↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating realistic 3D scenes, particularly 360° panoramas, remains challenging due to limited datasets and difficulty in ensuring multi-view consistency. Existing methods often struggle with scalability and producing consistent images across multiple viewpoints. This limits applications in virtual reality (VR) and other fields requiring immersive scene generation.
DiffPano tackles these issues with a novel framework. It leverages a newly created large-scale panoramic video-text dataset and a spherical epipolar-aware multi-view diffusion model. This model ensures consistent generation across different viewpoints, addresses scalability concerns, and improves overall image quality. The results show DiffPano significantly outperforms existing methods in terms of consistency and image quality, opening avenues for advancements in VR and related applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on 3D scene generation and especially those focusing on panoramic image synthesis. It introduces DiffPano, a novel framework that addresses limitations in existing methods by producing scalable and consistent multi-view panoramas. The research paves the way for advancements in various applications, including virtual reality, interior design, and robotics.
Visual Insights#

This figure showcases the DiffPano model’s ability to generate consistent and scalable 360° panoramas from text descriptions and camera poses. Each column displays a sequence of generated multi-view panoramas, demonstrating the model’s capacity to seamlessly transition between different rooms (scenes) while maintaining visual coherence. The text descriptions used to generate each set of panoramas are displayed above their corresponding image sets.
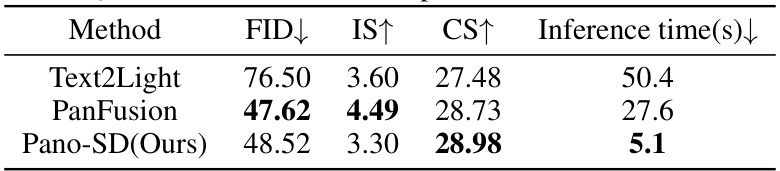
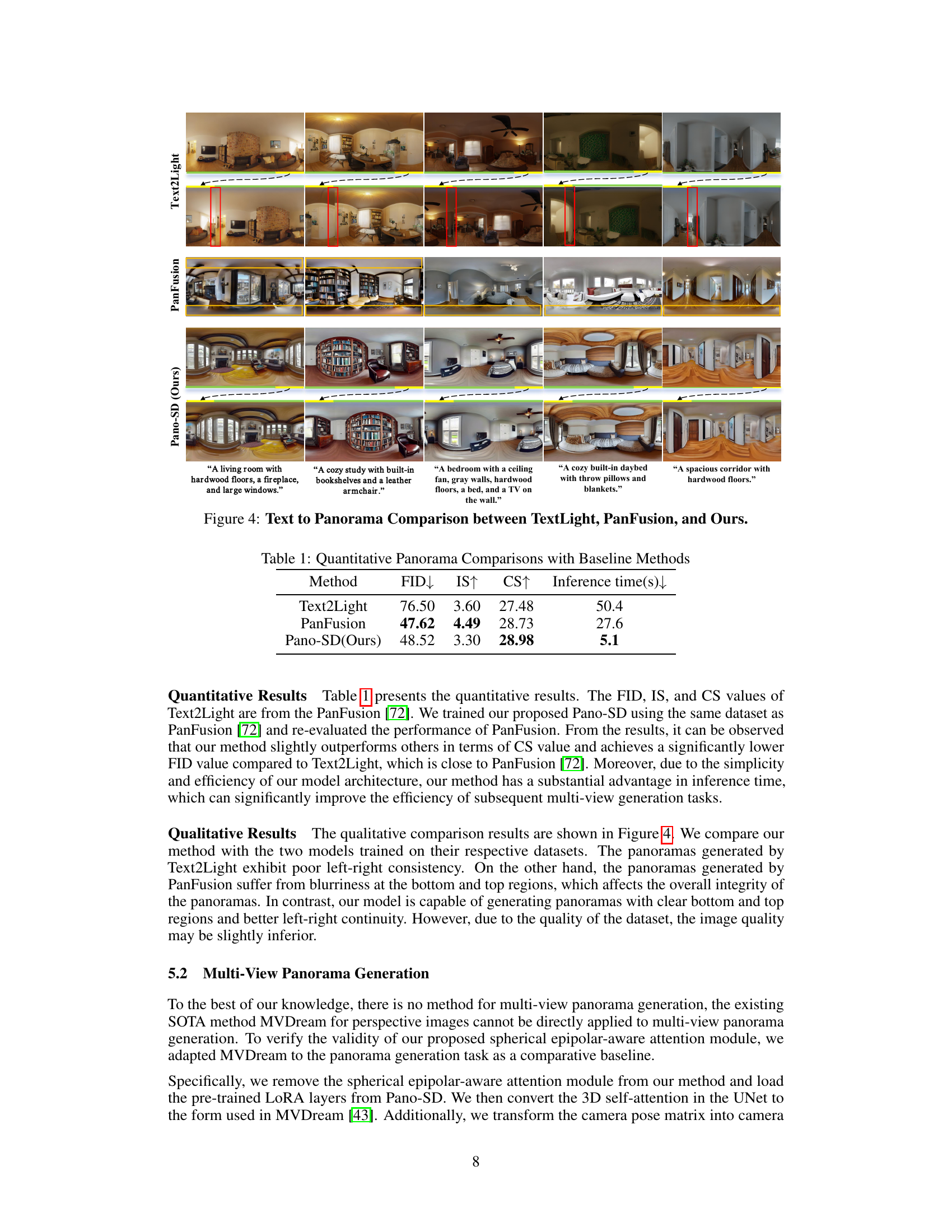
This table presents a quantitative comparison of the proposed Pano-SD method with two baseline methods, Text2Light and PanFusion, for single-view panorama generation. The comparison is based on three metrics: Fréchet Inception Distance (FID), Inception Score (IS), and CLIP Score (CS). Lower FID indicates better image quality, higher IS suggests both better quality and diversity, and higher CS shows better consistency between generated images and input text descriptions. Inference time is also compared to show the efficiency of each method.
In-depth insights#
Pano Video-Text#
A ‘Pano Video-Text’ dataset presents a unique opportunity to advance research in visual-language understanding and 3D scene generation. The combination of panoramic video, depth maps, and text descriptions offers a rich representation of real-world scenes. The integration of video allows for spatiotemporal analysis beyond single images, capturing dynamic aspects of scenes that are crucial for understanding context and motion. Depth information enhances scene understanding, facilitating more accurate 3D model generation and enabling realistic view synthesis. Text descriptions provide semantic grounding, enabling the development of models capable of generating realistic panoramas from text prompts, bridging the gap between textual and visual information. However, challenges exist in handling the complexities of panoramic image processing, multi-view consistency, and the computational cost of processing high-resolution video data. Addressing these challenges could lead to significant advancements in virtual and augmented reality applications, intelligent scene navigation and manipulation, and even large-scale 3D reconstruction, where the creation of realistic virtual environments from text descriptions is a key goal.
Spherical Diffusion#
Spherical diffusion, in the context of 3D image generation, presents a novel approach to address the limitations of traditional methods. Unlike Cartesian-based diffusion models that struggle with generating consistent multi-view panoramas, spherical diffusion leverages the natural spherical geometry of panoramic images. This approach directly models the image formation process on the sphere, thereby avoiding distortions and inconsistencies inherent in projecting spherical data onto planar representations. By operating directly in the spherical domain, spherical diffusion models can generate more realistic and coherent multi-view panoramas from text descriptions and camera poses. This avoids the need for complex post-processing steps like stitching or warping, which often introduce artifacts. Furthermore, spherical diffusion allows for efficient and scalable generation of high-resolution panoramic videos, offering significant advantages in applications such as virtual reality, 3D modeling, and image-based rendering. However, challenges remain in terms of computational complexity and the need for large-scale spherical datasets. The development of efficient algorithms and the creation of comprehensive datasets are crucial for advancing the field of spherical diffusion and unlocking its full potential for realistic 3D scene generation.
Multi-View Consistency#
Achieving multi-view consistency in 3D scene generation is crucial for creating realistic and immersive experiences. The core challenge lies in ensuring that multiple viewpoints of the same scene appear coherent and consistent, avoiding jarring discrepancies that break immersion. This requires careful consideration of several factors. Accurate camera pose estimation is paramount; errors in camera position and orientation will directly lead to inconsistencies between views. Epipolar geometry plays a vital role in maintaining consistency, as it defines the geometric relationship between corresponding points across different images. Effective diffusion models must be designed to explicitly respect epipolar constraints during generation. Additionally, data augmentation techniques can help improve consistency by creating diverse and challenging training data. Careful model design, incorporating mechanisms like epipolar attention or other multi-view consistency losses, is essential to explicitly guide the model toward generating coherent views. Finally, evaluation metrics beyond simple image similarity are needed to assess the overall consistency of the generated multi-view panoramas, accounting for the spatial relationships between the views.
Ablation Experiments#
Ablation experiments systematically remove components of a model or system to assess their individual contributions. In a research paper, this section would typically demonstrate the importance of each component by showing how performance degrades when it’s removed. The results highlight the critical features driving the model’s success and can guide future improvements. For example, if a new architectural component is introduced, ablation studies should show that it improves performance. A well-designed ablation study will also help to rule out alternative explanations for observed results by showcasing the impact of each part. The focus is on isolating the contributions of specific elements, providing evidence-based justification for design decisions and offering valuable insights into the model’s inner workings. The analysis should clearly describe the metrics used, the methodology for ablation, and the observed effect on overall performance, often visually represented in tables or charts to enhance clarity and impact.
Future of Panoramas#
The future of panoramas is bright, driven by advancements in AI and computer vision. High-resolution, 360° image generation is becoming increasingly accessible through diffusion models, promising realistic virtual environments and immersive experiences. The integration of text-to-panorama generation will further personalize and enhance these experiences. Multi-view consistency will improve the realism of generated panoramas, creating seamless virtual tours. Efficient rendering techniques are crucial for wider adoption, enabling fast generation and real-time viewing. Addressing challenges like dataset limitations and computational cost remain crucial for future developments. Ethical considerations around synthetic media are also paramount, ensuring responsible creation and use of panoramic imagery.
More visual insights#
More on figures
This figure showcases DiffPano’s ability to generate consistent and scalable panoramic images from textual descriptions and camera poses. Each column demonstrates the generation of a multi-view panorama of a different room, highlighting the model’s ability to seamlessly transition between rooms based on textual prompts and camera positions.
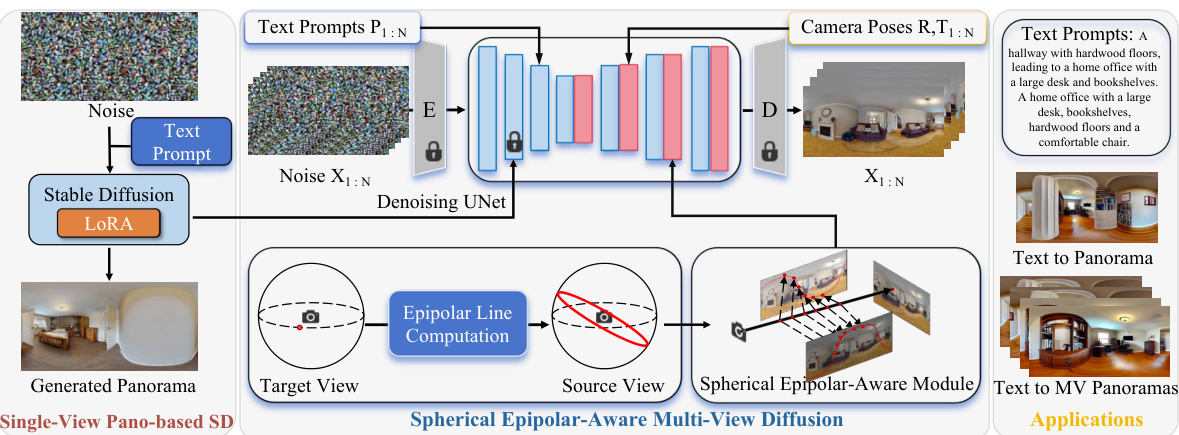
This figure illustrates the DiffPano framework, which is composed of two main models: a single-view text-to-panorama diffusion model and a spherical epipolar-aware multi-view diffusion model. The single-view model takes text prompts as input and generates a single panoramic image. The multi-view model builds upon the single-view model, incorporating spherical epipolar constraints to ensure consistency across multiple viewpoints generated from the same text prompt. The framework is designed for both single-view and multi-view panorama generation. Input text prompts and camera poses are processed through the models to output generated panoramic images, which can then be used in various applications.

This figure showcases the capabilities of DiffPano to generate consistent and scalable panoramic images from text descriptions. Each column shows a series of generated 360° panoramas, demonstrating the model’s ability to seamlessly transition between different rooms (scene switching). The text descriptions guiding the generation are also provided. The figure highlights the model’s ability to create realistic and coherent multi-view panoramas from text prompts alone.

This figure compares the results of DiffPano with those of MVDream, a baseline method for multi-view image generation. The top row shows the results from MVDream trained for a standard amount of time. The middle row shows the results from MVDream trained for twice the amount of time as DiffPano. The bottom row shows the results from DiffPano. Each row displays a sequence of generated multi-view panoramas from different viewpoints of the same scene, demonstrating the visual consistency of each model’s output. The figure highlights DiffPano’s superior ability to maintain consistency across multiple viewpoints, even when compared to MVDream trained for a longer duration. The text prompt used for generation is also provided, further contextualizing the generated image sequences.

This figure demonstrates the DiffPano model’s ability to generate consistent panoramic images of different rooms based on textual descriptions and camera poses. Each column shows a sequence of generated panoramas, simulating the experience of moving from one room to another within a virtual environment. The model successfully captures the details specified in the text prompts and ensures smooth transitions between different views.

This figure showcases the capabilities of the DiffPano model. Given a text description (examples provided in the image), DiffPano generates a series of panoramic images from multiple viewpoints (a multi-view panorama) representing different rooms. Each column shows the same room’s multi-view panoramas, while switching between columns demonstrates DiffPano’s ability to consistently generate panoramas for different rooms based on the descriptions provided. This highlights the model’s scalability and consistency in handling unseen text descriptions and camera poses.

This figure showcases the capability of DiffPano to generate consistent and scalable panoramic images from text descriptions and camera poses. Each column displays a sequence of generated multi-view panoramas, demonstrating the ability of the model to smoothly transition between different rooms based on the provided text input. This highlights DiffPano’s unique ability to manage room switching seamlessly within a consistent panoramic environment.

This figure compares the multi-view panorama generation results of DiffPano with those of MVDream, a baseline model. It shows that DiffPano produces more consistent multi-view panoramas, even when compared to MVDream trained with twice the number of iterations. The consistency is visually apparent in the generated images, demonstrating DiffPano’s superior performance in this aspect.

This figure demonstrates DiffPano’s ability to generate consistent and scalable panoramic images from textual descriptions and camera poses. Each column shows a sequence of generated panoramas, representing a change of scene (room switching). This showcases the model’s ability to maintain consistency across multiple viewpoints while generating diverse and realistic environments.

This figure showcases the capabilities of DiffPano, a novel text-driven panoramic generation framework. Given unseen text descriptions (examples provided above each set of images), DiffPano generates a series of consistent and scalable 360° panoramas. Each column displays multiple viewpoints of the same scene, demonstrating the ability of the model to generate coherent panoramas from varied perspectives within the same space, as well as transition smoothly between different scenes (rooms) described by different text prompts.

This figure showcases the ability of the DiffPano model to generate consistent and scalable 360° panoramas based on textual descriptions and camera poses. Each column displays a sequence of generated multi-view panoramas, demonstrating the model’s capacity to seamlessly transition between different rooms, showcasing the consistency and scalability of the panorama generation process.

This figure showcases the DiffPano model’s ability to generate consistent and scalable 360° panoramas from text descriptions. Each column displays a sequence of generated panoramas, demonstrating the model’s capacity to seamlessly transition between different rooms while maintaining visual consistency. This highlights DiffPano’s key advantage of generating multi-view panoramas for room switching, showcasing its scalability and consistency in handling unseen text descriptions and camera poses.
More on tables

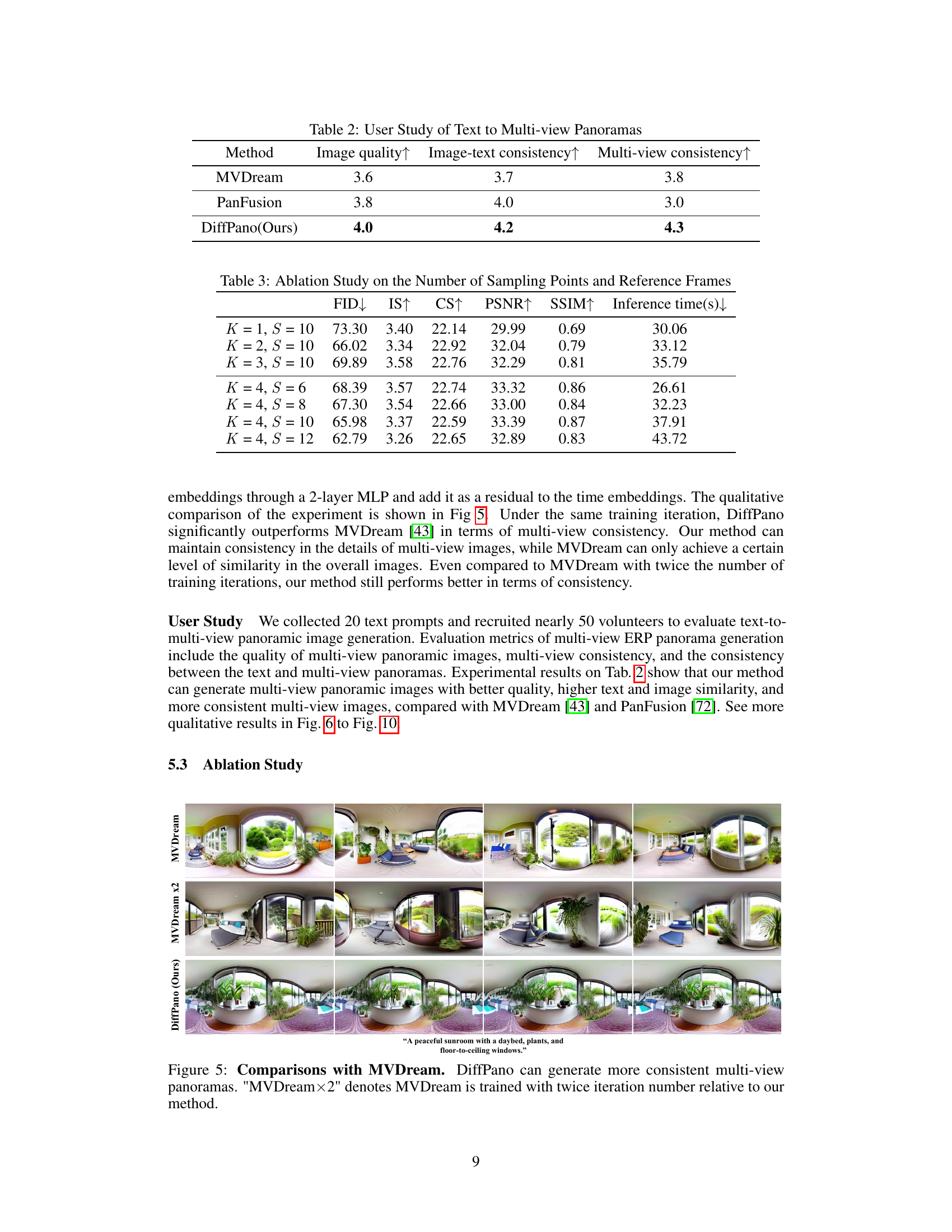
This table presents the results of a user study comparing three different methods for generating multi-view panoramas from text descriptions: MVDream, PanFusion, and DiffPano (the authors’ method). Users rated each method on three aspects: image quality, image-text consistency (how well the generated images matched the text), and multi-view consistency (how consistent the multiple views of the same scene were). Higher scores indicate better performance. The results show that DiffPano outperforms the other two methods across all three criteria.
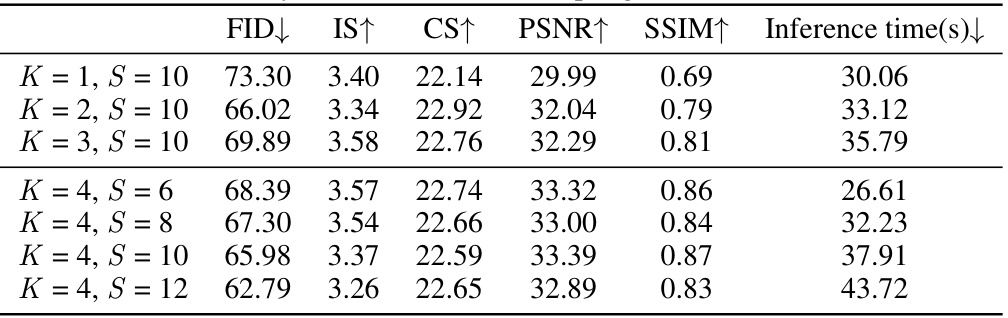
This table presents the results of an ablation study conducted to investigate the impact of varying the number of sampling points (S) and reference frames (K) on the performance of the multi-view panorama generation model. The study evaluates the model’s performance using FID (Fréchet Inception Distance), IS (Inception Score), CS (CLIP Score), PSNR (Peak Signal-to-Noise Ratio), and SSIM (Structural Similarity Index Measure). It shows how these metrics change as the number of sampling points and reference frames are adjusted, illustrating the effect on generation quality and consistency.
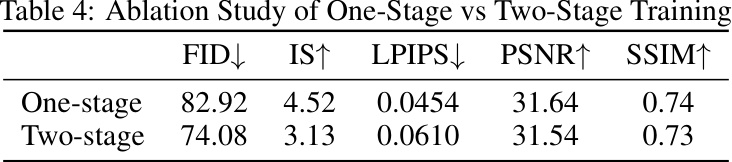
This table presents the results of an ablation study comparing the performance of a one-stage training approach against a two-stage training approach for generating multi-view panoramas. The metrics used to evaluate performance include FID (Fréchet Inception Distance), IS (Inception Score), LPIPS (Learned Perceptual Image Patch Similarity), PSNR (Peak Signal-to-Noise Ratio), and SSIM (Structural Similarity Index). Lower FID and LPIPS scores indicate better image quality, while higher IS, PSNR, and SSIM scores also represent improved image quality. The comparison highlights the differences in the overall performance of the model under the two training strategies.

This table presents a quantitative comparison of the performance of three different methods (MVDiffusion, PanFusion, and Pano-SD) in generating perspective images. The comparison is based on two metrics: Fréchet Inception Distance (FID), a measure of the similarity between generated and real images; and Inception Score (IS), a measure of the quality and diversity of the generated images. Lower FID values and higher IS values indicate better performance. The results show that the Pano-SD method achieves the lowest FID and a competitive IS, suggesting that it generates more realistic and diverse perspective images compared to the baseline methods.

This table details the architecture of the DiffPano-2 model, specifying the layers, output dimensions, and additional inputs at each layer. It shows the progression of the model through convolutional, attention, and upsampling blocks. The
CrossAttnUpBlocklayers are particularly relevant for multi-view consistency, utilizing time embeddings and prompt embeddings for contextual information. The table allows a reader to understand the technical construction of the multi-view panorama generation model.

This table details the architecture of the second part of the DiffPano model, specifically focusing on the
CrossAttnUpBlock2andCrossAttnUpBlock3components. It lists each layer (ResBlock, AttnBlock, EAModule, GroupNorm, SiLU, Conv.), their respective outputs (dimensions), and any additional inputs used in each layer (Time embedding and Prompt embedding). This structure illustrates the upsampling process within the network and how different information is integrated at various stages.
Full paper#