↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Score-based diffusion models (SDMs) are powerful generative models, but training them is computationally expensive due to the Jacobian trace calculation in score matching. Existing methods to circumvent this have drawbacks, like instability or approximations.
This paper introduces Local Curvature Smoothing with Stein’s Identity (LCSS), a novel score-matching method. LCSS uses Stein’s identity to bypass the Jacobian trace, enabling efficient computation and regularization. Experiments show LCSS outperforms existing methods in sample generation quality and training speed, even at high resolutions (1024x1024).
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces LCSS, a novel score matching method for training score-based diffusion models. LCSS offers significant advantages over existing methods by avoiding computationally expensive Jacobian trace calculations and achieving faster training with comparable or better sample quality. This opens exciting new avenues for research in high-resolution image generation and other applications of score-based models.
Visual Insights#

This figure displays samples generated by score-based diffusion models trained on the CelebA-HQ dataset at a high resolution (1024x1024). The images demonstrate the quality of image generation achieved using the proposed Local Curvature Smoothing with Stein’s Identity (LCSS) method. For comparison, the figure also includes images generated using two other state-of-the-art methods: DDPM++ with a subVP stochastic differential equation (SDE) and NCSN++ with a VE SDE. The rightmost images in each row represent DDPM++ samples, while the others represent NCSN++ samples.

This table compares the performance of DSM and LCSS on CIFAR-10 using four different diffusion models. FID (Fréchet Inception Distance), IS (Inception Score), and BPD (bits per dimension) are used to evaluate the quality of generated images. Lower FID and BPD scores and higher IS scores indicate better image quality.
In-depth insights#
Stein’s Identity Trick#
The core idea revolves around cleverly using Stein’s identity to sidestep the computationally expensive Jacobian trace calculation in score matching. Stein’s identity provides a way to express the expectation of the trace of the score function’s Jacobian as an expectation involving only the score function and a Gaussian perturbation of the data. This is a significant advantage because computing the Jacobian trace directly is prohibitive for high-dimensional data, as it is in many image generation tasks. The paper leverages this equivalence to formulate a novel score matching objective function. The ’trick’ is in its efficiency: replacing a computationally burdensome calculation with a more manageable expectation, all while retaining the regularizing properties of the original score matching loss. This allows the method, LCSS, to be efficiently applied to high-dimensional data and achieve state-of-the-art results in image generation.
LCSS vs. Existing#
The comparative analysis of LCSS against existing score matching methods (SSM, FD-SSM, and DSM) reveals significant advantages in terms of computational efficiency and sample quality. LCSS avoids the computationally expensive Jacobian trace calculation, a major drawback of traditional score matching, making it much faster. Unlike SSM and FD-SSM, LCSS avoids high variance issues stemming from random projections, leading to more stable and reliable training. Compared to DSM, LCSS produces higher-quality samples, particularly noticeable in high-resolution image generation, while maintaining comparable quantitative performance metrics like FID, IS, and BPD. The ability of LCSS to handle high-dimensional data effectively and the flexibility in SDE design, unlike DSM’s constraint to affine SDEs, are key strengths. Therefore, LCSS presents a compelling alternative to existing methods, offering a balance of efficiency and performance for score-based diffusion models.
High-Res Generation#
The section on “High-Res Generation” would explore the paper’s ability to produce high-resolution images. A key aspect would be evaluating the quality of these images, examining detail preservation, artifact reduction, and overall visual fidelity at resolutions exceeding those typically achieved by score-matching methods. The discussion would likely involve quantitative metrics (FID, Inception score, bits-per-dimension) and qualitative assessments to demonstrate the effectiveness of the proposed method (LCSS) in generating realistic high-resolution images. A crucial element is analyzing the computational cost and training time required for high-resolution image generation using LCSS, comparing this to other methods, and highlighting LCSS’s efficiency. Furthermore, it would address the method’s robustness to instability during the high-resolution training process. The results should demonstrate LCSS’s superiority in achieving high-resolution image generation that preserves realism and detail, surpassing existing score-matching techniques in terms of visual quality, efficiency, and stability.
SDE Flexibility#
The concept of “SDE Flexibility” in the context of score-based diffusion models centers on the ability to utilize stochastic differential equations (SDEs) beyond the typical affine constraints imposed by denoising score matching (DSM). Traditional DSM methods restrict SDEs to affine forms, limiting the expressiveness and potential of the models. This limitation stems from the requirement that the score function, a key component of the SDE, has a closed-form expression for efficient computation. Achieving SDE flexibility allows for the use of more complex and powerful SDEs, leading to improved sample generation quality and a wider design space for the generative models. This offers significant potential for generating higher-quality and more realistic samples, especially in high-dimensional datasets such as images. The ability to design SDEs without affine constraints empowers researchers to explore a richer class of diffusion processes, better aligning with the complexities of data distributions and resulting in more efficient training and better performance.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of the provided research paper, an ablation study on the proposed method (LCSS) would likely involve removing or altering specific parts of the algorithm, such as the local curvature smoothing term or Stein’s identity application, to assess their impact on the overall performance. By isolating the effects of each component, researchers can gain a deeper understanding of the model’s internal mechanisms and determine which parts are most crucial for its success. The results of this ablation study would ideally demonstrate the necessity of each component and provide insights into the design choices made. It also helps to validate the claims made about the model and potentially identify areas for future improvement. For example, it might show whether the local curvature smoothing improves model stability and convergence speed and whether Stein’s identity is essential for computational efficiency, thereby directly validating the core claims of the paper. Such validation strengthens the overall methodology and significance of the research.
More visual insights#
More on figures

This figure compares the image quality generated by SSM, FD-SSM, and LCSS at different training stages (5k and 90k steps) using NCSNv2 model trained on CIFAR-10 dataset. It visually demonstrates the difference in sample quality and convergence speed of the three score matching methods.

This figure compares the image generation quality of SSM, FD-SSM, and LCSS on the CelebA dataset at 64x64 resolution. The left panel shows samples generated after training for 10,000 steps, illustrating the relative speed of convergence for each method. The right panel shows samples generated after more extensive training (210,000 steps for FD-SSM and LCSS, 60,000 steps for SSM), highlighting the long-term stability and quality of images generated by LCSS compared to the other methods.

This figure compares the image generation quality of SSM, FD-SSM, DSM, and LCSS on the FFHQ dataset at 256x256 resolution. The models were trained for 600,000 steps with a batch size of 16. The results show that SSM and FD-SSM fail to generate realistic face images, while DSM and LCSS produce significantly better results. LCSS demonstrates superior image quality compared to DSM.

This figure compares the image generation quality of SSM, FD-SSM, DSM, and LCSS on the FFHQ dataset. The models were trained for 600,000 steps with a batch size of 16. The results show that LCSS generates significantly better quality images compared to SSM and FD-SSM which largely fail to produce realistic faces, and produces results comparable to DSM.

This figure shows the effect of different values of the balancing coefficient γ on image generation quality using LCSS. The images are generated from the FFHQ dataset (256x256 resolution) using the LCSS method with varying γ values and training iterations. The results show that a balanced value of γ is crucial to achieve high-quality generation. Values too low lead to noisy images that lack detailed features while high values result in images with enhanced contours but missing textures.
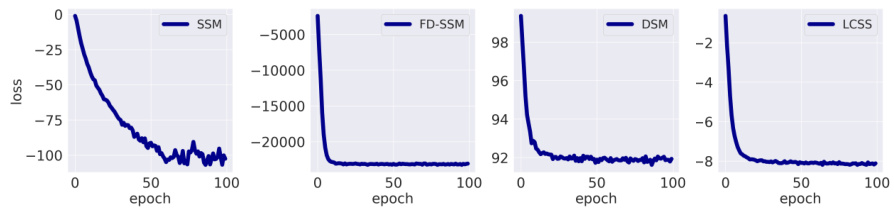
This figure shows the training loss curves for four different score matching methods: SSM, FD-SSM, DSM, and LCSS. The x-axis represents the training epoch, and the y-axis represents the loss. The plot visually compares the convergence speed and stability of each method during training on the Checkerboard dataset. The LCSS method demonstrates faster convergence and a more stable loss curve compared to SSM and FD-SSM, while exhibiting a similar performance to DSM.

This figure shows the image samples generated by two different score-based diffusion models (NCSN++ deep and DDPM++ deep) trained using the proposed LCSS method on the CIFAR-10 dataset. The top half displays samples generated by NCSN++ deep using the VE SDE, and the bottom half shows samples from DDPM++ deep using the subVP SDE. The figure demonstrates the visual quality of images generated by the LCSS method.

This figure displays several high-resolution (1024x1024 pixels) images of faces generated using the NCSN++ model with VE SDE and the LCSS (Local Curvature Smoothing with Stein’s Identity) method. CelebA-HQ is a high-quality celebrity face dataset used for training. The images demonstrate the model’s capability to generate realistic and diverse facial features at a high resolution, showcasing one of the key results presented in the paper.
Full paper#



















