↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Text-to-image (T2I) models, while impressive, often suffer from information loss and bias, particularly when generating multiple objects. This is because of the causal manner of text encoding, where the meaning of a word is influenced by previously processed words in the sentence, which leads to uneven representation of objects in the prompt. The generated image might favor the first-mentioned object, leaving others incomplete or missing entirely.
This paper delves into this problem by analyzing the causal effects of text encoding on image generation. The authors propose a new training-free optimization technique called Text Embedding Balance Optimization (TEBOpt). TEBOpt modifies text embeddings to reduce bias and promote more balanced representation. They also present a novel evaluation metric to better measure the presence and accuracy of generated objects. The results of using TEBOpt in various models demonstrate significant improvements in resolving the issue of incomplete or mixed objects, showcasing its effectiveness in enhancing the quality of generated images.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-image synthesis as it reveals and addresses critical information loss and bias issues within current models. It introduces a novel optimization technique and evaluation metric, paving the way for improved text-to-image generation quality and more reliable assessment methods. The findings could spur further research in mitigating information biases in other generative models and enhancing their semantic understanding.
Visual Insights#

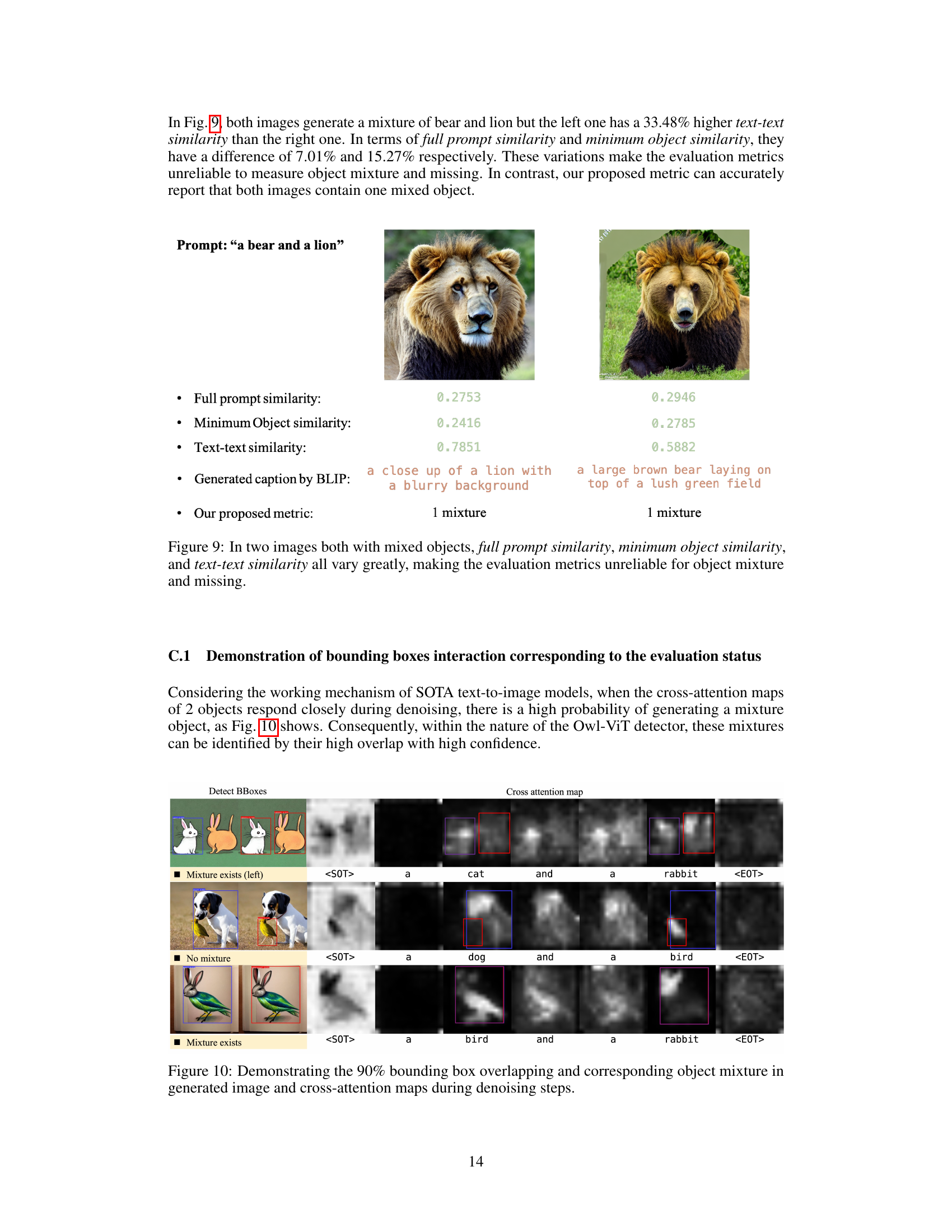
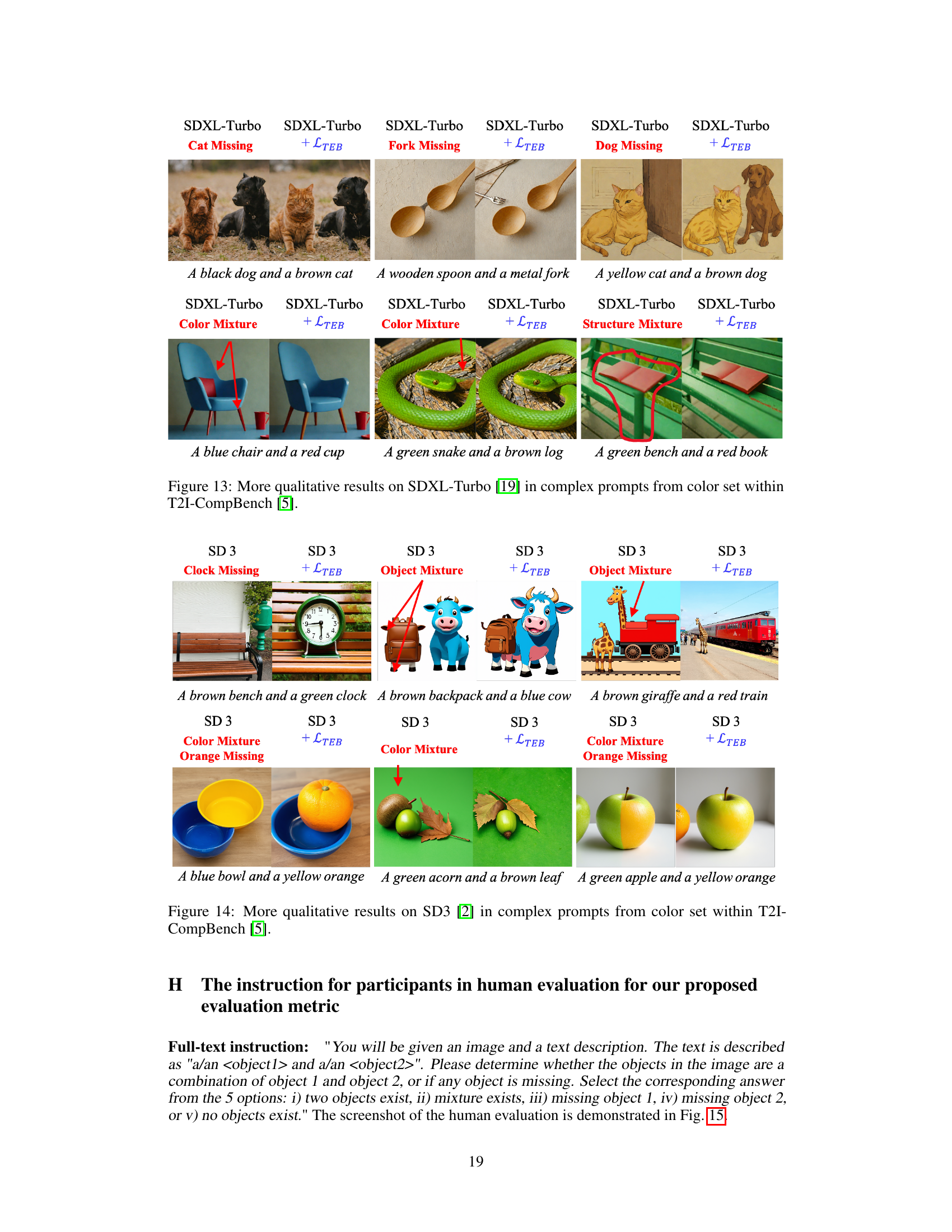
This figure shows examples of image generation outputs from a text-to-image model when presented with prompts containing multiple objects. The top row displays cross-attention maps which visualize the model’s attention to different parts of the image during generation. The bottom row shows the actual generated images. The images illustrate two main issues: 1. Object Mixture: The model blends features of different objects, creating a hybrid that doesn’t accurately represent any of the objects in the prompt. For example, in the image with a lion and elephant prompt, a creature is generated that is part lion and part elephant. 2. Object Missing: The model fails to generate one of the requested objects completely. For example, in the prompt with a chicken and a dog, the dog is missing from the generated image. These issues highlight the challenges in accurately representing multiple objects during image generation when the model has to resolve the order in which they are named (a causal manner).
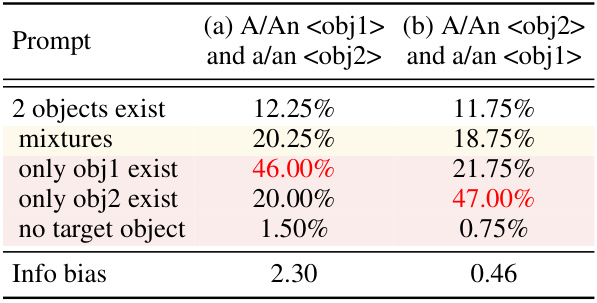
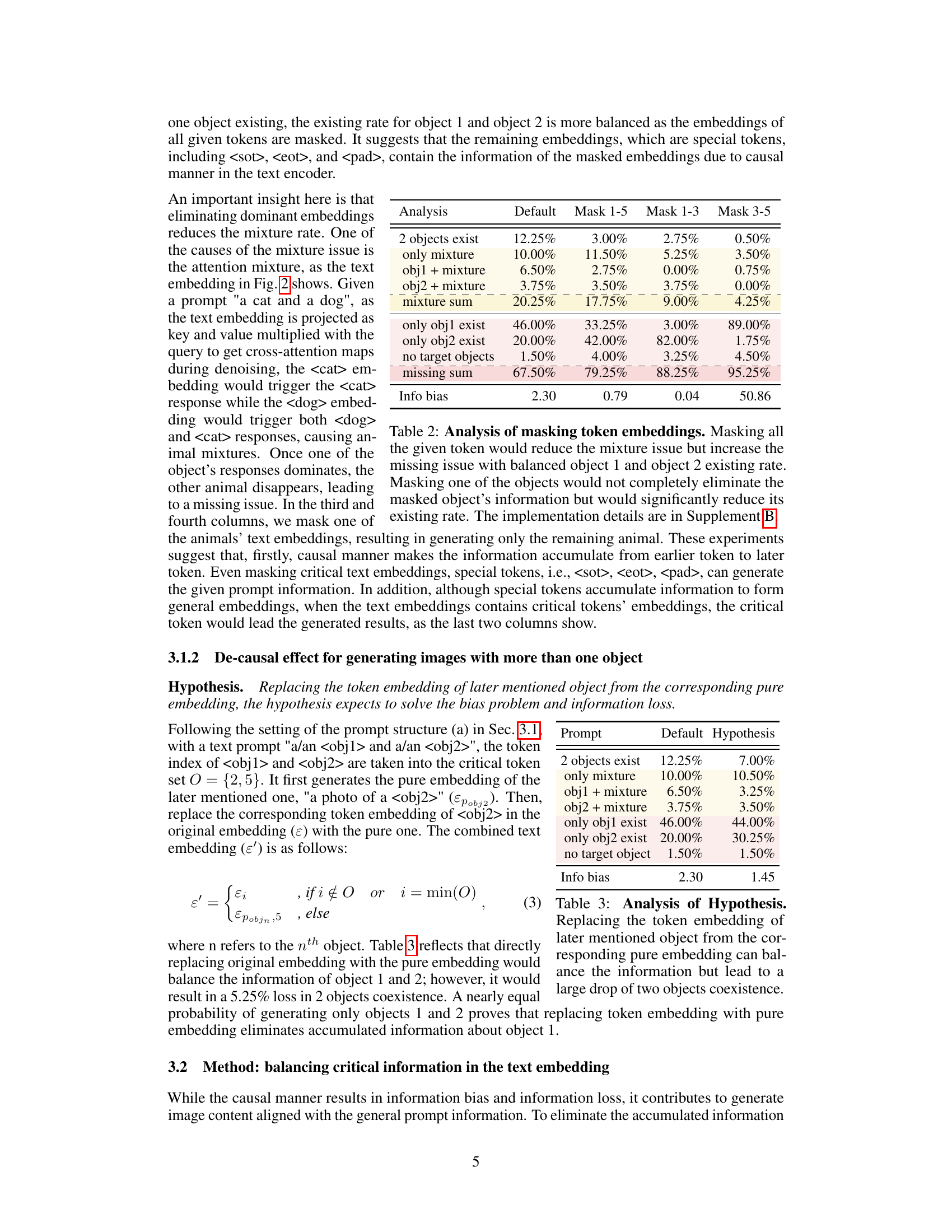
This table presents the results of an experiment investigating information bias in text-to-image models. Two sets of prompts were used, each containing two objects. The only difference between the sets is the order in which the objects were mentioned. The table shows the percentage of times that only the first object was generated, only the second object was generated, both objects were generated correctly, both objects were mixed, or neither object was generated. The ‘Info bias’ column quantifies the bias towards the first-mentioned object. A higher Info bias indicates a greater preference for the first-mentioned object.
In-depth insights#
Causal Text Effects#
The concept of “Causal Text Effects” in the context of text-to-image models centers on how the order of words in a text prompt influences the generated image. A sequential processing approach, inherent in many text encoders, leads to a bias towards objects mentioned earlier. This is because later words’ embeddings are influenced by prior words in a manner that can dilute the representation of later objects. Information loss can result, with only the initially mentioned object or a blend of features being prominently represented. This phenomenon highlights the non-commutative nature of language in image generation, where altering word order can significantly impact the resulting image. Addressing this requires methods that either mitigate the sequential bias or utilize alternative encoder architectures to more holistically process textual information. Strategies like embedding optimization can help balance the influence of each object in the prompt, producing more balanced and accurate image generations, thereby minimizing causal biases and improving overall output quality. Evaluation metrics also play a crucial role, needing to account for information loss beyond simple text-image similarity scores to accurately reflect the impact of these causal effects.
TEBOpt Method#
The TEBOpt method tackles information bias and loss in text-to-image models by directly addressing the causal nature of text encoding. It introduces a training-free optimization technique that focuses on balancing the embeddings of multiple objects within a prompt. This prevents the dominance of earlier-mentioned objects and promotes a more even distribution of attention, leading to improved generation quality and object representation. The method leverages a novel loss function to achieve this balance, encouraging the model to produce distinct embeddings for equally important objects, thereby mitigating the issues of object mixing and missing. TEBOpt’s training-free nature makes it readily applicable to various pre-trained models without requiring additional training data, making it a practical solution. By focusing on text embedding, TEBOpt addresses a fundamental cause of image generation issues, providing a foundation for improved image control and improved semantic understanding.
New Eval Metric#
The paper introduces a novel evaluation metric to address shortcomings of existing methods in assessing the quality of text-to-image generation, specifically concerning issues like object mixture and missing objects. Existing metrics, such as CLIP score, primarily focus on overall image-text similarity, failing to directly quantify the presence and accuracy of individual objects. The new metric directly addresses this limitation by providing a concrete numerical score that reflects whether specific objects are correctly generated, mixed, or missing. This approach offers a more nuanced and accurate evaluation of model performance, particularly in complex scenarios with multiple objects, where simple similarity scores can be misleading. The automated metric also shows high concordance with human evaluations, strengthening its validity and reliability. The development of this metric is a significant contribution, enhancing the field’s ability to objectively measure and improve the performance of text-to-image models. Its ability to distinguish between different types of errors (mixture vs. missing) allows for more targeted model improvement efforts, making it a valuable tool for future research.
Multi-Object Bias#
The concept of “Multi-Object Bias” in text-to-image models refers to the phenomenon where the model’s output disproportionately favors the first-mentioned object in a multi-object prompt. This bias stems from the causal nature of the text encoder’s self-attention mechanism, which processes the textual input sequentially. Earlier objects receive more attention and influence, resulting in a stronger representation in the generated image, often at the expense of subsequent objects. This isn’t simply an issue of object prominence; it can lead to information loss where latter objects may be missing, poorly rendered, or merged with earlier objects. Addressing this bias requires techniques that either balance the attention weights across all objects or modify the embedding representations to ensure distinct features for each object. Understanding and mitigating multi-object bias is crucial for generating faithful and balanced representations of complex scenes, enhancing the overall image quality and realism.
Future Work#
Future research could explore several promising avenues. Extending the TEBOpt framework to handle prompts with more than two objects is crucial. The current method focuses on balancing two objects; a more robust method capable of managing multiple objects simultaneously would significantly enhance its applicability. Investigating the interaction between TEBOpt and different denoising strategies is also important. The current work primarily uses Stable Diffusion; understanding how TEBOpt performs with alternative diffusion models or different denoising schedules would provide a more holistic understanding of its effectiveness. A deeper analysis into the impact of various text embedding models is necessary. The current research relies on CLIP; exploring the effects of alternative text embeddings could highlight the generalizability of TEBOpt and its potential limitations. Finally, developing more sophisticated evaluation metrics is crucial. While the paper introduces an automated metric, further refinement could lead to more accurate and comprehensive assessment of image generation quality, including a better way to quantify information bias and loss in complex scenarios.
More visual insights#
More on figures
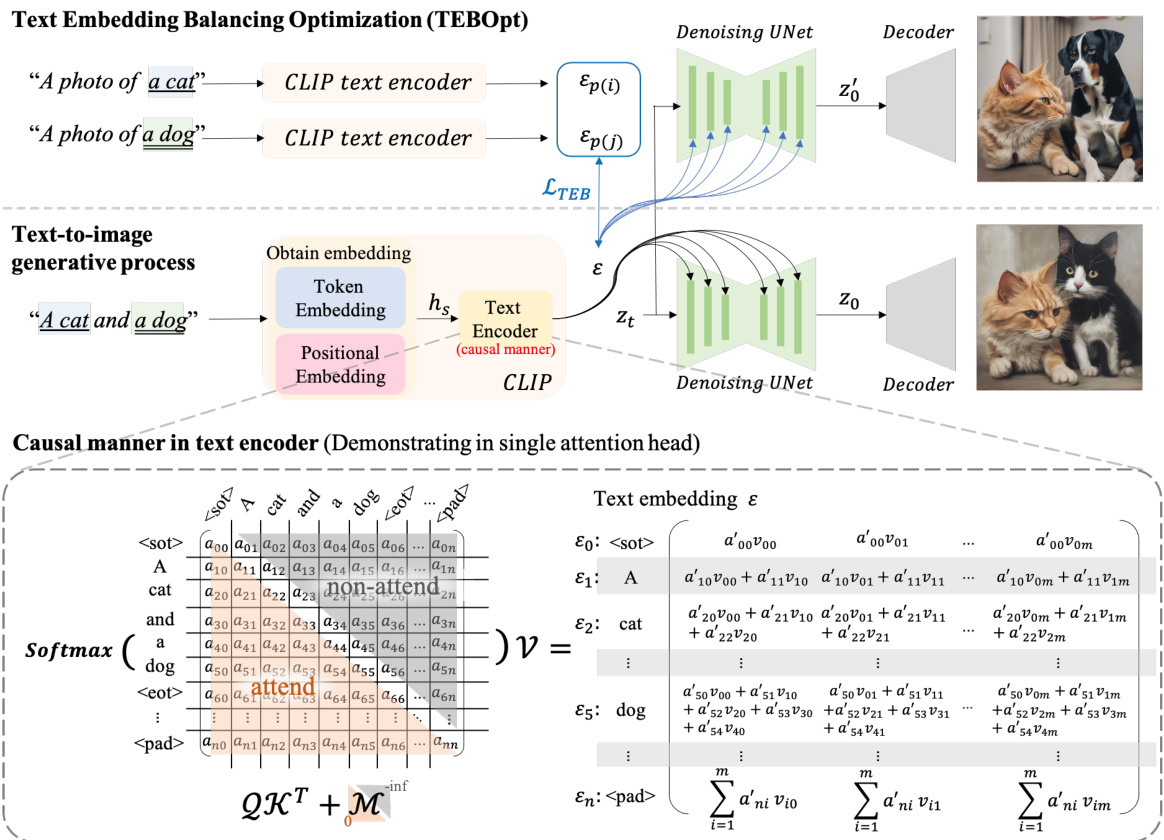
This figure illustrates the architecture of a text-to-image diffusion model and highlights the causal manner in the text encoder’s self-attention mechanism. The causal nature leads to information accumulation from the initial token to subsequent tokens, resulting in bias towards earlier tokens. The figure shows how the input text is processed through a CLIP text encoder to generate text embeddings. These embeddings are then fed into a denoising UNet along with initial image noise to iteratively refine the generated image. A key part of the figure visualizes the causal self-attention mechanism showing how each token’s embedding is influenced by the previous tokens. The figure also introduces the proposed ‘Text Embedding Balance Optimization (TEBOpt)’ as a method to mitigate this information bias by adjusting text embeddings for more balanced representation.

This figure shows the results of an experiment where different parts of the text embedding were masked to see how it affected the generated image. The top row shows prompts where ‘dog’ comes before ‘cat’, and the bottom row shows the opposite. The first four columns show the full embedding, illustrating the bias towards the first-mentioned animal (a cat-dog mixture). The final two columns show the effect of masking either the cat or dog tokens, illustrating that the remaining token (and special tokens) strongly influences the generated image. This demonstrates the impact of causal masking in the text encoder.

This figure shows a qualitative comparison of different text-to-image generation methods, including Stable Diffusion, Structure Diffusion, A&E, and SynGen, both with and without the proposed Text Embedding Balance Optimization (TEBOpt). Each row represents a different prompt, and each column shows the results of a different method. The prompts include pairs of objects, and the images generated show the effect of each method on the presence and mixture of those objects in the generated images. The overall visual comparison demonstrates the effectiveness of TEBOpt in reducing issues such as object mixtures and missing objects.

This figure shows two subfigures. Subfigure (a) is a heatmap showing the cosine similarity between different text embeddings (animal names). Warmer colors indicate higher similarity. Subfigure (b) is a bar chart showing the Kullback-Leibler (KL) distance between the cross-attention maps generated by pairs of words. The x-axis represents pairs of words, and the y-axis represents the KL distance. The words are ordered on the x-axis according to the cosine similarity of their embeddings shown in subfigure (a). This figure demonstrates that similar text embeddings lead to similar cross-attention maps, resulting in object mixture in the generated image.

This figure shows examples of how the text embedding affects the generated images. The first image shows an ambiguous creature that blends features of both a lion and an elephant (object mixture). The second image shows an image where one of the objects is missing (object missing).

This figure visually demonstrates the output of cross-attention maps in a text-to-image model when generating images with multiple objects. The top row shows the prompt ‘a lion and an elephant’, resulting in an ambiguous creature that blends features of both. The bottom row shows the prompt ‘a chicken and a dog’, resulting in one object missing. This illustrates the problems of information bias and loss due to the causal nature of the self-attention mechanism in text encoders.

The figure visualizes the cross-attention maps generated by a text-to-image diffusion model when presented with prompts containing multiple objects. The top row shows the intended prompt ‘a lion and an elephant.’ The model produces a cross-attention map exhibiting a mixture of both objects. The bottom row shows a prompt for ‘a chicken and a dog.’ The resulting image has an object missing. This illustrates the challenges of information loss and bias in text-to-image models that the paper seeks to address.
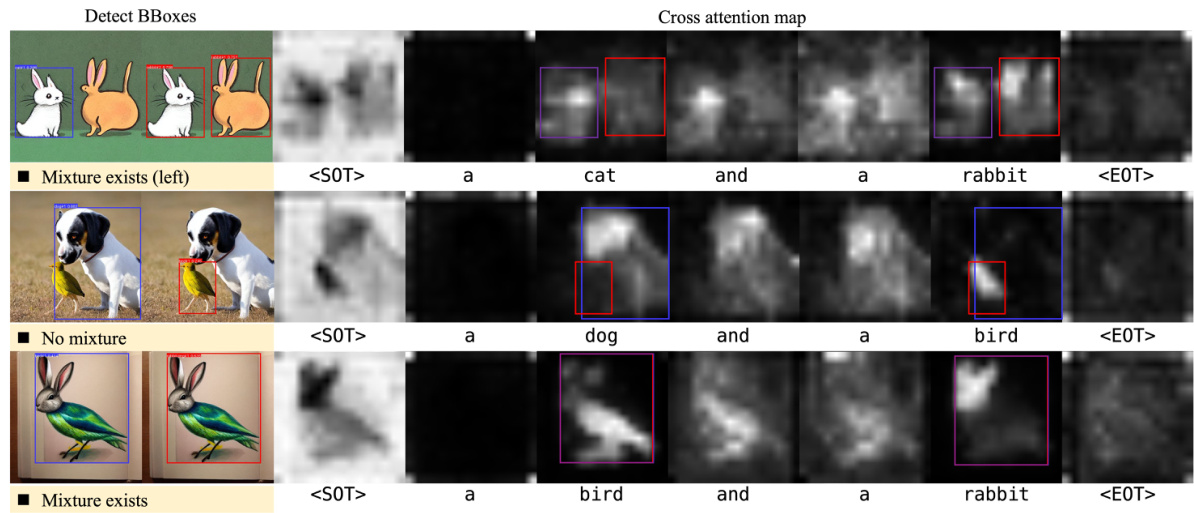
This figure visualizes the cross-attention maps generated by a text-to-image model when the prompt contains multiple objects. The first row shows a prompt with ‘a lion and an elephant’, resulting in an image where the generated creature blends features of both. The second row shows a prompt with ‘a chicken and a dog’, resulting in an image where one of the objects is missing entirely. The figure highlights the issues of semantic interpretation and token embedding that lead to information mix-ups in text-to-image models.

This figure visualizes the cross-attention maps generated by a text-to-image diffusion model when prompted with two objects. The top row shows examples where the model generates a mixture of the two objects (e.g., a creature that blends features of a lion and an elephant). The bottom row shows examples of object missing, where only one of the requested objects is present in the generated image.

This figure illustrates the architecture of a text-to-image generative model, focusing on the text encoder’s causal manner and its impact on information accumulation and bias. The causal manner, visualized in the lower part of the figure, shows that information from earlier tokens is propagated to subsequent tokens during self-attention calculations within the text encoder. This results in the first mentioned object having a stronger influence on the generated image. To address this issue, the authors propose a text embedding optimization technique to balance the information contribution of different tokens.

This figure illustrates the text-to-image generation process, highlighting the causal manner in the text encoder’s self-attention mechanism. The causal nature of the embedding leads to information accumulation, biasing the model toward the first-mentioned object. The figure also introduces the proposed text embedding optimization (TEBOpt) method to address this bias by balancing the information from different tokens and equalizing the weights of their corresponding embeddings.

This figure visually demonstrates the impact of the causal manner in text encoders on the generated images in text-to-image diffusion models. It shows examples of ‘object mixture’ (a single entity blending features from multiple objects described in the text prompt) and ‘object missing’ (objects mentioned in the prompt failing to appear in the generated image). In the object mixture examples, the generated image is a blend of features from both a lion and an elephant, or a chicken and a dog. In the object missing examples, only one of the mentioned objects appears (a lion, or a chicken) while the other is absent.

This figure visualizes the cross-attention maps generated by a text-to-image model for two different prompts: ‘a lion and an elephant’ and ‘a chicken and a dog’. It demonstrates two common issues in text-to-image generation. In the case of ‘a lion and an elephant’, an ambiguous creature blending features of both is generated (object mixture). In the case of ‘a chicken and a dog’, one of the animals is missing entirely from the generated image (object missing). The visualizations highlight how the model’s attention mechanisms fail to accurately represent the objects specified in the prompt, leading to these problems.
More on tables

This table presents the results of an experiment where different tokens in the text embedding were masked to analyze their contribution to the generation of images in a text-to-image model. The table shows the impact of masking on different aspects of image generation: the number of images containing two objects, only a mixture of objects, a single object with a mixture, and images with no target objects (objects missing). The impact on information bias, a measure of the imbalance between the generation of two objects in the prompt, is also reported. The results indicate that removing important tokens, like those representing the objects themselves, increases the missing rate and changes the generation balance, while special tokens preserve some information, even when other tokens are masked.
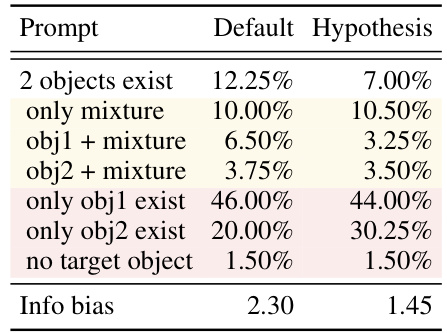
This table presents a comparison of the results obtained using the default Stable Diffusion model and the proposed hypothesis. The hypothesis involves replacing the token embedding of the second-mentioned object in a two-object prompt with the pure embedding of that object. The table shows the percentage of images with two objects, only one object (specifically object 1 and object 2), a mixture of objects, and no objects present. The results highlight the trade-off between improving information balance and reducing the instances of two objects coexisting.

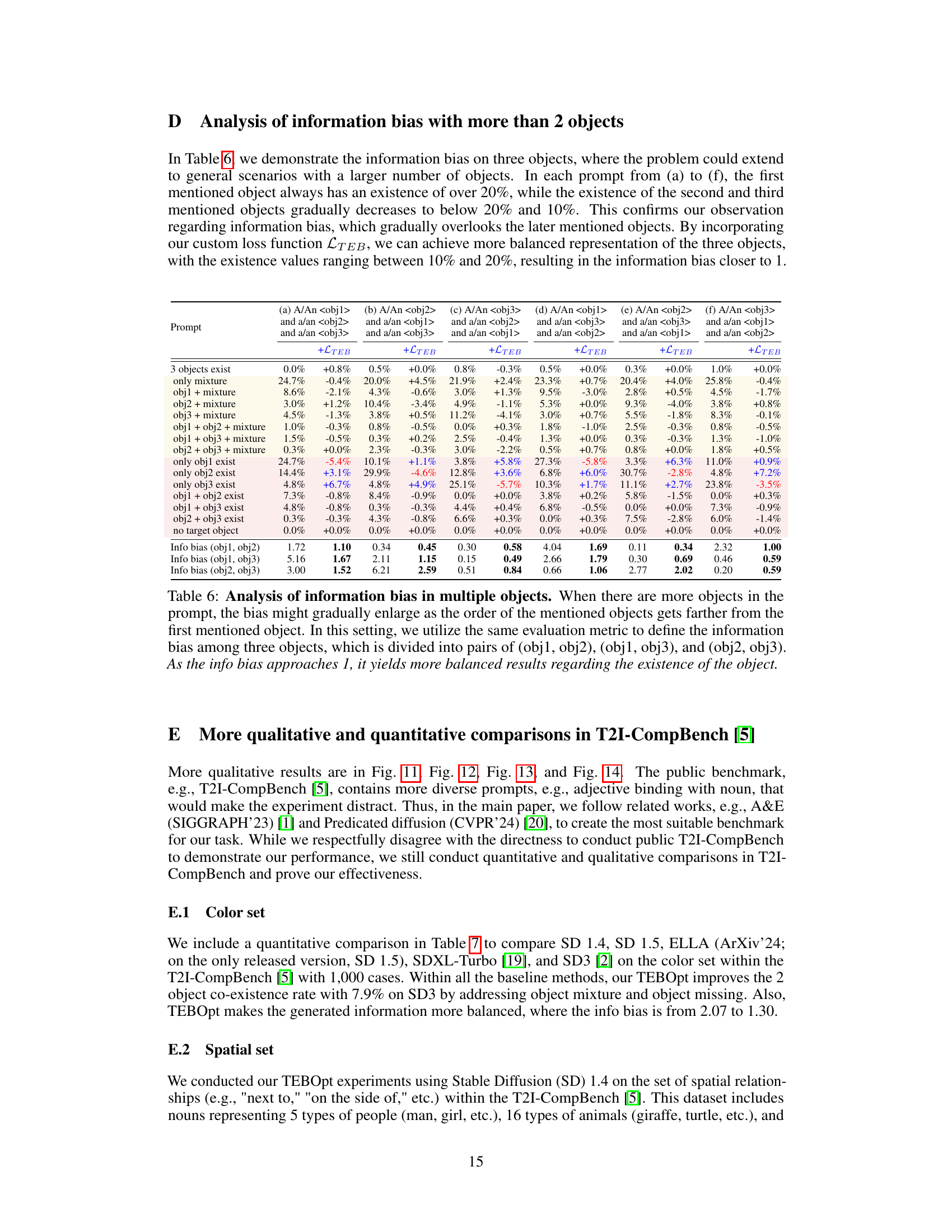
This table presents the results of an experiment investigating information bias in text-to-image models. Two prompts were used: one mentioning object1 before object2, and another mentioning object2 before object1. The table shows that regardless of the order, there is a strong bias towards the first-mentioned object in the generated images. The bias towards the first-mentioned object is quantified numerically. More detail on the bias for prompts with more than two objects is available in Supplement D.
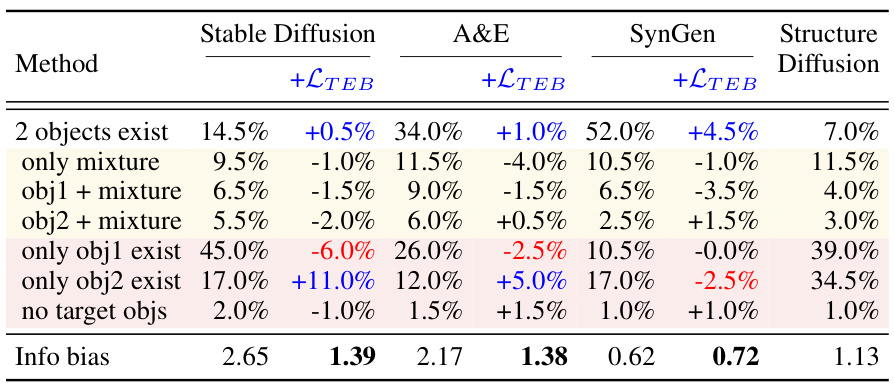
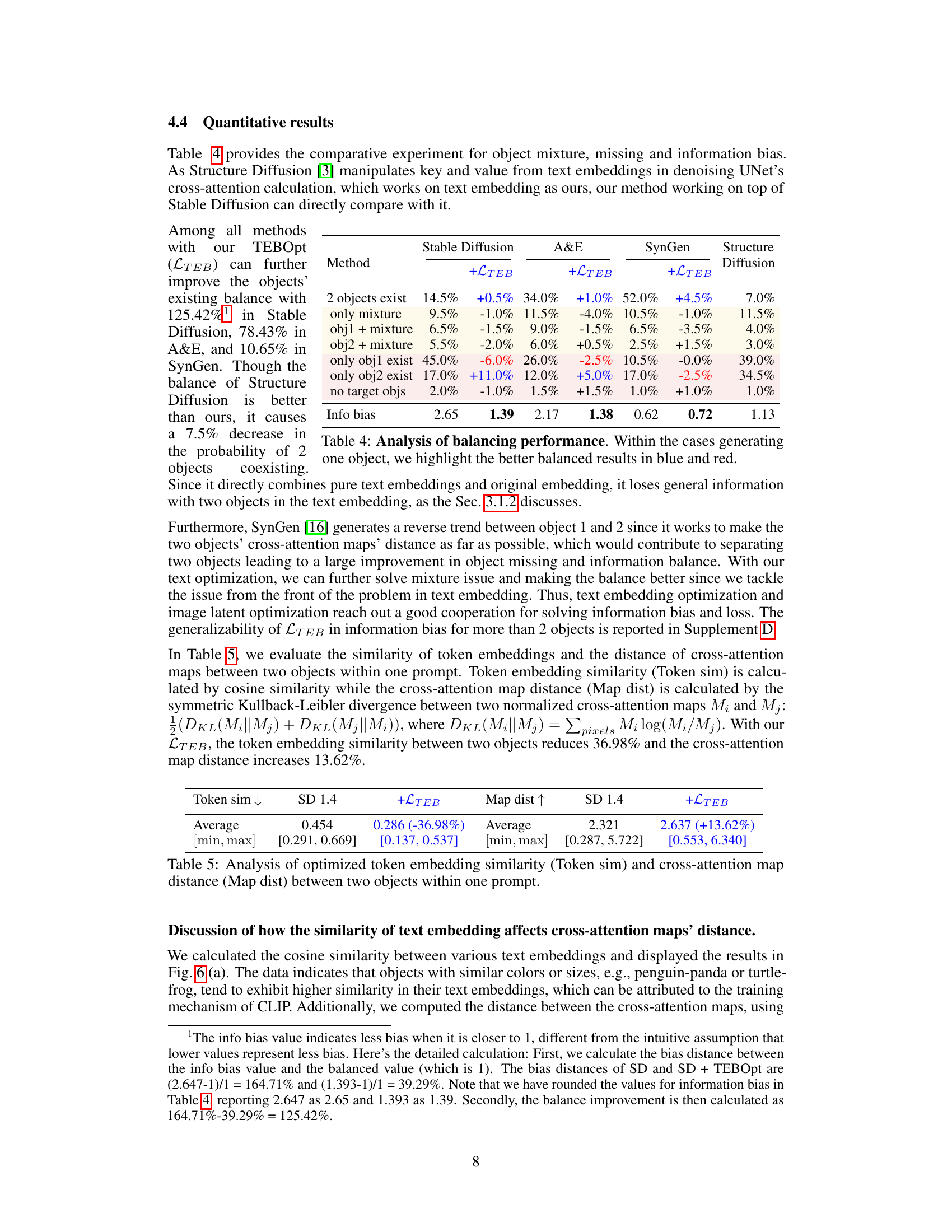
This table presents a quantitative comparison of different methods’ performance in terms of object mixture, missing objects, and information bias. The methods compared include Stable Diffusion, A&E, SynGen, and Structure Diffusion, both with and without the proposed Text Embedding Balance Optimization (TEBOpt). The metrics used are the percentage of images with two objects, only a mixture of objects, only one of the objects, and neither object. The information bias score quantifies the balance of information between the objects mentioned in the prompt. The table highlights the improved balance achieved by TEBOpt across different methods, especially in the cases where only one object is generated.

This table presents a quantitative comparison of different methods for addressing object mixture, missing objects, and information bias. The methods compared include Stable Diffusion with and without the proposed Text Embedding Balance Optimization (TEBOpt), Attend-and-Excite (A&E) with and without TEBOpt, SynGen with and without TEBOpt, and Structure Diffusion. The table shows the percentage of images with two objects, only mixture, object1 + mixture, object2 + mixture, only object1, only object2, no target objects, and the information bias. The information bias is a metric indicating the balance between the existence of the two objects. Improvements achieved by using the TEBOpt are highlighted.
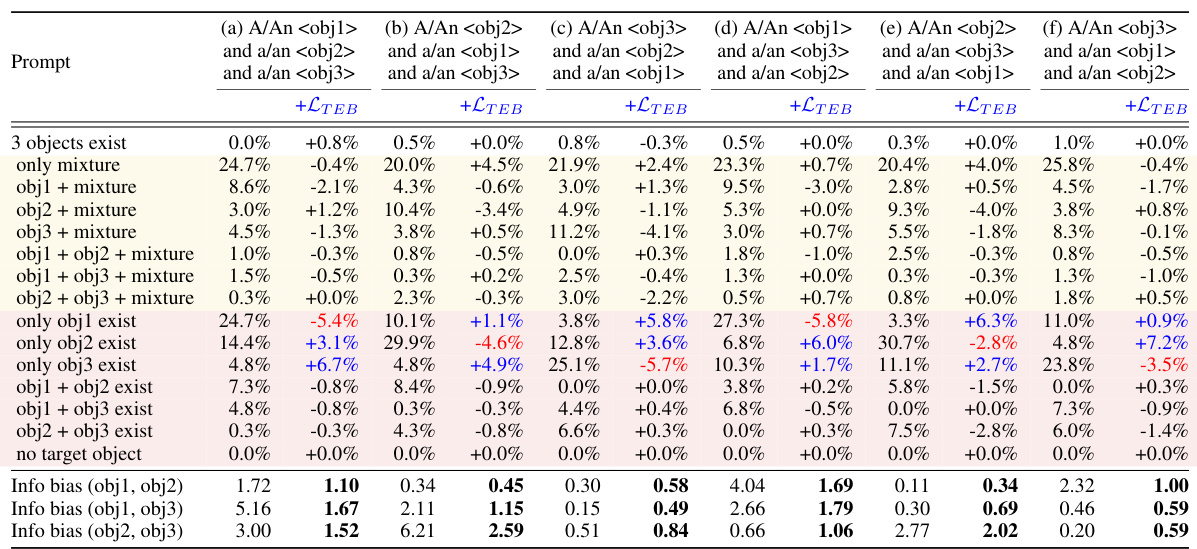
This table presents a quantitative analysis of information bias when prompts include more than two objects. It shows that the existence probability of the first-mentioned object is always higher than those of later-mentioned objects, confirming the information bias. The table compares the performance with and without the proposed Text Embedding Balance Optimization (TEBOpt). TEBOpt significantly improves the balance of object existence probabilities, bringing them closer to equal representation.

This table presents a quantitative comparison of different methods for addressing issues related to object mixture, missing objects, and information bias in text-to-image generation models. It shows the percentage of images with two objects, only mixture, only one object of each type (obj1, obj2), only one object of specific type (obj1 or obj2), images with no target objects. The ‘Info bias’ metric quantifies the balance in representing objects, with lower values indicating a better balance. The results show the effects of adding the proposed method (LTEB) on top of different baselines (Stable Diffusion, A&E, SynGen, and Structure Diffusion). The improvement in balance after adding the LTEB is highlighted in the table.

This table presents a quantitative comparison of the results obtained using Stable Diffusion 1.4 with and without the proposed Text Embedding Balance Optimization (TEBOpt) method on the spatial set of the T2I-CompBench benchmark. It shows the percentage of images falling into different categories: images with two objects, images with only a mixture of objects, images where only one of the two target objects is present, and images with neither of the target objects. The ‘Info bias’ metric reflects the balance between the presence of the two objects. The positive values in the ‘+LTEB’ column show improvement achieved by the TEBOpt method in specific categories.
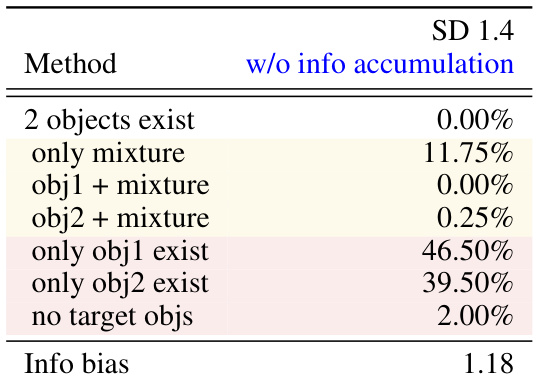
This table presents the results of an experiment where different combinations of tokens from the text embedding were masked to analyze their contribution to the generation of images. The first column shows the results for the default case, while the other columns show the results of masking specific tokens. The table shows the percentage of images with two objects, only one object, and no object, as well as the information bias towards the first-mentioned object. The results reveal the interplay between different tokens and how their absence affects the overall information balance in generating images.
Full paper#