↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing Video Anomaly Detection (VAD) methods primarily focus on single-domain learning, limiting their applicability to diverse real-world scenarios. A key challenge is the inconsistency in defining ‘abnormality’ across different datasets, leading to poor generalization. This research highlights the need for a more robust and generalized approach to VAD.
To address this, the paper introduces a new task called Multi-Domain VAD (MDVAD). They propose a novel framework using multiple instance learning and an abnormal conflict classifier to handle the conflicting definitions of abnormality across multiple datasets. Their experiments demonstrate that this approach is highly effective in improving the generalization and adaptability of VAD models across various domains, paving the way for more robust and reliable video anomaly detection systems.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel task, MDVAD (Multi-Domain learning for Video Anomaly Detection), addressing the limitations of single-domain VAD models. It proposes a new benchmark and baselines to handle the challenging issue of ‘Abnormal Conflicts’ across different datasets, improving the generalizability and robustness of VAD models. This opens new avenues for research in more generalized and adaptable video anomaly detection systems.
Visual Insights#
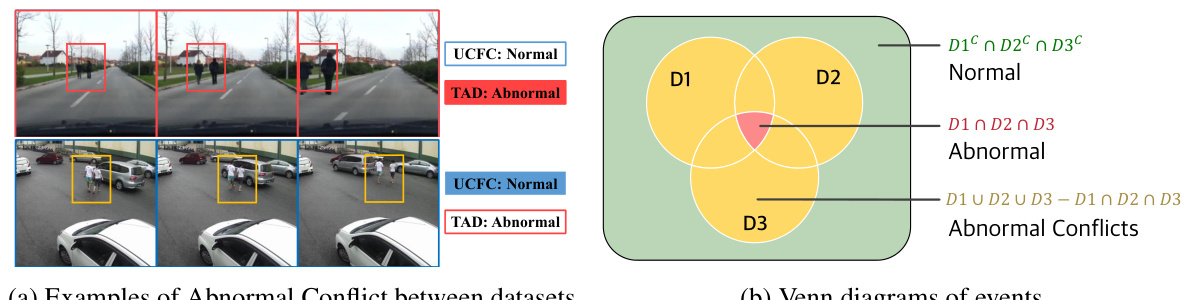
This figure illustrates the concept of ‘abnormal conflict’ in multi-domain video anomaly detection (VAD). (a) shows an example where a pedestrian on a road is considered normal in one dataset (UCFC) but abnormal in another (TAD). This highlights the inconsistency in defining ‘abnormal’ across different datasets. (b) uses Venn diagrams to represent datasets as circles. The overlapping regions show common normal and abnormal events, while the non-overlapping regions represent unique events in each dataset. The area outside all circles but within the outer shape represents the ‘Abnormal Conflicts’ – situations where an event is considered abnormal in some datasets but normal in others. The goal of Multi-Domain VAD (MDVAD) is to build a model that accurately accounts for these conflicts to achieve better generalization across different domains.
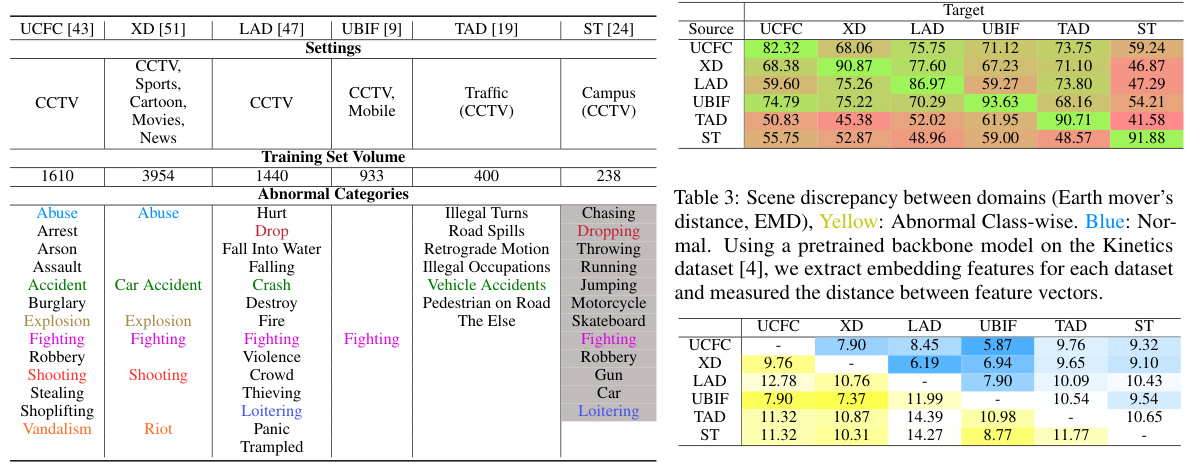
This table presents the Earth Mover’s Distance (EMD) between different video anomaly detection (VAD) datasets. The EMD measures the visual similarity between datasets, considering both normal and abnormal classes separately. A lower EMD indicates higher visual similarity. The results highlight the scene discrepancy between the datasets due to differences in environment and anomaly categories, making multi-domain learning more challenging.
In-depth insights#
Multi-Domain VAD#
Multi-Domain Video Anomaly Detection (MDVAD) tackles the limitations of single-domain VAD models, which struggle to generalize across diverse datasets. Traditional VAD trains and evaluates models on a single dataset, leading to poor performance when applied to unseen data with different abnormality criteria. MDVAD addresses this by training a single model on multiple datasets simultaneously. This approach aims to learn generalizable representations of normal and abnormal events, enabling better performance in diverse, real-world scenarios. However, a major challenge arises from what the authors term “Abnormal Conflicts” — situations where an event is considered normal in one dataset but abnormal in another. MDVAD necessitates innovative techniques to handle these conflicts and learn robust, domain-agnostic features. The authors introduce new benchmark datasets, baselines, and evaluation protocols to facilitate research in this area, highlighting the significance of understanding and mitigating abnormal conflicts for creating truly generalizable video anomaly detection systems.
Abnormal Conflicts#
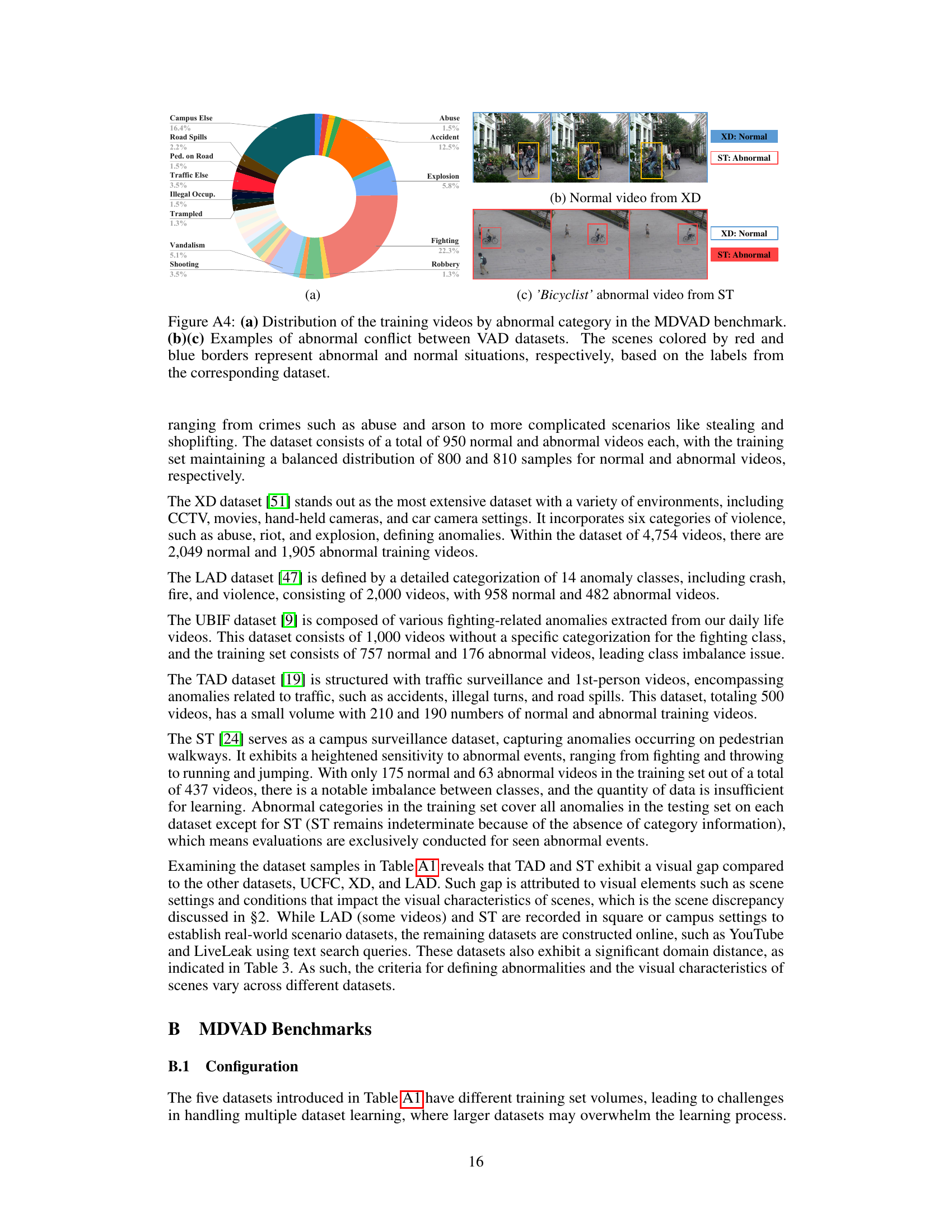
The concept of “Abnormal Conflicts” in the context of video anomaly detection (VAD) highlights a critical challenge in building generalizable models. Different VAD datasets often have varying definitions of what constitutes an anomaly, leading to conflicts where an event deemed normal in one dataset is labeled abnormal in another. This inconsistency severely hinders the training of a general VAD model capable of performing well across multiple domains. The core issue is the lack of universally consistent labeling standards for abnormal events across datasets. Addressing this requires innovative approaches such as multi-domain learning techniques that can effectively handle these conflicts, potentially through specialized loss functions or architectural modifications that account for domain-specific variations in anomaly definitions. The existence of ambiguous or conflicting labels introduces significant noise into the training process, impacting the model’s ability to learn general representations of both normal and abnormal behavior. This necessitates careful consideration of data curation, labeling strategies, and model architectures to mitigate the adverse effects of abnormal conflicts on the performance and generalizability of VAD models. Future research needs to focus on developing robust methods to identify and handle these conflicts, ultimately paving the way for more effective and generalizable VAD systems.
NullAng-MIL#
NullAng-MIL, a proposed loss function, addresses limitations in multi-domain video anomaly detection by incorporating angular margin into the Multiple Instance Learning (MIL) framework. It tackles the “Abnormal Conflict” problem, where events labeled as abnormal in one domain might be normal in another. Unlike standard MIL, which uses a single head to score abnormality, NullAng-MIL utilizes multiple heads, one per domain. Each head independently learns abnormality criteria for its respective domain. To prevent conflicts, the outputs of inactive heads are nullified (Null), focusing the learning on the relevant domain. By using an angular margin, NullAng-MIL encourages larger separation between normal and abnormal feature vectors in the cosine space. This enhances discriminative power and improves the model’s ability to generalize across various domains. The angular margin helps handle intra-class variance within each domain, making the model more robust. This approach is particularly beneficial when dealing with diverse, real-world scenarios where the definition of abnormality is context-dependent. Furthermore, combining NullAng-MIL with an “Abnormal Conflict” classifier aids in identifying ambiguous cases and increases overall performance.
MDVAD Benchmark#
The MDVAD Benchmark’s core strength lies in its holistic approach to evaluating generalizability in video anomaly detection (VAD). It moves beyond single-domain evaluations, a common limitation in VAD research. By incorporating multiple datasets with diverse scenarios and varying definitions of ‘abnormal,’ the benchmark directly addresses the challenge of real-world application where a model must handle unseen situations. The inclusion of datasets with varying characteristics (e.g., camera type, scene complexity, annotation quality) is crucial for assessing robustness. The multiple evaluation protocols (held-in, leave-one-out, low-shot adaptation, full fine-tuning) further enhance the rigor, providing insights into a model’s adaptability to new domains and data scarcity scenarios. However, potential limitations could include the representativeness of selected datasets and the computational cost associated with training and evaluating across multiple domains. Future improvements could involve expanding the number of datasets, incorporating more detailed annotations, and perhaps investigating the impact of specific dataset characteristics on model performance.
Future of VAD#
The future of Video Anomaly Detection (VAD) hinges on addressing its current limitations, particularly generalization across diverse domains and handling ambiguous ‘abnormal conflicts’. Multi-domain learning is crucial for building robust, adaptable models that can perform well in various real-world scenarios. Future research should focus on developing more effective methods to identify and resolve abnormal conflicts, potentially through innovative loss functions or specialized architectures. Addressing scene discrepancy between datasets is also vital for improved generalization. Advancements in unsupervised and weakly-supervised learning will be key, as they can reduce the need for extensive labeling efforts. Finally, the development of comprehensive benchmark datasets that encompass a wider range of scenarios and abnormal events will be essential for fostering more robust and generalizable VAD models. Combining modalities, such as integrating audio and other sensor data with video, holds promise for enhanced accuracy and contextual understanding. The ethical considerations surrounding VAD, especially concerning privacy and potential misuse, must also be carefully addressed.
More visual insights#
More on figures
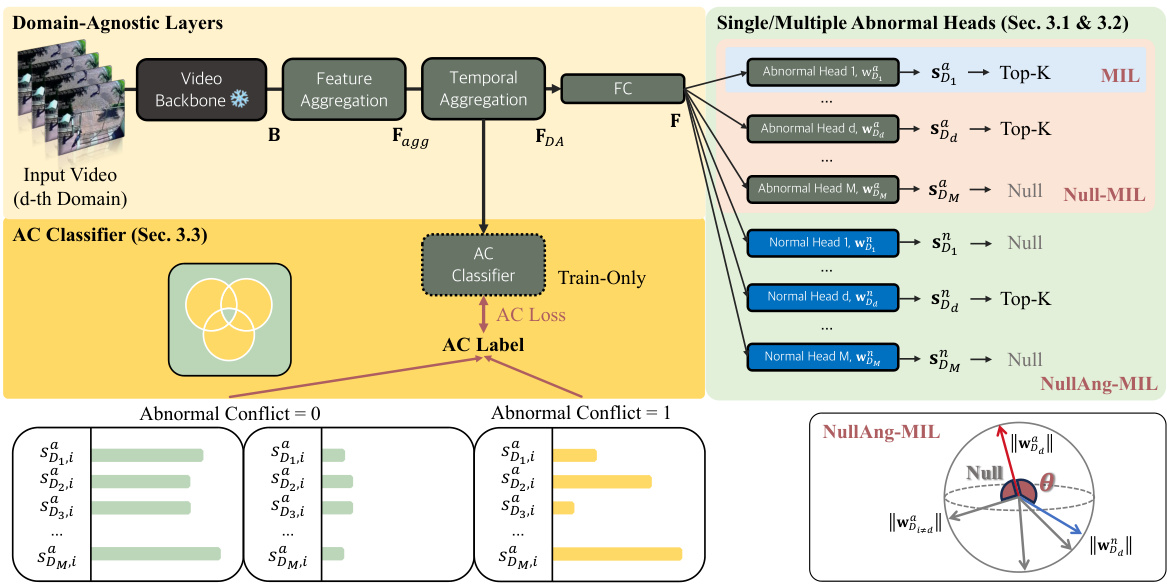
This figure illustrates the architecture of the proposed Multi-Domain Video Anomaly Detection (MDVAD) framework. It is composed of three main parts: domain-agnostic layers, single/multiple abnormal heads, and an abnormal conflict (AC) classifier. The domain-agnostic layers process input videos to extract general features. The abnormal heads then predict abnormality scores for each domain, handling abnormal conflicts using different methods (single head, Null-MIL, or NullAng-MIL). The AC classifier helps the model learn conflict-aware features by predicting whether an abnormal conflict exists. The framework aims to improve the generalizability and robustness of VAD models across multiple domains.

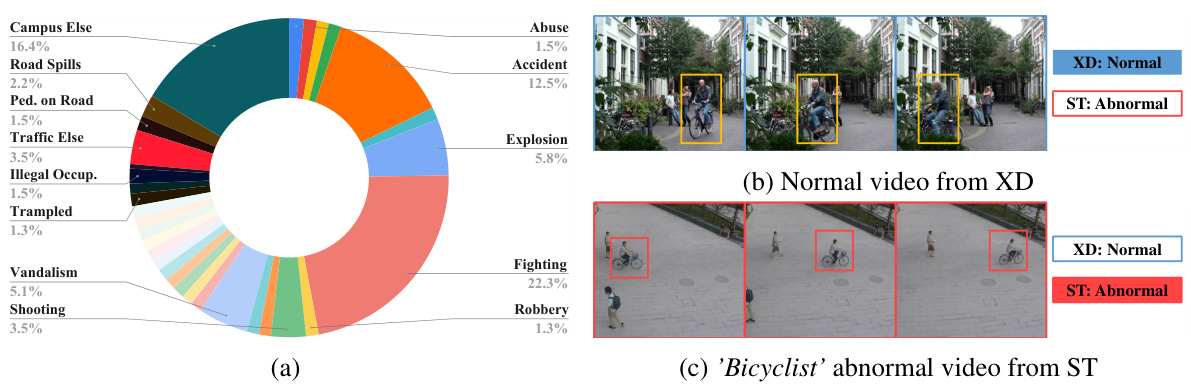
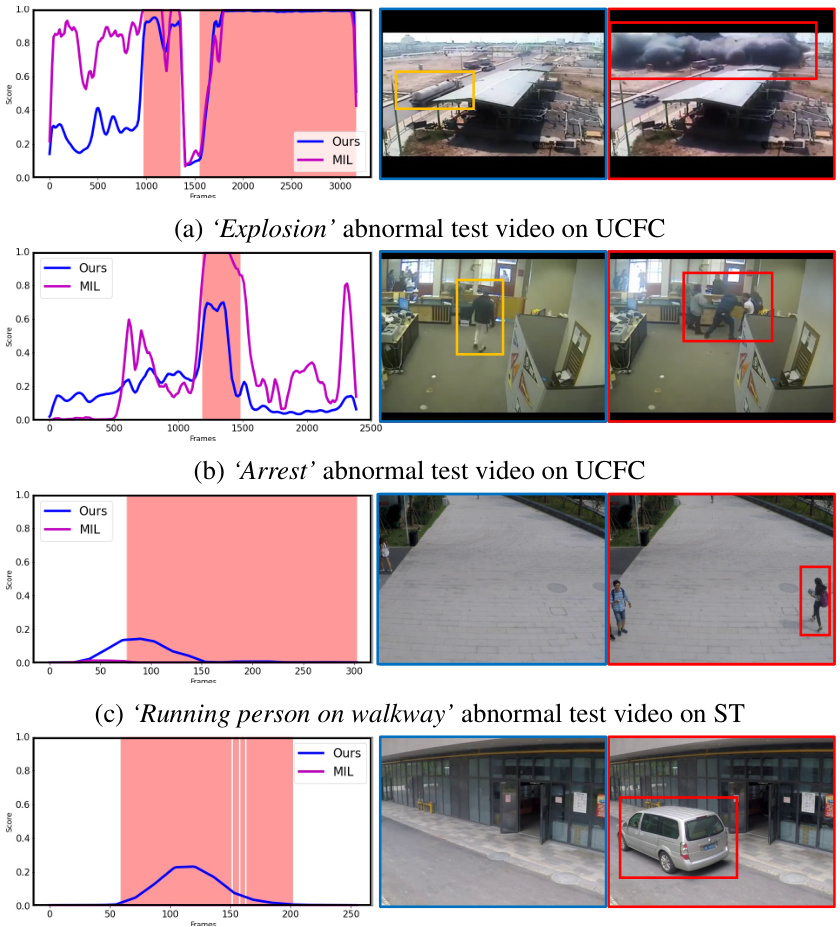
This figure shows the results of the AC classifier and qualitative examples. Figure 3(a) plots AC scores for two scenes from the UCFC dataset; one showing an example of abnormal conflict (a pedestrian on the road, which is considered normal in UCFC, but abnormal in ST), and one showing a normal scene. Figure 3(b) presents qualitative results with examples of the model correctly identifying abnormal events (bicyclist on walkway, accident) and an example of abnormal conflict (pedestrian on the road). The red boxes highlight the abnormal events in the images.
This figure illustrates the concept of ‘Abnormal Conflict’ in multi-domain video anomaly detection (VAD). Subfigure (a) shows a scenario where a pedestrian on the road is considered normal in one dataset (UCFC) but abnormal in another (TAD). This discrepancy highlights the challenges of applying single-domain VAD models to other domains. Subfigure (b) uses Venn diagrams to visualize how MDVAD aims to create a general model that accurately distinguishes between general normal and abnormal events across multiple domains while acknowledging these ambiguous conflicts.
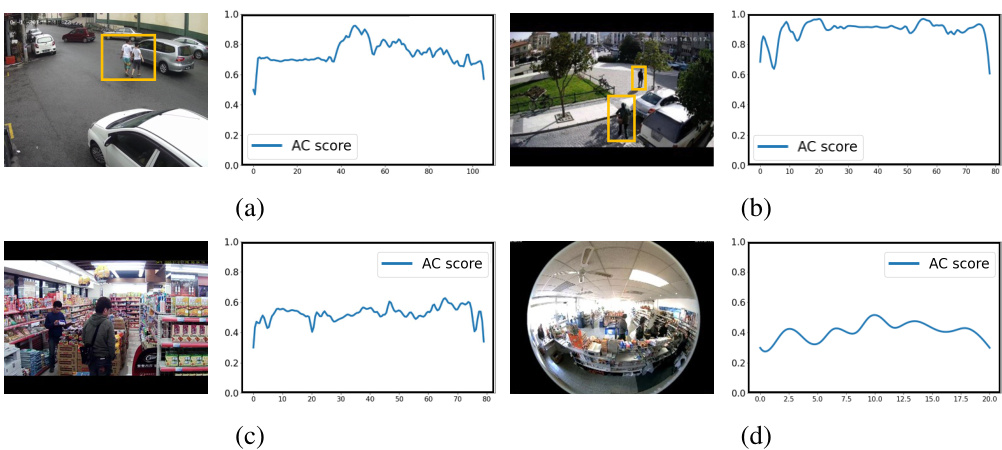
This figure shows the results of the Abnormal Conflict (AC) classifier and qualitative examples. Part (a) plots AC scores for two normal UCFC scenes; one exhibiting abnormal conflict (abnormal in ST, normal in UCFC), and another showing a purely normal scene. Part (b) gives visual examples of abnormal events (red boxes), with the top row displaying a bicyclist on a walkway (abnormal in ST), and the bottom showing an accident (abnormal in UCFC) and a pedestrian on a road (abnormal conflict; normal in UCFC, abnormal in TAD).
This figure illustrates the architecture of the proposed MDVAD (Multi-Domain Video Anomaly Detection) framework. It’s composed of three main parts: domain-agnostic layers (shared across all domains), single/multiple abnormal heads (one or more per domain, depending on the model variant), and an Abnormal Conflict (AC) classifier. The domain-agnostic layers process input videos to extract domain-invariant features. These features are then fed to the single or multiple abnormal heads, with each head specializing in a specific domain and predicting abnormal scores. Finally, the AC classifier helps to distinguish between actual abnormal events and ambiguous events arising from conflicting definitions of abnormality across domains. This design aims to create a more generalizable video anomaly detection model capable of handling diverse real-world scenarios.
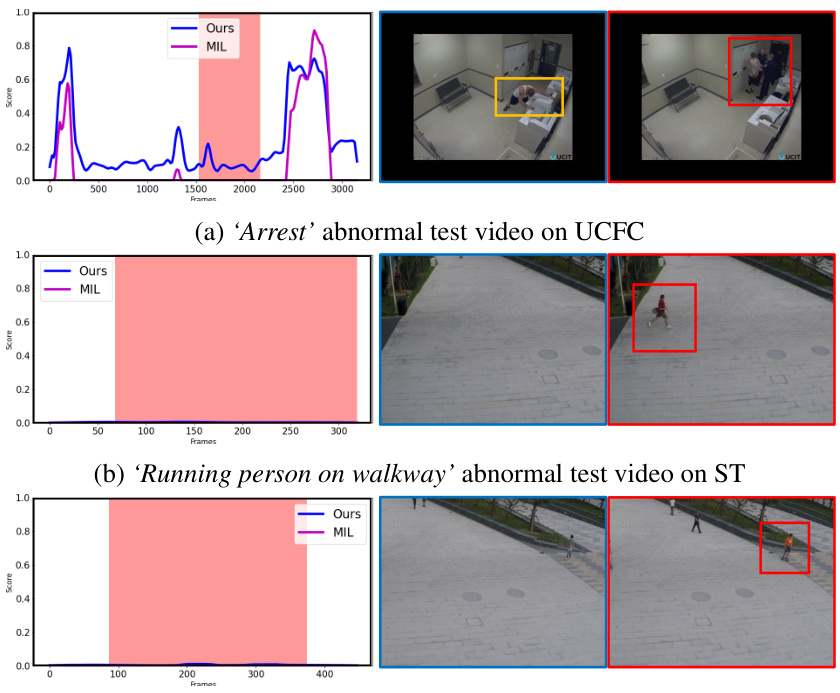
Figure 3 presents qualitative and quantitative results of the proposed approach. Subfigure (a) shows the AC (Abnormal Conflict) scores for two example scenes from the UCFC dataset. One scene (top) illustrates an abnormal conflict, where the scene is normal in UCFC but abnormal in another dataset (ST). The other scene (bottom) is a normal scene in both datasets. Subfigure (b) shows qualitative results, focusing on videos containing abnormal events (red boxes). Specifically, one example demonstrates a bicyclist on the walkway classified as an abnormal event in ST but not in other datasets. The other depicts an accident scene (normal in ST) which is deemed abnormal in both UCFC and TAD, and an example of a pedestrian on the road classified as abnormal in TAD and normal in UCFC. These examples showcase the model’s ability to recognize domain-specific abnormal events while handling conflicts between abnormal event definitions in different datasets.
More on tables
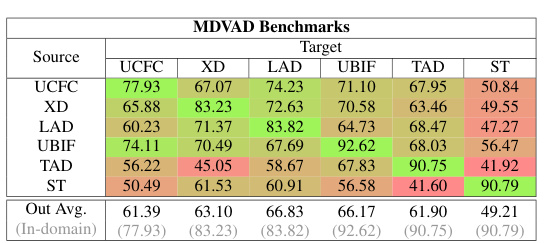
This table presents the Area Under the Curve (AUC) scores achieved by single-domain models. The diagonal elements represent the in-domain performance (where training and testing datasets are the same), while the off-diagonal elements show the cross-domain performance (where the training and testing datasets differ). This table highlights how well single-domain models generalize to different datasets. Low scores in off-diagonal elements indicate poor cross-domain generalization.

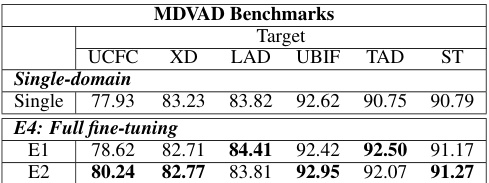
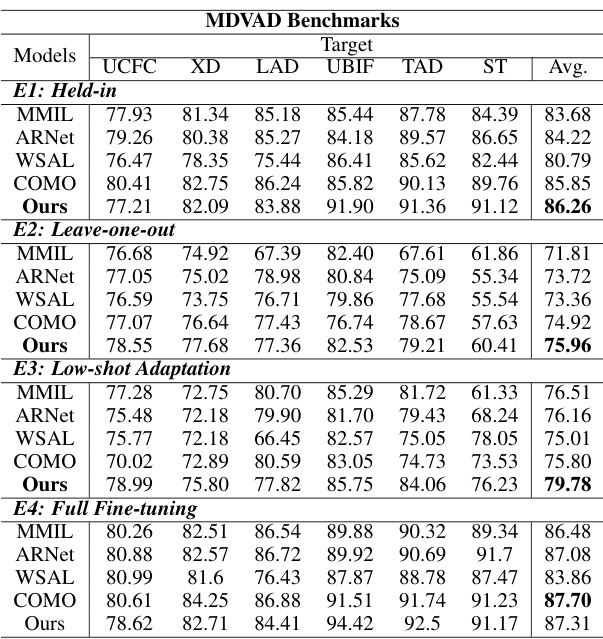
This table presents the Area Under the Curve (AUC) results for the held-in evaluation protocol (E1) of the MDVAD benchmark. The held-in protocol evaluates the model’s performance as a unified model trained on all six datasets, then tested on each dataset individually. The table shows the AUC scores for each dataset (UCFC, XD, LAD, UBIF, TAD, ST) for several different models, including the single-head MIL baseline and the proposed Null-MIL and NullAng-MIL models with and without the AC classifier. This allows for a direct comparison of the performance of single-domain models versus multi-domain models in a unified setting.
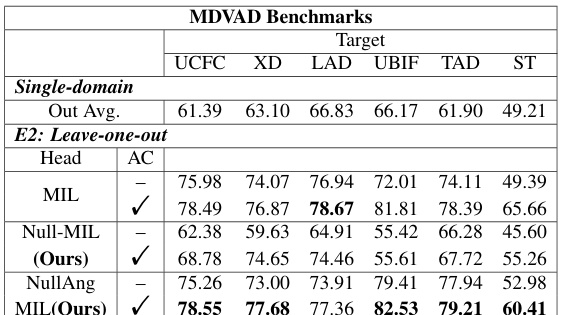
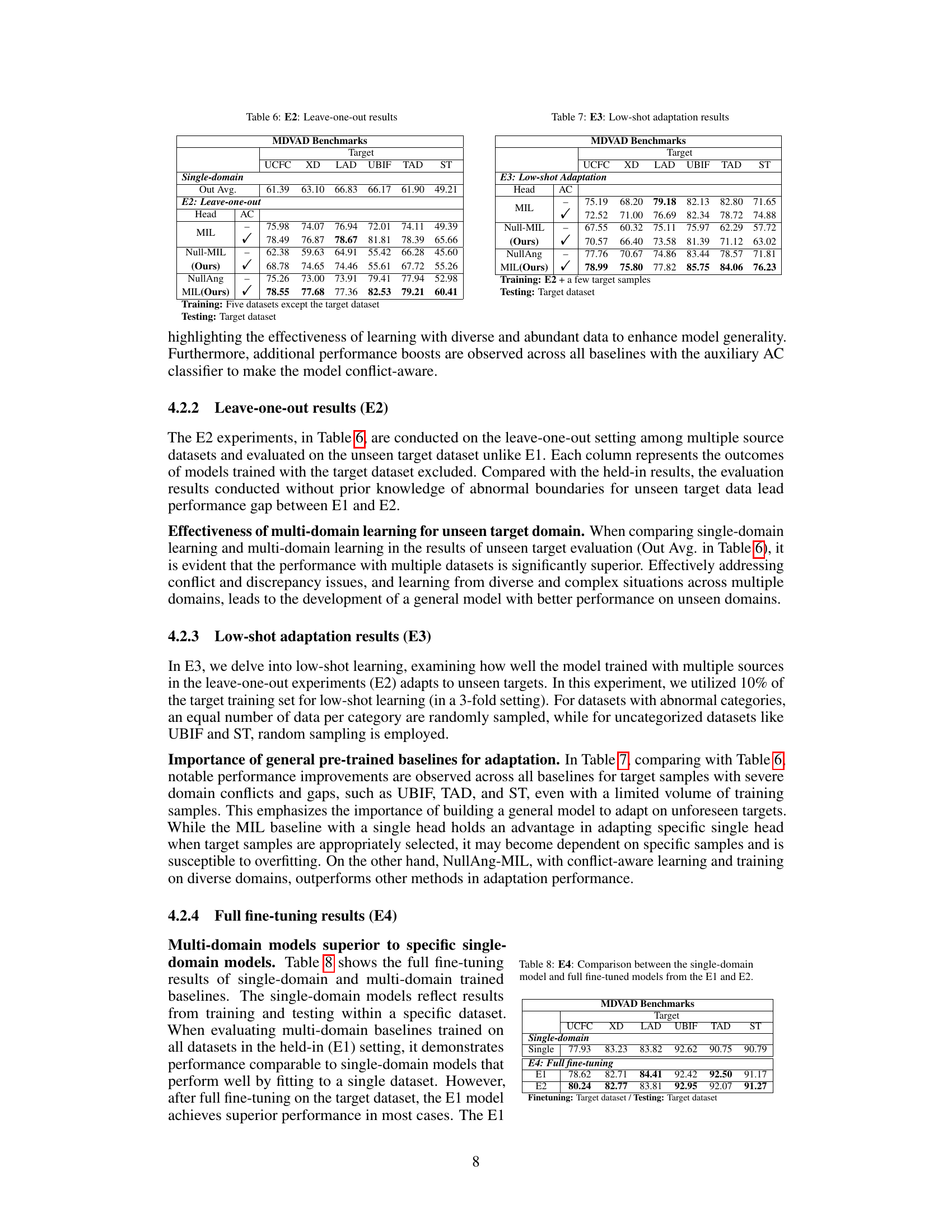
This table presents the results of leave-one-out experiments (E2) for the MDVAD benchmark. It shows the performance of various models (MIL, Null-MIL, NullAng-MIL) when one dataset is held out from training and the model is evaluated on that held-out dataset as the test set. The results are presented as AUC scores and highlight how well the models generalize to unseen domains, particularly in the face of ‘abnormal conflicts’ (differences in how abnormalities are defined across datasets).
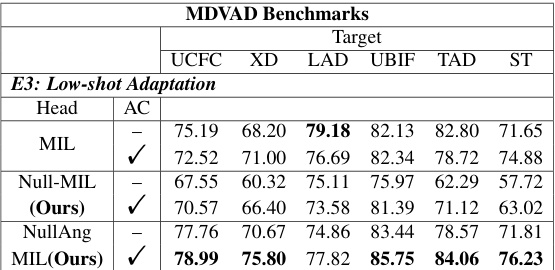
This table presents the results of the low-shot adaptation experiments (E3). In these experiments, the models were trained using multiple source datasets, except for the target dataset, and then fine-tuned using only 10% of the target dataset’s training samples. The table shows the AUC scores achieved by various models (MIL, Null-MIL, NullAng-MIL) on each target dataset (UCFC, XD, LAD, UBIF, TAD, ST) with and without the AC classifier. It highlights how well different models adapt to unseen domains with limited training data. The results demonstrate the effectiveness of multi-domain learning in handling unseen scenarios, especially for datasets with significant domain conflicts or ambiguities.
This table presents the Area Under the Curve (AUC) scores for the held-in evaluation protocol (E1) of the MDVAD benchmark. The held-in protocol evaluates the model’s performance as a unified model trained on all six datasets simultaneously. The table shows the AUC scores for each of the six datasets used in the benchmark (UCFC, XD, LAD, UBIF, TAD, and ST) when used as the target dataset. The results are presented for three different baselines: the single-domain MIL baseline and the proposed Null-MIL and NullAng-MIL multi-domain baselines. The ‘Out Avg.’ column represents the average AUC score across all six target datasets.
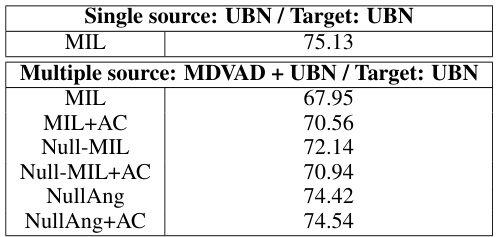
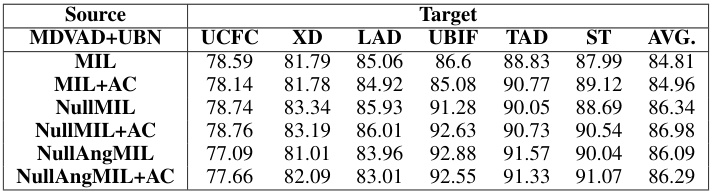
This table presents the ablation study results on the UBN dataset for open-set video anomaly detection. It compares the performance of different models, including the single-source model (trained only on UBN) and multiple-source models (trained on MDVAD and UBN). The models tested include the basic MIL model and variations incorporating the AC classifier and Null(Ang)-MIL. The results highlight the effectiveness of using multiple datasets to build more generalizable models, particularly when dealing with unseen anomalies and domain shifts.
This table presents the Area Under the Curve (AUC) scores achieved by different models on the MDVAD benchmark using a held-in evaluation protocol. The models were trained on all six datasets simultaneously and then evaluated on each dataset individually as a ‘held-in’ test. The table shows the average AUC across all datasets and the individual AUC scores for each dataset. This helps to assess the performance of each model as a unified model that can perform well across diverse domains, indicating the effectiveness of multi-domain training.
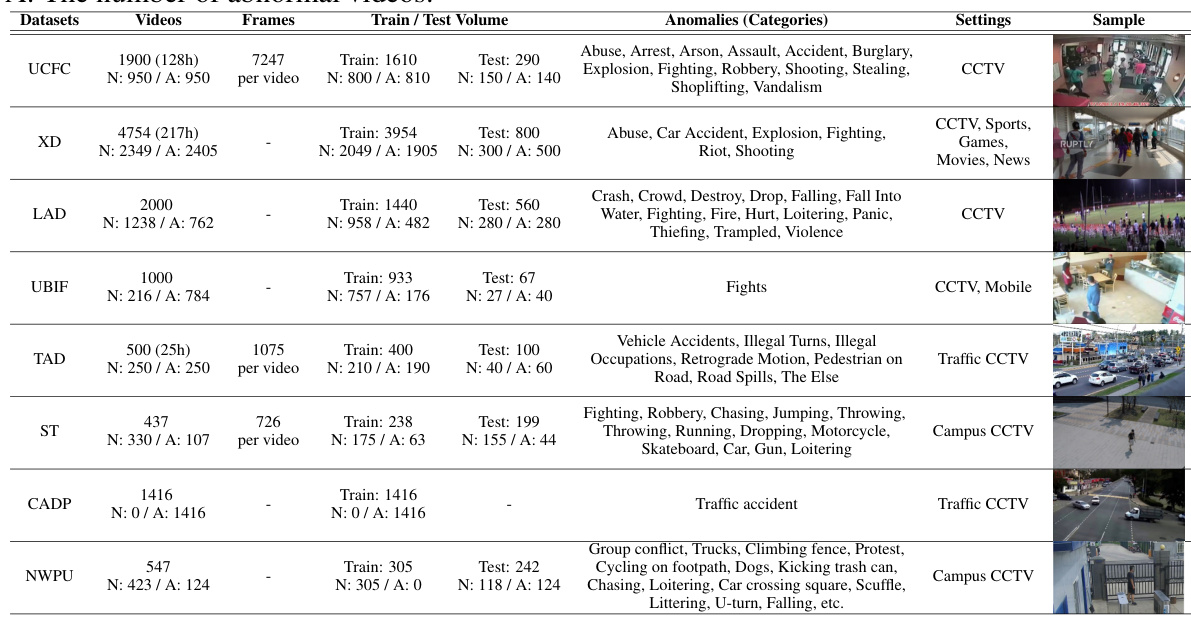
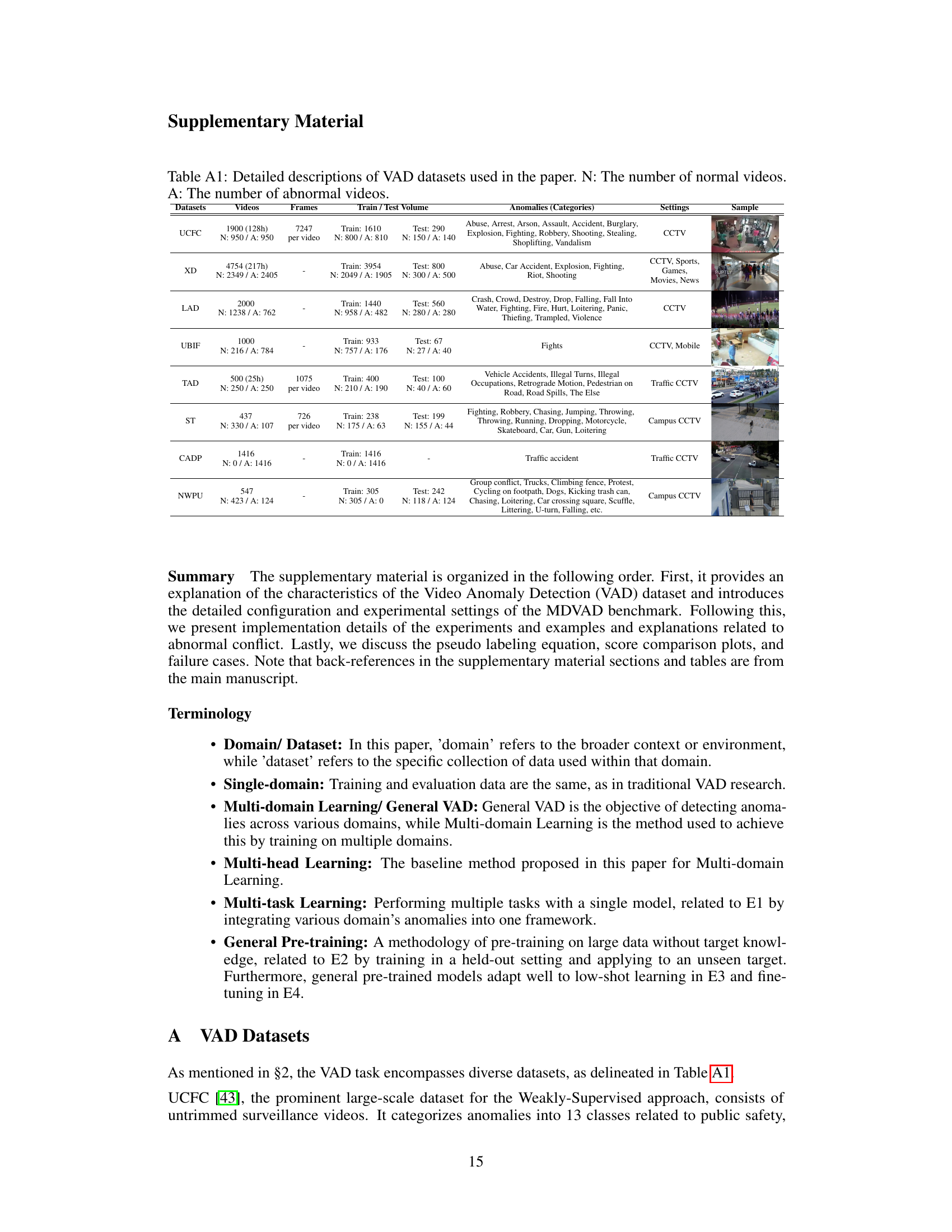
This table provides detailed information about the six video anomaly detection (VAD) datasets used in the paper. For each dataset, it lists the number of normal and abnormal videos, the number of frames per video, the training and testing set volumes, the types of anomalies present, and the setting (e.g., CCTV, traffic) in which the videos were recorded. Additional information about the CADP and NWPU datasets that are combined with TAD and ST datasets, respectively, is also included.
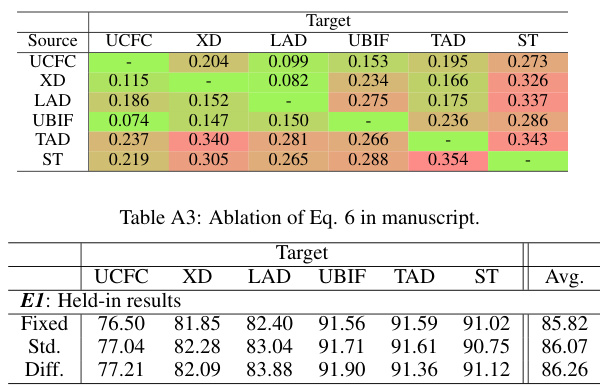
This table presents the ablation study results for Equation 6 from the manuscript. It shows the Area Under the Curve (AUC) scores obtained using different experimental settings. The rows represent the source datasets used for training, while the columns indicate the target datasets used for evaluation. The diagonal elements show in-domain results, while the off-diagonal elements show cross-domain results. The table helps to analyze the impact of Equation 6 on the overall performance of the model, demonstrating the effectiveness of handling abnormal conflicts across multiple domains.

This table presents the Area Under the Curve (AUC) scores achieved by different models in the held-in setting of the MDVAD benchmark. The held-in setting involves training models on all six datasets (UCFC, XD, LAD, UBIF, TAD, ST) and evaluating them on each dataset individually. The table compares the performance of three different baseline models (MIL, Null-MIL, and NullAng-MIL) across all six datasets, providing a row for each target dataset and a column for each model.
This table presents the results of the held-in evaluation (E1) for the MDVAD benchmark. In this protocol, models are trained on all six datasets simultaneously and tested on each dataset individually. The table shows the Area Under the Curve (AUC) scores achieved by six different models on each of the six datasets (UCFC, XD, LAD, UBIF, TAD, and ST). The models compared are a single-domain MIL baseline and four multi-domain models incorporating variations of Null-MIL and NullAng-MIL with and without an Abnormal Conflict (AC) classifier. The ‘Out Avg’ column provides the average AUC score across all six datasets, giving an overall measure of performance for each model across all domains.
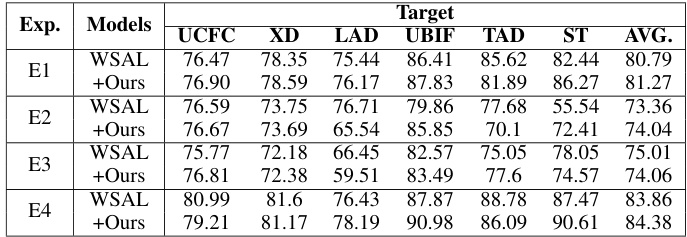
This table presents the results of experiments conducted using the WSAL model as a baseline to validate the proposed method. It compares the performance of the WSAL model alone against the performance of the WSAL model enhanced by the addition of multi-head learning with NullAng-MIL and the AC Classifier. The results are shown for four different experimental settings: held-in (E1), leave-one-out (E2), low-shot adaptation (E3), and full fine-tuning (E4). The table demonstrates the performance gains achieved by incorporating the multi-head learning and AC Classifier across various experimental settings and target datasets.
Full paper#