↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current 3D object detection heavily relies on bounding boxes, which lack the precision to capture detailed object geometry, especially for objects with irregular shapes or those that are incomplete or far away. This limitation affects the accuracy and robustness of perception systems in autonomous driving, hindering safe and efficient navigation. High-resolution occupancy maps offer a solution, but are computationally expensive for large scenes.
The paper proposes a novel approach that combines the advantages of both bounding boxes and occupancy maps using object-centric occupancy. This method constructs high-resolution occupancy maps for individual detected objects, enabling more accurate shape representation. It leverages a new network with an implicit shape decoder that utilizes temporal information from long sequences to complete object shapes under noisy conditions, enhancing the robustness of the system. Experiments show a significant improvement in detection accuracy, especially for incomplete or distant objects, demonstrating the effectiveness of the proposed technique.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D object detection and autonomous driving. It introduces object-centric occupancy, a novel representation that significantly improves accuracy, especially for incomplete or distant objects. This opens avenues for more robust perception systems and safer autonomous navigation.
Visual Insights#

This figure is a visual comparison between using bounding boxes and occupancy grids for 3D object representation. The left panel (a) shows a crane represented by a bounding box; it’s a simple cuboid that roughly encloses the object, failing to capture the detailed shape, especially the long boom extending from the crane’s cab. This results in a significant amount of unoccupied space inside the bounding box. The right panel (b) shows the same crane represented as a scene-level occupancy grid, where the 3D space is discretized into voxels, and each voxel is classified as occupied or unoccupied, effectively representing the crane’s shape and structure more precisely than the bounding box.
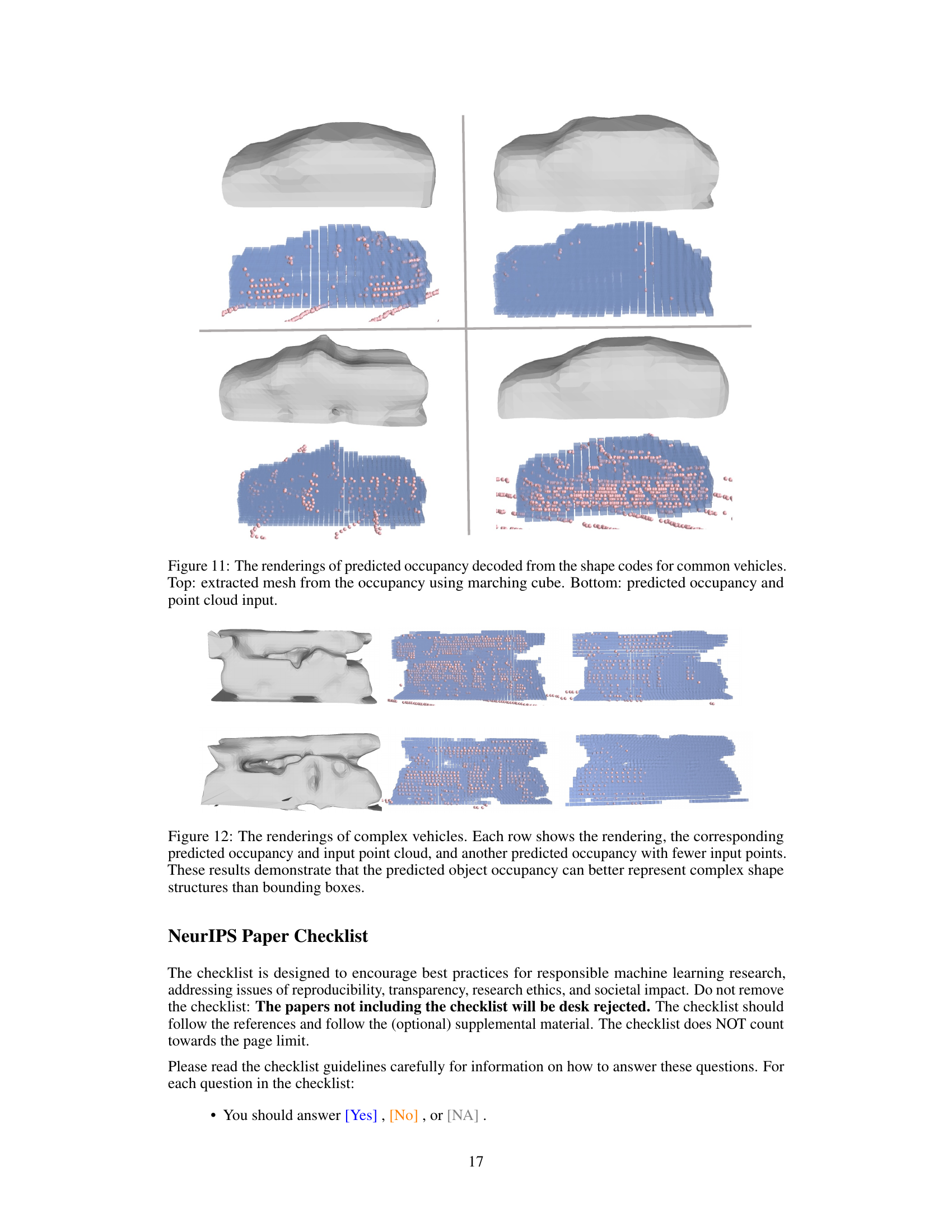
This table presents the results of the shape completion task on the Waymo Open Dataset validation set. The results are broken down by the type of tracklet input used: ground-truth tracklets, tracklets with added noise, tracklets generated by the CenterPoint detector, tracklets generated by the FSD detector, and tracklets generated by the FSDv2 detector. For each type of tracklet input, the table shows the baseline performance (i.e., the performance without using the proposed method) and the performance of the proposed method. The proposed method significantly improves upon the baseline performance in all cases. The ‘Ours-E’ column shows the performance of the proposed method when the occupancy is predicted for the entire ground-truth bounding box, even if it extends outside of the predicted region of interest (RoI).
In-depth insights#
Object-centric Occupancy#
The concept of “Object-centric Occupancy” offers a significant advancement in 3D scene perception by focusing on the occupancy of individual objects rather than the entire scene. This approach is particularly useful for autonomous driving, where precise object details are crucial. Unlike traditional scene-level occupancy, which suffers from computational limitations at high resolutions, object-centric occupancy enables the use of higher voxel resolutions because it only needs to represent a small portion of the scene. This leads to more accurate shape representation, especially beneficial for objects with irregular shapes. Data generation for such a system requires an automated pipeline, as extracting object occupancy from existing scene-level datasets can result in information loss. The proposed method uses temporal information from long sequences of noisy detection and tracking results to improve accuracy, demonstrating robust performance even under noisy conditions. This enhances state-of-the-art 3D object detectors and is especially beneficial for incomplete or distant objects. Overall, object-centric occupancy presents a compelling paradigm shift, offering a more detailed and computationally feasible approach to 3D scene understanding.
Occupancy Completion#
The concept of occupancy completion, within the context of 3D object detection, addresses the inherent limitations of bounding boxes in capturing the intricate geometry of objects, particularly those with irregular shapes or those that are incomplete or partially occluded in sensor data. The core idea is to enhance object representations by moving beyond simple bounding boxes towards occupancy maps that explicitly model which parts of 3D space are occupied by objects. This involves predicting a dense occupancy grid for each object, effectively creating a more detailed and complete shape representation. This approach leverages temporal information from long sequences of sensor data to resolve ambiguities in individual frames and improve prediction accuracy, especially for objects that may be only partially visible in any given frame. A key innovation is the use of an implicit shape decoder, which avoids the computational cost of explicitly generating occupancy grids of varying sizes. The decoder generates dynamic sized occupancy maps directly, and significantly improving the computational efficiency of the process.
Sequence-based Network#
A sequence-based network leverages temporal information from sequential data, such as video frames or sensor readings over time, to improve model performance. This approach is particularly useful for tasks where understanding the temporal evolution of events is crucial, unlike static single-frame analyses. Key advantages include enhanced accuracy in tasks like object tracking, motion prediction, and action recognition because the network can learn to predict future states based on past observations. Challenges in designing such networks might involve dealing with variable sequence lengths, managing computational complexity, and addressing potential issues related to data dependency and long-range temporal dependencies. Effective strategies might include recurrent neural networks (RNNs), long short-term memory (LSTM) networks, or transformers, each offering different ways to capture temporal patterns. Choosing the right architecture will depend heavily on the specific application and data characteristics. Furthermore, data augmentation techniques specifically designed for sequential data are critical to prevent overfitting and improve generalization. For instance, techniques like time warping or random cropping can introduce variability and increase the robustness of the model.
Shape Representation#
The choice of shape representation is crucial in 3D object detection. Traditional bounding boxes, while computationally efficient, lack the detail to capture complex object geometries. Occupancy representations, discretizing space into occupied and unoccupied voxels, offer a more nuanced approach, accurately reflecting object shapes, especially those with irregular forms. However, high-resolution occupancy maps for large scenes present computational challenges. This paper proposes object-centric occupancy as a compromise, focusing on foreground objects with higher voxel resolution within a localized coordinate system, thus addressing both accuracy and efficiency limitations. Implicit neural representations offer another avenue, learning continuous functions to describe shapes rather than relying on discrete grids, thereby improving memory efficiency and enabling dynamic size generation for varying object scales. The choice between explicit voxel grids and implicit neural functions is a key design decision balancing accuracy, computational cost, and memory usage. The selection ultimately depends on the specific application and the trade-offs acceptable in terms of accuracy and efficiency.
Dataset Generation#
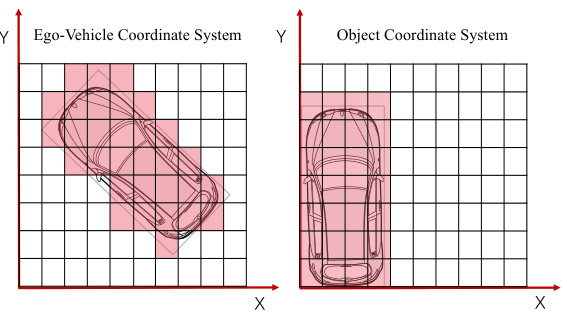
The process of dataset generation is crucial for the success of the research. The paper employs an automated pipeline to generate the object-centric occupancy dataset from scratch. This approach avoids the limitations of adapting existing datasets by meticulously creating data aligned with the research’s specific needs. Automation streamlines this process, enhancing efficiency and reducing manual effort. The pipeline begins by gathering LiDAR points from bounding boxes over time, converting these points to the object’s coordinate system to form dense point clouds. Voxelization then transforms these point clouds into occupancy grids, and occlusion reasoning is employed to precisely classify each voxel as either occupied, free or unobserved, addressing the challenge of sparse LiDAR data. This detailed annotation method is vital because it overcomes issues like jagged object representations caused by misaligned coordinates in existing scene-level occupancy datasets, allowing for more precise shape representations that are vital for shape completion tasks. The approach also ensures high voxel resolutions, allowing the capture of intricate details often missing in existing scene-level datasets. The object-centric nature of the data allows for higher resolution occupancy without increasing computational complexity, unlike scene-level occupancy. This novel dataset, generated via a robust and automated process, directly supports the study’s objectives and enhances the overall validity and reliability of its findings.
More visual insights#
More on figures

This figure demonstrates the challenges of generating occupancy grids directly from LiDAR point clouds. Subfigure (a) shows an example of a high-quality object-centric occupancy representation. (b) illustrates the sparsity of a single LiDAR scan for a foreground object, making it difficult to reconstruct the object’s shape. (c) shows that aggregating multiple scans using accurate ground-truth bounding boxes can create a reasonably complete occupancy representation. However, (d) shows that using noisy bounding boxes from a detection algorithm results in a blurry and inaccurate occupancy volume due to the accumulation of errors.
This figure compares two different coordinate systems for representing occupancy grids: ego-vehicle and object-centric. The left panel shows an occupancy grid centered on the ego-vehicle, where the object’s shape appears jagged due to coordinate misalignment. The right panel shows the object-centric occupancy grid, where the object is centered, resulting in a smoother, more accurate representation of its shape. This highlights the advantage of object-centric occupancy for capturing object details, especially those with irregular shapes.

This figure illustrates the architecture of the object-centric occupancy completion network proposed in the paper. The network takes as input a sequence of noisy object proposals, each with associated point clouds and bounding boxes at different timestamps. It consists of two main branches. The first (global branch) encodes global features (Zg) from the entire object sequence via a multi-layer perceptron (MLP). The second (local branch) encodes local features (Zl) from the Region of Interest (RoI) of each object proposal, also via an MLP. A causal attention mechanism integrates the global and local features to provide a robust temporal representation of the object’s shape. Finally, an implicit shape decoder (D) generates the complete object-centric occupancy volume using the combined features. A detection head uses the features to refine bounding box predictions and objectness scores.

This figure illustrates the two-step process used to calculate the Intersection over Union (IoU) for evaluating shape completion. First, the ground truth (GT) box is transformed into the coordinate system of the Region of Interest (RoI). Then, the predicted occupancy status for each voxel center within the transformed GT box is determined. The IoU is computed by comparing the predicted occupancy volume within the GT box to the ground truth occupancy volume. Voxels outside of the RoI are considered free during the computation.
The figure illustrates the object-centric occupancy annotation pipeline. It starts with a ground truth (GT) object sequence, which is then processed to densify the object points. These points are transformed into the object’s coordinate system. Voxelization then creates the object volume, where voxels are classified as occupied or unoccupied. Occlusion reasoning is performed to distinguish between free and unobserved voxels, resulting in the final object-centric occupancy grid.
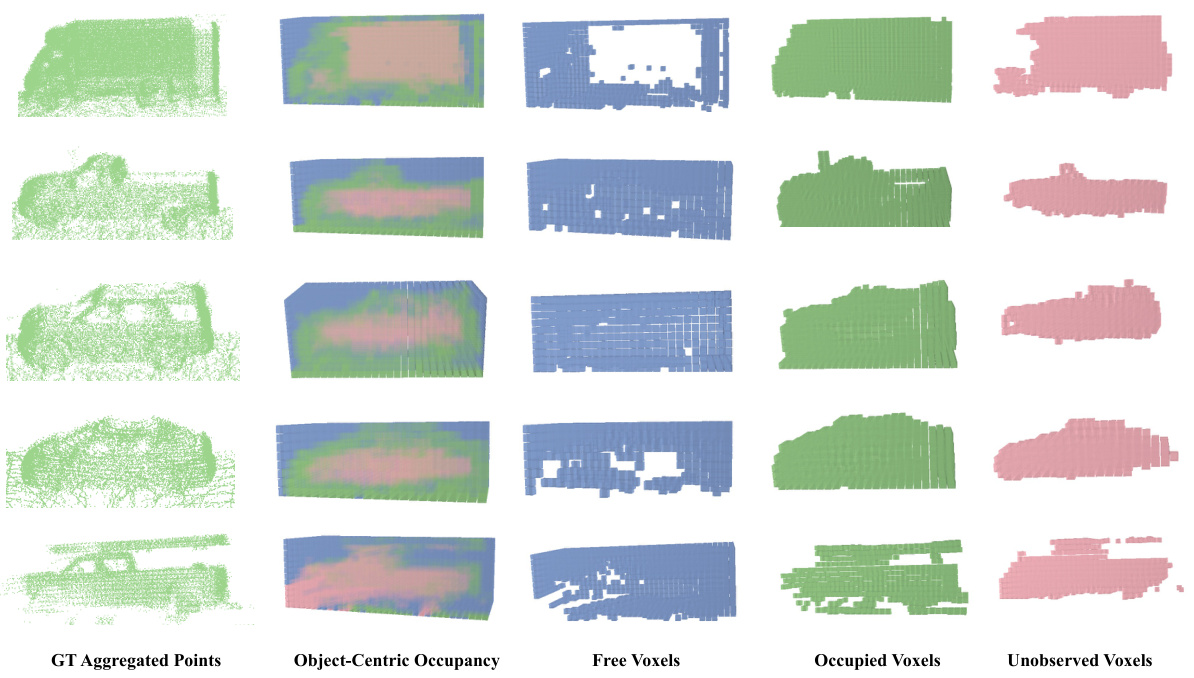
This figure visualizes examples from the Object-Centric Occupancy dataset. Each row shows a different object. The first column displays the ground truth point cloud of the object generated by aggregating multiple LiDAR scans. The second column presents the corresponding object-centric occupancy grid generated by the proposed method. The remaining columns break down the occupancy grid into voxels classified as ‘free’, ‘occupied’, and ‘unobserved’. The ‘unobserved’ voxels represent areas within the bounding box of the object that were not captured by the LiDAR due to occlusion.
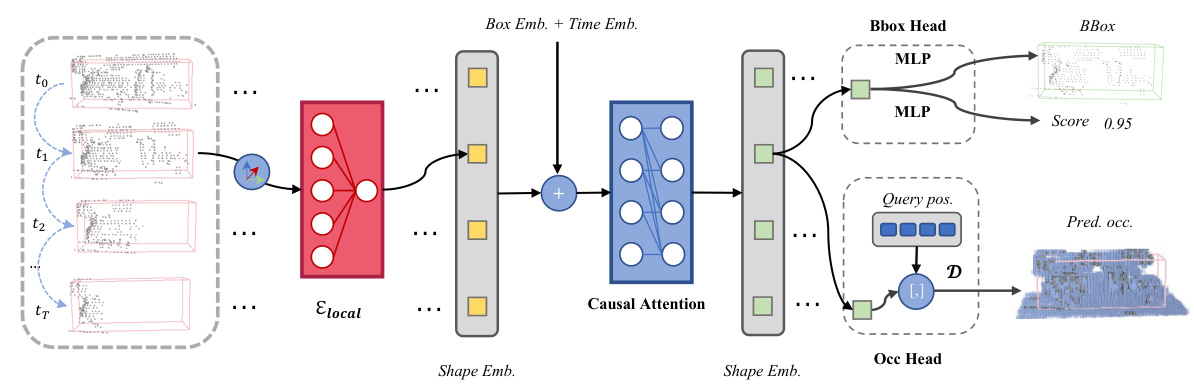
This figure illustrates the architecture of the object-centric occupancy completion network. The network takes a noisy object sequence as input and outputs the complete object-centric occupancy volume and a refined bounding box for each proposal. The network consists of several components: a local encoder (Elocal) that encodes the ROI in the local coordinate system, a global encoder (Eglobal) that encodes the ROI in the global coordinate system, a causal attention module that aggregates temporal information from the global features, an implicit shape decoder (D) that predicts the complete occupancy volume from a latent embedding, a bbox head that refines the bounding box, and an occupancy head (Occ Head) that predicts the occupancy volume. The notation [,] denotes the concatenation operation, while ‘global’/’local’ indicates features from global/local coordinate systems.
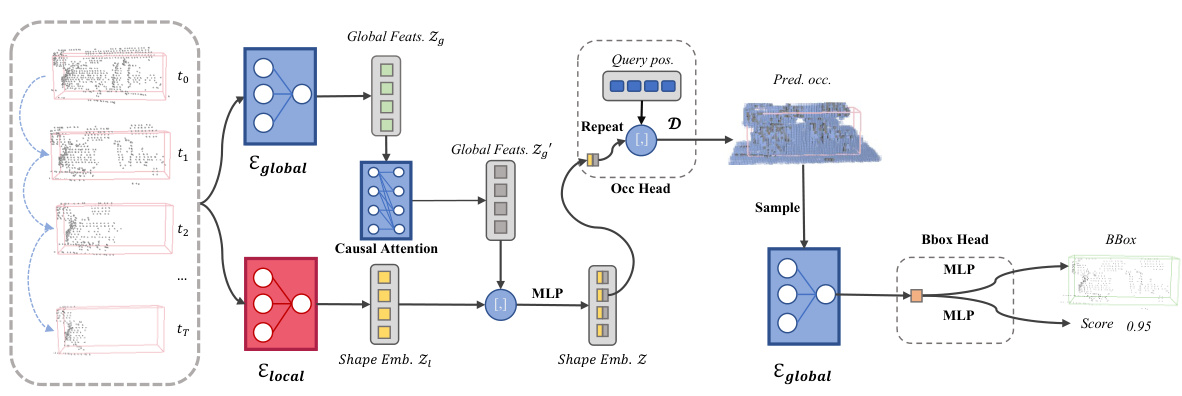
This figure shows the architecture of the object-centric occupancy completion network. The network takes a noisy object sequence as input, which includes point clouds and noisy bounding boxes at different timestamps. It processes this sequence through two branches: a global branch and a local branch. The global branch encodes the RoI (region of interest) in the global coordinate system, providing motion information. The local branch encodes the RoI in the local coordinate system. A causal attention mechanism combines information from the global branch across timestamps to enhance the local features. This combined information then feeds into an implicit shape decoder which outputs the complete object-centric occupancy volume. Finally, a detection head refines the bounding boxes and scores.
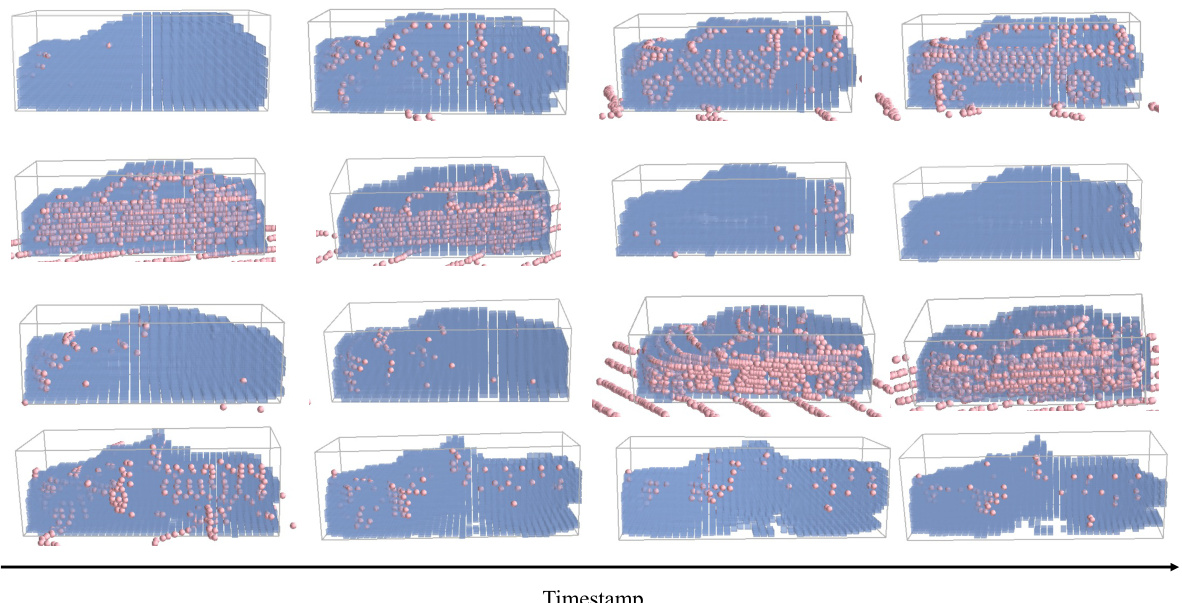
This figure visualizes the results of the object-centric occupancy prediction. Each row displays a different object. Pink points show the LiDAR points used in the prediction, while blue cubes represent the predicted occupied voxels. This provides a visual representation of how the model reconstructs the shape of objects by filling in missing data points.
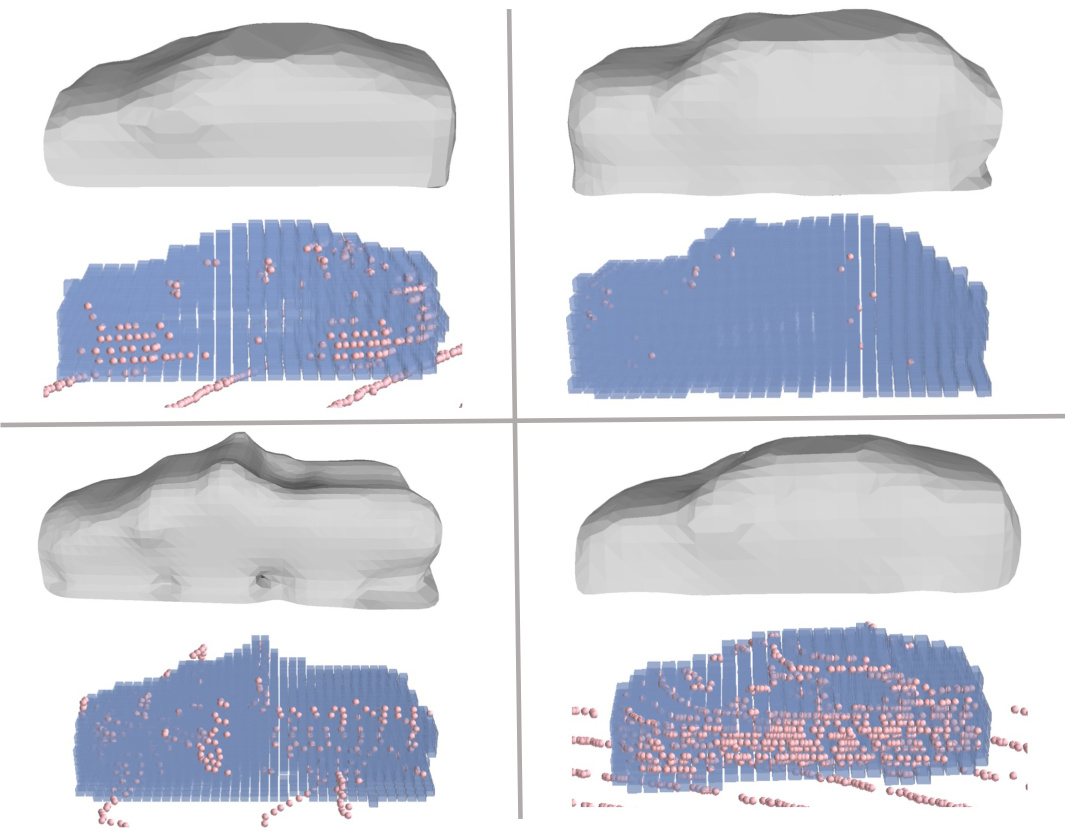
This figure visualizes the object-centric occupancy prediction results of the proposed method. Each row represents a different object. The pink points show the actual LiDAR points, while the blue cubes represent the voxels predicted as occupied by the model. The figure demonstrates the ability of the model to predict the shape of the objects, even in cases with occlusion or sparse LiDAR data.

This figure visualizes the results of the object-centric occupancy prediction. Each row shows a different object, represented by a 3D point cloud (pink points) and the predicted occupancy (blue cubes). The visualization highlights the model’s ability to predict the occupied voxels accurately, even in cases with sparse LiDAR point clouds, showcasing its effectiveness in reconstructing complex object shapes from incomplete data.
More on tables
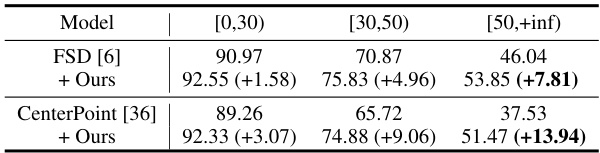
This table presents the 3D detection results on the Waymo Open Dataset (WOD) validation set, broken down by range. It shows significant improvements when the authors’ method is applied to tracklet proposals generated by CenterPoint and FSD. The improvements are more substantial at longer ranges, demonstrating the effectiveness of the method in addressing sparsity issues affecting distant objects.
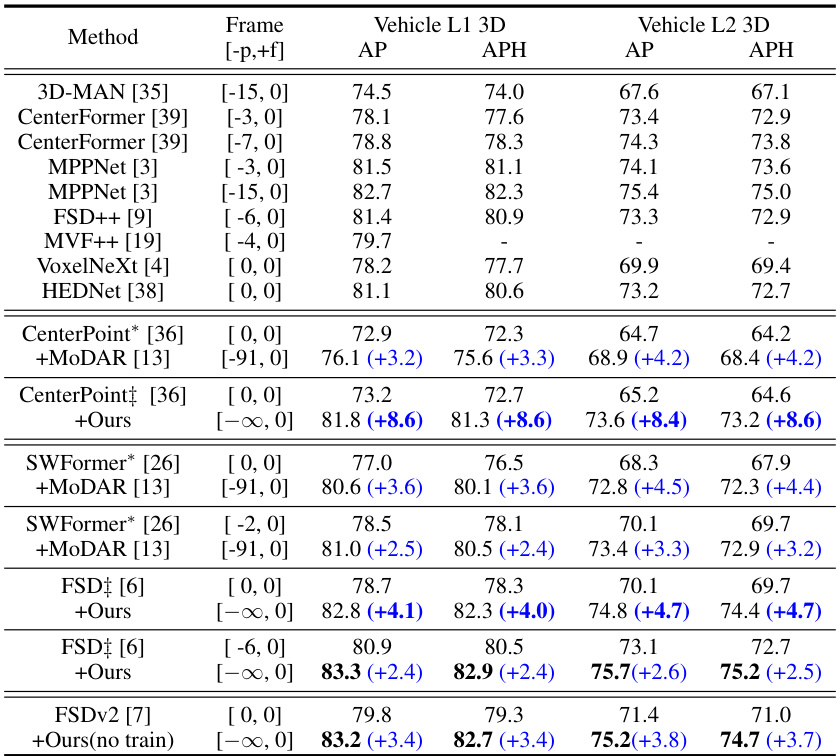
This table presents the 3D detection results on the Waymo Open Dataset (WOD) validation set. It compares the performance of several methods, including the authors’ proposed method, on different object detection tasks. The table shows Average Precision (AP) and Average Precision Weighted by Heading (APH) metrics for two difficulty levels (L1 and L2) of vehicles. Results are presented for various methods, including baselines (CenterPoint, SWFormer, FSD, etc.), and the same baselines with the addition of the proposed method or MoDAR. The ‘Frame’ column shows the number of frames used for each method. Blue numbers indicate the improvement achieved by the authors’ method compared to the baseline.

This table presents a comparison of different model designs, showing the impact of various design choices on shape completion and 3D detection performance. The models compared are: the full model (Ours), a single-branch model, a model using explicit occupancy, and a model without the occupancy decoder. The results are presented as IoU (Intersection over Union) for shape completion and AP/APH (Average Precision/Average Precision weighted by Heading) for 3D detection on the vehicle category of the Waymo Open Dataset, broken down into Level 1 and Level 2 difficulty levels.

This table presents the results of experiments conducted with varying lengths of training and testing sequences, demonstrating the impact of temporal context on the performance of the object-centric occupancy completion network. The table shows that longer training sequences generally lead to better performance, although the improvements diminish beyond a certain length. It also illustrates the model’s flexibility in handling variable-length sequences during inference, as indicated by the results using subsets of historical frames.

This table shows the average inference time and GPU memory consumption of the proposed object-centric occupancy completion network with and without the implicit shape decoder. The results demonstrate that the addition of the shape decoder only introduces a slight increase in computational cost, highlighting its efficiency.
Full paper#