↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Atmospheric turbulence distorts long-range videos, causing significant challenges for computer vision applications. Existing video atmospheric turbulence mitigation (ATM) methods struggle to maintain temporal consistency across frames, resulting in visually incoherent results. This inconsistency stems from the stochastic nature of turbulence, varying across space and time.
ConVRT addresses this by introducing a novel neural video representation. This representation decouples spatial and temporal information, enabling targeted regularization. Leveraging the low-pass filtering properties of these regularized representations, ConVRT mitigates temporal frequency variations and promotes consistency. It uses a hybrid training approach, combining supervised pre-training on synthetic data with self-supervised learning on real videos, significantly enhancing performance on diverse real-world scenarios. This leads to temporally consistent video restoration even in complex, real-world atmospheric conditions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on video atmospheric turbulence mitigation. It presents a novel approach that significantly improves temporal consistency, a major challenge in current methods. The hybrid training framework (combining supervised pre-training and self-supervised learning) and innovative neural video representation are highly relevant to current trends in both deep learning and computer vision. This work opens new avenues for improving the performance of long-range video applications like object detection, surveillance, and autonomous driving, where turbulence significantly degrades video quality.
Visual Insights#

This figure demonstrates the challenge of achieving temporally consistent restoration in videos affected by atmospheric turbulence. It shows that existing state-of-the-art methods (DATUM and TMT) struggle to maintain consistency across frames, resulting in flickering artifacts even in a static scene. The figure highlights the need for new methods that specifically address this temporal inconsistency issue.
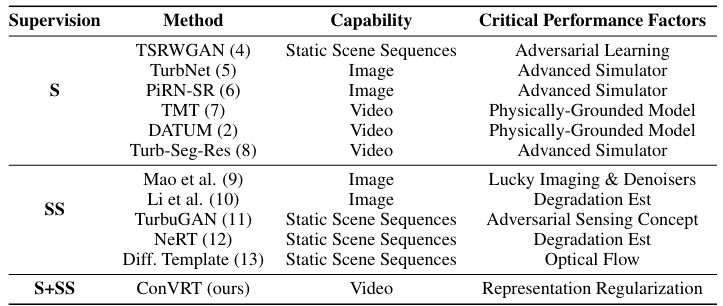
This table compares various state-of-the-art methods for Atmospheric Turbulence Mitigation (ATM) in images and videos. It categorizes methods by their supervision type (supervised, self-supervised, or hybrid) and highlights their capabilities (static scene sequences, image, or video). For each method, it also lists the critical factors influencing their performance, such as the use of adversarial learning, advanced simulators, physically-grounded models, or specific techniques like lucky imaging and denoisers. This provides a comprehensive overview of existing ATM techniques and their strengths and weaknesses.
In-depth insights#
Neural Video Rep#
The heading ‘Neural Video Representation’ suggests a focus on novel methods for encoding and processing video data using neural networks. This likely involves moving beyond traditional frame-by-frame analysis and exploring techniques that capture the inherent spatiotemporal relationships within video sequences. The core idea is to leverage the power of neural networks to learn efficient and informative representations of videos, potentially leading to improved performance in downstream tasks such as video compression, action recognition, or video generation. Efficient representation is crucial because videos contain significantly more data than images, and computationally expensive methods become infeasible. This approach likely involves designing neural network architectures that can effectively capture the rich temporal dynamics and correlations within video data. Success would likely depend on creating representations that are both compact and expressive, capturing fine-grained details while avoiding redundancy. Moreover, the choice of network architecture and training strategies would be critical, with methods such as recurrent neural networks, convolutional neural networks, or transformers potentially playing significant roles.
Temporal Regul#
The heading ‘Temporal Regul’ strongly suggests a focus on techniques to enforce temporal consistency in video processing. This is crucial because atmospheric turbulence, a key challenge in long-range video capture, introduces time-varying distortions. Methods addressing this would likely involve regularization strategies applied to temporal dimensions of neural network representations, perhaps using temporal convolutions, recurrent layers or specialized temporal attention mechanisms. A common approach could involve decoupling spatial and temporal information within a neural network architecture and then applying regularization (e.g., weight decay or constraints on the temporal components) to promote smoothness and consistency over time. The core idea would be to penalize high-frequency variations in the temporal domain, characteristic of turbulence-induced distortions while preserving fine-grained detail in the spatial domain. Successful temporal regularization would manifest in improved visual coherence, reduced flickering artifacts, and enhanced temporal consistency in reconstructed videos. Evaluation would likely involve metrics quantifying temporal consistency, such as temporal trajectory smoothness or average warp error, in addition to traditional image quality metrics.
ConVRT Method#
The ConVRT method is a novel approach to video atmospheric turbulence mitigation that leverages neural video representation. Its core innovation lies in explicitly decoupling spatial and temporal information, representing the video with a spatial content field and a temporal deformation field. This allows for targeted regularization of the temporal representation, effectively mitigating turbulence-induced temporal frequency variations. ConVRT’s training framework cleverly combines supervised pre-training on synthetic data with self-supervised learning on real-world videos, leading to improved temporal consistency in mitigation. By leveraging the low-pass filtering properties of the regularized temporal representations, ConVRT achieves temporally consistent restoration, significantly improving upon the state-of-the-art. The method demonstrates its effectiveness on diverse real-world datasets, showcasing its robustness and generalizability.
Real-World Tests#
A robust evaluation of any turbulence mitigation method necessitates rigorous real-world testing. This involves assessing performance on diverse datasets captured under varied atmospheric conditions, going beyond controlled simulations. Real-world tests should include scenarios with varying levels of turbulence intensity, differing camera parameters (e.g., exposure time, aperture), and object characteristics (e.g., distance, motion). Analyzing results across these diverse scenarios helps determine the method’s generalizability and resilience. Key performance indicators would involve evaluating both per-frame restoration quality (e.g., PSNR, SSIM) and temporal consistency, which is crucial for video applications. Qualitative analysis, involving visual inspection of restored videos, adds another layer of evaluation, often revealing subtleties not captured by quantitative metrics alone. Careful consideration of these aspects in real-world tests would build confidence in the method’s practical value and applicability.
Future Works#
Future research directions stemming from this work could explore several promising avenues. Extending ConVRT to handle longer video sequences and more complex motion patterns is crucial for broader applicability. Improving the computational efficiency of the algorithm, especially for high-resolution videos, would enhance its practicality. Investigating the integration of ConVRT with other advanced video processing techniques, such as super-resolution or de-noising, could yield further improvements in video quality. A thorough analysis of the model’s robustness to various types of atmospheric turbulence is also warranted, potentially leading to more adaptive and resilient video restoration. Finally, exploring the use of ConVRT in specific application domains, such as autonomous driving or remote sensing, would demonstrate its real-world value and could reveal new challenges and opportunities.
More visual insights#
More on figures

This figure compares the performance of ConVRT against state-of-the-art methods on real-world atmospheric turbulence data. It shows the original video frame, results from applying other methods individually, and the results after applying ConVRT to those other methods’ outputs. Key comparisons are made using ‘patches’ (zoomed-in regions), and Y-t slices (showing temporal evolution of a single vertical line in the frame). ConVRT is shown to reduce artifacts and achieve improved temporal consistency.
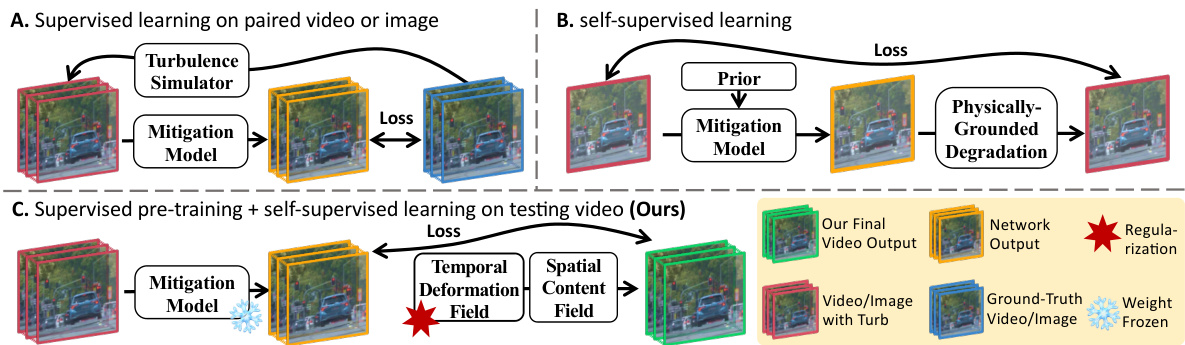
This figure compares three different learning approaches for atmospheric turbulence mitigation (ATM) in images and videos. (a) shows supervised learning, which uses paired training data (clean and distorted) generated by a turbulence simulator. This approach struggles with real-world data because simulated and real turbulence differ. (b) illustrates self-supervised learning, which uses unpaired data and learns from internal data patterns or lucky images. This method often produces inconsistent results and struggles with motion. (c) presents the authors’ hybrid approach (ConVRT), which combines supervised pre-training on synthetic data with self-supervised learning on real data. It introduces a neural representation that separates spatial and temporal information for improved temporal consistency.
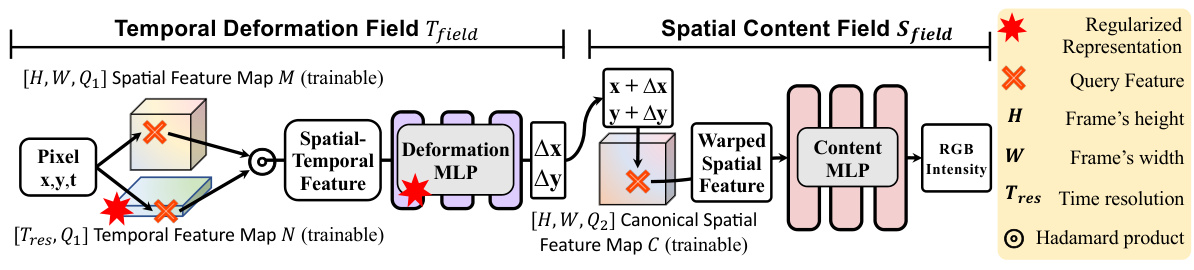
This figure illustrates the architecture of the ConVRT model, which consists of two main components: the Temporal Deformation Field (Tfield) and the Spatial Content Field (Sfield). The Tfield uses a Hadamard product to combine spatial and temporal feature maps and an MLP to output deformation offsets. The Sfield uses the offsets to warp a canonical spatial feature map and an MLP to predict the RGB intensity values. The model is regularized by constraining the dimensions of the temporal feature map and the size of the deformation MLP to promote temporal consistency.

This figure showcases the results of the proposed ConVRT method compared to other state-of-the-art methods for mitigating atmospheric turbulence in real-world videos. The visualization uses both KLT tracking (to show motion consistency) and Y-t slices (to show temporal consistency) to demonstrate that ConVRT significantly reduces erratic movements and flickering artifacts resulting from turbulence, improving temporal consistency in the restored videos.

This figure compares the performance of ConVRT against state-of-the-art methods (VRT, TMT, DATUM) in mitigating real-world atmospheric turbulence. It uses a video clip showing a static scene (a building) to highlight the temporal consistency issue. The left shows the original frame with marked regions used for close-up analysis. The right displays those close-ups, focusing on KLT tracking (showing movement over time) and Y-t slices (showing changes across frames). ConVRT’s results are markedly smoother and more temporally consistent than the baseline methods.

This figure presents an ablation study on the impact of the temporal consistency regularization loss (Ltemp) and the temporal resolution (Tres) on the performance of the proposed method, ConVRT. It shows that using Ltemp and a lower Tres leads to better mitigation of residual turbulence, resulting in smoother temporal dynamics. The canonical image, generated from the Canonical Spatial Feature Map C, provides a clear visualization of the spatial details of the video without temporal deformation. The results demonstrate the effectiveness of the proposed method in controlling the temporal dynamics of the restored videos.

This figure shows the effectiveness of the proposed method in handling camera shake and turbulence. It compares the results of the proposed method with a baseline method (DATUM) on synthetic videos with and without camera shake added, using Y-t slice plots and KLT trajectories to visualize temporal consistency and motion.

This figure compares the performance of ConVRT against two other methods (Li et al. and Mao et al.) on video sequences containing moving objects. The other methods struggle to accurately represent the motion of objects, often blurring or replacing them with the average background. In contrast, ConVRT demonstrates a superior ability to preserve the motion and details of moving objects.

This figure demonstrates the effectiveness of the proposed method (ConVRT) in mitigating real-world atmospheric turbulence compared to state-of-the-art methods. It uses KLT tracking to visualize the motion of features in the video and shows how ConVRT leads to smoother and more consistent trajectories, indicating improved temporal consistency in the restoration of the video.

This figure demonstrates the effectiveness of the proposed method (ConVRT) in mitigating atmospheric turbulence without relying on any base restoration techniques for preprocessing. It presents a comparison between the original video frame with turbulence, the results after applying ConVRT, and the results obtained using DATUM (a state-of-the-art video atmospheric turbulence mitigation method) with and without ConVRT. The comparison is made using visual inspection and analysis of KLT tracking and Y-t slice plots which show improved temporal consistency and reduced artifacts when using the proposed method.
More on tables

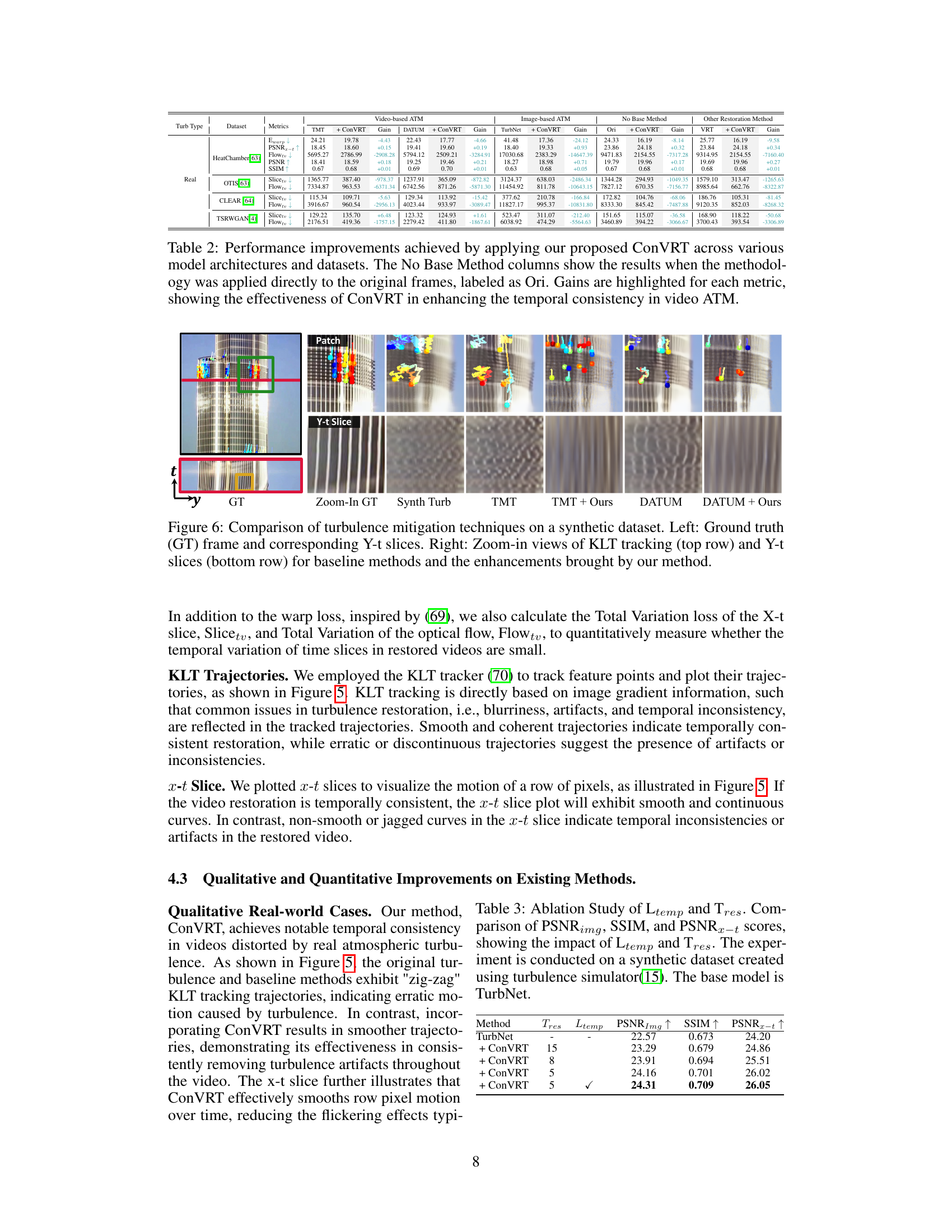
This table presents a quantitative comparison of the proposed ConVRT method with various state-of-the-art video and image atmospheric turbulence mitigation (ATM) methods. It shows the improvements achieved in terms of different metrics (Ewarp, PSNR, SSIM, Flowtv, Slicetv) by applying ConVRT to the results of other methods. The table also provides results when ConVRT is used independently, without pre-processing by other ATM methods, showing the standalone effectiveness of ConVRT.
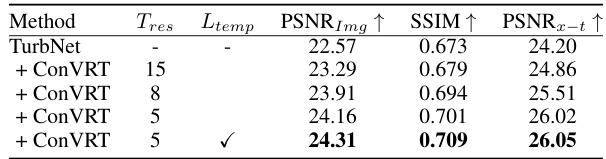
This table presents the results of an ablation study to analyze the impact of two hyperparameters: Tres (temporal resolution) and Ltemp (temporal consistency regularization loss) on the performance of the ConVRT method. The experiment uses synthetic turbulence data and TurbNet as the baseline model. The table shows that lower Tres and the inclusion of Ltemp lead to better PSNRimg, SSIM, and PSNRx-t scores, indicating improved image quality and temporal consistency.
Full paper#