↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement learning (RL) often struggles with continuous action spaces due to inefficient exploration of irrelevant actions. This issue is particularly prominent in complex tasks and safety-critical domains. Current techniques to address this problem usually employ discretization or penalization, which can limit performance.
This research introduces three continuous action masking methods to enhance RL training. These methods intelligently constrain exploration by only considering relevant actions determined using task knowledge and system dynamics. The generator, ray, and distributional masking methods are evaluated, showcasing their efficiency and effectiveness in reaching higher rewards and converging faster than the baseline without masking. The paper provides theoretical derivations for integrating the masking methods into the RL process, enhancing the algorithm’s predictability.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the significant challenge of sample inefficiency in reinforcement learning with continuous action spaces. By introducing novel action masking methods, it offers a practical solution to improve both training speed and final reward, opening new avenues for applying RL in various complex and safety-critical applications. The research also provides valuable theoretical insights into integrating action masking into existing RL algorithms.
Visual Insights#
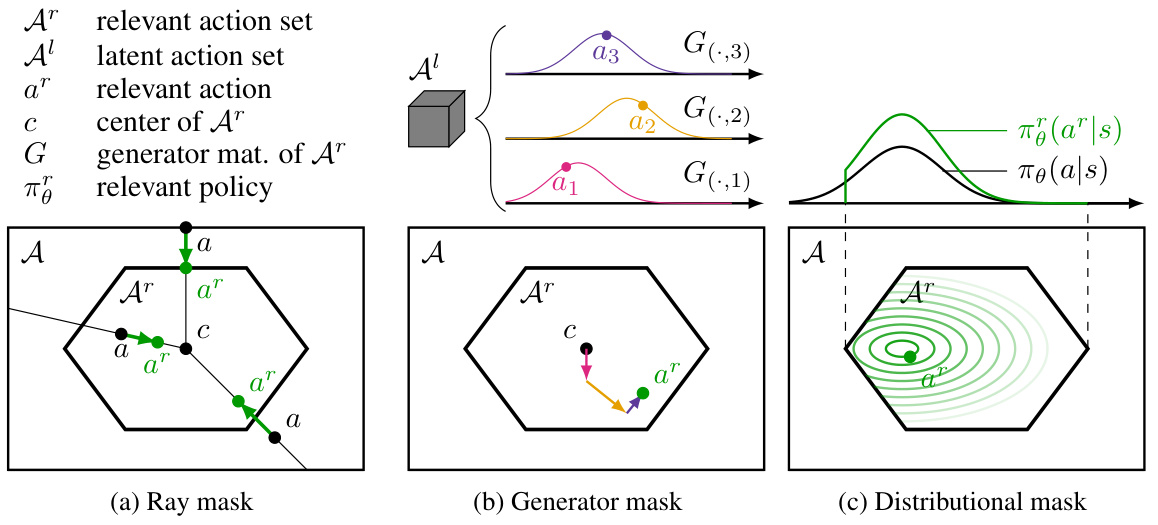
This figure illustrates three different continuous action masking methods. The hexagon represents the relevant action set (Ar) within a larger action space (A). (a) Ray Mask: Actions are scaled along rays originating from the center of Ar to its boundary. (b) Generator Mask: Uses a latent action space (A¹) that maps to Ar via a zonotope’s generator matrix (G). (c) Distributional Mask: Modifies the policy’s probability distribution to be zero outside Ar.

This table presents the mean and standard deviation of episode returns obtained from ten independent training runs for each of the five models (Baseline, Replacement, Ray Mask, Generator Mask, and Distributional Mask) across four different environments (Seeker, 2D Quadrotor, 3D Quadrotor, and Walker2D). The values provide a quantitative comparison of the performance of each model in each environment, showing the average reward achieved and the variability in performance across multiple training runs. The data reflects the final model performance after training completion.
In-depth insights#
Action Masking RL#
Action masking in reinforcement learning (RL) is a powerful technique to improve sample efficiency and stability by guiding the agent’s exploration towards relevant actions. By masking irrelevant actions, the algorithm avoids wasting resources on unproductive explorations, thus accelerating convergence and potentially enhancing performance. The effectiveness of action masking hinges on the accuracy and efficiency of identifying relevant actions. Various methods exist for achieving this, including handcrafted rules based on domain knowledge, data-driven approaches, or learning-based methods to dynamically adapt the mask during training. A key challenge lies in balancing the exploration-exploitation tradeoff; overly restrictive masks can limit the agent’s ability to discover novel solutions, while overly permissive ones negate the benefits of masking. Continuous action spaces present unique challenges, requiring more sophisticated techniques to map the continuous space to relevant action subsets. This often involves representing the relevant action set using flexible structures like convex sets (polytopes, zonotopes), enabling efficient computation of the mask and its gradient during backpropagation. Future research directions should focus on developing more robust and efficient methods for identifying relevant actions, particularly in complex and high-dimensional environments, and exploring the integration of action masking with other RL advancements to achieve further improvements in learning efficiency and performance.
Continuous Action#
In reinforcement learning, continuous action spaces, unlike discrete ones, allow for an infinite number of possible actions within a given range. This poses both challenges and opportunities. The challenge lies in the increased complexity of exploration and the need for efficient algorithms to handle the high-dimensional action space. Standard methods often struggle with sample inefficiency as they explore irrelevant actions. Addressing this, the concept of action masking emerges as a powerful technique to constrain exploration to a more relevant subset of actions, thereby significantly improving sample efficiency. This often involves utilizing task-specific knowledge to identify state-dependent sets of relevant actions. The benefits include faster convergence and better performance. However, the implementation of continuous action masking requires careful consideration, as it necessitates the development of methods that can effectively map the original continuous action space to the smaller, state-dependent relevant action set. Different approaches exist, each with its own strengths and limitations, impacting policy gradients and computational cost. The use of convex set representations like zonotopes, for example, offers a flexible and efficient approach for continuous action masking, but necessitates careful handling of the resulting policy gradients. Therefore, a thoughtful balance between effectiveness and computational efficiency is key.
Convex Set Masking#
The concept of “Convex Set Masking” in the context of reinforcement learning introduces a novel approach to action selection. It leverages the inherent structure of the problem by focusing learning on a state-dependent subset of actions defined by a convex set. This contrasts with traditional methods that operate across the entire action space, often wasting computational resources on exploring irrelevant or infeasible actions. The convexity constraint offers significant advantages by guaranteeing certain mathematical properties that simplify learning algorithms and improve convergence. This is especially beneficial in continuous action spaces where naive exploration strategies can be extremely inefficient. Different algorithms may be used to define and integrate the convex set constraint into the learning process, potentially leading to variations in computational cost and convergence speed. While this method may require more sophisticated mathematics compared to simpler action selection methods, the potential gains in efficiency and performance could be significant, especially for safety-critical applications or complex environments. Further research will likely focus on efficiently computing state-dependent convex sets and exploring the theoretical properties of various algorithms within this framework.
Policy Gradient Effects#
A thorough analysis of ‘Policy Gradient Effects’ within a reinforcement learning (RL) framework necessitates a multifaceted approach. Central to the investigation is the impact of action masking on the policy gradient, particularly in continuous action spaces. The core idea revolves around how restricting the agent’s actions to a state-dependent relevant subset alters the policy update rule. This involves understanding how the gradient calculation adapts to the masked space, and whether the modified gradient still effectively guides the agent toward optimal policy. Different masking methods (e.g., ray, generator, and distributional masks) will induce distinct effects on the gradient. A key consideration is the mathematical derivation of these effects; it would be essential to rigorously show how the proposed methods adjust the policy gradient calculation. Furthermore, the analysis should explore whether the modifications maintain convergence guarantees, particularly in the face of stochasticity in policy. An empirical investigation using various RL algorithms and benchmark tasks is essential to validate these theoretical findings. The experiments must quantify how the different masking methods impact learning efficiency and overall performance. Finally, a complete analysis needs to account for the computational complexity introduced by the action masking techniques and compare their performance against standard, unmasked RL approaches.
Future Work: Safety#
Concerning future safety research directions, a rigorous formal verification of the proposed action masking methods is crucial. This would involve proving that the methods indeed enhance safety and do not introduce unexpected vulnerabilities. Exploring alternative relevant action set representations beyond convex sets, potentially including non-convex sets or hybrid approaches, is vital to expand the applicability to a broader range of tasks. Furthermore, investigating the interaction between action masking and other safety mechanisms (e.g., safety constraints, fault tolerance) is necessary to ensure overall system robustness. The impact of masking on the sample efficiency of different RL algorithms needs additional study, especially in high-dimensional action spaces. Finally, developing efficient methods for computing relevant action sets in real-time for complex, dynamic systems is a major challenge requiring attention. Addressing these aspects would significantly advance the trustworthiness and reliability of the proposed approach in real-world safety-critical applications.
More visual insights#
More on figures

This figure illustrates the Seeker Reach-Avoid environment used in the paper’s experiments. It shows the state space (S), which is a 2D area where the agent (black dot) needs to reach the goal (gray square) while avoiding collision with a circular obstacle (red circle). The relevant action set (Ar) for the current state is highlighted in green within the overall action space (A). The reachable set (SΔt) at the next time step, given the relevant actions, is also shown.
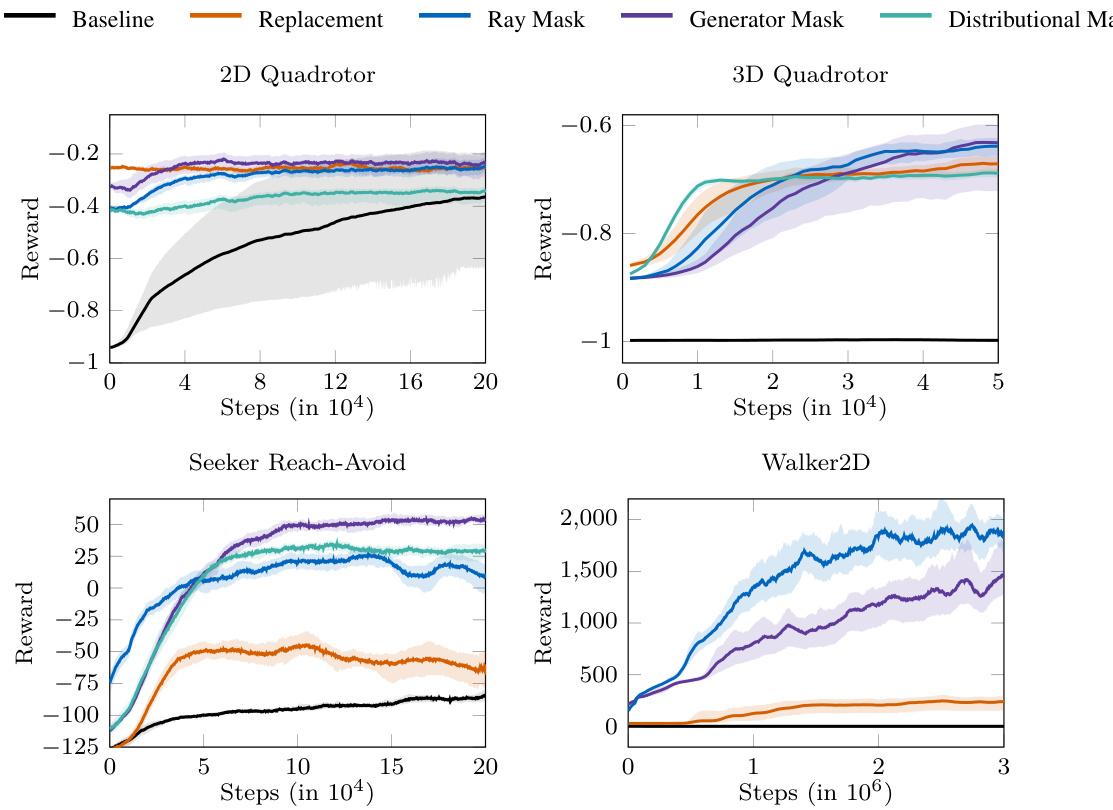
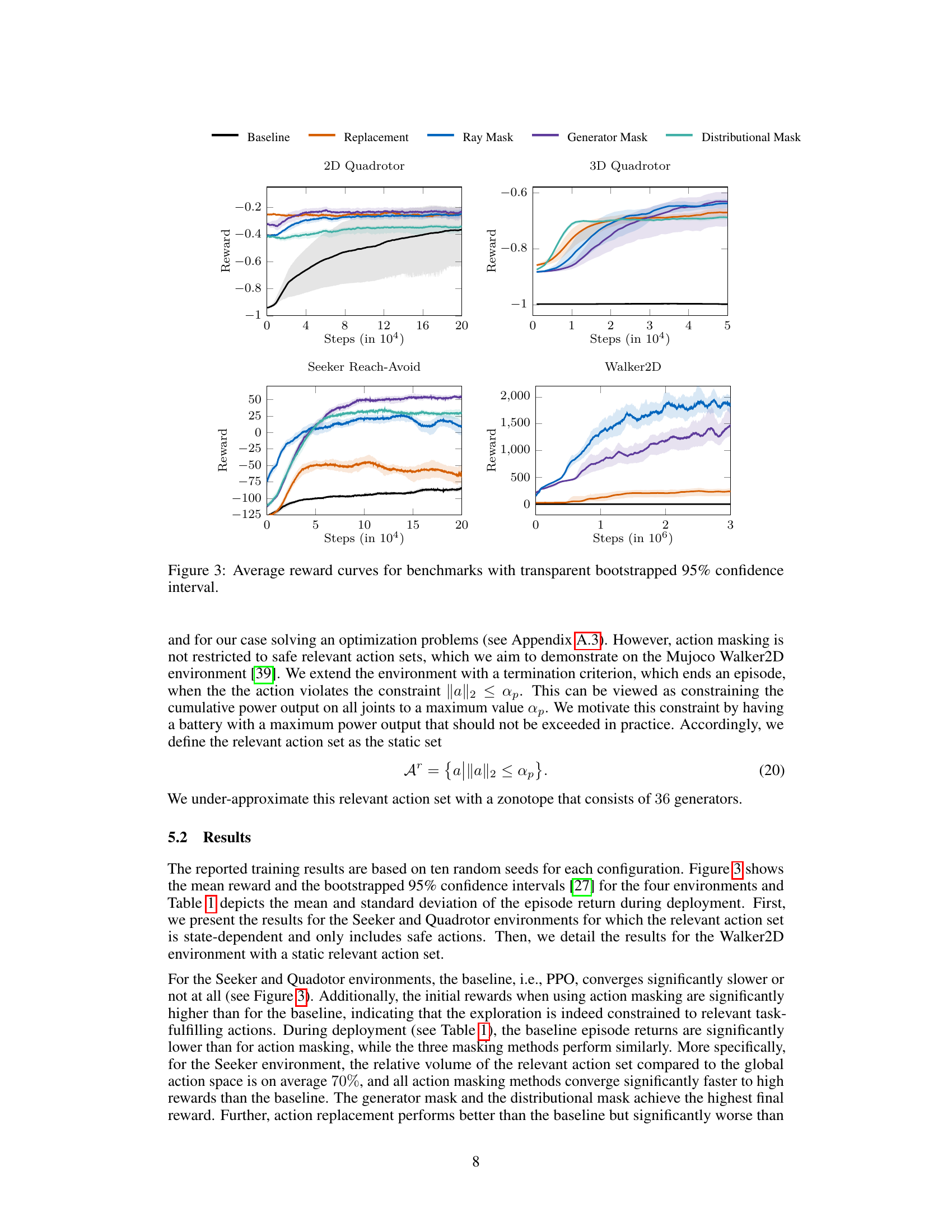
This figure presents the average reward curves for four different reinforcement learning benchmark environments (2D Quadrotor, 3D Quadrotor, Seeker Reach-Avoid, and Mujoco Walker2D). Each curve represents the performance of a different approach: Baseline (no action masking), Replacement (actions outside the relevant set are replaced by a sample from the relevant set), Ray Mask, Generator Mask, and Distributional Mask. The shaded regions around each line represent the 95% bootstrapped confidence intervals, indicating the variability in performance across multiple training runs. The figure shows the average reward accumulated over a certain number of training steps (time). This visualization allows for a comparison of the training efficiency and final performance of each method.
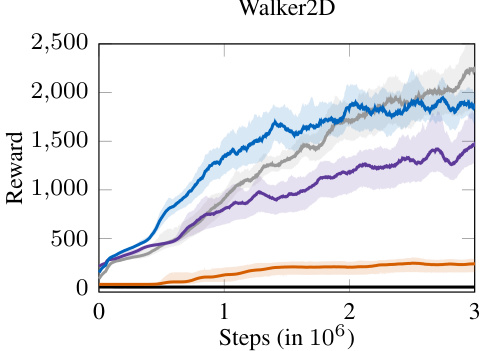
This figure presents the average reward curves obtained during training for four different reinforcement learning environments: Seeker Reach-Avoid, 2D Quadrotor, 3D Quadrotor, and Mujoco Walker2D. Each curve represents a different method for action masking: Baseline (no masking), Replacement (replacing invalid actions with random valid ones), Ray Mask, Generator Mask, and Distributional Mask. The shaded areas around each curve depict 95% bootstrapped confidence intervals, illustrating the variability in performance across multiple training runs. The graph shows the cumulative reward achieved over the course of training, indicating which methods lead to better performance and faster convergence.

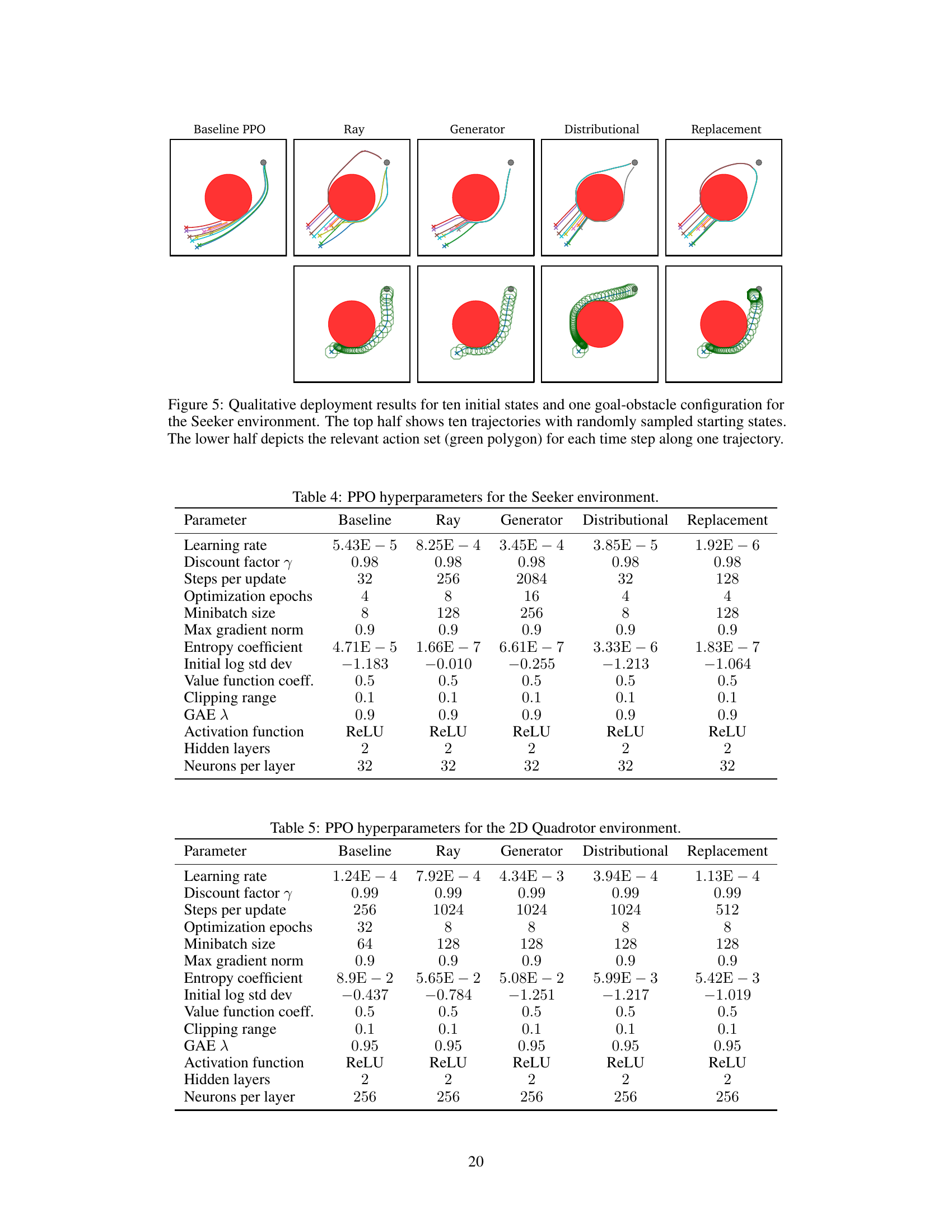
This figure shows ten example trajectories for each of the five reinforcement learning approaches used in the Seeker Reach-Avoid environment. The top panel displays the trajectories themselves. The bottom panel highlights the relevant action sets (green polygons) at each timestep for a single trajectory to illustrate how the action masking methods restrict the agent’s possible actions to a smaller, state-dependent set. The figure demonstrates that the action masking methods effectively guide the agent to reach the goal while avoiding collisions, which is not achieved by the baseline or replacement method.
More on tables
This table presents the mean and standard deviation of the episode return achieved by different reinforcement learning methods across ten independent runs. The methods compared include a baseline (PPO without action masking), a replacement method (replacing actions outside the relevant set with uniformly sampled actions), and the three proposed continuous action masking methods (Ray Mask, Generator Mask, and Distributional Mask). The results are shown for four different environments: Seeker, 2D Quadrotor, 3D Quadrotor, and Mujoco Walker2D.
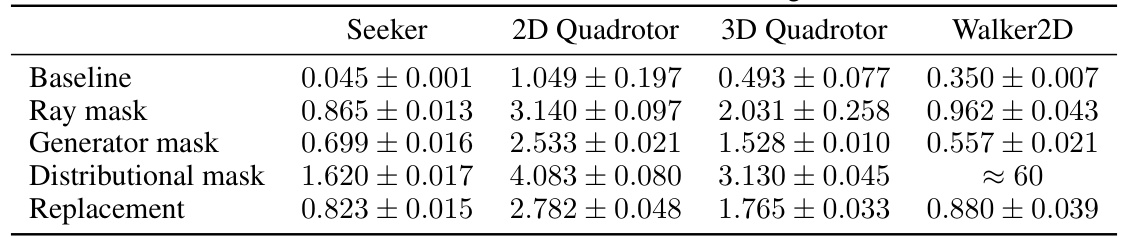
This table presents the mean and standard deviation of the episode return for each of the trained models across ten runs. The models include the baseline (no action masking), a replacement method, and the three proposed continuous action masking methods (Ray, Generator, and Distributional masks). The results are shown for four different environments: Seeker, 2D Quadrotor, 3D Quadrotor, and Walker2D. The table quantifies the performance of each method in each environment by providing a summary statistic across multiple trials.

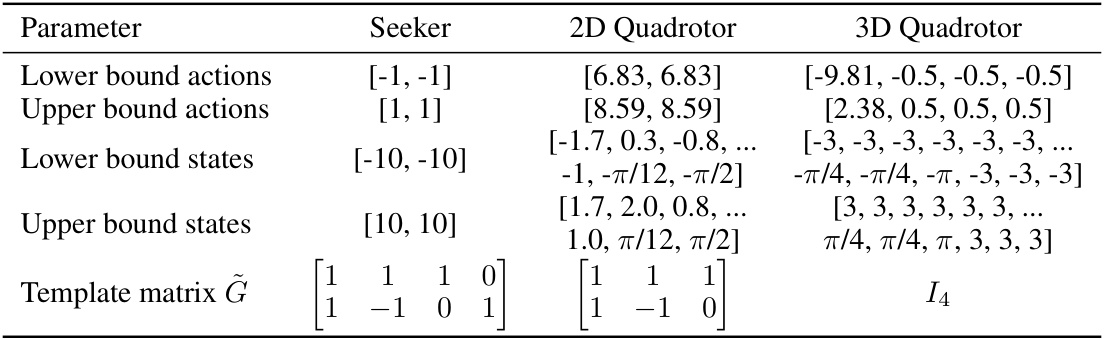
This table lists the hyperparameters used for the Proximal Policy Optimization (PPO) algorithm in the Seeker Reach-Avoid environment. It shows the settings for five different training configurations: the baseline PPO, Ray Mask, Generator Mask, Distributional Mask, and Replacement methods. Each row specifies a different hyperparameter, such as learning rate, discount factor, steps per update, and others. The values show how these parameters were tuned for each approach to optimize performance in this specific environment.

This table presents the hyperparameters used for the Proximal Policy Optimization (PPO) algorithm in the 2D Quadrotor experiment. It shows the settings used for the baseline (standard PPO) and the three action masking methods (Ray Mask, Generator Mask, and Distributional Mask), as well as the replacement agent. The hyperparameters include learning rate, discount factor, steps per update, optimization epochs, minibatch size, max gradient norm, entropy coefficient, initial log standard deviation, value function coefficient, clipping range, GAE lambda, activation function, hidden layers, and neurons per layer.
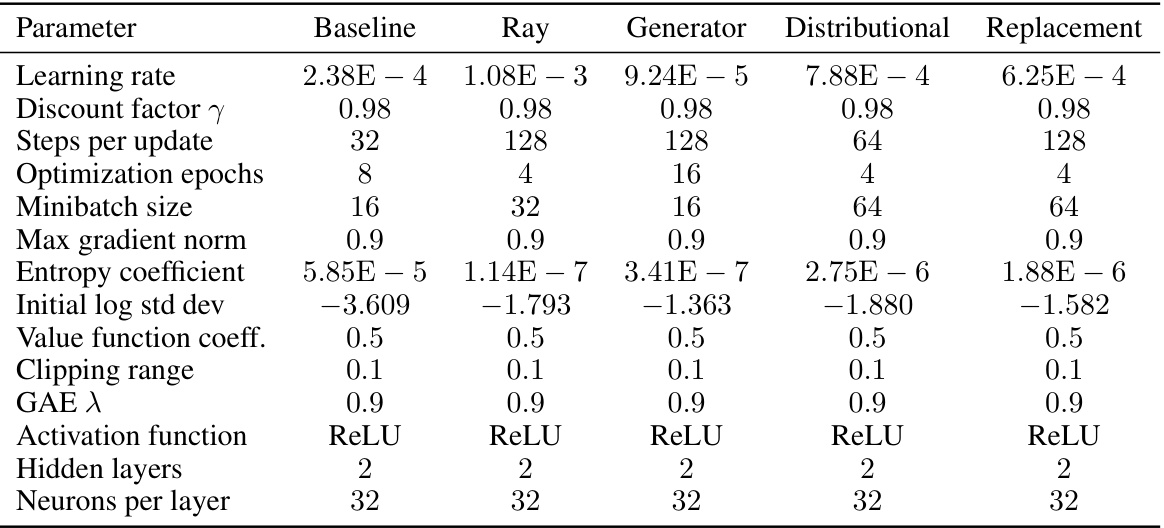
This table lists the hyperparameters used for the Proximal Policy Optimization (PPO) algorithm when training on the 3D Quadrotor environment. Different hyperparameter configurations are shown for each of five approaches: Baseline, Ray Mask, Generator Mask, Distributional Mask, and Replacement. Each row represents a specific hyperparameter (e.g., learning rate, discount factor, etc.), and each column displays the value used for that hyperparameter in each of the five training approaches. The hyperparameter settings were obtained through hyperparameter optimization with 50 trials for each method.

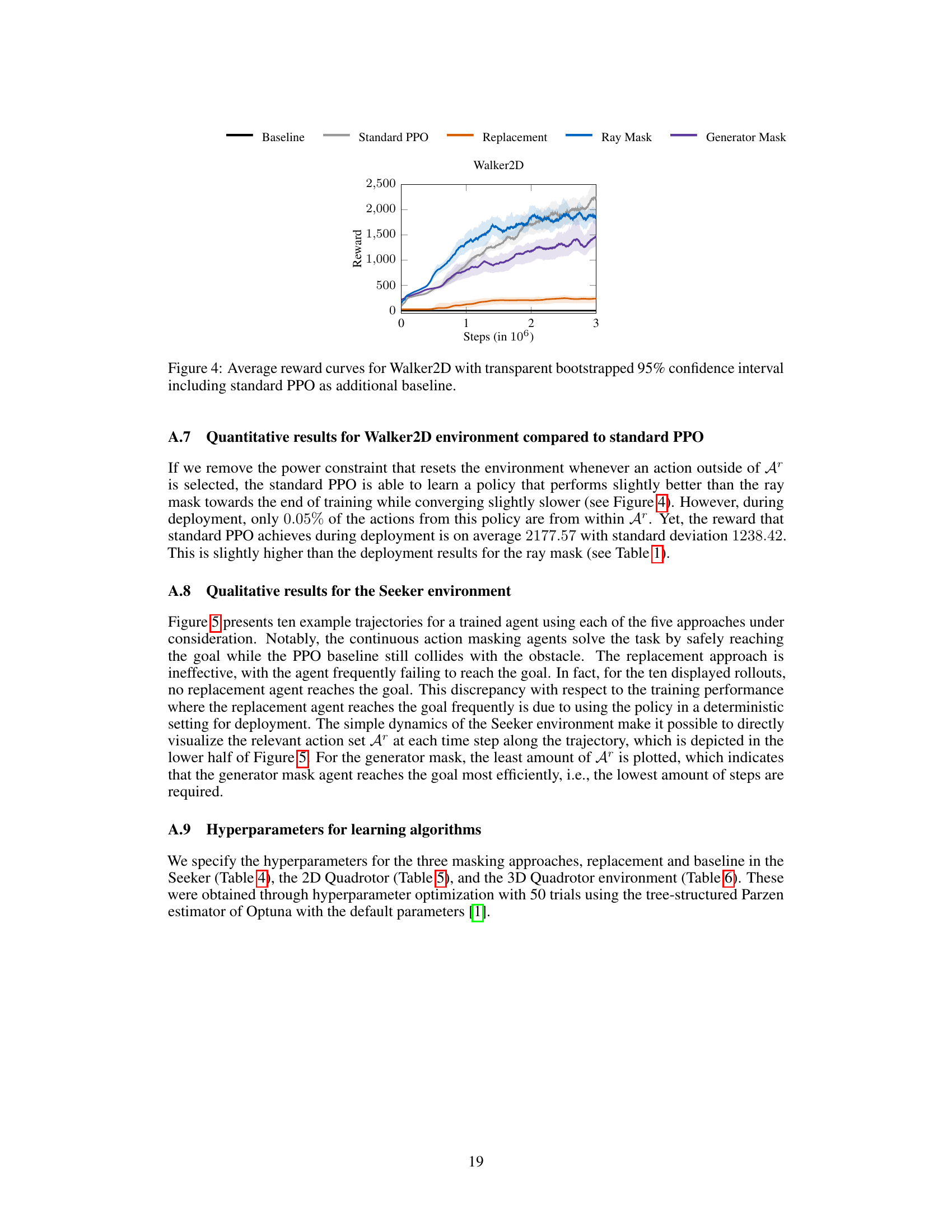
This table lists the hyperparameters used for training the Proximal Policy Optimization (PPO) algorithm in the MuJoCo Walker2D environment. It compares hyperparameter settings across five different training runs: the baseline PPO, a replacement method, and three continuous action masking methods (ray mask, generator mask, and distributional mask). Each row represents a specific hyperparameter, and each column shows the value used for each of the five training runs.
Full paper#