↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision Transformers (ViTs) are widely used but have a fixed architecture, limiting their applicability across devices with varying computational capabilities. Existing model compression techniques lack the flexibility to efficiently generate models of diverse sizes. Furthermore, pre-training methods require multiple training sessions for different sizes, increasing costs. This necessitates a more efficient and flexible approach to creating ViT models for various resource constraints.
This paper proposes linearly decomposing a ViT into basic components called “learngenes.” These learngenes are trained incrementally, and they can then be recombined to generate ViTs with different sizes, achieving comparable or better performance than conventional methods. This decomposition-recomposition strategy reduces computational costs because large datasets are trained on only once. Experiments validate that ViTs can be efficiently decomposed and recomposed into diverse-scale models, demonstrating improved performance and cost savings.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel and efficient method for creating diverse-scale Vision Transformer models. This addresses a critical limitation of existing ViT architectures—their fixed size—making them unsuitable for deployment across various devices and computational settings. The proposed decomposition-recomposition strategy offers a flexible and economical approach, reducing the need for repeated training on massive datasets. This opens up several avenues for future research, including exploring different decomposition techniques and applying this approach to other architectures.
Visual Insights#
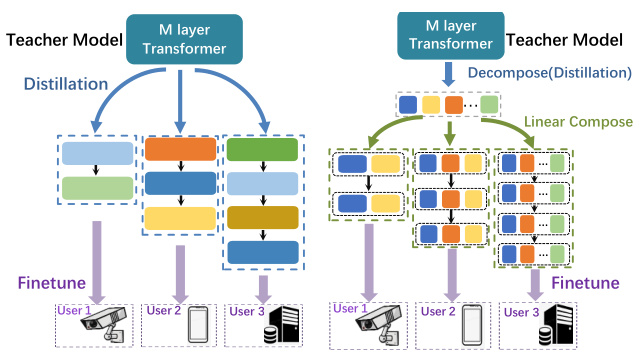
This figure compares the knowledge distillation (KD) approach with the proposed method for creating diverse-scale models. KD requires multiple training sessions with a teacher model to produce different-sized models for various clients. The new method only requires single training session to decompose a teacher model into learngenes (basic components). These learngenes can be recombined flexibly to generate models with different numbers of layers, accommodating various computational resource limitations.
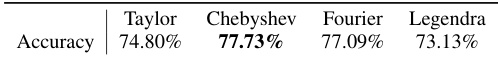
This table presents the accuracy results of Vision Transformers (ViTs) when different polynomial decomposition coefficients (Taylor, Chebyshev, Fourier, Legendre) are used. The table demonstrates the impact of the coefficient choice on the final performance of the model, showing that the Chebyshev polynomial achieves the best accuracy.
In-depth insights#
Linear ViT Decomp#
The concept of “Linear ViT Decomp” suggests a method for decomposing Vision Transformers (ViTs) linearly, potentially leveraging techniques from linear algebra or calculus to break down the complex model into smaller, more manageable components. This approach likely aims to improve efficiency in training, storage, and deployment by reducing model size while preserving accuracy. A linear decomposition scheme offers advantages over non-linear methods in terms of simplicity and interpretability, allowing for easier analysis of individual components and their contributions to the overall model performance. However, such a strategy might sacrifice expressiveness if the inherent non-linearity of ViTs is fundamentally crucial for their performance. The success hinges on carefully choosing the decomposition basis and ensuring that recombination maintains the original model’s accuracy. The method could potentially enable flexible model scaling, adapting ViT architectures to varying resource constraints, and might unlock techniques for incremental training where components are trained iteratively, potentially reducing overall training time and computational cost.
Learngene Training#
Learngene training is a novel approach to efficiently train Vision Transformers (ViTs) by decomposing the model into smaller, independent components called learngenes. This decomposition allows for incremental training, where each learngene is trained sequentially, significantly reducing computational cost compared to training the entire model at once. The process begins by decomposing a pre-trained ViT into learngenes using a linear combination of Chebyshev polynomials. Each learngene encapsulates specific knowledge of the original ViT, allowing for flexible recombination later. The sequential training of learngenes is a crucial aspect, focusing on one at a time while freezing the previously learned ones. This strategy not only improves training efficiency but also allows for the creation of varied-scale ViTs by combining a selective number of learngenes, catering to diverse resource requirements. This method offers a significant advancement over traditional methods like model compression which require repetitive training and lack the flexibility to create diverse model sizes. The final recombination step uses these learned learngenes to easily initialize ViTs of varying depths without additional heavy training, maintaining or improving performance compared to standard methods.
Recomposition Flex#
The concept of “Recomposition Flex” in the context of vision transformers suggests a system capable of dynamically adapting to varying computational resource constraints. This is achieved by linearly decomposing a pre-trained ViT into modular components (learngenes), allowing for flexible recombination into models of diverse scales and depths. Flexibility is key, enabling deployment on resource-constrained devices without the need for repeated, costly training on large datasets. This contrasts sharply with traditional methods like model compression, which often involve retraining for each target size and lack this adaptability. The method’s success hinges on the effectiveness of the linear decomposition and the ability of the learngenes to maintain performance when recombined in different configurations. The efficiency gains could be substantial, particularly when compared to training multiple models from scratch, offering a significant advantage in practical applications.
Ablative Study#
An ablative study systematically evaluates the contribution of individual components or features within a model or system. It does this by progressively removing (or “ablating”) each component and measuring the resulting performance drop. This allows researchers to quantify the impact of each part, revealing which are essential for achieving good results and which are less important or even detrimental. Careful design is crucial: components should be ablated independently and the baseline model needs to be robust. The results of such a study often inform architectural decisions, leading to simpler, faster, or more efficient models by identifying and removing unnecessary components. Interpreting the results requires understanding how the ablated features interact with the others. A large performance drop may indicate a crucial component, but it could also be caused by an unexpected interaction. Therefore, ablative studies are more effective when used in conjunction with other analysis methods, potentially giving valuable insights into feature engineering or model optimization.
Future Works#
Future work could explore several promising avenues. Extending the linear decomposition framework to other vision architectures beyond ViTs, such as CNNs, would broaden the method’s applicability. Investigating alternative decomposition techniques, perhaps employing non-linear methods or incorporating adaptive coefficient learning, could enhance performance and flexibility. A crucial area for further study is developing more sophisticated learngene regularization strategies to prevent overfitting and improve generalization capabilities. Exploring different polynomial functions beyond Chebyshev polynomials, and developing methods for automatically selecting the optimal function based on the data, would further refine the decomposition process. Finally, a comprehensive analysis of the trade-offs between different learngene numbers and network depths would guide users in selecting the best architecture for specific resource constraints.
More visual insights#
More on figures

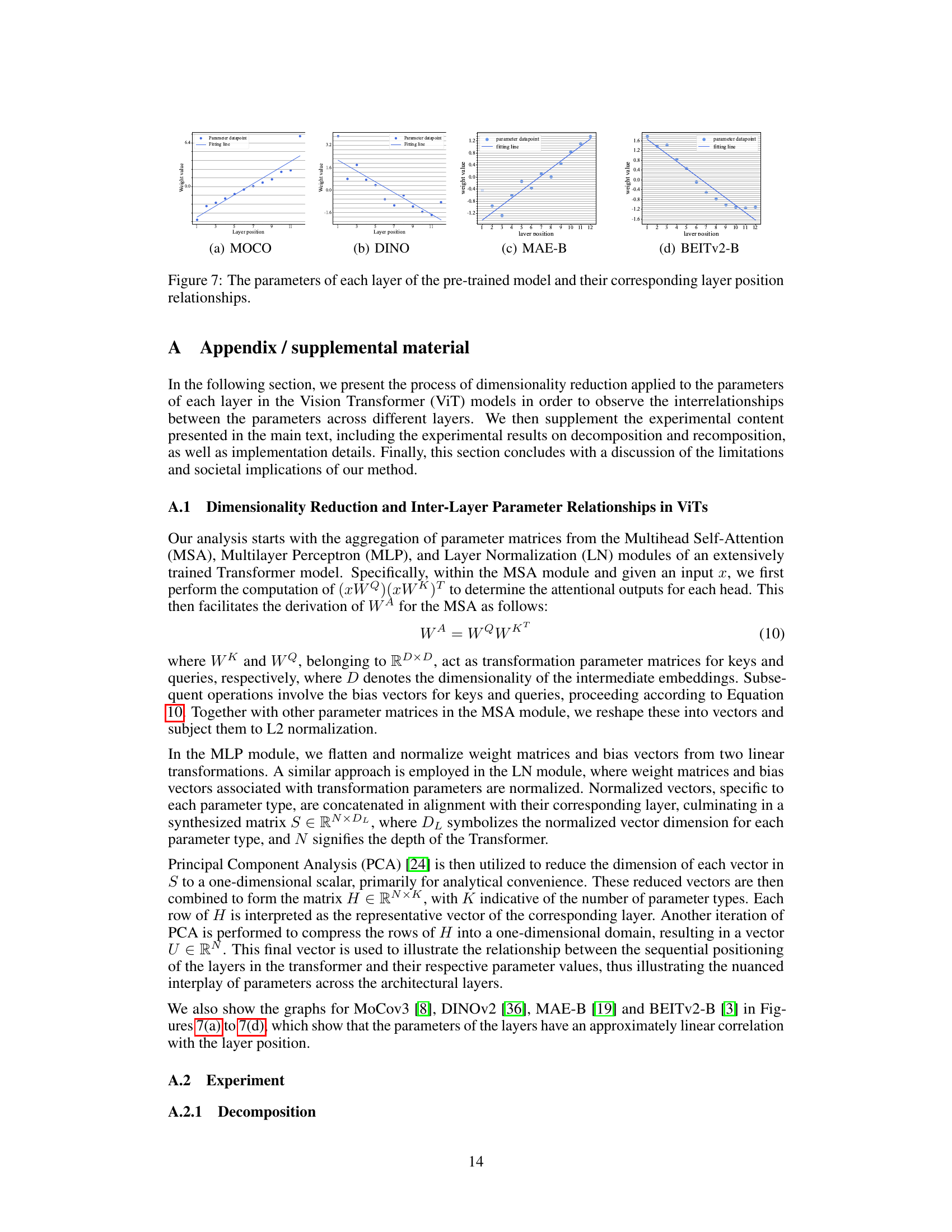
This figure shows the results of applying Principal Component Analysis (PCA) to reduce the dimensionality of the parameters in each layer of a well-trained Vision Transformer (ViT) model. The resulting plot demonstrates that there’s an approximately linear relationship between the parameters’ values and the layer’s position within the network’s architecture. This observation is discussed further in the supplementary materials of the paper, providing more context and detail regarding the PCA process and its implications for the proposed decomposition and recomposition strategy of the ViT model.

This figure illustrates the two-stage process of linearly decomposing a Vision Transformer (ViT) into learngenes and then recomposing them into ViTs with different depths. The decomposition process is shown in the upper part, while the recomposition process is shown in the lower part. Different training strategies are used for the recomposed ViTs, either with or without constraints on the learngene parameters.

This figure compares the performance of the proposed method (ICT) with DeiT-Base and SN-Net on ImageNet-1K. The left subplot shows that the accuracy of the proposed method increases with the number of learngenes used, surpassing that of SCT (simultaneous training) and eventually reaching a performance comparable to DeiT-Base. The right subplot compares the accuracy and the number of parameters with SN-Net, demonstrating that the proposed method achieves comparable or better accuracy with fewer parameters. This highlights the efficiency and effectiveness of the proposed decomposition strategy.

This figure illustrates the process of linearly decomposing a Vision Transformer (ViT) model into its basic components called learngenes, and then recomposing these learngenes to create ViT models with varying depths (number of layers). The decomposition happens iteratively, with one learngene added and trained at each step, while the previously trained learngenes remain fixed. The recomposition process demonstrates the flexibility to construct ViT models of different scales (number of layers) based on the availability of computational resources. Two example recomposition scenarios are shown: one without training constraints and the other with.

This figure compares the performance of Vision Transformers (ViTs) initialized using the proposed decomposition-recomposition method with pre-trained models and models generated by compression methods. Two variants of the proposed method are shown: one trained with constraints and one without. The results demonstrate the comparable or superior performance of the proposed method across various model sizes on different datasets.
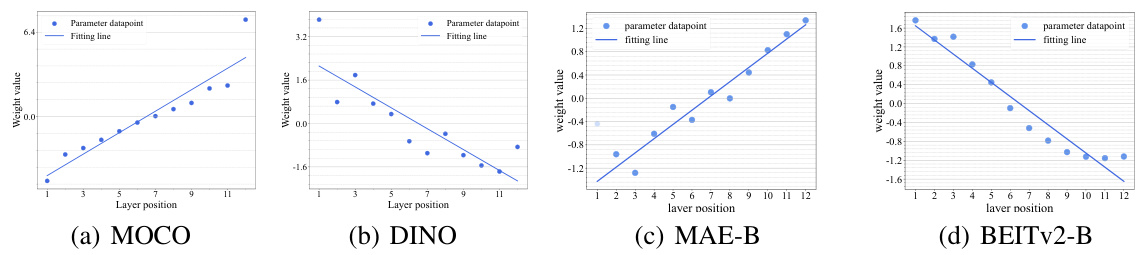
This figure displays four graphs, one for each of the four pre-trained models (MOCO, DINO, MAE-B, and BEITv2-B). Each graph shows the relationship between the layer position (x-axis) and the weight value (y-axis) obtained after applying dimensionality reduction to the parameters of each layer in each model. The graphs show that the parameters in most layers display an approximately linear correlation with layer position in well-trained ViTs.

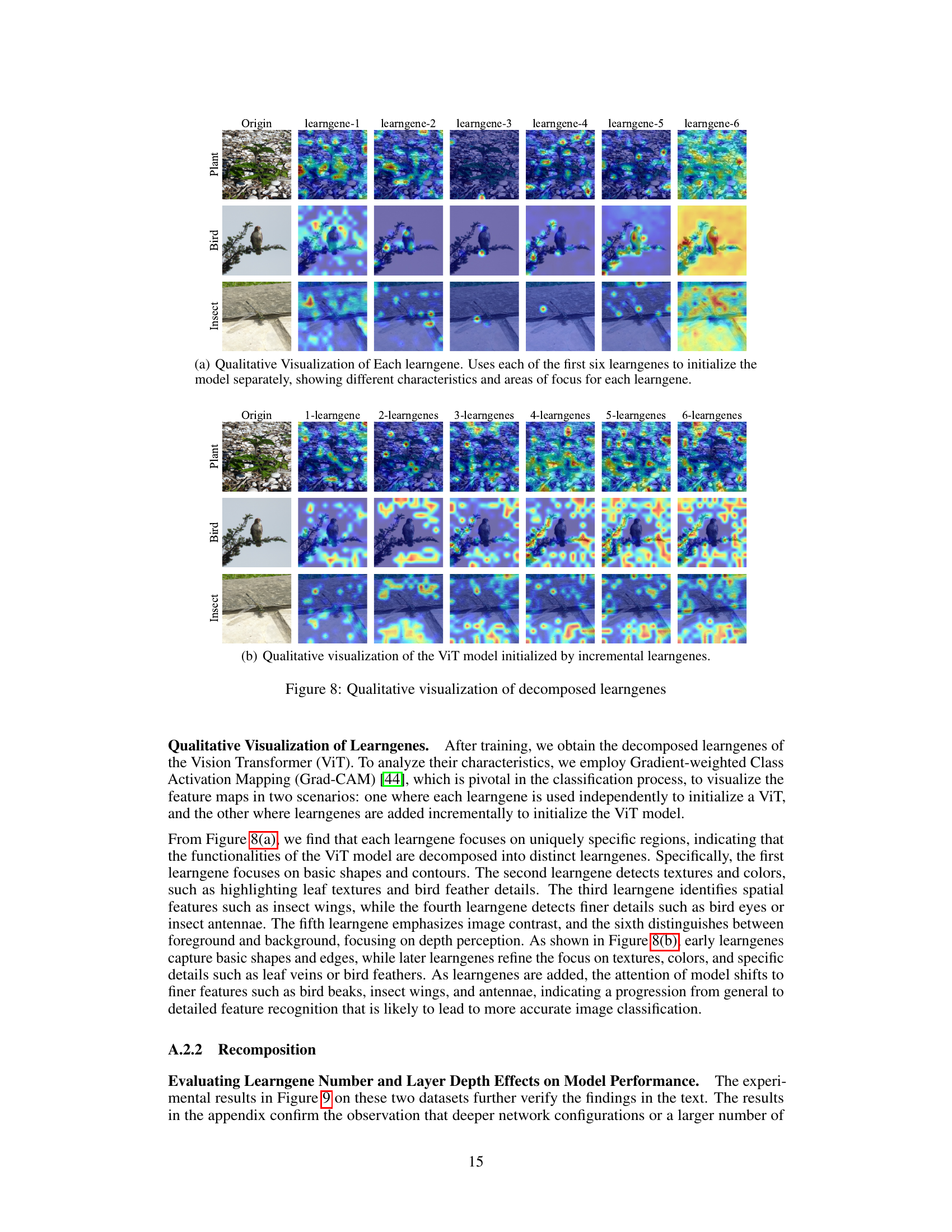
This figure visualizes the qualitative characteristics of the decomposed learngenes of the Vision Transformer (ViT) model. Grad-CAM [44] is used to show which parts of the image each learngene focuses on. The top row shows visualizations when each of the first six learngenes is used to initialize a ViT separately. The bottom row shows how the visualizations change as more learngenes are incrementally added. Early learngenes focus on basic shapes and contours. Later learngenes focus on finer details and unique features, demonstrating how the model’s attention to detail improves as more learngenes are incorporated.
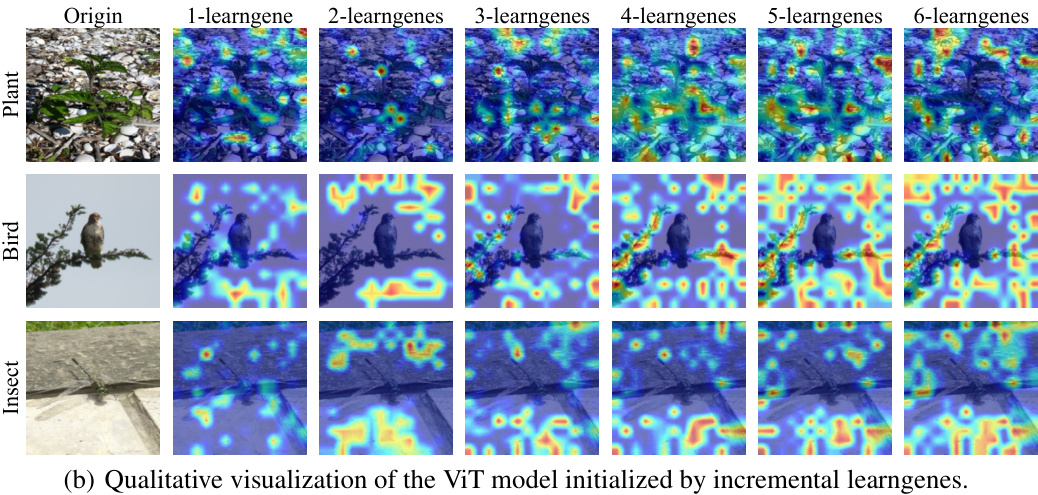
This figure visualizes the characteristics of decomposed learngenes using Grad-CAM. Part (a) shows each learngene initialized separately, highlighting different focuses (shapes, textures, colors, spatial features, contrast, background/foreground). Part (b) shows the incremental addition of learngenes, illustrating the shift from general to detailed features as more are included. This demonstrates how individual learngenes capture distinct aspects of the image leading to improved accuracy in image classification as more are used.

This figure illustrates the two-stage process of linearly decomposing a Vision Transformer (ViT) into learngenes and then recomposing them into ViTs with varying depths. The top half shows the decomposition where, in iterative steps, the ViT’s parameters are separated into multiple learngenes. Each stage only trains new learngenes while keeping previously trained ones frozen. The bottom half demonstrates recomposition, showing how to initialize ViTs of varying depths using these trained learngenes. Two cases are illustrated, one where training happens without layer parameter constraints, and the other where such constraints are in effect.

This figure illustrates the decomposition and recomposition process of the Vision Transformer (ViT) model. The top half shows how the ViT is incrementally decomposed into learngenes, training only the newly added ones at each stage while keeping the previously trained ones fixed. The bottom half presents two recomposition examples: one creating a 2-layer ViT from three learngenes (unconstrained), and another creating a 3-layer ViT from four learngenes (constrained). Flame icons represent trained parameters, while snowflake icons indicate frozen parameters.

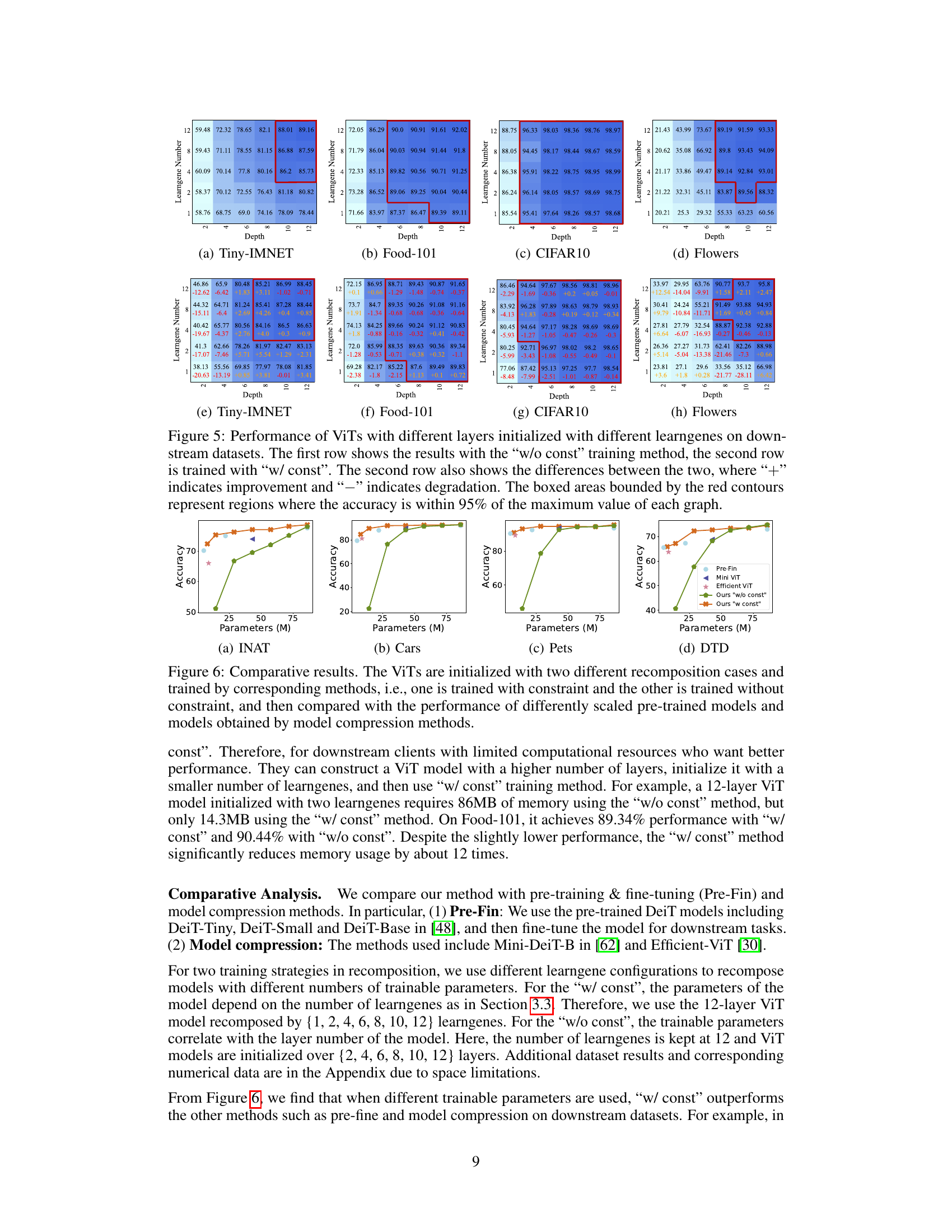
This figure visualizes the performance of Vision Transformers (ViTs) with varying numbers of layers and learngenes on various downstream datasets. It showcases the impact of the number of learngenes and the depth of the network on model accuracy. Each subfigure represents a different dataset, illustrating the trade-off between model complexity (number of layers and learngenes) and performance. The heatmaps show the performance for various combinations of learngenes and depths. The color intensity represents the accuracy, with darker shades indicating higher accuracy.
More on tables
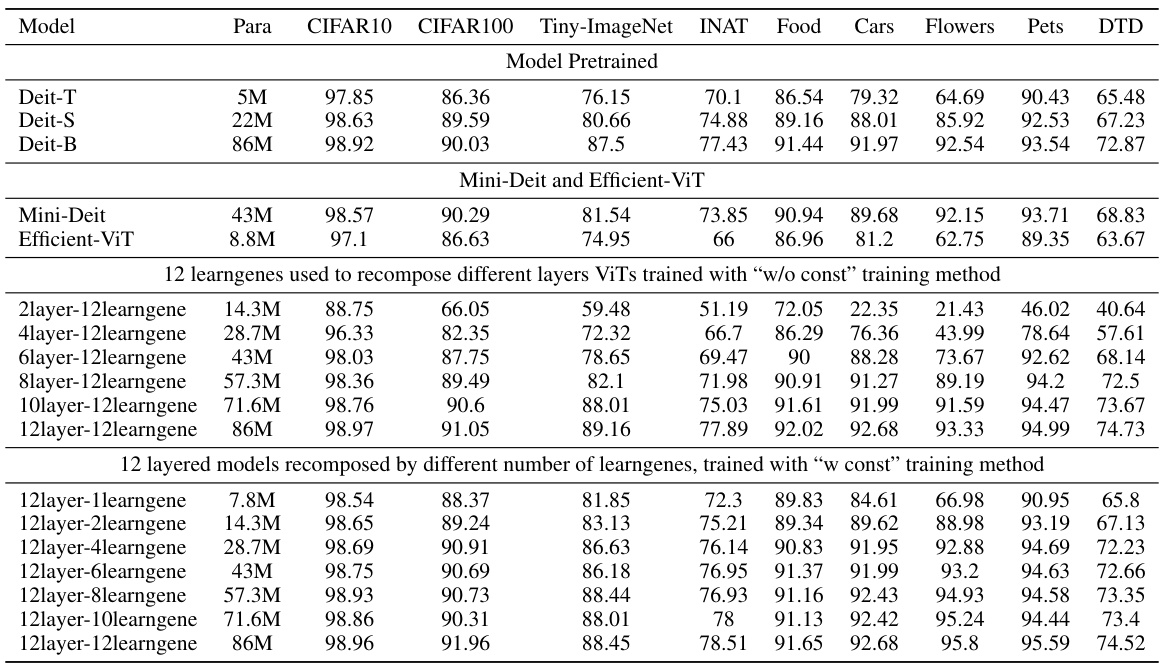
This table presents a comparison of the performance of different methods for training vision transformer models. It compares models trained using pre-training and fine-tuning, model compression techniques, and the proposed method (using different numbers of learngenes and training strategies). The comparison is done across various datasets and model sizes, evaluating the accuracy of each method. The table highlights the trade-off between model size (parameters), computational efficiency, and accuracy.
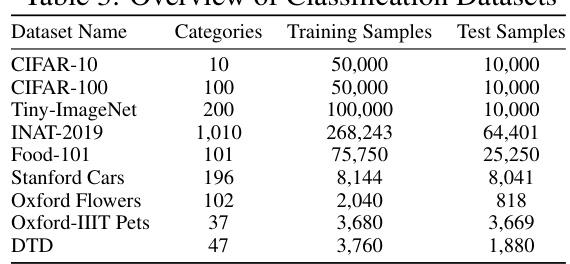
This table lists the nine datasets used for the downstream tasks in the paper. For each dataset, it shows the number of categories, the number of training samples, and the number of test samples. These datasets represent diverse image classification challenges, including general object recognition, fine-grained recognition (cars, flowers, pets), and texture classification.
Full paper#