↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training deep neural networks is challenging due to their non-convex optimization landscape, leading to suboptimal solutions and the need for extensive hyperparameter tuning. Existing approaches to convex reformulation faced scalability issues, limiting their applicability to small datasets.
The paper introduces CRONOS, a novel algorithm for training two-layer convex neural networks that addresses scalability issues. By leveraging operator splitting and Nyström preconditioning, CRONOS efficiently solves the resulting convex program. CRONOS-AM extends this approach to multi-layer networks using alternating minimization. Extensive experiments on large-scale datasets demonstrate CRONOS-AM’s effectiveness, achieving comparable or better performance than standard deep learning optimizers.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces CRONOS, the first algorithm capable of scaling convex neural network optimization to high-dimensional datasets like ImageNet. This breakthrough addresses a major limitation of previous convex methods, opening new avenues for research in efficient and theoretically sound deep learning optimization. The efficient GPU implementation in JAX further enhances its practicality and scalability, making it highly relevant to the current deep learning landscape. The combination of theoretical guarantees and strong empirical results makes this a valuable contribution to the field.
Visual Insights#
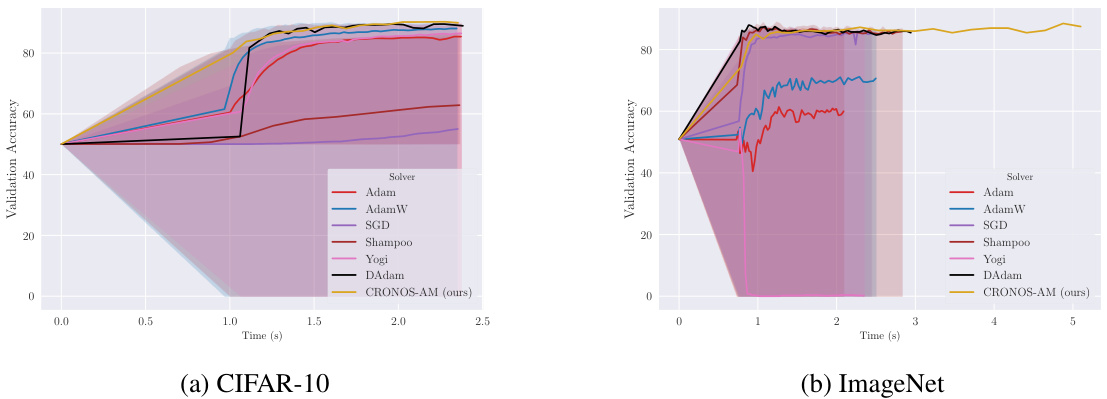
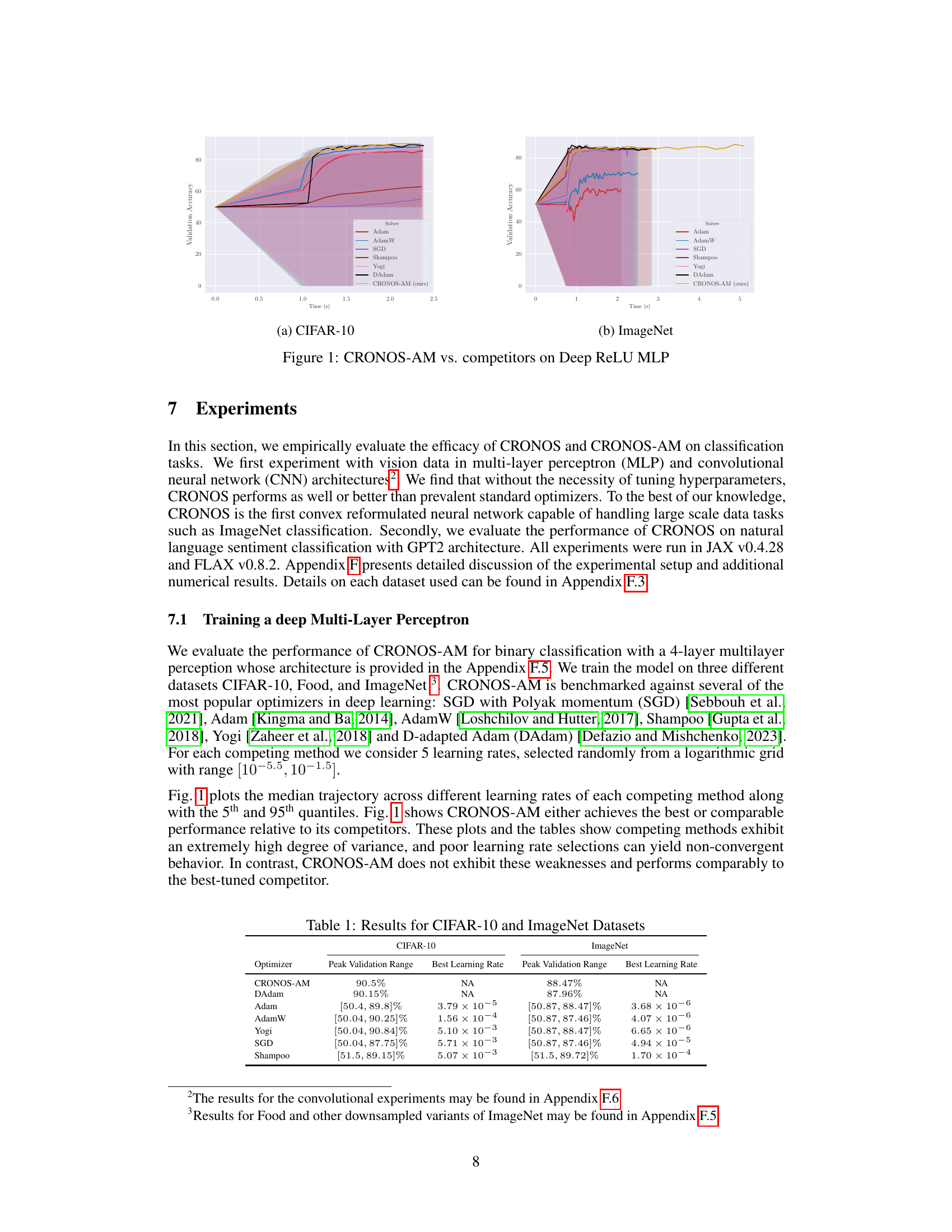
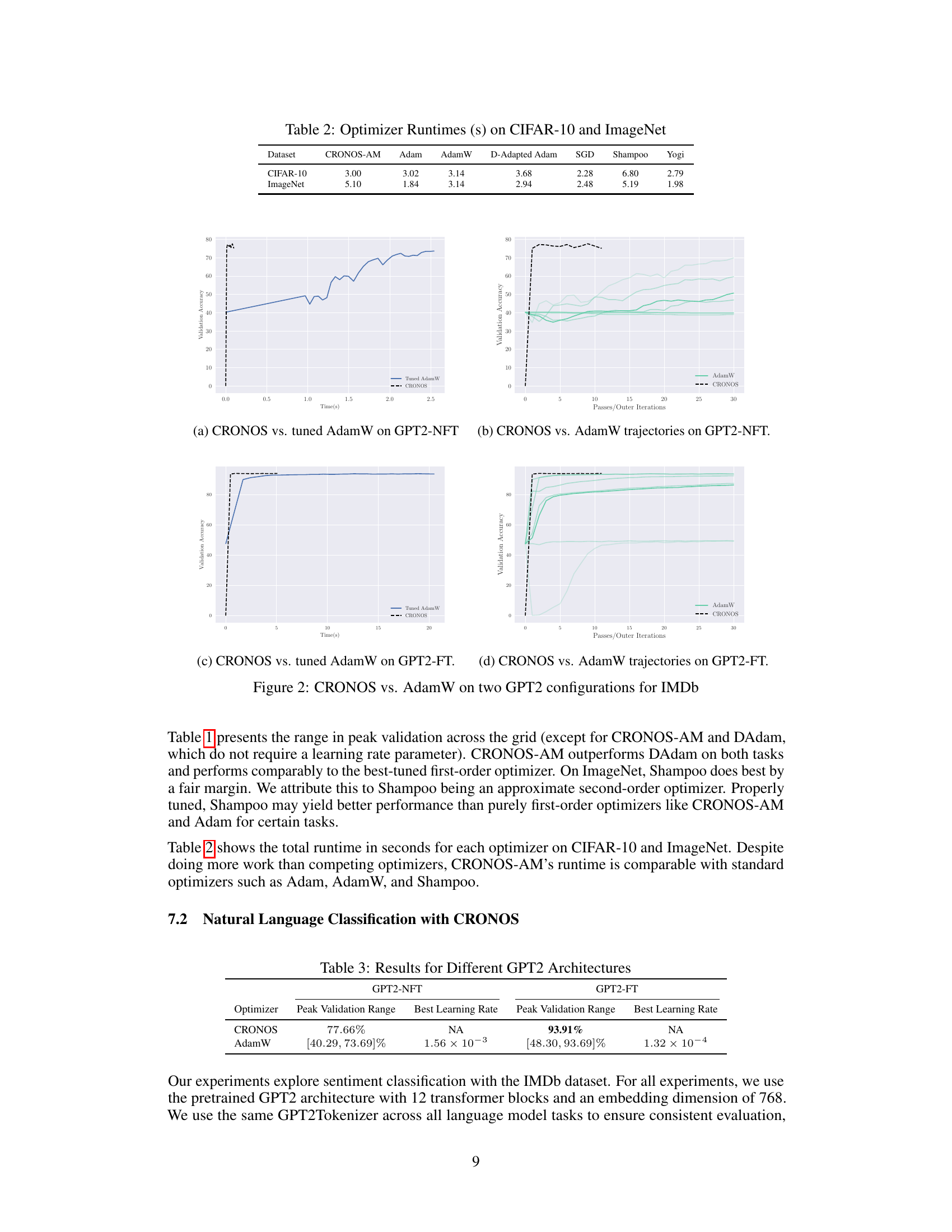
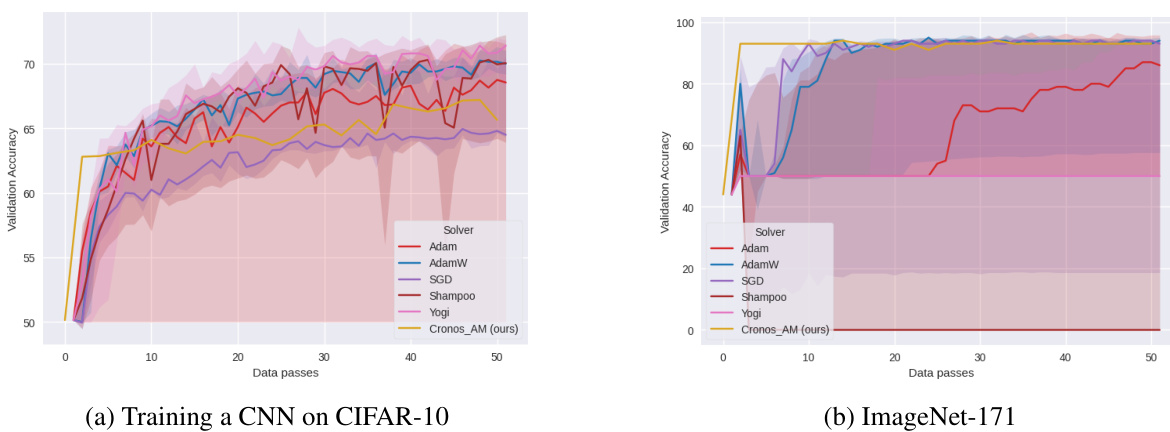
This figure compares the performance of CRONOS-AM against other popular optimizers (Adam, AdamW, SGD, Shampoo, Yogi, and DAdam) on two datasets: CIFAR-10 and ImageNet. The x-axis represents the training time, and the y-axis represents the validation accuracy. The shaded areas represent the 5th and 95th percentiles of the validation accuracy across multiple learning rates for each optimizer. CRONOS-AM demonstrates comparable or better performance than the best-tuned competitors, especially highlighting the stability of its performance across different learning rates, in contrast to the significant variance observed with other optimizers.

This table shows the runtime in seconds for different optimizers on CIFAR-10 and ImageNet datasets. It compares the runtime of CRONOS-AM to other popular optimizers like Adam, AdamW, SGD, Shampoo, and Yogi. The results highlight that despite CRONOS-AM performing more computation, its runtime remains comparable to standard optimizers.
In-depth insights#
Convex ReLU Nets#
The concept of “Convex ReLU Nets” presents a fascinating approach to address the challenges of non-convexity in training deep neural networks. The core idea is to reformulate the non-convex optimization problem inherent in training ReLU networks into an equivalent convex problem. This reformulation leverages the properties of ReLU activation functions and allows for the application of efficient convex optimization algorithms. A key advantage is the guarantee of convergence to the global optimum, unlike traditional methods which can get stuck in local minima. However, the reformulation often leads to a high-dimensional, computationally expensive problem, limiting its applicability to smaller datasets. The research into this area is focused on developing efficient algorithms to solve this high-dimensional convex problem and scaling it to large-scale datasets, which is a significant challenge, requiring novel techniques from areas like randomized numerical linear algebra and operator splitting methods. The success of this approach hinges on balancing the theoretical guarantees of convex optimization with the practical need for scalability and computational efficiency. If successful, this would represent a significant paradigm shift in deep learning, offering both improved performance and a deeper understanding of the underlying optimization landscape.
CRONOS Algorithm#
The CRONOS algorithm, designed for convex optimization of neural networks, presents a significant advancement in deep learning. Its key innovation lies in its scalability, unlike previous methods limited to small datasets. By leveraging operator splitting and the Alternating Directions Method of Multipliers (ADMM), CRONOS efficiently solves the high-dimensional convex reformulation of the neural network training problem. The algorithm’s efficiency is further enhanced through Nyström preconditioning, which accelerates the solution of large linear systems. GPU acceleration in JAX is utilized to handle the large-scale computations involved. The theoretical analysis proves CRONOS converges to the global minimum under mild assumptions, and empirical results demonstrate comparable or better performance than standard deep learning optimizers on various benchmark datasets, showcasing its potential to improve training efficiency and accuracy in large-scale deep learning tasks.
Large-Scale Tests#
A dedicated ‘Large-Scale Tests’ section in a research paper would ideally delve into experiments showcasing the scalability and real-world applicability of the proposed method. This would involve testing on datasets significantly larger and more complex than those used in smaller-scale evaluations, demonstrating the algorithm’s performance on high-dimensional data and intricate architectures. Key aspects would include a comparison with existing state-of-the-art approaches, highlighting the advantages of the novel method in terms of speed, accuracy, and resource efficiency. The results would ideally encompass a comprehensive analysis of metrics like training time, convergence rate, and generalization performance across various datasets, providing strong evidence to support the claim of scalability. Furthermore, the discussion should address potential limitations encountered during large-scale testing, such as memory constraints or computational bottlenecks, and propose solutions or mitigation strategies. Finally, a visualization of the results, perhaps using graphs or charts, is vital to provide a clear and intuitive understanding of the algorithm’s performance at scale. The inclusion of error bars or confidence intervals would improve the rigor and reliability of the findings.
CRONOS-AM#
The heading ‘CRONOS-AM’ suggests an extension of the core CRONOS algorithm, likely incorporating alternating minimization. This technique is commonly used to tackle the non-convexity challenges of deep learning by iteratively optimizing different parts of the network. CRONOS-AM’s effectiveness likely stems from combining CRONOS’s strength in efficiently solving the convex reformulation of two-layer neural networks with alternating minimization’s ability to handle multi-layer architectures. The resulting hybrid approach likely offers a scalable and efficient way to train complex neural networks, potentially achieving comparable or superior performance to traditional methods. The success of CRONOS-AM would depend on effective coordination between the convex optimization step and the alternating minimization iterations. A critical aspect would be the choice of optimization method used within the alternating minimization process. Further, the convergence properties and computational cost of CRONOS-AM would be crucial considerations. The use of GPU acceleration, implied by the original CRONOS description, would be vital for scalability in CRONOS-AM, making it practical for large-scale datasets and complex architectures. However, memory limitations remain a potential concern for handling extremely large models.
Future Works#
The paper’s primary focus is on CRONOS, a novel algorithm that efficiently solves convex formulations of neural networks, demonstrating its effectiveness on large-scale datasets. Future work should explore several promising avenues. Extending CRONOS-AM’s capabilities to handle more complex network architectures, such as transformers, and incorporating other loss functions beyond least squares is crucial. Theoretical analysis should be deepened to provide more precise convergence guarantees under broader assumptions and possibly analyze generalization bounds. Empirically evaluating CRONOS and CRONOS-AM on a wider array of datasets and tasks would solidify its versatility and practical applicability. Furthermore, investigating the algorithm’s performance in distributed or federated learning settings is vital for real-world scalability. Finally, developing techniques to automate hyperparameter selection for CRONOS-AM, potentially using Bayesian optimization, would make the algorithm more user-friendly and improve its ease of use.
More visual insights#
More on figures
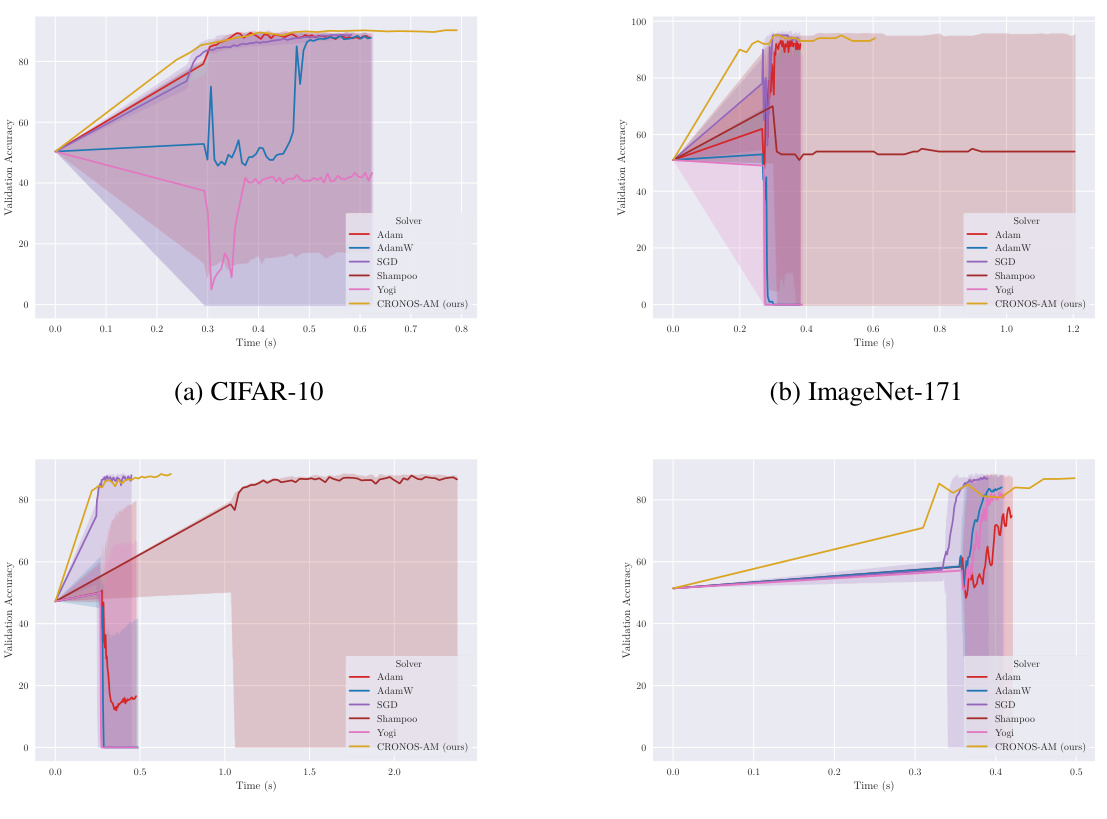
This figure compares the performance of CRONOS-AM with other optimizers (Adam, AdamW, SGD, Shampoo, Yogi, and DAdam) on two deep ReLU MLP tasks: CIFAR-10 and ImageNet. The plots show validation accuracy over time (in seconds). It highlights that CRONOS-AM achieves comparable or better accuracy than the other optimizers, often with less variance across different learning rates.

This figure compares the performance of CRONOS-AM with other optimizers (Adam, AdamW, SGD, Shampoo, Yogi, and DAdam) on two different datasets: CIFAR-10 and ImageNet, using a deep ReLU MLP architecture. The graphs show validation accuracy over time (in seconds). The plot illustrates that CRONOS-AM achieves competitive or superior performance compared to the other optimizers, which show significant variability and sensitivity to hyperparameter tuning.

The figure shows the performance comparison of CRONOS-AM against other optimizers (Adam, AdamW, SGD, Shampoo, Yogi, and DAdam) on CIFAR-10 and ImageNet datasets using a deep ReLU MLP architecture. The graphs plot validation accuracy against training time. It highlights CRONOS-AM’s competitive performance and robustness to hyperparameter tuning compared to other methods.
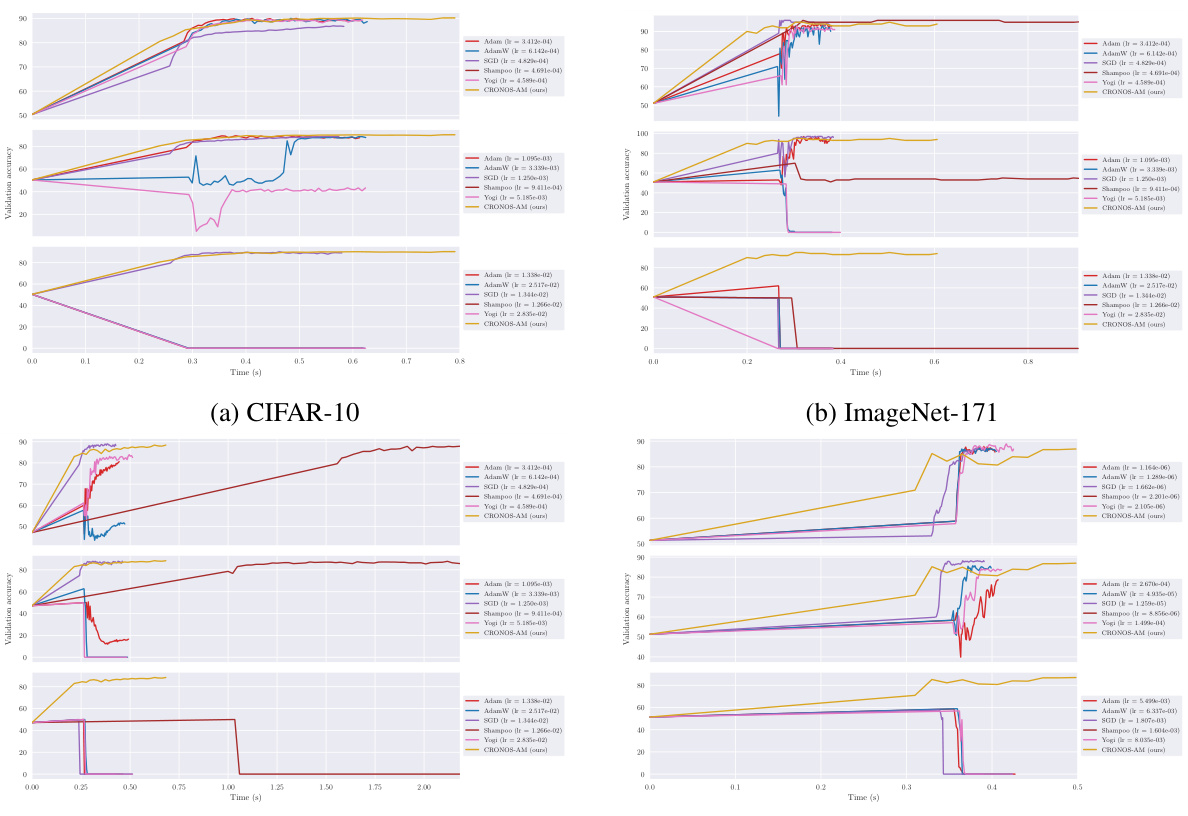
The figure compares the performance of CRONOS-AM with other optimizers (Adam, AdamW, SGD, Shampoo, Yogi, and DAdam) on two datasets: CIFAR-10 and ImageNet, using a deep ReLU MLP architecture. The x-axis represents time (in seconds), and the y-axis represents validation accuracy. The plot shows that CRONOS-AM achieves comparable or better validation accuracy than the other optimizers, while also demonstrating less sensitivity to hyperparameter tuning.
The figure compares the performance of CRONOS-AM against other popular optimizers (Adam, AdamW, SGD, Shampoo, Yogi, and DAdam) on two datasets: CIFAR-10 and ImageNet. The x-axis represents the training time in seconds, and the y-axis represents the validation accuracy. The figure shows that CRONOS-AM achieves comparable or better validation accuracy than the other optimizers, while also exhibiting less sensitivity to hyperparameter tuning. The shaded regions represent the 5th and 95th percentiles of the validation accuracy across multiple runs with different learning rates for each optimizer.
This figure compares the performance of CRONOS-AM against other popular optimizers (Adam, AdamW, SGD, Shampoo, Yogi, DAdam) on two different datasets: CIFAR-10 and ImageNet. The x-axis represents training time in seconds, and the y-axis shows validation accuracy. The plots show that CRONOS-AM achieves comparable or better accuracy than the other optimizers, and that the other optimizers exhibit high variance and sensitivity to hyperparameters.
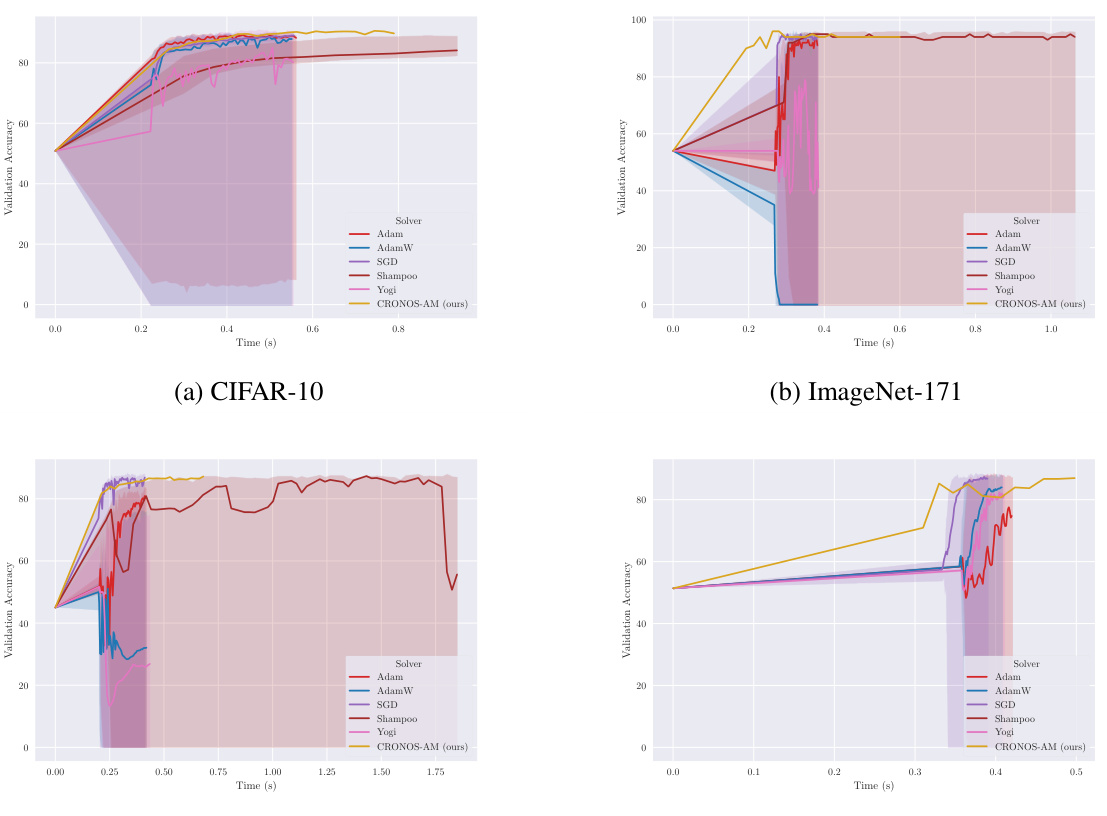
This figure compares the performance of CRONOS-AM against other popular optimizers (Adam, AdamW, SGD, Shampoo, Yogi, and DAdam) on two datasets: CIFAR-10 and ImageNet. The plots show the validation accuracy over time for each optimizer. The shaded regions represent the 5th and 95th percentiles across multiple runs with different learning rates for the competing methods. CRONOS-AM demonstrates comparable or better performance without requiring extensive hyperparameter tuning.
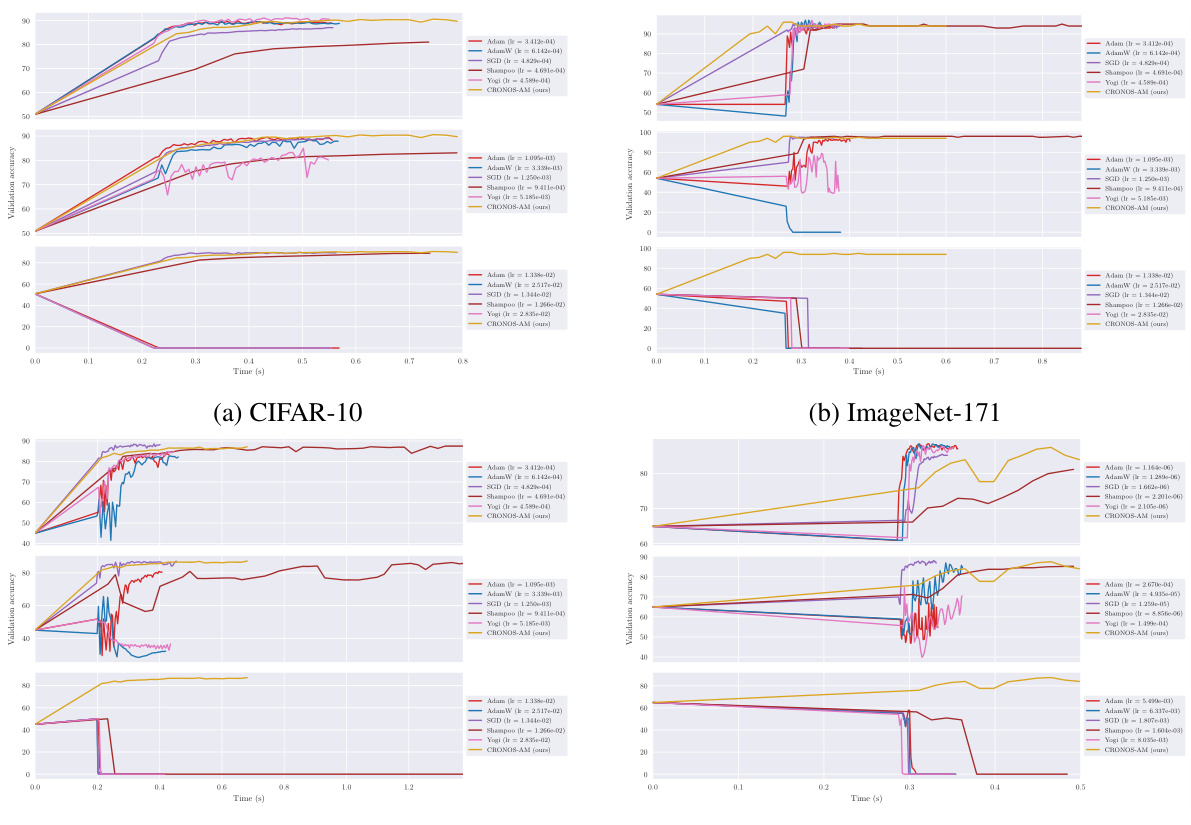
This figure compares the performance of CRONOS-AM with other optimizers (Adam, AdamW, SGD, Shampoo, Yogi, DAdam) on Deep ReLU MLPs for CIFAR-10 and ImageNet datasets. The plots show validation accuracy against training time. CRONOS-AM demonstrates competitive or superior performance compared to the other optimizers. Note that the non-CRONOS optimizers show a high degree of variability across different learning rates; CRONOS-AM does not exhibit this sensitivity.
More on tables
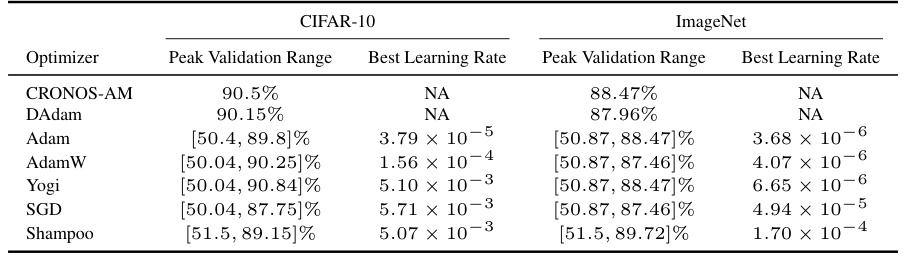
The table compares the performance of CRONOS-AM against other optimizers (Adam, AdamW, Yogi, SGD, and Shampoo) on CIFAR-10 and ImageNet datasets for a binary classification task using a deep ReLU MLP. For each optimizer, the table shows the range of peak validation accuracy achieved across different learning rates and the best learning rate found. It highlights CRONOS-AM’s consistent high performance and lack of sensitivity to hyperparameter tuning compared to other methods.

This table presents the runtime in seconds for various optimizers on the CIFAR-10 and ImageNet datasets. It compares the time taken by CRONOS-AM against popular optimizers like Adam, AdamW, D-Adapted Adam, SGD, Shampoo, and Yogi. The table highlights the relative computational efficiency of the different optimizers.

This table presents the runtime in seconds for various optimizers on two datasets: CIFAR-10 and ImageNet. The optimizers compared are CRONOS-AM, Adam, AdamW, D-Adapted Adam, SGD, Shampoo, and Yogi. The table shows that CRONOS-AM, despite performing more work than some competitors, has comparable runtime. This highlights the efficiency of the CRONOS-AM algorithm.

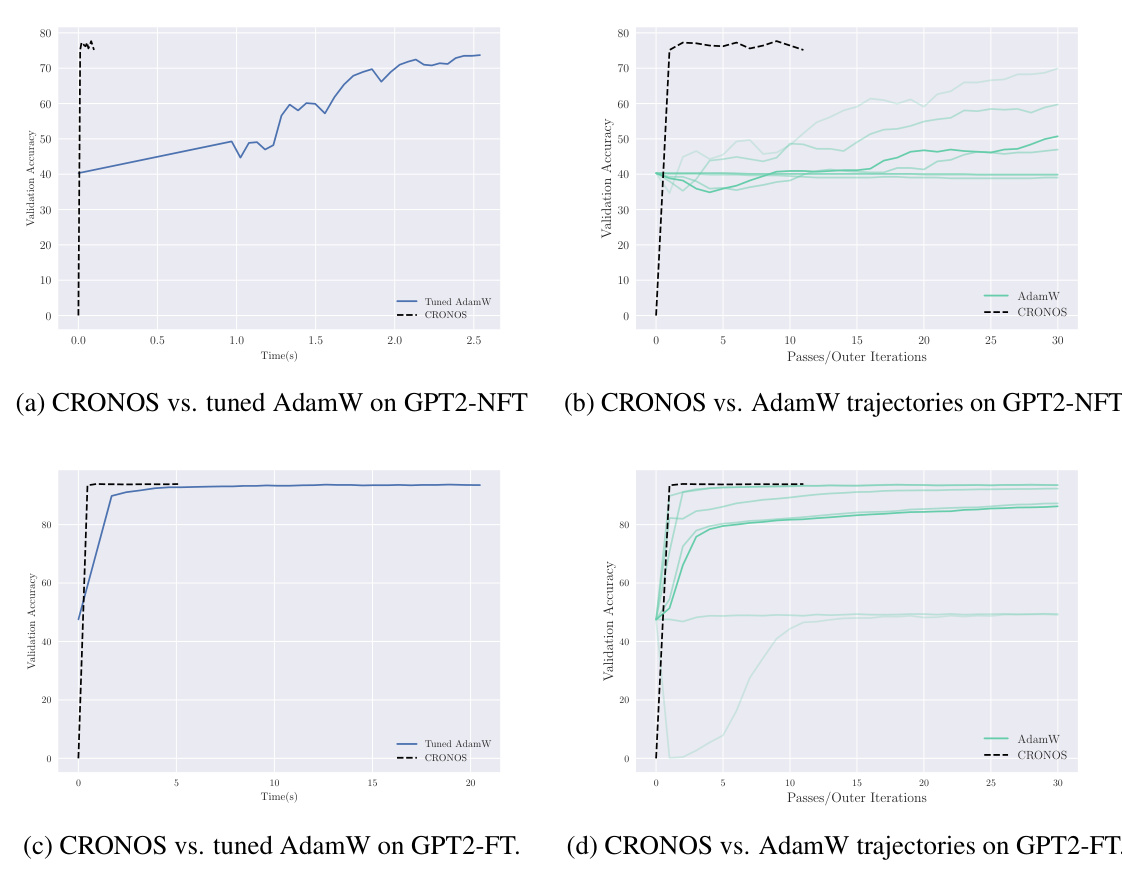
This table presents the validation accuracy results obtained by the CRONOS algorithm on the IMDB dataset under three different experimental settings: IMDB-NFT (no fine-tuning), IMDB-FT (one epoch of fine-tuning with AdamW), and IMDB-DA (unsupervised domain adaptation). The results represent averages across multiple batches and random seeds, providing a robust measure of the algorithm’s performance under various conditions. The IMDB-FT setting shows particularly high accuracy, likely due to the benefit of the initial fine-tuning step.
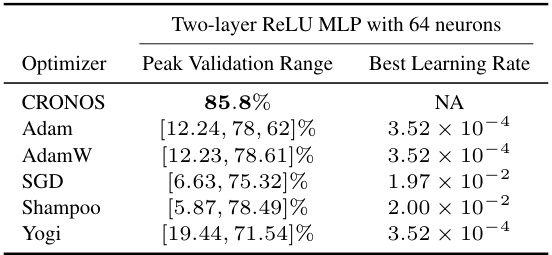
This table presents the results of a multiclass classification experiment using a two-layer ReLU MLP with 64 neurons on the Fashion MNIST dataset. It compares the performance of CRONOS against Adam, AdamW, SGD, Shampoo, and Yogi optimizers. The table shows the peak validation accuracy range achieved by each optimizer across a range of learning rates and the best learning rate found for each optimizer. Notably, CRONOS achieves the highest peak validation accuracy without requiring any hyperparameter tuning (learning rate).
Full paper#