. These representations also include an ‘optimal’ representation (w*) for each task. Second, a mutual information regularized diffusion model is trained to align generated trajectories (τ0) with the learned representations (w). This is accomplished by maximizing the mutual information between the generated trajectories and the conditions. Third, during inference, the optimal representation (w*) for a specific task is used as a condition for the diffusion model to generate trajectories aligned with that task’s preferences.

This figure compares the average success rates of different methods on the MT-10 benchmark using two different datasets: near-optimal and sub-optimal. It shows the performance of both reward-based (orange bars) and preference-based (green bars) methods. The results indicate that the proposed method (Ours) outperforms many others, particularly in the sub-optimal dataset setting.
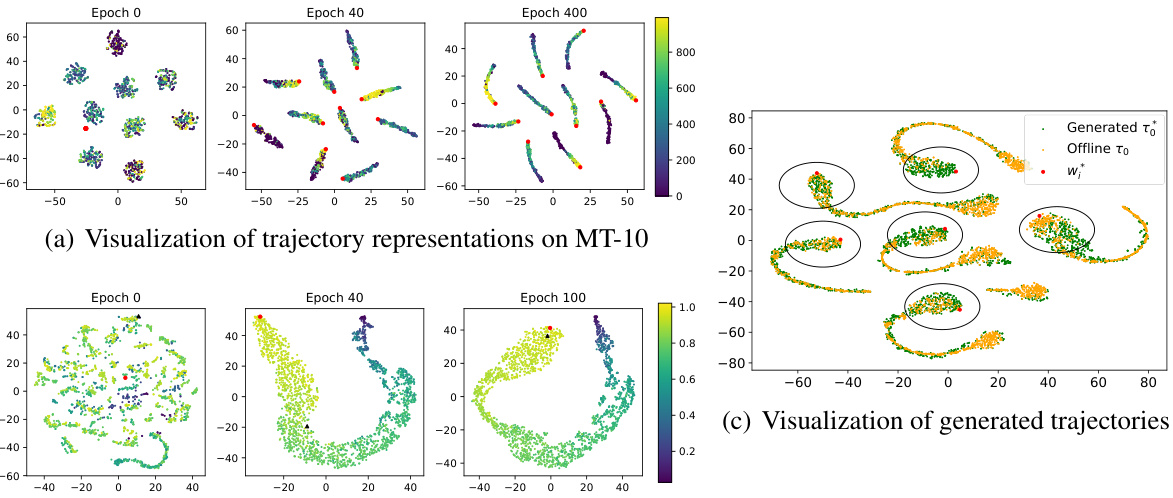
The figure demonstrates the visualization of trajectory representations and generated trajectories. The left panel shows how the learned representation (fψ) effectively separates trajectories with different returns and from different tasks, aligning the optimal representations (w*) with high-return trajectories. The right panel showcases how the generated trajectories, guided by w*, closely align with the optimal trajectories in the offline dataset. This visualization supports the effectiveness of the proposed method in learning meaningful representations and generating aligned trajectories.

This figure illustrates the overall framework of the proposed method, CAMP. It consists of three main stages: 1) Learning preference representations by using a triplet loss and KL divergence to differentiate trajectories with different preferences. 2) Augmenting the diffusion model with mutual information regularization to improve alignment between generated trajectories and preference representations. 3) Generating trajectories conditioned on optimal preference representations to align with desired preferences during inference.

This figure shows ten different tasks from the MetaWorld MT-10 benchmark. Each task involves a Sawyer robot manipulating various objects in a simulated environment. The tasks illustrate the diversity and complexity of the multi-task setting; the goal is to train a single agent capable of performing all of these different manipulation tasks.
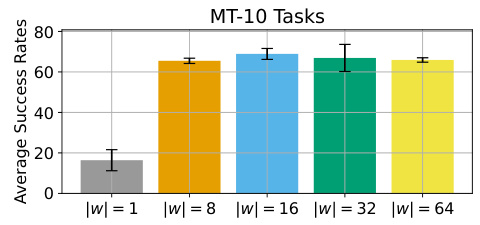
This ablation study investigates the impact of the dimension of the preference representation (w) on the performance of the proposed method. The study varies the dimension of w (|w|) and evaluates its effect on the average success rates across multiple tasks in the MT-10 benchmark. The results show that an intermediate dimension of w performs best, while both low-dimensional and high-dimensional representations result in performance degradation.
More on tables
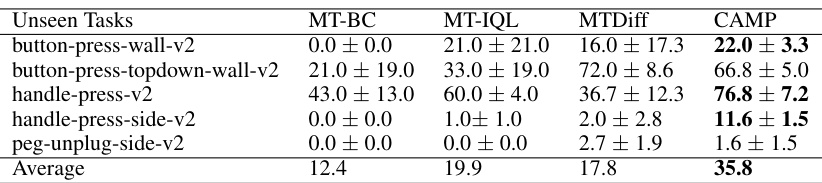
This table presents the generalization performance of the proposed CAMP method and several baseline methods on five unseen tasks. The unseen tasks are not included in the training data for the models. The table shows the average success rate for each method on each unseen task, demonstrating that CAMP achieves significantly better performance than the baseline methods in this generalization setting.

This table presents the ablation study results focusing on the impact of the mutual information (MI) regularization term. It compares the performance of the model with and without the MI regularization term across various tasks (MT-10, walker2d-medium-expert, walker2d-medium-replay, hopper-medium-expert, hopper-medium-replay, halfcheetah-medium-expert). The results demonstrate the significance of the MI regularization term in improving the model’s performance by enhancing alignment between the representation conditions and the generated trajectories.
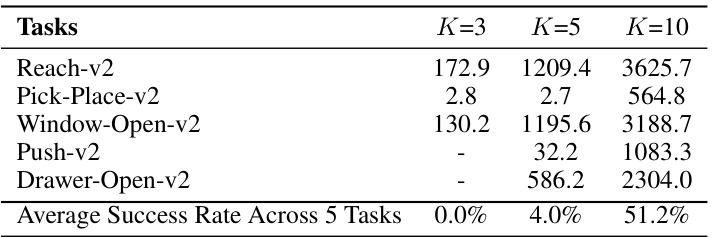
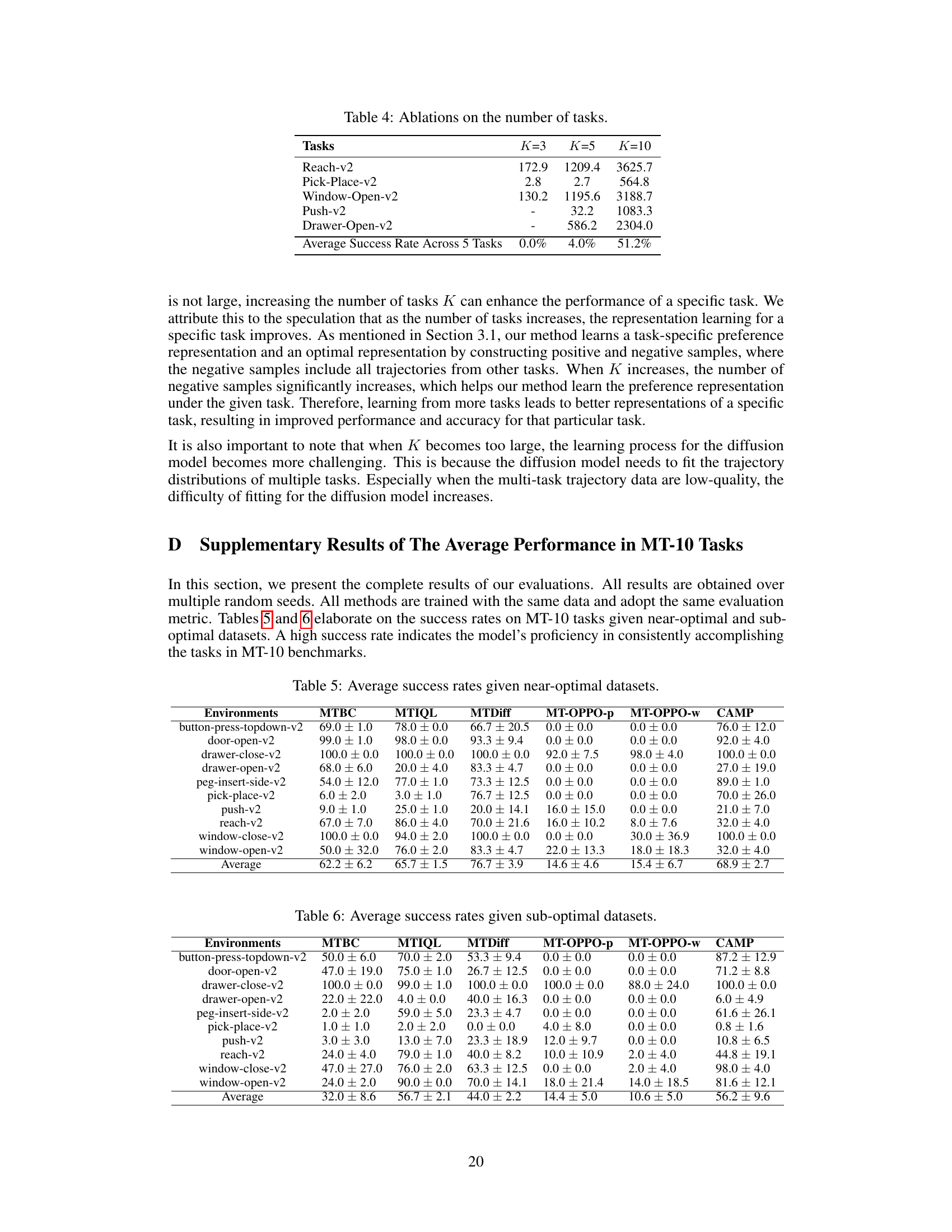
This table presents the ablation study results on varying the number of tasks (K) used in the experiments. It shows the average success rates across five MetaWorld tasks for three different values of K: 3, 5, and 10. The results demonstrate the impact of the number of tasks on the overall performance of the model, showing improvements with a larger number of tasks (and thus a greater number of training samples).

This table presents the average success rates achieved by different methods (MTBC, MTIQL, MTDiff, MT-OPPO-p, MT-OPPO-w, and CAMP) across various tasks in the MetaWorld MT-10 benchmark. The results are based on sub-optimal datasets, meaning that only a portion of the training data is used. Each row represents a specific task, and the values indicate the average success rate with the standard deviation. This shows the performance of each algorithm when provided with limited training data.
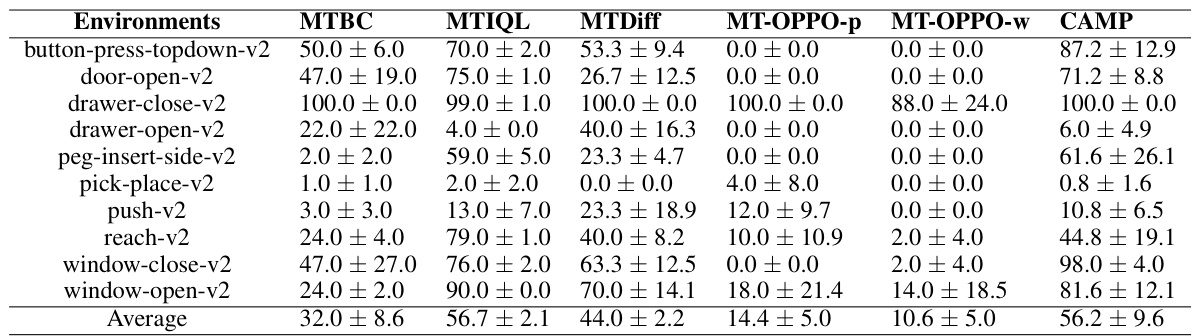
This table presents the average success rates for various multi-task learning methods on the MetaWorld MT-10 benchmark dataset. The dataset used is described as ‘sub-optimal’, meaning it contains a limited amount of training data. The table compares the performance of several methods, including MTBC (Multi-task Behavior Cloning), MTIQL (Multi-task Implicit Q-Learning), MTDiff (Multi-task Diffusion), MT-OPPO-p and MT-OPPO-w (modified versions of OPPO for multi-task settings), and CAMP (the authors’ proposed method). The success rate is the primary evaluation metric, indicating the percentage of successfully completed tasks. The results show the average success rate across ten different tasks. Error bars are provided to indicate the variability in performance.

This table compares the performance of the proposed CAMP method against several baselines on D4RL benchmarks. It shows the average success rates for different tasks and datasets (medium, medium-replay, and medium-expert). The baselines include behavior cloning (BC), Implicit Q-learning (IQL), Preference Transformer (PT), Offline Preference-based Reinforcement Learning (OPRL), and Offline Preference-based Policy Optimization (OPPO). The table highlights CAMP’s improved performance, especially compared to preference-based methods in some tasks.
Full paper#