↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large vision-language models (LVLMs) suffer from object hallucination, where generated image descriptions include objects not present in the image. Existing evaluation methods average results across different instructions, leading to inconsistent evaluations due to variations in image description length. This is problematic because the length of generated descriptions is often directly affected by instruction phrasing.
To address this, the paper proposes LeHaCE, a novel evaluation framework. LeHaCE fits a length-hallucination curve to evaluate object hallucinations at any given description length, ensuring consistent evaluation across varying instruction sets. It introduces an innovative metric, the curve’s slope, which reflects the effect of description length on hallucination degree. Experimental results show that LeHaCE is more stable, fair, and comprehensive than existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the challenge of inconsistent evaluation in object hallucination, a significant issue in large vision-language models (LVLMs). By introducing LeHaCE, a novel evaluation framework, the research provides a more stable and fair method for assessing hallucination across different instruction sets, paving the way for better model development and improved understanding of this pervasive phenomenon. This work is timely and relevant given the rapid advancement and wide-spread application of LVLMs.
Visual Insights#
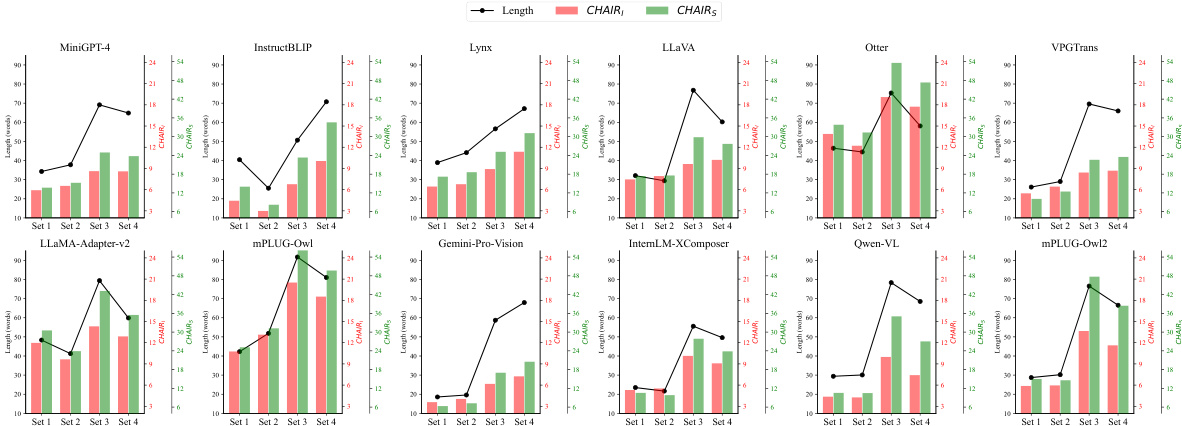
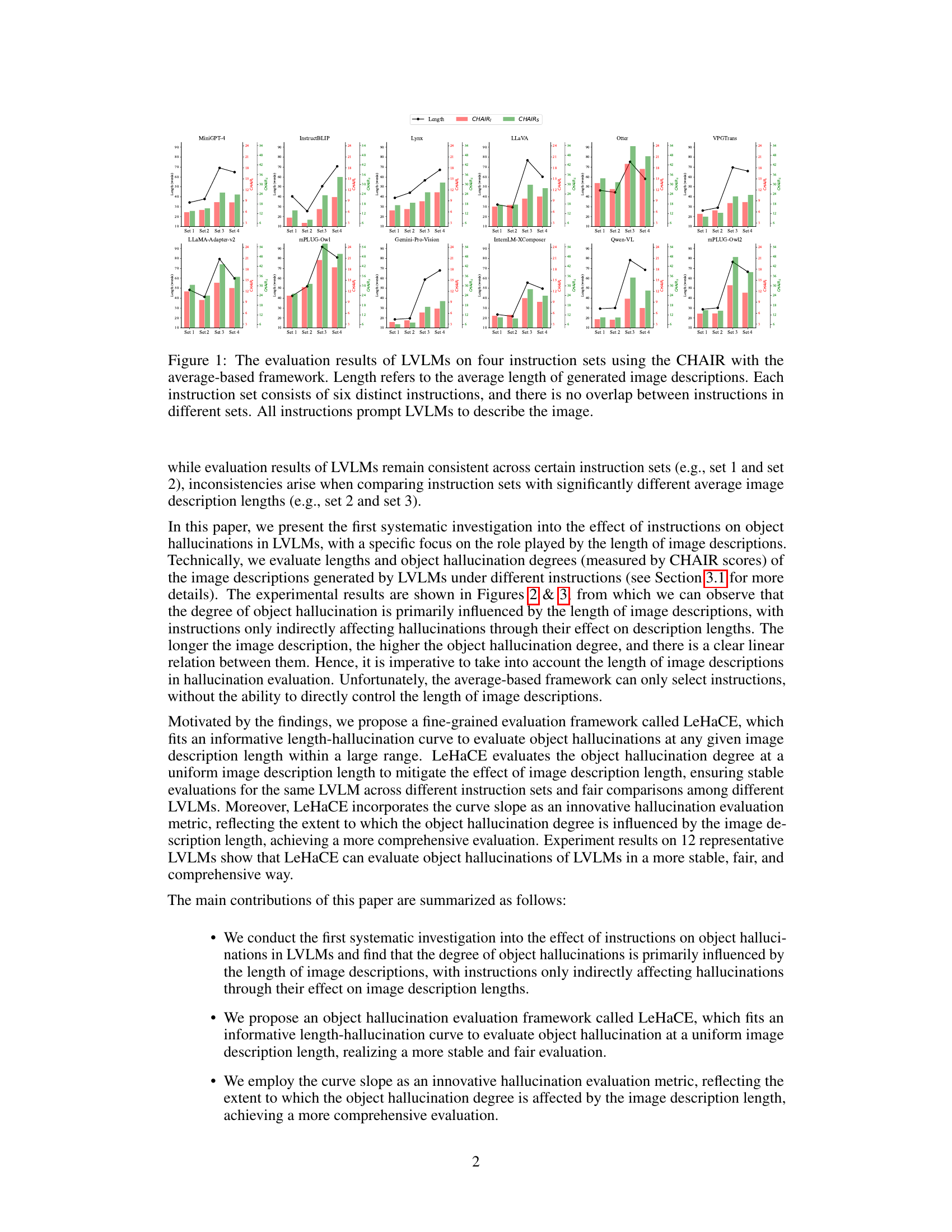
The figure displays the evaluation results of several Large Vision-Language Models (LVLMs) using the CHAIR metric under four different instruction sets. Each instruction set contains six unique instructions designed to elicit image descriptions. The key observation is that the average length of generated image descriptions varies significantly across the instruction sets, highlighting the impact of instruction length on the consistency of LVLMs’ evaluation.
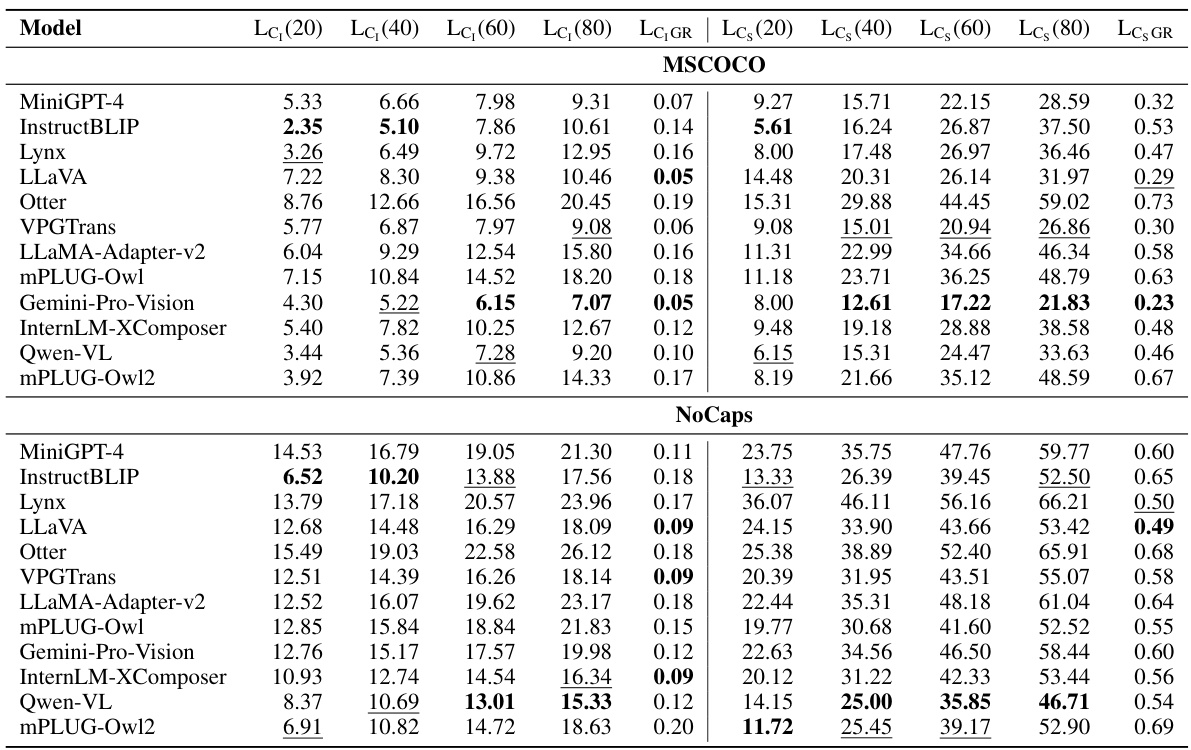
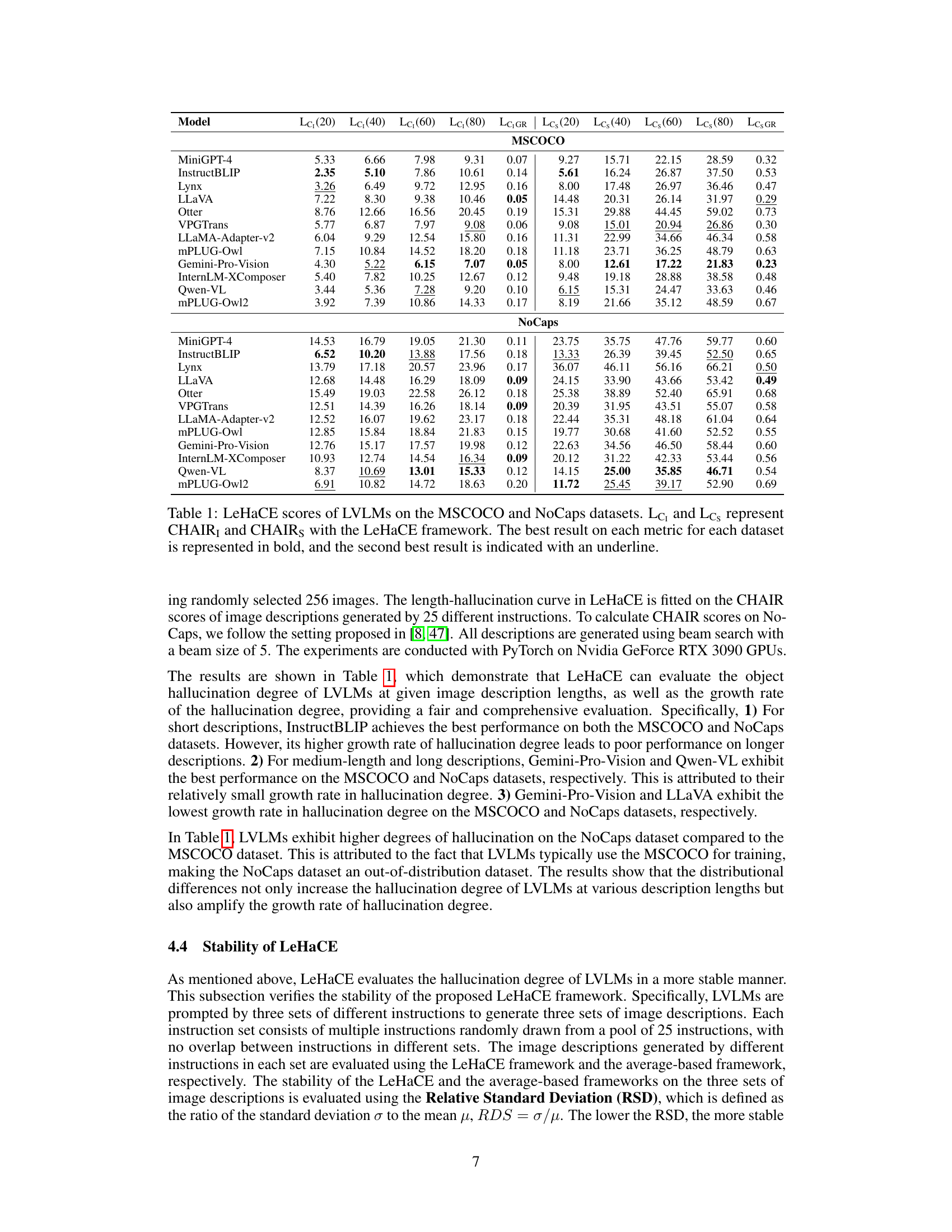
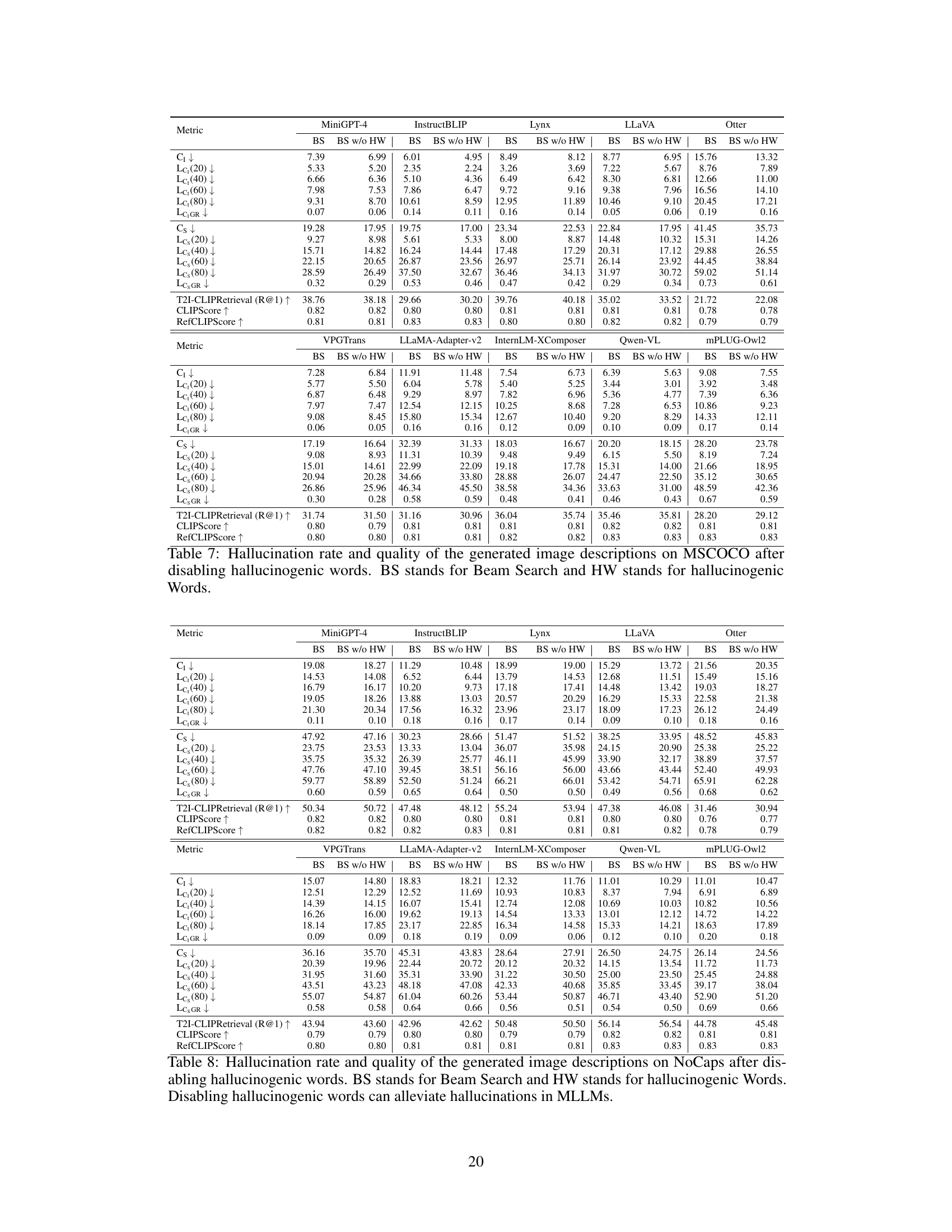
This table presents the LeHaCE scores for 12 large vision-language models (LVLMs) evaluated on two datasets: MSCOCO and NoCaps. LeHaCE is a novel framework introduced in the paper to evaluate object hallucination in a more stable and fair manner. The table shows the scores for two variants of CHAIR (CHAIR₁ and CHAIRs) at four different image description lengths (20, 40, 60, and 80 words) along with the growth rate (LeHaCEGR) of hallucination. The best performing LVLMs for each metric on each dataset are highlighted in bold, while the second-best are underlined.
In-depth insights#
Hallucination Evaluation#
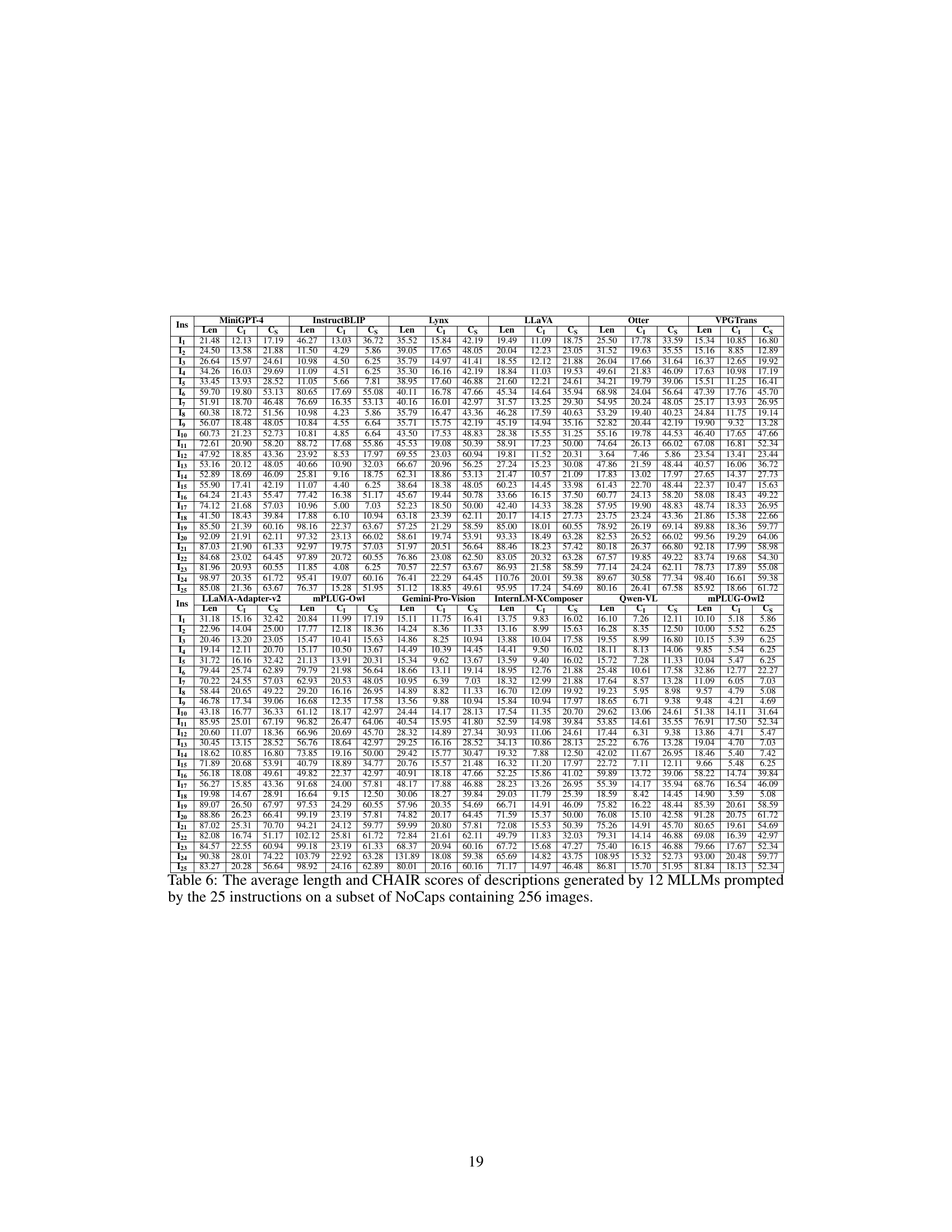
Hallucination evaluation in large vision-language models (LVLMs) presents a significant challenge due to the models’ sensitivity to instruction variations. Existing methods often average results across different instructions, failing to account for the influence of instruction length on the hallucination rate. This leads to inconsistent evaluations across different instruction sets. A key insight is that instruction length directly impacts the hallucination rate; longer descriptions correlate with higher hallucination. A more robust evaluation framework should therefore control for description length, perhaps by fitting a length-hallucination curve and evaluating models at a standardized length. This ensures fairness and stability in comparing different models and instruction sets. Furthermore, evaluating the slope of this curve provides an additional metric, capturing the extent to which hallucination is affected by description length, offering a more comprehensive analysis. Future work should focus on mitigating the effect of instruction length on hallucination and developing more nuanced evaluation metrics that consider factors beyond simple accuracy.
Instruction Effects#
Analyzing instruction effects in large vision-language models (LVLMs) reveals crucial insights into their behavior. Different instructions elicit varying degrees of object hallucination, highlighting the need for robust evaluation methods that account for this variability. A key observation is the indirect influence of instructions on hallucinations through their effect on the length of generated image descriptions. Longer descriptions correlate with a higher hallucination rate, suggesting that the model’s tendency to hallucinate increases with the complexity and length of the required response. This finding challenges traditional evaluation frameworks that average results across different instructions, as these methods may not accurately reflect the impact of description length. Therefore, new evaluation metrics should account for this length-hallucination relationship to provide a more fair and comprehensive assessment of LVLM performance. Focusing solely on the average hallucination rate may mask significant differences in model behavior under varying instructional contexts, ultimately leading to misleading conclusions about their overall capabilities and limitations.
LeHaCE Framework#
The LeHaCE framework offers a novel approach to evaluating object hallucination in large vision-language models (LVLMs) by directly addressing the inconsistencies caused by varying instruction lengths. It introduces a length-hallucination curve, which models the relationship between image description length and hallucination rate, providing a more stable and fair evaluation compared to previous average-based methods. This curve allows for the evaluation of hallucination at a uniform description length, thus mitigating the effects of instruction variability. LeHaCE also incorporates curve slope as an innovative metric, capturing how sensitive hallucination is to description length. This offers a more comprehensive analysis, going beyond a simple hallucination rate to assess the consistency of LVLM performance across different instructions. The framework enhances stability and fairness in LVLMs evaluation, ensuring more reliable comparisons between different models under various instruction sets. By fitting the curve to the experimental data, it offers a detailed understanding of the model’s behavior across different lengths, improving both the objectivity and informativeness of the evaluation process.
Experimental Results#
The Experimental Results section of a research paper is crucial for validating the claims made in the introduction and for demonstrating the effectiveness of the proposed approach. A strong Experimental Results section will present data clearly, showing that the proposed method outperforms existing methods or achieves a significant improvement over a baseline. Robust statistical analysis is also important, demonstrating the reliability and reproducibility of the results. In addition to quantitive results, qualitative analysis, such as case studies or visualizations, can further strengthen the findings. The discussion of the experimental findings should include addressing limitations, potential sources of error and any unexpected outcomes. A thorough examination of these aspects will ensure the results are credible and can be trusted by the research community. The results should be presented in a way that is easy to interpret and supports the claims made in the paper. Finally, a well-written experimental results section provides the necessary evidence and insights to convince readers of the study’s value and contributions.
Future Directions#
Future research could explore the generalizability of LeHaCE across diverse LVLMs and multimodal tasks beyond image captioning, investigating its effectiveness in evaluating other types of hallucinations. A deeper investigation into the causal mechanisms underlying the length-hallucination correlation is warranted, potentially involving linguistic analysis of generated descriptions and a more nuanced understanding of LVLMs’ internal processes. Improving the robustness of LeHaCE to different instruction styles and the development of methods to control description length without sacrificing semantic meaning are crucial for broader applicability. Furthermore, exploring the integration of LeHaCE with hallucination mitigation techniques offers exciting possibilities for a comprehensive evaluation loop, leading to more effective model training and deployment. Ethical considerations surrounding the use of large-scale datasets and potential biases in generated content also deserve further attention.
More visual insights#
More on figures

This figure displays the evaluation results of several Large Vision-Language Models (LVLMs) using the CHAIR metric under four different instruction sets. It highlights the inconsistency of the average-based evaluation framework when dealing with instruction sets that produce image descriptions of significantly different lengths. Each bar represents the hallucination rate for a specific LVLM and instruction set, illustrating how the average description length affects the consistency of the evaluation.
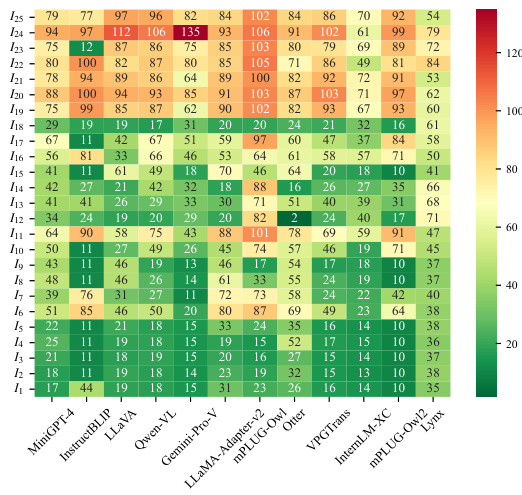
The figure displays the evaluation results of several Large Vision-Language Models (LVLMs) using the CHAIR metric, which measures object hallucination. The results are grouped into four sets, each comprising six unique instructions that prompt the models to describe an image. A key observation is the inconsistent evaluation across instruction sets which produce image descriptions of varying lengths, highlighting the limitation of the average-based evaluation framework.

This figure compares the average-based framework (ABF) and the proposed LeHaCE framework for evaluating object hallucination in large vision-language models (LVLMs). The left panel shows how ABF’s evaluation of LLaVA varies significantly depending on the instruction set used, because different instruction sets lead to image descriptions with varying lengths. In contrast, LeHaCE provides more stable evaluations across different instruction sets by fitting a length-hallucination curve and evaluating at a consistent description length. The right panel illustrates the unfairness of ABF when comparing different LVLMs (LLaVA and mPLUG-Owl). ABF’s comparison is influenced by varying description lengths, while LeHaCE provides a fair comparison by evaluating at the same description length.
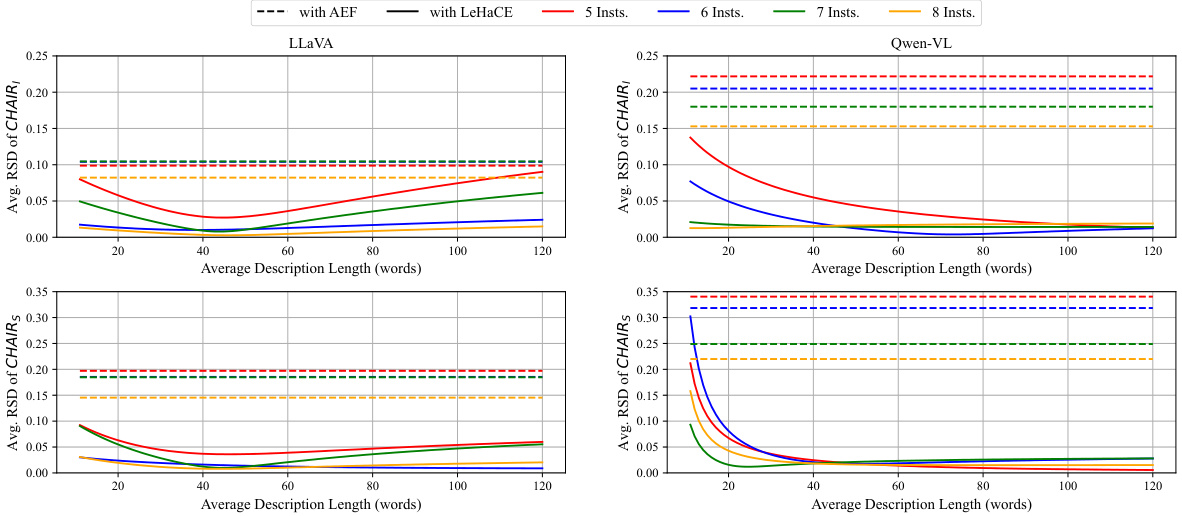
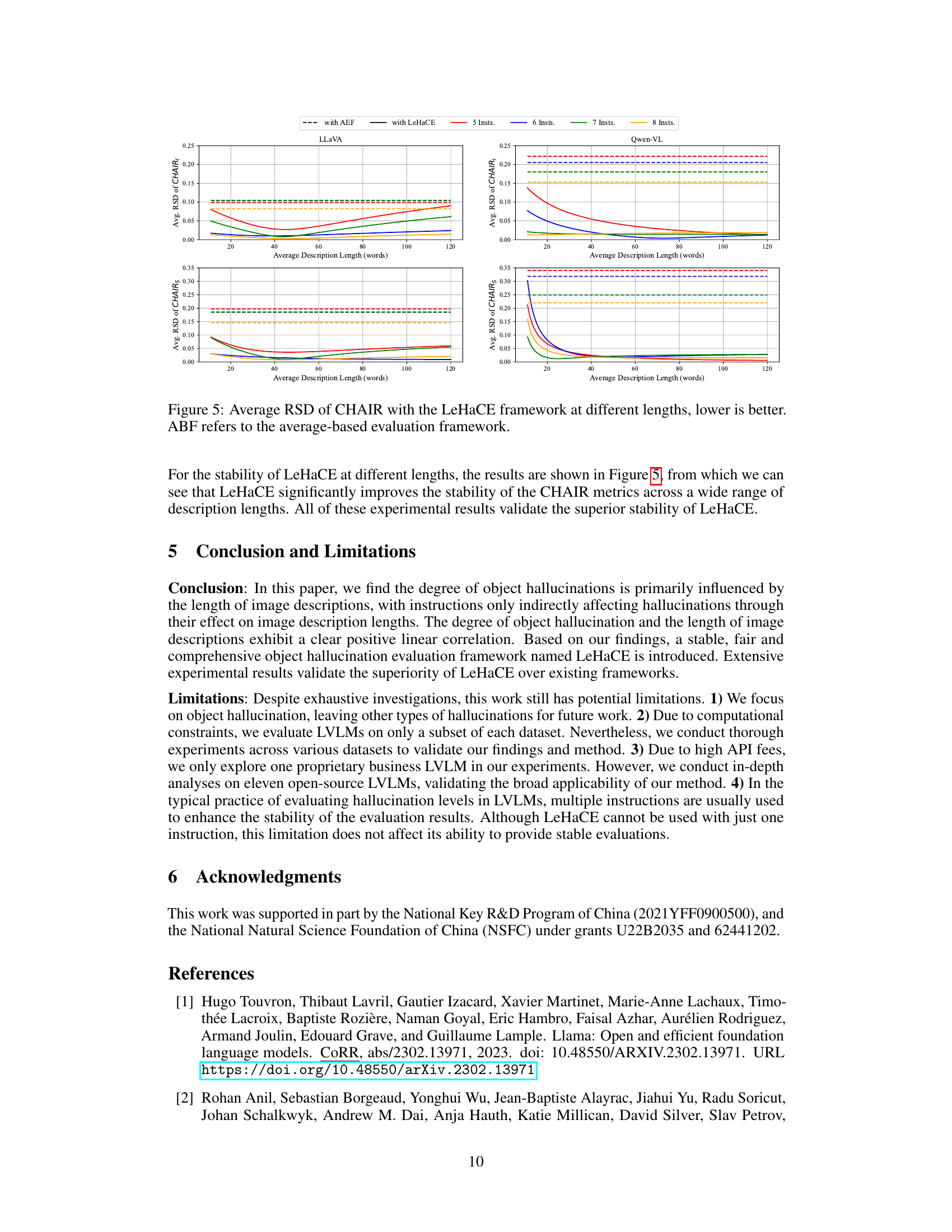
This figure displays the relative standard deviation (RSD) of CHAIR scores for both the average-based framework (ABF) and the proposed LeHaCE framework across various average description lengths. The lower the RSD, the more stable the evaluation method. The plot shows the RSD for four different numbers of instructions (5, 6, 7, and 8) for two different LVLMs (LLaVA and Qwen-VL). It demonstrates LeHaCE’s improved stability in hallucination evaluation compared to ABF across a range of description lengths.
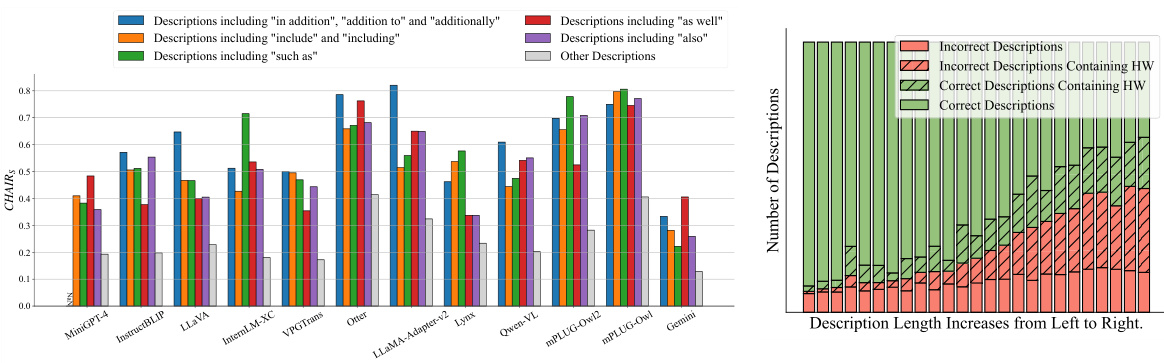
The figure on the left compares hallucination rates in image descriptions with and without what the authors call ‘hallucinogenic words.’ These are words that seem to trigger more hallucinations, like ‘in addition,’ ‘also,’ and ‘as well.’ The bar chart shows that the rate of hallucinations is higher when these words are present. The right-hand figure shows the percentage of these hallucinogenic words in image descriptions containing hallucinations, revealing a positive correlation between the frequency of these words and hallucination rate.

This figure displays the evaluation results of several large vision-language models (LVLMs) using the CHAIR metric, focusing on the impact of instruction set length on object hallucination. Four different instruction sets were used, each set prompting the models to describe the same image but with varying instruction lengths. The graph shows that the average-based framework, which averages results across instructions, yields inconsistent evaluations depending on the length of the image descriptions produced by the instructions.
More on tables
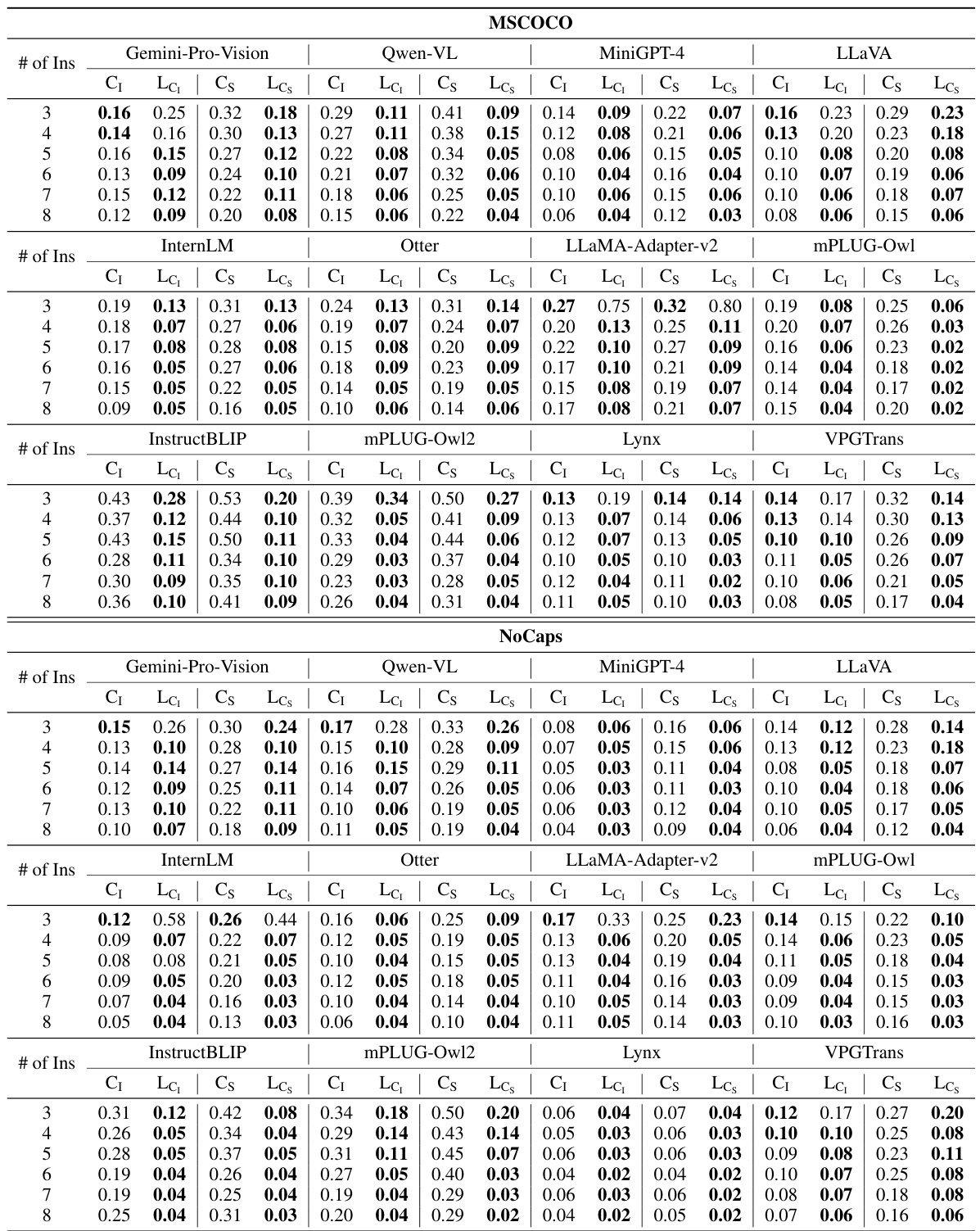
This table presents the LeHaCE scores (CHAIR1 and CHAIRs) for twelve different large vision-language models (LVLMs) on two datasets: MSCOCO and NoCaps. LeHaCE is a novel evaluation framework proposed in the paper, designed to provide a more stable and fair evaluation of object hallucination. The table shows the scores for different description lengths (20, 40, 60, and 80 words) and includes the growth rate (LeHaCEGR) of hallucination. The best performing LVLM for each metric on each dataset is highlighted in bold, with the second-best underlined. This allows for a comparison of the models’ performance and stability across different description lengths.
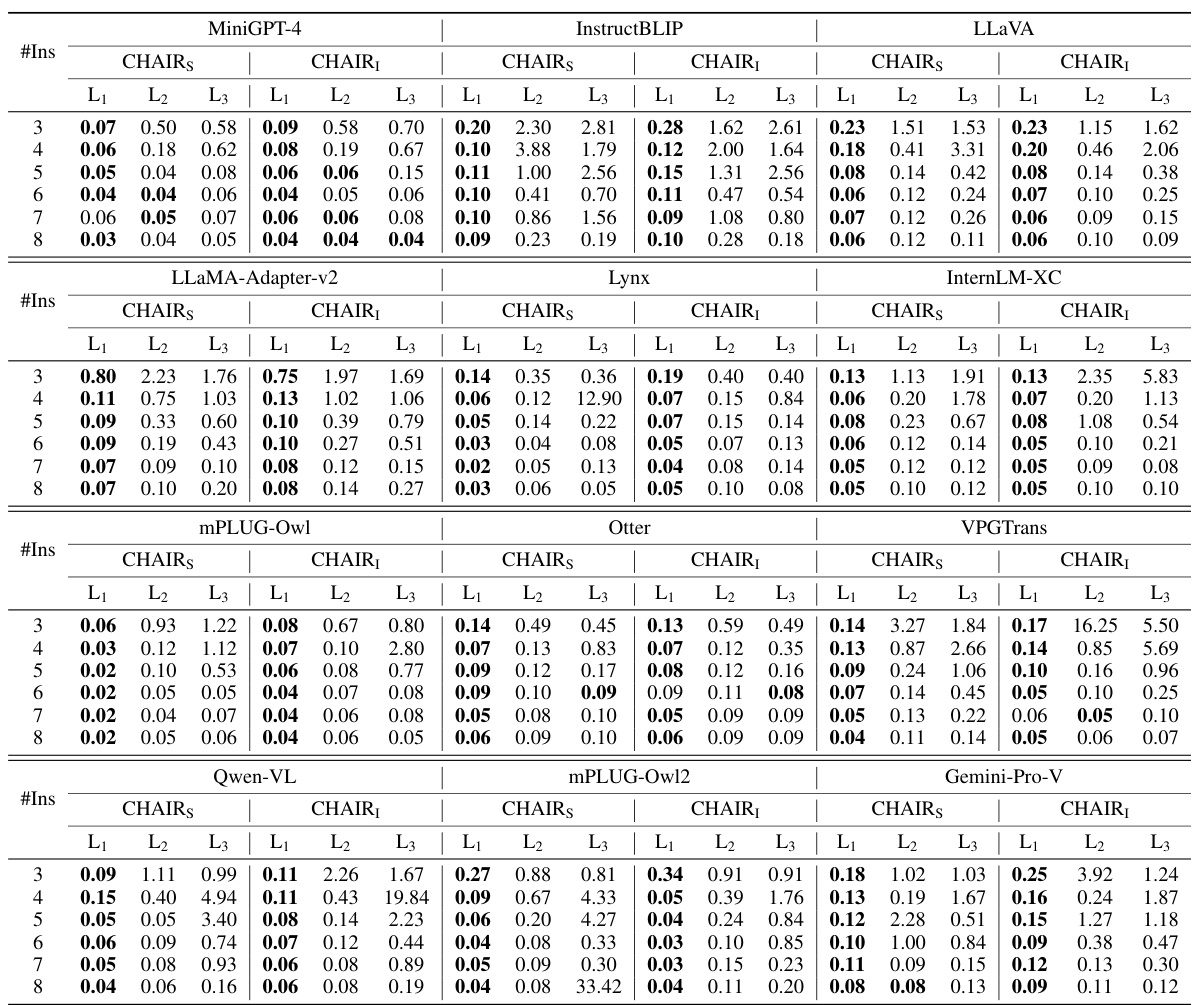
This table presents the LeHaCE scores (CHAIR₁ and CHAIRs) for twelve large vision-language models (LVLMs) evaluated on two benchmark datasets: MSCOCO and NoCaps. LeHaCE scores are provided for four different description lengths (20, 40, 60, and 80 words), along with the growth rate (LeHaCEGR) indicating the change in hallucination rate with respect to description length. The best performing LVLM for each metric in each dataset is highlighted in bold, while the second-best is underlined. This allows for a comparison of LVLMs’ performance in terms of hallucination rates at various description lengths.
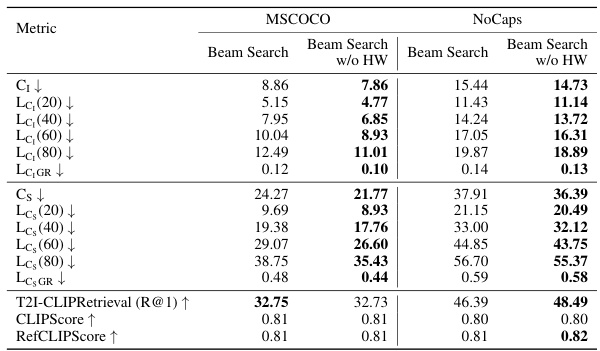
This table presents the LeHaCE scores for twelve Large Vision-Language Models (LVLMs) on two benchmark datasets: MSCOCO and NoCaps. LeHaCE is a novel evaluation framework proposed in the paper. The table shows the performance of each LVLM using two metrics derived from CHAIR (CHAIR₁ and CHAIRs) at four different lengths (20, 40, 60, and 80 words) of image descriptions. The best and second-best performing models for each metric and dataset are highlighted.

This table presents the results of evaluating twelve Large Vision-Language Models (LVLMs) using the LeHaCE framework on two datasets: MSCOCO and NoCaps. LeHaCE is a novel evaluation framework for object hallucination in LVLMs. The table shows the LeHaCE scores for two metrics: CHAIR₁ and CHAIRs, at four different lengths (20, 40, 60, and 80 words) of image descriptions. The best and second-best performing models for each metric and dataset are highlighted. This allows for a comparison of LVLMs across different description lengths and highlights models that are consistently strong performers or those whose performance is significantly affected by description length.

This table presents the LeHaCE scores (a novel framework for evaluating object hallucination in Large Vision-Language Models) for twelve different LVLMs on two datasets: MSCOCO and NoCaps. LeHaCE uses two metrics, Lc₁ (CHAIR₁) and Lcs (CHAIRs), to assess the hallucination rate. The table highlights the best and second-best performance for each metric and dataset, indicating superior performance among the models.

This table presents the LeHaCE (Length-Hallucination Curve-based Evaluation Framework) scores for twelve large vision-language models (LVLMs) on two datasets: MSCOCO and NoCaps. LeHaCE evaluates object hallucination at specific description lengths and includes two metrics: Lc₁ (CHAIR₁) and Lcs (CHAIRs). The table highlights the best and second-best performing models for each metric on each dataset, indicating the relative strengths of different LVLMs in handling object hallucination.

This table presents the results of evaluating twelve Large Vision-Language Models (LVLMs) using the LeHaCE framework on two datasets: MSCOCO and NoCaps. LeHaCE is a novel evaluation framework proposed in the paper to assess object hallucinations, which are inconsistencies between generated image descriptions and the actual image content. The table shows the LeHaCE scores for two different metrics: CHAIR₁ and CHAIRs, which measure different aspects of hallucinations. The best and second-best scores for each metric on each dataset are highlighted for easy comparison of the LVLMs.
Full paper#