↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current video generation and recognition methods are typically tackled separately, leading to suboptimal performance and difficulties in scenarios with incomplete data. Prior work uses pre-trained models, neglecting the potential synergy of jointly learning both tasks within a unified framework. This often involves trade-offs between generation and recognition capabilities.
GenRec proposes a novel unified framework, integrating video generation and recognition via a random-frame conditioning process during training. This allows for the learning of generalized spatial-temporal representations and addresses the limitations of previous methods. Results show GenRec achieves state-of-the-art or comparable performance on various benchmarks for both generation and recognition tasks, demonstrating robustness even under limited frame conditions. The novel approach and impressive performance highlight its significant contribution to the field.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel unified framework, GenRec, that successfully integrates video generation and recognition tasks within a single diffusion model. This addresses a significant challenge in the field by overcoming the limitations of separate training paradigms. The findings demonstrate the efficacy of GenRec for both tasks, particularly in scenarios with limited information, opening avenues for applications in various video understanding applications. The robustness and improved performance of GenRec highlight its potential for future research in various downstream video tasks.
Visual Insights#

This figure compares three different approaches for video processing: (a) traditional video classification using full videos, (b) diffusion-based video generation using noisy videos, and (c) the proposed GenRec method. GenRec combines both tasks by processing masked and noisy video frames. The masking function and noise sampling are employed to learn generalized spatial-temporal representations.
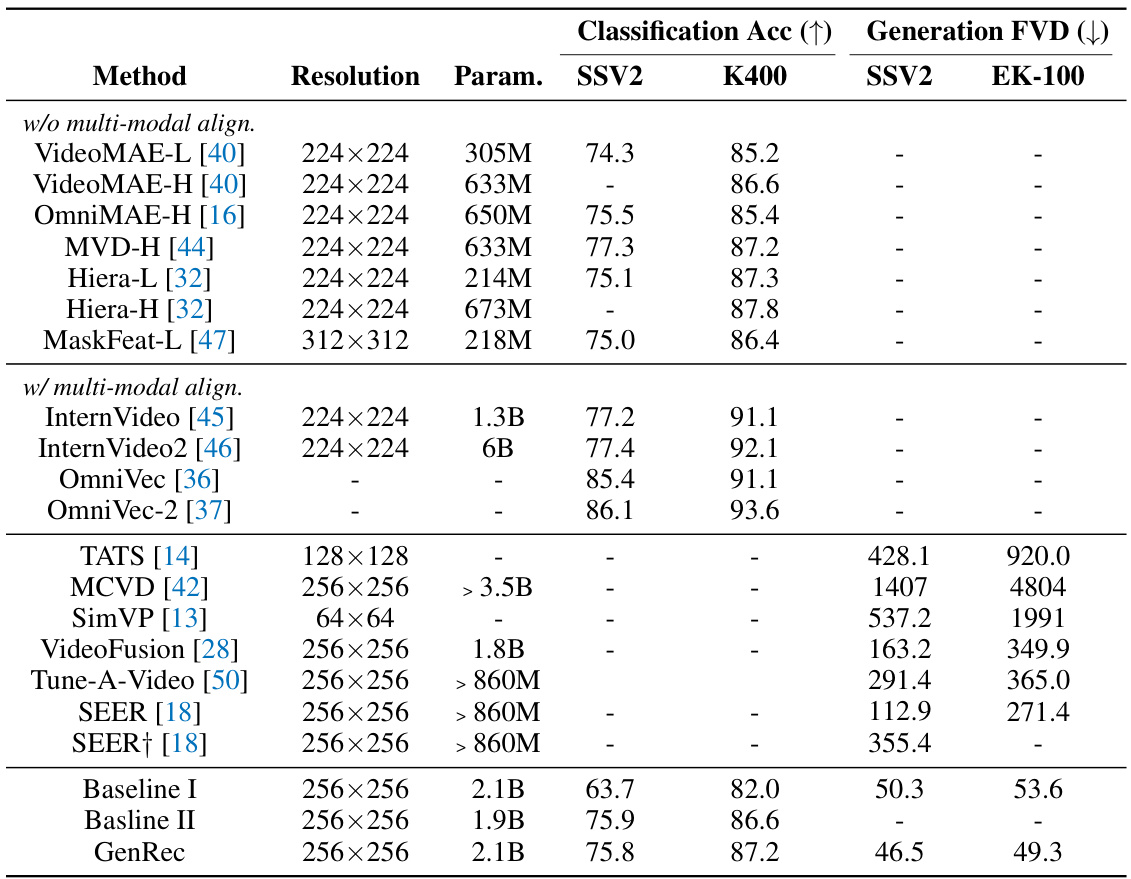
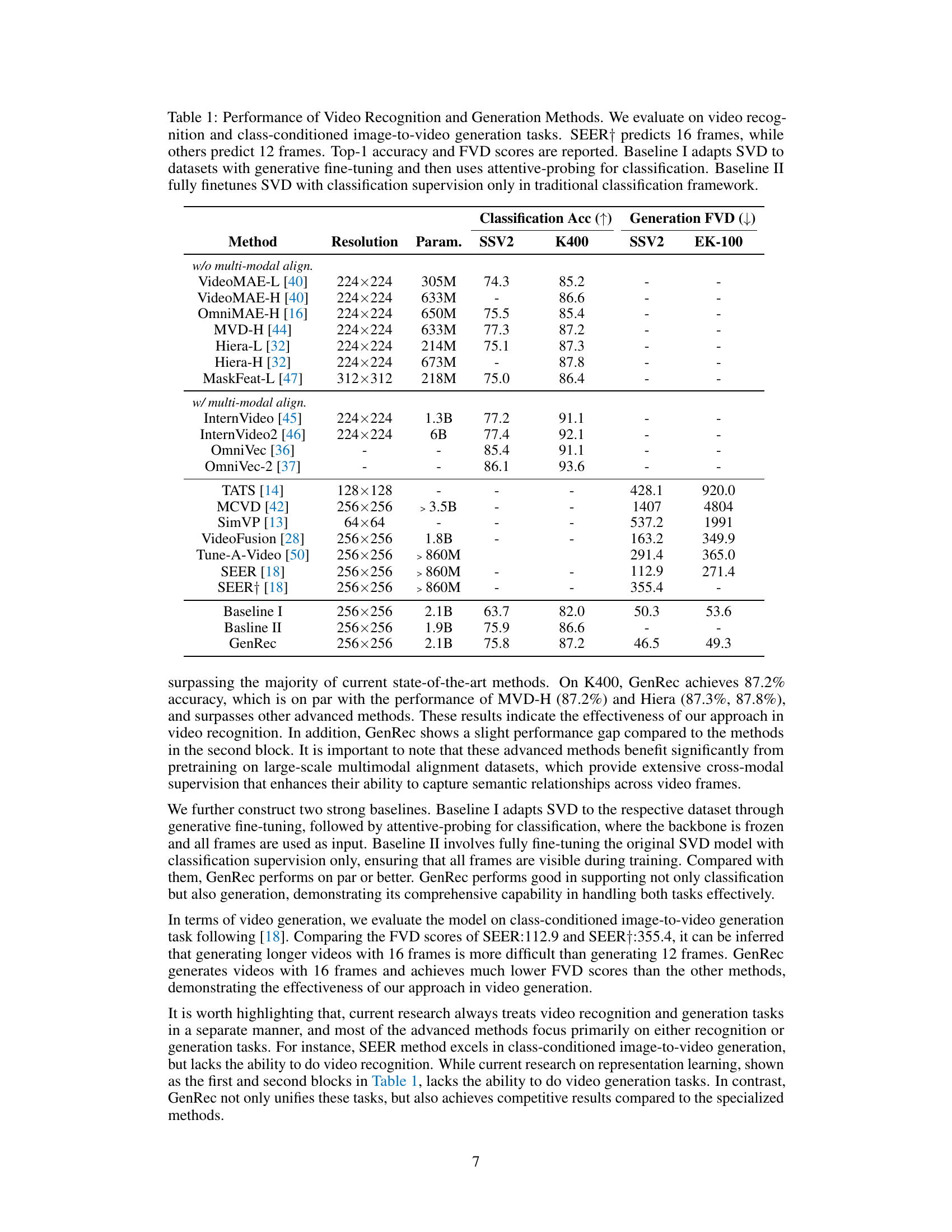
This table compares the performance of various video recognition and generation methods, including the proposed GenRec model. It shows the top-1 accuracy for video recognition on four datasets (SSV2, K400, SSV2, EK-100) and Fréchet Video Distance (FVD) scores for class-conditioned image-to-video generation on two datasets (SSV2, EK-100). Two baselines are included: one using generative fine-tuning with attentive-probing, and the other fine-tuning with traditional classification supervision. The table highlights GenRec’s competitive performance in both tasks and its advantage over baselines.
In-depth insights#
GenRec Framework#
The GenRec framework presents a novel approach to unifying video generation and recognition, leveraging the strengths of diffusion models. Its core innovation lies in a random-frame conditioning process during training, enabling the model to learn generalized spatial-temporal representations suitable for both tasks. This contrasts with traditional methods which treat generation and recognition as distinct processes. Joint optimization allows GenRec to excel in scenarios with limited visual information, demonstrating robustness and achieving competitive performance in both generation (lower FVD scores) and recognition (higher accuracy). The framework cleverly bridges the gap between distinct training paradigms for these tasks by using a masking strategy that ‘interpolates’ masked frames, allowing it to maintain strong generative capabilities while benefiting recognition with the capability to handle partial or missing frames. This unifying approach significantly advances the field by demonstrating the potential benefits of combining generative and discriminative learning within a single model.
Unified Training#
Unified training, in the context of video generation and recognition, aims to simultaneously optimize both tasks within a single framework. This approach contrasts with traditional methods that train separate models, leading to potential sub-optimality. A unified training strategy leverages shared representations learned during the generative process to improve recognition performance. For instance, a diffusion model might learn powerful spatial-temporal priors while generating videos. These same priors can then be exploited to enhance a video classifier’s ability to extract meaningful features. Key challenges in unified training include reconciling the differences in training paradigms between generative and discriminative models. Generative models typically work with noisy inputs while discriminative models rely on clean data. The success of unified training depends heavily on the design of the architecture and the effectiveness of the loss function in balancing both objectives. Successful implementations often incorporate creative techniques, such as conditional masking or random frame conditioning, to bridge the gap between the different task requirements.
Robustness Tests#
A dedicated ‘Robustness Tests’ section in a research paper would systematically probe the model’s resilience against various challenges. It would likely involve evaluating performance under conditions of noisy or incomplete data, exploring sensitivity to hyperparameter variations, and assessing the model’s behavior when faced with adversarial examples or data distribution shifts. Quantitative metrics such as accuracy, precision, recall, F1-score, and potentially novel metrics specific to the application domain should be reported. The results would critically assess the model’s generalizability and reliability beyond the idealized training environment. A robust model should exhibit consistent performance across these varied conditions, showcasing its readiness for real-world deployment where perfect data is unrealistic. The analysis should delve into why the model performs as it does under different stress tests, uncovering potential weaknesses and areas for future improvement. Visualizations and detailed descriptions of the test methodologies would strengthen the credibility and impact of the findings.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a video generation and recognition model, this would involve selectively disabling or removing parts, such as the masking function, the classifier, or different UNet layers, to observe the impact on both the generation (e.g., FVD scores) and recognition (e.g., accuracy) performance. A well-designed ablation study isolates the effects of specific design choices, verifying their necessity and demonstrating the model’s robustness. The results from such a study would likely highlight which components are crucial for high-quality video generation and accurate recognition, as well as which aspects are redundant or detrimental. By meticulously analyzing changes in performance upon removing components, the authors can provide strong evidence supporting their design decisions and offer insights into the model’s inner workings. Crucially, ablation studies help determine whether a complex model’s success is due to synergistic interactions or simply the sum of its parts. For instance, demonstrating that removing generation training negatively affects recognition performance suggests a beneficial interaction between the two tasks, supporting the unified model’s efficacy. The ablation study’s impact on the overall understanding of the paper lies in its ability to validate design claims and pinpoint the critical architectural elements which contribute most to the model’s performance.
Future Work#
The paper’s “Future Work” section would ideally delve into several promising directions. Addressing the limitations of relying on a pretrained video diffusion model, perhaps through model distillation or exploring more efficient training strategies, is crucial. Exploring the integration of GenRec with other modalities, such as audio or text, to create even more comprehensive video understanding systems would be highly beneficial. Investigating the model’s performance under more diverse and challenging conditions, including variations in video quality, frame rates, and lighting, would strengthen its robustness and real-world applicability. Furthermore, a deeper exploration of the interplay between generation and recognition, potentially through novel joint optimization techniques, could unlock greater synergy between the two tasks and lead to superior performance in both areas. Finally, examining the broader societal implications of GenRec, particularly regarding responsible use and mitigating potential biases, is essential for responsible AI development.
More visual insights#
More on figures

This figure illustrates the GenRec model’s architecture and training process. The input video is first encoded into a latent representation. Then, a diffusion process introduces noise, and a random mask is applied to a subset of the latent frames. The noisy and masked latent representations are concatenated and fed into a spatial-temporal UNet, which learns to reconstruct the original latent representation and perform video classification. The reconstructed latent is decoded to generate the final video. This unified framework enables joint optimization of video generation and recognition.

This figure illustrates the pipeline of GenRec, a unified framework for video generation and recognition. It shows how an input video is first encoded into a latent representation. Then, a random mask is applied to a subset of latent frames, and Gaussian noise is added to create a noisy latent representation. These representations are concatenated and fed into a Spatial-Temporal UNet for training. The UNet learns to reconstruct the original latent representation from the noisy and masked inputs, performing video generation, and simultaneously learns to classify the video content.

This figure illustrates the GenRec framework’s architecture. An input video is encoded into a latent representation. This latent representation is then noised and randomly masked. Both the noisy and masked representations are fed into a Spatial-Temporal U-Net, which simultaneously learns to reconstruct the original video and perform video classification. The reconstructed latent representation is then decoded to produce the generated video. This unified training approach allows GenRec to excel in both video generation and recognition tasks.

This figure shows four examples of video generation using only the first and last frames as input. The top row of each example shows the ground truth video sequence. The bottom row shows the video generated by the GenRec model. The red boxes highlight that the model successfully generated the missing frames between the given first and last frame, demonstrating its ability to interpolate and generate temporally coherent video content.

This figure compares the video generation results of the proposed GenRec method with the state-of-the-art method SEER for three different actions: Pushing something from left to right, Covering something with something, and Dropping something in front of something. For each action, the ground truth video (GT) is shown along with the generated videos from SEER and GenRec. The comparison highlights the visual quality and temporal consistency of the generated videos from each method.
More on tables

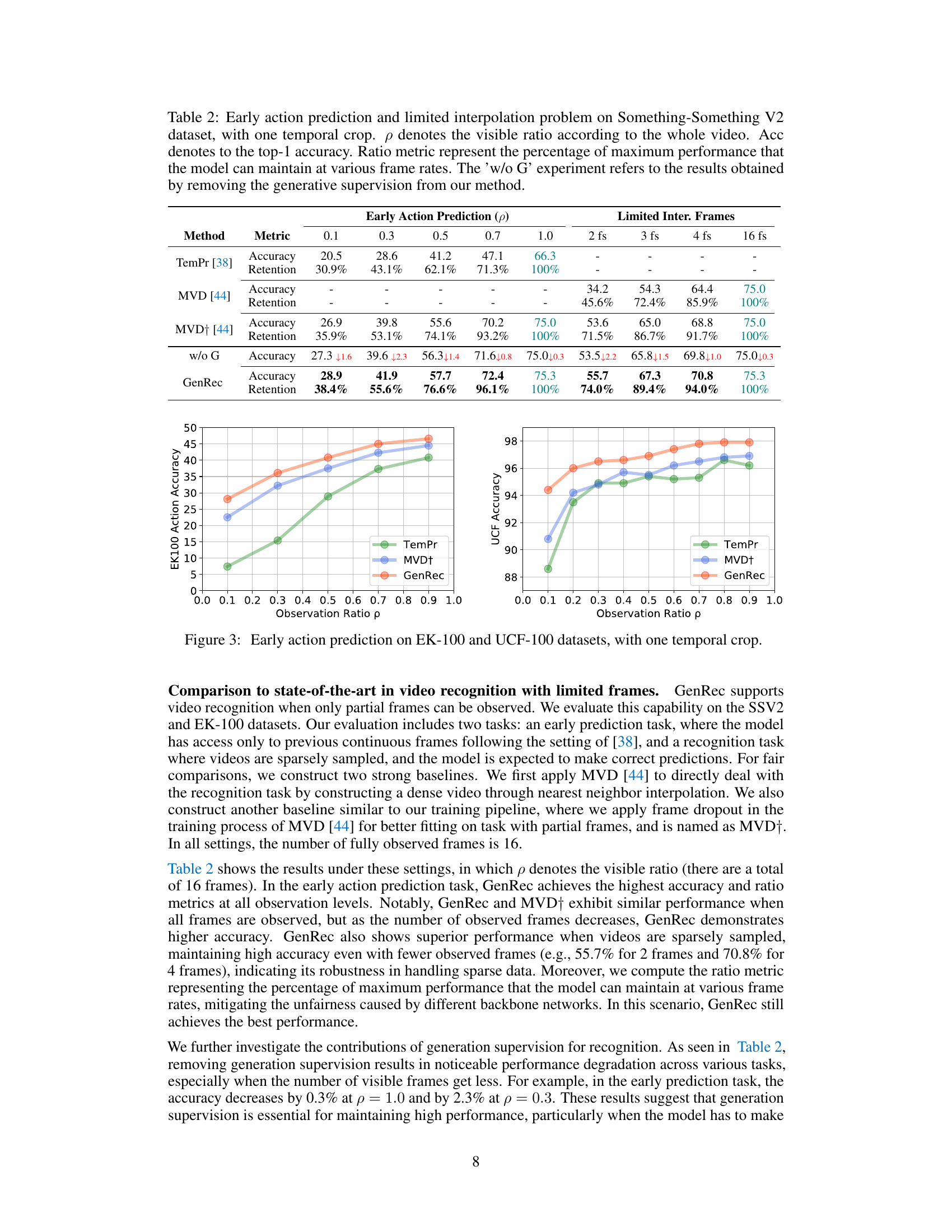
This table presents a quantitative comparison of the performance of the GenRec model on video recognition and generation tasks with limited frames. The ‘Early Frames’ section shows accuracy (Acc↑) and Fréchet Video Distance (FVD↓) scores when only the initial frames of a video are visible, while the ‘Limited Inter. Frames’ section provides the same metrics when only a limited number of frames are available. The results highlight the relationship between the model’s ability to generate videos and its performance on recognizing actions, indicating potential synergy between generation and recognition.

This table presents a comparison of various video recognition and generation methods. It shows the top-1 accuracy for video recognition on four datasets (SSV2, K400, SSV2, EK-100) and the Fréchet Video Distance (FVD) for image-to-video generation. Two baselines are included for comparison: Baseline I uses generative fine-tuning and attentive-probing; Baseline II uses full fine-tuning with classification supervision. The table highlights GenRec’s performance relative to state-of-the-art models.
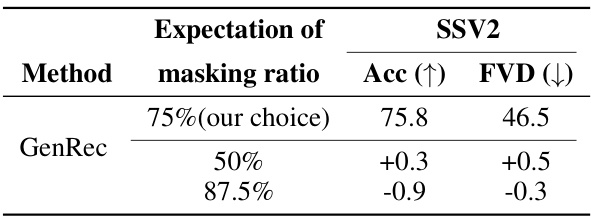
This table compares the performance of various video recognition and generation methods. It shows the top-1 accuracy for video recognition on four datasets (SSV2, K400, SSV2, EK-100) and the Fréchet Video Distance (FVD) scores for class-conditioned image-to-video generation on two datasets (SSV2 and EK-100). Two baseline methods are included for comparison, showing the effect of different training strategies on the overall performance.

This table compares the performance of various video recognition and generation methods. It shows classification accuracy (top-1 accuracy) on four datasets (SSV2, K400, SSV2, EK-100) and Fréchet Video Distance (FVD) scores for class-conditioned image-to-video generation. Two baselines are included: one using generative fine-tuning with attentive probing and the other using full fine-tuning with classification supervision. The table highlights GenRec’s competitive performance in both tasks.

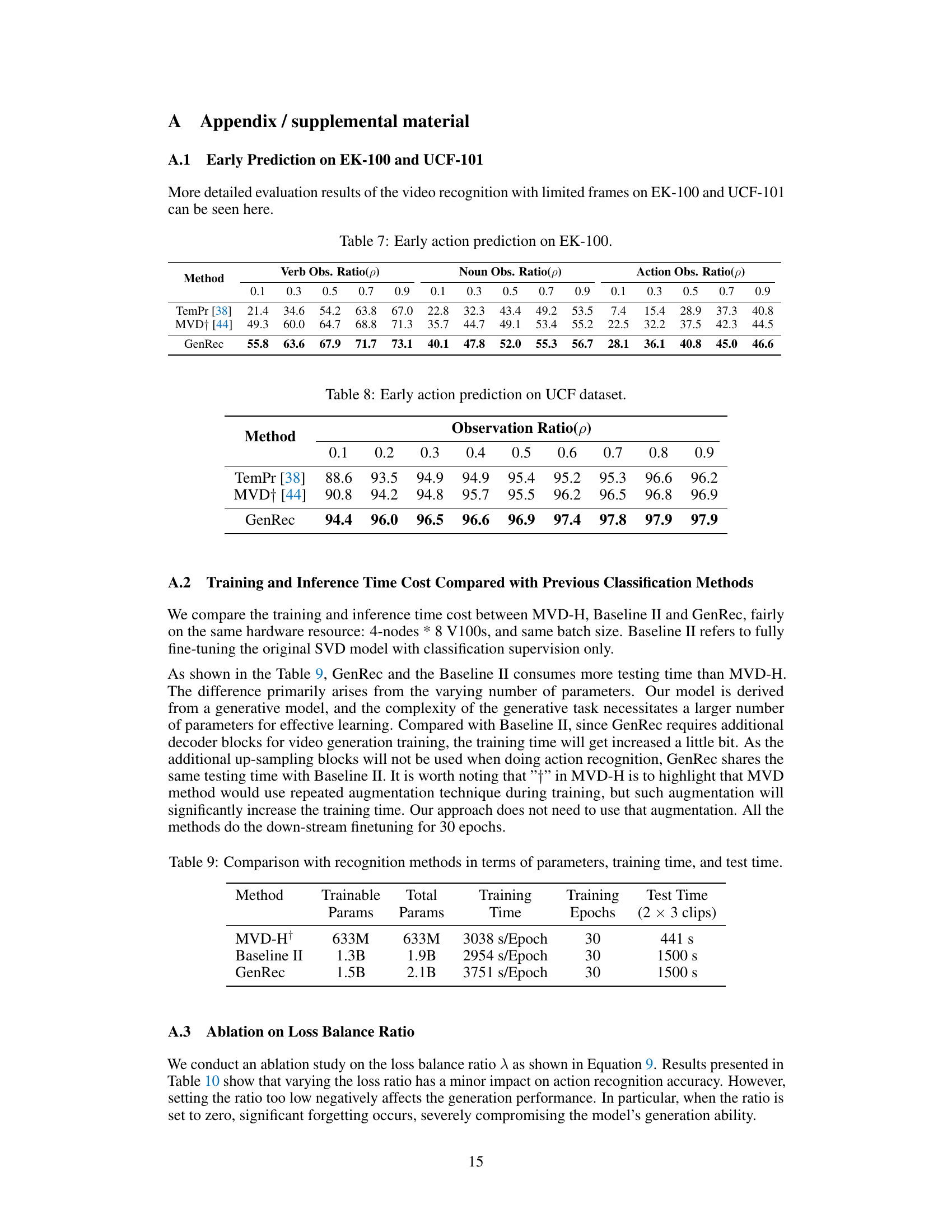
This table presents a detailed breakdown of early action prediction results on the EK-100 dataset. It shows the accuracy (in percentage) achieved by three different methods (TemPr, MVD+, and GenRec) at varying observation ratios (p) representing the proportion of the video visible. The results are further categorized into Verb Obs., Noun Obs., and Action Obs., reflecting different aspects of action recognition.

This table presents a comparison of various video recognition and generation methods. It includes results for top-1 accuracy on several datasets (SSV2, K400, EK-100) and Fréchet Video Distance (FVD) scores for image-to-video generation. Two baselines are included, representing different approaches to adapting the Stable Video Diffusion (SVD) model for these tasks. The table highlights GenRec’s performance relative to state-of-the-art methods, demonstrating its ability to achieve competitive results on both video recognition and generation.

This table compares the performance of various video recognition and generation methods. It includes methods that don’t use multi-modal alignment and those that do, highlighting the impact of this technique. The table shows top-1 accuracy for video recognition on four datasets (SSV2, K400, SSV2, EK-100), and Fréchet Video Distance (FVD) scores for class-conditioned image-to-video generation. Baselines are included to demonstrate the improvement achieved by the GenRec method. The number of predicted frames (12 or 16) is noted for each method.

This table compares the performance of various video recognition and generation methods. It shows the top-1 accuracy for video recognition on four datasets (SSV2, K400, SSV2, EK-100) and the Fréchet Video Distance (FVD) scores for class-conditioned image-to-video generation on two datasets (SSV2, EK-100). Two baselines are included for comparison: Baseline I uses generative pre-training and attentive probing for classification, while Baseline II performs full fine-tuning for classification only. The table highlights GenRec’s performance relative to these baselines and state-of-the-art methods.

This table compares the performance of various video recognition and generation methods. It shows top-1 accuracy for video recognition on four datasets (SSV2, K400, SSV2, EK-100) and Fréchet Video Distance (FVD) scores for class-conditioned image-to-video generation on two datasets (SSV2 and EK-100). Two baselines are included: Baseline I uses a generative pre-training approach with attentive probing for classification; Baseline II fully fine-tunes a video diffusion model for classification. The table highlights GenRec’s competitive performance compared to state-of-the-art methods.
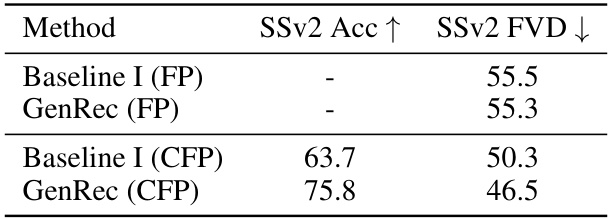
This table compares the performance of various video recognition and generation methods. It shows the top-1 accuracy for video recognition on four datasets (SSV2, K400, SSV2, EK-100) and Fréchet Video Distance (FVD) scores for class-conditioned image-to-video generation on two datasets (SSV2, EK-100). Two baseline methods are included: one using generative fine-tuning and attentive-probing, and another fully fine-tuning a standard video diffusion model for classification. The table highlights GenRec’s performance relative to these baselines and other state-of-the-art methods.
Full paper#