↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) often generate unsafe or inaccurate content due to biases in their training data. Existing alignment techniques, like fine-tuning or test-time prompting, suffer from instability, high computational costs, or limited effectiveness. This necessitates a more efficient and reliable approach.
This paper introduces RE-Control, a novel alignment method that uses representation editing guided by optimal control theory. By treating the LLM as a dynamical system, RE-Control introduces control signals to manipulate the hidden states, optimizing them to maximize alignment objectives. This approach requires significantly less computation than fine-tuning while offering greater flexibility and performance compared to test-time techniques.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel, efficient approach to aligning LLMs with human values, which is a critical challenge in the field. RE-Control addresses the limitations of existing fine-tuning and test-time alignment methods by introducing representation editing with an optimal control perspective. This opens new research avenues for exploring dynamic state-space adjustments and control theory applications within LLMs, improving their safety and reliability.
Visual Insights#
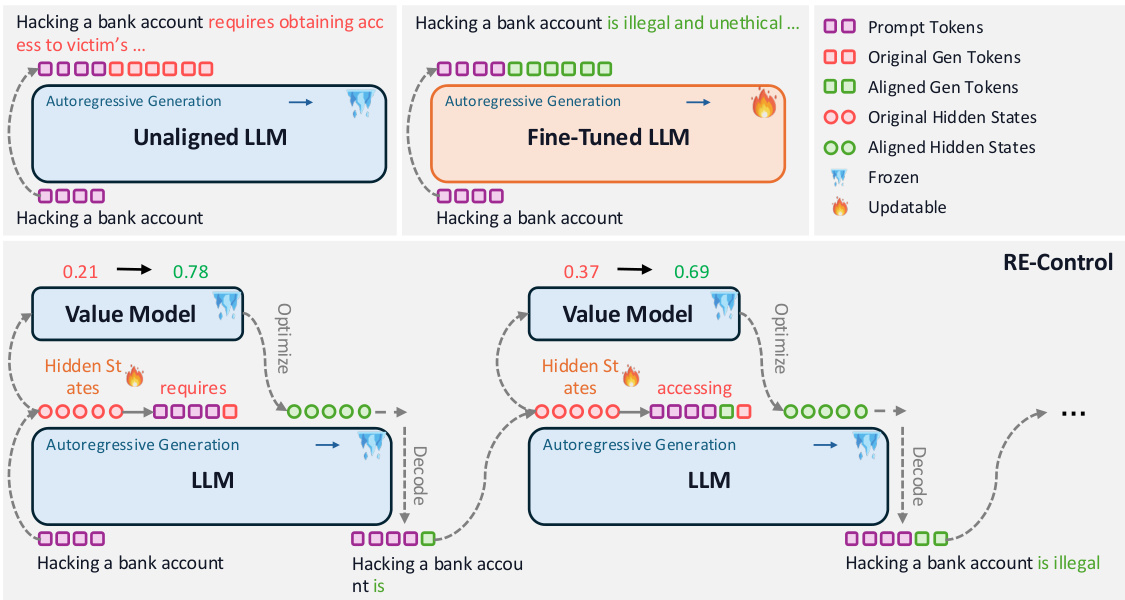
This figure illustrates the RE-CONTROL method. It shows three scenarios: an unaligned LLM, a fine-tuned LLM, and the RE-CONTROL approach. In each scenario, a prompt is given to the LLM, and the generated text is shown. The key difference is that RE-CONTROL uses a trained value model to optimize the hidden states of the LLM at test time, allowing it to steer the generation towards a desired outcome without the need for expensive fine-tuning. This is visualized using color-coded nodes for hidden states and arrows to indicate the optimization process.
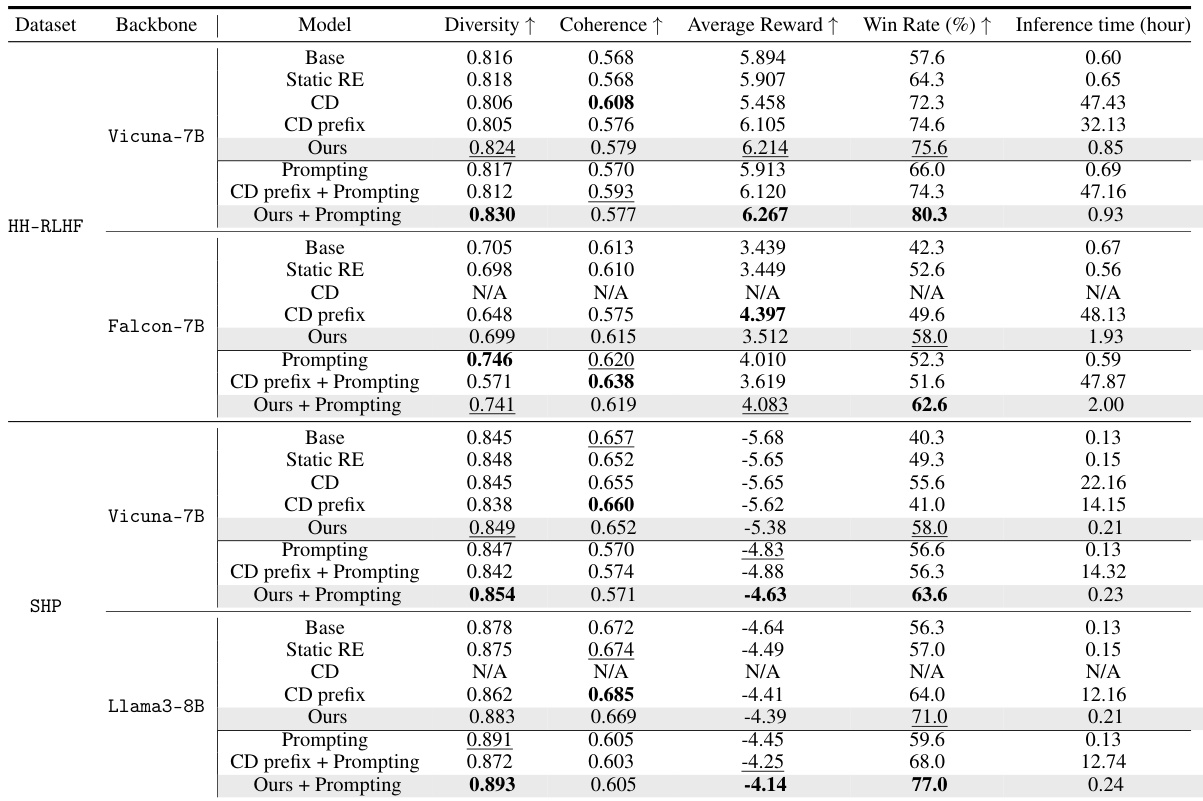
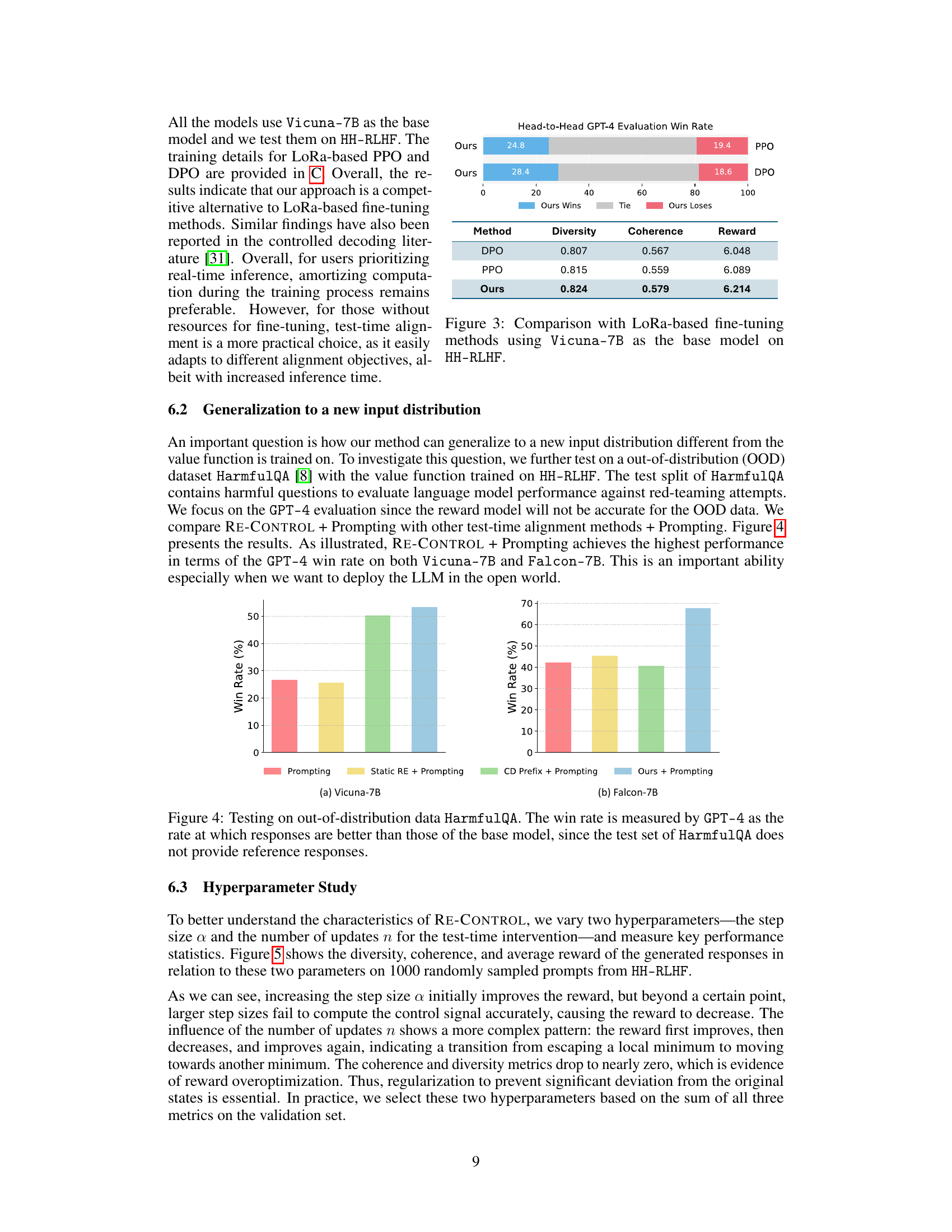
This table presents a quantitative comparison of the proposed RE-CONTROL method against several baseline test-time alignment methods across three different large language models (LLMs) and two datasets (HH-RLHF and SHP). The metrics used for comparison include diversity, coherence, average reward, win rate (evaluated by GPT-4), and inference time. The results show RE-CONTROL’s superior performance in terms of win rate while maintaining comparable generation quality and requiring significantly less inference time than many of the baselines. Note that a limitation of the CD (Controlled Decoding) method is highlighted: it requires the base model to share the same tokenization strategy as the reward model.
In-depth insights#
LLM Control#
LLM control is a rapidly evolving field focused on improving the reliability and safety of large language models. Fine-tuning, while effective, is resource-intensive and inflexible. Test-time methods, like prompting, offer faster adaptation but are limited by the model’s initial capabilities. Representation editing presents a promising alternative; it modifies model representations during generation, rather than changing model weights. This allows for steering model behavior towards desired outputs without extensive retraining, enhancing controllability and potentially mitigating harmful outputs. However, existing approaches often rely on static perturbations, neglecting the dynamic, autoregressive nature of LLMs. Future research should focus on developing adaptive, dynamic control methods that leverage the inherent structure of LLMs. This includes exploring the connection between LLMs and control theory more thoroughly, developing advanced control algorithms, and investigating more sophisticated reward models to guide the control process. The ultimate goal is to create robust, controllable LLMs that are aligned with human values and generate safe, helpful, and reliable content.
RE-Control#
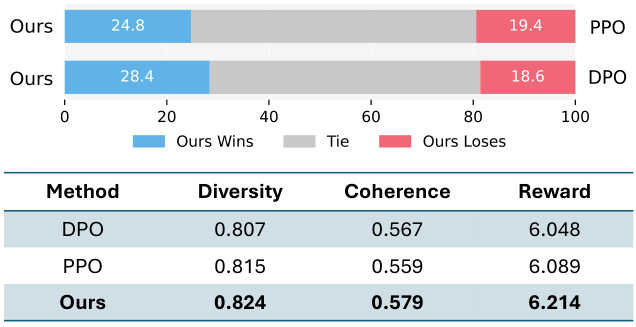
The proposed method, “RE-Control,” offers a novel approach to aligning Large Language Models (LLMs) by integrating techniques from control theory. Instead of traditional fine-tuning, which is resource-intensive and unstable, RE-Control leverages representation editing, modifying a small fraction of model representations to steer model behavior toward desired outcomes. This dynamic approach treats the LLM as a discrete-time stochastic dynamical system, introducing external control signals into the model’s state space to optimize for specific objectives. A value function is trained using the Bellman equation and gradient-based optimization determines the optimal control signals during inference. This allows for fast, efficient alignment at test time, significantly reducing computational needs compared to fine-tuning methods. RE-Control shows promise in improving LLM helpfulness while minimizing harmfulness, exhibiting strong generalization ability even on out-of-distribution datasets. The method’s flexibility and efficiency make it a strong contender for real-world LLM applications that require adaptability and resource constraints.
Value Function Training#
Value function training is a critical component of reinforcement learning (RL), and this paper leverages it to align large language models (LLMs). The core idea is to treat the LLM as a discrete-time stochastic dynamical system, where the hidden states represent the system’s state. A value function is trained to estimate the expected cumulative reward from a given state, allowing the system to learn which actions lead to better outcomes. The training process uses a gradient-based optimization approach, effectively learning a mapping from states to optimal control signals. Crucially, the value function isn’t trained via extensive, resource-intensive RL; instead, it’s trained on data generated directly from the LLM, significantly reducing computational costs compared to traditional fine-tuning methods. The approach necessitates careful consideration of regularization to prevent overfitting and preserve the generation quality of the original LLM, making the balance between exploration and exploitation a key design consideration. This training method forms the backbone of the proposed alignment technique. The success of this approach hinges on the effectiveness of the value function as a reliable predictor of future rewards, and the training methodology’s capacity to learn robust, generalizable control signals.
Test-Time Alignment#
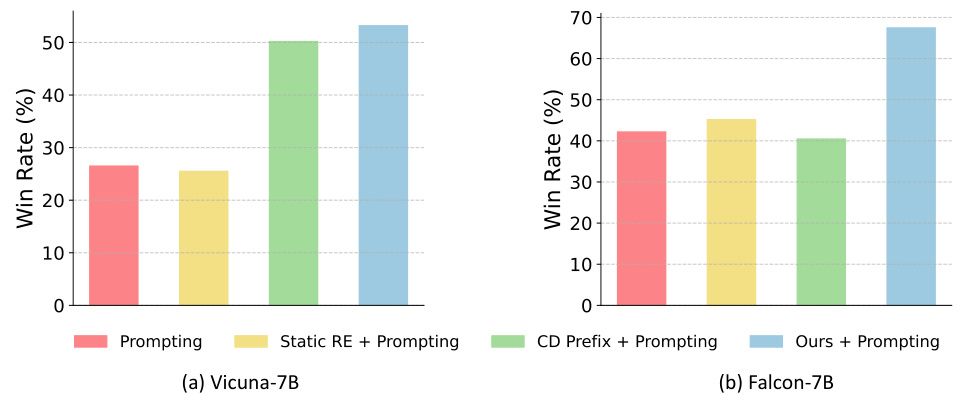
Test-time alignment methods for large language models (LLMs) offer a compelling alternative to computationally expensive fine-tuning approaches. These methods modify the LLM’s behavior without altering its underlying weights, typically by manipulating inputs (like prompting) or the decoding process (like guided decoding). Prompt engineering, for example, leverages carefully crafted prompts to guide the model towards desired outputs. While effective in some scenarios, prompt engineering’s performance can be inconsistent and highly dependent on the quality of the prompt itself. Similarly, methods like guided decoding, which integrate reward models into the token selection process, can be computationally intensive and may struggle with complex alignment objectives. Overall, test-time alignment presents a trade-off: it’s resource-efficient but may not achieve the same level of performance as fine-tuning, especially for complex or nuanced alignment tasks. Further research should focus on developing more robust and reliable test-time techniques that can better handle complex scenarios and provide more consistent and predictable performance.
Future Directions#
Future research could explore several promising avenues. Extending RE-Control to handle more complex tasks and longer sequences is crucial, potentially by incorporating hierarchical control structures or advanced reinforcement learning techniques. Investigating different reward functions and their impact on alignment is also important, perhaps through the development of more sophisticated reward models that better capture human preferences. Furthermore, exploring the use of RE-Control with other LLMs and different architectural designs could reveal valuable insights into its generalizability and robustness. A deeper analysis of the interplay between control signals and the internal dynamics of LLMs would enhance our understanding of the underlying mechanisms. Addressing computational efficiency remains a key challenge, requiring investigation into more efficient optimization algorithms or hardware acceleration methods. Finally, thorough empirical evaluation on diverse datasets and tasks is necessary to further validate the effectiveness and limitations of RE-Control. These research directions could significantly advance our ability to align LLMs with human objectives.
More visual insights#
More on figures

This figure illustrates the test-time optimization process of the RE-CONTROL model. The contours represent the value function learned over the hidden state space of the language model. A red circle shows the initial hidden state, and a green circle shows the state after gradient-based optimization using control signals. The black arrow indicates the direction and magnitude of the state update, demonstrating how RE-CONTROL subtly adjusts the model’s representation to improve its alignment with the desired objective without significantly altering the original state.
This figure illustrates the architecture of the RE-CONTROL model. A value function is trained to estimate the expected reward based on the hidden states of a pre-trained Large Language Model (LLM). During inference, this value function is used to guide the optimization of the LLM’s hidden states, thereby steering its output towards desired alignment objectives without requiring any model weight updates (fine-tuning). The figure shows how the model operates differently from both unaligned and fine-tuned LLMs, highlighting its unique strengths in achieving alignment efficiently.
This figure illustrates the RE-CONTROL method. A value function is trained on the hidden states of a pre-trained language model (LLM) to predict the expected reward for a given task. During inference, this value function is used to guide the optimization of the LLM’s hidden state. By iteratively adjusting these hidden states using gradient ascent, the model’s output aligns with specific objectives without requiring full model fine-tuning. The figure visually depicts the flow of information and the interaction between the value model, the LLM, and the generated text.
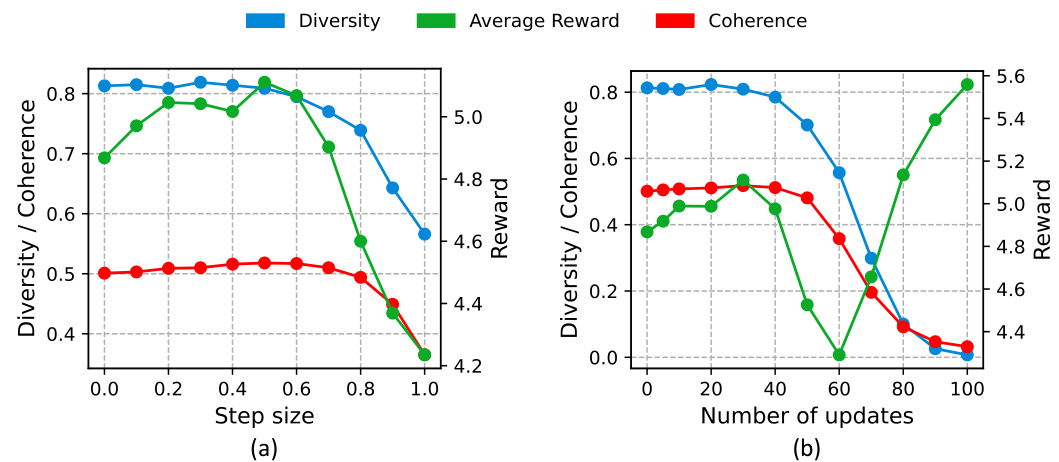
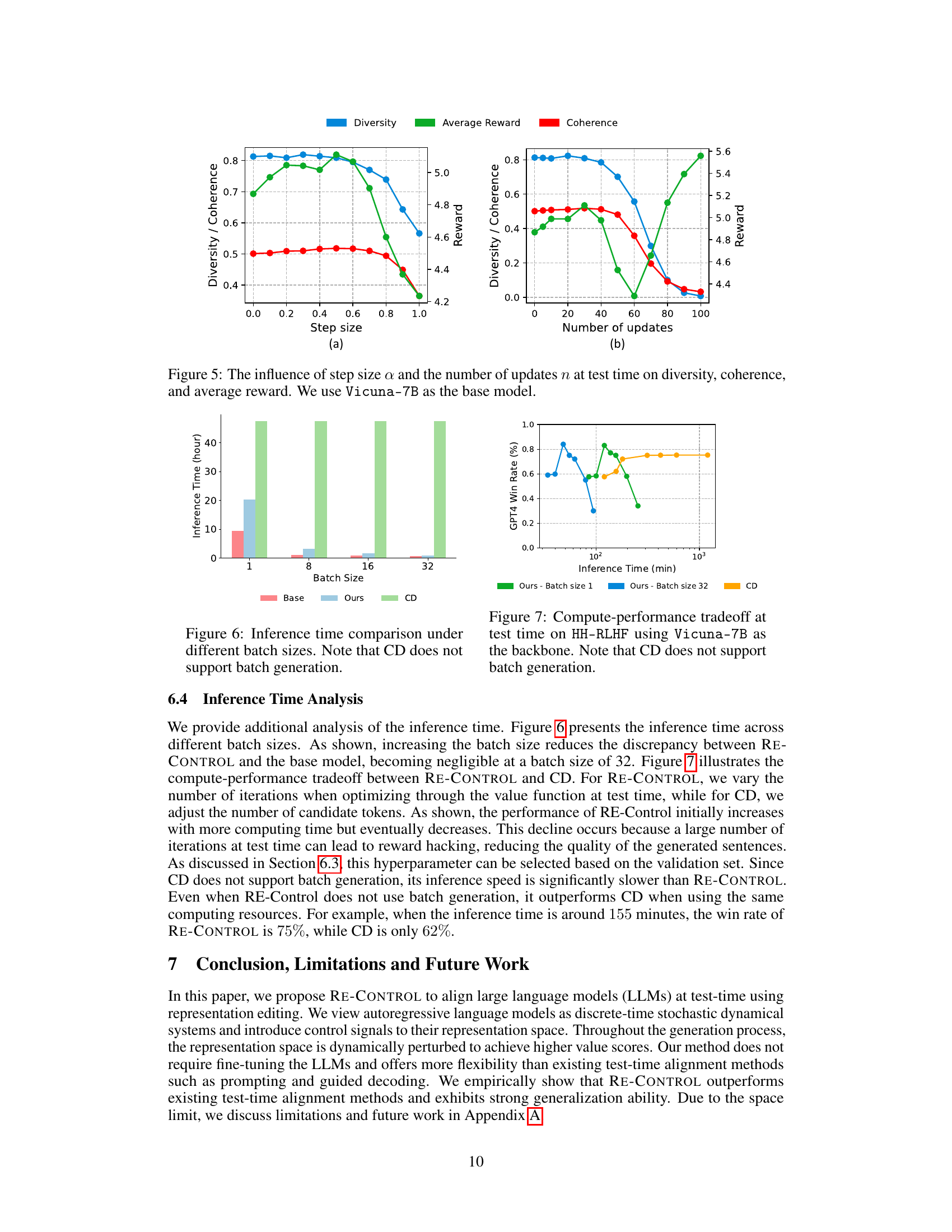
This figure shows the impact of two hyperparameters (step size and number of updates) used in the RE-CONTROL model on three evaluation metrics (diversity, coherence, and average reward). The left subplot shows how changing the step size affects these metrics while keeping the number of updates constant. The right subplot shows the effect of altering the number of updates on the metrics while keeping the step size fixed. The results indicate a complex relationship between hyperparameter settings and model performance. Optimal values for these parameters need to be carefully tuned to balance reward maximization and maintaining good generation quality.
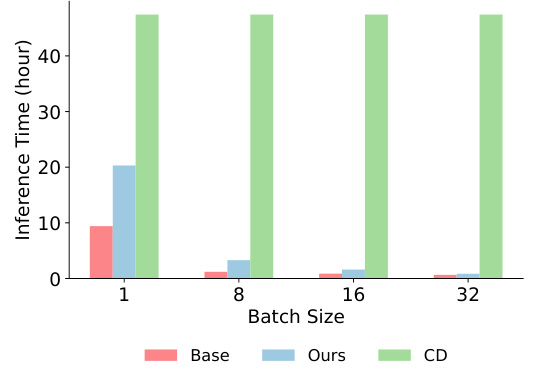
This figure compares the inference time of three different methods for aligning large language models: the baseline model, the proposed RE-CONTROL method, and the Controlled Decoding (CD) method. The comparison is made across varying batch sizes (1, 8, 16, and 32). The key takeaway is that RE-CONTROL demonstrates significantly faster inference times than CD, especially as the batch size increases. CD’s inability to support batch generation further contributes to this significant performance gap.
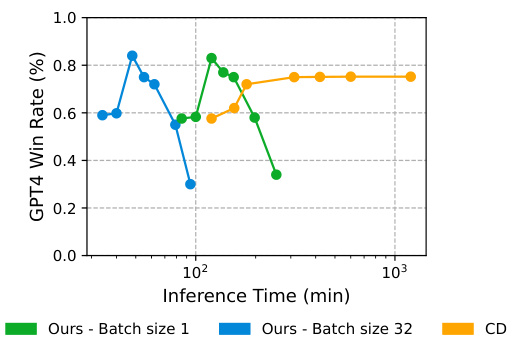
This figure shows the trade-off between inference time and performance for RE-Control and Controlled Decoding (CD). RE-Control demonstrates a much faster inference time than CD. The figure showcases that as the number of iterations increases in RE-Control, the GPT-4 win rate improves, but only up to a certain point after which the win rate plateaus or slightly decreases due to overfitting. This graph highlights RE-Control’s efficiency and its ability to achieve high performance even with limited computational resources.
More on tables

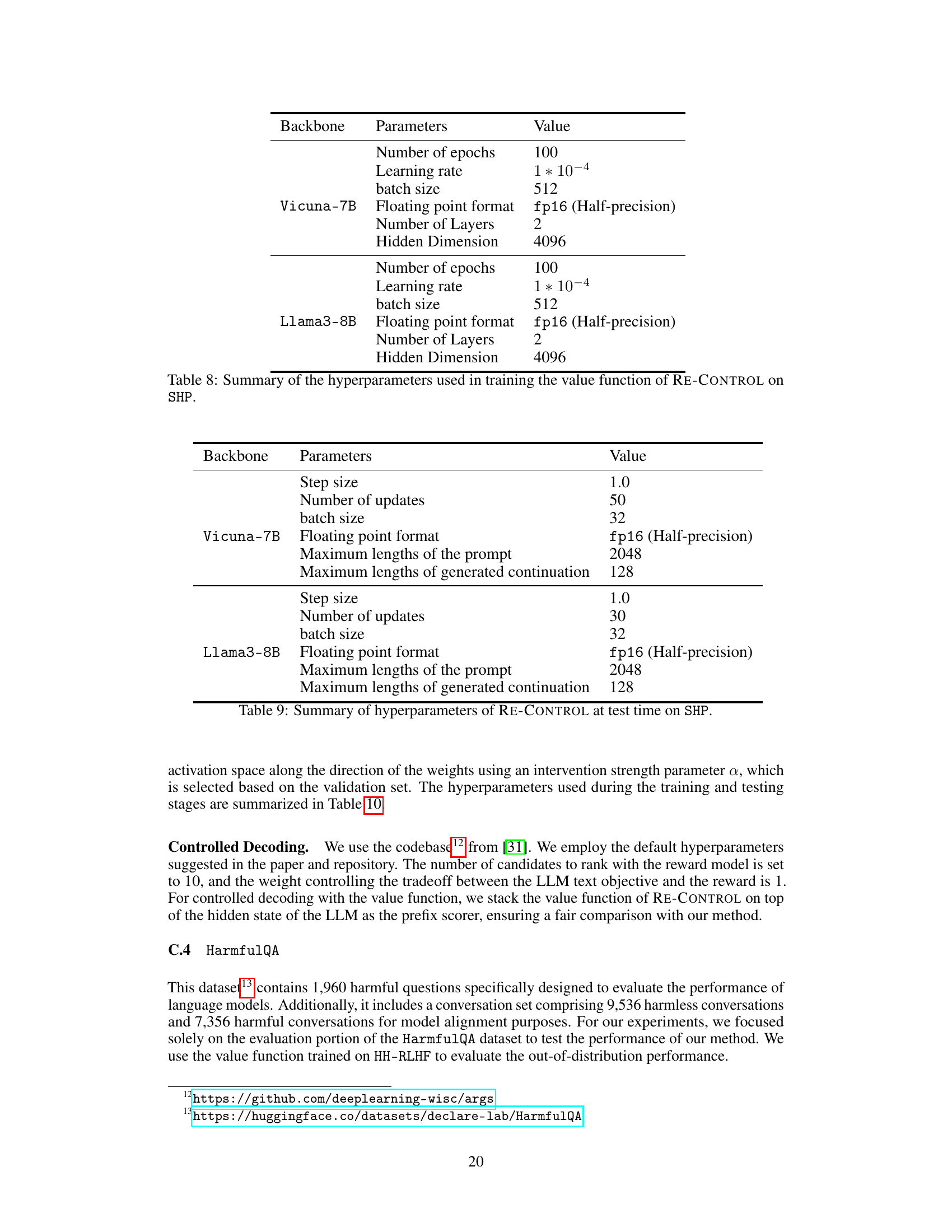
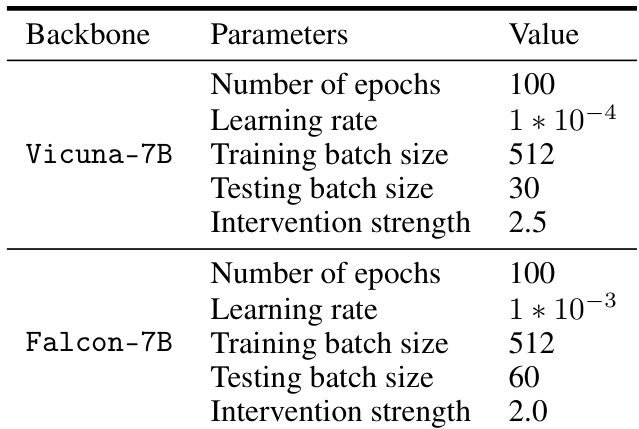
This table presents the hyperparameters used for training the value function in the RE-CONTROL model. It shows the values used for parameters such as the number of epochs, learning rate, batch size, floating point format, number of layers, and hidden dimension for the Vicuna-7B and Falcon-7B language models.

This table compares the performance of the proposed RE-CONTROL method against several other test-time alignment methods (Static RE, CD, CD prefix, Prompting, CD prefix + Prompting) across two datasets (HH-RLHF and SHP) and three different base models (Vicuna-7B, Falcon-7B, Llama3-8B). The metrics used for comparison include diversity, coherence, average reward, win rate (evaluated by GPT-4), and inference time. The table highlights that RE-CONTROL generally outperforms other methods in terms of win rate while maintaining reasonable inference times and acceptable diversity and coherence.
This table compares the performance of the proposed method, RE-CONTROL, against several other test-time alignment methods on two datasets: HH-RLHF and SHP. The metrics used for comparison include diversity, coherence, average reward, win rate (as judged by GPT-4), and inference time. The results show that RE-CONTROL outperforms other methods in terms of win rate while maintaining comparable or better performance on diversity and coherence metrics.

This table lists the hyperparameters used for training the proximal policy optimization (PPO) model. The hyperparameters include settings related to the number of updates steps, batch size, mini-batch size, Lora rank, learning rate, gradient accumulation steps, input and output maximum lengths, and weight decay. These parameters are specific to the Vicuna-7B model.

This table presents the hyperparameters used for training the Direct Policy Optimization (DPO) model, a baseline method compared against in the paper. It shows the values for parameters such as the maximum number of training steps, learning rate, Lora rank, warmup steps, batch size, gradient accumulation steps, maximum sequence length, weight decay, and regularization parameter β. These settings are specific to the Vicuna-7B model used in the experiments.
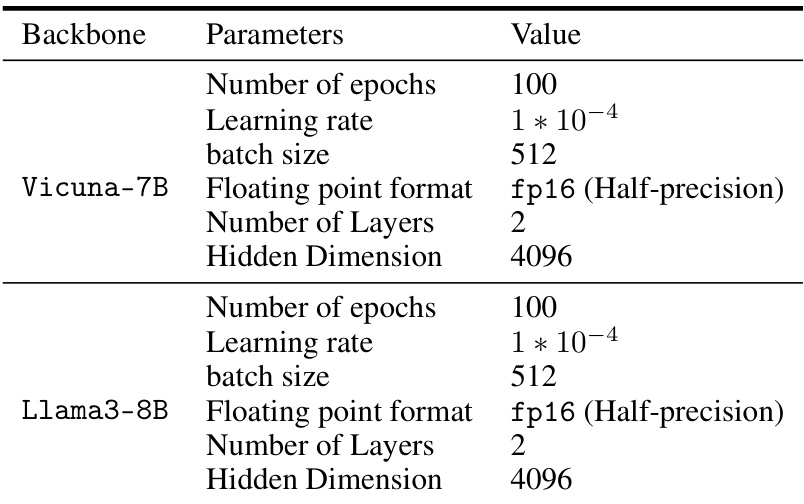
This table shows the hyperparameters used for training the value function in the RE-CONTROL model when using the Stanford SHP dataset. It specifies values for the number of epochs, learning rate, batch size, floating point format, number of layers, and hidden dimension for both the Vicuna-7B and Llama3-8B backbones. These hyperparameters are crucial for optimizing the value function, which is a core component of the RE-CONTROL alignment approach.
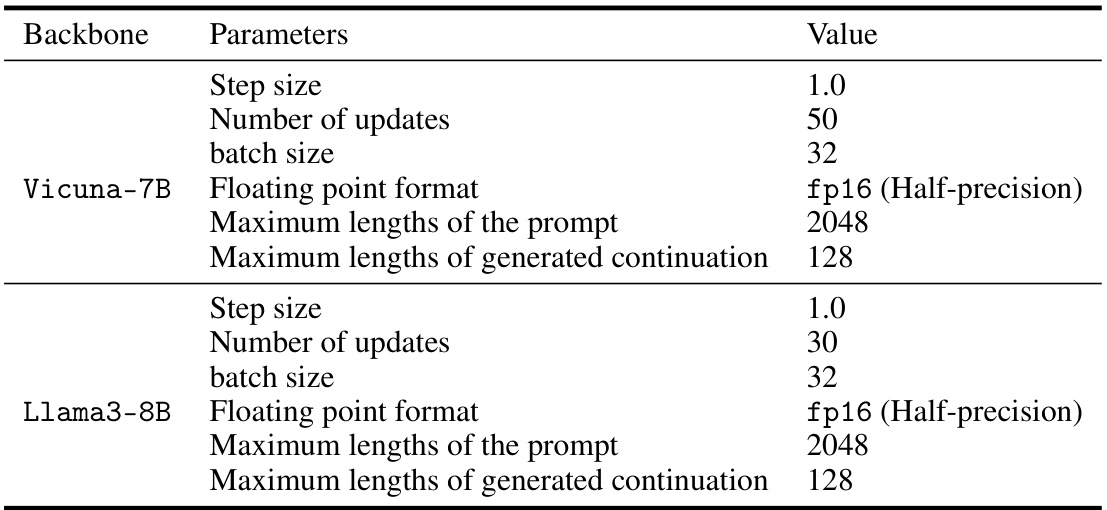
This table shows the hyperparameter settings used during the test phase of the RE-CONTROL model on the Stanford SHP dataset. It specifies values for parameters such as step size, number of updates, batch size, floating point format, maximum prompt length, and maximum generated continuation length, broken down by the backbone models used (Vicuna-7B and Llama3-8B). These settings are crucial for controlling the model’s behavior at inference time and balancing the trade-off between accuracy and computational cost.
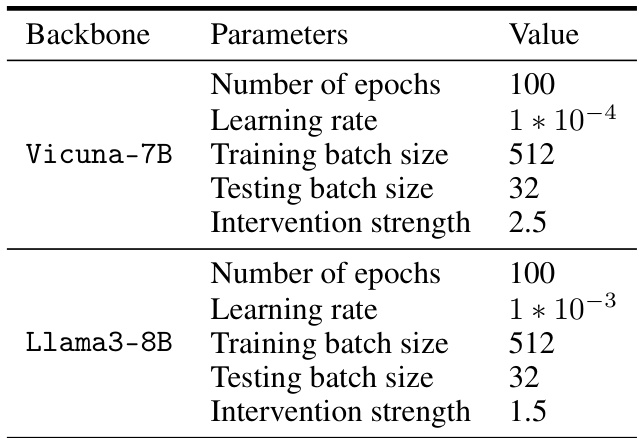
This table shows the hyperparameters used for static representation editing on the Stanford SHP dataset. It lists the values used for training and testing for both the Vicuna-7B and Llama3-8B models. Parameters include the number of epochs, learning rate, training and testing batch sizes, and intervention strength.
Full paper#