↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current vision encoders excel at image recognition but struggle with text, limiting their use in document analysis. This necessitates separate models for image and text processing, increasing complexity and cost. The field lacks a unified approach that efficiently handles both tasks simultaneously.
The paper introduces UNIT, a novel training framework that integrates image and text recognition within a single vision encoder. UNIT uses a two-stage training process: intra-scale pretraining (on common resolutions) and inter-scale finetuning (on swapped resolutions) to enhance scale robustness. This unified approach significantly outperforms existing methods on document-related tasks (OCR, DocQA) while preserving image recognition performance. UNIT is highly efficient, adding no extra cost during deployment and inference.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UNIT, a novel training framework that significantly improves the ability of vision transformer models to handle both image and text recognition tasks simultaneously. This addresses a critical limitation of existing models and opens new avenues for research in document analysis and related fields. The cost-free nature of UNIT in terms of inference and deployment makes it highly practical for real-world applications. Furthermore, the paper’s findings have implications for improving accessibility for individuals with visual impairments and streamlining various document analysis processes.
Visual Insights#

The figure shows the architecture of the UNIT model, which processes both high-resolution documents and low-resolution images. It uses a unified vision encoder, a language decoder for text recognition, and a vision decoder to prevent catastrophic forgetting of image encoding abilities. The model is trained with multiple objectives: OCR, image captioning, and vision reconstruction.

This table compares the performance of UNIT with other ViT-based models on text recognition tasks, specifically focusing on F1 scores across various datasets. The asterisk indicates that some results were re-implemented using the authors’ document datasets for better comparison. The results show that UNIT outperforms other models on the document recognition tasks.
In-depth insights#
Unified Vision Model#
A unified vision model aims to integrate diverse visual information processing tasks within a single framework, moving beyond specialized models for individual tasks like image classification or object detection. This approach offers potential benefits like enhanced efficiency, requiring fewer computations and less memory than multiple separate models. Furthermore, a unified model could lead to improved contextual understanding, as the model can leverage information from various sources simultaneously. A key challenge in developing such models is ensuring that the integration does not negatively impact individual task performance. Careful consideration of model architecture and training techniques is critical to avoid catastrophic forgetting where the model loses its ability to perform well on previously learned tasks. A successful unified model would be a major step towards more robust and generalized visual AI systems that can adapt to complex and varied real-world scenarios.
Multi-Scale Training#
Multi-scale training in computer vision models addresses the challenge of handling variations in image or document resolutions. Standard training often struggles when inputs deviate from the resolution used during pre-training, leading to performance degradation. Multi-scale training mitigates this by incorporating images and documents of different resolutions during the training phase. This approach enhances the model’s robustness and generalization ability, enabling it to accurately process data that it hasn’t seen before. By exposing the model to diverse resolutions, it learns to extract relevant features irrespective of the input size, improving its performance on real-world applications where input variability is common. However, multi-scale training introduces complexities in model design and training procedures, especially concerning computational resource requirements and the potential for overfitting. Careful consideration of data augmentation, optimization strategies, and architectural design is necessary to leverage the benefits of multi-scale training effectively.
Text Recognition Boost#
A hypothetical research paper section titled “Text Recognition Boost” would likely detail advancements improving automatic text recognition (ATR) accuracy and efficiency. This could involve novel approaches to handling challenges like varying font styles, low resolution images, complex layouts, and noisy backgrounds. The section might present a new model architecture, a refined training methodology (e.g., incorporating synthetic data, transfer learning from other tasks), or a combination of both. Quantitative results, comparing the proposed method’s performance to state-of-the-art ATR systems on standard benchmarks (e.g., ICDAR, COCO-Text), would be crucial. A thorough discussion of the limitations of the proposed method, along with potential future research directions, would complete the section, possibly highlighting areas like handling multilingual texts or integrating advanced pre-processing techniques for improved robustness.
Ablation Study Results#
Ablation studies systematically remove components of a model to understand their individual contributions. In the context of a research paper, the ‘Ablation Study Results’ section would detail the impact of removing or altering specific elements. A strong ablation study isolates the effects of individual parts, revealing if improvements are due to a single innovation or a synergistic combination of features. Analyzing results requires careful consideration of how performance metrics are affected. For example, a small drop in accuracy after removing one feature might be insignificant, while a larger drop shows that this element is crucial. The discussion should highlight both positive and negative results, acknowledging limitations and potential areas for future work. The overall goal is to present a clear picture of what aspects are most important and warrant further investigation or refinement. Well-designed ablation studies build confidence in the overall model architecture and its effectiveness.
Downstream Tasks#
The ‘Downstream Tasks’ section of a research paper would typically detail how a model, trained on a primary task (e.g., image classification), performs when applied to secondary, related tasks. This section is crucial for demonstrating the model’s generalizability and transfer learning capabilities. A strong ‘Downstream Tasks’ section would include a diverse range of applications, showcasing the model’s adaptability across different domains. Quantitative results—like accuracy, precision, recall, or F1-scores—are paramount to show performance on these downstream tasks, often compared to state-of-the-art baselines. The choice of downstream tasks should be carefully justified, reflecting the model’s inherent strengths and potential applications. Qualitative analysis might accompany quantitative results, providing a deeper understanding of the model’s behavior and limitations in various contexts. Finally, a discussion of the results in relation to the model’s architecture and training methodology would strengthen the overall significance and impact of this section, revealing insights into the model’s learning process and its potential.
More visual insights#
More on figures

This figure illustrates the UNIT training framework, which consists of three stages. (a) Intra-scale pretraining: The model is trained on images and documents at their typical resolutions to learn both image and text recognition. (b) Inter-scale finetuning: The model is further trained on scale-exchanged data (high-resolution images, low-resolution documents) to improve robustness. (c) Application in LVLMs: The trained UNIT model is integrated into Large Vision-Language Models (LVLMs) for downstream tasks such as visual question answering and document analysis.

This figure provides a detailed overview of the UNIT architecture. It shows how the model processes both high-resolution documents and low-resolution images, creating visual tokens that are fed into both a language decoder (for text recognition) and a vision decoder (to preserve the original image encoding capabilities). The inclusion of image captioning further enhances the model’s understanding of natural images. The diagram highlights the key components and their interconnections within the UNIT framework.
More on tables

This table compares the performance of UNIT against other ViT-based models on text recognition tasks, specifically focusing on F1 scores across several benchmark datasets. The datasets include FUNSD, SROIE, CORD, SYN-L-val, and MD-val, each representing different challenges in document image analysis. The asterisk indicates that some results were re-implemented by the authors on their own document datasets to ensure fair comparison.
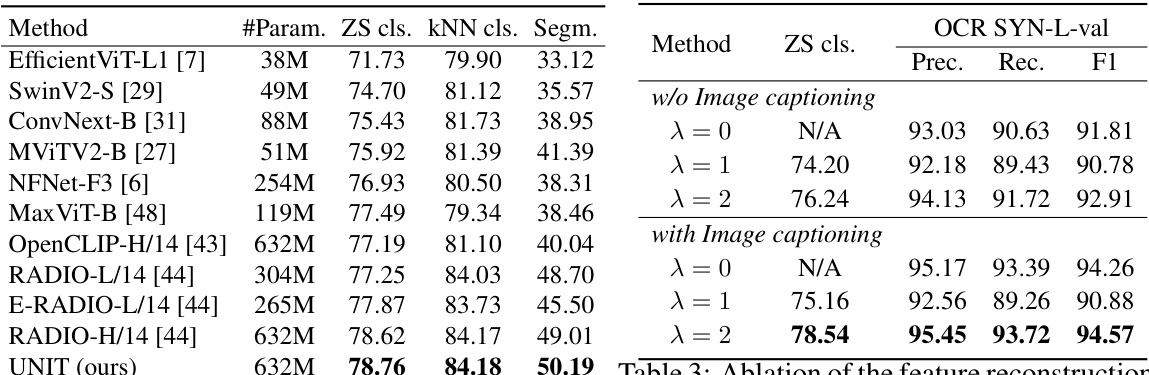
This table compares the performance of UNIT with other ViT-based models on text recognition tasks using F1 scores. The models are evaluated on several document-level OCR datasets. The asterisk (*) indicates that some results were re-implemented by the authors for a fair comparison since the original results were reported on different datasets.

This table compares the performance of UNIT with other ViT-based models on text recognition tasks, specifically focusing on F1 scores. It includes results across multiple datasets, highlighting UNIT’s superior performance compared to existing methods.

This table compares the performance of UNIT with other ViT-based models on text recognition tasks, specifically focusing on F1 scores. It includes results on several datasets (FUNSD, SROIE, CORD, SYN-L-val, and MD-val) and highlights that UNIT significantly outperforms existing methods. The asterisk denotes that certain results were re-implemented by the authors on their document datasets for a fair comparison.
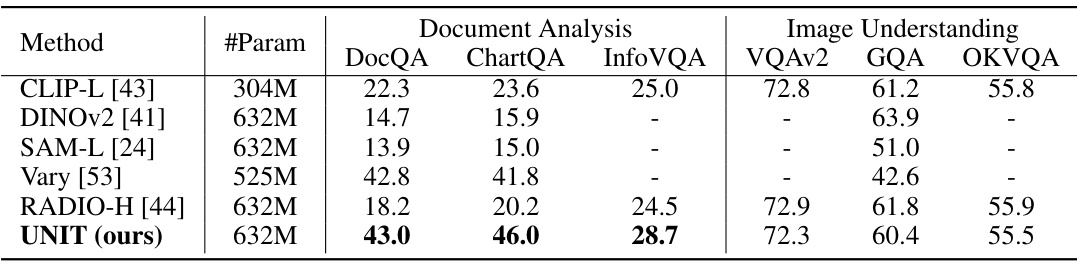
This table compares the performance of several vision encoders, including the proposed UNIT model, on various downstream tasks categorized into document analysis and image understanding. The naive resolution refers to the commonly used resolutions for the respective tasks. The results show UNIT’s performance in relation to other state-of-the-art vision encoders for document analysis tasks like DocQA, ChartQA, and InfoVQA, while maintaining comparable performance on image understanding tasks such as VQAv2, GQA, and OKVQA.

This table compares the performance of various vision encoders (CLIP-L, SigLIP, and UNIT) when integrated into Large Vision-Language Models (LVLMs) using a high-resolution grid slicing technique for image processing. The performance is evaluated across several downstream tasks, including ChartQA, DocVQA, InfoVQA, OCRBench, GQA, OKVQA, MME, and MathVista. The results highlight UNIT’s superior performance across these tasks compared to the other vision encoders.
Full paper#