↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deepfakes, particularly those manipulating lip synchronization with audio, pose a significant threat. Existing methods often struggle to detect these subtle forgeries due to lack of visual artifacts and identity changes. This research addresses the challenge by focusing on the temporal inconsistencies between lip movements and accompanying audio. The paper highlights the difficulty in detecting lip-syncing deepfakes compared to other types, and its impact across various applications.
The researchers propose a novel method, LipFD, which exploits these audio-visual inconsistencies. LipFD leverages a dual-headed model architecture capturing both global temporal correlations and subtle regional discrepancies. A high-quality dataset called AVLips is introduced, and experimental results demonstrate that LipFD significantly surpasses existing techniques in terms of accuracy and robustness, particularly in real-world scenarios. The research also highlights the limitations of existing methods when encountering high-quality forgeries and emphasizes the importance of further research.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and multimedia security due to the rising threat of sophisticated deepfakes. It introduces a novel approach for detecting lip-syncing forgeries, which are particularly challenging to detect. The high-quality dataset and robust method advance deepfake detection, opening up new avenues for research in this critical field. The proposed model’s ability to function in real-world scenarios, such as WeChat video calls, further increases its practicality and significance.
Visual Insights#

This figure compares different types of deepfakes. The top row shows examples of facial-editing deepfakes, which involve significant alterations such as face swapping, gender swapping, and age regression. The bottom two rows show examples of lip-syncing deepfakes, where the only manipulation is the synchronization of lip movements with a given audio. The figure highlights the difficulty of detecting lip-syncing deepfakes because they don’t involve obvious visual artifacts or identity changes.
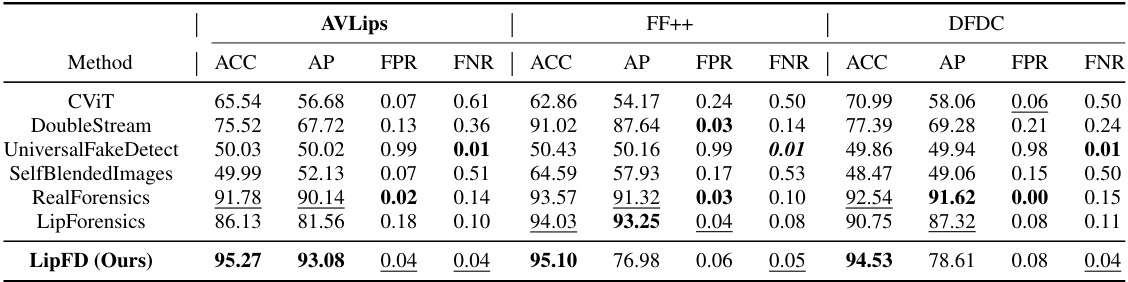
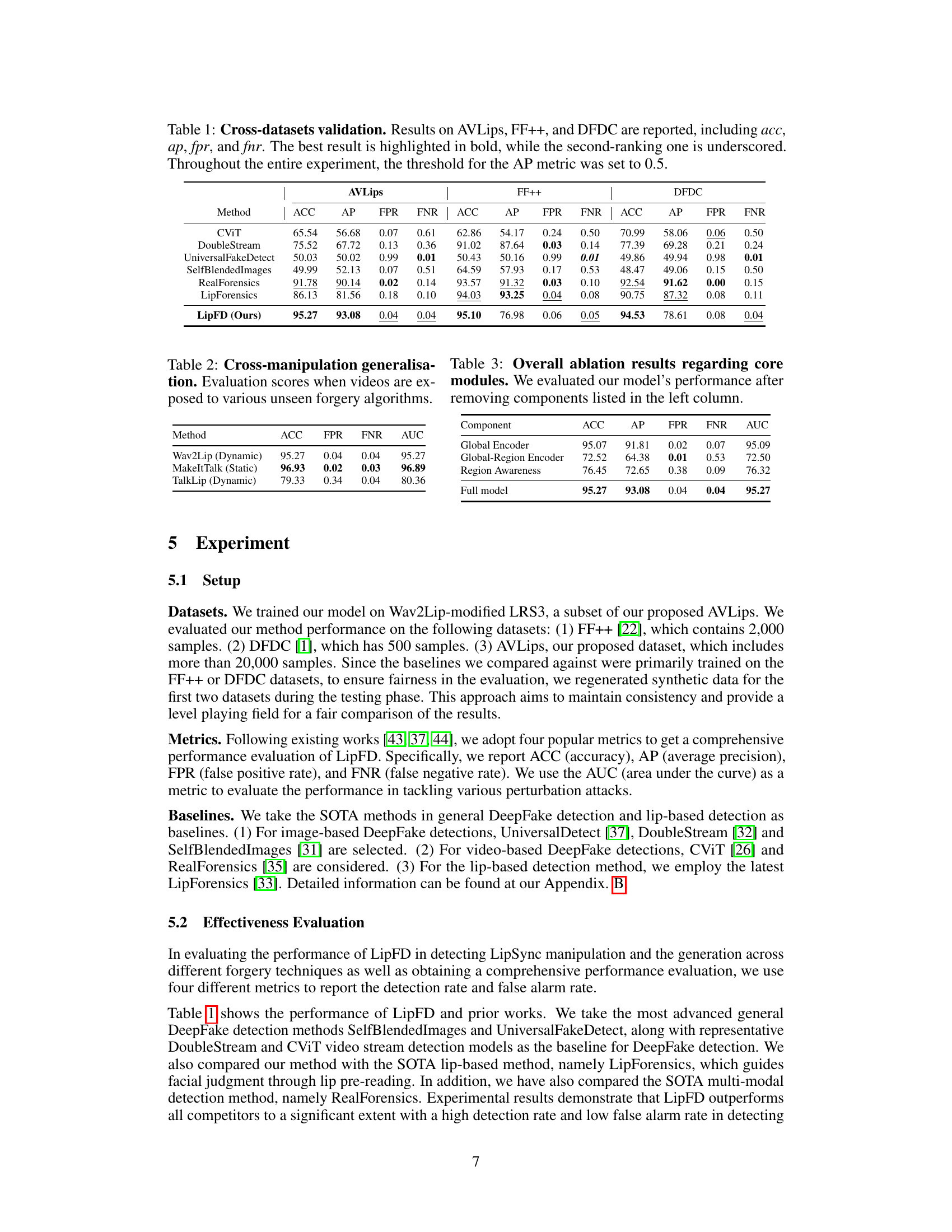
This table presents the performance comparison of LipFD and other state-of-the-art (SOTA) methods on three different datasets: AVLips, FaceForensics++, and DeepFake Detection Challenge dataset. The metrics used are accuracy (ACC), average precision (AP), false positive rate (FPR), and false negative rate (FNR). The best performing method for each dataset and metric is highlighted in bold, showing LipFD’s superior performance.
In-depth insights#
LipSync Deepfake Spotting#
LipSync deepfake spotting presents a significant challenge in the field of media forensics due to the subtle nature of these forgeries. Unlike other deepfakes that involve gross identity manipulation, LipSync deepfakes only alter the lip movements to match a given audio, leaving other facial features largely untouched. This makes them extremely difficult to detect using traditional visual analysis methods which typically focus on identifying visual inconsistencies like artifacts or inconsistencies in facial expressions. Effective detection methods therefore require a multimodal approach, combining audio and video analysis to identify inconsistencies in lip movements and audio synchronization. This is a complex task as it involves analyzing subtle and nuanced temporal relationships between lip movements and the corresponding audio spectrogram, accounting for individual variations in speech patterns and lip movements. A key area of research focus is the development of robust temporal alignment techniques that can accurately correlate lip movements and audio and identify deviations. Another challenge lies in the creation of high-quality, diverse datasets for training and evaluation of LipSync detection models. Existing deepfake datasets often lack the representation needed to specifically train on the subtle visual alterations found in LipSync videos. Therefore, the creation of new benchmark datasets with extensive, realistic examples will be crucial to advancing this critical field of research.
AVLips Dataset#
The AVLips dataset represents a significant contribution to the field of DeepFake detection, specifically targeting lip-syncing forgeries. Its high quality is achieved through the use of state-of-the-art lip-generation methods, ensuring realistic lip movements. The dataset’s diversity is also noteworthy, encompassing a wide range of scenarios including those from publicly available datasets and real-world settings. The inclusion of various perturbations adds to its robustness, enabling the training of more resilient models. By providing a dedicated resource for lip-syncing DeepFake detection, AVLips addresses a critical gap in existing datasets and fosters further research into this increasingly important area of security and misinformation. The availability of this high-quality, diverse dataset is crucial for the advancement of robust and generalizable DeepFake detection methods. Its comprehensive nature, including both audio and visual components, makes it uniquely suited to evaluate techniques focused on the temporal inconsistencies between lip movements and audio signals, a key characteristic of lip-syncing DeepFakes. The dataset is therefore a valuable resource for researchers and practitioners, accelerating the development of effective countermeasures against this sophisticated form of media manipulation.
Dual-Headed Model#
A dual-headed model in the context of a deepfake detection system likely refers to an architecture with two distinct processing pathways operating in parallel. One head might focus on global temporal features, capturing long-range dependencies between audio and visual information across the entire video sequence. This head could leverage a transformer architecture to identify inconsistencies in the overall synchronization. The second head, on the other hand, would concentrate on local spatial features, analyzing smaller regions of interest within individual frames. This approach could involve multiple convolutional layers operating on cropped image regions (e.g., lips, face, head), helping to pinpoint inconsistencies in lip movements or facial expressions that are not globally synchronized. The outputs of both heads are combined, potentially through weighted fusion or concatenation, for a final classification decision. This dual-headed model design allows for a more holistic and nuanced analysis of deepfake videos, leveraging both macro-level temporal relationships and subtle micro-level visual details to improve detection accuracy and robustness.
Robustness Analysis#
A robustness analysis in a deepfake detection context evaluates the model’s resilience against various corruptions and perturbations. A robust model should maintain high accuracy even under adverse conditions, such as noise, compression artifacts, or other manipulations. The analysis typically involves testing the model on modified versions of the original data, systematically introducing different types and levels of perturbations. Key aspects to consider include the types of perturbations used (e.g., Gaussian noise, JPEG compression, blurring), their intensity levels, and the evaluation metrics employed (e.g., AUC, accuracy, precision). A thoughtful robustness analysis goes beyond simply reporting performance under various attacks; it seeks to understand why the model is robust or not, providing insights into its strengths and weaknesses. For example, does the model’s performance degrade more significantly with high-frequency noise than low-frequency noise? Understanding this can inform improvements in model architecture or data augmentation strategies. Finally, a robust model should generalize well to unseen data and unseen types of perturbations, demonstrating that the robustness observed is not an artifact of the specific training data or attack types.
Future Directions#
The research paper’s “Future Directions” section would ideally explore extending the LipSync forgery detection model’s capabilities to encompass multilingual support. The current model’s performance might vary across languages due to phonetic and prosodic differences affecting lip movements. Addressing this requires training the model on diverse linguistic datasets. Another critical area is developing real-time detection algorithms. The present method lacks the speed required for applications like live video streaming and conferencing. Optimizing the model’s architecture and leveraging hardware acceleration could achieve real-time performance. Finally, exploring new types of audio-visual inconsistencies for forgery detection is warranted. As methods for generating LipSync deepfakes evolve, new inconsistencies may emerge that are currently undetected. Investigating and incorporating these into the model would enhance its robustness against future deepfake techniques. Dataset expansion with more diverse real-world scenarios is also key to ensure the model’s generalizability and effectiveness.
More visual insights#
More on figures

This figure shows a comparison between real and fake lip-sync videos. The top part displays spectrograms which represent audio frequencies. The bottom part shows a sequence of frames. (a) shows a real video: a woman is speaking, the spectrogram shows that frequencies increase at the beginning of her speech and gradually decrease. (b) shows a fake video: a man’s mouth movements are not synchronized with the audio spectrogram.
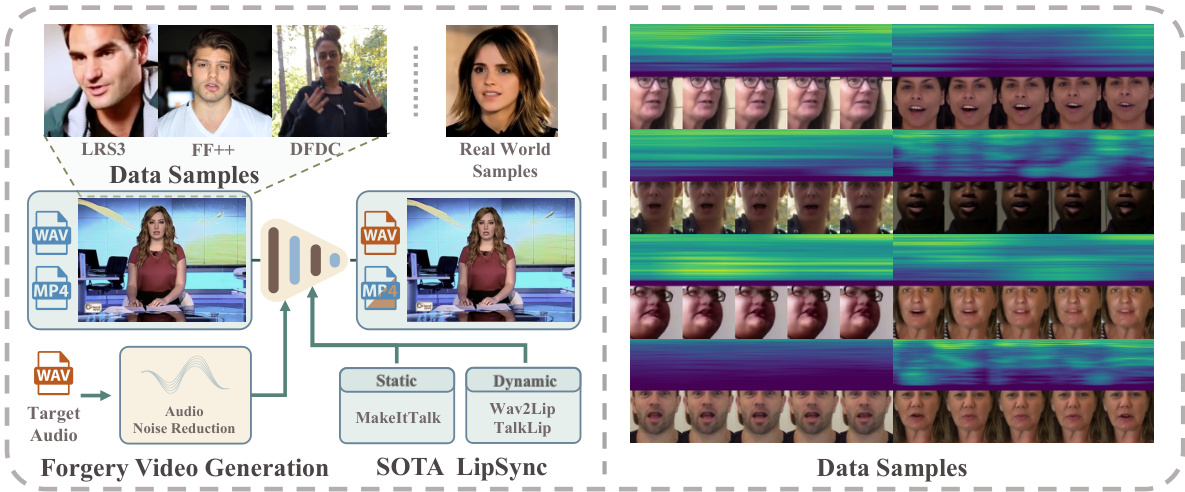
The figure illustrates the process of creating the AVLips dataset. It starts with data samples from LRS3, FaceForensics++, DFDC, and real-world videos. These videos and their corresponding audio are processed using static (MakeItTalk) and dynamic (Wav2Lip, TalkLip) LipSync generation methods. Noise reduction is applied to the audio before video generation. The resulting videos undergo several types of perturbations (noise, compression, etc.) for robustness. The final dataset includes diverse real-world scenarios and various lip movements.

This figure presents a detailed overview of the LipFD framework, highlighting its core modules and workflow. LipFD processes both video and audio inputs to detect lip-syncing inconsistencies. It consists of four main components: 1) Global Feature Encoder, which captures long-term audio-visual relationships using self-attention; 2) EGR (Encoder for Global-Region), encoding features from different facial regions; 3) Region Awareness, dynamically adjusting the attention weights based on region importance; 4) Fusion and Classification, combining features for the final decision.
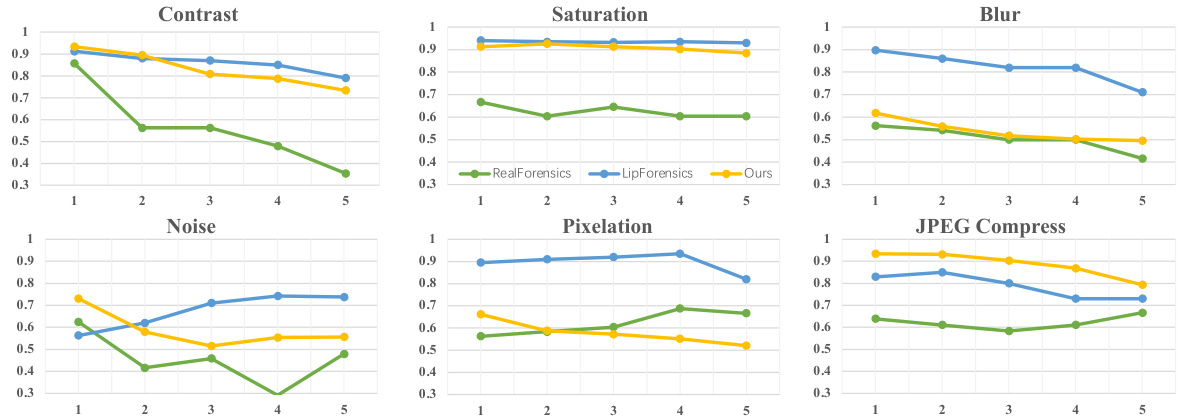
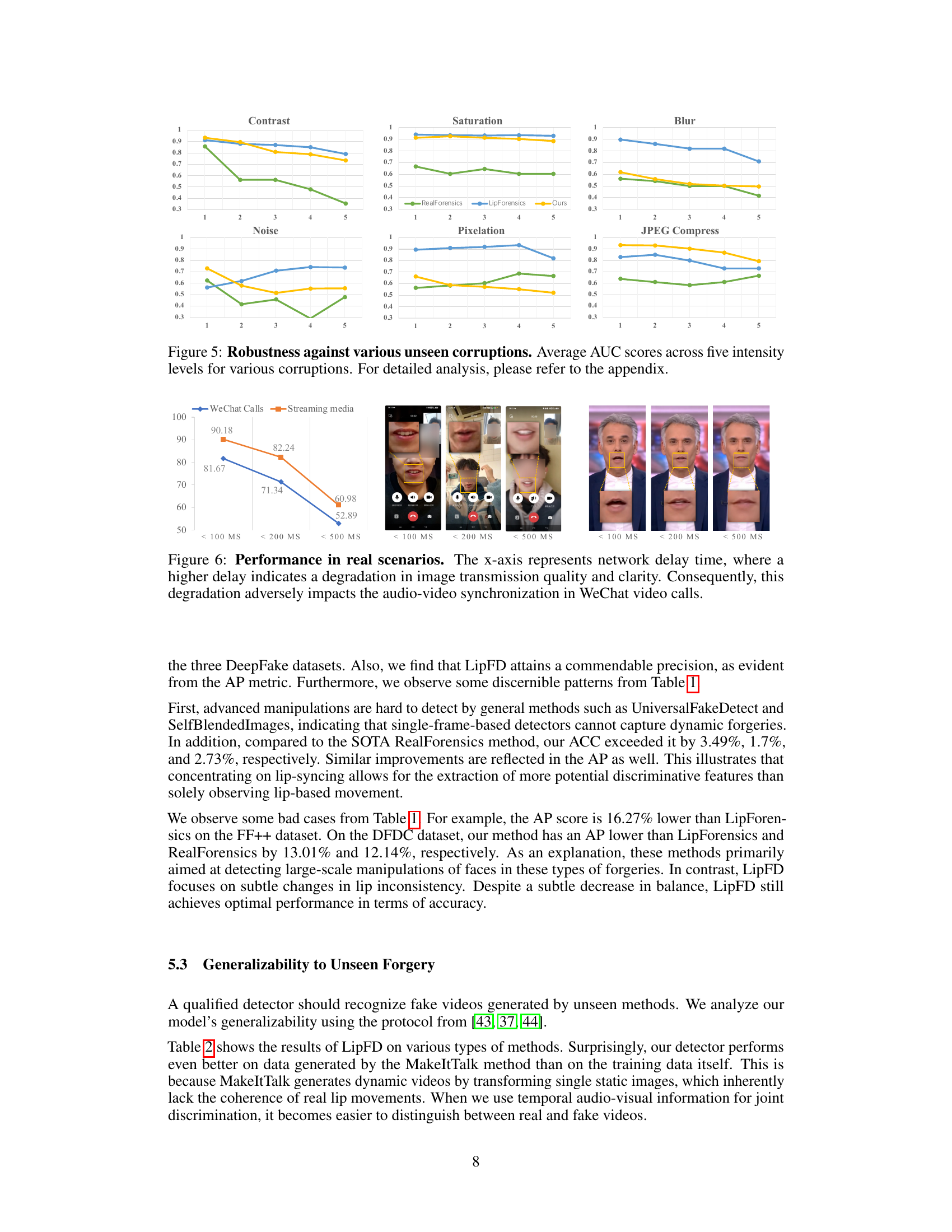
This figure demonstrates the robustness of the proposed LipFD model against various image corruptions. The AUC (Area Under the Curve) scores are shown for five different corruption types (Contrast, Saturation, Blur, Noise, Pixelation, JPEG Compression) across five different intensity levels. Each line represents the performance of a different model (RealForensics, LipForensics, and the proposed LipFD model). The higher the AUC score, the better the model’s performance in the presence of corruption. The appendix provides a more detailed breakdown of these results.
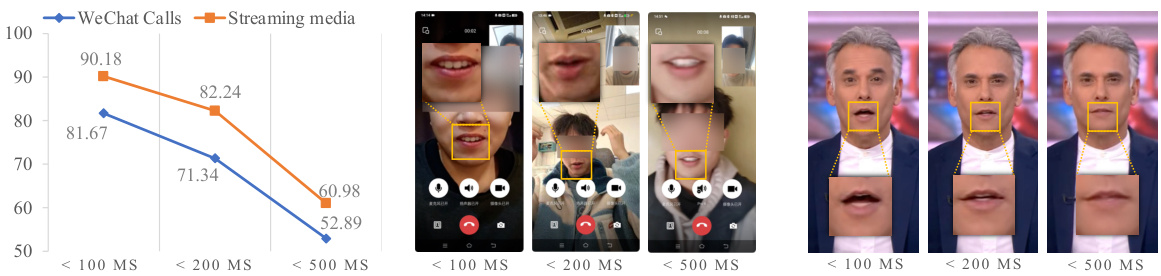
The figure shows the performance of the proposed LipFD method in real-world scenarios, specifically WeChat video calls and streaming media, under varying network delays (100ms, 200ms, and 500ms). The results are presented as accuracy percentages. The visualization demonstrates that the accuracy of the model in detecting LipSync decreases as network delay increases, especially in WeChat video calls. This is because increased latency leads to desynchronization between audio and video, which the model relies on for detection. The performance on streaming media is less affected by the delay.

This figure visualizes the gradients from the last layer of the Global-Region encoder in LipFD, a deepfake detection model. The gradients highlight the image regions that most strongly influence the model’s prediction. The left column shows real videos, while the right column shows fake videos. The visualization shows that for real videos, the model focuses on a broader area including head, face and lip regions, indicating that it considers the overall consistency and coherence of these regions in the real video. However, for fake videos, the model’s attention is strongly focused on the lip region, highlighting the discrepancies between the real lip movements and those generated by the LipSync deepfake method. The differences in attention highlight the model’s ability to differentiate between authentic and synthetic lip movements based on audio-visual consistency.

This figure shows examples of expanded data samples from the AVLips dataset. Each sample is composed of a sequence of T frames from a video and its corresponding audio spectrogram. This visual representation is designed to capture the temporal relationship between the visual lip movements and the audio signal, which is crucial for detecting inconsistencies in lip-synced deepfakes. The figure displays samples from four different sources: FF++, DFDC, LRS3, and real-world videos, showcasing the diversity of the dataset.
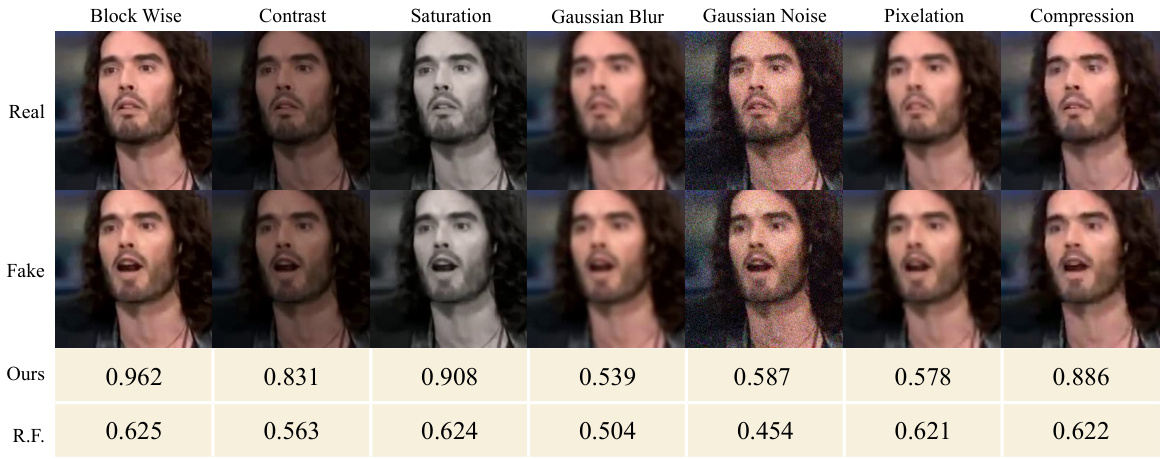
This figure shows the robustness of the proposed method (LipFD) and the RealForensics method against common image corruptions. Seven types of corruptions were applied to both real and fake videos at intensity level 3: Block Wise, Contrast, Saturation, Gaussian Blur, Gaussian Noise, Pixelation, and Compression. For each corruption type, sample images of real and fake videos are shown, followed by the AUC (Area Under the Curve) scores for both LipFD and RealForensics. The results demonstrate that LipFD maintains significantly higher AUC scores across all corruption types, indicating better robustness against various distortions.
More on tables
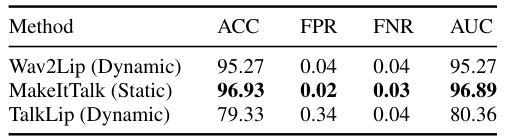
This table presents the results of evaluating the model’s performance on videos generated using unseen forgery algorithms. It demonstrates the generalizability of the model by testing its ability to detect lip-sync deepfakes created with methods not included in its training data. The metrics used are accuracy (ACC), average precision (AP), false positive rate (FPR), and false negative rate (FNR). The higher the accuracy and average precision scores, while keeping the false positive and negative rates low, the better the model’s performance at generalizing to unseen methods.
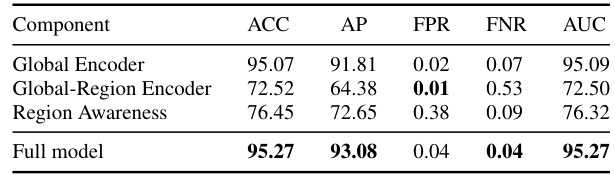
This table presents the ablation study results of the LipFD model. It shows the performance of the model when key components (Global Encoder, Global-Region Encoder, and Region Awareness) are removed one at a time. The results (ACC, AP, FPR, FNR, AUC) highlight the importance of each component in achieving high accuracy in lip-sync forgery detection.
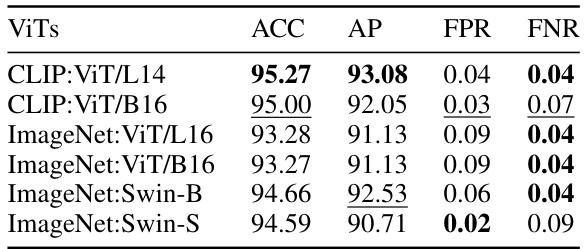
This table presents the performance comparison of different Vision Transformers (ViTs) used as the Global Feature Encoder in the LipFD model. It shows the Accuracy (ACC), Average Precision (AP), False Positive Rate (FPR), and False Negative Rate (FNR) achieved by the model using six different ViT architectures. These architectures are variations of CLIP and ImageNet pre-trained ViTs and Swin Transformers, with different sizes (L14, B16, L16, B16). The results highlight the impact of the choice of ViT on the model’s overall performance in LipSync forgery detection.
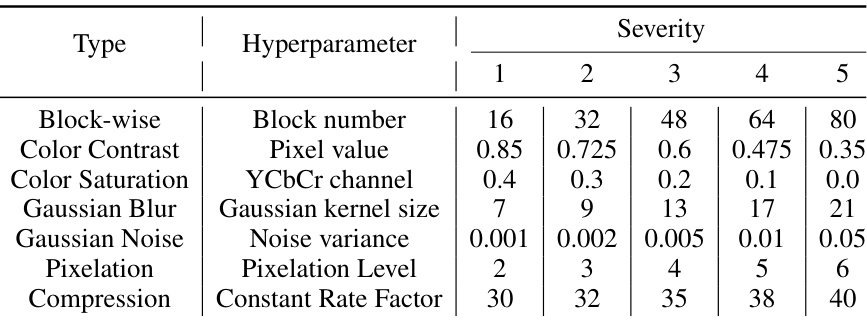
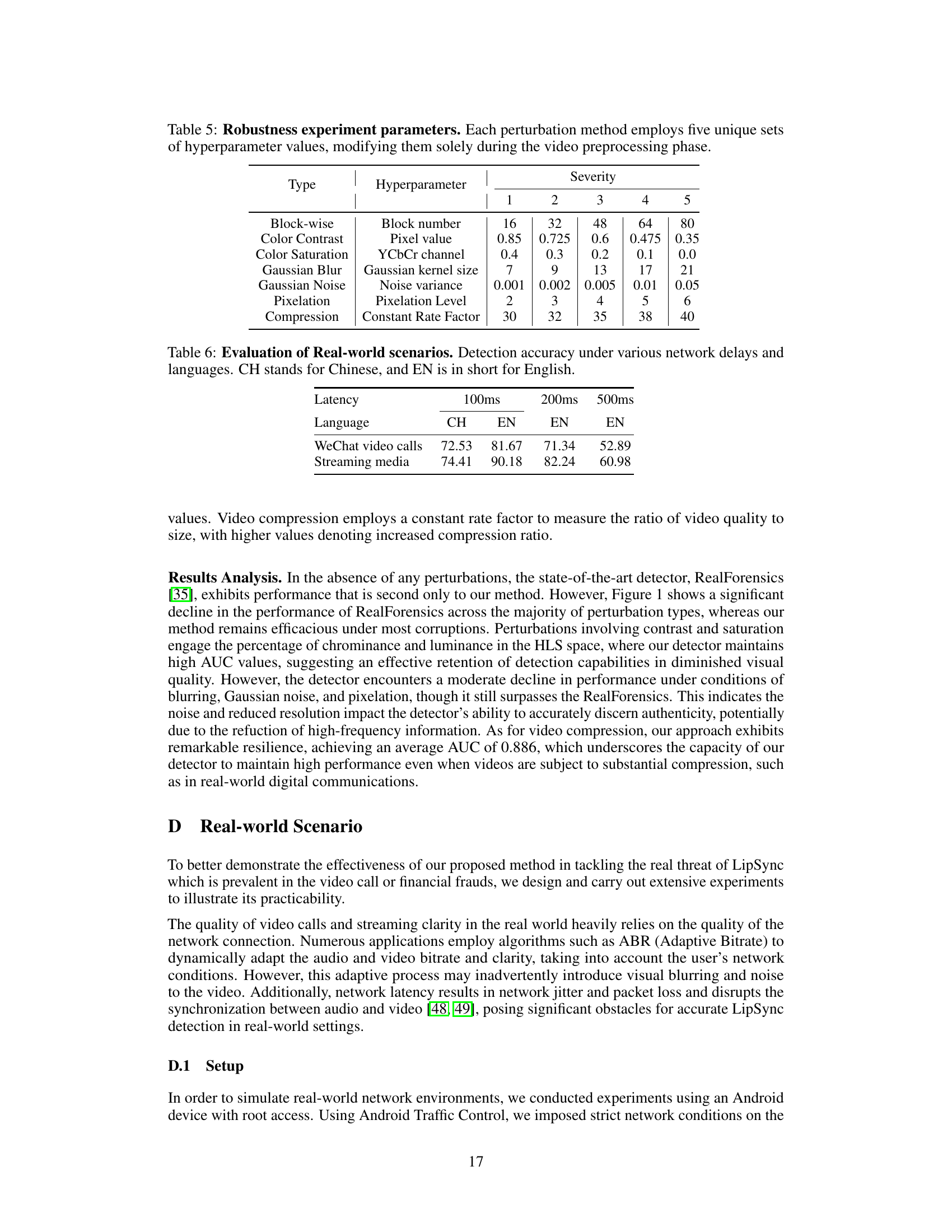
This table details the hyperparameters used in the robustness experiments. Each type of perturbation (Block-wise, Color Contrast, Color Saturation, Gaussian Blur, Gaussian Noise, Pixelation, Compression) has five different ‘severity’ levels, each with a corresponding hyperparameter value. This allows for a systematic evaluation of the model’s resilience to various degrees of image corruption.
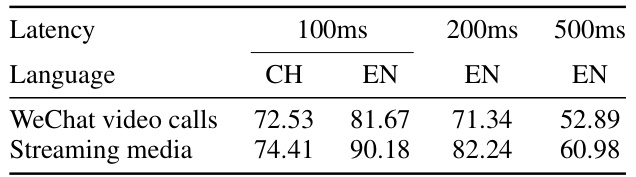
This table shows the performance of the proposed LipFD model in real-world scenarios with different network delays (100ms, 200ms, and 500ms) and languages (Chinese and English). The accuracy is measured for two types of scenarios: WeChat video calls and streaming media. The results demonstrate the robustness and real-world applicability of the proposed model, showing how the model performs in less-than-ideal network conditions.
Full paper#