↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large foundation models offer great potential but also security risks. This paper explores the vulnerability of the Segment Anything Model (SAM) and its fine-tuned versions. Existing transfer-based attacks require knowledge about the target model or datasets, which is often unavailable due to privacy concerns. This limits their practical use in real-world security assessments. The lack of generalizable and readily deployable methods for evaluating the security of these models poses a significant challenge.
To tackle this, the authors propose UMI-GRAT, a novel adversarial attack. UMI-GRAT uses meta-initialization to identify inherent vulnerabilities in the SAM and employs a gradient robust loss function to improve its effectiveness against fine-tuned models. The proposed method effectively attacks various downstream models fine-tuned from SAM, showcasing its powerful transferability and practicality, even without accessing downstream tasks or datasets. This significantly advances the state-of-the-art in transfer-based adversarial attacks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals vulnerabilities in widely used foundational models like Segment Anything Model (SAM). This has significant implications for security and privacy, especially concerning downstream applications built using these models. The proposed attack method, UMI-GRAT, offers a novel approach to adversarial attacks, opening new avenues for research into robust defenses and more secure model development. The findings underscore the need for increased caution when employing open-source foundation models and for robust model security measures.
Visual Insights#
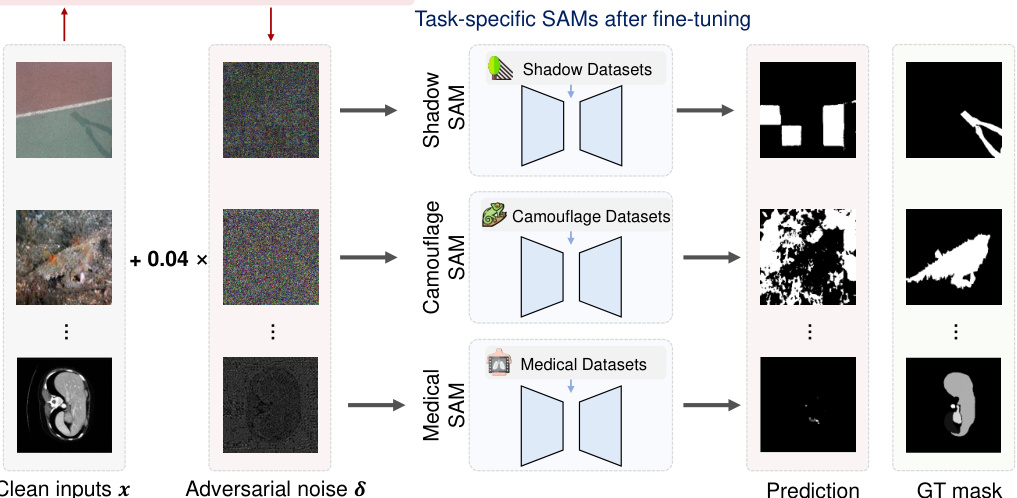
This figure illustrates the UMI-GRAT (Universal Meta-Initialized and Gradient Robust Adversarial Attack) method. It shows how imperceptible adversarial perturbations, generated only using information from the open-source SAM (Segment Anything Model), can mislead various downstream models fine-tuned on different tasks (medical, shadow, camouflage image segmentation). The attack’s effectiveness comes from the UMI algorithm, which extracts the inherent vulnerabilities in the foundation model, and the gradient robust loss, which enhances robustness against gradient-based noise and improves transferability. This showcases the risk of using open-sourced models without considering potential adversarial attacks.

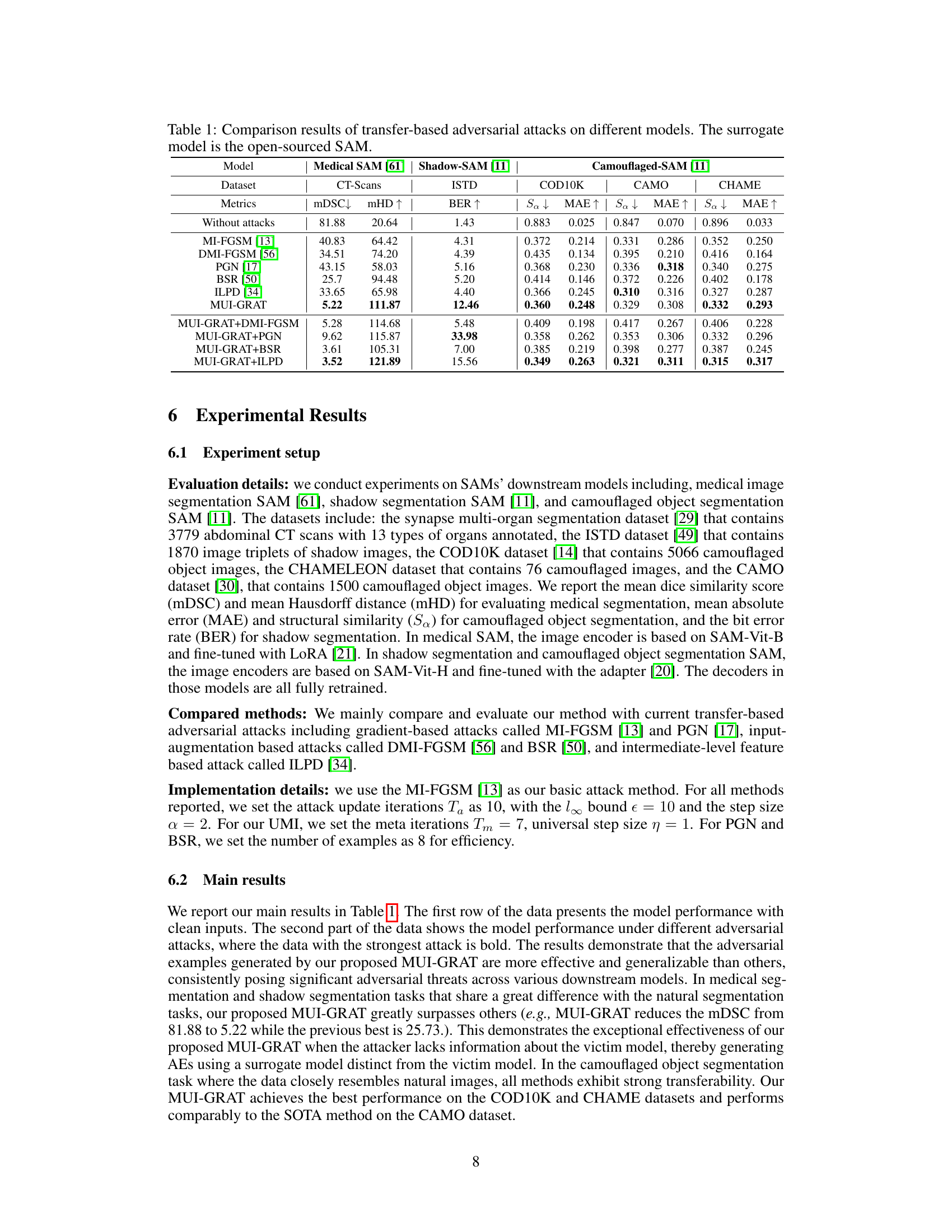
This table compares the performance of different transfer-based adversarial attacks on various downstream models fine-tuned from the Segment Anything Model (SAM). The attacks leverage only information from the open-sourced SAM, without access to the downstream task datasets. Metrics such as mDSC, mHD, BER, Sa, and MAE are used to evaluate the effectiveness of each attack on different models and datasets (Medical SAM, Shadow-SAM, Camouflaged-SAM). The table showcases the significant impact of the proposed UMI-GRAT attack in comparison to existing methods.
In-depth insights#
UMI-GRAT: A New Attack#
UMI-GRAT, presented as a novel attack, likely leverages universal meta-initialization (UMI) to identify inherent vulnerabilities within foundational models like Segment Anything Model (SAM). This is combined with a gradient robust loss to create adversarial examples (AEs) that effectively transfer to various downstream models fine-tuned from SAM. The approach is particularly noteworthy because it doesn’t require access to downstream task datasets; instead, it exploits the foundational model’s structure. The effectiveness likely hinges on the UMI’s ability to extract universal vulnerabilities and the gradient robust loss’s ability to overcome the gradient disparity between the foundational model and its downstream variants, enhancing transferability. UMI-GRAT’s success highlights potential security risks of utilizing open-source foundational models for downstream tasks without adequate safeguards. The attack’s effectiveness and ease of implementation underscore the need for robust defense mechanisms against this type of transfer-based adversarial attack.
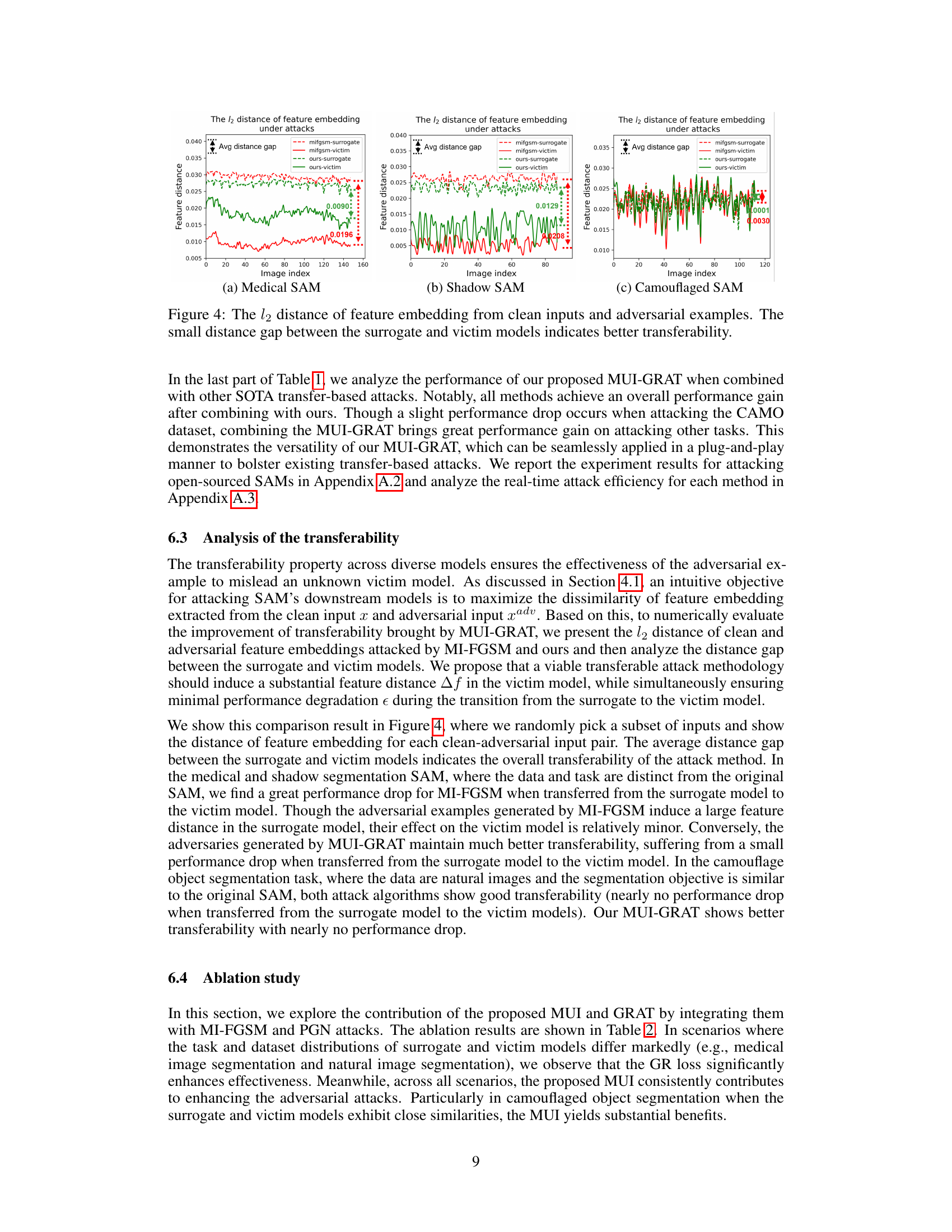
Transferability Enhanced#
Enhancing the transferability of adversarial attacks is crucial for their effectiveness against unseen models. A successful approach would likely involve understanding and mitigating the factors that hinder transferability, such as differences in model architectures, training datasets, and optimization objectives. Methods might focus on generating more robust adversarial examples that are less susceptible to these variations, possibly through techniques like data augmentation or adversarial training. Another strategy might be to focus on transferable features rather than pixel-level perturbations, targeting high-level representations that are more consistent across different models. The ultimate goal is to create attacks that are effective not just against specific models, but against a broader class of models, maximizing their practical impact and minimizing the need for model-specific adaptation.
Gradient Robust Loss#
The concept of a gradient robust loss function is crucial in the context of adversarial attacks against machine learning models. Standard gradient-based training methods can be highly susceptible to adversarial examples, small perturbations added to legitimate inputs that cause misclassification. A gradient robust loss aims to mitigate this vulnerability by incorporating mechanisms that account for the inherent uncertainty in the gradient calculations. This robustness is particularly important when dealing with transfer-based attacks, where the attacker doesn’t have access to the specific victim model but uses a surrogate model for generating adversarial examples. The gradient of the surrogate model can differ significantly from the victim model’s gradient, hindering the transferability of adversarial examples. The paper proposes a method that explicitly addresses this issue through a carefully designed loss function to enhance the effectiveness of generated adversarial examples (AEs) against the target models despite these gradient discrepancies, improving the transferability of the attack strategy.
SAM Vulnerability#
The Segment Anything Model (SAM) presents a unique vulnerability due to its open-source nature and widespread adoption. While SAM’s generalizability is beneficial for various downstream tasks, this accessibility also poses a significant security risk. Adversarial attacks, leveraging even minimal information from the open-sourced model, can effectively mislead models fine-tuned on SAM for specific tasks. This transferability of attacks across datasets highlights a crucial vulnerability. The lack of access to the downstream model’s training data or specific task makes it difficult to mitigate such attacks effectively. This emphasizes the need for robust defense mechanisms and further research in understanding SAM’s inherent vulnerabilities and enhancing its resilience against malicious exploitation.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the UMI-GRAT framework to a broader range of foundation models beyond SAM is crucial, evaluating its effectiveness and transferability across diverse architectures and downstream tasks. Investigating the robustness of UMI-GRAT against different defense mechanisms employed by downstream models would enhance its practical relevance. A deeper theoretical analysis into the relationship between the intrinsic vulnerabilities of foundation models and the transferability of adversarial attacks is warranted. Furthermore, exploring new loss functions or optimization strategies to further improve the robustness and efficiency of UMI-GRAT should be prioritized. Finally, research should focus on developing effective defense mechanisms against UMI-GRAT and similar transferable attacks, possibly incorporating techniques from robust optimization or adversarial training to enhance the security of fine-tuned downstream models.
More visual insights#
More on figures
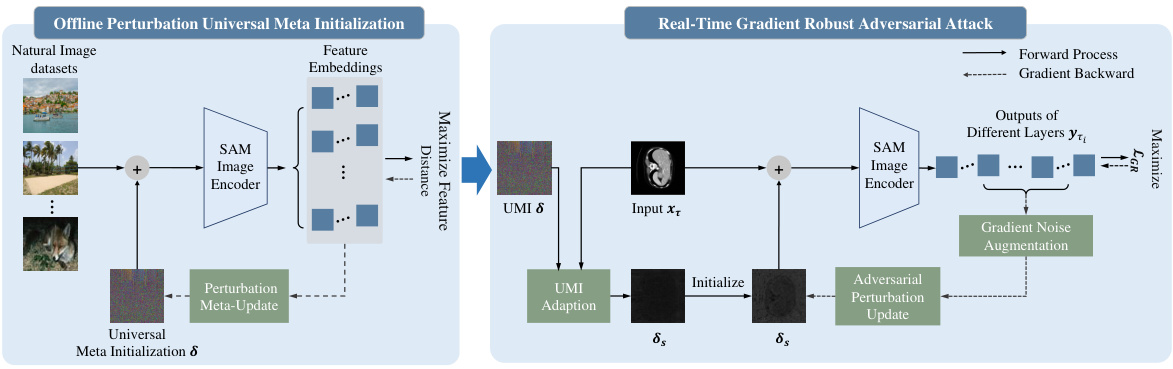
This figure illustrates the two-stage process of the proposed UMI-GRAT method. The first stage involves an offline learning process for universal meta-initialization (UMI). This process aims to extract the intrinsic vulnerability of the foundation model (SAM) by training on natural image datasets. The extracted vulnerability is represented as a universal meta-initialization perturbation (δ). In the second stage, a real-time gradient robust adversarial attack is performed. The UMI (δ) is adapted to a specific input (xt) and is used to initialize the adversarial perturbation. Then the adversarial perturbation is updated by maximizing a gradient robust loss (LGR) that is designed to mitigate the deviation caused by gradient disparity between the surrogate model (open-sourced SAM) and the victim model (fine-tuned downstream model). Gradient noise augmentation is used to enhance robustness.

This figure shows the cosine similarity between the gradients of white-box generated adversarial perturbations on both the surrogate model (open-source SAM) and the victim models (fine-tuned downstream models) across different attack methods (MI-FGSM, MI-FGSM+GR, and ILPD). The x-axis represents the iteration step (t) of the attack, and the y-axis represents the cosine similarity. Higher cosine similarity indicates higher alignment between the gradients, suggesting better transferability of adversarial examples. The figure demonstrates that MI-FGSM+GR achieves higher cosine similarity compared to other methods, implying that its adversarial examples transfer better to victim models. The ‘opt’ labels point to the optimal cosine similarity for each attack method.
This figure illustrates the two-stage process of the proposed UMI-GRAT method. The first stage is an offline learning process for Universal Meta Initialization (UMI) where the model learns to extract the intrinsic vulnerability from the foundation model. The second stage is a real-time gradient robust adversarial attack. Here, the UMI is adapted to the specific task and a gradient robust loss is used to generate adversarial perturbations that are robust to the variations between the surrogate and victim models. The figure shows the data flow for both offline UMI learning and real-time attack using the extracted UMI.

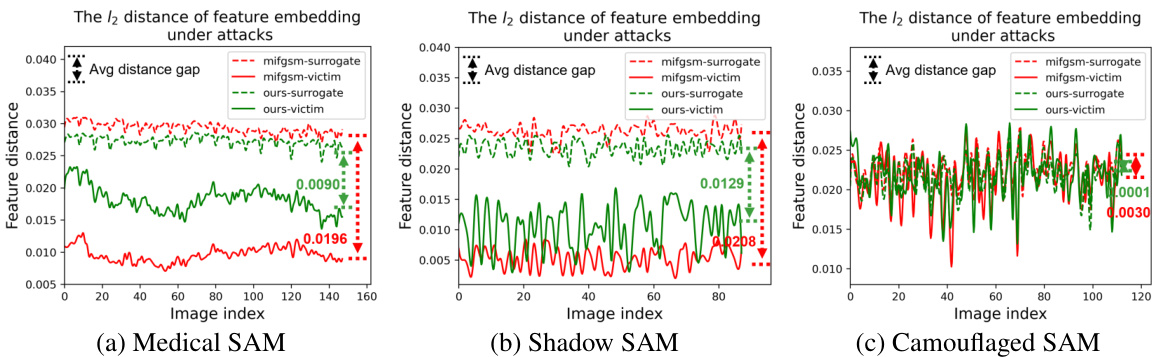
This figure visualizes the results of adversarial attacks on camouflaged object segmentation. For three different datasets (COD-10K, CHAME, CAMO), it shows the original image, the image with adversarial noise added, the ground truth segmentation mask, and the segmentation mask produced by the model when given the adversarial image. The goal is to illustrate how imperceptible adversarial noise can cause significant errors in the model’s segmentation output.

This figure illustrates the two-stage process of the proposed UMI-GRAT attack method. The first stage (left panel) is an offline process where Universal Meta-Initialization (UMI) is performed. This involves using natural images to train the image encoder of the open-sourced SAM to find an optimal adversarial perturbation that is robust to downstream model variations. The second stage (right panel) is a real-time gradient robust adversarial attack. The pre-trained UMI from the first stage is used to initialize the adversarial perturbation, then the perturbation is further optimized using a gradient-robust loss function to mitigate the deviation that can occur between the surrogate (open-sourced SAM) and victim (downstream) models. Gradient noise augmentation helps enhance the robustness of the adversarial example, improving transferability to different downstream tasks.
More on tables
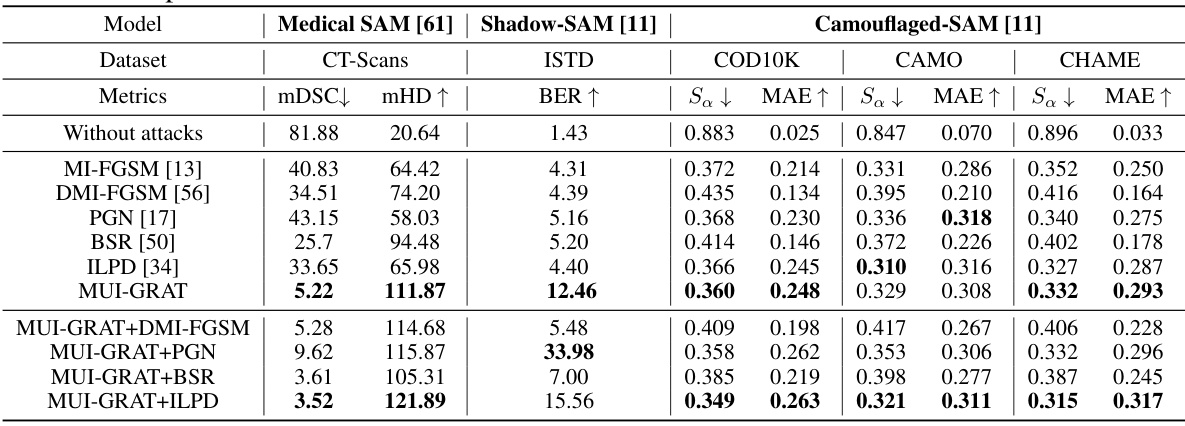
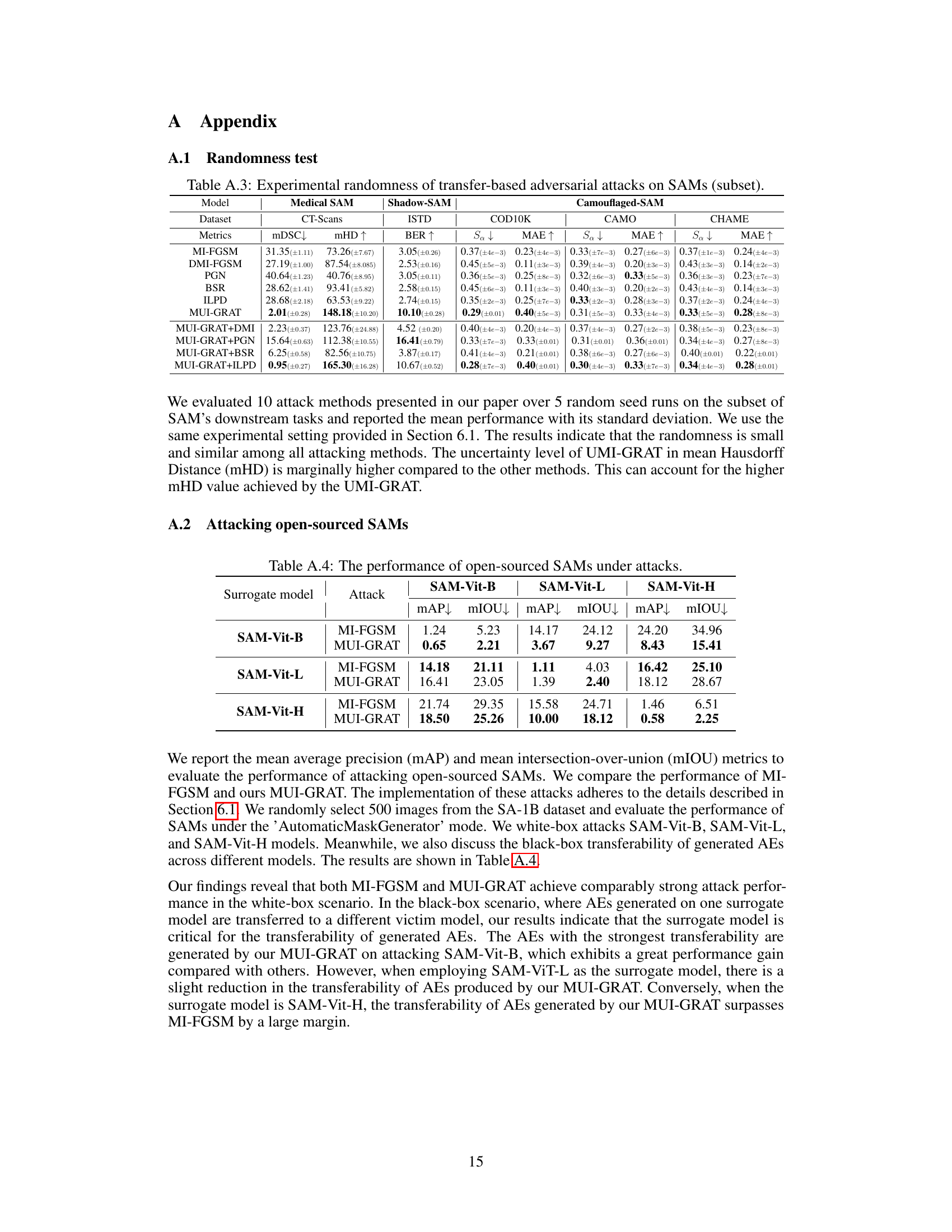
This table presents a comparison of different transfer-based adversarial attacks on various downstream models fine-tuned from the Segment Anything Model (SAM). The attacks utilize only information from the open-sourced SAM, without access to downstream task datasets. The table shows the performance of several attacks (MI-FGSM, DMI-FGSM, PGN, BSR, ILPD, and the proposed UMI-GRAT) across three different downstream tasks and datasets: medical image segmentation, shadow segmentation, and camouflaged object segmentation. Metrics include mean Dice Similarity Coefficient (mDSC), mean Hausdorff Distance (mHD), Bit Error Rate (BER), and Structural Similarity (Sa) along with Mean Absolute Error (MAE). The results show the effectiveness of the proposed UMI-GRAT attack in misleading the downstream models compared to existing transfer-based attacks.

This table presents a comparison of different transfer-based adversarial attack methods on various downstream models fine-tuned from the Segment Anything Model (SAM). The attacks use the open-sourced SAM as a surrogate model, meaning they don’t have access to the specific training data or task of the downstream models. The table shows the effectiveness of different attack methods (MI-FGSM, DMI-FGSM, PGN, BSR, ILPD, and the proposed UMI-GRAT, and combinations thereof) on three types of downstream models: Medical SAM, Shadow-SAM, and Camouflaged-SAM. Metrics used for evaluation include mean Dice Similarity Coefficient (mDSC), mean Hausdorff Distance (mHD), Bit Error Rate (BER), Structural Similarity (Sa), and Mean Absolute Error (MAE), depending on the task of the downstream model. The results highlight the transferability and effectiveness of the proposed UMI-GRAT attack method in misleading these models.
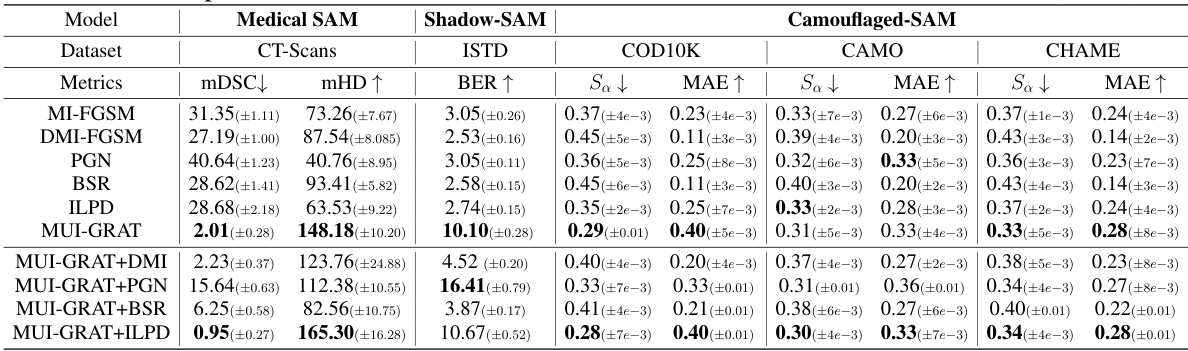
This table presents a comparison of different transfer-based adversarial attack methods on various downstream models fine-tuned from the Segment Anything Model (SAM). The attacks are evaluated using metrics relevant to each model’s task (mDSC, mHD for medical segmentation; Sa, MAE for camouflaged object segmentation; BER for shadow segmentation). The key point is that all attacks use the open-sourced SAM as a surrogate model, simulating a real-world scenario where an attacker does not have access to the downstream model or dataset.
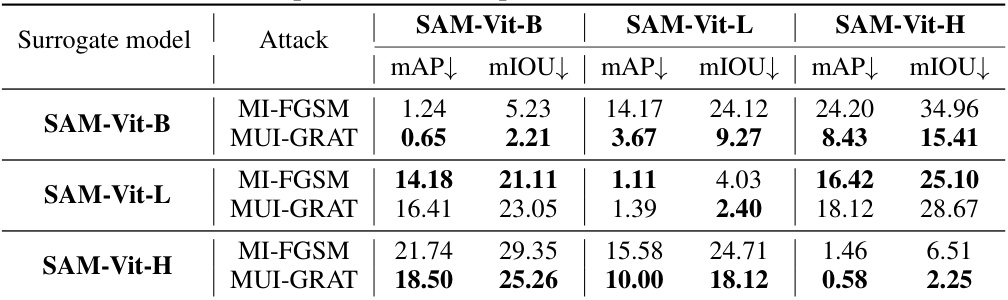
This table presents a comparison of different transfer-based adversarial attack methods on three downstream models (Medical SAM, Shadow-SAM, and Camouflaged-SAM) fine-tuned from the Segment Anything Model (SAM). The attacks are evaluated using various metrics depending on the downstream task (mDSC and mHD for medical segmentation, Sa and MAE for camouflaged object segmentation, and BER for shadow segmentation). The table shows the effectiveness of each attack method, with the proposed MUI-GRAT consistently outperforming other methods across all three downstream models. The results highlight the transferability and effectiveness of the proposed MUI-GRAT.

This table compares the performance of different transfer-based adversarial attack methods on various downstream models fine-tuned from the Segment Anything Model (SAM). The attacks are evaluated using metrics relevant to each downstream task (e.g., mDSC and mHD for medical image segmentation, Sa and MAE for camouflaged object segmentation). The ‘Without attacks’ row provides the baseline performance of each model. The results show that the proposed method (MUI-GRAT) consistently achieves better performance than other methods across various downstream tasks and datasets.
Full paper#