↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large-scale training datasets are computationally expensive and require substantial storage. Dataset distillation (DD) aims to address this by creating smaller, representative datasets. However, existing DD methods often overlook the significant color redundancy present in images. This redundancy limits storage efficiency and model performance.
AutoPalette tackles this issue with a two-pronged approach: a palette network that intelligently reduces the color palette within individual images, and a color-guided initialization method that selects images with diverse color distributions for the distilled dataset. The results show that AutoPalette synthesizes smaller, more efficient datasets that preserve essential information, leading to competitive model performance with a reduced storage footprint.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in dataset distillation: color redundancy. By introducing a novel color-aware framework, AutoPalette, it significantly improves the efficiency and effectiveness of training deep learning models. This research is highly relevant to current trends in resource-efficient machine learning and opens up exciting avenues for future exploration in model compression, and data-efficient AI.
Visual Insights#

This figure illustrates the AutoPalette framework, which consists of two main stages: initialization and training. In the initialization stage, the information gain of quantized images is used to select representative images for the synthetic dataset. The training stage involves a palette network that dynamically allocates colors to pixels, aiming to reduce color redundancy while preserving essential image features. The palette network is trained using the Ltask loss, as well as auxiliary losses La, Lb, and Lm to ensure color utility and balance.
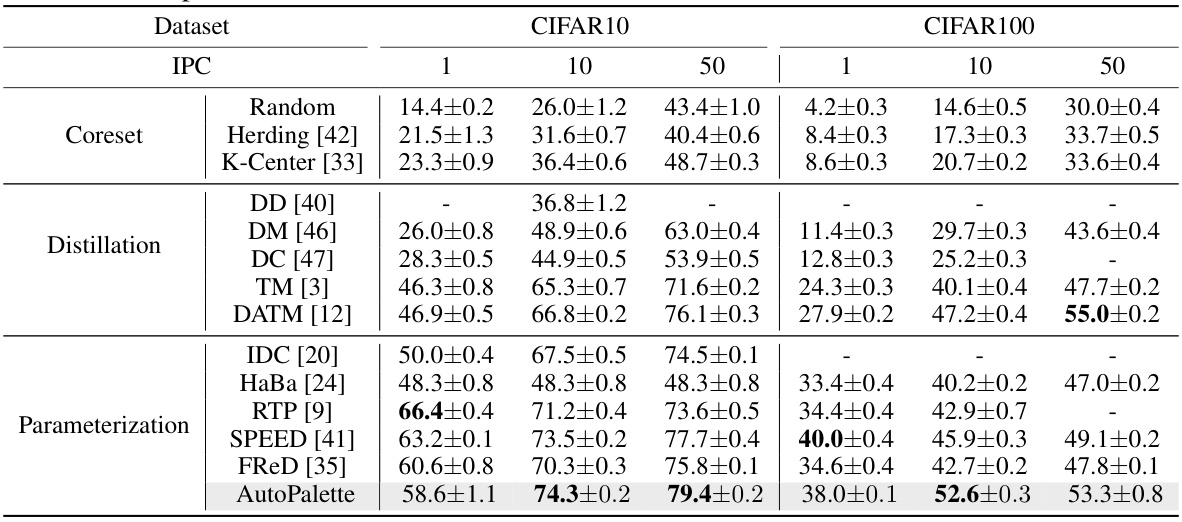
This table presents a comparison of the test accuracy achieved by various dataset distillation methods on the ConvNet D3 model. The synthetic images used in this experiment were reduced from 256 colors to 64 colors. The results show that the proposed AutoPalette method outperforms existing methods and achieves state-of-the-art performance.
In-depth insights#
AutoPalette Overview#
AutoPalette, a novel color-oriented redundancy reduction framework for dataset distillation, addresses the limitations of existing methods by minimizing color redundancy at both the image and dataset levels. At the image level, a palette network dynamically allocates colors from a reduced color space, enhancing color utility in synthetic images. This network prioritizes essential image features by assigning more unique colors to critical areas. At the dataset level, a color-guided initialization strategy selects representative images with minimal color redundancy, based on information gain, to optimize the synthetic dataset. This dual approach ensures that the distilled dataset retains essential features while significantly reducing color redundancy, leading to improved storage efficiency and enhanced model performance. The integration of additional losses—maximum color loss and palette balance loss—further optimizes the color distribution within and across images, improving overall efficiency. AutoPalette provides a plug-and-play solution that seamlessly integrates with existing data distillation frameworks, offering a significant advancement in resource-efficient model training.
ColorQuant Network#
A hypothetical ‘ColorQuant Network’ in a dataset distillation paper would likely focus on efficient color representation for reduced storage and improved training efficiency. The network’s architecture might involve a deep learning model trained to map an input image’s RGB values to a compressed color palette, significantly reducing the number of unique colors. This compression is crucial for minimizing redundancy, a major goal of dataset distillation. Loss functions would need to balance color accuracy with compression, perhaps using a combination of perceptual loss measures (e.g., to prevent artifacts) and a quantization loss, ensuring a smooth transition between similar colors. The network might also incorporate a color-guided initialization strategy, which selects a representative subset of colors from the original dataset, guiding the network’s early training and overall palette selection to avoid color biases. The network’s output would be a low-bit representation of the input image, suitable for storage and efficient training. The success of this network hinges on its ability to achieve high compression rates without severely impacting discriminative image features. The evaluation would involve comparing model performance when trained on both original and quantized datasets, demonstrating the effectiveness of the ColorQuant Network in dataset distillation.
Init Strategy#
An effective initialization strategy is crucial for dataset distillation, especially when dealing with color-reduced images. A naive random initialization may lead to suboptimal results, failing to capture the diversity present in the original dataset. A well-designed initialization method should prioritize selecting images with diverse color palettes and structures, ensuring the resulting distilled dataset is representative. The proposed color-guided initialization module addresses this by employing information gain to identify images with the least replicated color patterns. This approach is superior to random selection as it strategically minimizes redundancy among synthetic images. It ensures that the initial set of images provides sufficient variability in the reduced color space, enabling the training process to converge to a more representative solution and improving the quality of distilled dataset. Furthermore, the use of color condensation, in combination with information gain, allows for efficient selection of diverse images, even with the significantly reduced color representation. This ensures that the final distilled dataset contains an effective balance between diversity and compactness, leading to improved training efficiency and model performance.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a dataset distillation paper, this might involve removing or altering individual modules within the proposed framework. For instance, the impact of the color-guided initialization module, or the contributions of individual loss functions (like maximum color loss or palette balance loss) could be evaluated by removing them and measuring the resulting performance drop. A well-designed ablation study helps isolate the impact of each component, confirming their effectiveness and demonstrating the necessity of each part in the overall framework. Furthermore, an ablation study can reveal unexpected interactions between modules—a module may show insignificant performance on its own but may synergistically improve model performance when combined with others. The results should clearly show how each component contributes to overall performance. A clear and thorough ablation study significantly enhances the credibility and understanding of the proposed methods. It is a powerful tool to objectively demonstrate the necessity of each individual component and their overall impact on the final performance.
Future Work#
The ‘Future Work’ section of this research paper on color-oriented redundancy reduction in dataset distillation presents exciting avenues for advancement. Improving color allocation strategies is paramount; the current method, while effective, may benefit from a more sophisticated approach that dynamically adjusts color depth based on class-specific characteristics. Exploring dynamic color depth allocation is a crucial next step. This would address the limitation of a fixed color reduction across all classes, allowing for finer control and potentially improving overall performance. Investigating alternative loss functions beyond the maximum color loss and palette balance loss could also yield improvements. Ultimately, further research into the interplay between color representation and model performance could unlock greater efficiency in training large-scale models. Finally, extending the methodology to other data modalities beyond images, such as video or 3D point clouds, would broaden its applicability and impact.
More visual insights#
More on figures

This figure visualizes the effect of color condensation on images. (a) shows original images at different bit depths (8, 6, 3, 1-bit), demonstrating the reduction in color information. (b) and (c) display color-condensed synthetic images generated by the proposed AutoPalette model. (b) uses the full model, including the palette loss, while (c) omits the palette loss. The color palettes accompanying each set of images show how the model allocates colors, with a larger variation in color usage indicating more efficient color utilization.
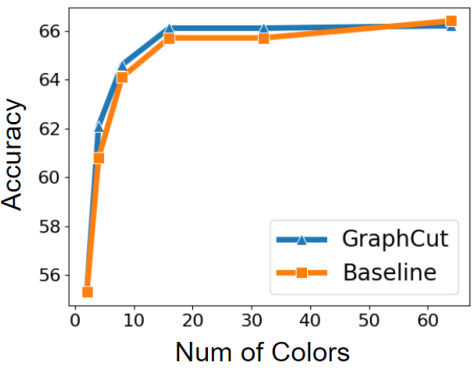
This figure shows a comparison of the performance of two different initialization methods: one using a submodular color diversity approach (GraphCut) and the other using randomly selected real images (Baseline). The x-axis represents the number of colors used in the quantized images, while the y-axis shows the accuracy achieved. The graph illustrates how the submodular color diversity initialization generally outperforms random initialization, especially when using a lower number of colors. This highlights the effectiveness of the proposed color-guided initialization in improving model performance by selecting more diverse images during the initialization stage.

This figure provides a high-level overview of the AutoPalette framework, which consists of two main stages: initialization and training. The initialization stage uses information gain to select representative images with low color redundancy from the dataset. These images are then used to train a palette network. The training stage involves passing synthetic data through the palette network to obtain color-reduced images. The network’s objective function includes several components to balance color utility and minimize dataset redundancy.

This figure shows a visualization of the color-condensed synthetic images generated by the AutoPalette framework for the CIFAR-10 dataset. ZCA whitening, a dimensionality reduction technique, has been applied to the images. Each small square represents a single image from the synthetic dataset, showcasing the visual characteristics after color reduction and data augmentation. The overall image provides a sense of the diversity and quality of the distilled dataset created by the proposed method.

This figure shows the effect of the proposed AutoPalette method on color reduction. Subfigure (a) displays the same image with different bit depths (8, 6, 3, and 1), representing different levels of color quantization. Subfigures (b) and (c) show the synthetic images generated by AutoPalette with and without the palette loss, respectively. The color palettes for each image are also shown, with larger differences between palette rows indicating more efficient color utilization.

This figure shows a comparison of images at different bit depths (8, 6, 3, and 1-bit), demonstrating the effect of color condensation. Subfigures (b) and (c) present examples of synthetic images generated by the AutoPalette model, with (b) using the full model and (c) excluding the palette loss. The color palettes for each image are also displayed, illustrating that a wider range of colors in the palette corresponds to better color utilization.

This figure shows the effect of the proposed AutoPalette model on color reduction. (a) shows images at different bit depths (8,6,3,1), demonstrating the progressive reduction in color information. (b) displays color-condensed synthetic images generated by the full AutoPalette model, showcasing the preserved key features despite fewer colors. (c) shows results when the palette loss is removed, highlighting the importance of this component for efficient color utilization. The variation in color palette row heights visually represents the model’s efficiency in distributing colors.

This figure visualizes the effect of reducing the number of bits used to represent colors in images. (a) shows images with 8, 6, 3, and 1-bit color depth, demonstrating the significant loss of detail as the color depth decreases. (b) and (c) show the color-condensed synthetic images produced by the AutoPalette model with and without a palette loss, respectively, along with their associated color palettes. A larger difference between the colors in a palette signifies a more efficient use of the color space.

This figure shows a set of color-condensed synthetic images generated for the ImageFruit subset of the ImageNet dataset using the AutoPalette method. The images have a reduced color palette, aiming for efficient storage while preserving essential visual features. The reduced color palette is a key aspect of the AutoPalette approach, which seeks to minimize redundancy in the color space for improved efficiency.

This figure visualizes the effect of reducing the number of bits used to represent color in images. Subfigure (a) shows example images with 8, 6, 3, and 1 bits per color channel. Subfigures (b) and (c) display the color-condensed synthetic images generated by the AutoPalette model, with and without the palette loss respectively. The color palettes are shown alongside their corresponding images. A larger difference in color values within a palette suggests more effective color utilization by the model.

This figure shows a collection of 64 synthetic images generated for the ImageWoof dataset using the AutoPalette method. The images have been condensed to a reduced color palette, which aims to reduce storage space while preserving essential image features. Each image represents a different class within the ImageWoof dataset, and the overall visual quality demonstrates the effectiveness of the color reduction technique in preserving relevant details despite the reduced color information.

This figure visualizes the effect of reducing the number of bits used to represent color in images. Panel (a) shows example images at different bit depths (8, 6, 3, and 1). Panels (b) and (c) show the color-condensed synthetic images generated by the proposed method (AutoPalette). Panel (b) shows the results with the full model (including the palette loss), and panel (c) shows the results when the palette loss is removed. The color palettes show that using the palette loss results in a better distribution of colors across the palette (larger differences among rows). This indicates a more effective use of the limited color space.
More on tables

This table compares the performance of different parameterization methods (TM, HaBa, FrePo, SPEED, and AutoPalette) on six subsets of ImageNet. The results show the test accuracy for each method on each ImageNet subset, with each experiment using a CIFAR10 setting and an IPC (Images Per Class) value of 10. AutoPalette consistently shows strong performance, often outperforming the other methods.

This table shows the ablation study results on the effectiveness of each loss component (Lm, Lb, La) in the AutoPalette framework. It demonstrates the impact of removing each loss function individually on the model’s accuracy. The result shows that all three loss functions contribute significantly to the overall performance.

This table presents the results of an ablation study comparing different initialization methods for dataset distillation. The goal is to assess the impact of using quantized images versus full-color images on the performance of a color-guided initialization strategy that selects images with diverse structures. Three methods are compared: random selection of real images, graph cut-based selection of real images, and graph cut-based selection of quantized images. The metric used is the test accuracy achieved by the models trained on the resulting distilled datasets. The table shows that the proposed method of using graph cut on quantized images achieves the highest accuracy.
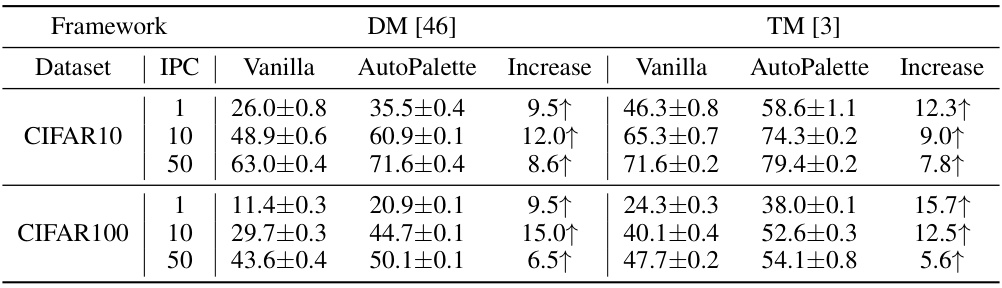
This table presents the test accuracy results achieved by applying the proposed AutoPalette method to two different dataset distillation frameworks (DM and TM) across various image per class (IPC) settings, using ConvNetD3 as the backbone network for both CIFAR10 and CIFAR100 datasets. It compares the performance of the vanilla versions of these frameworks against the versions that incorporate AutoPalette, highlighting the increase in accuracy obtained by using AutoPalette.

This table presents the test accuracy results achieved by different dataset distillation methods on the ConvNet D3 model. The synthetic images used in our method were reduced from 256 colors to 64 colors. The results demonstrate that our proposed method outperforms existing methods and sets a new state-of-the-art in terms of accuracy. The table is organized by the type of distillation method used, with Coreset, Dataset Distillation, and Parameterization-based methods listed separately. For each method, results are presented for different numbers of images per class (IPC) on both CIFAR10 and CIFAR100 datasets.

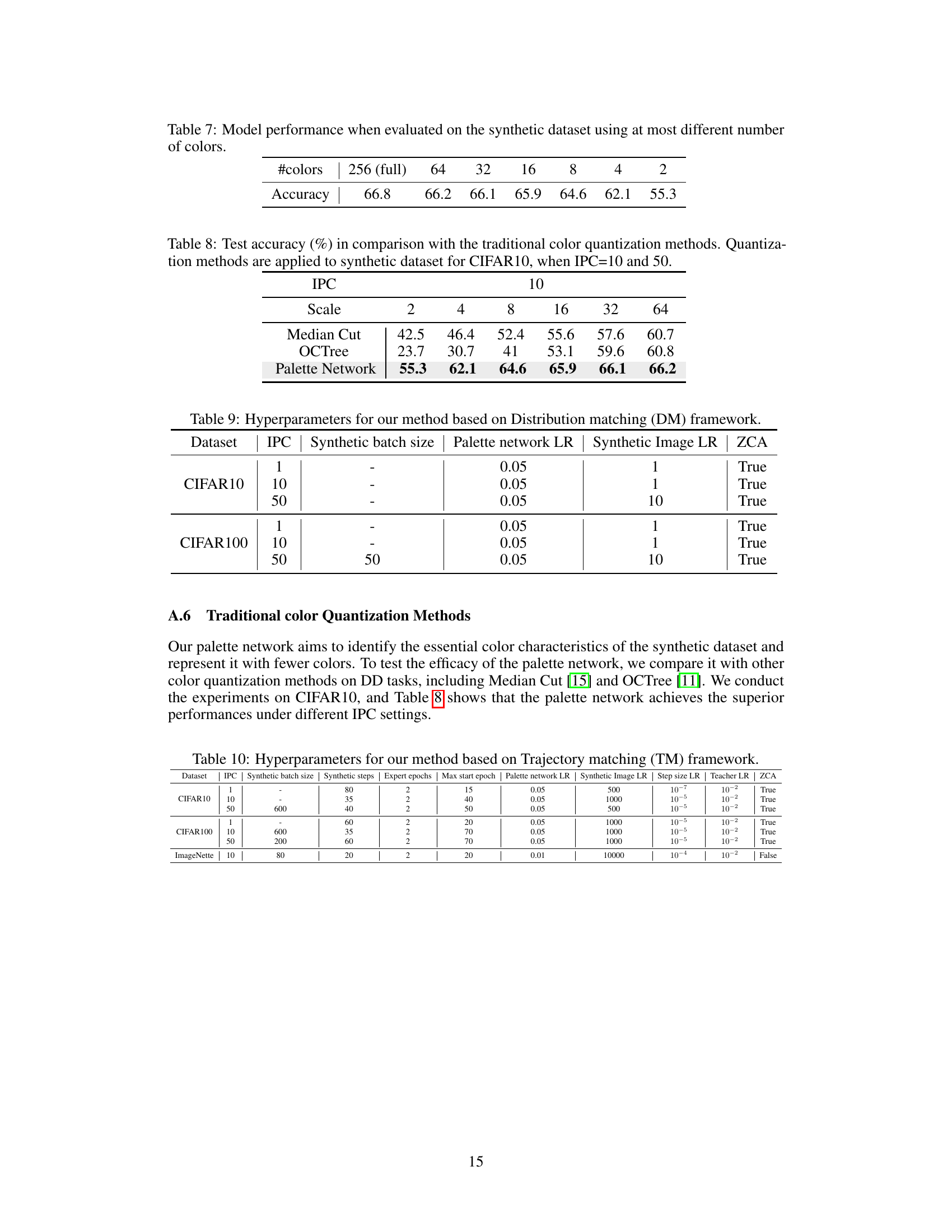
This table shows the impact of reducing the number of colors in the synthetic images on model accuracy. The accuracy is tested on different numbers of colors (256, 64, 32, 16, 8, 4, 2), demonstrating the trade-off between storage efficiency and model performance. As expected, reducing the number of colors reduces the accuracy, but only to a certain point before it drops significantly.

This table compares the performance of the proposed palette network against traditional color quantization methods (Median Cut and OCTree) on the CIFAR10 dataset. The comparison is done for different numbers of colors (2, 4, 8, 16, 32, 64) used in the color quantization process, keeping the images per class (IPC) at 10 and 50. It demonstrates the superior performance of the palette network in preserving image fidelity and accuracy during dataset distillation.

This table compares the test accuracy of different dataset distillation methods on ConvNet D3, using CIFAR10 and CIFAR100 datasets. The synthetic images generated by the proposed AutoPalette method uses only 64 colors, while the original datasets have 256 colors. The results show that AutoPalette achieves superior performance compared to existing methods.

This table presents the test accuracy achieved by different dataset distillation methods on the ConvNet D3 model. The synthetic images used in the proposed method were reduced from 256 colors to 64 colors. The results show that the proposed method outperforms existing methods and achieves state-of-the-art performance.
Full paper#