↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current instruction tuning for LLMs relies on either expensive human annotation or GPT-4 distillation, both of which have limitations in scale and diversity. This often leads to biased and less generalizable models. This paper tackles this issue by proposing a new paradigm for enhancing LLM reasoning. Existing instruction data is scarce and costly, limiting the scalability and diversity of training.
The proposed solution involves a three-step pipeline: recalling relevant documents from a pre-training web corpus, extracting instruction-response pairs, and refining these pairs using open-source LLMs. Fine-tuning base LLMs on the resulting 10-million instruction dataset (WEBINSTRUCT) creates significantly improved models (MAmmoTH2). The results demonstrate the effectiveness and cost-efficiency of this method, achieving state-of-the-art performance on several benchmarks. This offers a new approach for building better instruction tuning data for LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on instruction tuning and large language models (LLMs). It presents a novel, cost-effective method for creating high-quality instruction datasets by mining existing web data. This addresses the limitations of current methods that rely on expensive human annotation or GPT-4 distillation, opening new avenues for research on more scalable and diverse LLM training. The state-of-the-art performance achieved by the proposed MAmmoTH2 models on various benchmarks highlights the potential of this approach for advancing LLM capabilities.
Visual Insights#
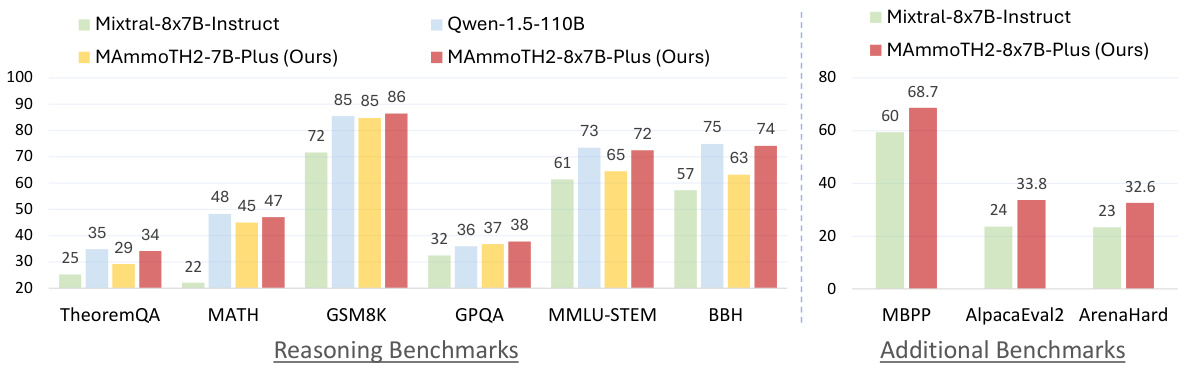
This figure presents a comparison of the performance of the MAmmoTH2-Plus models (specifically the 8x7B variant) against other state-of-the-art LLMs on various reasoning benchmarks (TheoremQA, MATH, GSM8K, GPQA, MMLU-STEM, BBH, MBPP, AlpacaEval2, and ArenaHard). The bar chart visually demonstrates that MAmmoTH2-8x7B-Plus outperforms Mixtral-Instruct across multiple benchmarks and achieves comparable results to Qwen-1.5-110B, despite having significantly fewer parameters (13B vs 110B). The figure highlights the significant performance gains achieved by the MAmmoTH2-Plus models, particularly in reasoning tasks.
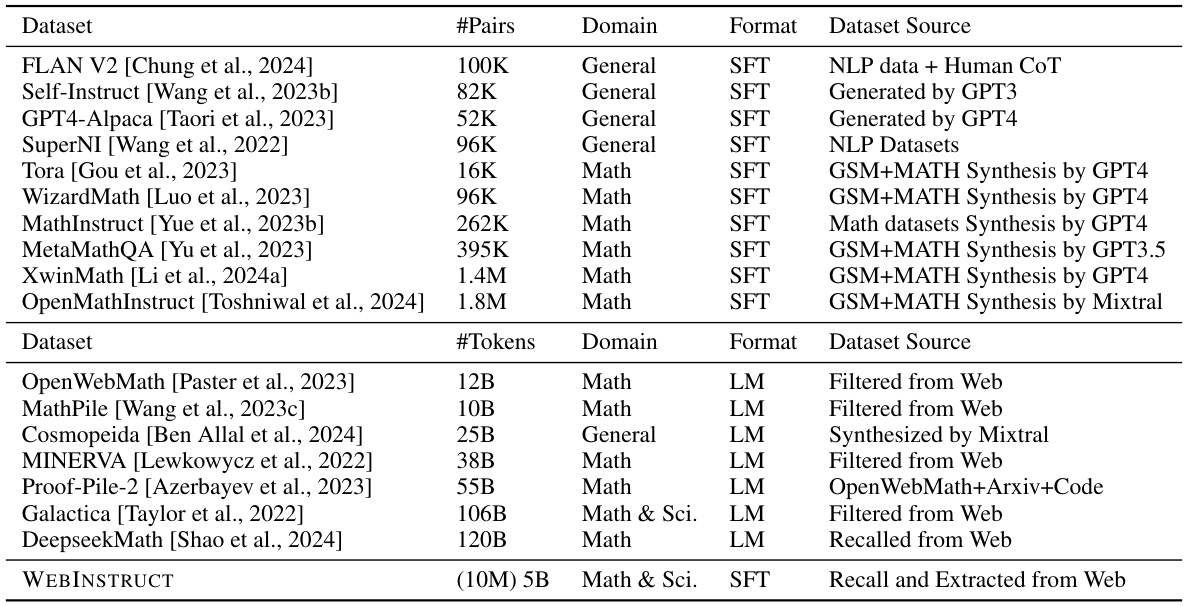
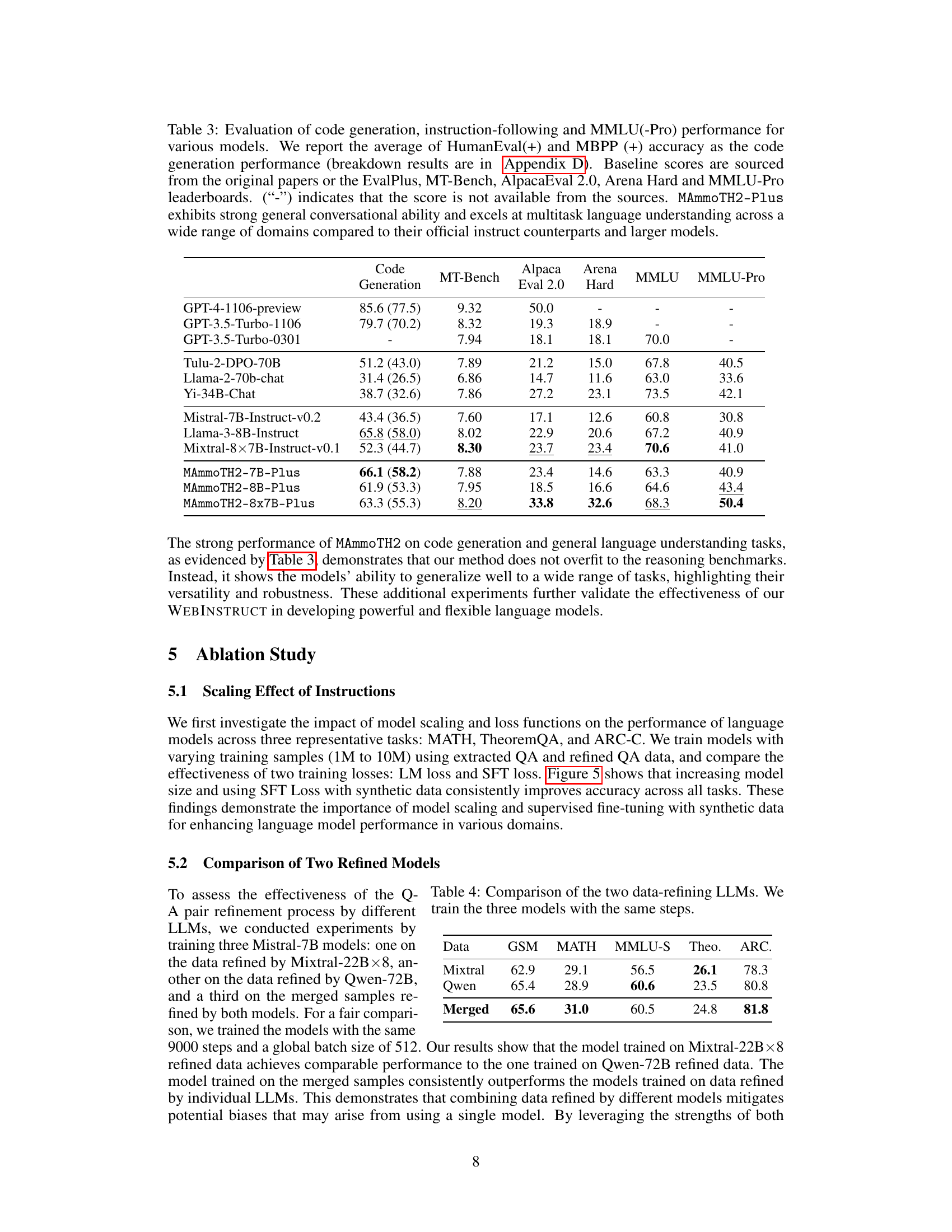
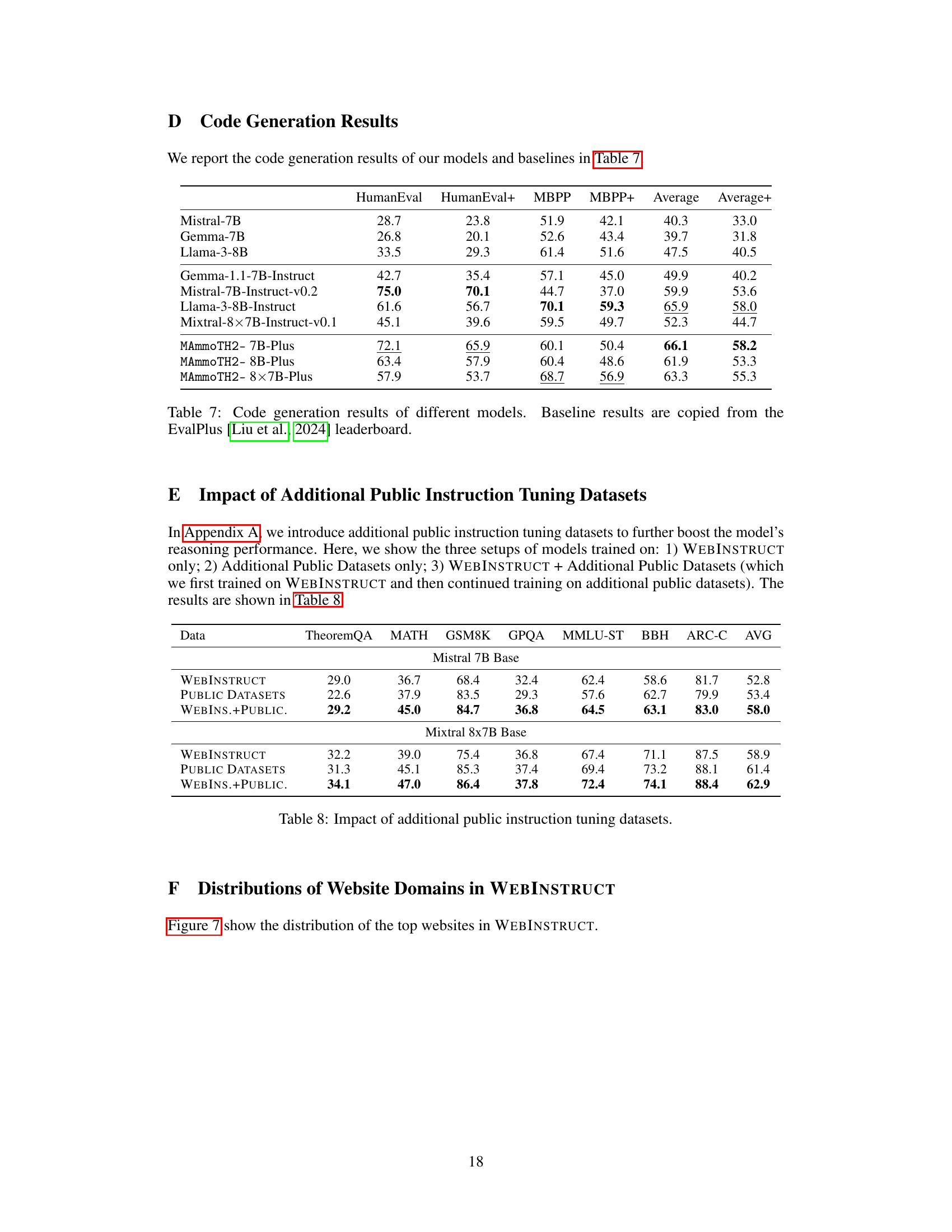
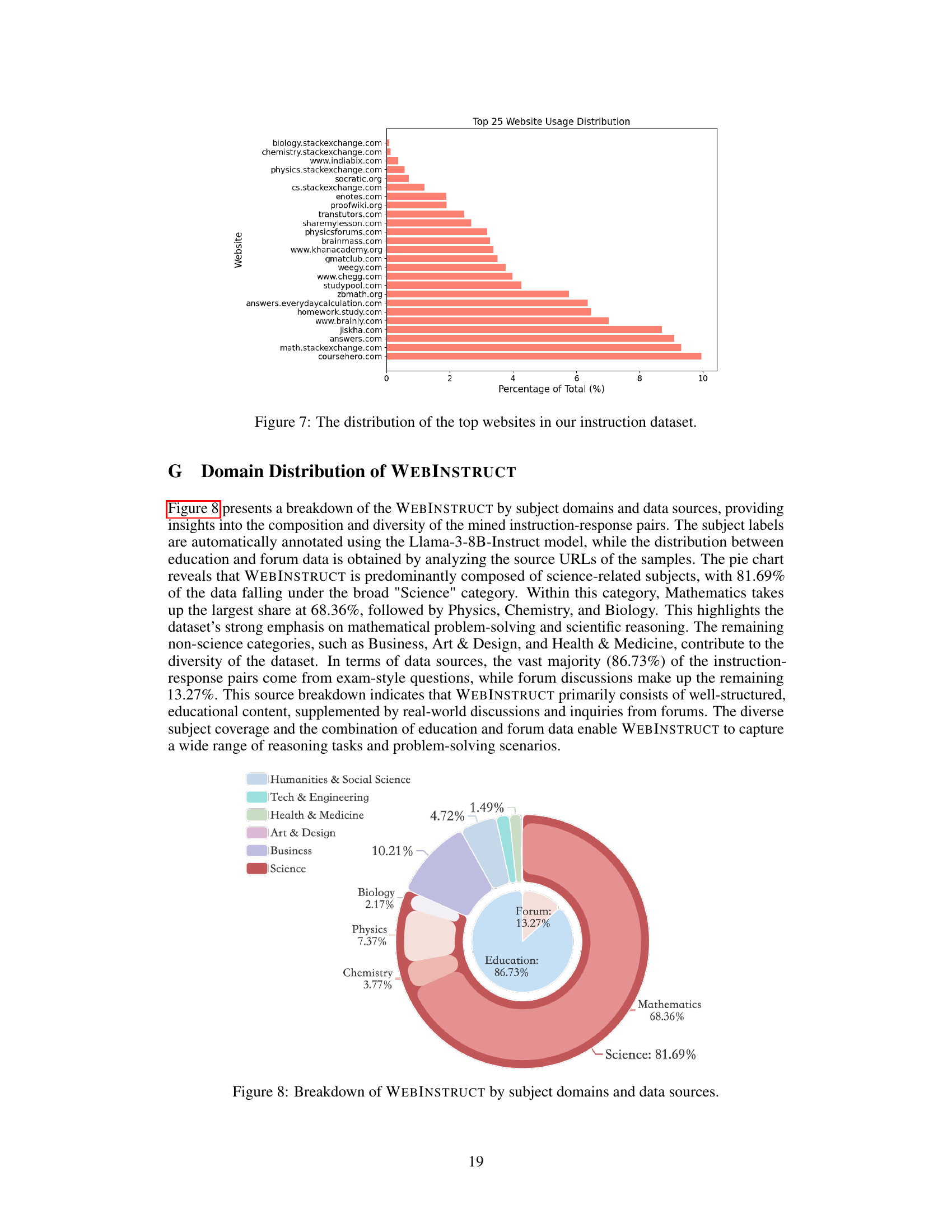
This table compares various existing datasets used for training language models, categorized as either Supervised Fine-Tuning (SFT) or Continued Training (CT). SFT datasets are generally smaller, higher quality, and often created using human-annotated data or GPT-3.5/4 generation. CT datasets are much larger but contain more noise. The table highlights the size, domain focus, format, and creation method of each dataset. It also positions the WEBINSTRUCT dataset (developed in this paper) in relation to these other datasets, showing that it falls between SFT and CT methods, achieving a good balance between size and data quality.
In-depth insights#
Web Instruction Mining#
Web instruction mining presents a powerful paradigm shift in training large language models (LLMs). Instead of relying on expensive and potentially biased human-annotated datasets or GPT-4 distillation, it leverages the vast, readily available instruction data hidden within the massive web corpus. This approach offers significant advantages in terms of scalability and cost-effectiveness. However, effectively mining this data requires sophisticated techniques. The core challenge lies in accurately identifying and extracting relevant instruction-response pairs from noisy, unstructured web content. This often involves employing powerful LLMs for tasks such as document retrieval, instruction-response pair extraction, and refinement. The resulting dataset’s quality heavily depends on the performance and robustness of these LLMs, highlighting the critical need for careful data cleaning and validation steps to mitigate potential biases and hallucinations. Despite challenges, successful web instruction mining can produce massive, high-quality instruction datasets at significantly lower costs, enabling the training of significantly improved LLMs with enhanced reasoning abilities. Further research could focus on improving the efficiency and accuracy of instruction-response pair extraction, and on developing robust methods for addressing issues such as bias and hallucination to fully unlock this resource’s potential.
LLM Reasoning Boost#
A significant focus in enhancing Large Language Models (LLMs) is boosting their reasoning capabilities. This often involves instruction tuning, where the model learns from a dataset of instructions and their corresponding answers. However, high-quality instruction data is often expensive to create, limiting the scalability of these methods. A promising approach involves leveraging readily available web data to create large instruction datasets efficiently. This is often done by utilizing a pipeline that extracts instruction-response pairs from the web, then refines these using other LLMs. This method has demonstrated the potential to significantly improve LLM reasoning abilities on various benchmarks, achieving state-of-the-art performance in some cases. However, it’s crucial to consider the challenges related to data quality and the potential for biases in web data. Further research is needed to investigate techniques for mitigating these issues and improving the quality and diversity of automatically generated instruction datasets.
Scaling Instruction Data#
Scaling instruction data for large language models (LLMs) is crucial for enhancing their reasoning and performance. Current methods, such as human annotation and GPT-4 distillation, are expensive and limited in scale. This paper proposes a novel paradigm to efficiently harvest high-quality instruction data directly from the pre-training web corpus. This approach significantly reduces the reliance on costly human effort. The process involves three key steps: recalling relevant documents, extracting instruction-response pairs using LLMs, and refining the extracted pairs via advanced LLMs for quality control. This method successfully generates a large-scale, high-quality instruction dataset (10 million pairs), surpassing the scale and diversity of existing datasets. Fine-tuning LLMs on this dataset significantly improves performance on various reasoning benchmarks, showcasing the potential of leveraging readily available web data to enhance LLM capabilities. The scalability and cost-effectiveness are key advantages of this approach, offering a new paradigm for building better instruction tuning data.
MAmmoTH2 Model#
The MAmmoTH2 model represents a significant advancement in large language model (LLM) reasoning capabilities. Its core innovation lies in leveraging a massive, high-quality instruction dataset (WEBINSTRUCT) mined from the pre-training web corpus. This approach avoids costly human annotation or GPT-4 distillation, offering a more efficient and scalable solution. By fine-tuning base LLMs on WEBINSTRUCT, the MAmmoTH2 models achieve state-of-the-art performance on various reasoning and chatbot benchmarks, demonstrating strong generalization abilities. The model’s success highlights the potential of effectively harvesting large-scale instruction data from readily available web resources, thereby creating a new paradigm for building better instruction-tuned LLMs. Furthermore, MAmmoTH2’s enhanced performance across diverse tasks showcases its versatility and robustness, surpassing many existing models, and presenting a cost-effective alternative to other instruction tuning methods.
Future Research#
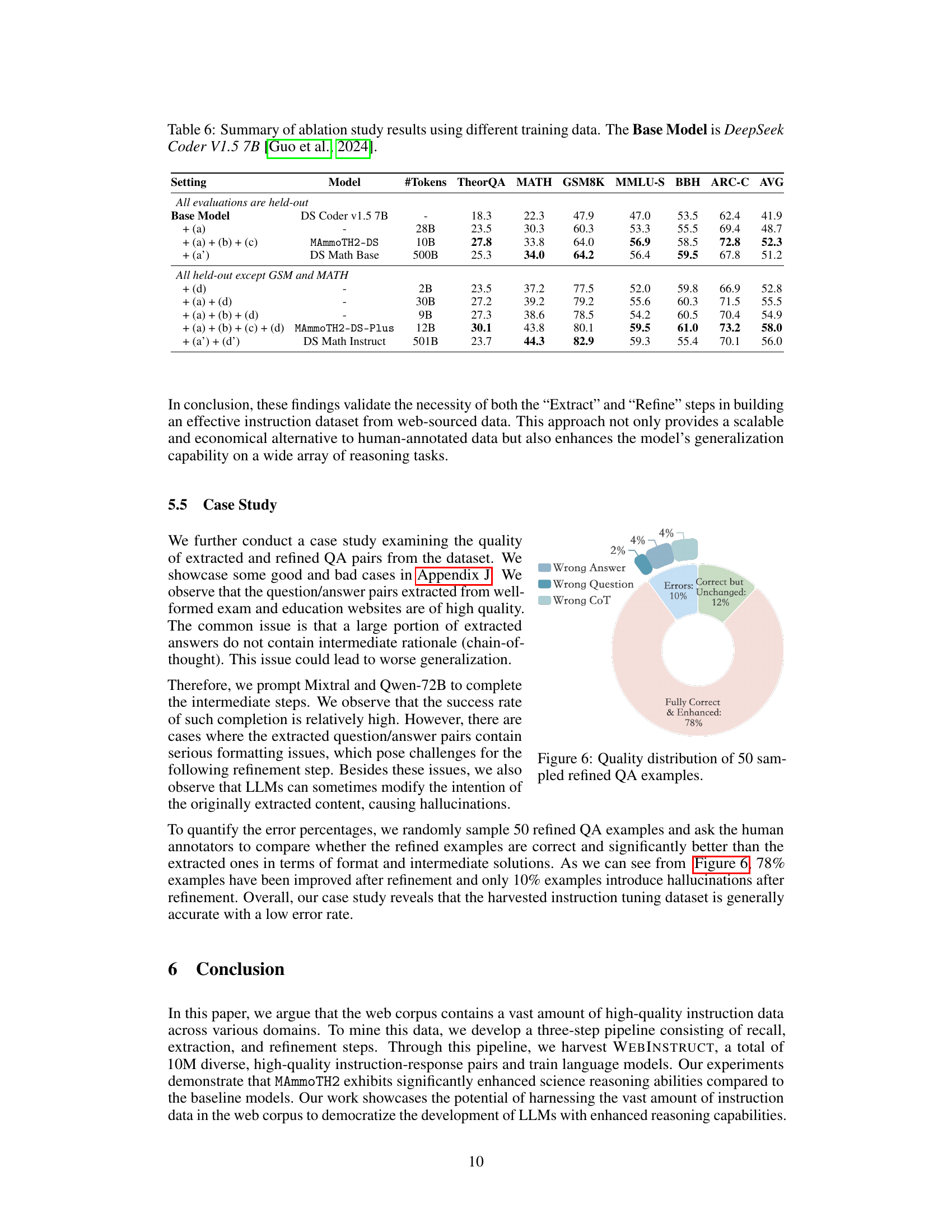
Future research directions stemming from this work on instruction tuning could explore several avenues. Improving data quality remains paramount; refining the three-step pipeline with more advanced LLMs or incorporating human-in-the-loop validation could significantly enhance WEBINSTRUCT’s accuracy and reduce biases. Expanding WEBINSTRUCT’s scope to broader domains and languages is crucial for creating truly generalizable models. Investigating the influence of different LLMs in the extraction and refinement steps is key to understanding their impact on the final dataset quality. Finally, exploring new methodologies to discover high-quality instructions directly from web corpora, reducing the reliance on seed data, could lead to more scalable and efficient instruction tuning methods. A deeper understanding of the effectiveness of different loss functions (SFT vs. LM) would allow for better tuning strategies. Also, a comprehensive comparison across a wider range of base LLMs would strengthen the generality of the conclusions.
More visual insights#
More on figures
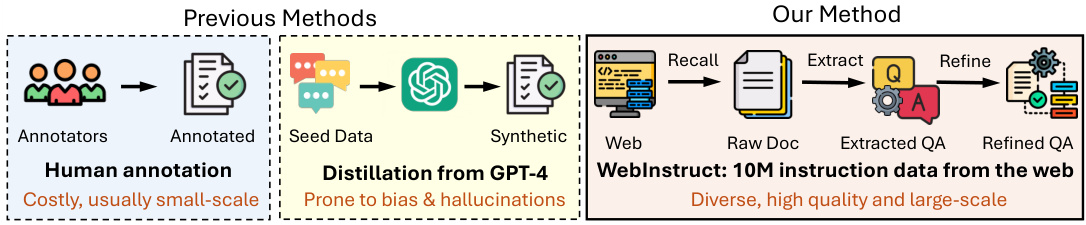
This figure compares the dataset creation methods used in previous studies with the proposed method in this paper. Previous methods relied on costly human annotation or GPT-4 distillation to create instruction-response pairs. These methods typically resulted in small-scale datasets prone to biases and hallucinations. In contrast, the authors’ method leverages a vast, naturally existing instruction dataset mined from the pre-training web corpus. Their three-step pipeline (recall, extract, refine) efficiently harvests 10 million instruction-response pairs, resulting in a diverse, high-quality, and large-scale dataset.
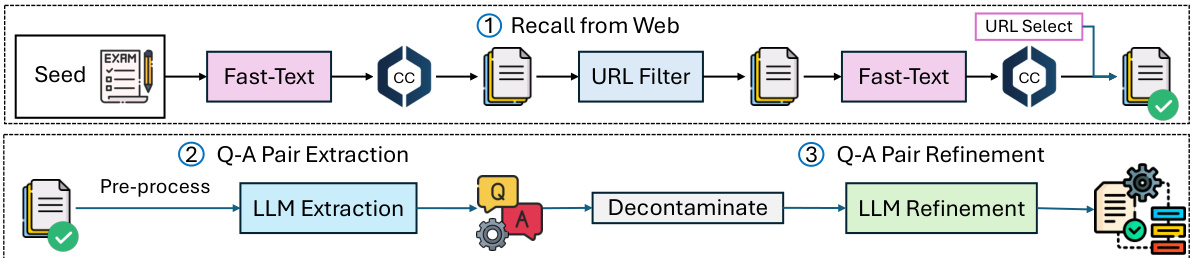
This figure illustrates the three-step pipeline used to construct the WEBINSTRUCT dataset. The first step involves recalling relevant documents from the Common Crawl web corpus using a pre-trained fastText model. The second step extracts question-answer pairs from the recalled documents using a large language model (LLM). Finally, the third step refines the extracted Q-A pairs using another LLM to remove unrelated content, fix formality issues, and add missing explanations. This pipeline results in a dataset of high-quality instruction-response pairs obtained solely from web data, without human annotation or GPT-4 distillation.

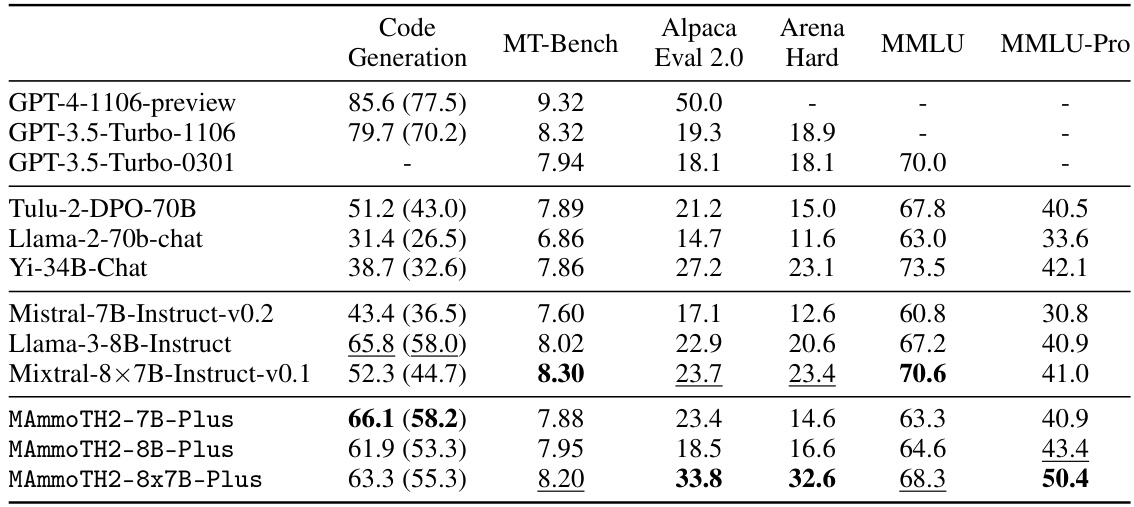
This figure presents a bar chart comparing the performance of several large language models (LLMs) on various reasoning benchmarks. The key takeaway is that the MAmmoTH2-8x7B-Plus model, developed by the authors, significantly outperforms the Mixtral-Instruct model on most benchmarks, achieving performance comparable to the much larger Qwen-1.5-110B model. This demonstrates that the MAmmoTH2-Plus models are highly efficient in terms of parameter count for their performance. The chart also shows MAmmoTH2-Plus’s strong results on code and chatbot evaluation.
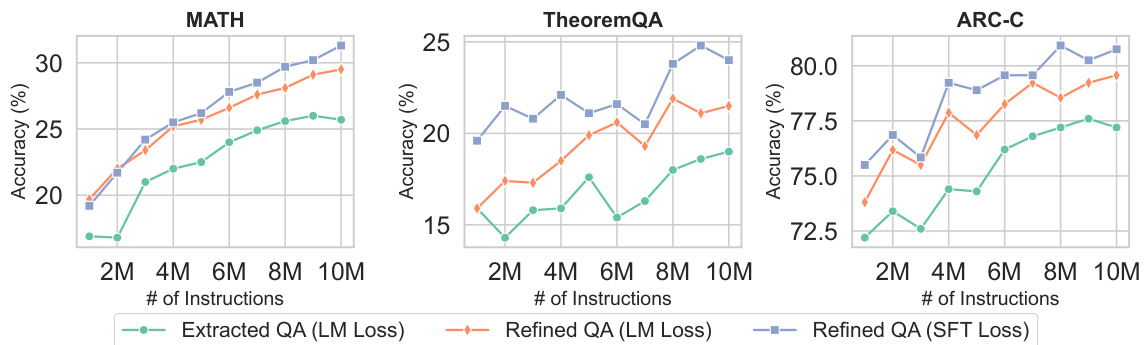
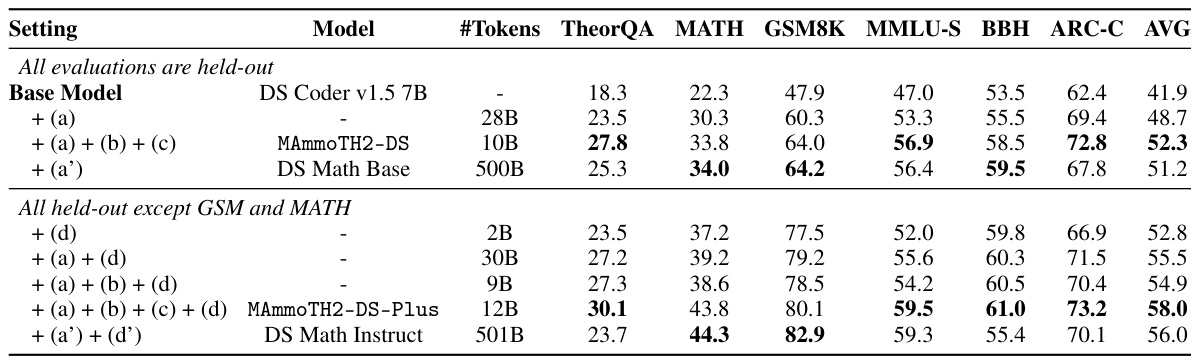
This figure shows the impact of scaling the number of instructions and using different loss functions (LM Loss and SFT Loss) on the performance of the Mistral-7B language model across three reasoning benchmarks: MATH, TheoremQA, and ARC-C. The x-axis represents the number of instructions used in training (2M, 4M, 6M, 8M, and 10M). The y-axis shows the accuracy of the model on each benchmark. The three lines represent different training settings: using extracted QA pairs with LM Loss, refined QA pairs with LM Loss, and refined QA pairs with SFT Loss. The figure demonstrates that increasing the number of instructions improves model performance and that using the SFT Loss function with refined QA pairs leads to better results compared to the LM Loss function.
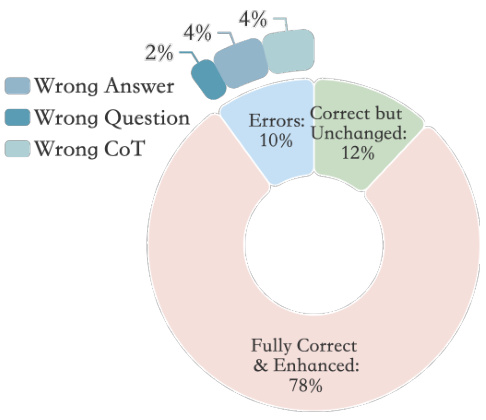
This figure shows the results of a quality assessment of 50 randomly selected refined question-answer pairs from the WEBINSTRUCT dataset. Human annotators evaluated each pair, classifying them into categories: Fully Correct & Enhanced (78%), Correct but Unchanged (12%), and various error types including Wrong Answer (4%), Wrong Question (4%), and Wrong CoT (Chain of Thought) (2%). The breakdown illustrates the overall quality and the types of errors present in the refined dataset after the refinement step in the WEBINSTRUCT pipeline.

This figure shows a bar chart comparing the performance of the MAmmoTH2-Plus model (specifically the 8x7B variant) against other large language models (LLMs) across various benchmarks. The benchmarks are categorized into reasoning and additional benchmarks (which include code generation and chatbot tasks). The chart demonstrates that MAmmoTH2-8x7B-Plus outperforms Mixtral-Instruct significantly on reasoning tasks, achieving comparable performance to the much larger Qwen-1.5-110B model, while also showing advantages on the additional tasks.

This figure presents a bar chart comparing the performance of the MAmmoTH2-Plus models (specifically the 8x7B variant) against other state-of-the-art large language models (LLMs) on various reasoning and common sense benchmarks. It highlights that MAmmoTH2-8x7B-Plus achieves comparable or better performance to significantly larger models (like Qwen-1.5-110B) while being much more parameter efficient. The chart showcases improved performance on multiple reasoning benchmarks (TheoremQA, MATH, GSM8K, GPQA, MMLU-STEM, BBH, MBPP) as well as additional benchmarks encompassing general code and chatbot tasks (AlpacaEval2 ArenaHard).
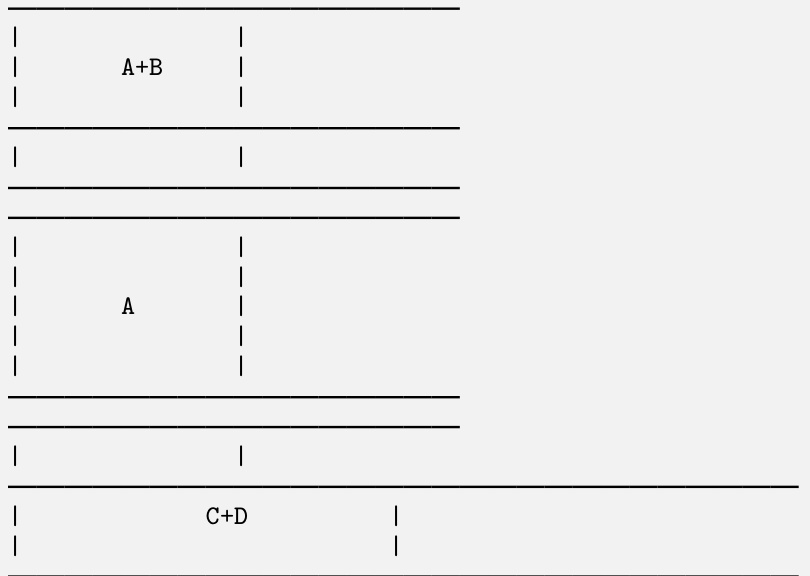
This figure shows an example of how the WEBINSTRUCT dataset is created. The left side shows the raw document from a website, which contains unformatted text, site information, and ads. The middle shows the extracted question and answer pair (QA pair) using LLMs. It’s formatted but lacks detailed solutions. The right shows the refined QA pair after further refinement using LLMs. The refined QA pair is formatted and augmented with detailed solutions.
More on tables
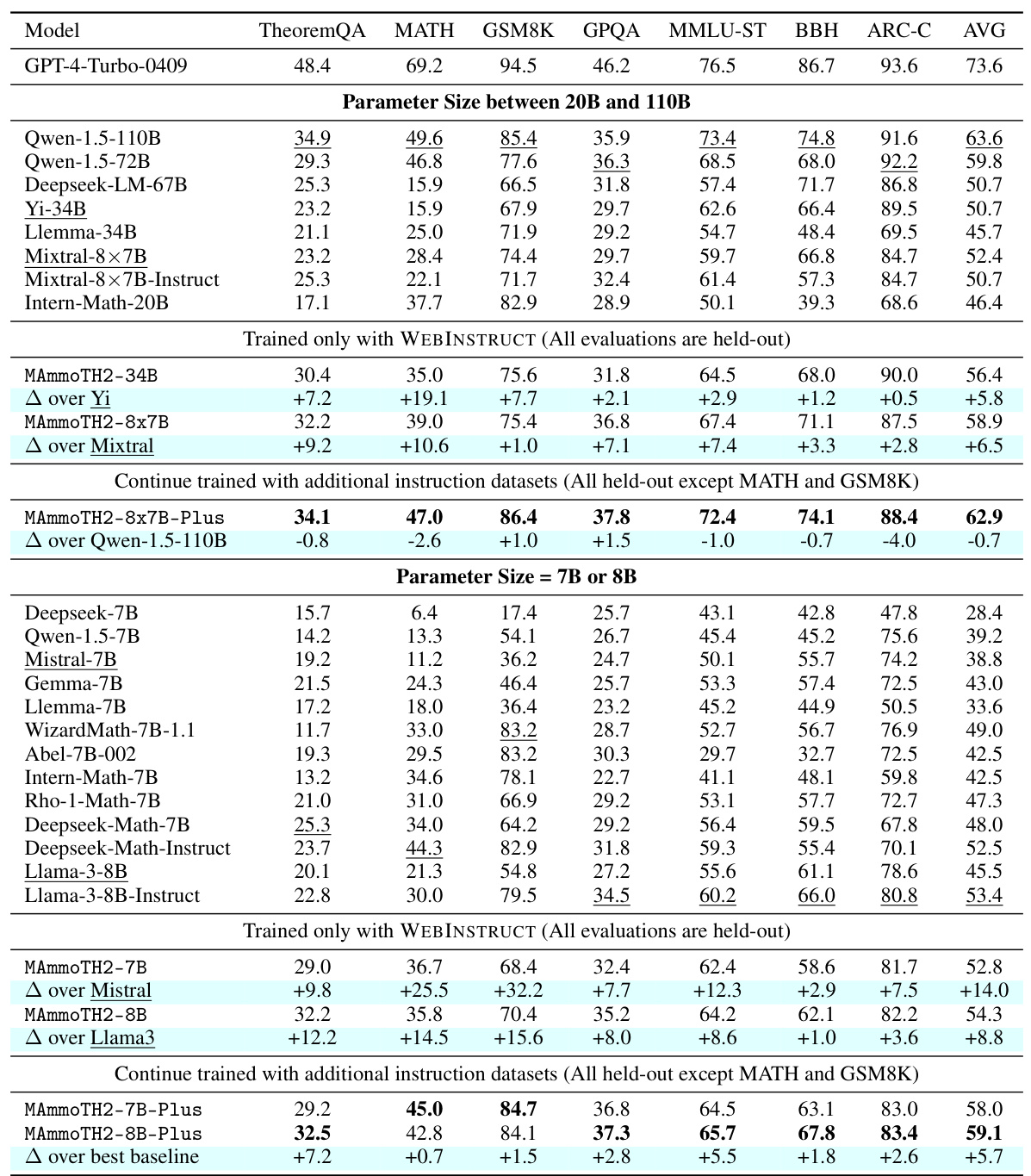
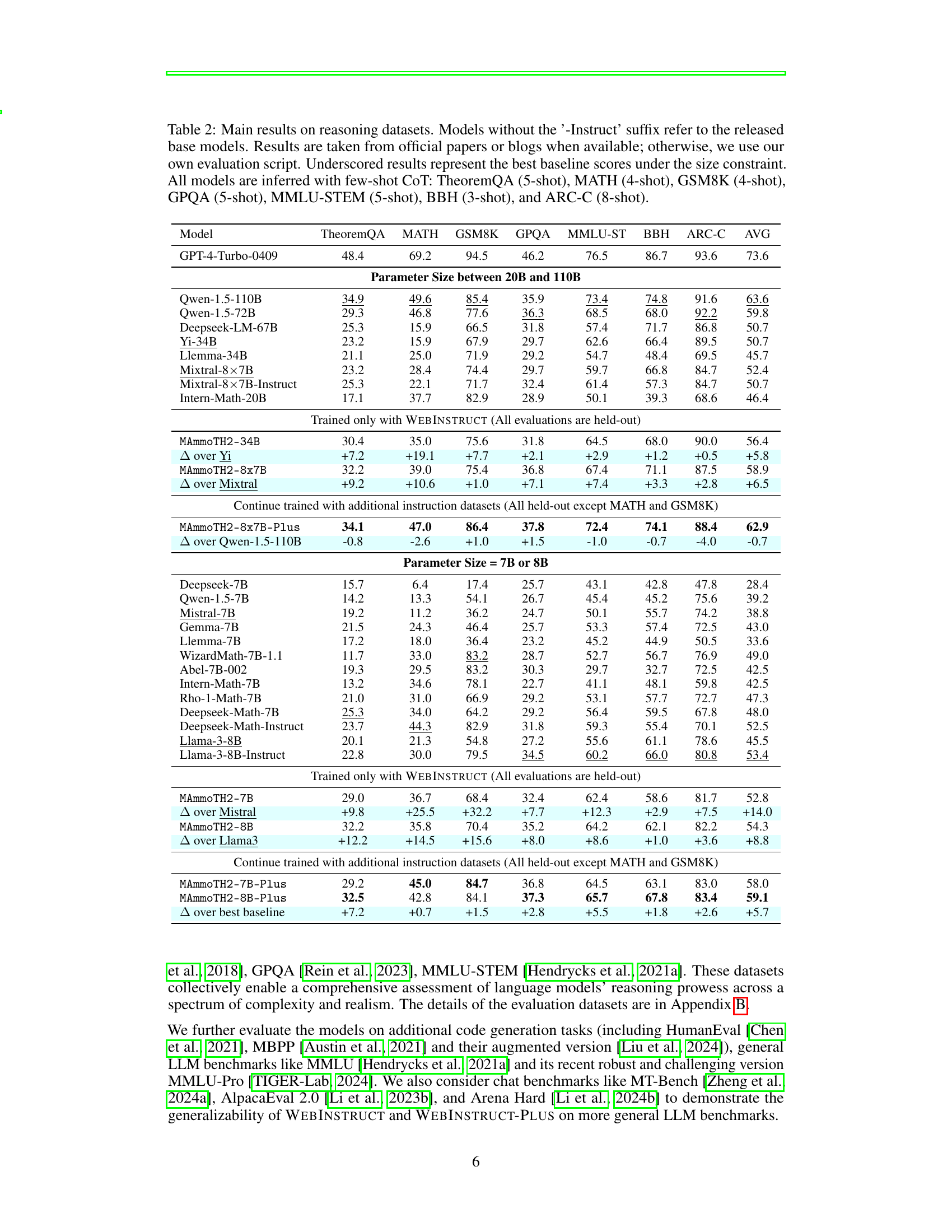
This table presents the main results of the experiments conducted on seven reasoning benchmark datasets. It compares the performance of various language models, categorized by their parameter size (7B, 8B, or >20B). The table shows each model’s performance on each benchmark and highlights the improvement achieved by the models trained using WEBINSTRUCT, both alone and in combination with additional public instruction datasets. Few-shot Chain-of-Thought (CoT) prompting was used for all model evaluations. The table clearly indicates improvements made by the models trained on the proposed WEBINSTRUCT dataset, demonstrating their effectiveness in enhancing reasoning capabilities.
This table presents the main experimental results on seven reasoning benchmarks. It compares the performance of various language models, both with and without instruction tuning, across different parameter sizes (7B and 8B). The table highlights the performance gains achieved by the MAmmoTH2 models, particularly when trained using WEBINSTRUCT, a novel web-derived dataset. Few-shot chain-of-thought prompting was used for evaluation.
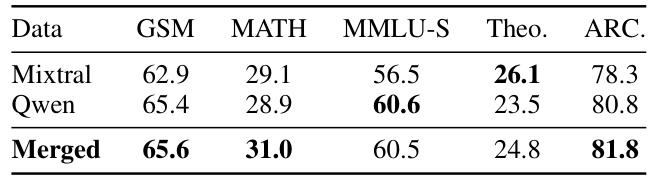
This table compares the performance of three Mistral-7B models trained on data refined by different LLMs. One model was trained on data refined by Mixtral-22B×8, another on data refined by Qwen-72B, and the third on a merged dataset combining data refined by both Mixtral and Qwen. The table shows the results on GSM8K, MATH, MMLU-STEM, TheoremQA, and ARC-C benchmarks, demonstrating the impact of different refinement methods on model performance.

This table presents the results of training Mistral 7B language model on subsets of WEBINSTRUCT categorized by domain (Math, Science, Education, Forum, Other) and data source (Education, Forum). The performance is evaluated on five benchmark datasets: GSM8K, MATH, MMLU-STEM, TheoremQA, and ARC-C. It shows how different domains and data sources affect the model’s performance on these tasks.
This table presents the main results of the reasoning benchmarks comparing different language models. It shows the performance of various models (both base models and those fine-tuned with WEBINSTRUCT) on seven reasoning benchmarks. The table is divided into two sections based on model parameter size (20B-110B and 7B-8B). Few-shot Chain-of-Thought (CoT) prompting was used for all models, with the number of shots specified for each benchmark. Results are taken from official sources when available, otherwise, the authors’ own evaluation was used. Underscored scores indicate the best baseline performance among comparable models. Finally, the table highlights performance improvements achieved through fine-tuning with WEBINSTRUCT and additional datasets.
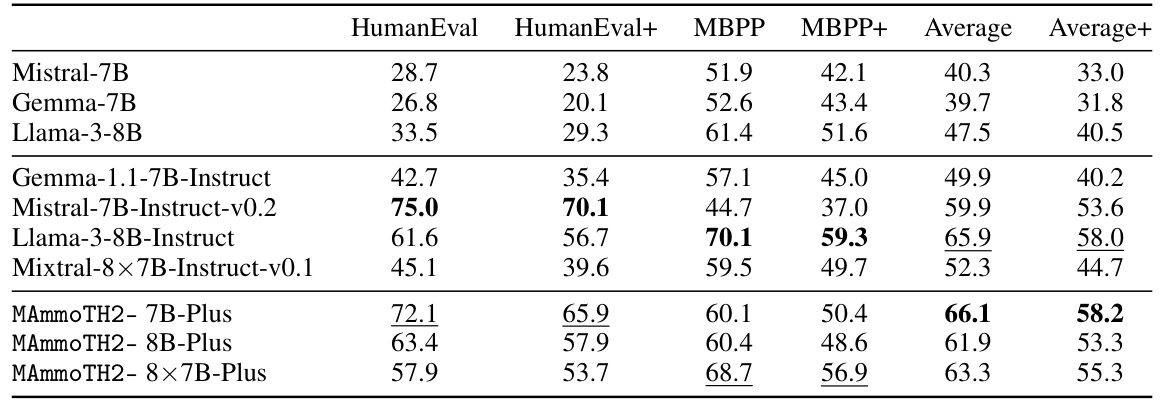
This table presents the main experimental results on several reasoning benchmarks. It compares the performance of various language models, both with and without instruction tuning, across different sizes (7B, 8B, 34B parameters). The models are evaluated using few-shot chain-of-thought prompting on several datasets. The table highlights the performance gains achieved by models trained using the WEBINSTRUCT dataset. Results are also shown for models further fine-tuned with additional instruction datasets.
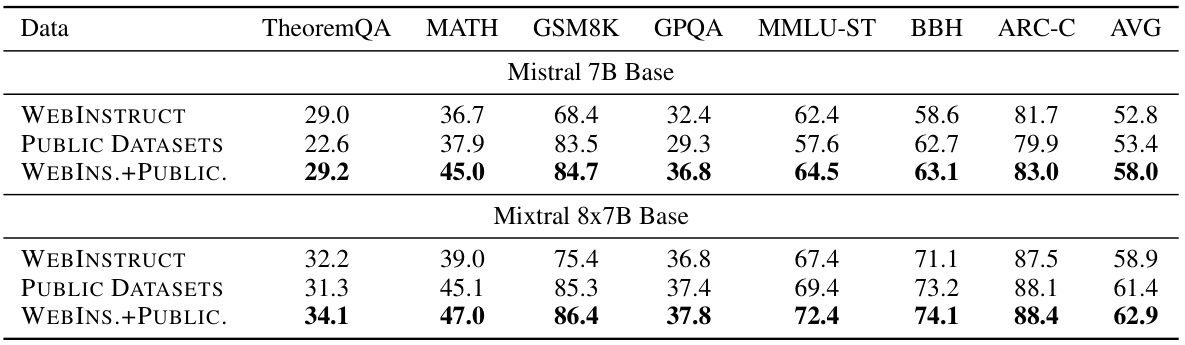
This table presents the main experimental results on seven reasoning benchmarks, comparing the performance of various language models. It shows the performance of models trained solely with WEBINSTRUCT, compared to those trained with additional instruction datasets and the base models. Models are categorized by their parameter size (7B or 8B, and 20B-110B). Few-shot chain-of-thought (CoT) prompting is used for all evaluations. The results highlight the performance gains achieved by training models using WEBINSTRUCT, even exceeding state-of-the-art performance in several cases.
Full paper#