↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for image-to-text (I2T) and text-to-image (T2I) generation struggle with spatial understanding, particularly in modeling 3D spatial relationships. This limitation leads to inaccuracies in spatial feature extraction and synthesis. The paper addresses these shortcomings by proposing a novel dual learning strategy.
The proposed approach leverages a novel 3D scene graph (3DSG) representation to model 3D spatial relationships more accurately. This 3DSG is shared between the I2T and T2I tasks. Furthermore, it introduces a synergistic dual learning strategy, where the easier 3D-to-text or 3D-to-image process aids the harder processes, improving the overall performance. Experiments on the VSD dataset show that the proposed method outperforms state-of-the-art (SoTA) techniques for both I2T and T2I tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel dual learning framework that significantly improves the accuracy of both image-to-text and text-to-image generation tasks in the visual spatial understanding domain. The introduction of 3D scene graphs and the synergistic dual learning approach represent a major advancement in the field, opening exciting new research avenues. The findings are highly relevant to ongoing research efforts and demonstrate the substantial improvements achievable by connecting and complementing dual learning processes.
Visual Insights#
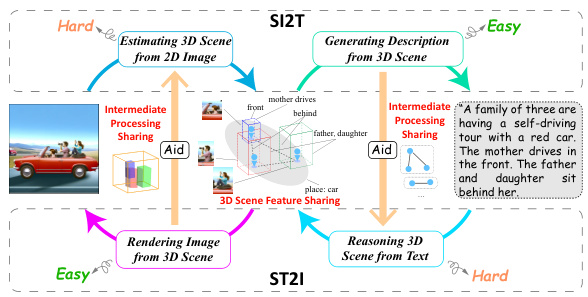
This figure illustrates the complementary nature of the SI2T and ST2I tasks. It shows that SI2T (spatial image-to-text) involves a relatively difficult 3D scene construction process from a 2D image, followed by an easier process of generating a textual description of that 3D scene. Conversely, ST2I (spatial text-to-image) has an easier process of constructing a 3D scene from the textual input, but faces the difficulty of generating the actual 2D image from the 3D scene. The figure highlights the concept of ‘intermediate processing sharing’ where the easier process of each task aids in the harder process of the other, and ‘3D scene feature sharing’ where the common 3D scene representation benefits both tasks. The example illustrates how a family scene would be processed, indicating the information flow between input (image/text), intermediate 3D scene representation, and output (text/image).

This table presents the quantitative results of the proposed Spatial Dual Discrete Diffusion (SD³) model and compares it with various baselines on the VSD dataset for both ST2I and SI2T tasks. Metrics such as FID, IS, CLIP, BLEU4, and SPICE are used to evaluate the performance. The table shows that SD³ outperforms the baselines, especially on VSDv2 which uses more meticulous descriptions.
In-depth insights#
Dual Learning Synergy#
Dual learning synergy, in the context of a research paper, likely explores the mutual benefits of training two related tasks together. This approach suggests that the strengths of one task can compensate for the weaknesses of the other, leading to improved performance for both. The core idea is that the two tasks share common underlying features or knowledge, which can be leveraged to enhance the learning process. For example, in image-to-text and text-to-image generation, the shared representation of spatial scenes allows each task to benefit from the other’s learning. The “synergy” arises from this shared knowledge, facilitating better spatial understanding and overall improvements in generation quality. A key focus would likely be on how the training processes are designed to optimize both tasks simultaneously, possibly by sharing intermediate representations or using a joint loss function. This could involve clever strategies for backpropagation and weight updates to ensure both tasks are learned efficiently and effectively.
3D Scene Graph#
The concept of a ‘3D Scene Graph’ represents a significant advancement in scene representation for visual spatial understanding. It moves beyond traditional 2D scene graphs by explicitly incorporating three-dimensional spatial relationships between objects, going beyond simple adjacency. This richer representation is crucial because 2D images inherently lack the depth information essential for accurate spatial reasoning. A 3D Scene Graph offers several key advantages: it allows for more precise modeling of spatial arrangements (e.g., occlusion, relative distances), enabling more accurate and detailed image-to-text and text-to-image generation. Integration of 3D spatial information fundamentally improves tasks such as visual question answering, 3D scene reconstruction, and robot navigation. However, constructing a reliable 3D Scene Graph presents challenges, especially with ambiguous or partially occluded objects in 2D images. The development of robust methods for inferring 3D Scene Graphs from 2D inputs and efficiently leveraging this representation remains an area of active research. Data requirements for training 3D Scene Graph models are also substantial, potentially necessitating large datasets of precisely annotated 3D scenes.
Discrete Diffusion#
Discrete diffusion models offer a compelling approach to generative modeling, particularly when dealing with discrete data. Unlike continuous diffusion, which operates in a continuous space, discrete diffusion directly models the probability distribution over discrete states. This makes it inherently suitable for tasks involving discrete data types, such as text or scene graphs, where continuous representations might lead to information loss or inaccuracies. The use of Markov chains in the forward and reverse diffusion processes provides a structured way to progressively introduce and remove noise, facilitating the learning of complex data distributions. The discrete nature also enables computational efficiency, especially when compared to continuous methods, as the operations are simpler and can often be parallelized more easily. However, the discrete setting might present limitations. Careful design of the transition probabilities (e.g., using learned transition matrices) and the handling of high-dimensional spaces are crucial for successful implementation. The discrete approach’s reliance on transition matrices can also pose challenges regarding scalability to high-dimensional data and modeling complex relationships between states.
Spatial Feature Align.#
The heading ‘Spatial Feature Alignment’ suggests a crucial step in a vision-language model designed for visual spatial understanding tasks, likely bridging the gap between visual and textual spatial representations. The core challenge addressed is the inherent difference in how spatial information is encoded in images versus text. Images provide rich, pixel-level detail, while text offers a more abstract, symbolic description. This necessitates a mechanism to align these disparate modalities’ spatial features, facilitating meaningful cross-modal interaction. The alignment method likely involves transforming visual features extracted from an image, such as object locations and relationships, into a common feature space that is compatible with corresponding textual embeddings. A successful alignment would enable the model to effectively correlate spatial concepts expressed in the text with their visual counterparts in the image, ultimately improving the accuracy of tasks such as spatial image captioning or spatial image generation. The approach may employ techniques from geometric deep learning or graph neural networks which are adept at modeling relational information. Careful attention to alignment strategies is key to ensuring the model accurately interprets spatial relationships, avoiding common errors resulting from misalignments that can lead to inaccurate descriptions or unrealistic image synthesis.
Future Work#
The ‘Future Work’ section of a research paper on synergistic dual spatial-aware generation of image-to-text and text-to-image would ideally explore several promising avenues. Extending the 3D scene graph representation to incorporate more complex spatial relationships and contextual information is crucial. This could involve integrating higher-order relations, handling occlusion and ambiguity, and incorporating temporal dynamics for video understanding. Improving the efficiency of the discrete diffusion model is also vital, potentially by exploring alternative diffusion architectures or more efficient training strategies. The current framework’s effectiveness relies heavily on the quality of 3DSG data; therefore, developing better methods for 3DSG generation and annotation is a major focus for future research. Finally, exploring the application of the dual learning framework to other cross-modal tasks beyond image-to-text and text-to-image could reveal further benefits. This might include tasks involving different modalities (e.g., audio, 3D point clouds), or those requiring more intricate spatial reasoning (e.g., robotic navigation).
More visual insights#
More on figures

This figure illustrates the complementary nature of the SI2T (Spatial Image-to-Text) and ST2I (Spatial Text-to-Image) tasks. It shows how the input and output of each task are reversed, highlighting their dual nature. It also visually represents the concept of ‘intermediate processing sharing,’ where easier sub-tasks within each main task (e.g., 3D scene generation from text in ST2I) can aid more difficult ones (e.g., 3D scene reasoning from an image in SI2T), and ‘3D scene feature sharing,’ emphasizing that both tasks fundamentally rely on constructing a 3D understanding of the scene.

This figure illustrates the Synergistic Dual Discrete Diffusion (SD³) framework proposed in the paper. It shows how the model handles both spatial image-to-text (SI2T) and spatial text-to-image (ST2I) tasks simultaneously. The framework consists of three main components: 1) a shared graph diffusion model to generate a 3D Scene Graph (3DSG) representation from either image or text input. This 3DSG is then used to guide 2) an image diffusion model for ST2I and 3) a text diffusion model for SI2T. Importantly, the easier 3D-to-image/text processes aid the more difficult image/text-to-3D processes, resulting in synergistic improvement in both tasks. The diagram clearly depicts the information flow and the different processes involved.

The figure illustrates the overall framework of the proposed Spatial Dual Discrete Diffusion (SD³), which consists of three separate discrete diffusion models: a shared 3DSG diffusion model, an ST2I diffusion model, and an SI2T diffusion model. The 3DSG diffusion model converts initial TSG (for ST2I) and VSG (for SI2T) to a 3DSG representation. The ST2I and SI2T models then generate images and texts, respectively, using the 3DSG as a condition. Intermediate features from the easy parts of the processes are used to guide the harder parts, facilitating mutual benefit between the two dual tasks.

This figure illustrates the overall framework of the proposed synergistic dual framework for spatial image-to-text (SI2T) and spatial text-to-image (ST2I) generation. It highlights the dual processes involved and the shared 3D scene graph (3DSG) that benefits both tasks. The framework uses three separate discrete diffusion models: one for 3DSG generation from visual or textual inputs, one for image generation from the 3DSG (ST2I), and one for text generation from the 3DSG (SI2T). The figure emphasizes the intermediate processing sharing and the 3D scene feature sharing that enhances the performance of each task.
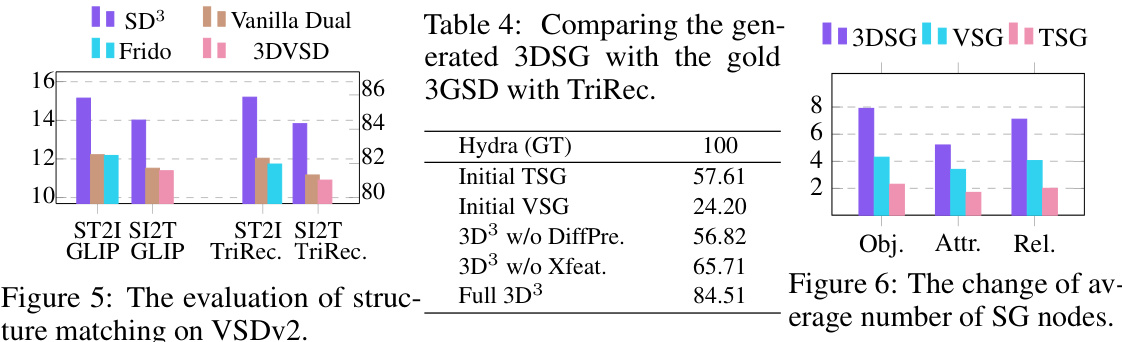
This figure illustrates the Synergistic Dual Spatial-aware Generation framework for both spatial image-to-text (SI2T) and spatial text-to-image (ST2I) tasks. It highlights the dual nature of the processes, showing how easier sub-tasks (3D→Text and 3D→Image) assist harder ones (Text→3D and Image→3D), and how a shared 3D Scene Graph (3DSG) representation benefits both tasks. Three main diffusion processes are shown: one for generating the 3DSG from input image or text, and separate ones for generating the image and text outputs respectively.

This figure illustrates the overall framework of the proposed Synergistic Dual Spatial-aware Generation of Image-to-Text and Text-to-Image model. It shows the three main components and their interactions: 1) a shared graph diffusion model for generating 3D scene graph (3DSG) representations from input images (VSG) or texts (TSG); 2) an image diffusion model for generating images from 3DSG (ST2I); and 3) a text diffusion model for generating text from 3DSG (SI2T). The figure highlights the dual learning process, where the intermediate features from the easier 3D→X (Image or Text) process are used to guide the harder X→3D process, thereby improving the performance of both tasks. This synergistic approach emphasizes the sharing of 3D scene features and intermediate processing results between the SI2T and ST2I tasks.

This figure shows the impact of noisy 3DSG training data on the performance of the model. The x-axis represents the percentage of noise added to the gold standard 3DSG dataset. The y-axis shows the percentage of successful matches (Noisy/No Noise). Three lines represent the performance of SI2T, ST2I, and 3DSG generation tasks. As the noise rate increases, the performance of all three tasks degrades significantly, demonstrating the sensitivity of the model to the quality of the 3DSG training data.

This figure illustrates the synergistic dual framework for spatial image-to-text (SI2T) and spatial text-to-image (ST2I) generation. It shows three main components: 1) A shared graph diffusion model to generate a 3D scene graph (3DSG) from either an image or text input. The 3DSG serves as a common representation for both tasks; 2) A discrete diffusion model for ST2I, which uses the 3DSG to generate images; 3) A discrete diffusion model for SI2T, which leverages the 3DSG to generate text. The design incorporates intermediate processing sharing, allowing easier tasks (3D→Text and 3D→Image) to aid harder ones (Text→3D and Image→3D), improving the overall performance of both SI2T and ST2I.

This figure showcases qualitative results from different models on the VSDv2 dataset. For each row, it displays the ground truth image, the ground truth text caption, and then outputs from four different models: VQ-Diffusion, Frido, 3DVSD, and SD³. The outputs include both generated images (for text-to-image) and generated text captions (for image-to-text). The figure visually demonstrates the comparative performance of the different models in terms of accurately generating images from text descriptions and generating spatial descriptions from images. The focus is on the spatial relationships depicted. Note that SD³ is the authors’ proposed model.

This figure illustrates the overall framework of the proposed Spatial Dual Discrete Diffusion (SD³) model for synergistic dual spatial-aware generation of Image-to-Text (SI2T) and Text-to-Image (ST2I). It shows three main components: a shared graph diffusion model that generates a 3D Scene Graph (3DSG) from either an image or text input, an image diffusion model for generating images from the 3DSG (ST2I), and a text diffusion model for generating text from the 3DSG (SI2T). The model uses an intermediate processing sharing strategy, where the easier 3D→X processes (3D to image or text) guide the harder X→3D processes (image or text to 3D). The 3DSG is a key component that allows for shared information between the two tasks.

This figure shows additional examples of images generated by the proposed Spatial Dual Discrete Diffusion (SD³) model for the spatial text-to-image (ST2I) task. Each row presents a text prompt and several images generated by the model, illustrating the model’s ability to generate images that accurately reflect the spatial relationships described in the text.

This figure illustrates the Synergistic Dual Discrete Diffusion (SD³) framework, which uses three discrete diffusion models for image-to-text (SI2T) and text-to-image (ST2I) generation. It highlights the dual processes (X→3D and 3D→X) and shows how a shared graph diffusion model generates a 3D scene graph (3DSG) that benefits both SI2T and ST2I tasks. The intermediate features from the easier 3D→X processes help guide the harder X→3D processes.
More on tables

This table presents the quantitative results of the proposed SD³ model and compares it with various baseline models for both ST2I and SI2T tasks on the VSD dataset (versions 1 and 2). The results are evaluated using multiple metrics: FID, IS, CLIP, BLEU4, and SPICE, reflecting image quality, diversity, and textual quality. The bold numbers highlight the best-performing model for each metric, and underlined numbers denote the best-performing baseline. The experiment is conducted five times with different random seeds, and the average results are reported.
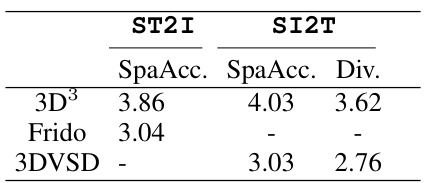
This table presents the quantitative results of the proposed SD³ model and compares it with several strong baselines on the VSD dataset. The results are shown for two versions of the dataset (VSDv1 and VSDv2) and for two main tasks (ST2I and SI2T). Evaluation metrics include FID, IS, CLIP, BLEU4, and SPICE, offering a comprehensive performance comparison across different aspects of image and text generation quality. The bold numbers indicate the best performance, while underlined numbers represent the best-performing baseline models. Results are averaged over five runs to account for variability.
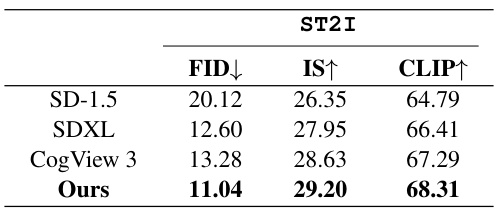
This table presents the quantitative results of the proposed SD³ model and compares it with various baselines on the VSD dataset for both ST2I and SI2T tasks. The metrics used include FID, IS, CLIP, BLEU4, and SPICE, reflecting both the image generation quality (ST2I) and text generation quality (SI2T). Lower FID is better, while higher values for IS, CLIP, BLEU4, and SPICE are preferred. The table shows that the SD³ model significantly outperforms the baselines across most metrics.

This table presents a comparison of the model’s performance using discrete diffusion and continuous diffusion. The metrics used are Triplet Recall (TriRec), Fréchet Inception Distance (FID), Inception Score (IS), CLIP score, BLEU4, and SPICE. It shows that the discrete diffusion model outperforms the continuous diffusion model across all metrics, suggesting that the discrete approach is more suitable for this task.

This table presents a comparison of the results obtained using two different SI2T (Spatial Image-to-Text) models within the SD³ (Spatial Dual Discrete Diffusion) framework. One model uses a diffusion-based approach, while the other uses a non-diffusion based vision-language model (OFA). The comparison focuses on the performance metrics for both ST2I (Spatial Text-to-Image) and SI2T tasks, including FID (Fréchet Inception Distance), IS (Inception Score), CLIP (Contrastive Language-Image Pre-training) score, BLEU4 (Bilingual Evaluation Understudy), and SPICE (Semantic Propositional Image Caption Evaluation). The results highlight the relative effectiveness of diffusion-based SI2T models within the SD³ framework.

This table presents the quantitative results of the proposed Synergistic Dual Spatial-aware Generation model on the VSD dataset. It compares the performance of the model against several baseline methods for both image-to-text (SI2T) and text-to-image (ST2I) tasks using metrics such as FID, IS, CLIP, BLEU4, and SPICE. The table is split into sections for VSDv1 and VSDv2 datasets, showing results for both ST2I and SI2T tasks. The best performing methods for each metric and dataset are bolded, and the best baseline results are underlined.
Full paper#