↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
3D object detection struggles with domain adaptation, meaning models trained on one environment often perform poorly in others. Existing methods often focus on single factors, like object size, leaving room for improvement. This is partly due to biased pseudo-label selection during self-training. The proposed GroupEXP-DA tackles these issues.
GroupEXP-DA addresses these issues by using a grouping mechanism to ensure that all object types receive equal attention during training, avoiding bias. It does this in a data-driven way, considering multiple factors that influence object perception. Additionally, an explorative group update strategy helps reduce false negative detection in new environments. This improves overall adaptation performance by learning features that generalize well across domains.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a critical challenge in 3D object detection: domain adaptation. By introducing a novel grouping-exploration strategy, it significantly improves the robustness and generalizability of 3D object detectors across diverse environments. This addresses a major limitation of current methods and opens new avenues for research in autonomous driving and related fields. The proposed approach is also easily adaptable to existing detectors, making it practical and impactful.
Visual Insights#
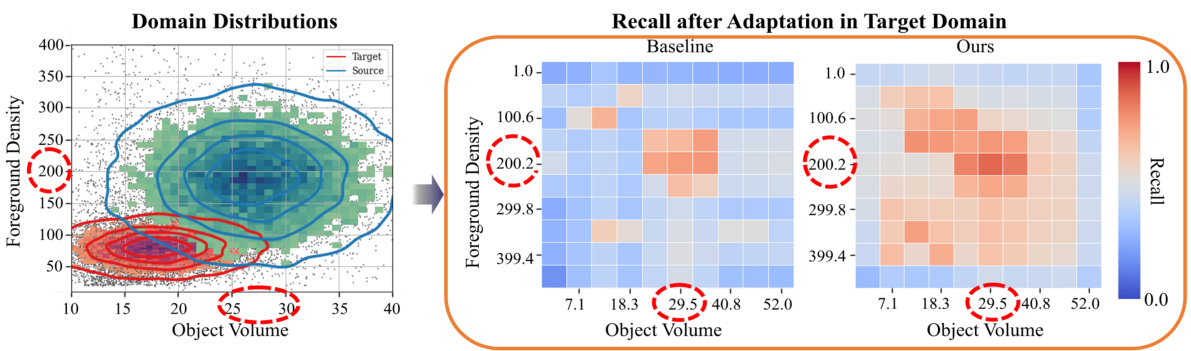
This figure shows how the proposed method addresses the inter-domain gap in 3D object detection. The left panel displays the distributions of point density and object volume in the source (Waymo) and target (NuScenes) domains, highlighting the differences. The middle panel shows the recall of the baseline method, which struggles with objects outside the mean of the source domain distribution. The right panel shows how the proposed method improves recall by grouping objects and exploring the target domain, addressing the false negatives. The heatmaps visualize the average recall for different object volumes and foreground densities.
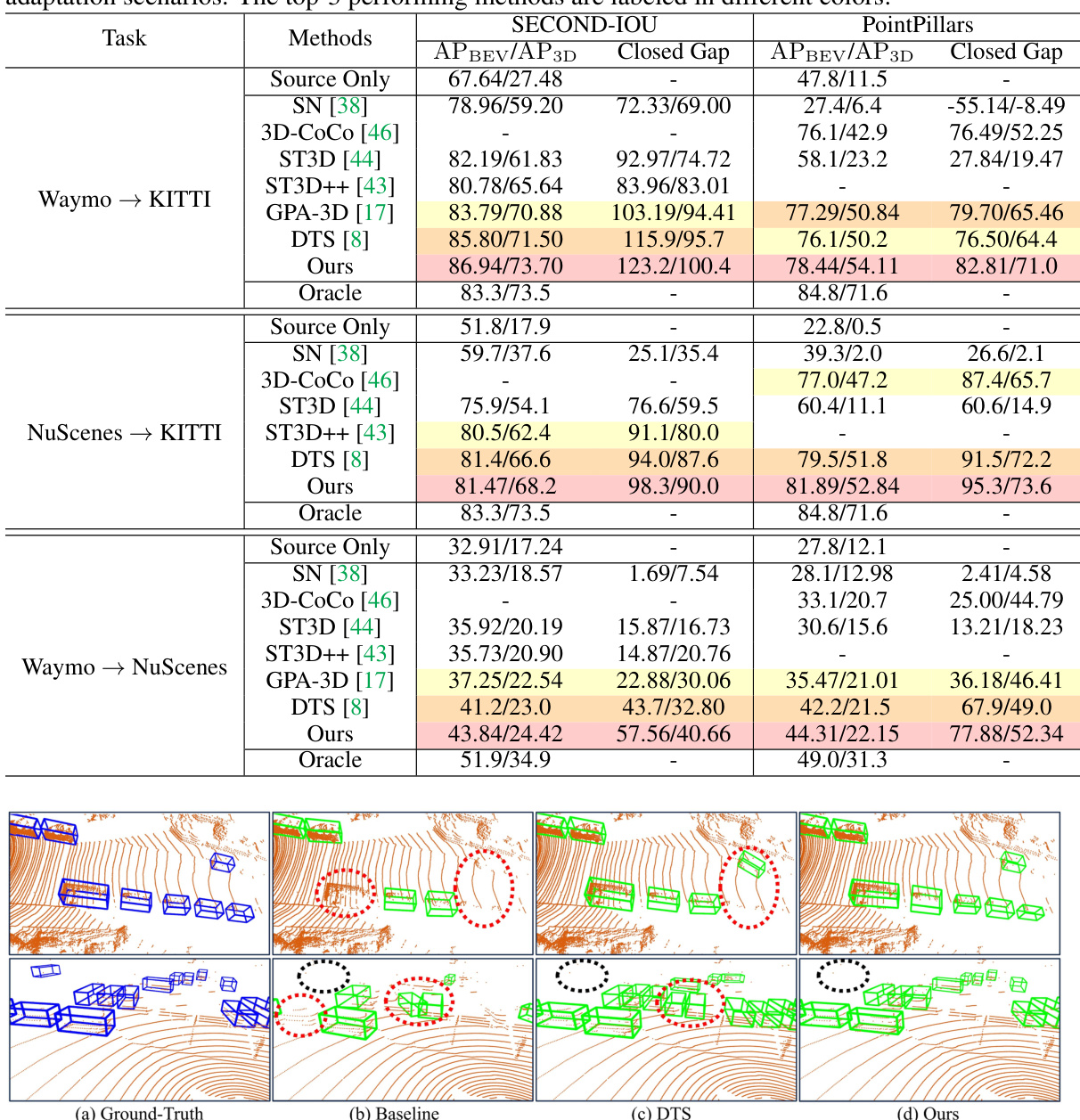
This table presents a quantitative comparison of state-of-the-art domain adaptive 3D object detection methods across three different adaptation scenarios: Waymo to KITTI, NuScenes to KITTI, and Waymo to NuScenes. The comparison is based on two commonly used detectors: SECOND-IOU and PointPillars. For each scenario and detector, the table shows the Average Precision (AP) in Bird’s Eye View (BEV) and 3D Box IoU, both for the source-only model and the adapted models. The ‘Closed Gap’ columns show the improvement achieved by each method over the source-only baseline. The top three performing methods for each scenario and metric are highlighted in different colors.
In-depth insights#
GroupEquivariant Feat#
The concept of ‘GroupEquivariant Features’ in the context of 3D object detection within the paper signifies a significant advancement in handling domain adaptation challenges. The core idea revolves around leveraging the inherent symmetries present in object classes. By grouping similar objects based on their features (e.g., size, shape, point density), the model learns group-specific representations that are robust to variations within each group but sensitive to differences between groups. This strategy addresses the issue of biased pseudo-label collection in self-training methods. Instead of relying on single factors causing domain shift, the method considers multiple factors, thereby enhancing the generalization capability. Furthermore, the utilization of group-equivariant spatial features enhances the model’s robustness to viewpoint changes, improving overall detection accuracy. The explorative group update strategy is also a key contribution, further improving the adaptation by redistributing labels to address false negatives in the target domain. This method is designed as an add-on, making it highly compatible with existing detectors.
Domain Adaptation#
Domain adaptation in 3D object detection addresses the challenge of applying models trained on one dataset (the source domain) to a different, unseen dataset (the target domain). The core problem is the domain gap, where differences in object appearance, scene characteristics, sensor viewpoints, etc. hinder the model’s performance. Approaches to domain adaptation often involve self-training, where pseudo-labels are generated for the target domain and used to refine the model. However, limitations exist. Bias in pseudo-label generation from self-training and the failure to account for multiple factors causing the domain gap often result in suboptimal adaptation. A promising direction involves a group-exploration strategy that considers inherent data characteristics rather than individual factors. This strategy involves grouping objects based on shared attributes, ensuring balanced representation during learning, and progressively refining these groups to better capture target domain characteristics. This approach can potentially minimize the domain gap and improve the adaptability of 3D object detection models to various real-world environments.
GMM Grouping#
The Gaussian Mixture Model (GMM) grouping strategy, employed within the context of domain adaptation for 3D object detection, offers a robust approach to clustering objects based on their inherent features. Instead of relying on simplistic criteria like size or density, GMM leverages the multivariate nature of object characteristics, capturing complex inter-object variations effectively. This data-driven method avoids the bias associated with prioritizing dominant object types, a common issue in self-training approaches. By using GMM’s probabilistic framework, the algorithm dynamically assigns objects to groups and updates group parameters iteratively, promoting a more balanced representation of object diversity within the training data. The resulting groups become more representative of intra-domain variations, facilitating the exploration of the target domain and mitigating inter-domain discrepancies. This method of grouping proves superior to simpler proximity-based methods, providing a more comprehensive understanding of data heterogeneity, hence leading to improved generalization and robustness in the 3D object detection task.
Exploratory Update#
The ‘Exploratory Update’ strategy, as described in the research paper, is a crucial component for enhancing domain adaptation in 3D object detection. It directly addresses the limitations of relying solely on source domain data by actively engaging with the target domain’s characteristics. This iterative process refines pseudo-label sets, preventing the model from overfitting to dominant object types found in the source domain. The method dynamically updates group parameters (mean, covariance, and weight) using a weighted linear combination of source and pseudo-labeled data from the target domain. This intelligent weighting, guided by a data-driven grouping mechanism, ensures fair representation of diverse object characteristics, mitigating bias toward dominant features. The strategy’s explorative nature facilitates the discovery of objects under-represented in initial pseudo-label sets, significantly reducing false negatives. By leveraging group-equivariant spatial features and incorporating inter- and intra-group loss functions, the model effectively balances diversity and cohesion, promoting robustness. In essence, ‘Exploratory Update’ transforms a passive self-training approach into an active exploration of the target domain, achieving superior domain adaptation in 3D object detection.
Multi-domain results#
A hypothetical ‘Multi-domain Results’ section would ideally present a comparative analysis of the model’s performance across diverse datasets and scenarios. Key aspects to include would be a detailed breakdown of metrics (precision, recall, F1-score, etc.) for each domain, allowing for a clear evaluation of the model’s generalization capabilities. Visualization of performance, such as bar charts or line graphs comparing the metrics across domains, would strengthen the analysis and highlight strengths/weaknesses. The section should explicitly address any domain-specific challenges or biases, explaining how the model adapts or fails to adapt in each case. Crucially, it should analyze potential reasons for performance discrepancies across datasets, discussing factors like data variability, annotation quality, or specific characteristics of the domains. Finally, including a discussion on the statistical significance of observed differences adds rigor and trustworthiness to the conclusions drawn.
More visual insights#
More on figures
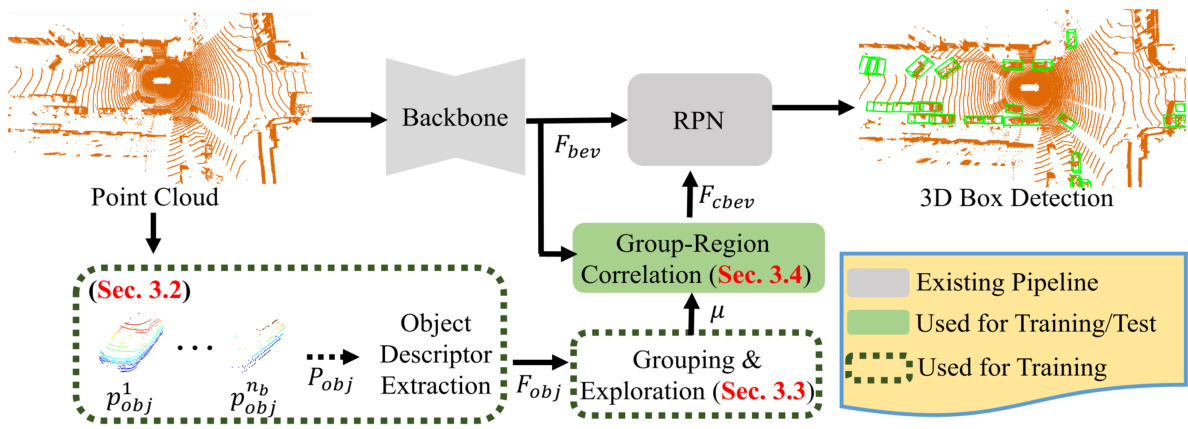
This figure illustrates the overall pipeline of the proposed Group Explorer Domain Adaptation (GroupEXP-DA) method for 3D object detection. It starts with a point cloud as input, then extracts foreground points from existing 3D bounding boxes. These points are fed into an Object Descriptor Extraction module, which generates object descriptors. These descriptors are then used in a Grouping & Exploration module to group similar objects and refine these groupings. The grouped features are then input into a Group-Region Correlation module, which generates region proposals for object detection. Finally, the proposed system utilizes a Regional Proposal Network (RPN) to generate 3D bounding boxes for detected objects. The figure clearly shows how the different components of the proposed method interact with each other, and highlights the modules that are used during training and those used during both training and testing.
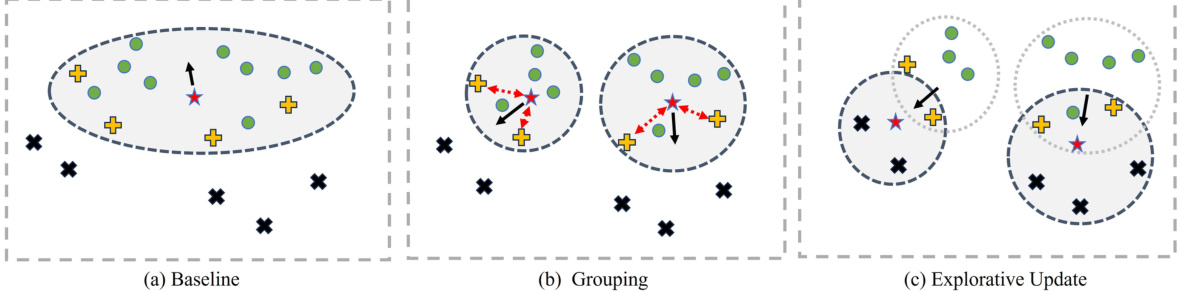
This figure illustrates the differences in pseudo-label generation between the baseline method and the proposed Group Explorer Domain Adaptation (GroupEXP-DA) method. (a) Baseline: Shows how the baseline method generates pseudo-labels without considering the distribution of objects in the target domain. This leads to an over-reliance on dominant object types. (b) Grouping: Illustrates how GroupEXP-DA groups similar objects together, creating a more balanced representation of the target domain. This helps in reducing the bias towards dominant object types. (c) Explorative Update: Shows how GroupEXP-DA further refines the grouping by using an explorative update strategy. This strategy aims to reduce false negatives in the target domain by redistributing labels according to the characteristics of the groups identified in the target domain.
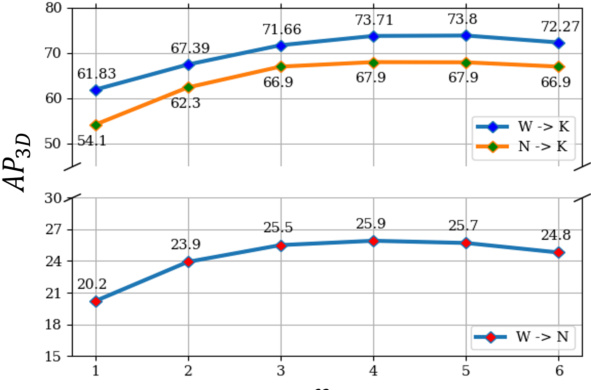
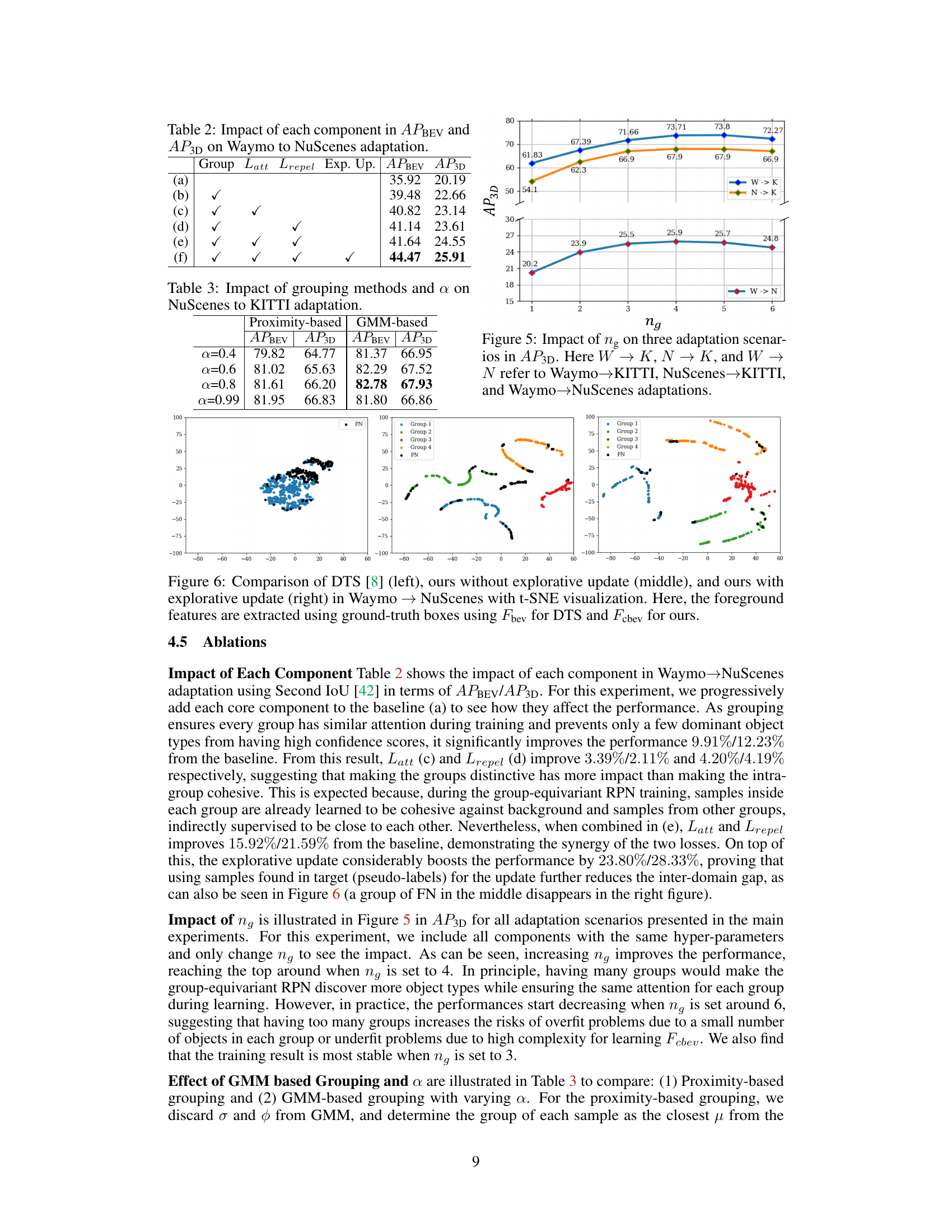
This figure shows how the number of groups (ng) affects the 3D Average Precision (AP3D) performance across three different domain adaptation scenarios: Waymo to KITTI, NuScenes to KITTI, and Waymo to NuScenes. The x-axis represents the number of groups, and the y-axis represents the AP3D. Each line represents a different adaptation scenario, illustrating the optimal number of groups for achieving the best performance in each setting.
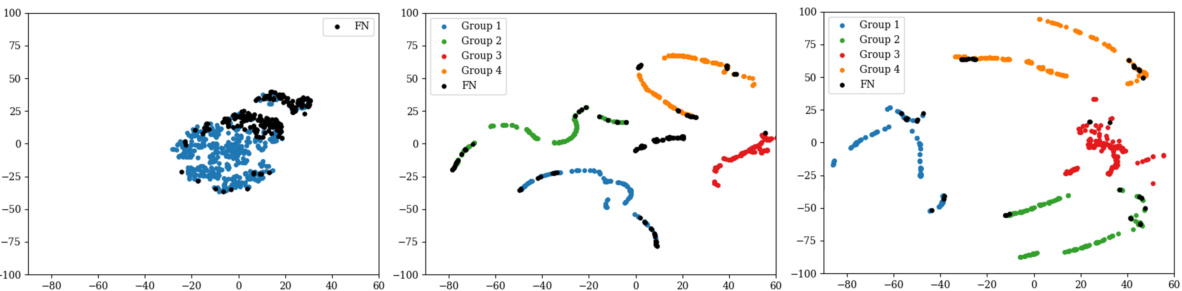
This figure uses t-SNE to visualize the foreground features extracted from the Waymo to NuScenes adaptation. It compares the results of three methods: DTS [8] (a baseline), the proposed method without explorative update, and the proposed method with explorative update. The visualization shows how the explorative update in the proposed method improves the grouping of similar objects, reducing false negatives.
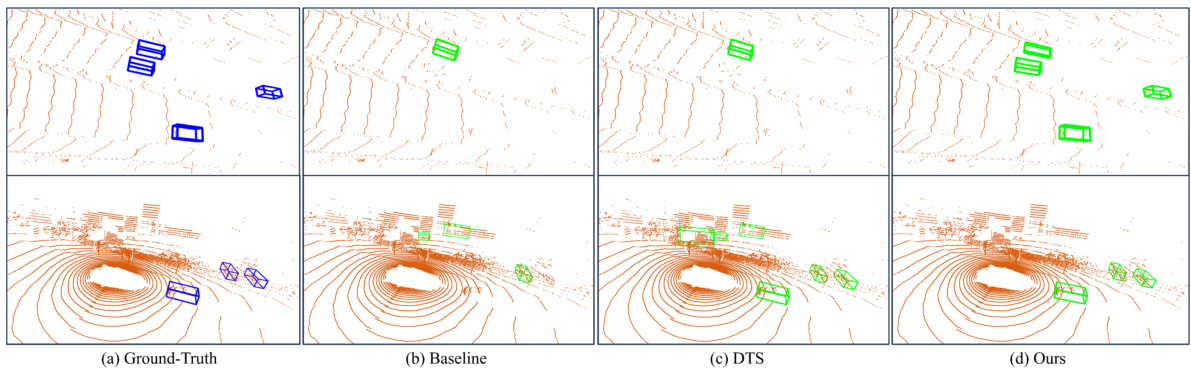
This figure compares the qualitative 3D detection results of three different methods: the baseline (ST3D), DTS, and the proposed GroupEXP-DA method. The top row shows the results for the NuScenes to KITTI adaptation, while the bottom row displays the results for the Waymo to NuScenes adaptation. Each column represents a different method, showing the ground truth, baseline results, DTS results, and the results of the proposed method. The visualizations highlight the differences in detection performance between the methods, particularly in terms of false positives and false negatives, demonstrating the superior performance of the proposed approach in handling inter-domain variations.
More on tables
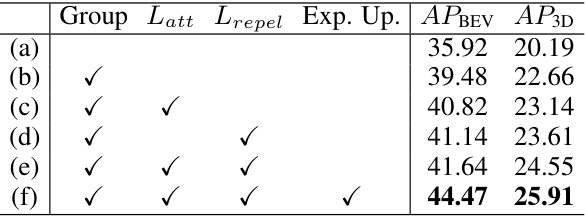
This ablation study analyzes the contribution of each component of the proposed GroupEXP-DA method on the Waymo to NuScenes adaptation task. The table shows the impact of adding each component sequentially: grouping, intra-group attraction loss (Latt), inter-group repulsion loss (Lrepel), and explorative update. The results are presented in terms of Average Precision (AP) on Bird’s Eye View (APBEV) and 3D bounding boxes (AP3D).
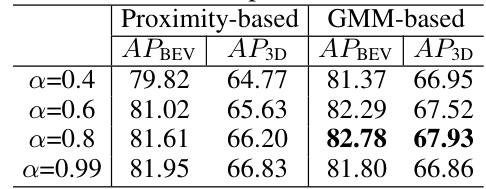
This table shows the performance of different grouping methods (Proximity-based and GMM-based) and different values of α (a hyperparameter that controls the balance between existing group parameters and newly calculated ones) on the NuScenes to KITTI adaptation task. The results are presented as Average Precision (AP) for Bird’s Eye View (BEV) and 3D box IoU (AP3D). The table helps to demonstrate the effectiveness of the GMM-based grouping method and the impact of the α parameter on the model’s performance.
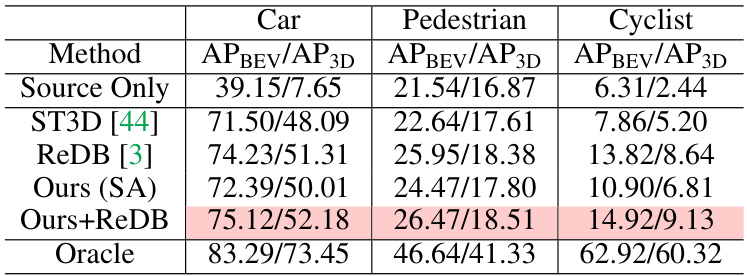
This table presents the results of a multi-class adaptation experiment on the NuScenes to KITTI adaptation task. It compares the performance of several methods: Source Only (baseline), ST3D [44], ReDB [3], Ours (SA) (a naive extension of the single-class adaptation to multi-class), Ours + ReDB (the proposed method combined with ReDB), and Oracle (a fully supervised model). The performance is measured by Average Precision (AP) in Bird’s Eye View (BEV) and 3D, separately for Car, Pedestrian, and Cyclist classes.
Full paper#