↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Existing video-to-3D/4D models struggle with dynamic multi-object scenes due to limitations in handling fast motion and scene complexity. Current generative models work well on individual objects but not entire scenes, rendering error gradients are often insufficient to recover fast object motion, and score distillation objectives don’t apply effectively at the scene level. This limits their applicability in scenarios such as robot perception and augmented reality.
DreamScene4D overcomes these limitations with a novel “decompose-recompose” strategy. It separates the video into background and individual object tracks, factorizing object motion into three components (object-centric deformation, object-to-world transformation, and camera motion). This allows the model to leverage object-centric view predictive models while bounding box tracks guide the large object movements. Results show significant improvements in 4D scene generation, novel view synthesis, and 2D persistent point tracking on various challenging datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents DreamScene4D, the first method to generate dynamic 3D scenes with multiple objects from monocular videos, addressing limitations in existing generative models. This opens avenues for advanced video understanding, robot perception, and augmented/virtual reality applications. The accurate 2D persistent point tracking and 360° novel view synthesis also offers valuable improvements to existing video analysis techniques.
Visual Insights#

This figure demonstrates the capabilities of DreamScene4D in generating 3D dynamic scenes from monocular videos. It shows two example videos. The left side shows a person kicking a soccer ball, and the right side shows a person walking a dog. For each video, the top row displays the input frames, and the following rows depict 360° novel view synthesis results, illustrating the method’s ability to generate realistic and consistent 3D scene representations across different viewpoints and timesteps. The generated views include both the reference viewpoint and novel viewpoints.
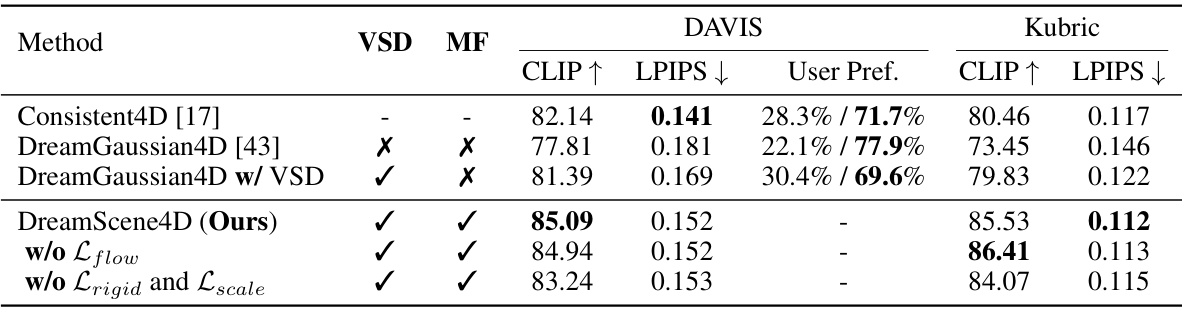
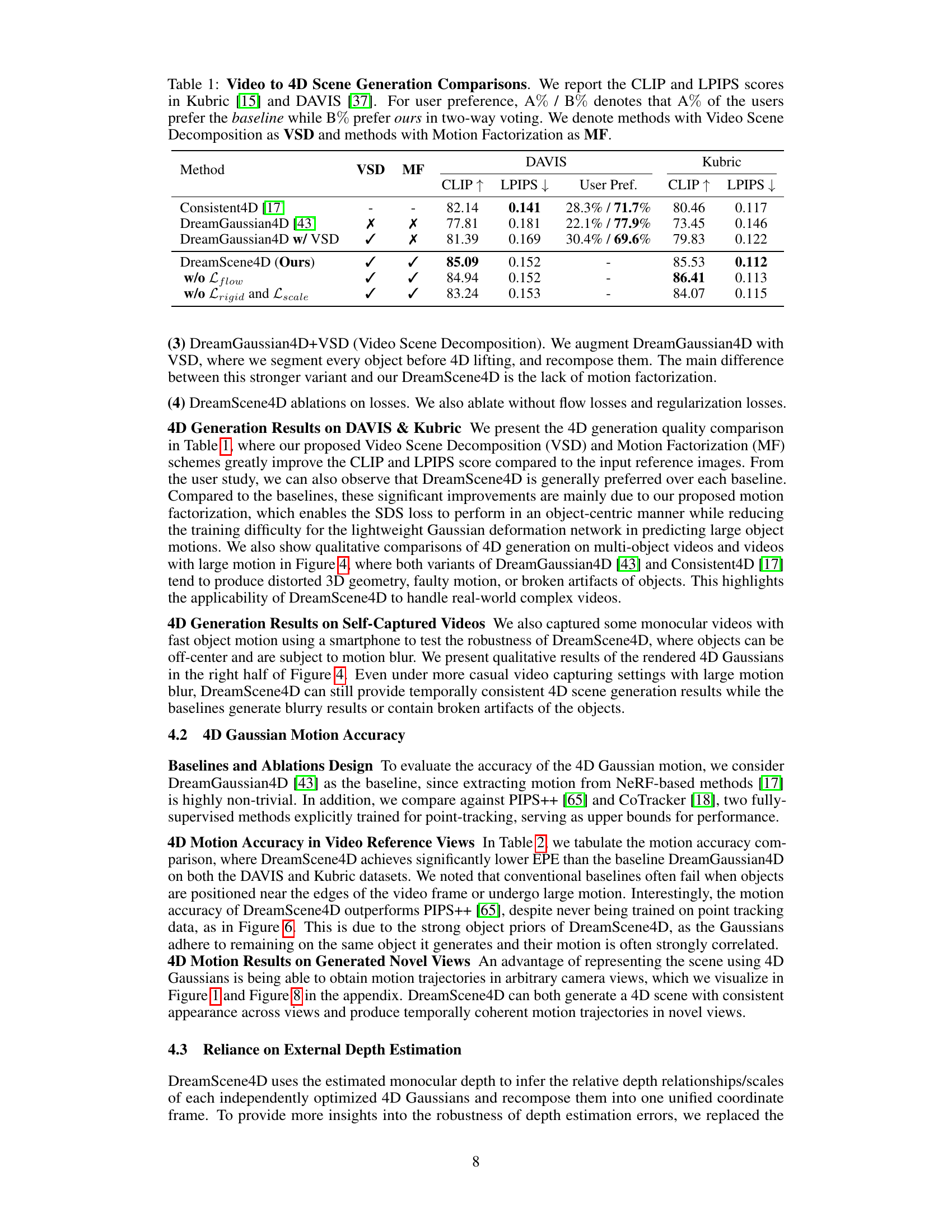
This table compares the performance of DreamScene4D against several baseline methods for video-to-4D scene generation on the DAVIS and Kubric datasets. The comparison uses CLIP and LPIPS scores to evaluate the visual quality of the generated 4D scenes. User preference is also measured through a two-way voting system. The table indicates whether each method incorporates Video Scene Decomposition (VSD) and/or Motion Factorization (MF). Ablation studies on DreamScene4D (removing different components) are also shown.
In-depth insights#
4D Scene Synthesis#
4D scene synthesis, as explored in this research paper, presents a significant advance in computer vision by enabling the generation of realistic and dynamic 3D scenes from monocular video input. The core challenge lies in bridging the gap between sparse 2D observations and rich 4D representations, especially when dealing with multiple objects exhibiting fast motion and occlusions. The proposed “decompose-recompose” approach directly addresses these challenges by breaking down the complex scene into manageable components: background, individual objects, and their corresponding motions. This decomposition facilitates effective 3D object completion and motion factorization, leveraging object-centric generative models to enhance accuracy and efficiency. The factorization of object motion into camera, object-to-world, and deformation components is particularly crucial, enhancing the optimization stability and leading to more robust results. The integration of monocular depth guidance further refines the scene composition, resulting in more coherent and accurate 4D models. The quantitative and qualitative evaluations demonstrate significant improvements over existing state-of-the-art methods, highlighting the effectiveness of the proposed framework in generating 4D scenes that faithfully capture the dynamic aspects of multi-object scenarios.
Motion Factorization#
The concept of ‘Motion Factorization’ in the context of video-to-4D scene generation is a crucial innovation. It addresses the challenge of handling complex, fast object movements within dynamic scenes by decomposing the 3D motion into three key components: camera motion, object-centric deformation, and object-to-world-frame transformation. This decomposition significantly improves the stability and quality of motion optimization. By separating these aspects, the model tackles the challenges associated with rendering error gradients that are often insufficient to capture fast movement and the limitations of view-predictive models which work better for individual objects than entire scenes. Object-centric components, particularly deformation, are handled by object-centric generative models, leveraging their effectiveness in predicting novel views. The world-frame transformation is guided by bounding box tracking, providing robust handling of larger-scale movements. Camera motion is estimated by re-rendering static background components, creating a more well-defined and accurate motion representation. This multi-faceted approach is key to DreamScene4D’s success in generating high-quality, dynamic 4D scenes from monocular videos, surpassing the capabilities of existing video-to-4D methods.
Amodal Video Completion#
Amodal video completion, as discussed in the supplementary materials, addresses the challenge of reconstructing occluded regions in videos. The approach builds upon Stable Diffusion, incorporating spatial-temporal self-attention to leverage information across frames and enhance consistency. A key innovation is the latent consistency guidance, which enforces temporal coherence during the denoising process, ensuring that the completed video frames are temporally consistent. This technique enhances the quality of the completion, particularly for scenarios with complex motion or occlusions. The method demonstrates improvements over existing inpainting techniques, particularly in preserving identity consistency and temporal coherence. Zero-shot generalization capability is achieved by adapting the method to videos without further fine-tuning. The results show significant improvements in PSNR, LPIPS scores, and temporal consistency metrics compared to baselines, highlighting the effectiveness of the proposed enhancements. Limitations remain in scenarios with heavy occlusions, where inpainting fails and artifacts can arise. Future work could incorporate semantic guidance loss to improve performance and address these limitations.
Depth-guided Composition#
Depth-guided composition, in the context of 3D scene reconstruction from videos, is a crucial step that leverages depth information to intelligently integrate multiple independently processed objects into a unified, coherent scene. Accurate depth estimation is paramount, as it dictates the relative distances and spatial relationships between objects within the 3D model. This process goes beyond simple layering; it involves resolving occlusions, ensuring proper object scaling and placement, and maintaining realistic spatial consistency. A robust depth-guided approach carefully considers the uncertainties inherent in depth estimation, potentially employing techniques like uncertainty-aware fusion or probabilistic methods to handle noisy or incomplete depth maps. Furthermore, sophisticated algorithms are needed to reconcile conflicts arising from occlusions or inconsistent depth values, perhaps through iterative refinement or optimization schemes that minimize inconsistencies between rendered views and the original video frames. Successful depth-guided composition is critical for generating high-fidelity and visually plausible 3D dynamic scenes.
Future of Video4D#
The future of Video4D research is incredibly promising, driven by the need for more robust and nuanced scene understanding. Significant advancements are expected in handling complex scenarios involving occlusions, intricate object interactions, and rapid motions. This will likely involve integrating advanced techniques from fields like computer graphics and robotics, such as physics-based modeling and more sophisticated tracking algorithms. The development of more comprehensive and accessible datasets is crucial, especially those with diverse lighting conditions and camera viewpoints. This will enable the training of more robust and generalizable Video4D models. Further research into efficient representations for dynamic scenes, perhaps leveraging techniques beyond neural radiance fields, is also vital, particularly to tackle the computational challenges involved in processing high-resolution, long-duration videos. Ultimately, the goal is to move beyond simple reconstruction and toward a richer understanding of the 4D world, capable of supporting tasks such as autonomous navigation, virtual and augmented reality experiences, and advanced video editing tools.
More visual insights#
More on figures
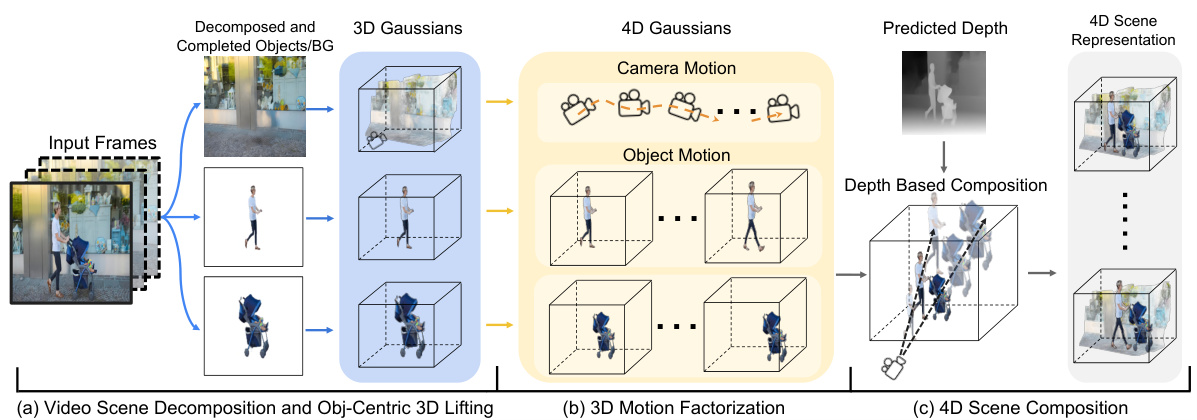
This figure shows a high-level overview of the DreamScene4D method. It’s broken down into three stages: (a) Video Scene Decomposition and Obj-Centric 3D Lifting, (b) 3D Motion Factorization, and (c) 4D Scene Composition. In the first stage, the input video frames are decomposed into individual objects and the background. These components are then amodally completed and lifted into 3D Gaussian representations. The second stage involves factorizing object motion into camera motion, object-centric deformations, and object-to-world frame transformations. These motion components are optimized independently. Finally, the third stage involves recomposing these optimized 4D Gaussians into a unified coordinate frame using monocular depth information, yielding a complete 4D scene representation.

This figure illustrates the three components into which DreamScene4D factorizes 3D motion for improved stability and quality in motion optimization. These components are: object-centric deformation (changes in object shape and form), camera motion (movement of the camera itself), and object-centric to world frame transformation (changes in object position and orientation within the scene). The process starts with 3D Gaussians representing the object, which are then optimized using a combination of rendering losses and score distillation sampling (SDS) along with constraints such as flow rendering loss, scale regularization, and rigidity. These optimized components are then combined to reconstruct the original object motion from the video.

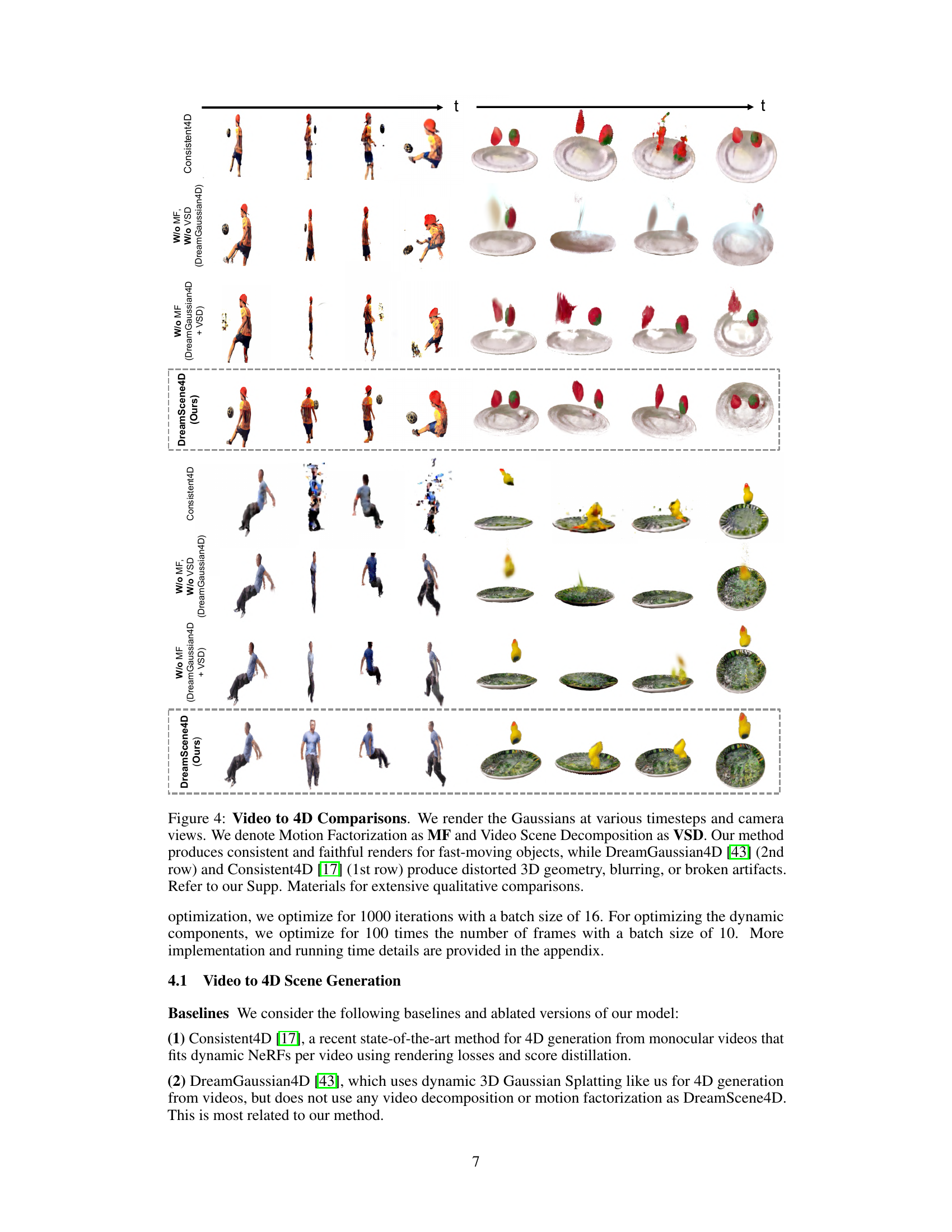
This figure compares the video-to-4D generation results of DreamScene4D against several baselines (Consistent4D and DreamGaussian4D). It shows that DreamScene4D produces more realistic and consistent 4D scene generation results, especially for videos with fast-moving objects. The other methods show artifacts like distortions, blurring, and broken objects.
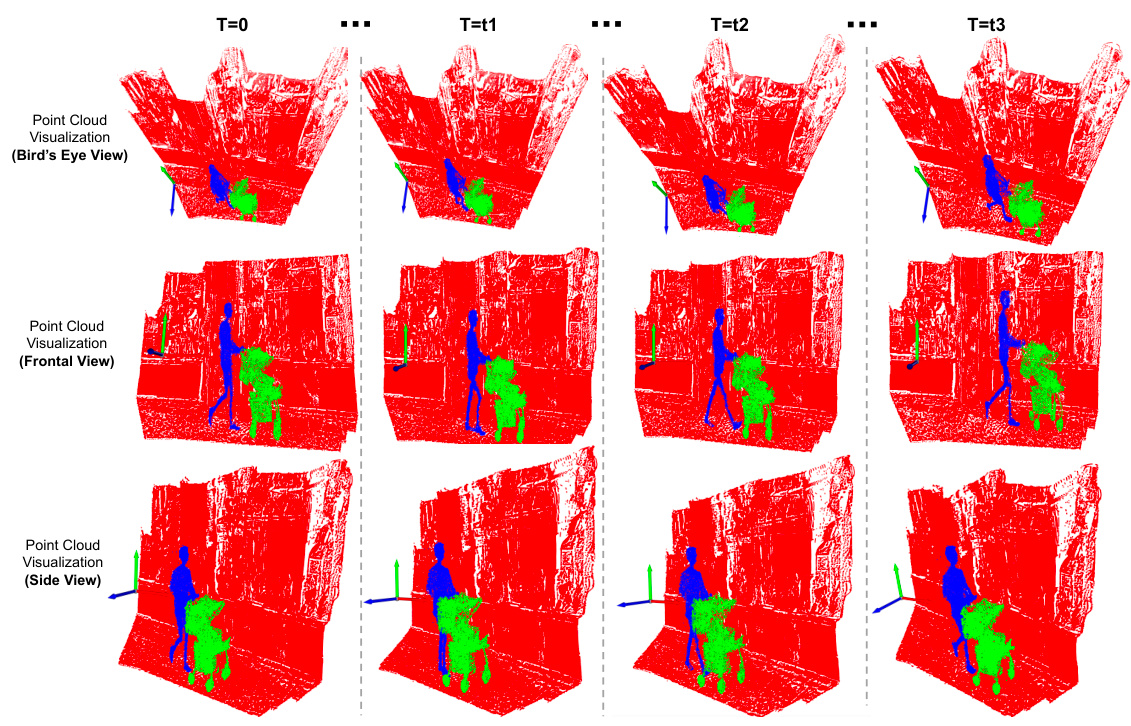
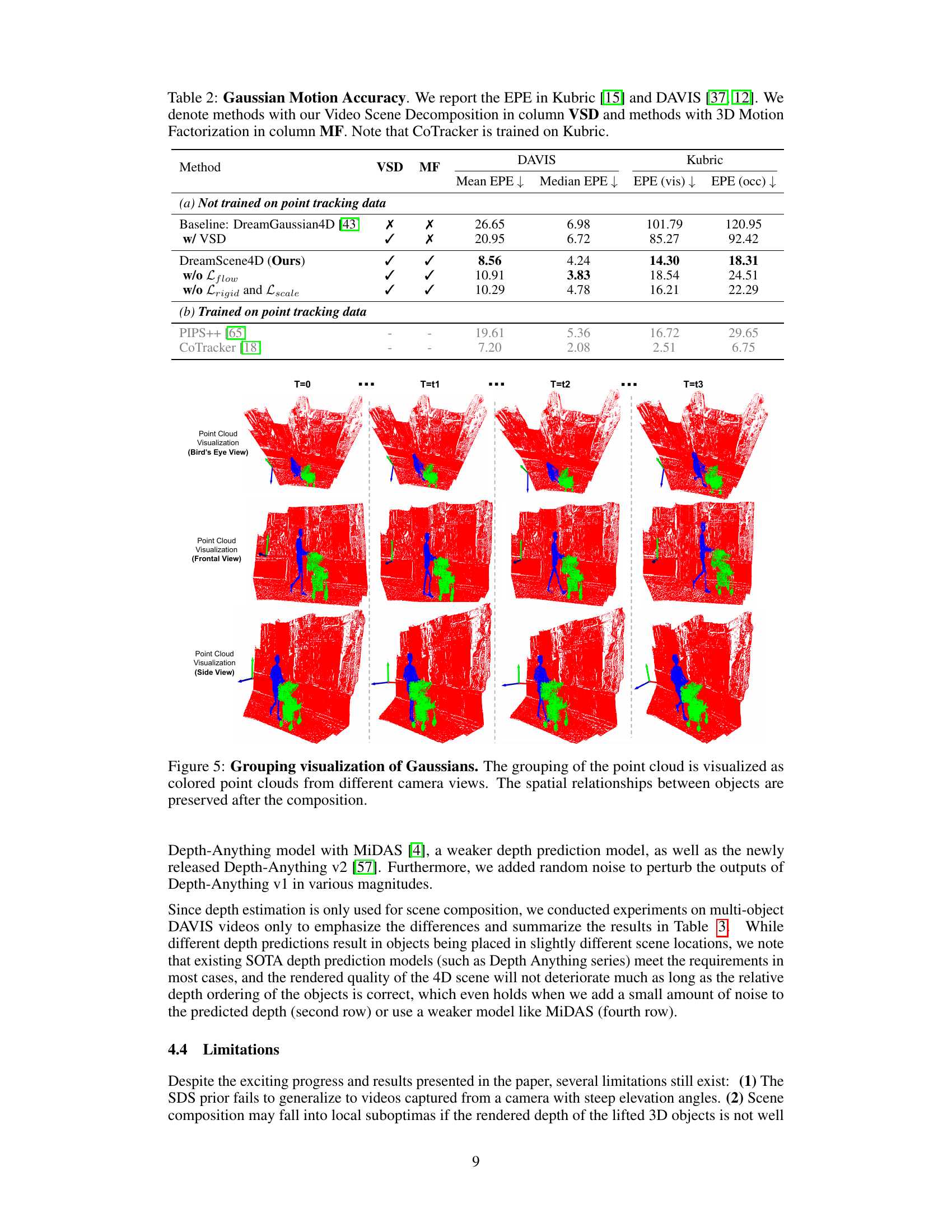
This figure visualizes the grouping of Gaussians from different viewpoints (bird’s eye view, frontal view, and side view) at different time steps (T=0, T=t1, T=t2, T=t3). The spatial relationships between objects are maintained after the composition process, demonstrating the effectiveness of the proposed method in preserving the scene structure.

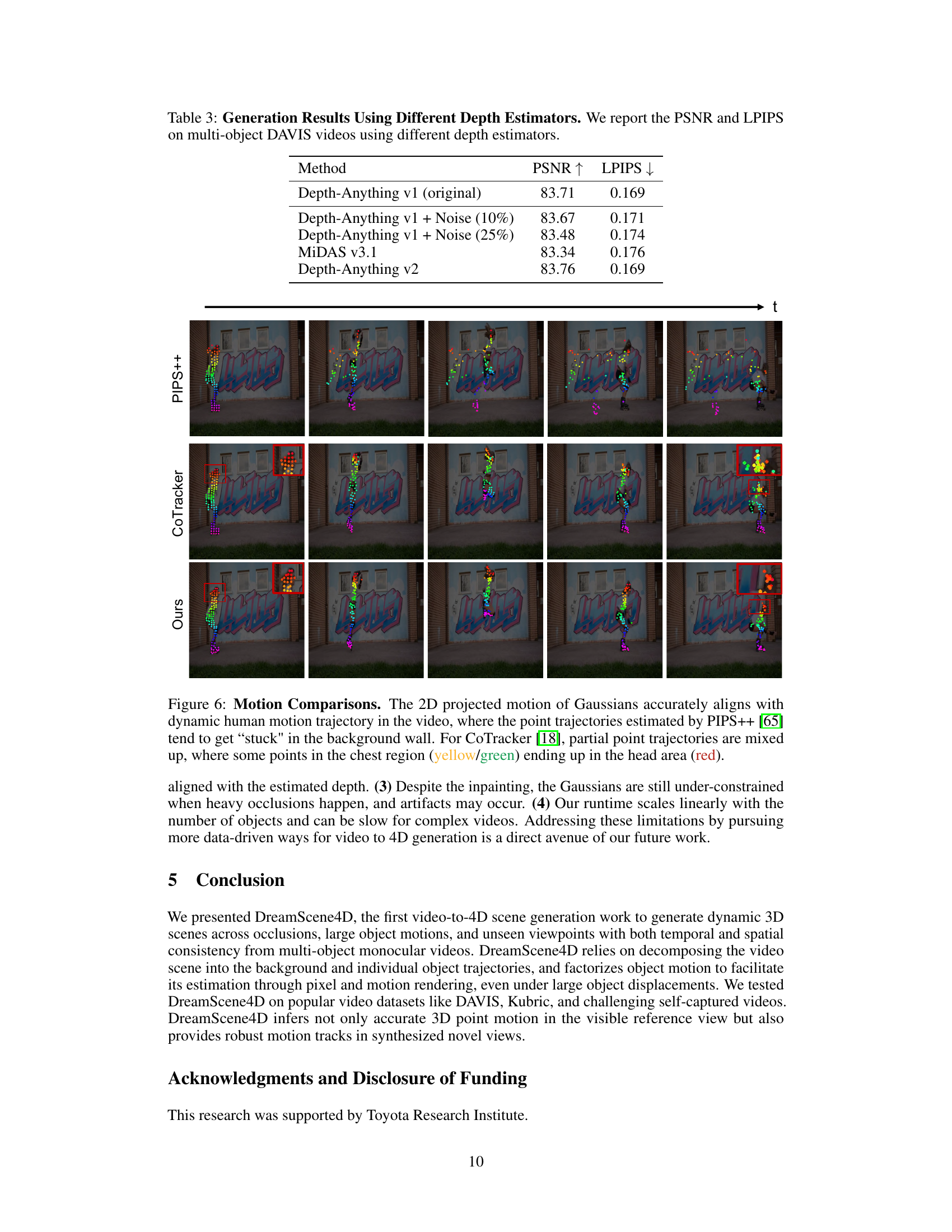
This figure compares the 2D projected motion of Gaussians generated by DreamScene4D against two state-of-the-art methods, PIPS++ and CoTracker, on a video of a person skateboarding. DreamScene4D demonstrates accurate alignment with the actual motion, while PIPS++ and CoTracker exhibit inaccuracies, such as points ‘getting stuck’ or being misaligned.

This figure shows the graphical user interface (GUI) used in a user study conducted on Amazon Mechanical Turk (AMT). The AMT workers were presented with three video clips for comparison: the original video and two novel view videos (orbit videos A and B) generated from different viewpoints. They were then asked to choose which of the orbit views best represents the original video, or to indicate if they viewed the orbit views as equally good representations. This figure is an example of the screen presented to the AMT workers, illustrating the simple user interface and the choices they were presented with.
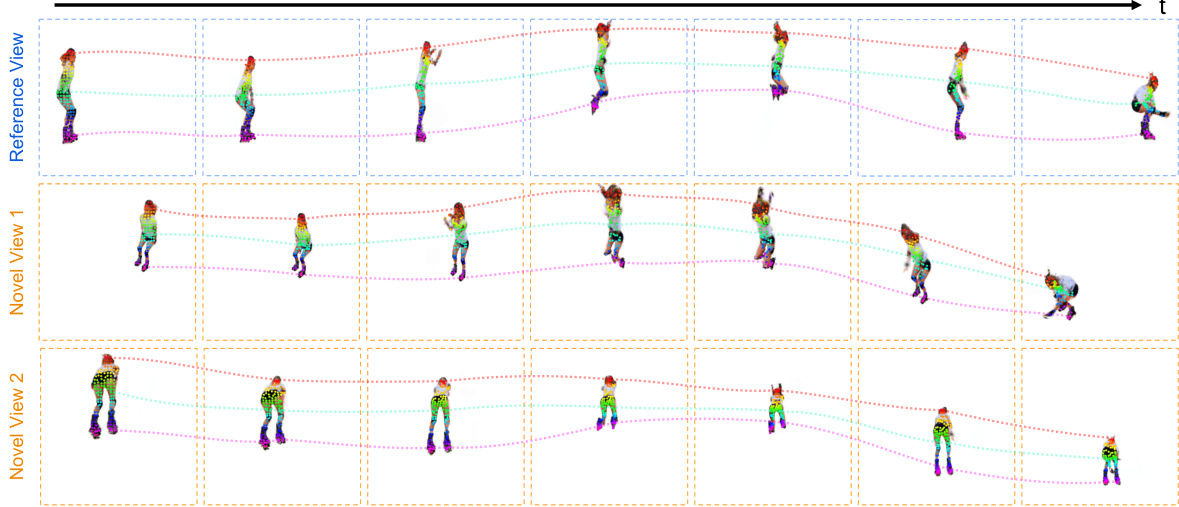
This figure shows the visualization of Gaussian motion trajectories. The top row displays the reference view of the video, showing the motion of the object. The bottom two rows depict novel views, generated by the model. The consistency of the trajectories across different viewpoints highlights the model’s ability to produce accurate motion without explicit supervision.

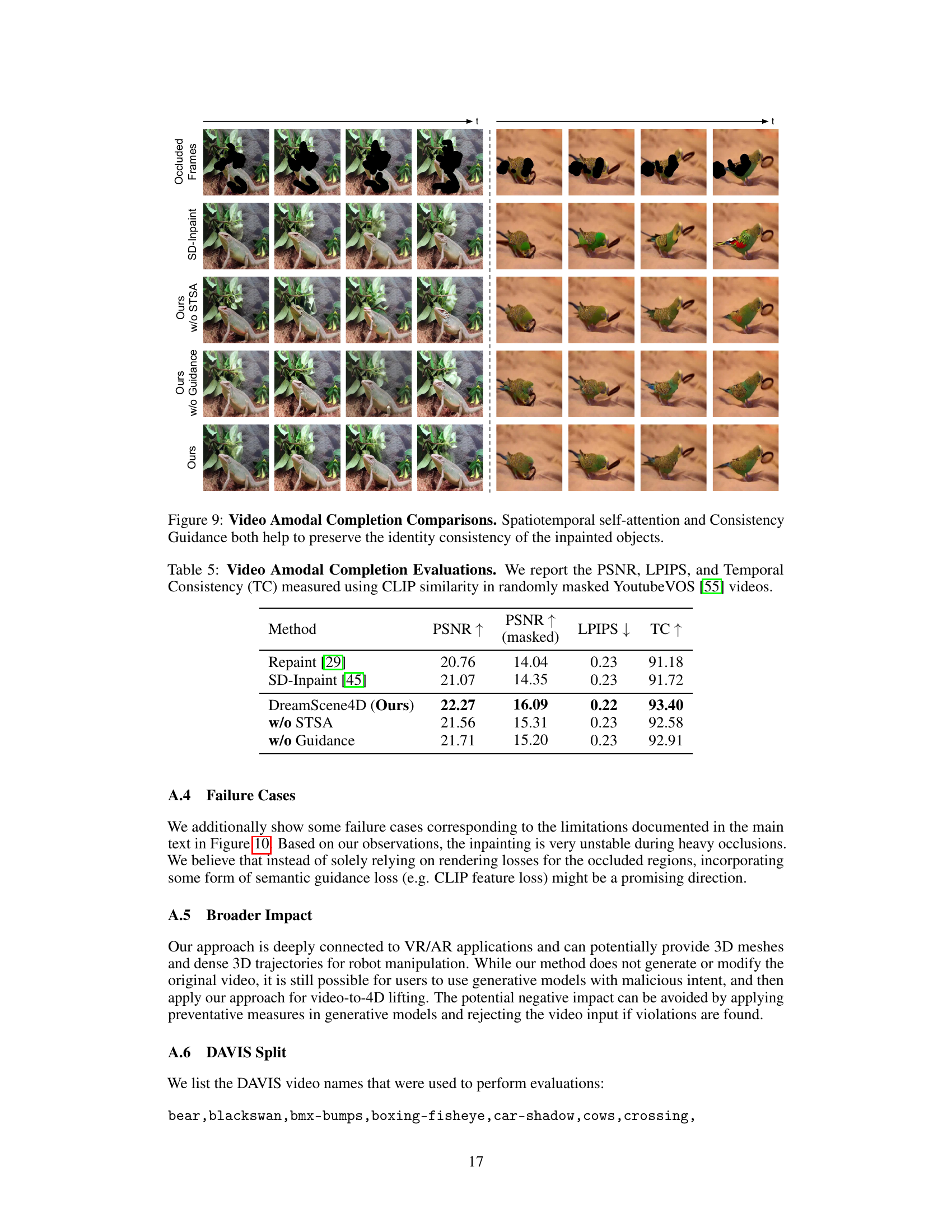
This figure compares the performance of different video inpainting methods. The left column shows the results of inpainting a video of a lizard, while the right column shows the results of inpainting a video of parrots. Each row represents a different method: SD-Inpaint (a baseline method), Ours (without spatiotemporal self-attention), Ours (without consistency guidance), and Ours (our full method). The figure demonstrates that incorporating spatiotemporal self-attention and consistency guidance significantly improves the quality of the inpainted videos, resulting in more coherent and realistic results.

This figure compares the 4D scene generation results of DreamScene4D with two state-of-the-art baselines (Consistent4D and DreamGaussian4D) across multiple challenging videos with fast object motion. The comparison highlights DreamScene4D’s ability to generate consistent and realistic 4D scene representations, in contrast to the baselines, which show artifacts like distorted 3D geometry, blurring, and broken objects. DreamScene4D’s superior performance stems from its novel motion factorization and video scene decomposition strategies.

This figure shows the effect of a small amount of joint fine-tuning steps on mitigating the parallax effect and aligning the rendered 3D Gaussians to the input video frames. The top row shows the result without this fine-tuning, while the bottom row demonstrates how the process improves the alignment, resulting in a more realistic rendering.
More on tables
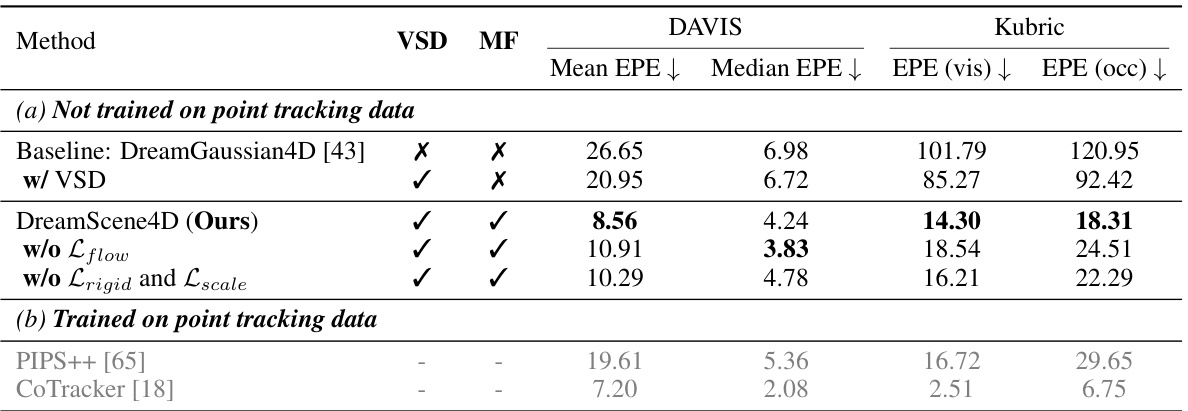
This table presents a comparison of the End Point Error (EPE) for different methods on the DAVIS and Kubric datasets. The EPE measures the accuracy of 3D motion estimation. It compares DreamScene4D to baselines (DreamGaussian4D, with and without video scene decomposition) and methods specifically trained on point tracking (PIPS++, CoTracker). The table highlights the improvements achieved by DreamScene4D’s motion factorization and video scene decomposition, particularly in reducing the EPE for both visible and occluded points.

This table presents the Peak Signal-to-Noise Ratio (PSNR) and Learned Perceptual Image Patch Similarity (LPIPS) scores for 4D scene generation on multi-object DAVIS videos using various depth estimation methods. The methods compared include the original Depth-Anything v1, Depth-Anything v1 with added noise (10% and 25%), MiDAS v3.1, and Depth-Anything v2. The results demonstrate the robustness of the DreamScene4D approach to variations in depth estimation accuracy.

This table compares the performance of DreamScene4D against several baselines on two video datasets: DAVIS and Kubric. The comparison uses CLIP and LPIPS scores to evaluate the quality of 4D scene generation, and includes a user preference study to gauge the relative appeal of each method’s output. The table also indicates whether each method uses Video Scene Decomposition (VSD) or Motion Factorization (MF).

This table presents a comparison of video amodal completion methods. It shows the Peak Signal-to-Noise Ratio (PSNR), Learned Perceptual Image Patch Similarity (LPIPS), and Temporal Consistency (TC) scores for different approaches. The methods compared include Repaint [29], SD-Inpaint [45], and the authors’ method, DreamScene4D. Ablation studies removing the spatiotemporal self-attention (STSA) and consistency guidance components from DreamScene4D are also included to assess their individual impact on the results.
Full paper#