↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional LLM training uses randomly sampled data, unlike how humans learn. This approach often leads to “catastrophic interference”—forgetting previously learned information. The paper explores a structured, cyclical training approach where documents are presented repeatedly in a fixed sequence, mimicking real-world learning patterns.
The study reveals a novel phenomenon of “anticipatory recovery”. Large LLMs, when trained cyclically, surprisingly recover from forgetting before encountering the same information again. This behavior is more pronounced with larger models. The findings also show improved performance in a prequential evaluation setting, suggesting a potential practical advantage to cyclical training. This study offers a new understanding of overparameterized neural networks and has implications for the design of more efficient and effective training methods in continual learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the conventional wisdom of LLM training by demonstrating that structured, cyclical training can lead to unexpected improvements in model performance and robustness. This opens new avenues for investigating more efficient and effective methods for training large language models and other neural networks. It also offers a new perspective on catastrophic interference, a long-standing challenge in continual learning.
Visual Insights#
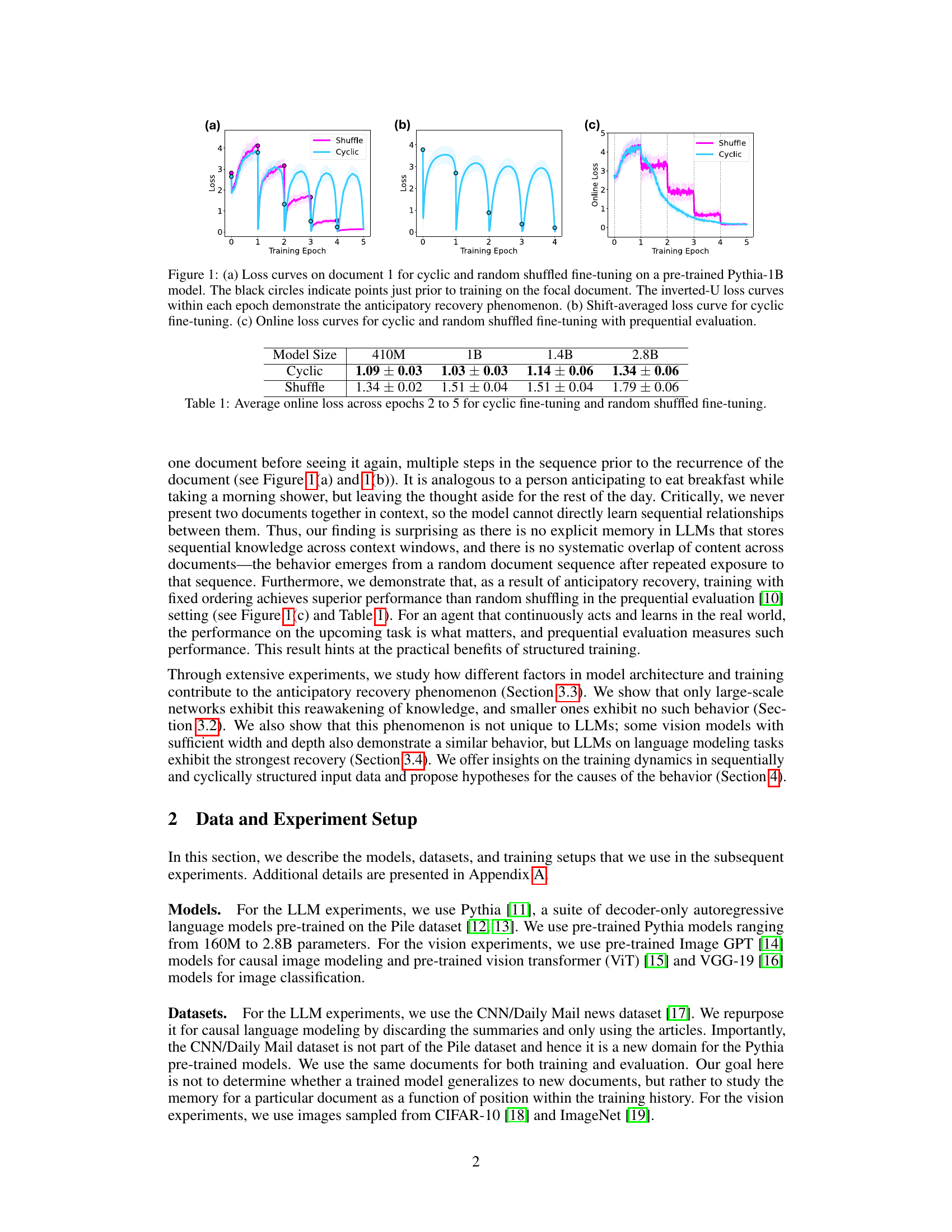
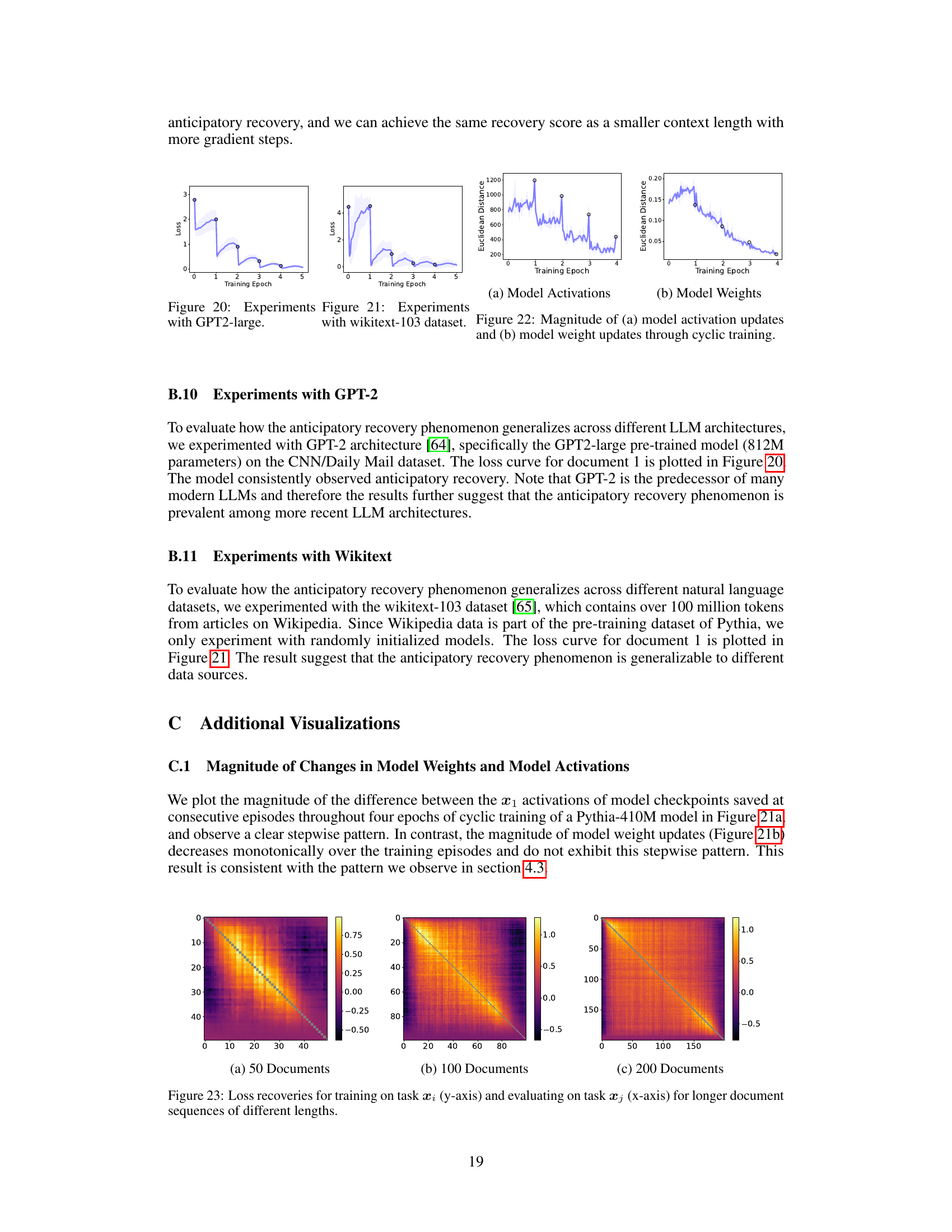
This figure demonstrates the anticipatory recovery phenomenon observed in the paper. (a) shows the loss curves for document 1 under cyclic and shuffled fine-tuning, highlighting the inverted-U shape indicating anticipatory recovery before encountering the document again. (b) presents the shift-averaged loss curves for cyclic fine-tuning, showing the average loss across different documents and epochs. (c) compares online loss curves for cyclic and shuffled fine-tuning using prequential evaluation, where the model is evaluated on the next document before fine-tuning, demonstrating better performance with cyclic fine-tuning.

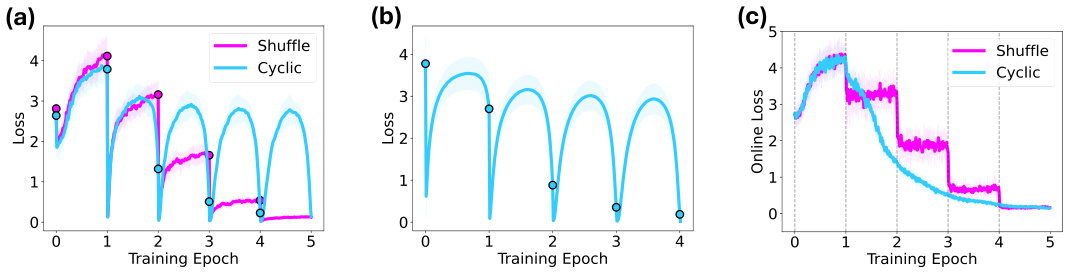
This table presents the average online loss across epochs 2 to 5 for two different training methods: cyclic fine-tuning and random shuffled fine-tuning. The results are shown for four different model sizes (410M, 1B, 1.4B, and 2.8B parameters). The table demonstrates the performance improvement achieved with cyclic fine-tuning compared to random shuffling, especially as the model size increases.
In-depth insights#
Anticipatory Recall#
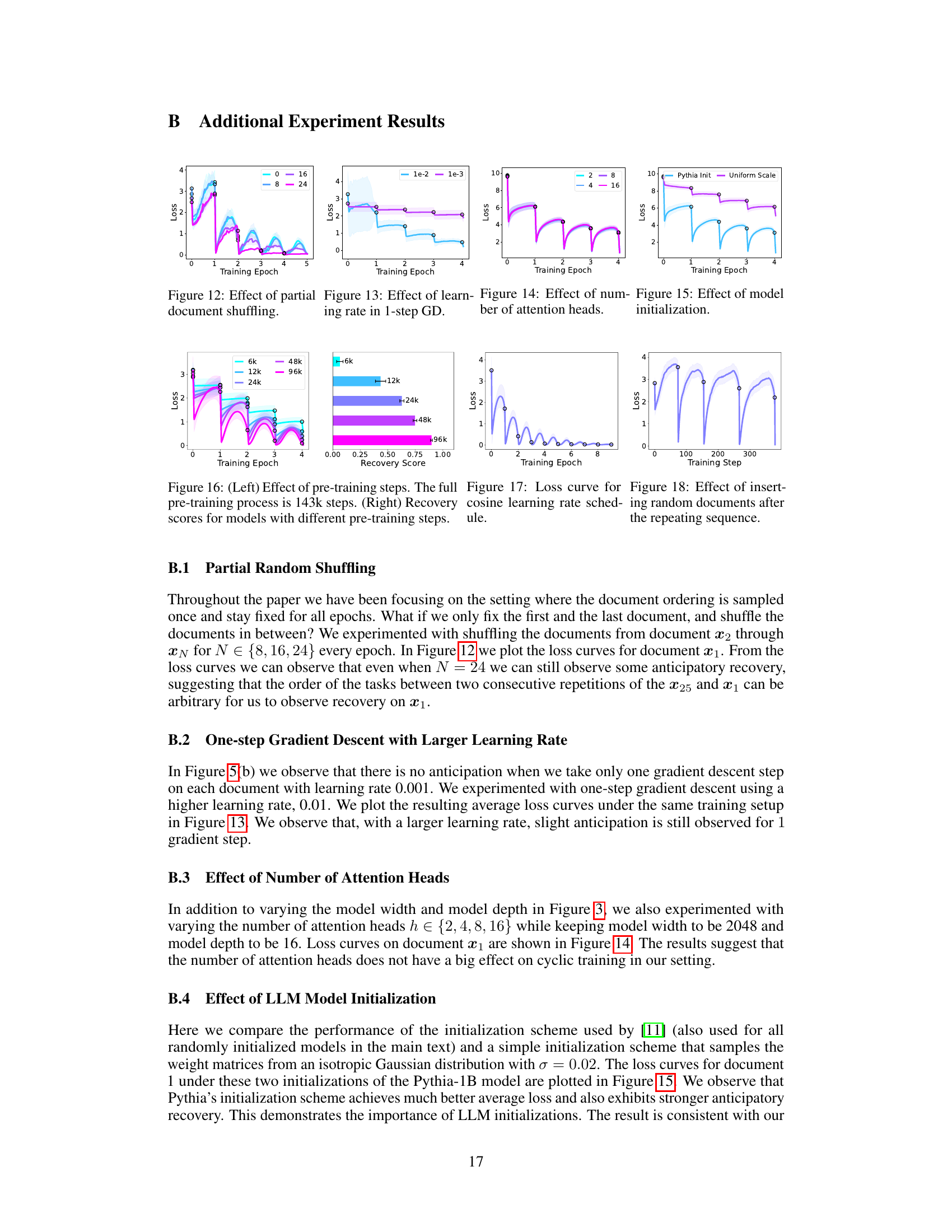
The concept of “Anticipatory Recall” in the context of the provided research paper is fascinating. It suggests that sufficiently large and well-trained language models (LLMs), when trained on a cyclically repeating sequence of documents, exhibit a remarkable ability to “remember” documents before they are even presented again. This is unexpected because it demonstrates a form of proactive memory not typically observed in standard LLMs that are trained on randomly shuffled data. The phenomenon goes beyond simply recognizing previously seen data, as it suggests an anticipatory process of reactivating relevant knowledge in the model’s internal representation even in the absence of explicit contextual cues connecting the related documents. This behavior implies a deeper understanding of temporal relationships within the training data, possibly due to the emergence of complex internal representations and learned sequences within the vast parameter space of the LLMs. This research suggests exciting possibilities for future research, particularly in the field of continual learning where the ability to anticipate and reactivate previous knowledge could be a significant advancement, leading to more efficient and robust learning systems.
Cyclic Training#
The concept of ‘cyclic training’ in the context of neural network training introduces a paradigm shift from traditional random data sampling. Instead of presenting data points randomly, cyclic training involves presenting data in a fixed, repeating sequence. This approach, while seemingly simple, unveils fascinating dynamics. The paper investigates how these cyclic presentations affect the network’s ability to learn and retain knowledge across multiple encounters with the same data point. The emergence of ‘anticipatory recovery’—where the network demonstrates improved performance on a data point before its next scheduled presentation—is a remarkable finding. This phenomenon challenges the typical understanding of catastrophic interference, suggesting that over-parametrized networks can exhibit a form of implicit memory, even without explicit mechanisms designed for memory retention. The cyclic approach also enables a closer examination of the relationship between the temporal structure of data presentation and the network’s training dynamics, and it might also have practical advantages over random sampling strategies when dealing with real-world, structured environments.
Emergent Behavior#
The concept of “emergent behavior” in the context of the provided research paper likely refers to the unexpected and remarkable ability of sufficiently large language models (LLMs) to recover from catastrophic interference during cyclic training. This behavior is termed “anticipatory recovery”, where the models seemingly anticipate and preemptively mitigate forgetting of previously seen data before encountering it again in the training sequence. Crucially, this recovery is not explicitly programmed but emerges as a property of the over-parameterized network architecture. The emergence of this behavior highlights a potential new mechanism for mitigating catastrophic forgetting and suggests novel training paradigms. The scale of the LLMs plays a crucial role in the phenomenon’s strength, implying that model size and complexity are key contributors to this emergent capacity. It challenges conventional assumptions about neural network learning and opens up avenues for further research into the nature of over-parameterization and the conditions under which such spontaneous recovery phenomena appear.
Model Scaling#
Model scaling, in the context of large language models (LLMs), involves increasing model parameters to improve performance. This approach often yields substantial gains in capabilities, but comes with trade-offs. Increased computational costs are a significant concern, requiring substantial resources for training and inference. The relationship between model size and performance is not always linear; diminishing returns can set in beyond a certain size. Understanding the emergent properties of LLMs, such as anticipatory recovery from catastrophic forgetting as discussed in the paper, is crucial for effectively leveraging scaling. Optimizing training strategies and architecture to mitigate the negative effects of scaling are paramount. Ultimately, optimal model size represents a balance between performance gains and resource constraints, necessitating a careful evaluation of both factors in the context of specific applications.
Future Research#
Future research directions stemming from this work on anticipatory recovery in cyclic training could explore several key areas. Extending the model’s ability to handle more complex, real-world data with noise and irregularities beyond simple cyclic patterns is crucial. Investigating different model architectures and training methodologies beyond LLMs to assess the generality of anticipatory recovery would broaden our understanding. A critical area is to develop a more robust theoretical framework that explains the underlying mechanisms driving this behavior, potentially bridging the gap between empirical observations and theoretical models. Furthermore, research should examine the practical implications of structured training for continual learning, evaluating its advantages and disadvantages in various scenarios. Finally, exploring the relationship between anticipatory recovery and other emerging properties of LLMs, such as chain-of-thought reasoning, could yield significant insights. Addressing potential limitations concerning the computational cost and the risk of overfitting associated with structured training will also be important for future research.
More visual insights#
More on figures
This figure demonstrates the anticipatory recovery phenomenon observed in the cyclic fine-tuning of a large language model (LLM). Subfigure (a) shows the loss curve for a single document during cyclic and shuffled fine-tuning. The inverted-U shape in the cyclic fine-tuning curve indicates that the model’s loss on the document decreases before it is seen again, even without any overlap between documents. Subfigure (b) presents a shift-averaged version of the cyclic loss curves across all documents. Subfigure (c) offers a comparison between online losses for cyclic and shuffled fine-tuning across several model sizes using a prequential evaluation metric.
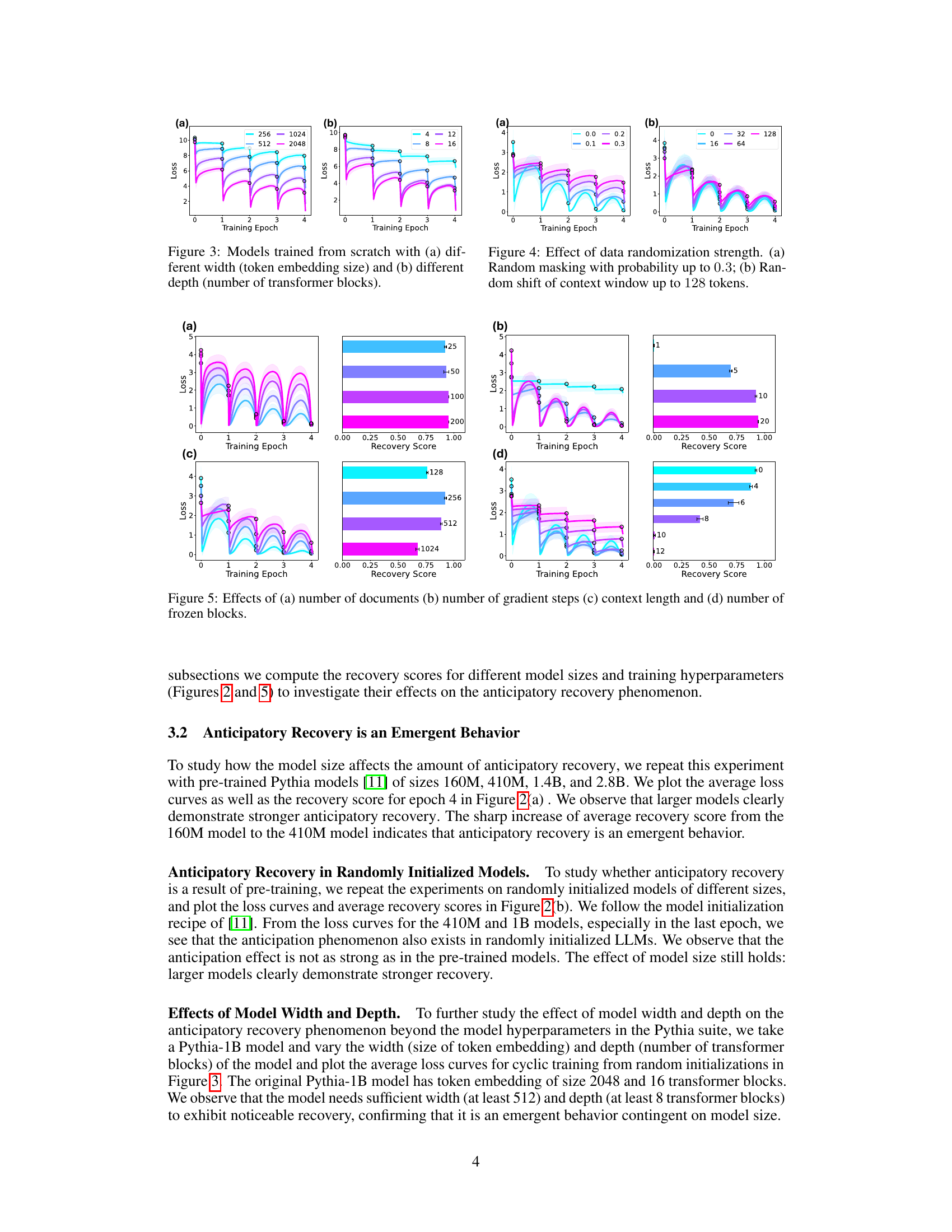
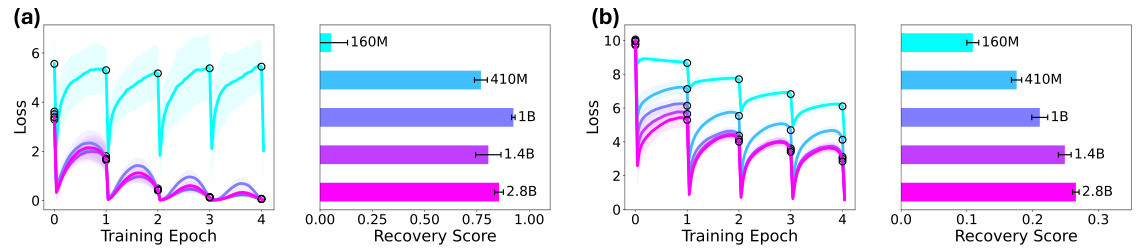
This figure shows the results of experiments on models trained from scratch, varying width (token embedding size) and depth (number of transformer blocks) to investigate the impact on anticipatory recovery. The plots display the training loss curves for cyclic training, showing how the model’s ability to recover from catastrophic forgetting is affected by changes in width and depth. It visually supports the paper’s claim that sufficient width and depth are necessary to observe the anticipatory recovery behavior.
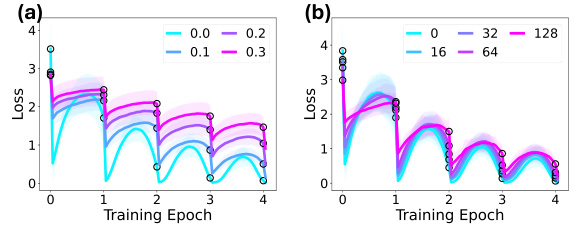
This figure shows the effect of adding different levels of noise to the training data on the anticipatory recovery phenomenon. (a) shows results when a portion of the tokens in each document are randomly masked with a probability ranging from 0 to 0.3. (b) shows the impact of randomly shifting the context window by 0 to 128 tokens. The plots illustrate that while anticipatory recovery is generally weaker with increased data variation, it still exists.
This figure shows the effect of model size on the anticipatory recovery phenomenon. The left side of the figure (a) displays shift-averaged loss curves for pre-trained models of different sizes (160M, 410M, 1B, and 2.8B parameters), illustrating how the anticipatory recovery becomes more pronounced as model size increases. The right side of (a) shows the recovery score for each model size, quantifying the strength of the anticipatory effect. Similarly, (b) repeats the experiment but using randomly initialized models instead of pre-trained models, demonstrating that the phenomenon is still present but less strong in randomly initialized models.

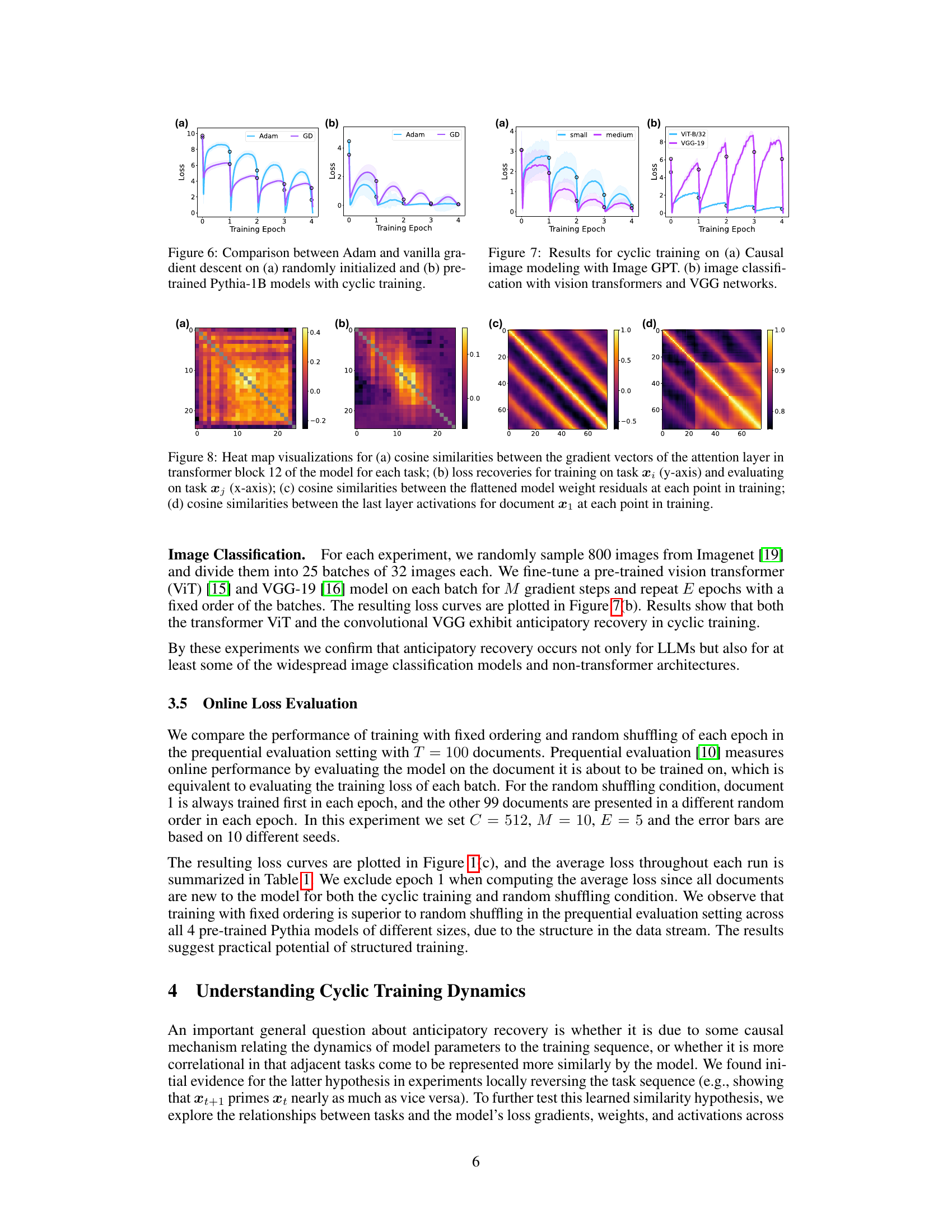
This figure compares the performance of Adam and vanilla gradient descent optimizers on two sets of Pythia-1B language models during cyclic training. The left panel shows results for models initialized randomly, while the right panel displays results for pre-trained models. Each panel shows loss curves over multiple training epochs. The results show that Adam, a more advanced optimizer, generally leads to better performance than vanilla gradient descent, particularly in the context of cyclic training and pre-trained models.
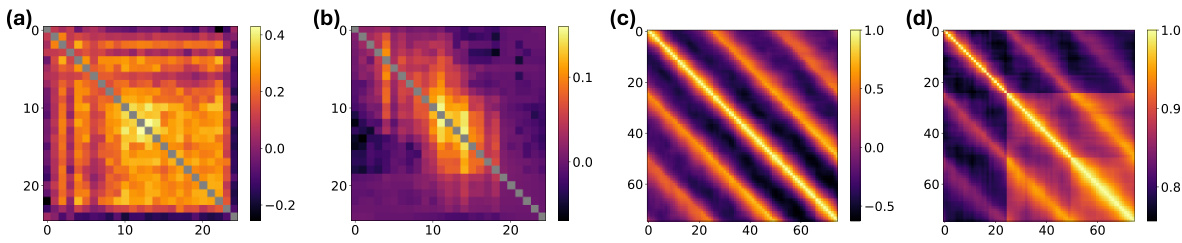
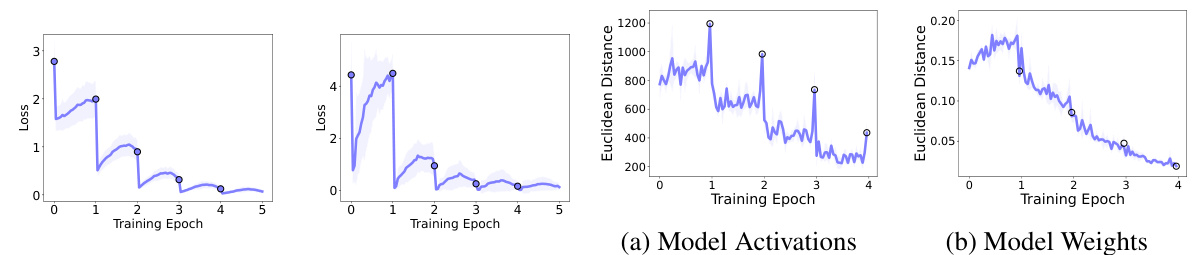
This figure visualizes several heatmaps to analyze the temporal structure of gradients, model weights, and activations during cyclic training. Specifically, it shows cosine similarities between: (a) gradients of the attention layer across different tasks, revealing high similarity between proximal documents; (b) pairwise loss recovery, illustrating the amount of loss recovery on one task when training on another, showcasing a cyclical pattern; (c) flattened model weight residuals, demonstrating a cyclical structure in the weight updates; and (d) last layer activations for a specific document, indicating increasing similarity in representations across epochs. These visualizations offer insights into the dynamics and relationships between different parts of the model during cyclic training, contributing to the understanding of anticipatory recovery.
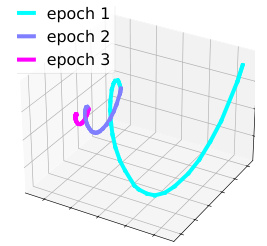
This figure visualizes the PCA embeddings of projected data points in a toy model throughout the training process. Each point represents a task (document) in the cyclic training sequence. The function fi(w) = yi w projects the model weights (w) onto the task-specific embedding space. The plot shows how these projected points evolve across multiple training epochs. Epoch 0 shows the initial state before training. The visualization helps to understand the dynamic of cyclic training and how tasks are represented in the model’s weight space.

This figure demonstrates the anticipatory recovery phenomenon observed in cyclic fine-tuning of LLMs. Panel (a) shows the loss curve for a single document across multiple training epochs, illustrating the initial loss decrease upon training, subsequent increase due to catastrophic forgetting, and a surprising decrease before the document is seen again. The inverted-U shape highlights the anticipatory recovery. Panel (b) presents the average loss curve across all documents, showcasing the same anticipatory recovery behavior across the entire sequence. Finally, panel (c) compares online performance between cyclic and random fine-tuning using prequential evaluation, showing the superior performance of cyclic training.
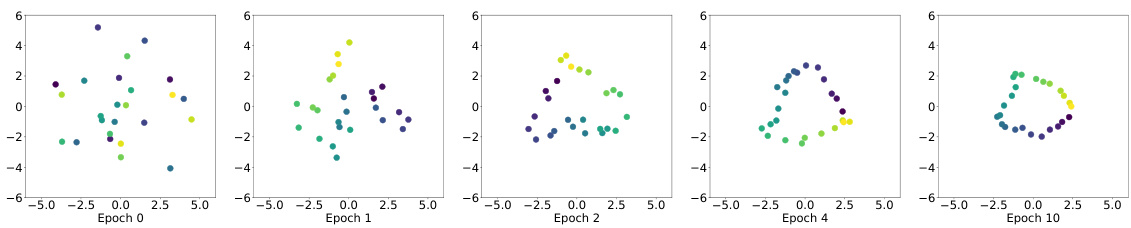
This figure visualizes the PCA embeddings of projected data points in a toy model throughout training. Each point represents a task, and its position reflects the task’s representation in the model’s embedding space. The color of each point indicates the training epoch. The figure demonstrates how the task representations evolve and organize into a circular pattern during cyclic training, illustrating the anticipatory recovery phenomenon observed in the paper.

This figure shows the effect of model size on the anticipatory recovery phenomenon. The left side of the figure displays shift-averaged loss curves for cyclic fine-tuning of pre-trained Pythia models (a) and randomly initialized models (b) of varying sizes (160M, 410M, 1B, 1.4B, and 2.8B parameters). The right side shows the corresponding recovery scores which quantify how much of the initial loss is recovered before seeing the document again. Larger models exhibit stronger anticipatory recovery, suggesting it is an emergent property of model scale.
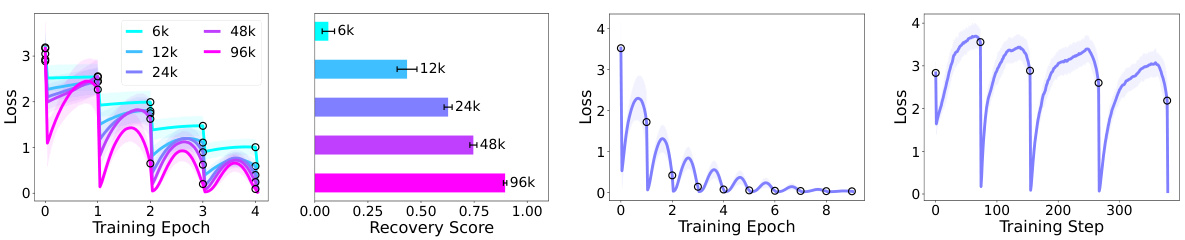
This figure shows the effect of the number of pre-training steps on the anticipatory recovery phenomenon. The left panel shows the loss curves for cyclic fine-tuning with pre-trained Pythia models that have undergone different numbers of pre-training steps (6k, 12k, 24k, 48k, and 96k). The right panel shows the average recovery score for epoch 4 as a function of the number of pre-training steps. The results indicate that models with more pre-training steps exhibit stronger anticipatory recovery, suggesting that the model’s ability to fit each task is crucial for the phenomenon.
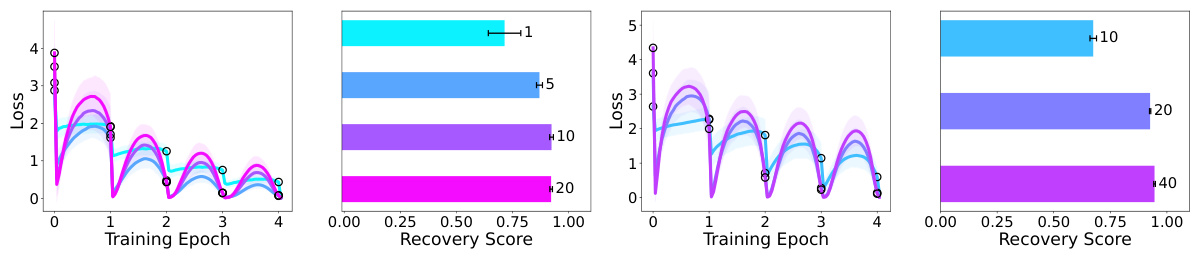
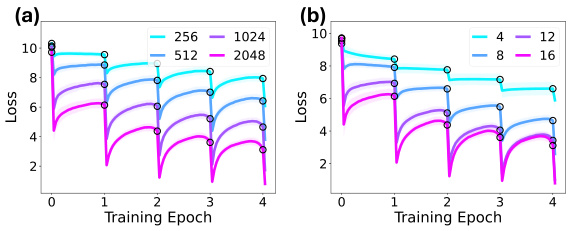
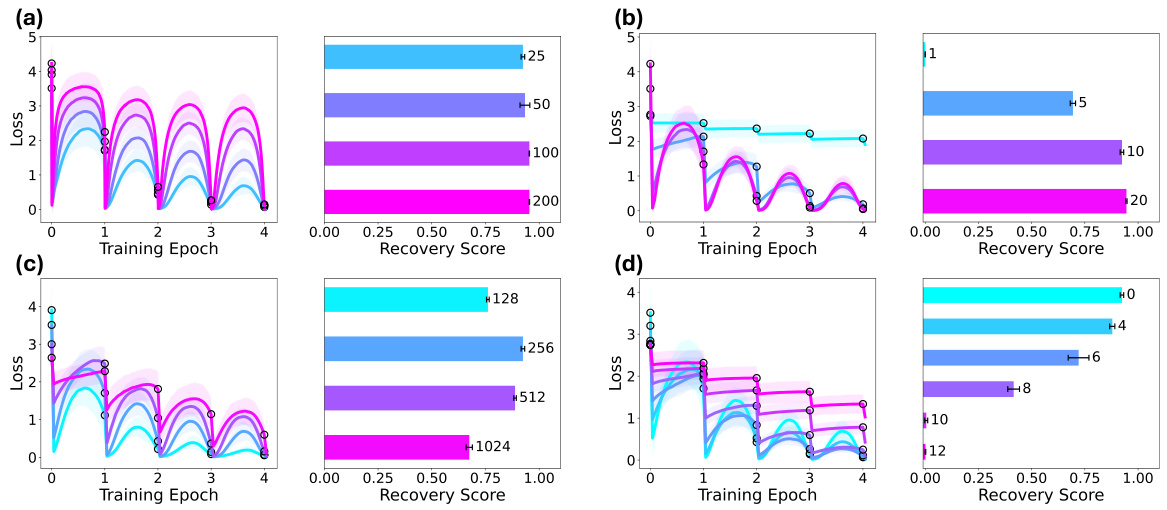
This figure shows the effects of various hyperparameters on the anticipatory recovery phenomenon. It demonstrates how the number of documents, gradient steps, context length, and frozen blocks impact the model’s ability to recover from catastrophic forgetting. The results showcase that certain parameters are more conducive to anticipatory recovery than others, highlighting the importance of model architecture and training setup in this phenomenon.
This figure shows the effect of model size on anticipatory recovery. The left panels show the average loss curves over multiple epochs for both pre-trained (a) and randomly initialized models (b). The right panels show the recovery score, a measure of how much the model recovers from forgetting before encountering a document again. The results indicate that anticipatory recovery is an emergent behavior that becomes more pronounced as model size increases.
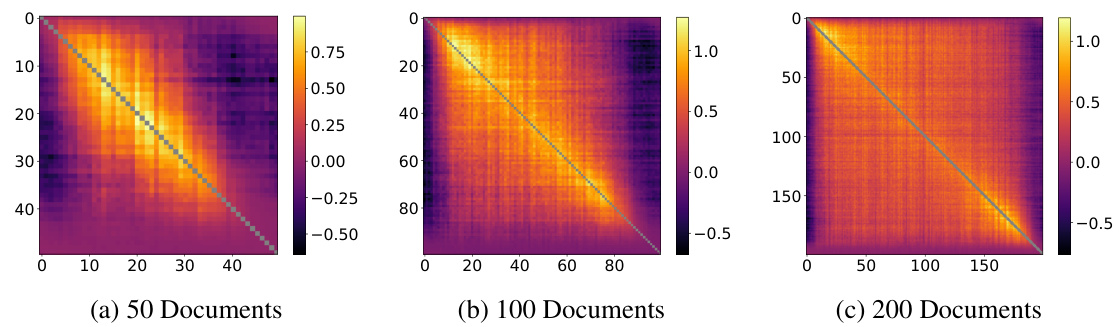
This figure shows the pairwise loss recovery matrices for document sequences of different lengths (50, 100, and 200). The heatmaps illustrate how much the model’s loss on a given document (xj) decreases after training on a nearby document (xi) during cyclic training. The diagonal represents the loss recovery when training and evaluating on the same document. The off-diagonal elements show the effect of training on one document and evaluating on a different document. The results indicate that the anticipatory recovery is not limited to short sequences and persists even with longer document sequences. The figures highlight a symmetrical pattern of recovery, suggesting the anticipatory behavior is not a strictly sequential phenomenon but involves relational learning between documents within the cyclical sequence.
Full paper#