↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current vision-language models (VLMs) struggle with higher-level 3D spatial reasoning tasks. Existing methods rely on extensive training data, which is difficult and expensive to obtain, limiting their generalizability. This creates a need for methods that can effectively enhance spatial reasoning capabilities in a zero-shot, training-free manner.
This paper introduces SpatialPIN, a novel framework that addresses this limitation. SpatialPIN leverages prompting and interactions with multiple 2D/3D foundation models to enhance VLM’s understanding of 3D scenes without requiring additional training. The results show significant improvements in spatial VQA performance and successful application to various downstream robotics tasks. The modular design makes SpatialPIN easily adaptable and extensible, making it a valuable contribution to the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models and robotics. It presents a novel framework for enhancing the spatial reasoning capabilities of these models, opening up new avenues for research in areas such as 3D scene understanding, robotic task planning, and spatial visual question answering. The zero-shot, training-free nature of the proposed approach is particularly significant, as it addresses the limitations of current data-driven methods and enables broader applicability of VLMs across various tasks. The modular design of the framework makes it readily adaptable and extensible, paving the way for future improvements and expansions.
Visual Insights#

This figure illustrates the SpatialPIN framework. It shows a modular pipeline that enhances Vision-Language Models (VLMs) spatial reasoning abilities by combining prompting techniques with 3D priors from multiple foundation models. The process is zero-shot and training-free, making it efficient and adaptable. The framework takes as input an image and a spatial task. Through a series of steps involving 2D scene understanding, 3D scene understanding, and solving with spatial reasoning, the framework arrives at an answer to the posed spatial visual question or task. The figure visually represents this process.

This table presents the results of qualitative Intra-image Object Relations Visual Question Answering (IaOR-VQA). It compares the accuracy of several vision-language models (VLMs) with and without the SpatialPIN framework. The models tested include GPT-4V, GPT-40, LLaVA-1.5, InstructBLIP, and SpatialVLM. The ‘w/o ours’ column represents the accuracy without SpatialPIN, while the ‘w ours’ column shows the accuracy after integrating SpatialPIN. The table highlights the significant improvement in accuracy achieved by using SpatialPIN across all models.
In-depth insights#
3D Prior Injection#
The concept of ‘3D Prior Injection’ in vision-language models (VLMs) focuses on enriching the models’ understanding of spatial relationships by integrating information from external 3D sources. This approach is particularly valuable for tasks requiring a deeper, more nuanced comprehension of 3D scenes than is typically achievable with 2D image data alone. By incorporating 3D priors, the VLM can leverage the explicit geometric and spatial information provided by 3D models, thereby enhancing its reasoning capabilities. This injection can take various forms, such as providing 3D object models, depth maps, or even full 3D scene reconstructions. The key benefit is that it enables zero-shot or few-shot learning, avoiding the extensive training data that’s typically required for training VLMs on complex 3D tasks. The success of this method hinges on the effective integration of the 3D priors with the VLM’s existing mechanisms for processing visual and linguistic information. However, challenges remain in efficiently and effectively incorporating the 3D information without compromising the VLM’s efficiency or robustness, as well as in selecting and representing the 3D priors in a format that is readily understandable by the VLM. Further research is needed to explore different types of 3D priors, integration techniques, and to fully assess the impact of 3D prior injection across various spatial reasoning tasks.
Prompt Engineering#
Prompt engineering plays a crucial role in effectively leveraging large language models (LLMs) for complex tasks. Careful crafting of prompts is essential for guiding the LLM to produce the desired output, particularly in the context of spatial reasoning, where nuanced instructions are crucial. The choice of prompt words, structure, and the inclusion of contextual information directly impact the model’s understanding and its ability to generate accurate and relevant responses. A well-designed prompting strategy can significantly boost performance. However, over-reliance on prompt engineering alone might have limitations, especially when dealing with complex, multi-faceted tasks which necessitates incorporating 3D priors and interactions with external tools. Effective prompting should be viewed as a complementary approach, rather than a standalone solution, and integrated into a broader system for optimal performance.
VQA Benchmark#
A robust VQA benchmark is crucial for evaluating and advancing the field of visual question answering. A good benchmark should include a diverse set of images and questions, reflecting the complexity and nuances of real-world scenarios. It must consider various question types (factual, logical, multi-step) and image characteristics (resolution, clarity, object diversity). A balanced dataset, avoiding bias towards specific image types or question styles, is essential to ensure fair and generalizable evaluations. Furthermore, the benchmark needs to be carefully annotated to reduce ambiguity and facilitate accurate performance assessment. Detailed metrics beyond simple accuracy, such as precision and recall at different levels of question difficulty, will offer more comprehensive insights into the capabilities and shortcomings of different models. Ultimately, a well-defined VQA benchmark acts as a catalyst for research innovation, guiding the development of more robust and intelligent VQA systems, and ultimately helping bridge the gap between visual perception and human-level comprehension.
Robotics Extension#
A hypothetical Robotics Extension section in a research paper would likely detail the application of the paper’s core methodology to robotic systems. This could involve using the described approach for tasks like visual question answering in robotic contexts, where a robot needs to understand and respond to questions about its environment. Further, it might explore motion planning and control, applying the framework to enable robots to autonomously navigate and execute complex actions. The results section would then present quantitative and qualitative evaluations of the robot’s performance on various tasks, possibly comparing it to existing approaches. Specific robotic platforms used and the datasets employed for evaluation would need to be clearly articulated. Finally, the discussion could address the limitations and challenges encountered when integrating the proposed method into the real world, such as robustness to noise and sensor inaccuracies, real-time performance considerations, and potential safety implications.
Zero-Shot Learning#
Zero-shot learning (ZSL) aims to enable models to recognize novel classes unseen during training, a significant challenge in machine learning. Its core idea is leveraging auxiliary information, such as semantic attributes or word embeddings, to bridge the gap between seen and unseen classes. This approach has important implications for practical applications because it reduces the reliance on large, labeled datasets which are often expensive and time-consuming to create. ZSL’s success depends heavily on the quality and relevance of the auxiliary information, with effective knowledge transfer being crucial. However, a major limitation is the domain adaptation problem, where the distribution of features in seen and unseen data differs significantly, leading to performance degradation. Addressing this domain shift, through methods like domain adaptation techniques or improved feature representations, is a key focus in current ZSL research. While promising, ZSL’s inherent challenge is to effectively learn transferable representations and robustly handle the significant discrepancy between training and testing data distributions. This is an active area of research with ongoing advancements exploring diverse techniques to achieve generalized zero-shot learning capabilities.
More visual insights#
More on figures
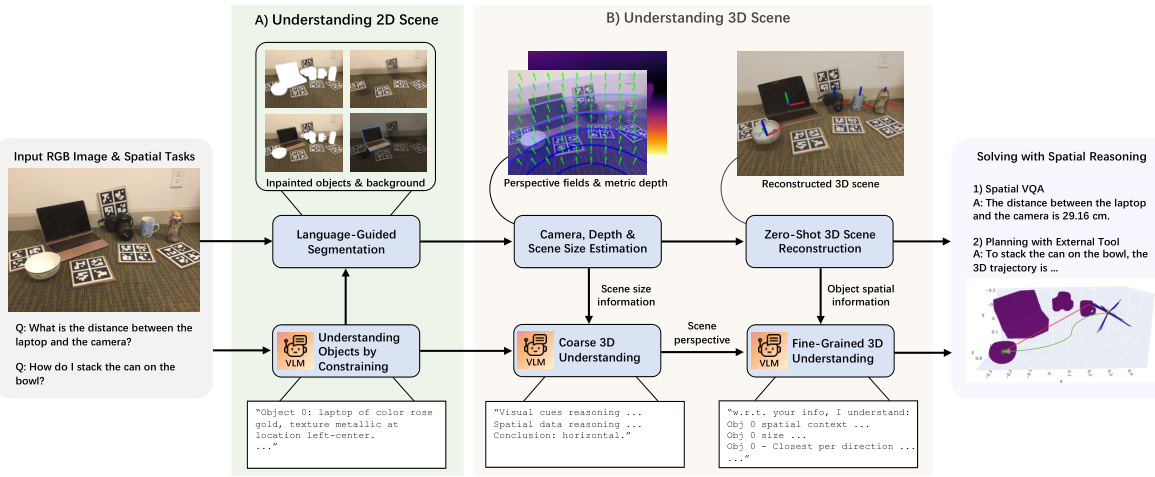
This figure illustrates the SpatialPIN framework, a modular pipeline designed for zero-shot deployment. It enhances the spatial understanding capabilities of Vision-Language Models (VLMs) through progressive interactions with scene decomposition, comprehension, and reconstruction. The framework consists of several modules, each easily replaceable with the latest improvements in its domain. The figure shows the flow of processing from input RGB images and spatial tasks through 2D and 3D scene understanding to the final solving of spatial reasoning tasks (Spatial VQA and robotic task planning). The Appendix contains details of the prompts used.

This figure shows the results of a partial 3D scene reconstruction method. (a) illustrates the method’s process, visualizing the scene’s reconstruction from different perspectives. (b) presents the reconstructed 3D scene, and (c) displays the original input image. The high alignment between the reconstructed scene and the input image demonstrates the effectiveness of the reconstruction method.

This figure presents a qualitative comparison of SpatialPIN and SpatialVLM’s performance on three spatial visual question answering (VQA) tasks: Intra-Image Object Relations VQA (IaOR-VQA), Intra-Image Angular Discrepancies VQA (IaAD-VQA), and Inter-Image Spatial Dynamics VQA (IrSD-VQA). For each task, example questions and answers from both models are shown. SpatialPIN demonstrates superior performance, providing more accurate and detailed answers that incorporate fine-grained 3D reasoning.

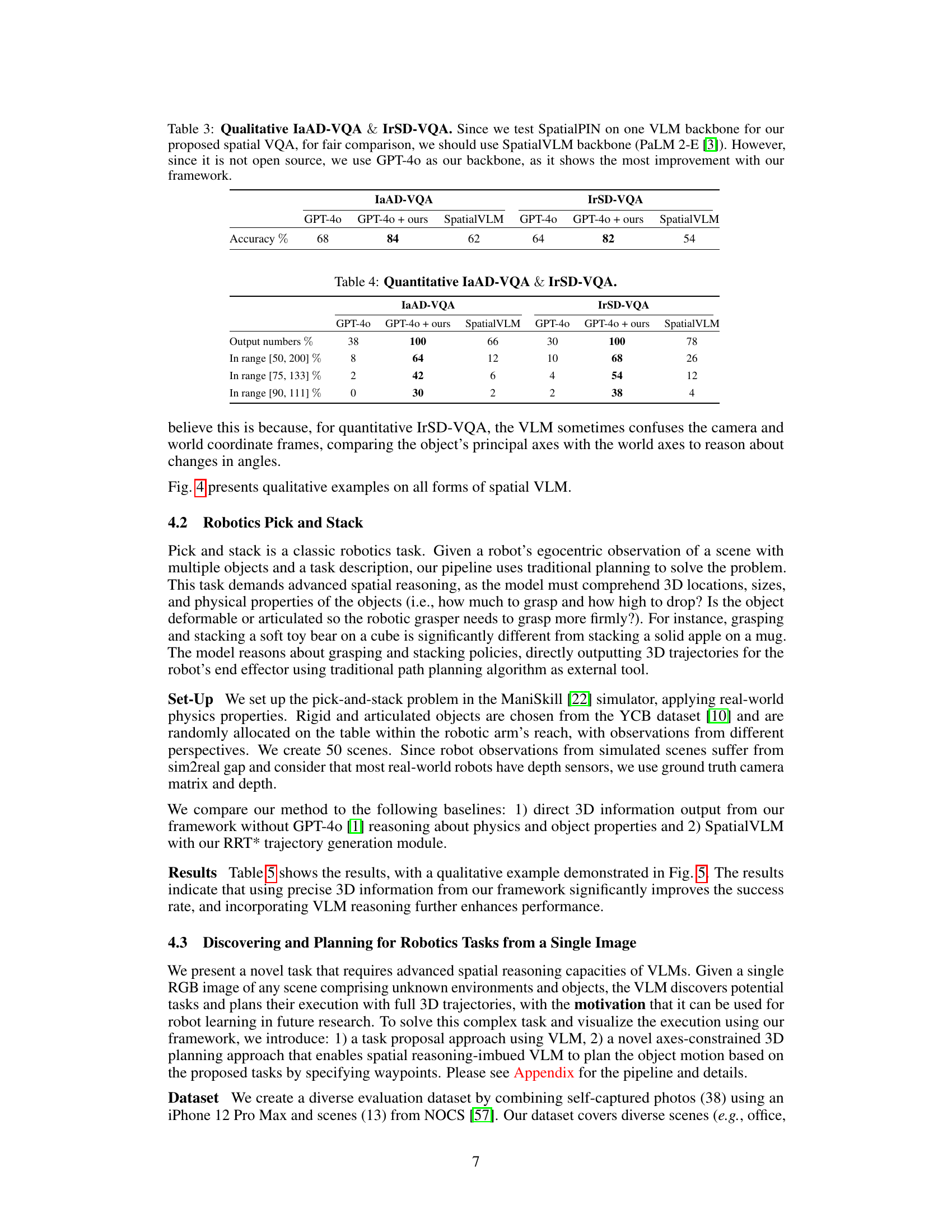
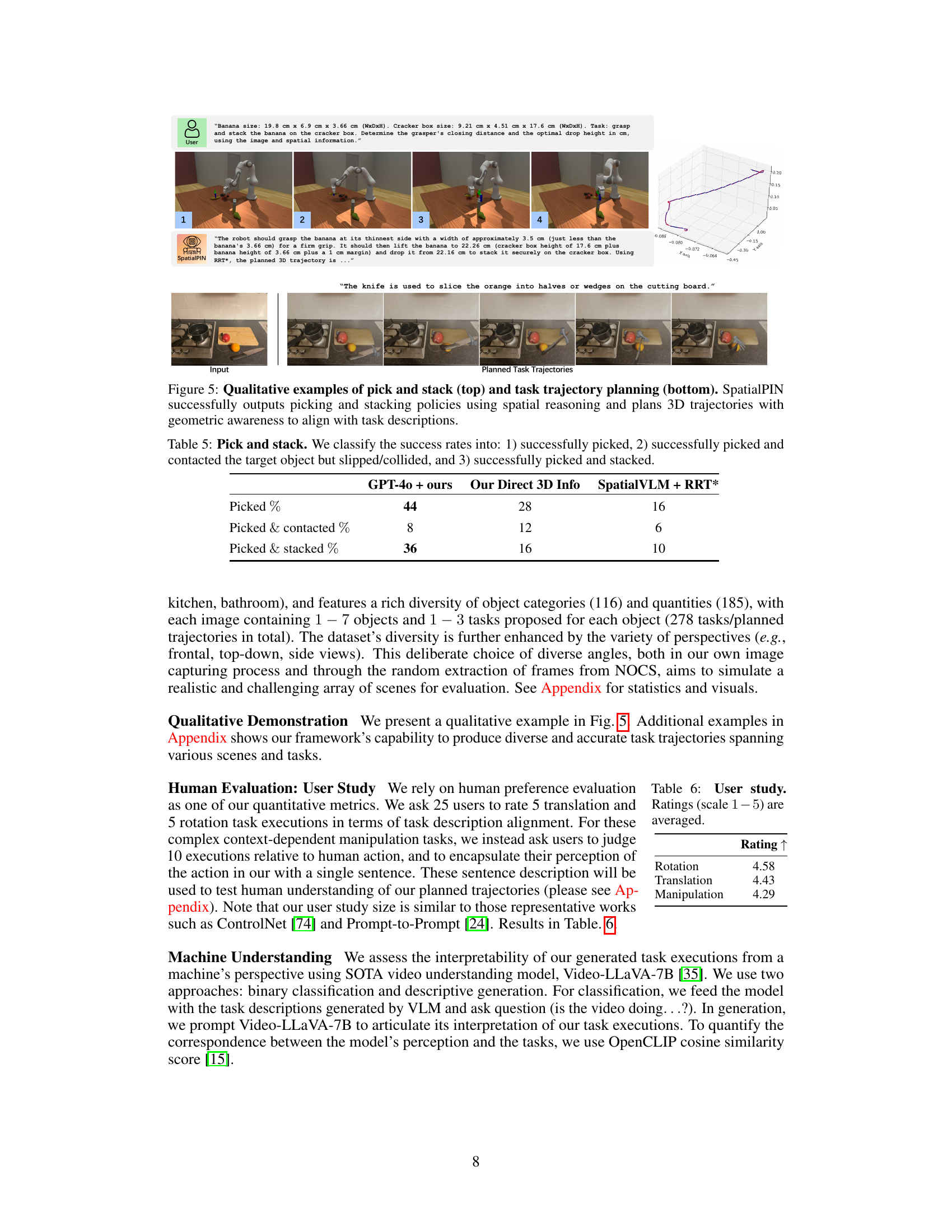
This figure shows two examples of SpatialPIN’s performance on pick-and-stack tasks. The top row shows images of a robot successfully picking up and stacking a banana on a cracker box, and the bottom row shows the successful task of slicing an orange with a knife on a cutting board. For each task, SpatialPIN not only provides the solution but also shows a 3D trajectory that the robot uses.

This figure shows example images used for the three types of spatial visual question answering (VQA) tasks explored in the paper: Intra-Image Object Relations VQA, Intra-Image Angular Discrepancies VQA, and Inter-Image Spatial Dynamics VQA. Each row represents a different type of VQA task, showcasing the diverse image scenes and object arrangements used to evaluate the model’s spatial reasoning capabilities.
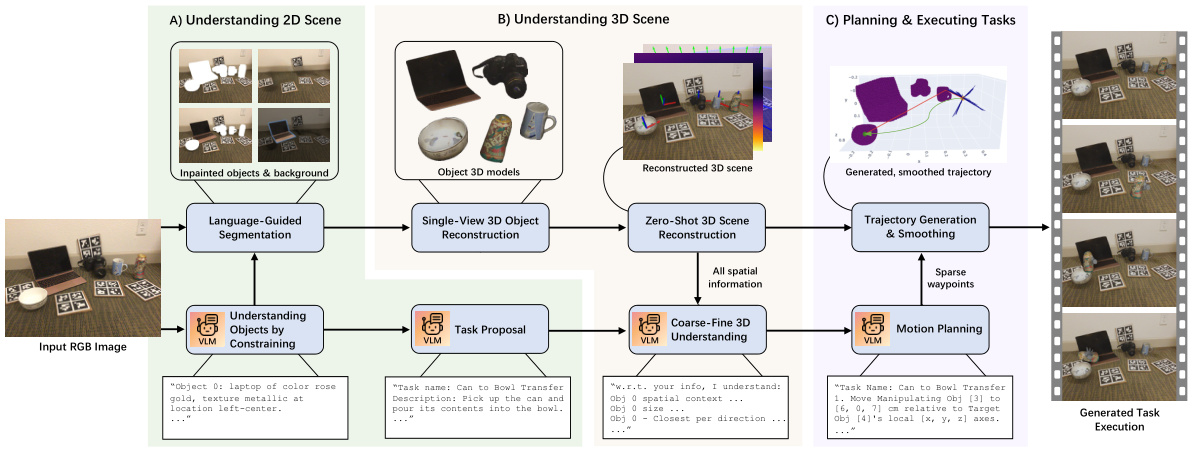
This figure illustrates the overall pipeline of SpatialPIN for robotics tasks. It starts with an input RGB image, which undergoes 2D scene understanding (inpainting, object identification). This is followed by 3D scene understanding (depth estimation, 3D object reconstruction), which provides the necessary information for task proposal and planning. The VLM proposes a task, and the system uses motion planning to generate a smoothed trajectory, culminating in the generated task execution.

This figure presents a statistical overview of the dataset used in the paper. It shows a pie chart breaking down the dataset’s scene composition (13 scenes from the NOCS dataset and 38 captured from various locations). Additionally, images illustrate the diversity of scenes, object types, quantities, and task variations within the dataset.

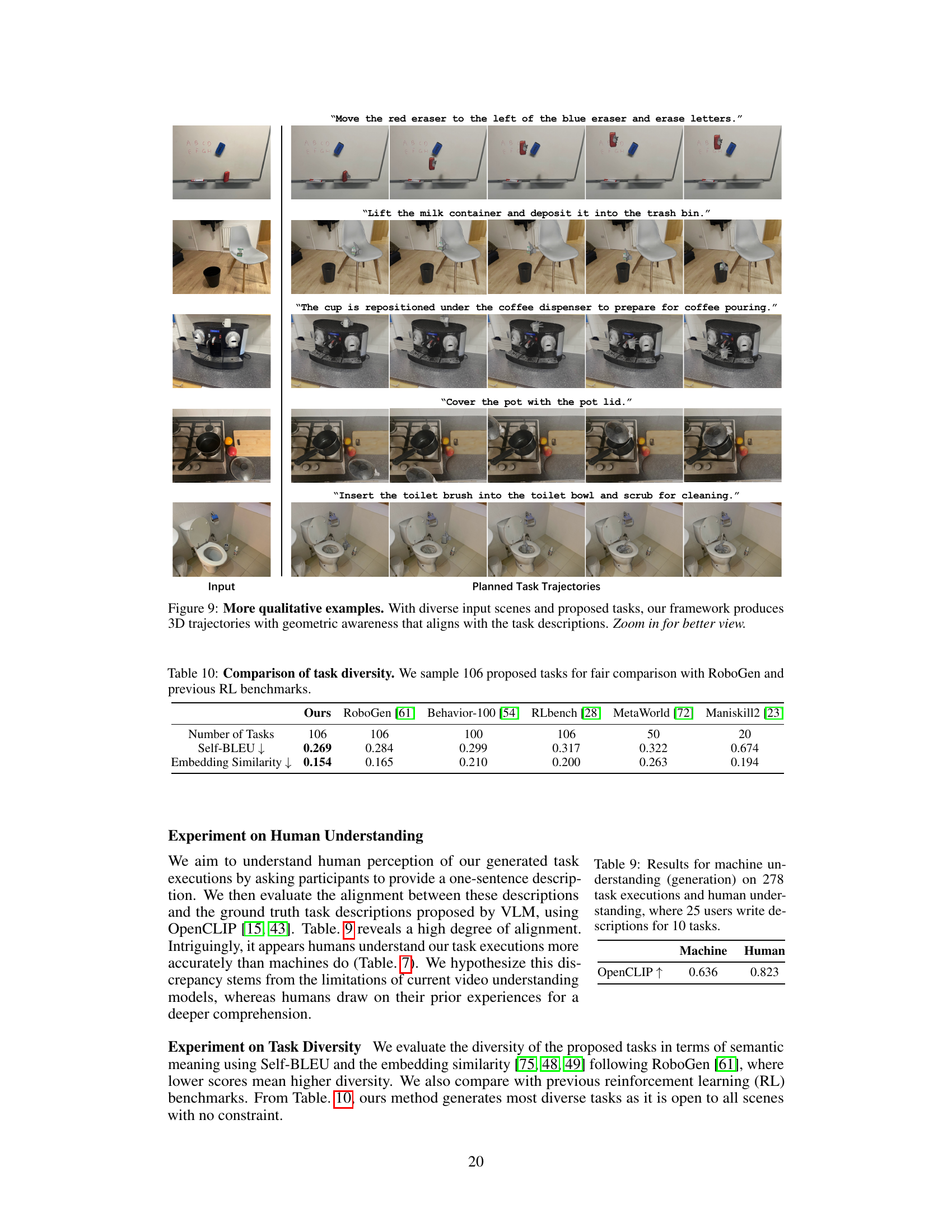
This figure shows five example scenarios where SpatialPIN successfully generates 3D trajectories for various tasks. Each row shows an input image, a task description, and the planned trajectory. The tasks involve manipulating objects in different scenes and viewpoints, demonstrating the framework’s ability to handle diverse and complex situations.
More on tables

This table presents the quantitative results for Intra-Image Object Relations Visual Question Answering (IaOR-VQA). It shows the accuracy of different Vision-Language Models (VLMs) in answering quantitative spatial questions, comparing their performance with and without the SpatialPIN framework. Accuracy is measured by how closely the VLM’s numerical answer matches the ground truth, considering different acceptable ranges of error (0.5x to 2.0x, 0.75x to 1.33x, and 0.9x to 1.11x). It also notes the percentage of times the VLMs produced a numerical answer instead of a descriptive one.

This table presents the quantitative results for two new Spatial Visual Question Answering (VQA) tasks: Intra-Image Angular Discrepancies VQA (IaAD-VQA) and Inter-Image Spatial Dynamics VQA (IrSD-VQA). It shows the accuracy of different Vision-Language Models (VLMs) with and without the SpatialPIN framework. The accuracy is measured by the percentage of answers that fall within specific ranges (0.5x to 2.0x, 0.75x to 1.33x, and 0.9x to 1.11x) of the ground truth value. The ‘Output numbers %’ row indicates the percentage of times the VLMs produced numerical answers instead of vague descriptions. The table compares the performance of GPT-40 and GPT-40 enhanced with SpatialPIN against SpatialVLM, highlighting the improvement achieved by SpatialPIN.

This table presents the success rates of a pick-and-stack robotics task, categorized into three levels: successfully picked, successfully picked and contacted but failed to stack, and successfully picked and stacked. The results are compared across three different methods: GPT-40 + ours (the proposed method), using only direct 3D information, and SpatialVLM + RRT*. The table quantifies the effectiveness of different approaches for robotic manipulation tasks.
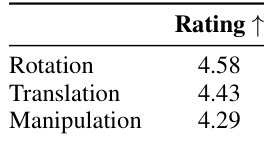
This table presents the results of a user study evaluating the quality of generated task executions in terms of task description alignment. Specifically, 25 users rated 5 translation and 5 rotation task executions on a scale of 1 to 5, with higher scores indicating better alignment. The table provides the average rating for each type of task (Rotation, Translation, Manipulation).

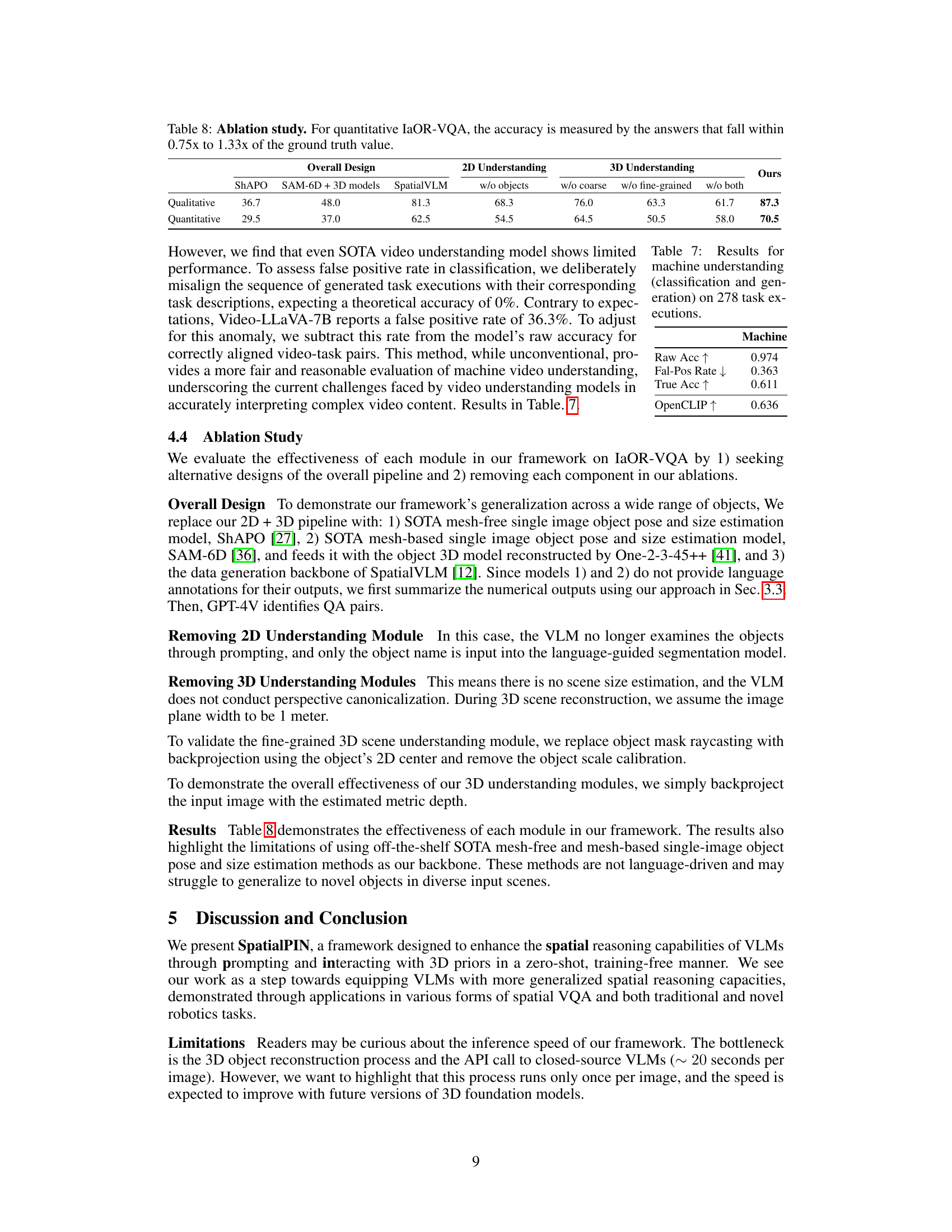
This table presents the results of an ablation study conducted to evaluate the effectiveness of each module within the SpatialPIN framework. The study assesses the impact of removing different modules (2D understanding, coarse 3D understanding, fine-grained 3D understanding) on the performance of the system, both qualitatively and quantitatively on IaOR-VQA tasks. The baseline results are compared against the performance of the complete SpatialPIN framework to highlight the contribution of each module. Quantitative results are specifically calculated based on the accuracy of the answers falling within a range (0.75x to 1.33x) of the ground truth.
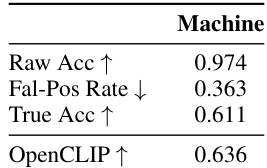
This table presents the results of evaluating the machine’s understanding of the generated task executions. It shows the raw accuracy, false positive rate, true accuracy (raw accuracy minus false positive rate), and OpenCLIP similarity score. The OpenCLIP score measures the alignment between the machine’s perception and the human-provided ground truth descriptions of the tasks.

This table presents the results of evaluating the machine’s understanding of generated task executions. It compares the raw accuracy against a false positive rate to arrive at a true accuracy score. OpenCLIP scores are also provided, offering an additional metric for understanding the results.

This table compares the diversity of tasks generated by the proposed SpatialPIN framework with those from other existing methods such as RoboGen, Behavior-100, RLBench, MetaWorld, and Maniskill2. Diversity is measured using Self-BLEU and embedding similarity, where lower scores indicate higher diversity. The table shows that SpatialPIN generates a more diverse set of tasks compared to the other methods.

This table presents the results of evaluating the machine’s understanding of the generated task executions. It compares the performance of a video understanding model (Video-LLaVA-7B) in classifying and generating descriptions of task executions. The ‘Raw Acc’ column shows the model’s accuracy, while ‘Fal-Pos Rate’ is the false positive rate. The ‘True Acc’ column is obtained after adjusting for the false positive rate to provide a more fair evaluation.
Full paper#