↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are computationally expensive, hindering deployment on resource-limited devices. Structural pruning, a technique to reduce LLM size, is limited by either following structural dependencies, which restricts flexibility, or by introducing extra parameters. This creates a trade-off between efficiency and performance.
DISP-LLM tackles these limitations by proposing a novel dimension-independent structural pruning approach. This method breaks structural dependencies, allowing different layers to use diverse feature subsets and layer widths. Experimental results show DISP-LLM outperforms existing state-of-the-art methods across various LLMs (OPT, LLaMA, LLaMA-2, Phi-1.5, Phi-2) achieving an accuracy similar to semi-structural pruning, a significant breakthrough in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) optimization because it introduces a novel dimension-independent structural pruning method. It offers significant improvements over existing techniques by enhancing flexibility and achieving accuracy comparable to more complex semi-structural methods. This opens avenues for creating more efficient and deployable LLMs with similar performance while significantly reducing computational costs and memory requirements. This addresses a critical challenge in deploying LLMs on resource-constrained devices.
Visual Insights#

This figure illustrates the difference between regular structural pruning and the proposed dimension-independent structural pruning method. In regular methods, the pruning process must respect the structural dependencies within the network (e.g., residual connections), limiting flexibility. The proposed method breaks this dependence using index operations to enable each block to utilize varying subsets of the feature maps, significantly increasing pruning flexibility.

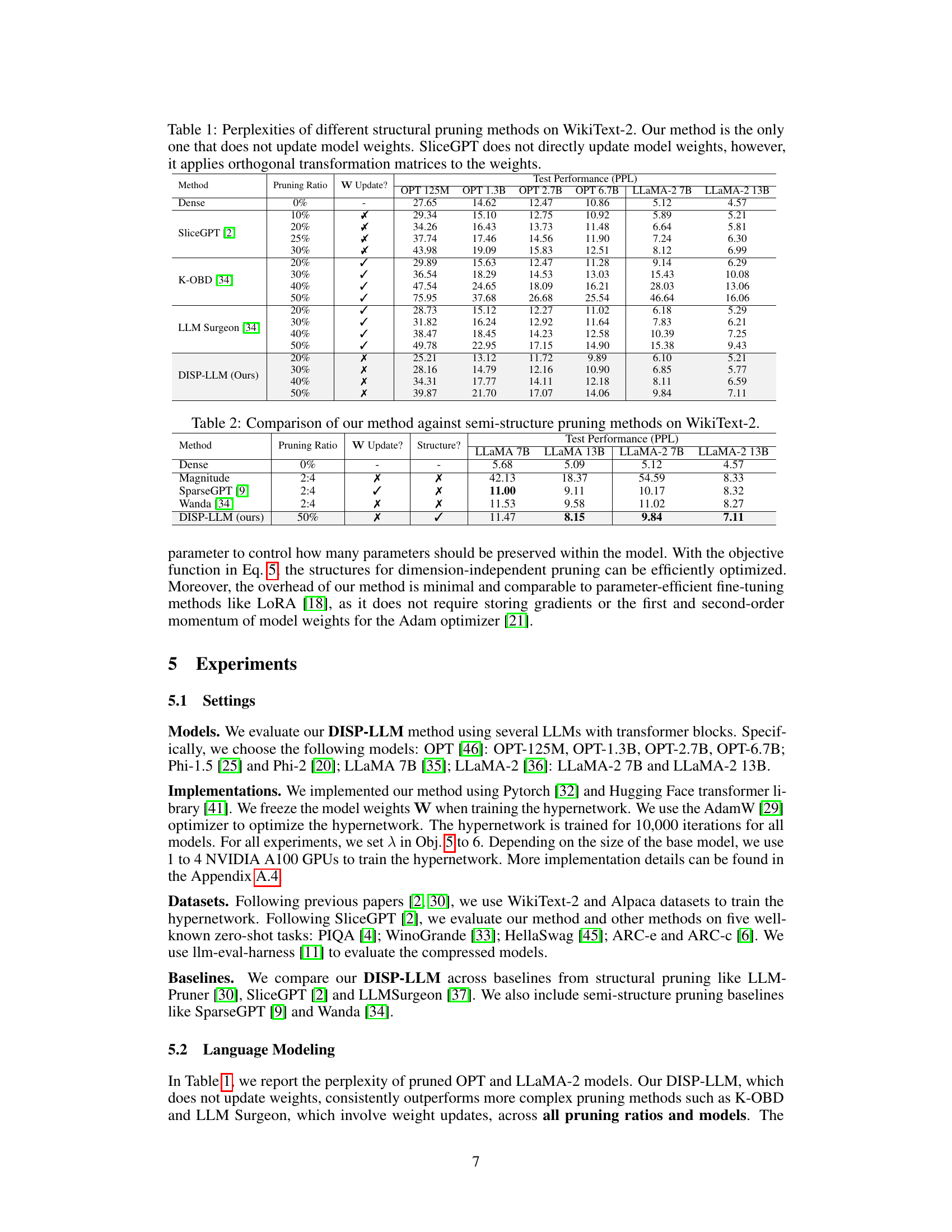
This table compares the perplexity scores achieved by various structural pruning methods on the WikiText-2 benchmark. It showcases the performance of different methods across various Large Language Models (LLMs) at different pruning ratios. Notably, it highlights that the proposed DISP-LLM method achieves comparable or better results without updating the model weights, unlike other methods that do require weight updates. SliceGPT, while not directly updating weights, uses orthogonal transformations, introducing additional parameters.
In-depth insights#
Dimension-Free Pruning#
Dimension-free pruning presents a novel approach to model compression in deep learning, specifically targeting large language models (LLMs). Traditional pruning methods often rely on the inherent structure of the model, which limits flexibility and can hinder performance. Dimension-free pruning aims to overcome this limitation by decoupling the pruning process from the model’s dimensionality, allowing for more flexible and potentially more effective compression. This technique could involve selectively removing or modifying weights or neurons based on criteria independent of their location or layer, leading to a more adaptable and less constrained pruning strategy. The key advantage lies in its potential to discover more optimal subnetworks within the model, resulting in better performance-efficiency trade-offs compared to structured pruning. However, dimension-free pruning also poses challenges. It requires sophisticated algorithms to identify and remove dimensions without negatively impacting the model’s functionality. The implementation could be computationally expensive, especially for LLMs with billions of parameters. Moreover, evaluating the effectiveness of such a method necessitates rigorous testing and comparison against existing techniques across diverse datasets and model architectures. The success of dimension-free pruning will greatly depend on the development of efficient algorithms that can accurately identify and remove irrelevant dimensions while maintaining or improving overall model performance. This area of research promises to be significant for optimizing the performance and efficiency of LLMs for various applications.
DISP-LLM Approach#
The DISP-LLM approach presents a novel solution to the challenge of efficiently compressing large language models (LLMs) through structural pruning. Unlike traditional methods, DISP-LLM breaks free from the constraints of structural dependencies, enabling greater flexibility in selecting and pruning features across different layers. This is achieved by strategically relocating selection matrices within the model, thereby allowing different layers to utilize distinct subsets of feature maps and dynamically adjusting the width of each layer. The method leverages a gradient-based optimization approach using a hypernetwork to learn optimal widths, eliminating the need for additional parameters compared to other techniques. The core innovation lies in its dimension-independent nature, allowing for more flexible and adaptable pruning, ultimately resulting in improved accuracy and efficiency. Experimental results show DISP-LLM’s superior performance over state-of-the-art structural pruning methods across various LLMs, demonstrating the effectiveness of this novel approach in achieving comparable accuracy to more computationally expensive semi-structural pruning techniques.
Hypernetwork Learning#
Hypernetwork learning, in the context of large language model (LLM) compression, presents a powerful approach to optimize structural pruning. Instead of manually selecting which parts of the network to remove, a hypernetwork learns to generate the optimal pruning masks. This approach offers enhanced flexibility because it allows different layers to utilize different subsets of features, overcoming the limitations of traditional methods that rely on structural dependencies. Furthermore, the hypernetwork allows for dynamic width adjustment across layers, improving pruning efficiency and model accuracy. By learning the optimal pruning strategy from data, the hypernetwork implicitly discovers the most important sub-networks within the LLM, leading to superior compression ratios compared to methods that rely on hand-crafted rules. However, training the hypernetwork adds computational overhead; finding the right balance between the hypernetwork’s complexity and its pruning effectiveness is crucial for successful application. The use of gradient-based methods and techniques like ReinMax, for handling binary operations, are critical in effectively training the hypernetwork to learn the optimal pruning masks. This optimization process ultimately yields models that achieve comparable or even superior accuracy to semi-structural pruning techniques, setting a new precedent in LLM compression.
Residual Connection#
The concept of “Residual Connections” in deep learning architectures, particularly relevant to large language models (LLMs), is a crucial innovation impacting performance and efficiency. Residual connections, or skip connections, allow the direct passage of information from earlier layers to later layers, bypassing intermediate processing. This addresses the vanishing gradient problem inherent in very deep networks, where gradients become extremely small during backpropagation, hindering effective training. By adding a residual path, the gradient flow is enhanced, allowing for easier training of deeper networks and significantly improving model performance. The research paper likely explores the impact of residual connections on LLM structural pruning. The reliance on these connections in standard LLM architectures presents a challenge for pruning methods. Existing methods either preserve entire structural units due to the dependence introduced by the skip connections or add substantial computational overhead to compensate. Therefore, a novel approach might focus on breaking this structural dependence, to achieve improved pruning flexibility without compromising the benefits of residual connections.
Future Work#
The ‘Future Work’ section of a research paper on dimension-independent structural pruning for large language models (LLMs) could explore several promising avenues. Extending the approach to other LLM architectures beyond the ones tested (OPT, LLaMA, etc.) is crucial to establish its general applicability. Investigating the impact of different pruning strategies on various downstream tasks would provide further insights into the method’s effectiveness. Developing more efficient indexing mechanisms to further reduce computational overhead during inference is another important consideration. Furthermore, research into combining dimension-independent pruning with other compression techniques (e.g., quantization, knowledge distillation) could lead to even more significant reductions in model size and computational cost. Finally, a comprehensive study on the theoretical properties of the method, perhaps including analyses of its convergence and generalization behavior, would add significant value to the research.
More visual insights#
More on figures

This figure illustrates the DISP-LLM method, showing how different selection matrices (S1 to S5) are applied to the input and output dimensions of the attention and MLP layers within a transformer block. It highlights the modifications made during the pruning process: index selection is added before layer normalization, and addition operations are replaced with index addition operations. These changes break the structural dependence in standard pruning methods, enhancing flexibility. The figure shows the process both during the hypernetwork training phase and during the actual pruning phase.

This figure compares three different structural pruning methods: SliceGPT, regular structural pruning, and the proposed dimension-independent structural pruning (DISP-LLM). It highlights the key difference in how these methods handle projection matrices and structural dependence, illustrating the improved flexibility of DISP-LLM in selecting different subsets of features for different layers, without introducing additional parameters.

This figure visualizes the results of applying the DISP-LLM pruning method to the LLaMA-2 7B model at a 50% pruning ratio. The left panel shows a heatmap representing the pruning decisions across both the embedding dimension (horizontal axis) and the depth of the model (vertical axis). Darker blue indicates preserved weights, while lighter teal indicates pruned weights. The right panel provides a histogram summarizing the pruning rate across the embedding dimension and shows the overall pruning ratio.
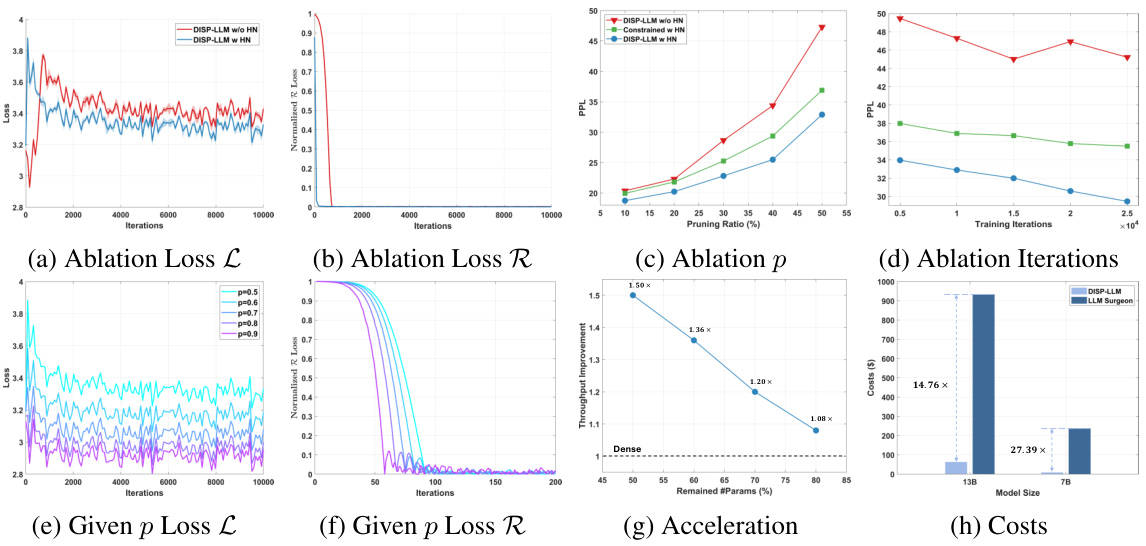
This figure visualizes how the model’s embedding dimension is pruned at a 50% pruning ratio for the LLaMA-2 7B model. It shows which parts of the embedding dimension are preserved and which are pruned across different layers of the model, illustrating the dimension-independent nature of the proposed pruning method. The color coding represents the preserved and pruned elements in the embedding dimension, demonstrating the flexibility in pruning different parts of the embedding dimension for different layers.

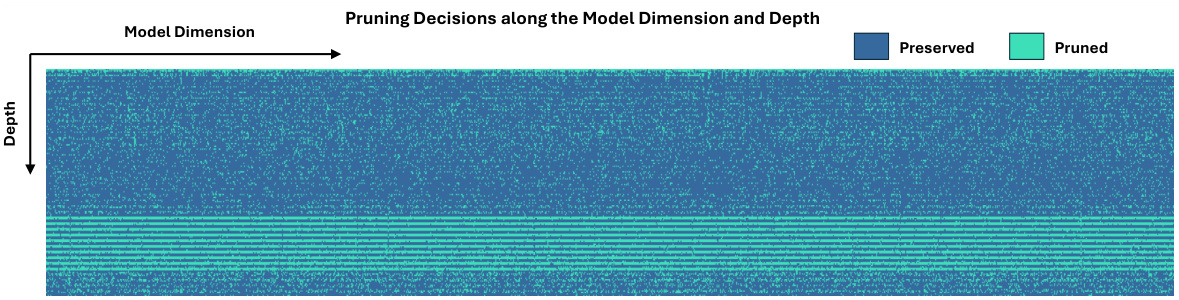
This figure visualizes the width of each layer in the LLaMA-2 7B model after applying the proposed dimension-independent structural pruning method with a 50% pruning ratio. The x-axis represents the layer number, and the y-axis shows the preserved rate (the proportion of features retained) for each layer. Different colors represent different selection matrices (S1 to S5) used in different parts of the transformer block. The graph reveals the varying widths assigned to different layers after pruning, highlighting the flexibility of the proposed method. Some layers are pruned more aggressively than others.

This figure compares the SliceGPT method and the proposed DISP-LLM method. SliceGPT adds projection matrices (Q) to the residual connection which increases the number of parameters. The DISP-LLM method, on the other hand, adds index selection and index addition operations which does not add extra parameters. Both methods use different selection matrices for different layers to improve flexibility.
This figure visualizes the pruning decisions made by the DISP-LLM method on the LLaMA-2 7B model when 50% of the parameters are pruned. The heatmap shows the embedding dimension on the horizontal axis and the depth (number of layers) on the vertical axis. Each cell represents a parameter, and is colored blue if the parameter is preserved and teal if it’s pruned. The figure demonstrates how DISP-LLM selectively prunes parameters across different layers and embedding dimensions, leading to a flexible and effective model compression technique. Note that the lower portion of the figure shows more consistent pruning across the embedding dimension, while the upper portion exhibits more scattered pruning decisions.
This figure visualizes the model architecture after applying the dimension-independent structural pruning method with a 50% pruning ratio on the LLaMA-2 7B model. It shows how different layers of the model retain varying numbers of features across the embedding dimension, highlighting the flexibility of this pruning technique. The preserved and pruned parts in each layer along the embedding dimension are clearly depicted.
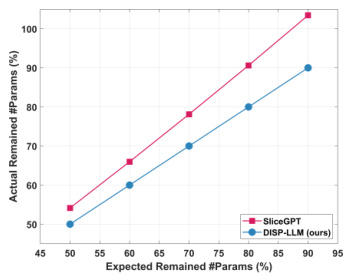
This figure compares the expected and actual compression rates achieved by DISP-LLM and SliceGPT for the LLaMA-7B language model. The x-axis represents the expected compression rate (percentage of parameters intended to be preserved), while the y-axis shows the actual compression rate achieved. The figure visually demonstrates the discrepancy between the expected and actual compression rate in SliceGPT, highlighting a significant difference. In contrast, DISP-LLM exhibits a much closer alignment between expected and actual compression rates, indicating its improved accuracy and reliability in pruning.
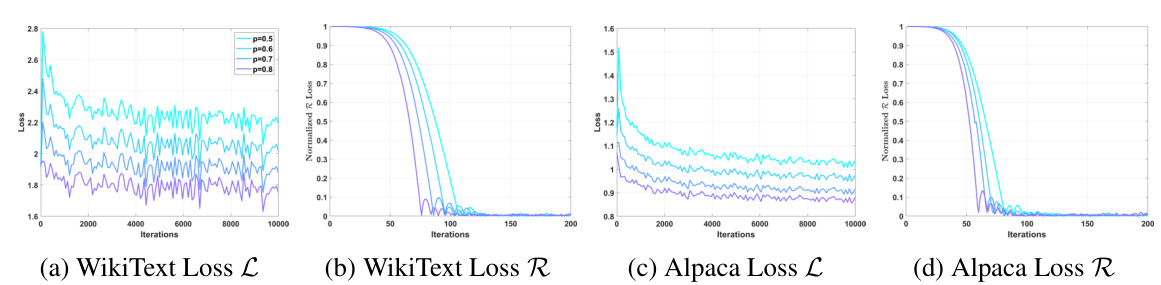
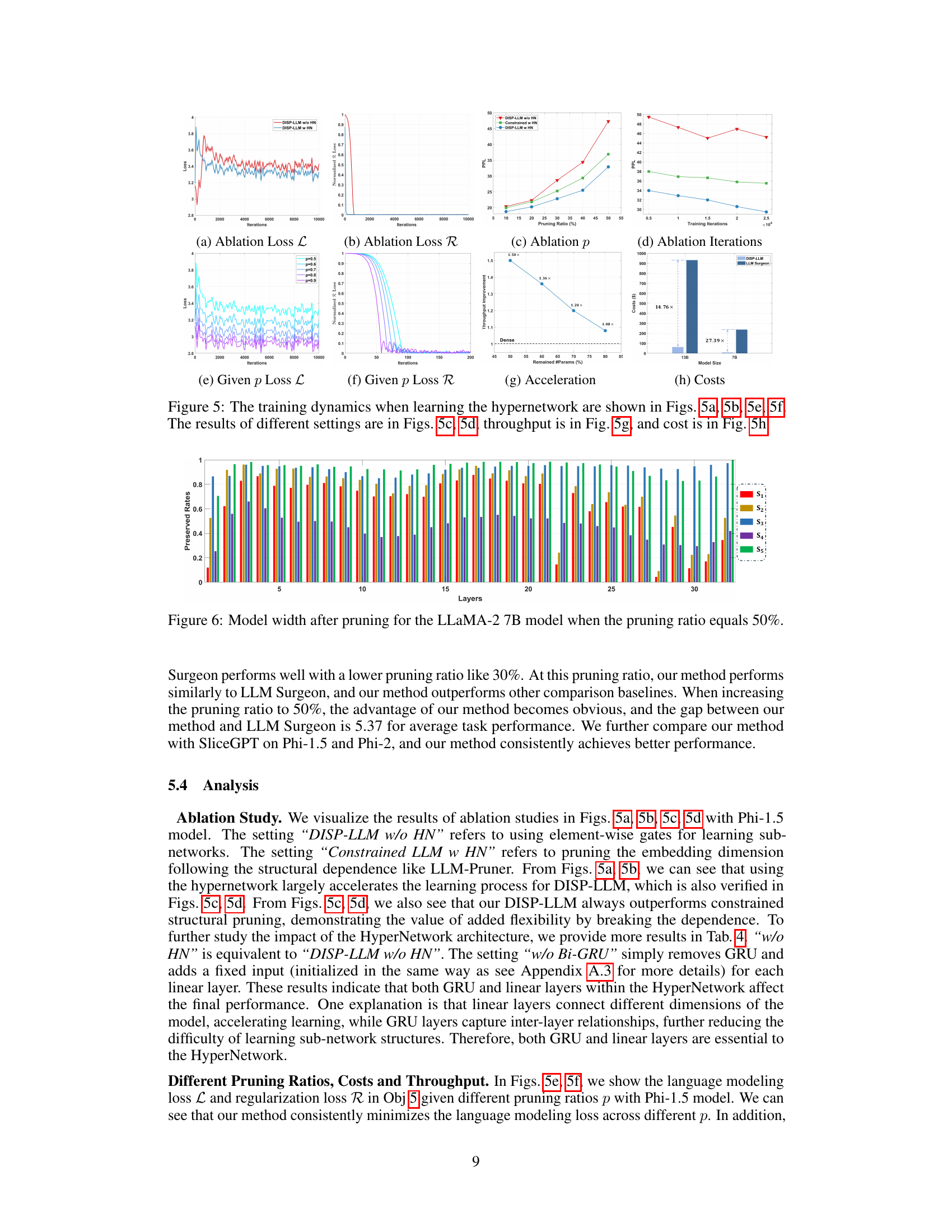
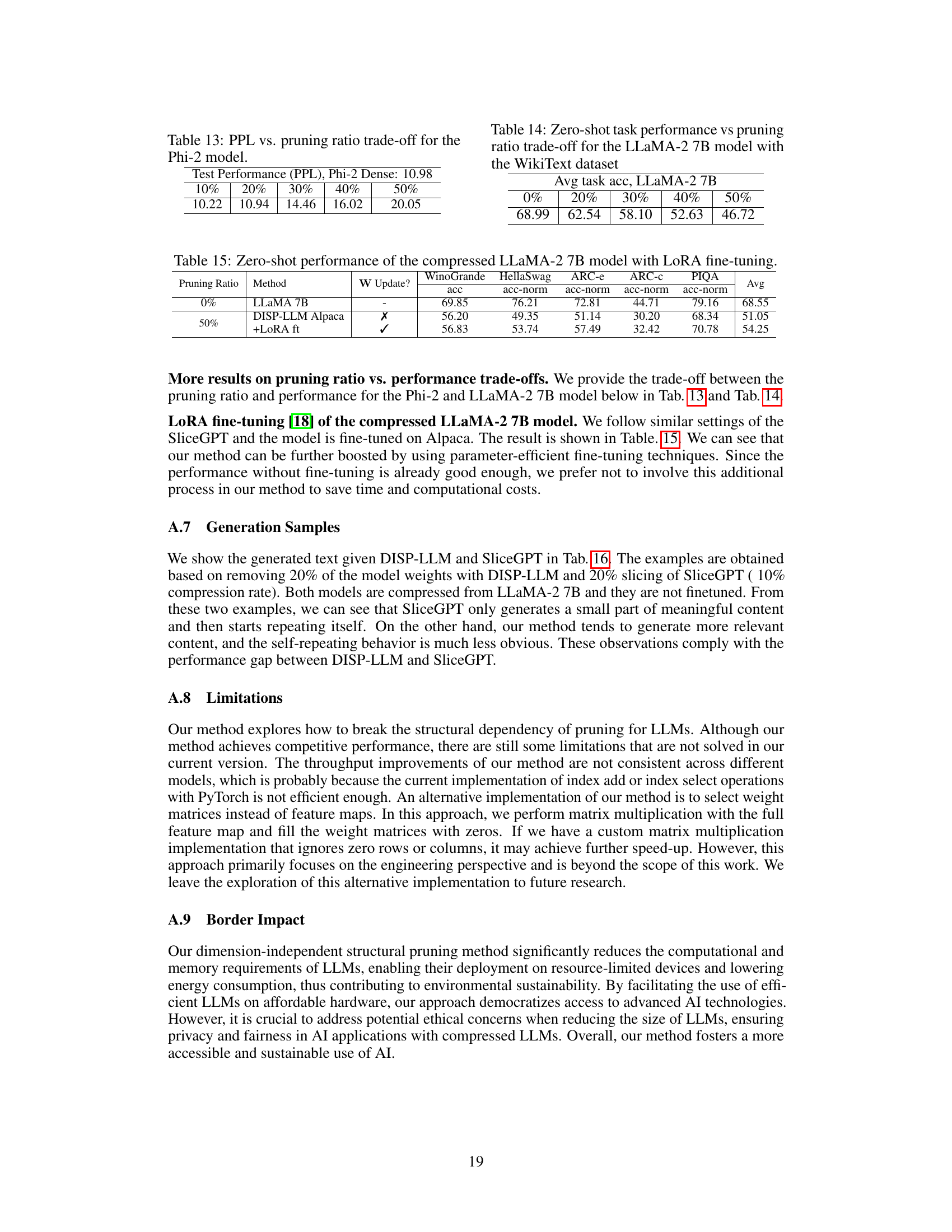
This figure shows the training dynamics of the hypernetwork used in the DISP-LLM method. It illustrates the loss curves for both the language modeling loss (L) and regularization loss (R), under different pruning ratios (p) and hyperparameter settings. The effect of using the hypernetwork versus not using it, and the impact of different hyperparameter choices are visually demonstrated. Finally, the figure also displays the resulting throughput improvement and cost reduction achieved by the method.

This figure visualizes how the proposed dimension-independent structural pruning method affects the LLaMA-2 7B model’s architecture when 50% of its parameters are pruned. The x-axis represents the embedding dimension, while the y-axis shows the preserved rate (proportion of parameters retained). The color gradient illustrates the pruning decisions across the embedding dimension and depth of the model, revealing which dimensions are more or less heavily pruned. This demonstrates the method’s flexibility in selecting subnetworks with varying widths along the embedding dimension, unlike traditional pruning approaches.
More on tables

This table presents the perplexity scores achieved by different structural pruning methods on the WikiText-2 dataset for several language models. The pruning methods are compared based on their performance at different pruning ratios (percentage of parameters removed). The table highlights that the proposed DISP-LLM method is unique in not updating the model weights during pruning, which is a significant difference from other methods. The results demonstrate the effectiveness of DISP-LLM even when compared to methods that do update model weights.

This table compares the performance of the proposed DISP-LLM method against several semi-structured pruning methods on the WikiText-2 benchmark. It shows the test perplexity (PPL) achieved by each method at a 50% pruning ratio. The table also indicates whether each method updates model weights during pruning and whether it maintains the original structure of the model. The results highlight DISP-LLM’s competitive performance compared to other methods, even without weight updates.
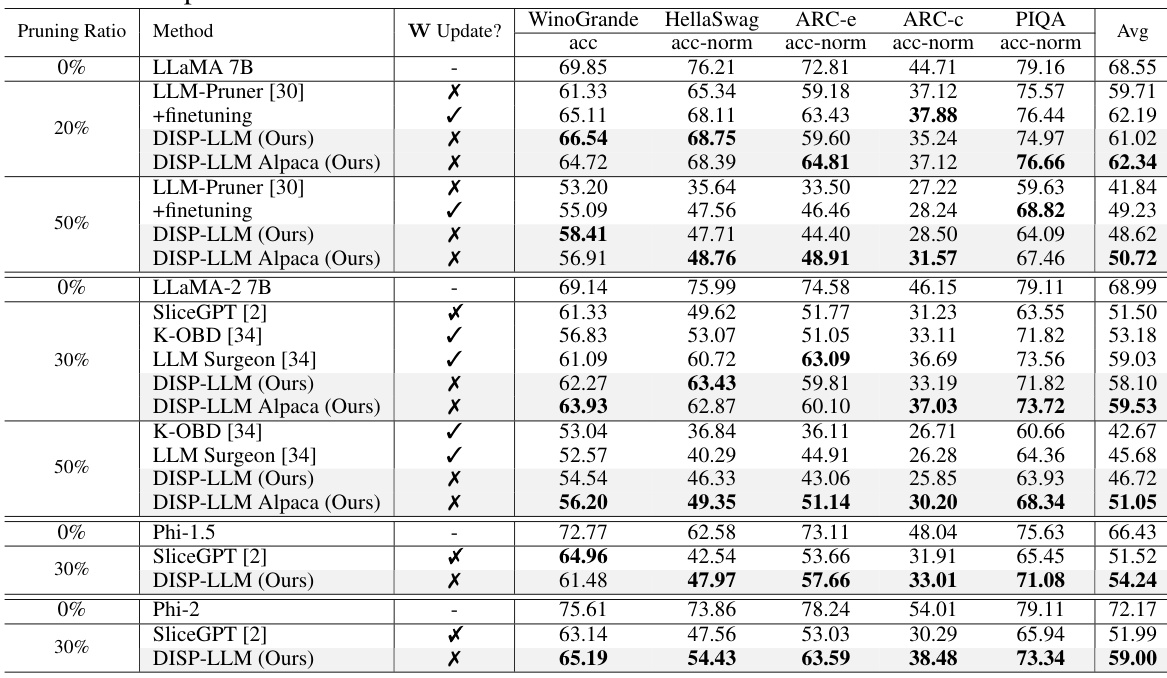
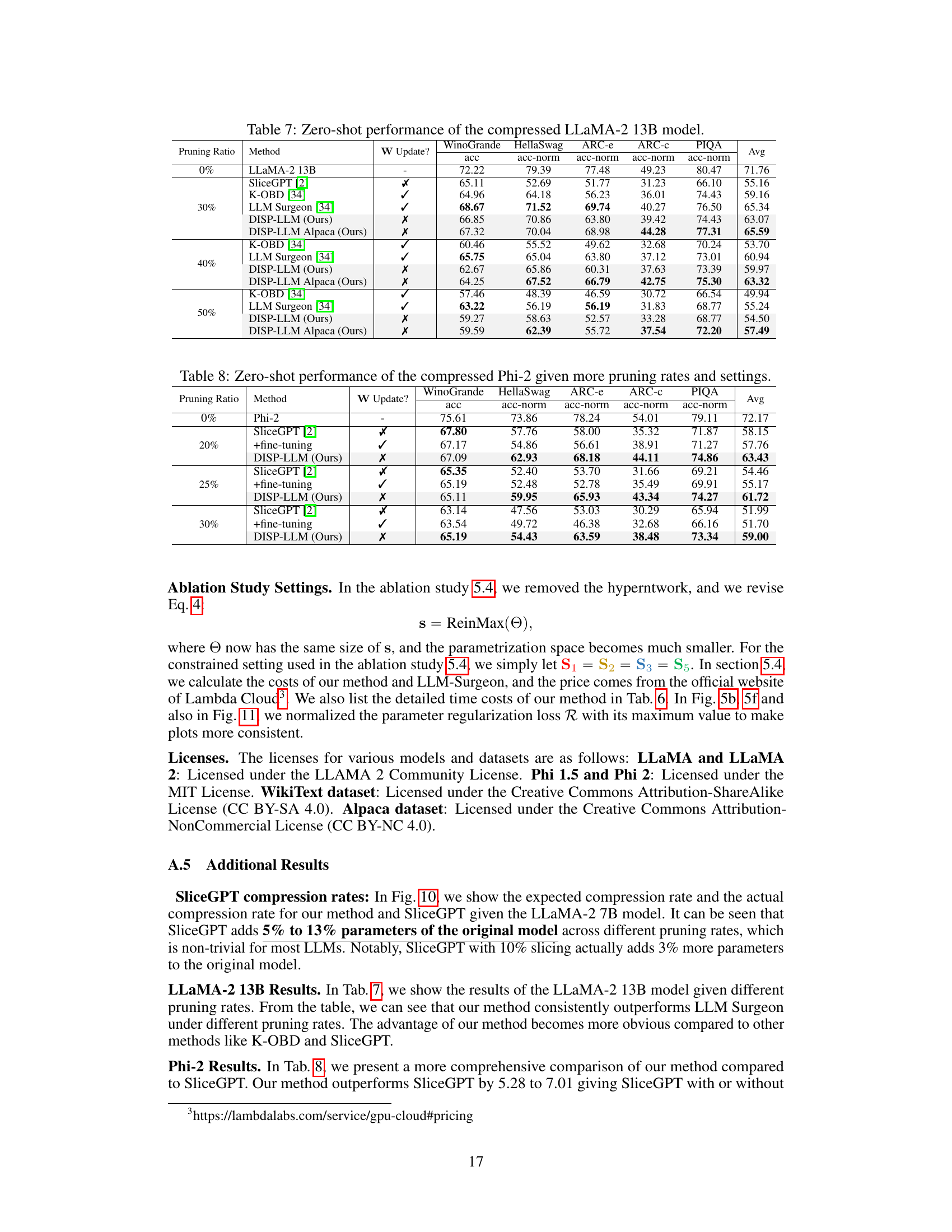
This table presents the zero-shot performance results on five different tasks (WinoGrande, HellaSwag, ARC-e, ARC-C, and PIQA) for various compressed language models. The models are compressed using different methods (DISP-LLM, LLM-Pruner, SliceGPT, K-OBD, and LLM Surgeon) at different pruning ratios (20% and 50%). The table shows the accuracy and accuracy normalized results for each method, task, and pruning ratio. The DISP-LLM results are shown separately for models trained on WikiText and Alpaca datasets to highlight the impact of training data on performance.

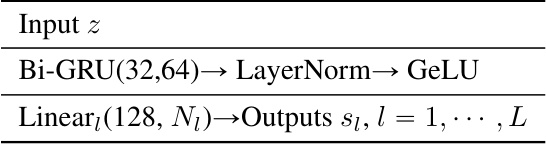
This table presents an ablation study on the impact of different hypernetwork architectures on the performance of the DISP-LLM method using the Phi-1.5 model. It compares the perplexity (PPL) scores achieved with three different hypernetwork configurations: one without a hypernetwork, one without Bi-GRU layers within the hypernetwork, and one with the full hypernetwork architecture. The comparison is made across different compression rates (0%, 10%, 20%, 30%, 40%, 50%). The results show the impact of the hypernetwork design on the model’s performance, highlighting the benefit of using the full hypernetwork.
This table compares the perplexity scores achieved by several structural pruning methods on the WikiText-2 benchmark across different LLMs (OPT and LLaMA). It highlights the performance of the proposed DISP-LLM method against state-of-the-art methods, emphasizing DISP-LLM’s unique characteristic of not updating model weights during pruning, unlike other methods which either update weights directly or indirectly through transformation matrices. The table shows perplexity results for various pruning ratios.

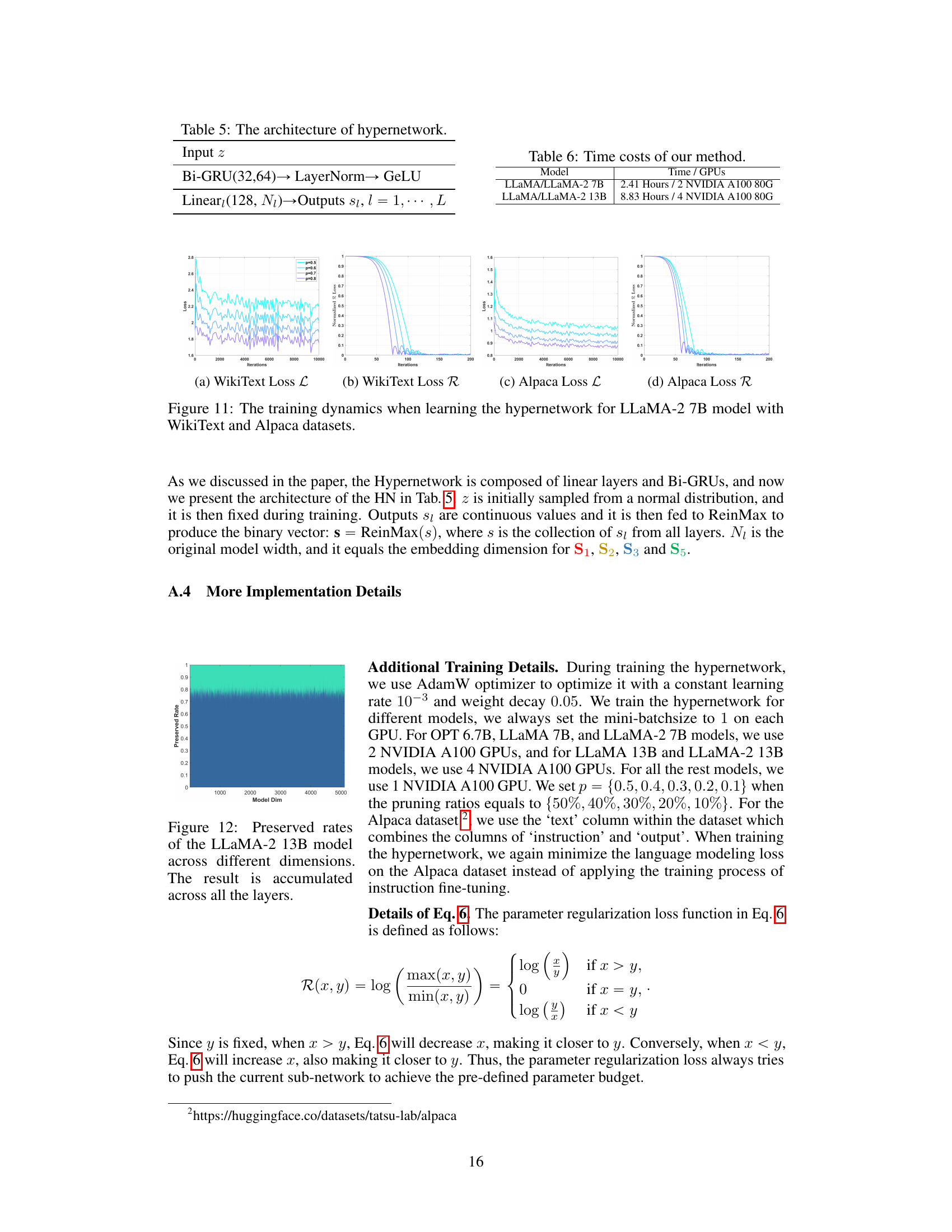
This table presents the time taken and the number of GPUs used to train the hypernetwork for different sized language models. The models listed are LLaMA 7B and LLaMA 13B, and their corresponding LLaMA-2 versions. The training time varied depending on the model size, with the larger 13B models requiring substantially more time and GPUs.

This table presents the zero-shot performance results on five different tasks (WinoGrande, HellaSwag, ARC-e, ARC-c, and PIQA) for three different language models (LLaMA 7B, LLaMA-2 7B, and Phi models) using the DISP-LLM method and comparing it to other state-of-the-art structural pruning methods. The results are shown for different pruning ratios (20% and 50%) and indicate whether the model weights were updated during pruning. The ‘DISP-LLM Alpaca’ results use a hypernetwork trained on the Alpaca dataset instead of the WikiText dataset.
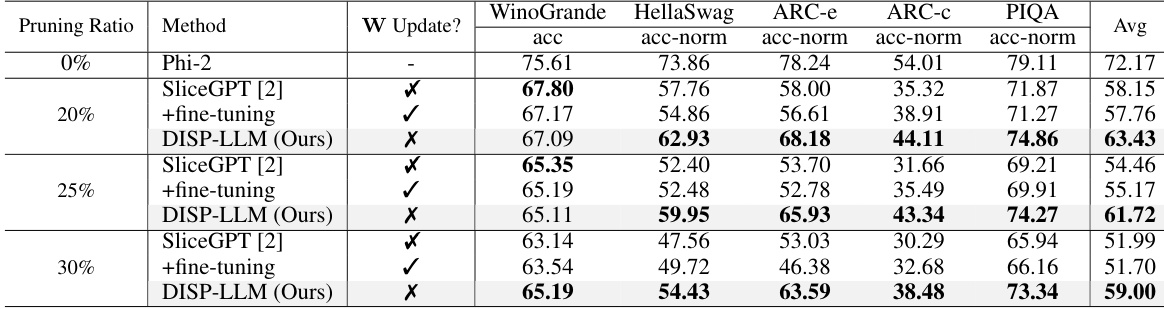
This table presents the zero-shot performance of several compressed large language models (LLMs) across five different tasks: WinoGrande, HellaSwag, ARC-e, ARC-C, and PIQA. The LLMs are compressed using different methods, including DISP-LLM (the authors’ method) and baseline methods like LLM-Pruner and SliceGPT. Two versions of DISP-LLM are shown: one trained on the WikiText dataset and another trained on the Alpaca dataset. The table shows the accuracy (acc) and accuracy normalized by the dense model (acc-norm) for each model and task. The pruning ratios (20% and 50%) indicate the proportion of parameters removed during the compression process.

This table presents the zero-shot performance results of the compressed LLaMA 13B model across various pruning methods. It includes the average accuracy across five zero-shot tasks (WinoGrande, HellaSwag, ARC-e, ARC-c, PIQA) for different pruning ratios (0%, 20%, 50%). The table shows results with and without fine-tuning and compares different pruning approaches (Magnitude, LLM Pruner - Channel, LLM Pruner - Block, and DISP-LLM). The ‘W Update?’ column indicates whether model weights were updated during the pruning process. The results highlight the performance of DISP-LLM compared to other state-of-the-art methods, especially when considering that DISP-LLM does not update weights.

This table presents the throughput (Tokens/seconds) of the LLaMA-2 13B model under different pruning ratios (0%, 20%, 30%, 40%, 50%). It shows how the speed of token processing changes as more parameters are removed from the model through pruning. Higher numbers indicate faster processing.

This table shows the impact of the regularization parameter λ on the performance of the Phi-1.5 model when 50% of parameters are pruned. The results demonstrate that a λ value of 6 or higher yields stable performance, whereas smaller λ values result in unstable performance (indicated by ‘NC’ for non-convergence). This suggests that the appropriate magnitude of λ is crucial for the effectiveness of the pruning method.

This table presents the results of experiments conducted on the Phi-2 model to analyze the trade-off between perplexity (PPL) and different pruning ratios. It demonstrates how the model’s performance, measured by PPL, changes as the pruning ratio increases from 10% to 50%. The results are essential for understanding the impact of structural pruning on the model’s accuracy and efficiency.

This table shows the trade-off between the pruning ratio and the average zero-shot task accuracy for the LLaMA-2 7B model. It demonstrates how performance changes as different percentages of parameters are pruned from the model using the WikiText dataset for evaluation.

This table presents the zero-shot performance results for three different large language models (LLaMA 7B, LLaMA-2 7B, and Phi models) after applying the proposed dimension-independent structural pruning method (DISP-LLM). It compares the performance of the pruned models against several baselines across five different zero-shot tasks (WinoGrande, HellaSwag, ARC-e, ARC-C, and PIQA) at different pruning ratios (20% and 50%). The table also shows results for DISP-LLM trained on the Alpaca dataset (DISP-LLM Alpaca), highlighting that the pruning strategy can be adapted to different training data. The ‘W Update?’ column indicates whether the model weights were updated during the pruning process.

This table compares the perplexity scores achieved by various structural pruning methods on the WikiText-2 dataset across different model sizes (OPT and LLaMA-2). It highlights that the proposed DISP-LLM method outperforms other state-of-the-art methods while not requiring model weight updates, a key advantage in terms of computational efficiency and ease of deployment. It also shows the impact of pruning ratios on model performance.
Full paper#