↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional curriculum reinforcement learning (CRL) struggles to effectively guide agents, particularly without prior domain knowledge. Many existing methods rely on heuristics or assumptions that don’t hold in complex environments, leading to inefficient learning. Sparse reward problems exacerbate this, making exploration crucial but costly.
DiCuRL tackles these issues by using conditional diffusion models to generate a curriculum of goals. DiCuRL uniquely uses a Q-function and an adversarial intrinsic motivation reward within the diffusion model to assess goal achievability and guide exploration. This approach proves effective across various environments, outperforming existing methods and showing the potential of diffusion models for curriculum learning. DiCuRL’s environment-agnostic nature is a key advantage, eliminating the need for domain-specific knowledge.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and effective approach to curriculum learning in reinforcement learning, addressing a key challenge in the field. DiCuRL’s environment-agnostic nature and strong empirical results demonstrate its potential to advance the state-of-the-art across various RL applications. This research opens new avenues for exploration in curriculum design and diffusion models within reinforcement learning, especially by addressing the sparse reward problem.
Visual Insights#

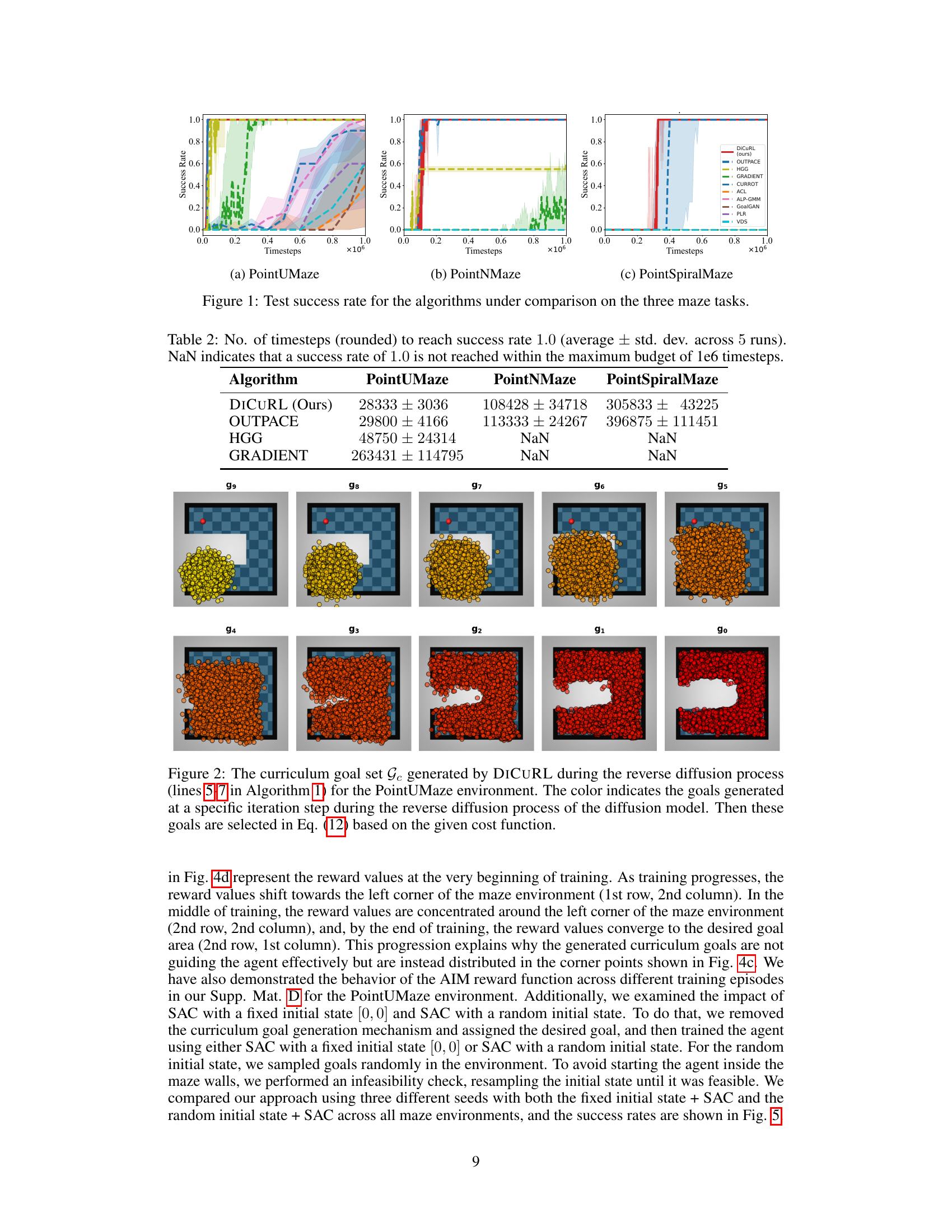
This figure shows the success rate of different curriculum reinforcement learning algorithms across three maze environments (PointUMaze, PointNMaze, and PointSpiralMaze). Each line represents the performance of a specific algorithm, with the x-axis showing the number of timesteps and the y-axis showing the success rate. The figure allows for a visual comparison of the algorithms’ performance in terms of their ability to guide an agent toward the goal in different maze complexities. DICuRL’s performance is compared to nine state-of-the-art algorithms from the literature.

This table compares DiCuRL with nine state-of-the-art curriculum reinforcement learning (CRL) algorithms. For each algorithm, it shows the curriculum generation method used, whether a target distribution curriculum was employed, if the algorithm is geometry-agnostic, whether it’s an off-policy method, and whether it uses external reward. The table also includes the publication venue and year for each algorithm.
In-depth insights#
DiCuRL: Diffuser CRL#
DiCuRL, a Diffusion-based Curriculum Reinforcement Learning approach, presents a novel method for generating curriculum goals using conditional diffusion models. This is a significant departure from traditional CRL methods, which often struggle in complex environments lacking domain knowledge. DiCuRL’s strength lies in its ability to generate challenging yet achievable goals by incorporating a Q-function and an adversarial intrinsic motivation reward function within the diffusion model. This unique approach allows the agent to effectively learn without explicit domain knowledge. The inherent noising and denoising mechanism of the diffusion models also promotes exploration. The environment-agnostic nature of DiCuRL is another key advantage, making it highly adaptable to various tasks. The promising empirical results on maze and robotic manipulation tasks suggest that DiCuRL is a powerful new tool for advancing the field of reinforcement learning. However, limitations exist regarding the scalability to higher-dimensional data and the selection of optimal curriculum goals, requiring further research.
AIM-Q Fusion#
The heading ‘AIM-Q Fusion’ suggests a method combining Adversarial Intrinsic Motivation (AIM) and a Q-function. AIM rewards an agent for exploring novel states, promoting efficient learning in environments with sparse rewards. The Q-function estimates the expected cumulative reward of taking specific actions. Combining them likely means using AIM-derived rewards to shape the Q-learning process, potentially guiding the agent toward more rewarding areas of the state space, while simultaneously fostering exploration. This fusion is particularly beneficial when dealing with complex environments requiring exploration to discover rewarding states, which would be a major contribution of this work. The effectiveness of such fusion would depend on how well the AIM and Q-function components are integrated and how their relative strengths are balanced. A well-designed AIM-Q Fusion approach could lead to significant improvements in exploration efficiency and overall performance compared to methods using either technique independently.
Maze & Robot Tests#
The maze and robot experiments section of the research paper is crucial for validating the proposed DiCuRL algorithm. Maze environments, with varying complexities, provide a controlled setting to assess DiCuRL’s ability to generate effective curriculum goals, guiding an agent to progressively more difficult tasks. The results from these tests demonstrate DiCuRL’s performance against state-of-the-art methods. Furthermore, the inclusion of robotic manipulation tasks extends the evaluation beyond simplified simulations. This demonstrates DiCuRL’s generalization capability to more complex and realistic scenarios, which is important for evaluating the practical applicability of the proposed method. By employing tasks such as FetchPush and FetchPickAndPlace, the study showcases DiCuRL’s effectiveness in a diverse range of environments, strengthening the overall conclusions about its efficacy and robustness.
Diffusion Model#
Diffusion models, in the context of reinforcement learning, offer a powerful mechanism for generating diverse and challenging curriculum goals. They achieve this by framing the goal generation process as a controlled diffusion of latent variables. This inherent stochasticity facilitates exploration, as opposed to deterministic methods which can get stuck in local optima. The ability to condition the diffusion process on relevant information (like the current agent state) is key to creating goals that are appropriately challenging for the current learning stage. A key advantage is that diffusion models don’t require explicit specification of the goal space, but rather implicitly learn its structure, making them adaptable to complex environments. However, the use of diffusion models introduces computational costs, and the balance between exploration and exploitation needs careful consideration through techniques like reward shaping and Q-function integration. The effectiveness of a diffusion model-based approach hinges upon the proper training and parameter tuning of the underlying diffusion process, along with careful consideration of the appropriate level of noise and the conditioning information.
Future Work#
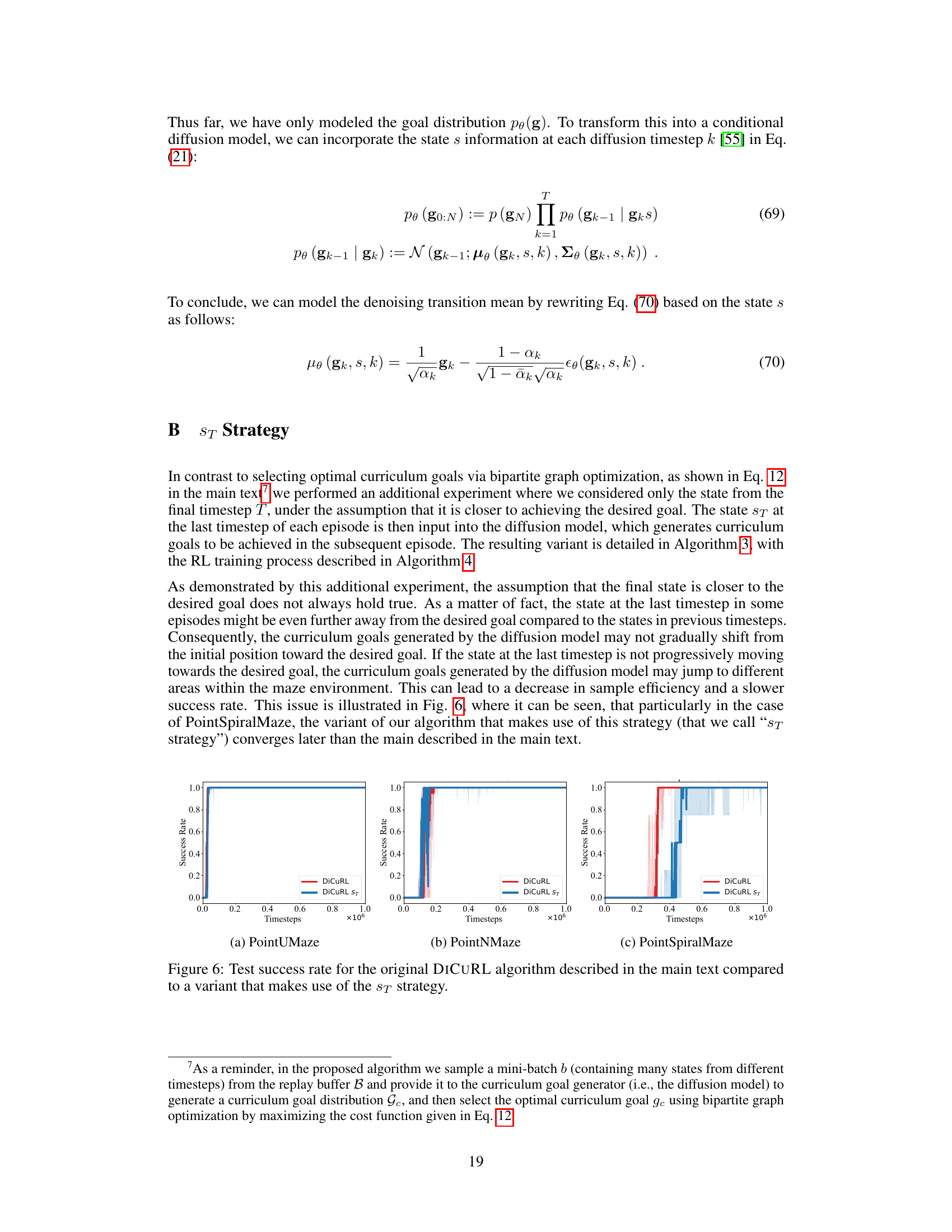
The authors suggest several promising avenues for future research. Extending DiCuRL to more complex environments beyond the simulated mazes and robotic tasks is a crucial next step, potentially involving more complex reward structures and higher-dimensional state spaces. Addressing the limitations of the Minimum Cost Maximum Flow algorithm used for curriculum goal selection is also important, exploring alternative methods that might be more efficient or robust. Investigating the impact of the AIM reward function in high-dimensional settings is another key area, as its performance might degrade with increasing dimensionality. Finally, a thorough comparison with a wider range of state-of-the-art CRL algorithms using more challenging and diverse benchmarks would further solidify the method’s position within the field and provide a clearer understanding of its strengths and weaknesses.
More visual insights#
More on figures
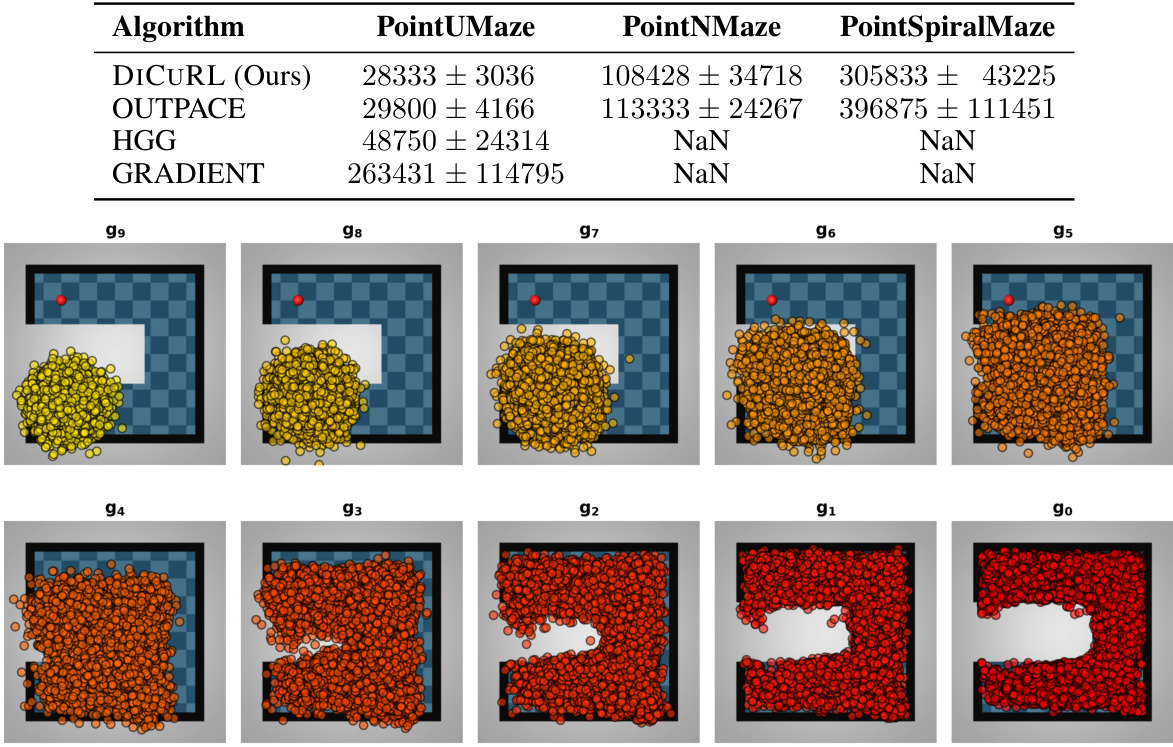
This figure visualizes the curriculum goals generated by the DiCuRL algorithm for the PointUMaze environment. Each color represents goals generated at different iteration steps during the reverse diffusion process. The final goal selection is based on a cost function (Eq. 12) which finds the optimal curriculum goal from the generated set.

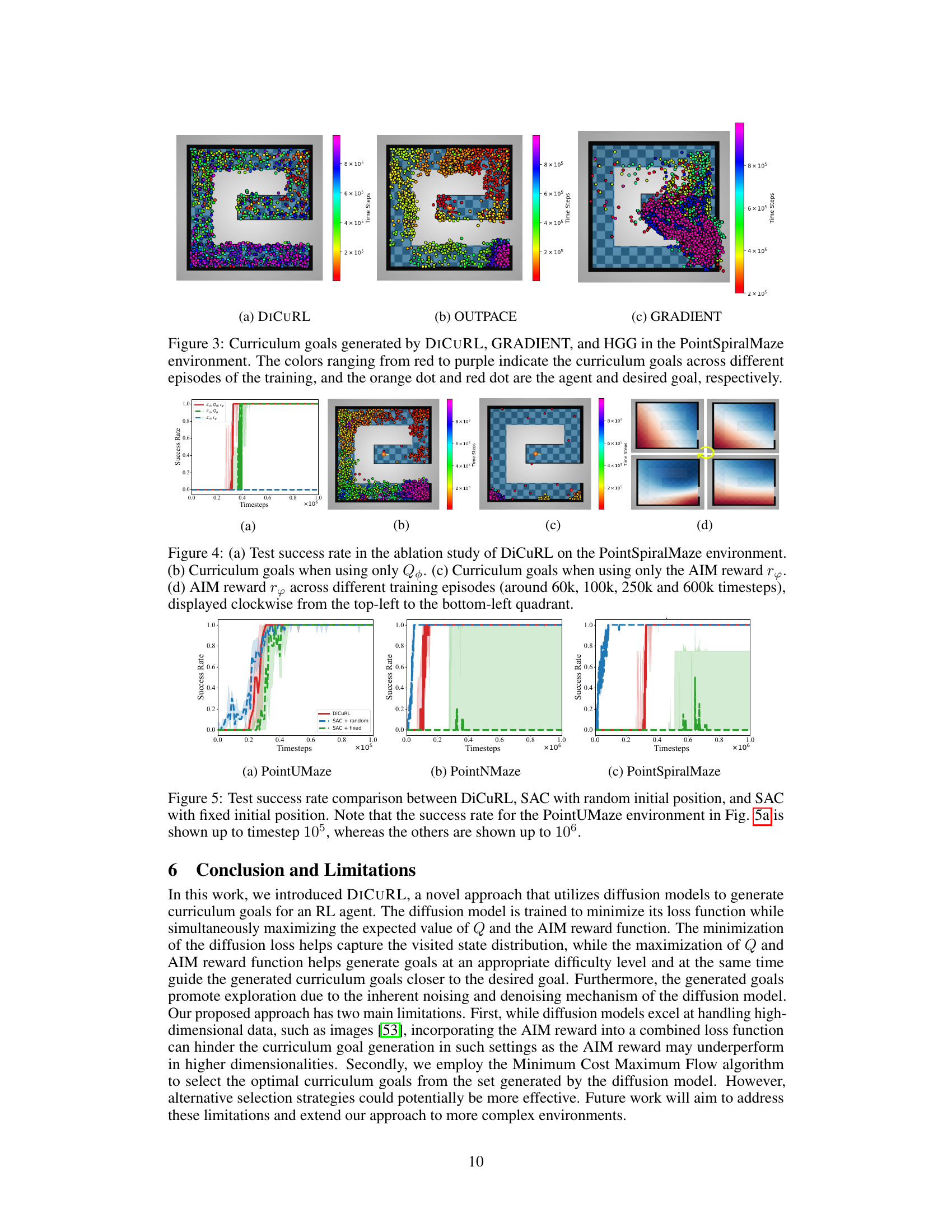
This figure compares the curriculum goals generated by three different algorithms: DICURL, GRADIENT, and HGG, in the PointSpiralMaze environment. Each algorithm’s curriculum goals are visualized using different colors, ranging from red (earlier episodes) to purple (later episodes). The orange dot represents the agent’s position, while the red dot indicates the desired goal. The figure illustrates how each algorithm approaches the generation of curriculum goals, highlighting differences in exploration strategies and how they guide the agent towards the final goal.

This figure presents the ablation study results of DiCuRL on the PointSpiralMaze environment. Subfigure (a) shows the test success rate when using the full DiCuRL model, when only using the Q-function, and when using only the AIM reward function. Subfigures (b) and (c) visualize the generated curriculum goals for the respective cases. Subfigure (d) illustrates the AIM reward values throughout the training process at different time steps.

This figure compares the success rate of DiCuRL and nine other state-of-the-art curriculum reinforcement learning (CRL) algorithms across three different maze environments: PointUMaze, PointNMaze, and PointSpiralMaze. The x-axis represents the number of timesteps, and the y-axis represents the success rate (the percentage of trials where the agent successfully reached the goal). The figure shows that DiCuRL consistently outperforms or matches the other algorithms in all three environments, demonstrating its effectiveness in generating challenging yet achievable curriculum goals.

The figure shows the success rate of DiCuRL and other state-of-the-art CRL algorithms on three different maze environments. The x-axis represents the number of timesteps, and the y-axis represents the success rate. Each line represents a different algorithm. This graph visually demonstrates the relative performance of DiCuRL against other approaches in reaching the target successfully.
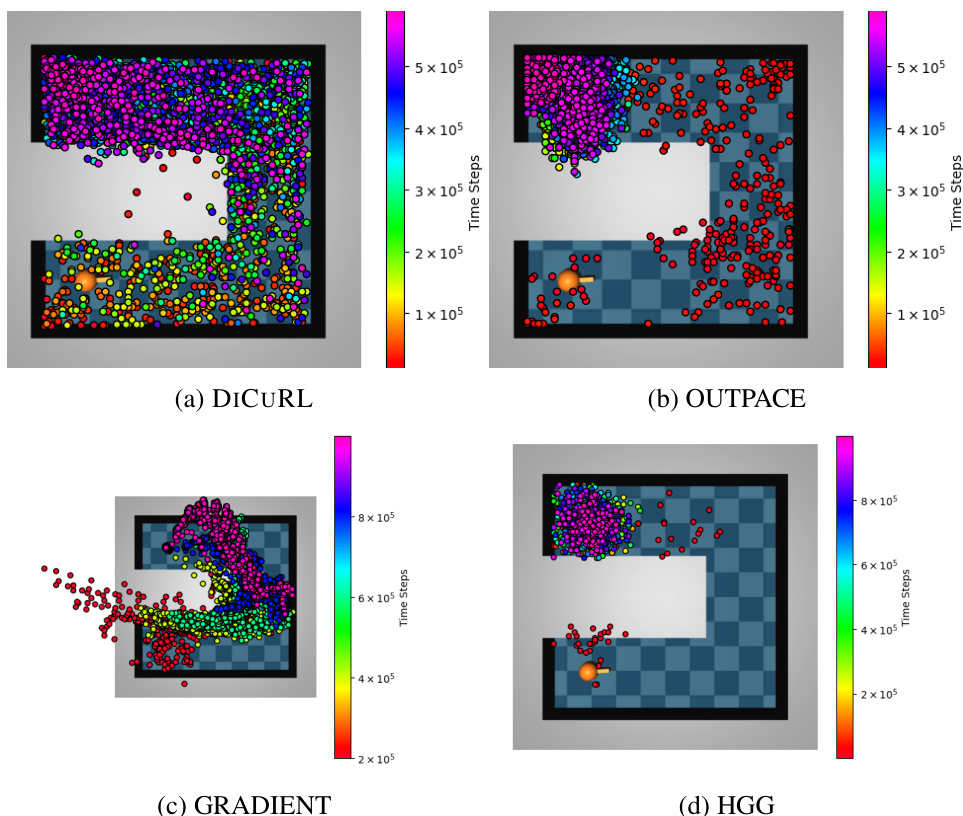
This figure shows the curriculum goals generated by four different curriculum reinforcement learning algorithms in the PointUMaze environment. The colors represent the progression of the curriculum goals over training episodes. The orange dot represents the agent’s location, and the red dot represents the desired goal location. The figure illustrates the differences in how each algorithm explores and generates curriculum goals during training.
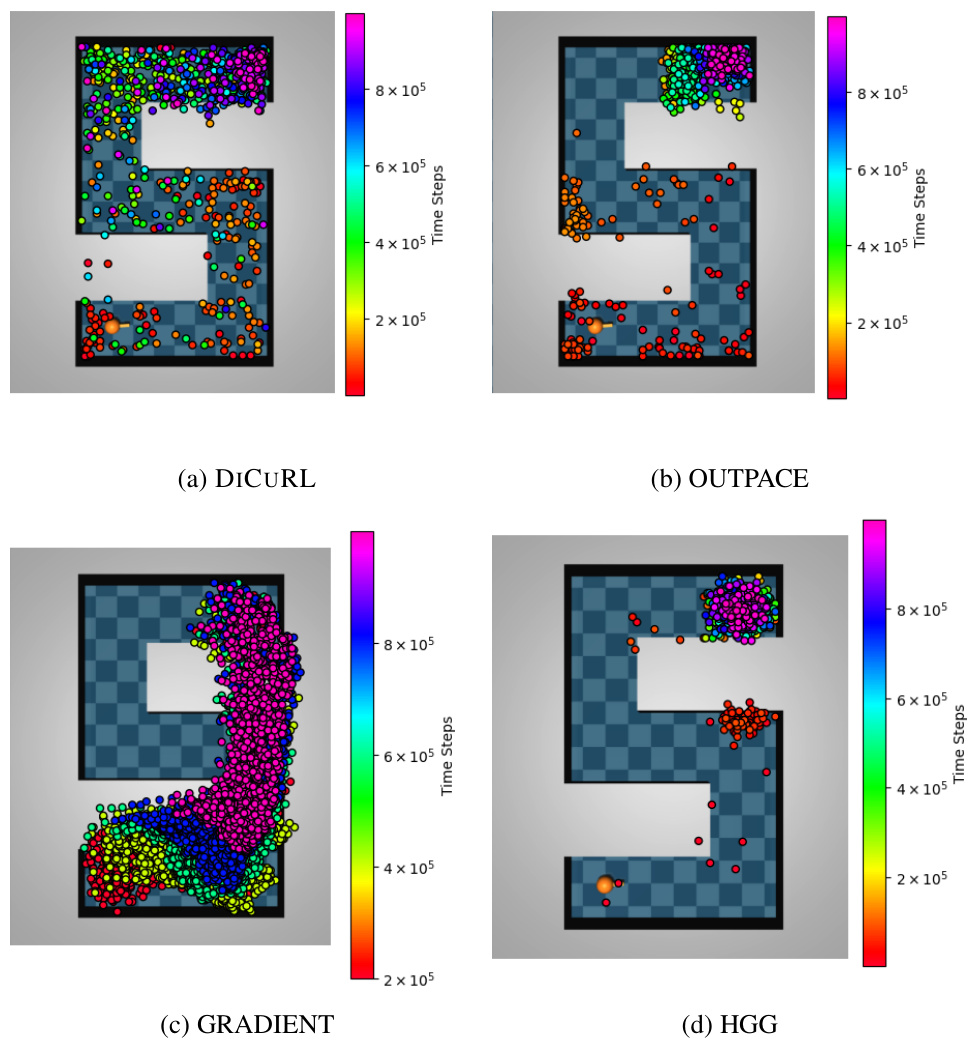
This figure compares the curriculum goals generated by DiCuRL, GRADIENT, and HGG algorithms in the PointSpiralMaze environment. Different colors represent goals generated during different training episodes, showing the progression of goals from the initial state to the target. The orange dot indicates the agent’s position, and the red dot represents the desired goal. The visualization helps understand how each algorithm generates and selects intermediate goals to guide the agent towards the target.

This figure compares the curriculum goals generated by three different algorithms: DiCuRL, GRADIENT, and HGG, in the PointSpiralMaze environment. Each algorithm generates a sequence of goals that guide the agent’s learning process. The colors represent the time progression, with red being the earliest goals and purple being the latest. The orange dot indicates the agent’s current position, and the red dot indicates the desired goal. The figure visually demonstrates how DiCuRL’s generated goals effectively explore the environment, in contrast to GRADIENT and HGG, which seem less comprehensive in their goal selection.

This figure shows the curriculum goals generated by the DiCuRL algorithm in the PointUMaze environment at different steps of the reverse diffusion process. Each image represents a different step, with the color of the points indicating the step in the process. The final selected goals are then used as curriculum goals in the RL process.

This figure shows a visualization of the AIM reward function and Q-function in the early stage of training for the PointUMaze environment. The AIM reward function is a measure of how close the agent is to achieving its goal, while the Q-function estimates the expected cumulative reward. The visualization helps to understand how these two functions guide the agent’s learning process in the early stages of training.

This figure shows the curriculum goals generated by the DiCuRL model during the reverse diffusion process for the PointUMaze environment. Each image represents a specific timestep in the reverse diffusion process, with the color of the points indicating the goals generated at that timestep. The final goal is selected from this set based on a cost function (Eq. 12). This illustrates how DiCuRL progressively refines the curriculum goals, moving from more noisy samples towards the desired goal.

This figure shows a visualization of the AIM reward function and the Q-function in the early stage of training for the PointUMaze environment. The AIM reward function estimates how close the agent is to achieving its goal, while the Q-function predicts the cumulative reward starting from a state and following a policy. The visualization helps to understand how these two functions influence the generation of curriculum goals by the diffusion model in DiCuRL.

This figure shows curriculum goals generated by DiCuRL for the PointUMaze environment. The color gradient represents the progression of goals throughout the reverse diffusion process. Goals start as noisy samples and gradually become refined, representing a curriculum of increasing difficulty.
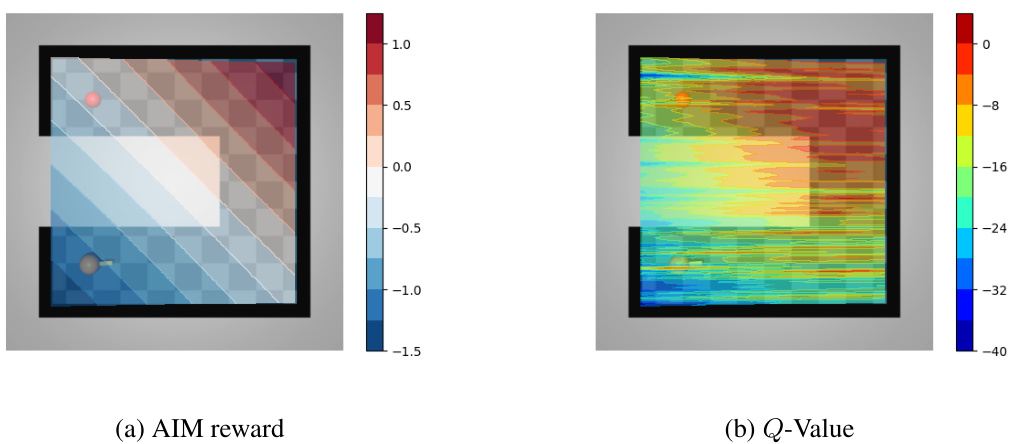
This figure visualizes the AIM reward function and Q-function in the PointUMaze environment during the initial stage of training. The AIM reward function estimates how close an agent is to achieving its goal and is represented in a color map, with higher values indicating closer proximity to the goal. The Q-function predicts the cumulative reward starting from a state and following the policy and is also represented in a color map. The figure demonstrates how both functions evolve during the initial phase of learning, reflecting the agent’s progress toward goal achievement.
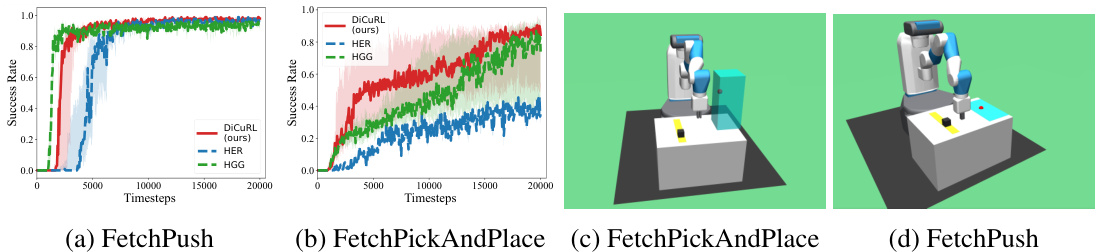
This figure presents the results of applying the DiCuRL method to two robotic manipulation tasks: FetchPush and FetchPickAndPlace. The success rate (the proportion of times the robot successfully completes the task) is plotted over time for DiCuRL, HER, and HGG. Shaded areas represent variability across multiple trials. Panels (c) and (d) illustrate the tasks and their goal areas. The results show that DiCuRL generally outperforms the baseline methods.

This figure showcases the success rates of different curriculum reinforcement learning (CRL) algorithms across three maze environments: PointUMaze, PointNMaze, and PointSpiralMaze. The x-axis represents the number of timesteps, and the y-axis represents the success rate. Each line corresponds to a different CRL algorithm. The figure visually demonstrates the comparative performance of DiCuRL against other state-of-the-art CRL algorithms in terms of achieving the desired goals within the maze environments. The PointSpiralMaze environment is particularly challenging, as shown by the lower success rates of most algorithms.
More on tables

This table compares DiCuRL with nine state-of-the-art curriculum reinforcement learning (CRL) algorithms. For each algorithm, it lists the curriculum method used, whether a target distribution is used for the curriculum, if the algorithm is geometry-agnostic, whether it uses an off-policy approach, and the type of external reward used, as well as the publication venue and year. This allows for a comparison of DiCuRL’s approach against existing methods in the field.

This table compares DiCuRL with nine state-of-the-art curriculum reinforcement learning (CRL) algorithms. For each algorithm, it lists the curriculum method used, whether the algorithm considers the target distribution or geometry, whether it is off-policy or not, if it uses external reward, and the publication venue and year. This allows for a comparison of DiCuRL’s approach to existing techniques and highlights its unique features.
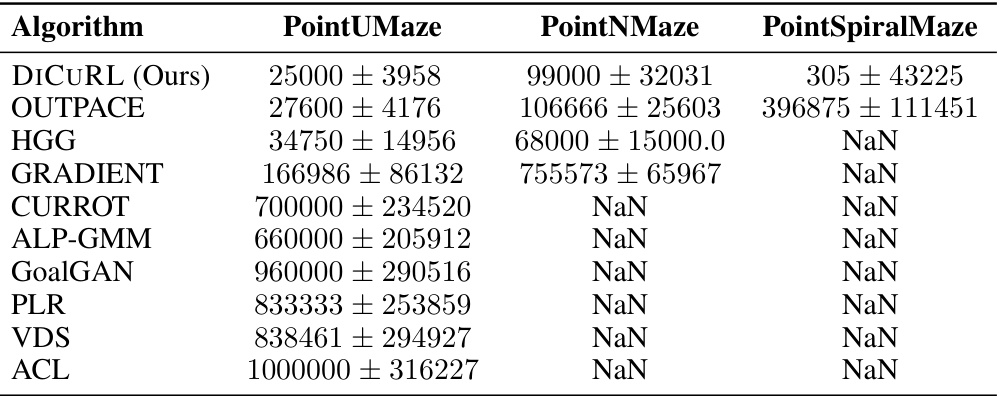
This table compares DICURL against nine state-of-the-art CRL algorithms. It details the curriculum method used by each algorithm, whether it considers target distribution or geometry, whether it is off-policy or not, and whether it uses external rewards, along with the publication venue and year.
Full paper#