↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Many large language models (LLMs) struggle to fully utilize information within long contexts, a phenomenon known as the “lost-in-the-middle” problem. This limitation stems from insufficient explicit supervision during training, which fails to adequately emphasize the importance of information at all positions within the long context. This inability to effectively use all contextual information significantly hinders the development of truly effective and robust long-context LLMs.
This paper introduces Information-Intensive (IN2) training, a novel data-driven solution to overcome the “lost-in-the-middle” problem. IN2 training leverages a synthesized long-context question-answer dataset, forcing the model to utilize information from various positions within the long context. The results demonstrate that FILM-7B, a model trained using IN2, significantly improves long-context information retrieval performance across various context styles and retrieval patterns. Furthermore, FILM-7B shows comparable or improved performance on real-world long-context tasks while maintaining comparable performance on short-context tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the significant challenge of “lost-in-the-middle” in long-context LLMs. It introduces a novel data-driven training method (IN2) that significantly improves the ability of LLMs to utilize information from all positions within long contexts, not just the beginning and end. This addresses a major bottleneck in developing truly effective long-context LLMs and opens exciting avenues for future research in improving LLM context utilization and downstream tasks performance.
Visual Insights#

This figure presents the results of three probing tasks designed to assess the ability of different LLMs to utilize long contexts. The x-axis represents the relative position of information within a long context (800 sentences, 800 functions, or 750 entities). The y-axis shows the performance (%). FILM-7B (the model introduced in this paper), Mistral-7B-Instruct-v0.2 (a baseline model), and GPT4-Turbo (a strong commercial model) are compared. The results demonstrate that FILM-7B significantly outperforms the baselines in retrieving information from various positions within the long context, especially in the middle of the context, thus addressing the ’lost-in-the-middle’ challenge.
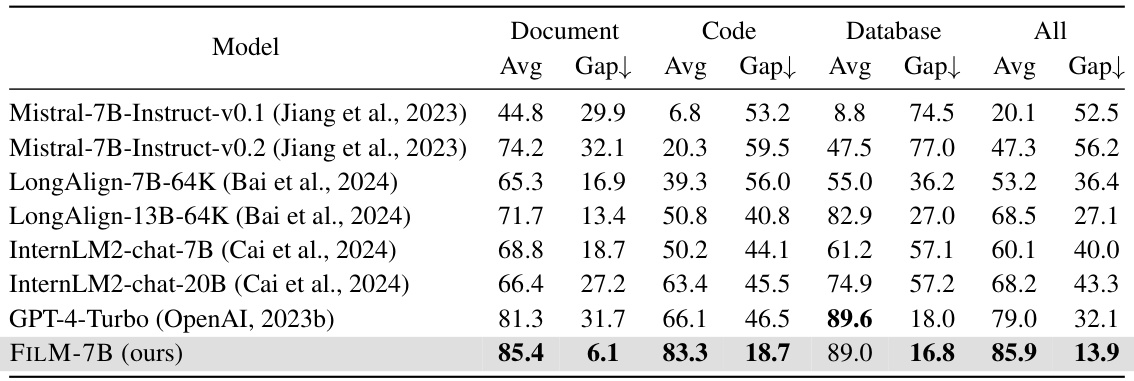
This table presents a quantitative comparison of various language models’ performance on the VAL (Various Long-context) Probing tasks. The VAL Probing tasks evaluate a model’s ability to utilize information across various context types (document, code, database) and retrieval patterns (forward, backward, bidirectional). The table shows the average performance (Avg) and the gap between maximum and minimum performance (Gap) across different relative positions of the information within the context. A smaller gap indicates greater robustness in information retrieval across the context.
In-depth insights#
Contextual Loss#
Contextual loss in large language models (LLMs) refers to the phenomenon where the model struggles to utilize information present in the middle of a long input sequence. This is a significant challenge because it limits the model’s ability to process and reason with extensive contextual information. Several factors contribute to contextual loss, including the architecture of the model, specifically limitations in the attention mechanisms that may fail to effectively weigh long-range dependencies. Also, training data biases might play a role; models may learn to prioritize information at the beginning and end, neglecting the middle. Moreover, the training process itself could lead to contextual loss, due to the way the model is optimized during training. Overcoming this limitation requires addressing these underlying causes through advanced architectural designs, careful data curation strategies, and innovative training methodologies that ensure the model effectively processes and integrates information throughout the entire input sequence. Research into techniques like improved attention mechanisms, position encodings, and specialized training paradigms offers promising avenues for mitigating contextual loss and unlocking the full potential of LLMs to leverage comprehensive contexts.
IN2 Training#
The core concept of “IN2 Training” revolves around intensifying the learning process for Large Language Models (LLMs) to better utilize long-context information. The method tackles the “lost-in-the-middle” problem where LLMs struggle to fully leverage information present beyond the beginning and end of a long input. Instead of relying solely on general training data, IN2 employs a synthesized dataset of long-context question-answer pairs. These pairs are strategically constructed to ensure that crucial information isn’t just located at the beginning or end but distributed throughout the input. This is achieved by integrating segments of varied context styles (document, code, structured data) and prompting the model to locate information at different positions, demanding nuanced retrieval patterns. The data-driven approach, coupled with the careful dataset design, aims to provide explicit supervision for the LLM, forcing it to recognize the importance of any given position in a lengthy context. This results in significantly improved performance on various long-context tasks while maintaining comparable results on short-context tasks.
VAL Probing#
The heading ‘VAL Probing’ suggests a novel and rigorous evaluation methodology for assessing the capabilities of large language models (LLMs) in handling long-context information. Instead of relying solely on existing benchmarks, which may have limitations in their design or focus, VAL Probing appears to offer a more multifaceted approach. The method likely involves diverse context types (document, code, structured data) and retrieval patterns (forward, backward, bidirectional) to create a more realistic and comprehensive evaluation. This holistic evaluation approach is crucial because it can expose weaknesses in an LLM’s ability to handle long contexts that may not be apparent using simpler or more limited tests. By addressing multiple context styles and retrieval tasks, VAL Probing moves beyond surface-level assessment of information recall to potentially uncover deeper issues related to information integration and reasoning within extended contexts. The focus on different retrieval patterns is especially insightful, as it helps differentiate between models that may excel in simple sequential tasks versus those with greater proficiency in complex, non-sequential information retrieval.
Long-context LLM#
Long-context LLMs represent a significant advancement in large language models, enabling the processing of significantly longer input sequences. This addresses a key limitation of earlier LLMs, which struggled with the “lost-in-the-middle” problem—the inability to effectively utilize information beyond the immediate context window. The core challenge lies in training these models effectively, requiring substantial data and computational resources. While increasing context window size is crucial, simply expanding the window is insufficient. Methods such as specialized attention mechanisms and improved positional encodings are being explored to mitigate the “lost-in-the-middle” problem and fully leverage long-context information. The development of effective training strategies remains a primary focus, including techniques to emphasize information at all positions within the extended context. The ultimate goal is to create LLMs that can robustly and reliably process extensive amounts of information to facilitate more complex and nuanced reasoning tasks, improving performance on downstream applications like question-answering and summarization.
Future Work#
Future work in this area could explore several promising directions. Extending IN2 training to other LLMs and exploring variations of the training data would demonstrate the generalizability and robustness of the approach. It would be beneficial to conduct a thorough investigation into the impact of different hyperparameters on model performance, potentially revealing optimal configurations for improved long-context utilization. Further research is warranted to investigate the interaction between IN2 training and other techniques for enhancing long-context performance. For instance, combining IN2 training with advanced attention mechanisms or novel positional encoding schemes might yield synergistic improvements. Finally, a more comprehensive evaluation across diverse downstream tasks and model sizes would offer strong evidence of the effectiveness of IN2 training in practical applications. Analyzing the impact of IN2 training on specific types of reasoning (e.g., deductive, inductive, abductive) and its influence on different context styles would provide further valuable insights into its effectiveness.
More visual insights#
More on figures

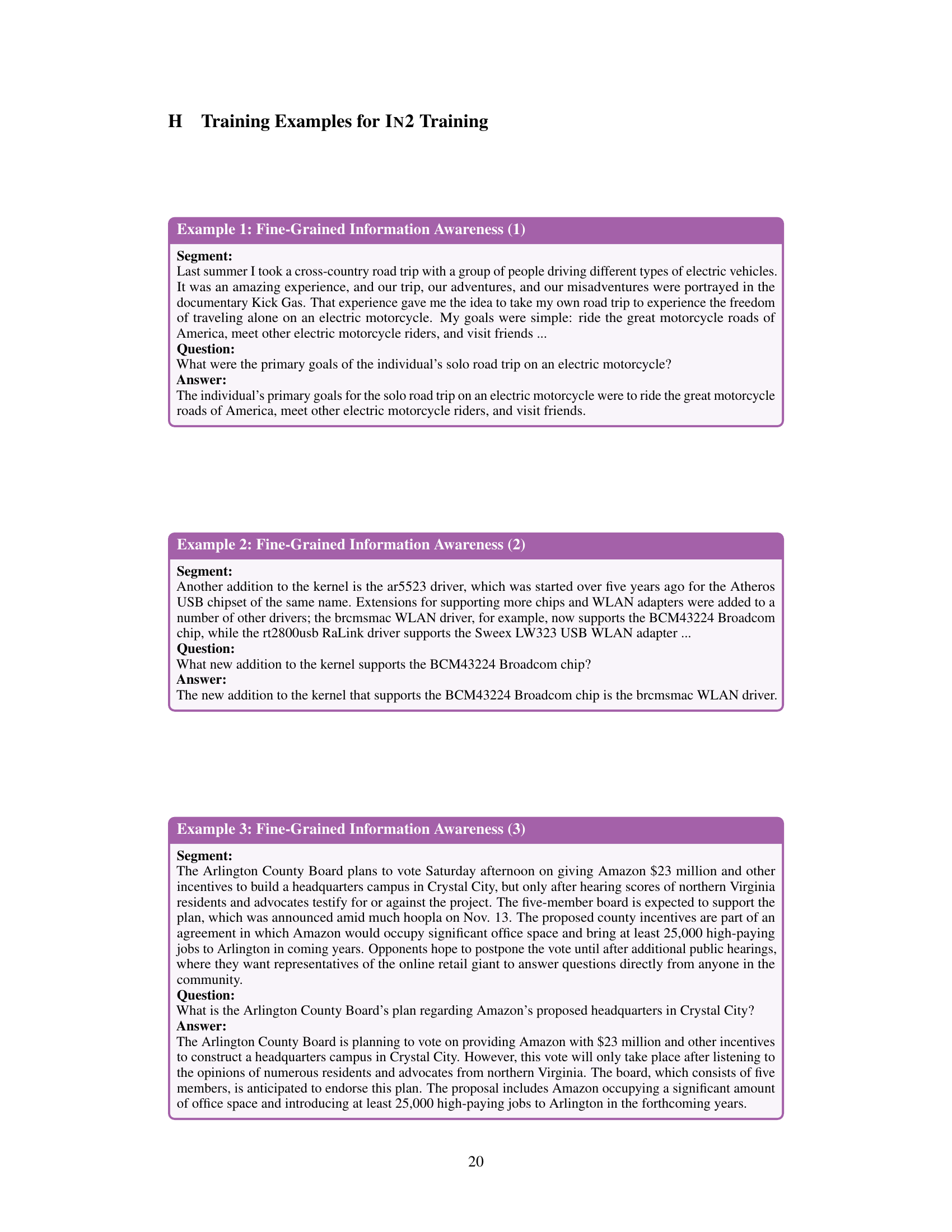
This figure illustrates the process of creating the dataset for Information-Intensive (IN2) training. The top half shows the creation of question-answer pairs focusing on fine-grained information awareness. A raw text is split into 128-token segments. One segment is used to prompt GPT-4 to generate a question and answer focusing only on the information within that segment. This QA pair, along with other randomly selected segments, forms the long context. The bottom half shows the generation of QA pairs focused on integration and reasoning. Multiple segments are selected, and GPT-4 is prompted to generate a QA pair requiring integration of information across these segments. Again, the generated QA pair is combined with randomly selected segments to create the long context. The goal is to create data where the answer requires information from specific positions within a long context, forcing the model to fully utilize all information.

This figure displays the performance of three different large language models (FILM-7B, Mistral-7B-Instruct-v0.2, and GPT4-Turbo) on three probing tasks designed to evaluate their ability to utilize information from various positions within a long context. The x-axis represents the relative position of the information within the context, while the y-axis shows the performance (likely accuracy or F1 score). The results indicate that FILM-7B significantly outperforms the other two models, especially in retrieving information from the middle of the context, demonstrating its improved ability to avoid the ’lost-in-the-middle’ problem.

This figure displays the performance of three different large language models (FILM-7B, Mistral-7B-Instruct-v0.2, and GPT4-Turbo) on three probing tasks designed to evaluate their ability to utilize information from long contexts. The x-axis represents the relative position of the information within the context, and the y-axis represents the performance. FILM-7B shows a significant improvement over the other models, particularly in retrieving information from the middle of the long context, thus addressing the ’lost-in-the-middle’ problem.
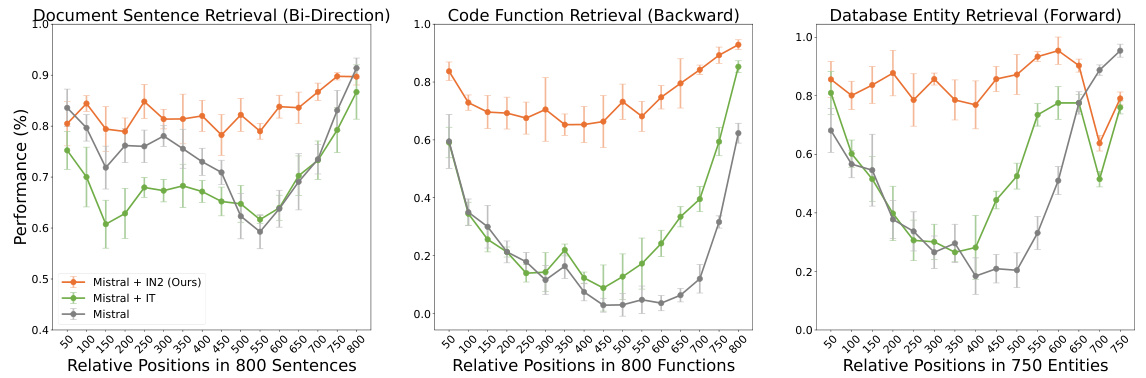
This figure compares the performance of the Information-Intensive (IN2) training method with standard instruction tuning (IT) on three probing tasks. Both methods used the same number of training examples (20% of the full dataset, or 300,000 examples). The results show that IN2 training significantly improves performance, especially in addressing the lost-in-the-middle problem, whereas instruction tuning provides only marginal and inconsistent improvements.
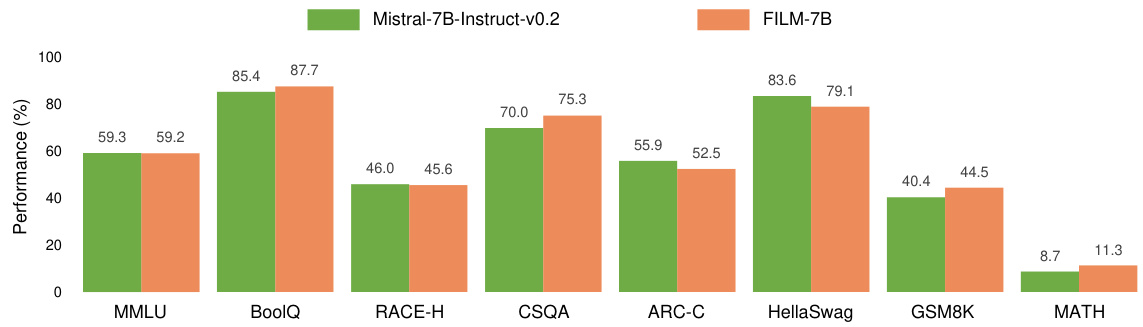
This figure shows the performance comparison between FILM-7B and its base model, Mistral-7B-Instruct-v0.2, across eight common short-context tasks. The tasks include MMLU, BoolQ, RACE-H, CSQA, ARC-C, HellaSwag, GSM8K, and MATH. The bar chart visually represents the accuracy achieved by each model on each task, highlighting whether FILM-7B maintains or improves upon the performance of the base model on these tasks that are typically used to evaluate general language model capabilities.

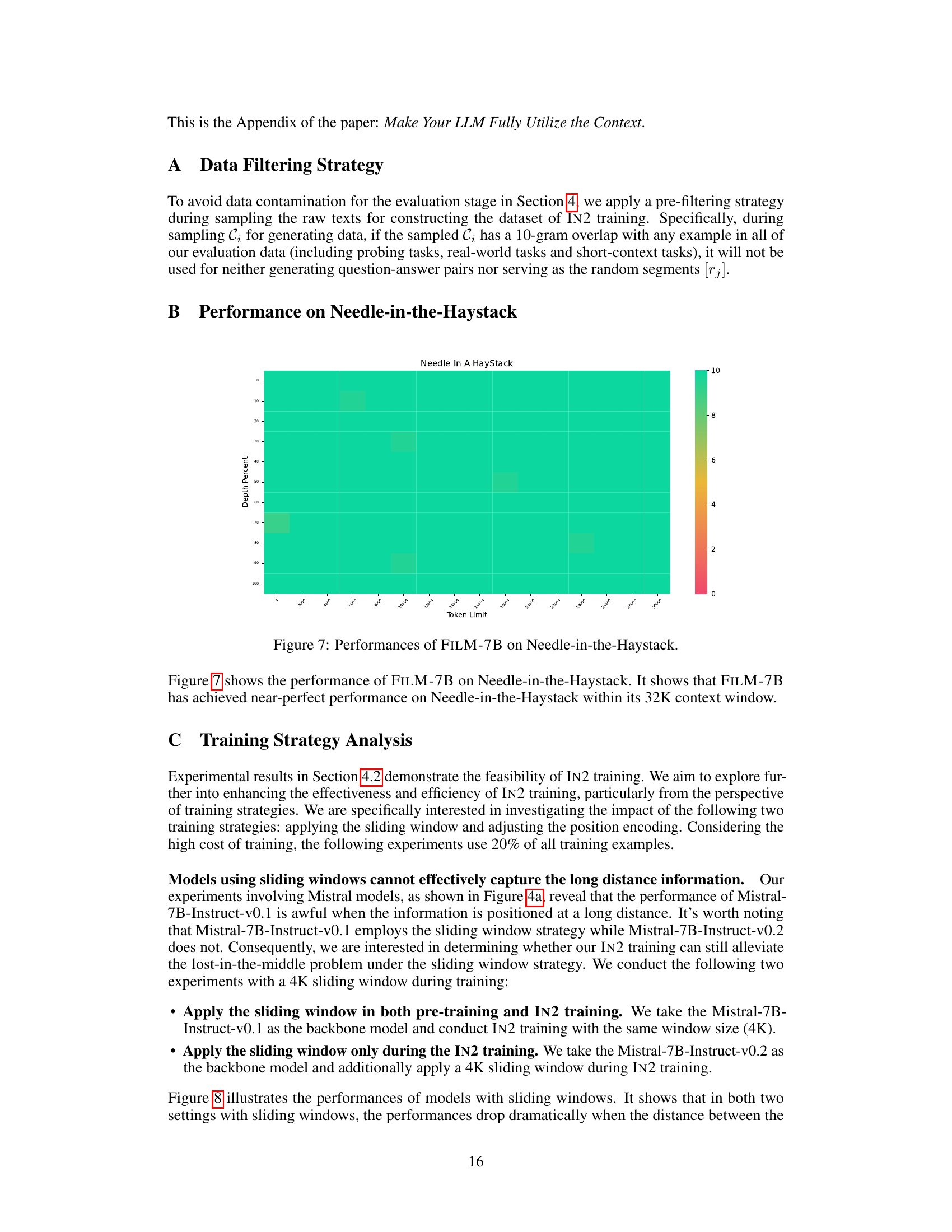
This heatmap visualizes the performance of the FILM-7B model on the Needle-in-the-Haystack task. The x-axis represents the token limit (length of the context), while the y-axis shows the depth percent (the relative position of the answer within the context). The color intensity represents the model’s accuracy in finding the answer. Darker colors indicate better performance. This figure demonstrates that FILM-7B achieves near-perfect performance on this task, even with a long context window.
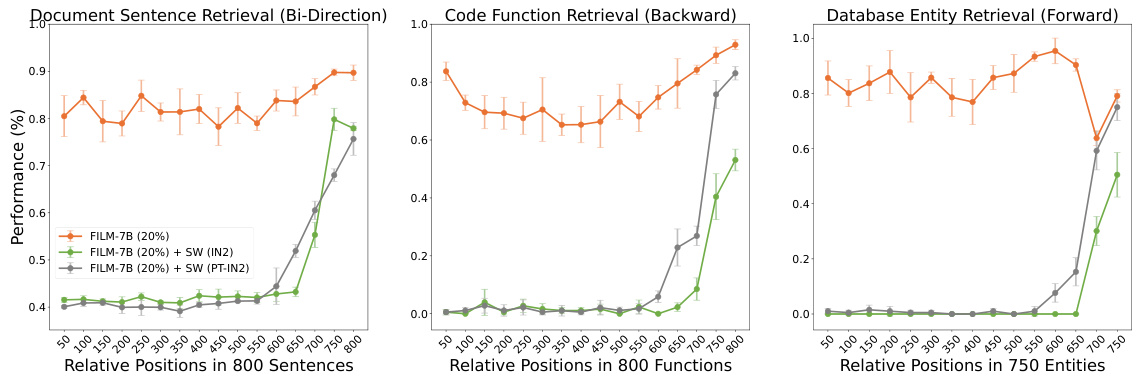
This figure shows the performance comparison of FILM-7B under different training strategies with a 4K sliding window. The x-axis represents the relative positions of information in the context. The y-axis represents the performance. Three lines represent three training strategies: FILM-7B (20%) without a sliding window; FILM-7B (20%) + SW (IN2), applying the sliding window during IN2 training only; and FILM-7B (20%) + SW (PT-IN2), applying the sliding window during both pre-training and IN2 training. The results demonstrate that using sliding windows during training significantly hurts the model’s ability to retrieve information, especially when the distance between the retrieval keyword and the information exceeds the sliding window size.

This figure shows the performance of FILM-7B model with 64K context window length on a document sentence retrieval task (bi-directional retrieval). The x-axis represents the relative positions of the sentences in the context and y-axis represents the performance in terms of percentage. Two models are being compared, FILM-7B and Mistral-7B-Instruct-v0.2. The position embeddings of FILM-7B are extended using YaRN (Yet Another Retrieval Network) technique to handle longer contexts. The figure demonstrates that FILM-7B significantly outperforms the baseline Mistral model, especially in the middle sections of the long context, indicating the effectiveness of the FILM-7B model in addressing the ’lost-in-the-middle’ problem.
More on tables

This table compares the performance of the Mistral-7B-Instruct-v0.2 model after undergoing two different training methods: Information-Intensive (IN2) training and normal instruction tuning. The comparison is quantified using average scores and the difference between the maximum and minimum performance across three probing tasks (Document, Code, Database) and overall. It highlights the effectiveness of IN2 training in improving the model’s performance, particularly in reducing the performance gap between different context positions.
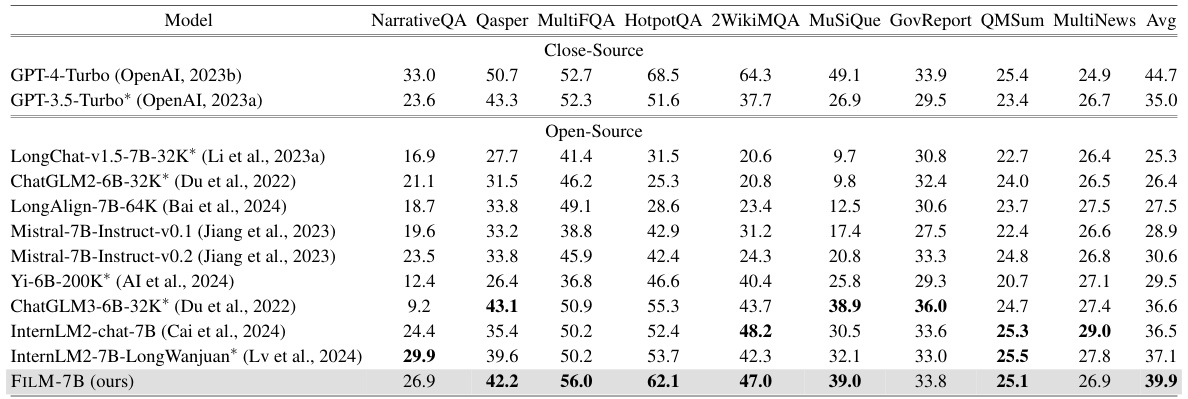
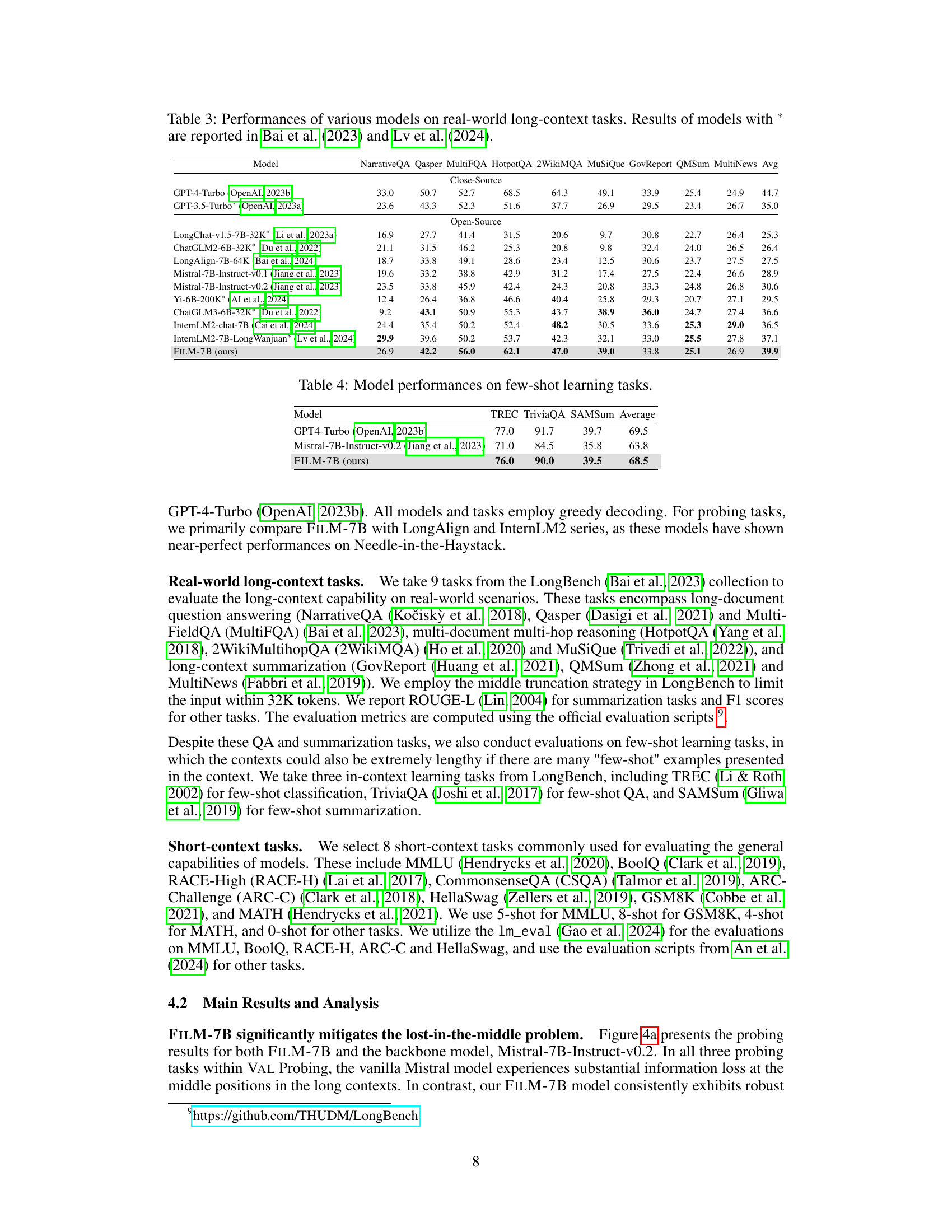
This table presents the performance comparison of various language models on nine real-world long-context tasks. These tasks cover diverse areas like question answering, multi-hop reasoning, and summarization. The table allows a quantitative assessment of the models’ abilities to handle long-context information across different problem types.

This table compares the performance of three different language models (GPT-4-Turbo, Mistral-7B-Instruct-v0.2, and FILM-7B) on three few-shot learning tasks: TREC, TriviaQA, and SAMSum. The ‘Average’ column provides the mean performance across all three tasks. The results show that FILM-7B, despite being an open-source model, achieves comparable performance to GPT-4-Turbo, a proprietary model, highlighting its effectiveness.
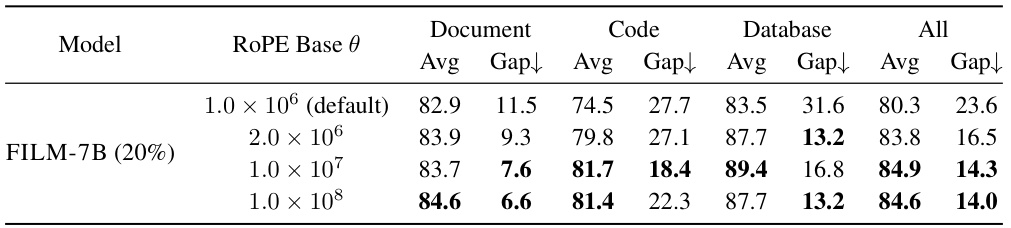
This table presents the results of experiments conducted to analyze the impact of different RoPE (Rotary Position Embedding) base values on the performance of the FILM-7B model during IN2 (Information-Intensive) training. The table shows the average performance (Avg) and the difference between the maximum and minimum performance (Gap) across various probing tasks (Document, Code, Database). The results demonstrate how varying the RoPE base affects the model’s ability to handle long-context information, particularly its robustness across different positions in the context. The experiment uses 20% of the training data for IN2 training and a 4K sliding window.
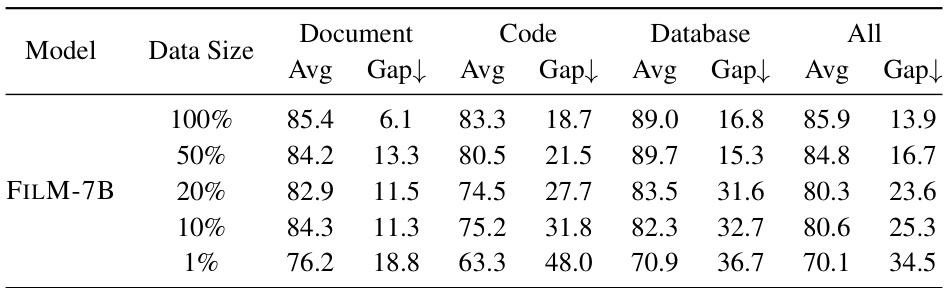
This table presents the results of the FILM-7B model trained with varying amounts of data using the IN2 training method. It shows the average scores (Avg) and the difference between the maximum and minimum scores (Gap) across three probing tasks: Document, Code, and Database. The results are broken down by the percentage of the full training data used (1%, 10%, 20%, 50%, and 100%). The ‘Gap’ metric indicates the robustness of the model’s performance across different positions within the long context.

This table presents the performance of various 7B parameter scale language models on the RULER benchmark. The RULER benchmark is designed to evaluate the effective context length of language models, which is the maximum context length that a model can effectively utilize. The table shows the claimed context window size of each model and its effective context window size as determined by the RULER benchmark. The performance of each model is reported for various context lengths, from 4K to 128K tokens. The performance exceeding the Llama2-7B performance at context length 4K is underlined. This table highlights the ability of FILM-7B to handle longer contexts compared to other models.
Full paper#