↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional federated learning struggles with real-time predictions on streaming data, especially in dynamic environments where pre-trained models may be inefficient. Existing online federated learning algorithms also don’t significantly outperform local model training in such situations.
This research introduces Fed-POE, a novel personalized federated learning algorithm that addresses these issues. Fed-POE enables clients to construct personalized models by adaptively combining locally fine-tuned models and models learned through federated learning. Theoretical analysis proves that Fed-POE achieves sublinear regret. Experiments on real datasets confirm its superior performance compared to existing methods in online prediction and model fine-tuning scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing federated learning methods in handling real-time, non-stationary data. It proposes a novel personalized federated learning algorithm, Fed-POE, which achieves sublinear regret bounds and outperforms existing methods in real-world datasets. This work is highly relevant to the growing field of online federated learning and opens up new avenues for research in personalized model adaptation and ensemble methods.
Visual Insights#

This figure shows the cumulative regret over time for different federated learning algorithms on CIFAR-10 (image classification) and WEC (regression) datasets. The cumulative regret is a measure of how much worse the algorithm’s predictions are compared to the best possible model in hindsight. Lower cumulative regret indicates better performance. The plot visually compares the performance of Fed-POE against baselines, demonstrating its effectiveness in minimizing regret.
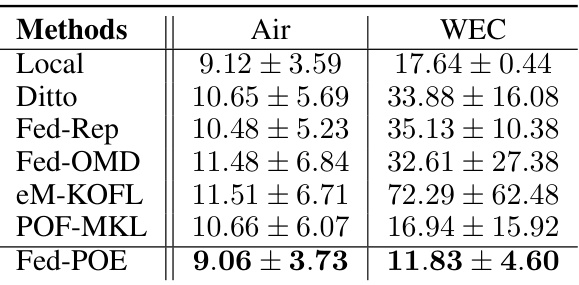
This table presents the mean squared error (MSE) and standard deviation achieved by different federated learning algorithms and a local learning baseline on two real-world regression datasets: Air and WEC. The MSE is a measure of prediction accuracy, with lower values indicating better performance. The standard deviation shows the variability of the results across different clients. The table aims to compare the performance of the proposed Fed-POE method against other state-of-the-art algorithms for online prediction and demonstrates its superior performance.
In-depth insights#
Fed-POE Algorithmic Design#
The Fed-POE algorithmic design centers around personalized online federated learning. Adaptive ensembling is key, combining locally fine-tuned models with multiple federated models selected by each client. This addresses the challenge of concept drift in non-stationary environments. Client-side model selection dynamically chooses a subset of server-stored federated models to balance computational cost and prediction accuracy, mitigating the risk of forgetting in online learning. The weights assigned to local and federated models are adjusted using multiplicative updates based on prediction losses, achieving a balance between local adaptation and global generalization. Theoretical analysis demonstrates sublinear regret bounds. Periodic server storage of federated models is crucial for handling non-convex models, preventing catastrophic forgetting, and allowing efficient personalized model construction.
Personalized Regret Bounds#
The concept of “Personalized Regret Bounds” in federated learning is crucial because it addresses the inherent heterogeneity of client data distributions. Standard federated learning often assumes similar data distributions across clients, leading to suboptimal results for clients with unique data characteristics. Personalized bounds directly account for the variability in individual client data, thus offering stronger theoretical guarantees on the performance of personalized models. This is essential for applications where individual client accuracy is vital. The analysis typically involves comparing a client’s cumulative loss to that of an oracle that knows the true data distribution for each client in advance, providing a measure of how well a personalized model adapts to its specific data. Research in this area frequently focuses on demonstrating sublinear regret, indicating that the model’s performance improves over time. This is a significant step towards ensuring fairness and effectiveness of federated learning, where personalized models are critical to cater to individual client needs. Further research should explore methods that provide tighter bounds while being less computationally expensive, as the complexity of personalization can often hinder practical deployment.
Non-Convexity Challenges#
The non-convexity of many machine learning models presents significant challenges in the context of federated learning, especially when dealing with online prediction and model fine-tuning. Gradient-based optimization methods, commonly used in federated learning, are prone to getting trapped in local optima, hindering the convergence to a globally optimal solution. In online settings, catastrophic forgetting becomes a major issue, where the model’s ability to perform well on previously encountered data degrades as it adapts to new, streaming data. This is exacerbated in federated learning by the non-i.i.d. nature of data across clients and the inherent communication constraints. Addressing non-convexity often requires employing sophisticated techniques like second-order optimization or exploring alternative loss functions. The development of effective algorithms needs to balance the need for personalization (adaptation to individual client data) and generalization (maintaining good performance on unseen data across clients). This necessitates careful consideration of model architecture, training strategies, and the trade-off between local model updates and global model aggregation.
Ensemble Model Analysis#
An Ensemble Model Analysis section would delve into the performance gains achieved by combining multiple models. It would examine whether the ensemble consistently outperforms individual models across various datasets and scenarios, and assess the impact of different ensemble methods (e.g., weighted averaging, voting). The analysis would likely cover the trade-offs between model diversity and accuracy, exploring the effect of model heterogeneity on the ensemble’s robustness. A key aspect would be determining the optimal number of models in the ensemble to balance performance and computational cost. Error analysis would dissect the ensemble’s shortcomings and investigate strategies for improvement. Finally, the analysis would connect the theoretical guarantees for the ensemble’s performance (if any) to the observed experimental results, providing a comprehensive evaluation of this approach to federated learning.
Future Research Scope#
Future research could explore extensions to non-convex models, addressing the limitations of current theoretical analysis. Investigating different model selection strategies and their impact on performance is also warranted. The effects of data heterogeneity and non-stationarity on the algorithm’s convergence and regret bounds could be further explored. Additionally, a comprehensive study on the algorithm’s scalability and communication efficiency in large-scale distributed environments is needed. Finally, applying Fed-POE to diverse real-world applications and evaluating its performance against existing state-of-the-art methods would provide valuable insights and demonstrate practical applicability.
More visual insights#
More on tables
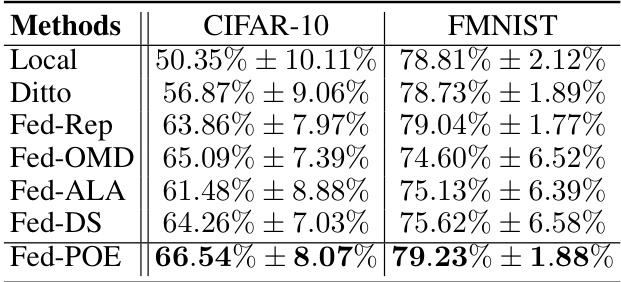
This table presents the average accuracy and standard deviation across 20 clients for image classification tasks using different federated learning algorithms on CIFAR-10 and FMNIST datasets. The results show the performance of each algorithm in terms of classification accuracy and the variability in performance among the clients.

This table presents the average accuracy and standard deviation achieved by the Fed-POE algorithm on the CIFAR-10 image classification dataset. It shows the impact of varying two key hyperparameters: the number of models (M) selected from the server’s stored models and the batch size (b) used during each local model update. The results reveal the performance trade-offs between model diversity (M) and the potential for overfitting to recent data (b), guiding the selection of optimal hyperparameters for different data and computational constraints.

This table presents the average accuracy and standard deviation achieved by the Fed-POE algorithm on the CIFAR-10 image classification dataset. It shows the impact of varying two hyperparameters: the number of models (M) selected by each client at each time step to construct an ensemble model, and the batch size (b) used to update the model parameters. The results demonstrate the effect of different model selection and training strategies on model performance.
Full paper#



















