↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current audio-visual rendering often suffers from inconsistencies due to reliance on visual cues and lag caused by sequential audio generation after image rendering. These limitations hinder the creation of truly immersive virtual experiences, such as real-time dynamic navigation in 3D scenes. Moreover, accurate modeling of Room Impulse Response (RIR) for spatial audio is challenging for real-world scenes reconstructed from sparse images or videos.
To overcome these challenges, the paper introduces AV-Cloud, a novel point-based audio-visual rendering framework. AV-Cloud leverages Audio-Visual Anchors derived from camera calibration, creating an audio-visual representation that allows for simultaneous spatial audio and visual rendering. The core of the method is a new module called Audio-Visual Cloud Splatting, which decodes these anchors into a spatial audio transfer function. This function, applied through a Spatial Audio Render Head, generates viewpoint-specific spatial audio aligned with any visual viewpoint. Experiments demonstrate that AV-Cloud surpasses state-of-the-art methods in various aspects including audio reconstruction accuracy and perceptual quality.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to high-quality spatial audio rendering that is synchronized with visual rendering without relying on pre-rendered images or explicit visual conditioning. This significantly improves the realism and immersiveness of virtual experiences, particularly in real-world scenarios. It opens avenues for research in point-based audio-visual rendering, efficient spatial audio algorithms, and real-time applications like virtual tourism.
Visual Insights#
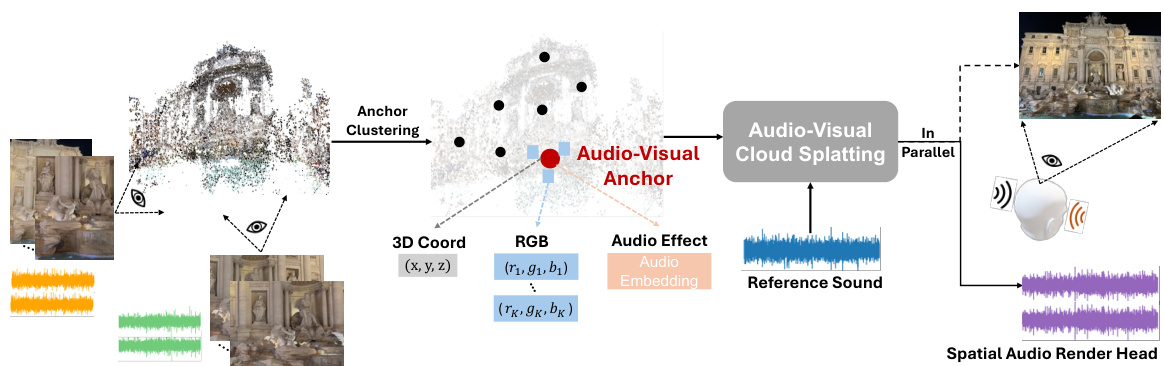
This figure illustrates the AV-Cloud framework, which synchronizes audio and visual rendering. It starts with video collections used to construct Audio-Visual Anchors (AV Anchors), representing the scene with 3D coordinates, RGB, and audio effects. These AV Anchors are input to the Audio-Visual Cloud Splatting module which transforms monaural reference audio into spatial audio aligned with the visual perspective. The Spatial Audio Render Head module generates the final stereo spatial audio output.
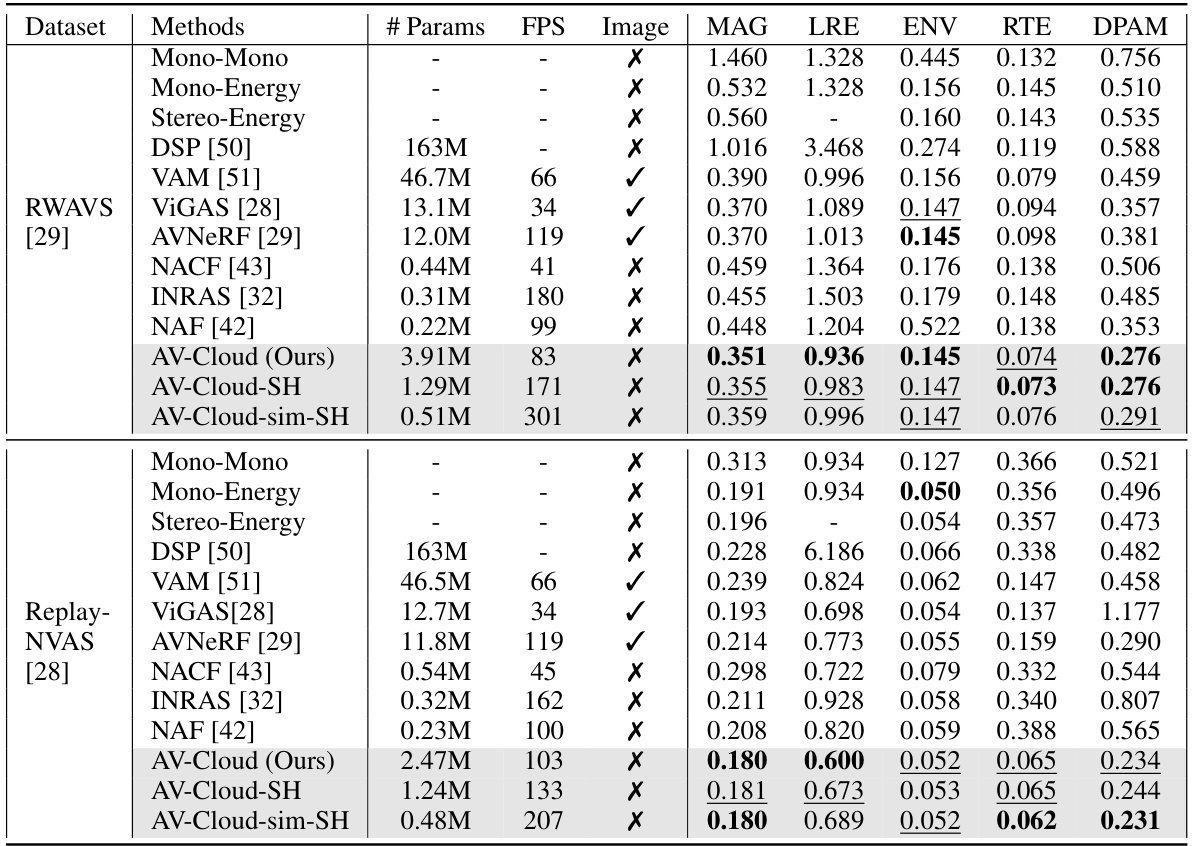
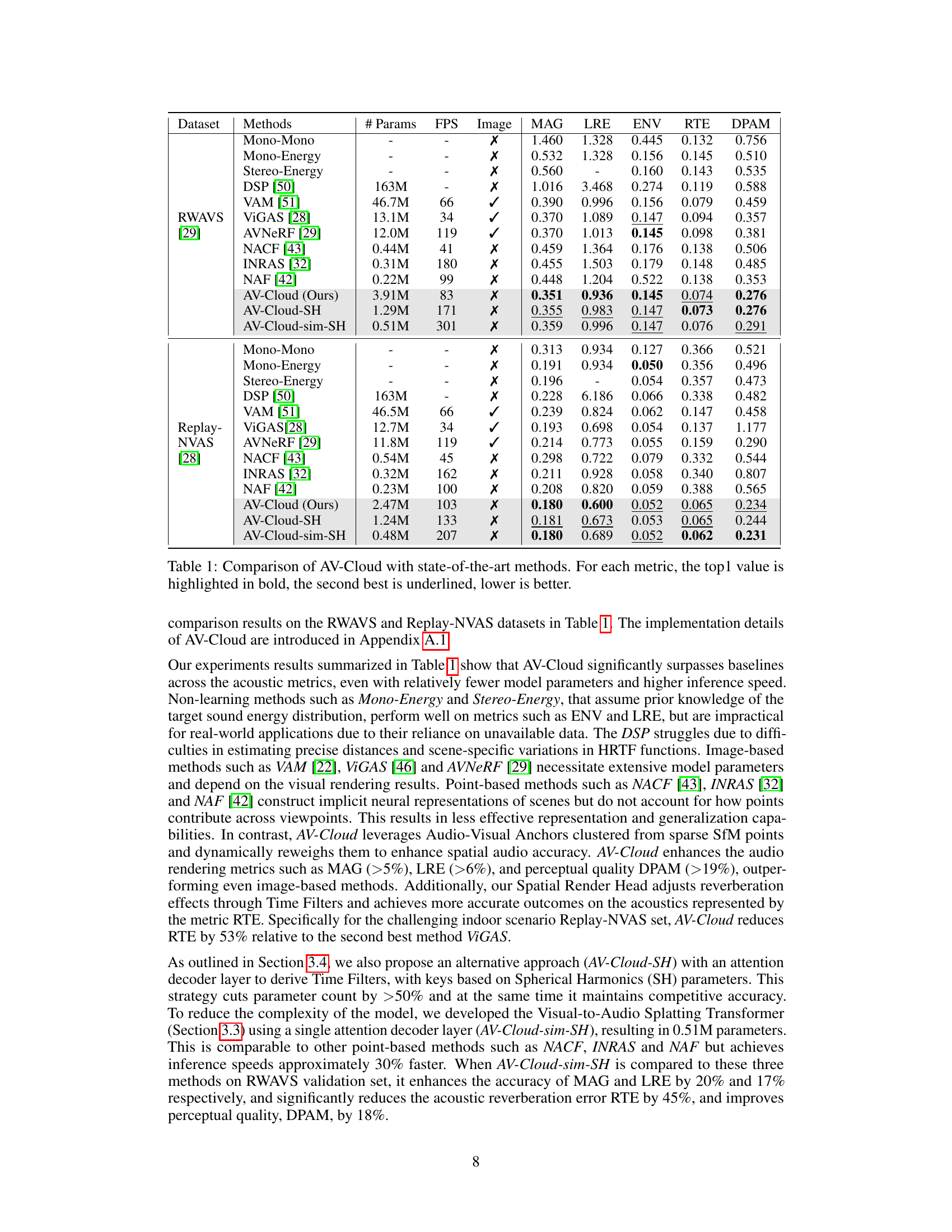
This table compares the performance of the proposed AV-Cloud model against several state-of-the-art baselines across two datasets, RWAVS and Replay-NVAS. The metrics used evaluate various aspects of spatial audio reconstruction quality, including magnitude spectrogram distance, left-right energy ratio error, energy envelope error, reverberation time error, and deep perceptual audio metric. The table also shows the number of parameters, frames per second (FPS) achieved, and whether pre-rendered images were used for each method. Lower values indicate better performance for all metrics except FPS, for which higher values are preferred. The results demonstrate that AV-Cloud outperforms the baselines across most metrics.
In-depth insights#
AV-Cloud Framework#
The AV-Cloud framework presents a novel approach to spatial audio rendering for 3D scenes by integrating audio and visual information through a point-based representation. Instead of relying on pre-rendered images, it leverages Audio-Visual Anchors, derived from camera calibration, to learn a compact representation of the audio-visual scene. This approach avoids the audio lag often associated with methods that generate audio after visual rendering. The core of the system is the Audio-Visual Cloud Splatting module, which dynamically decodes these anchors into a spatial audio transfer function for any listener location, ensuring synchronicity between audio and visual perspectives. The use of a Spatial Audio Render Head further refines the audio output, producing high-quality, viewpoint-specific spatial audio. The framework’s efficiency and ability to handle real-world scenes, even with noisy data, make it a significant advancement in immersive virtual tourism and similar applications.
Audio-Visual Splatting#
The core concept of “Audio-Visual Splatting” involves a novel approach to spatial audio rendering in 3D scenes. Instead of relying on traditional Room Impulse Response (RIR) modeling or solely visual cues, this method leverages a set of sparse Audio-Visual Anchor Points. These points, derived from camera calibration and scene geometry, encapsulate both audio and visual information, creating an efficient audio-visual representation of the scene. A key module, the Audio-Visual Cloud Splatting (AVCS) transformer, decodes these anchor points to generate a spatial audio transfer function tailored to the listener’s perspective. This function, when applied through a spatial audio render head, transforms monaural input audio into dynamic, high-fidelity spatial audio. This approach eliminates pre-rendered images, reduces latency by synchronizing audio and visual rendering, and demonstrates improved accuracy and perceptual quality compared to state-of-the-art methods. The technique’s reliance on sparse anchor points suggests significant potential for efficient real-time rendering in complex, real-world scenarios, enhancing immersive virtual experiences, particularly in applications like virtual tourism.
Real-World Datasets#
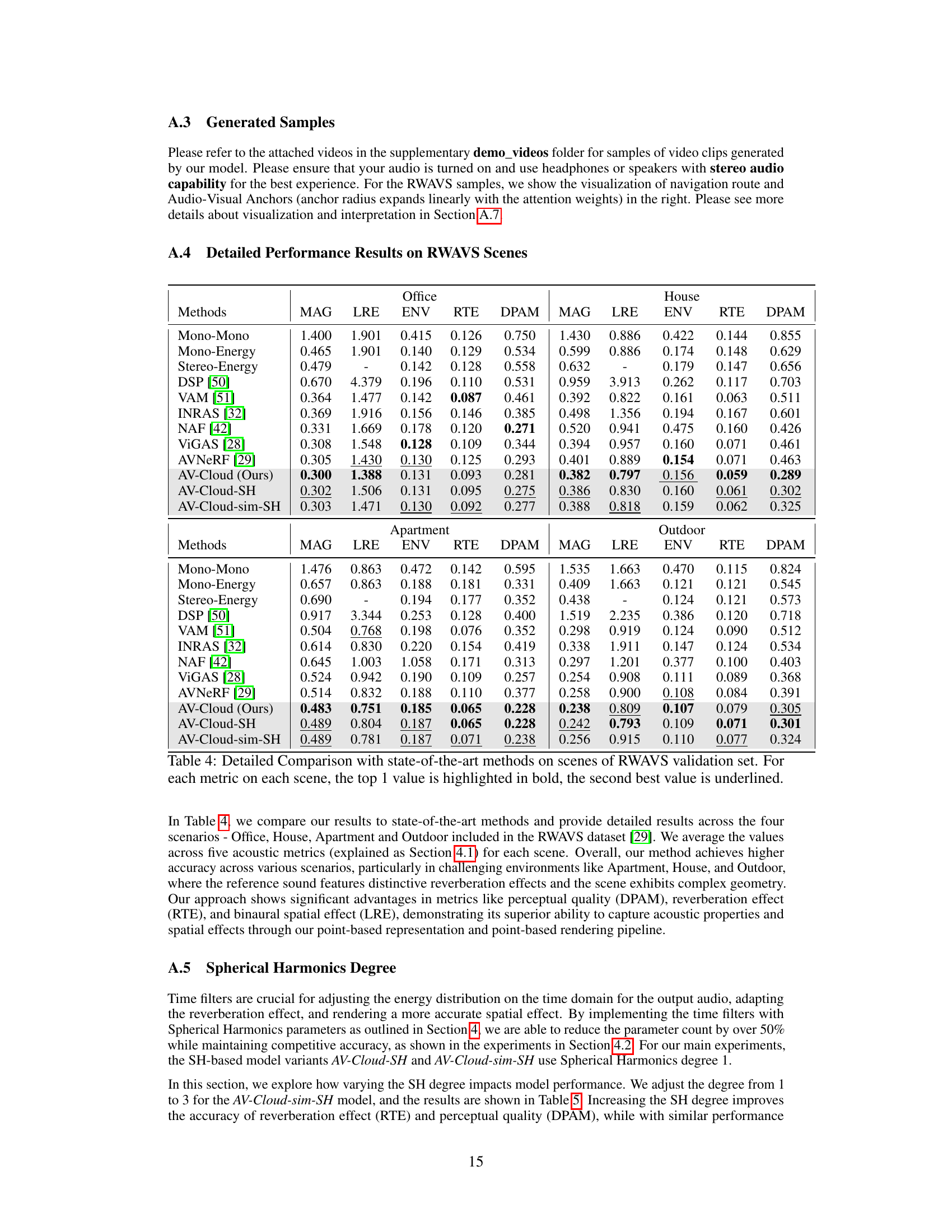
The utilization of real-world datasets is crucial for evaluating the generalizability and robustness of the proposed AV-Cloud model. Real-world data inherently possesses complexities absent in simulated environments, including background noise, variations in acoustic properties, and unpredictable environmental factors. Employing such datasets allows for a more accurate assessment of the model’s performance in diverse and challenging scenarios. The selection of datasets is also important; diverse settings and audio-visual content are vital to demonstrate adaptability. Benchmarking against existing methods using the same real-world data provides a meaningful comparison and highlights potential improvements. Furthermore, using established metrics is essential for reliable and consistent evaluation. The results demonstrate the superior performance of AV-Cloud in real-world settings, thus validating its practical applicability.
Point-Based Rendering#
Point-based rendering offers a compelling alternative to traditional polygon-based methods, particularly for complex scenes or those with dynamic geometry. Its core strength lies in representing objects as collections of points, each carrying attributes like color, normal, and potentially other data relevant to the rendering process. This approach eliminates the need for complex mesh structures and allows for efficient representation of highly detailed surfaces and even volumetric data. However, challenges remain: effectively rendering point clouds requires careful consideration of point density and splatting techniques to prevent visual artifacts like holes or aliasing. Furthermore, efficient algorithms are crucial to handle the computational cost associated with processing large point sets in real-time applications. Adaptive techniques, which adjust point density based on screen-space location, are often employed to optimize performance. Ultimately, the success of point-based rendering depends on balancing visual fidelity with computational efficiency, making it a powerful tool especially suited for applications where flexibility and detail are prioritized over strict polygon-based accuracy.
Future Directions#
Future research could explore improving the efficiency and scalability of AV-Cloud by optimizing the Audio-Visual Cloud Splatting module and reducing computational cost. Investigating novel methods for audio-visual anchor point generation beyond SfM, potentially using more robust techniques or incorporating other modalities, would enhance the system’s robustness. The development of more sophisticated audio rendering models, such as those incorporating higher-order acoustic effects or advanced reverberation modeling, is crucial. A significant area for expansion involves generalizing the approach to diverse environments and scenarios, enhancing the system’s ability to handle noise and complex real-world acoustic interactions. Finally, exploring user interaction within AV-Cloud is essential to maximize the technology’s immersive capabilities; developing intuitive interfaces and real-time user feedback mechanisms will be vital.
More visual insights#
More on figures
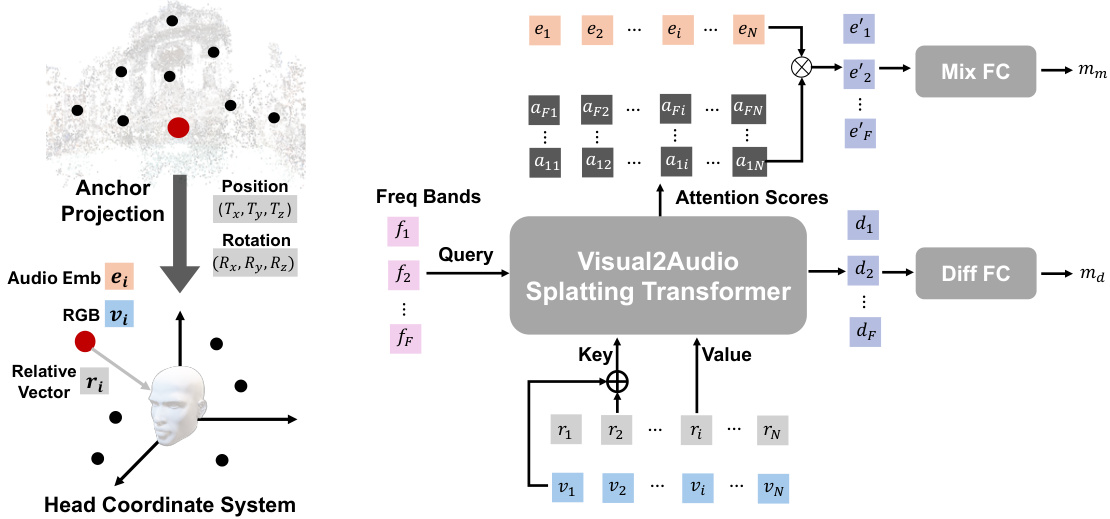
This figure illustrates the Audio-Visual Cloud Splatting (AVCS) module, a core component of the AV-Cloud framework. AVCS takes Audio-Visual Anchors as input, projects them into the listener’s coordinate system, and then uses a transformer network to decode audio spatial effect features for each frequency band. The output of the transformer is two acoustic masks: a mixture mask and a difference mask. These masks are used to transform a monaural input sound into a stereo output sound tailored to the specific viewpoint of the listener.
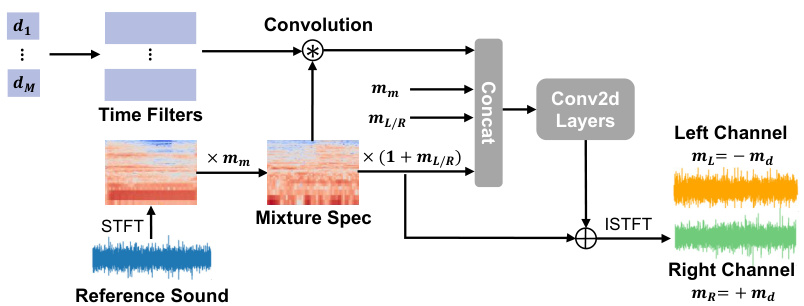
The SARH (Spatial Audio Render Head) module takes the acoustic masks (mixture and difference masks) from the AVCS (Audio-Visual Cloud Splatting) module and the monaural reference sound as inputs. It uses a single-layer residual structure with two convolutional modules: Time Filters and Conv2D layers. The Time Filters module adjusts the energy distribution in the time domain, improving the quality of the sound and taking into account things like reverberation time. The Conv2D Layers smooth and enhance the time-frequency distribution of the sound, using a stacked convolutional network to achieve this. The output of this module is a stereo audio signal, with the left and right channels calculated using the mixture and difference masks.
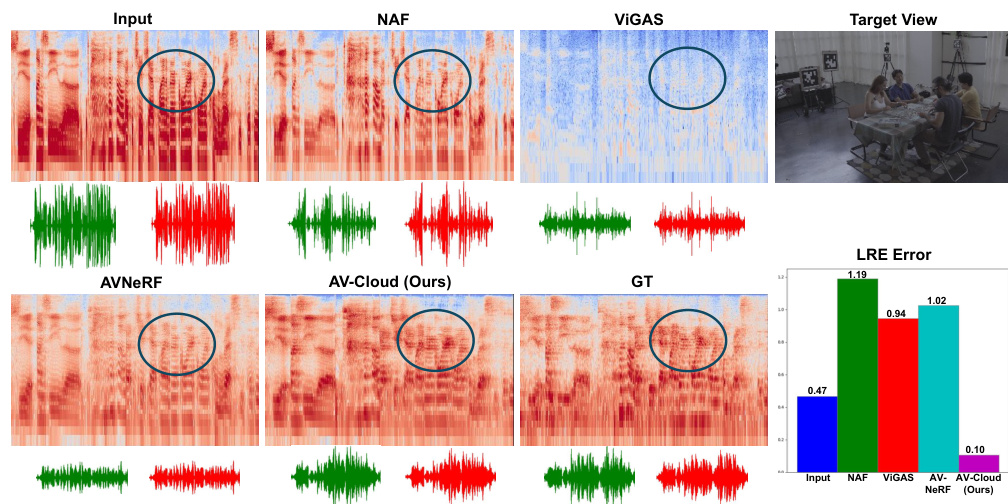
This figure compares the qualitative results of AV-Cloud with other state-of-the-art methods (NAF, VIGAS, AV-NeRF) for spatial audio rendering. The left side shows the input audio spectrogram, the spectrograms generated by each method, and finally the ground truth spectrogram. The bottom-left section displays the corresponding waveforms. The right side shows a bar chart comparing the Left-Right Energy Ratio (LRE) error for each method. The blue circles in the spectrograms highlight the reverberation effect, visually demonstrating AV-Cloud’s superior ability to capture and reproduce the prolonged energy decay characteristic of reverberation.

This figure illustrates the AV-Cloud framework. It starts with video collections which are processed to obtain structure from motion (SfM) points. These points are then clustered to create Audio-Visual Anchors. These anchors contain visual and audio information to represent the 3D scene. A novel Audio-Visual Cloud Splatting module decodes the anchors into a spatial audio transfer function based on the listener’s viewpoint. Finally, a Spatial Audio Render Head module takes monaural input and creates viewpoint-specific stereo audio. The whole system is designed to be synchronized with the visual rendering.

This figure illustrates the AV-Cloud framework, showing how it processes video data to generate synchronized spatial audio. The input is a collection of videos from which structure-from-motion (SfM) points are extracted. These points are used to create Audio-Visual Anchors (AV anchors) which capture both visual and audio information from the scene. These AV anchors form the Audio-Visual Cloud, and are used by the Audio-Visual Cloud Splatting module to decode a spatial audio transfer function. This function, along with a Spatial Audio Render Head, transforms a monaural input sound into viewpoint-specific spatial audio, aligned with the visual perspective. The figure highlights the key components of the system and the flow of data.

This figure visualizes how the AV-Cloud model interprets the scene to generate spatial audio. The left side shows a 3D point cloud of the scene, with the emitter (black triangle), listener (green cross), and AV Anchors (red circles) highlighted. The size of the red circles representing AV Anchors is proportional to their attention weights, indicating their importance in the spatial audio rendering. The right side shows images from real-world scenes corresponding to the point clouds on the left. This visualization demonstrates the ability of AV-Cloud to focus on relevant anchors based on listener position and emitter location, resulting in improved accuracy and realism.
More on tables

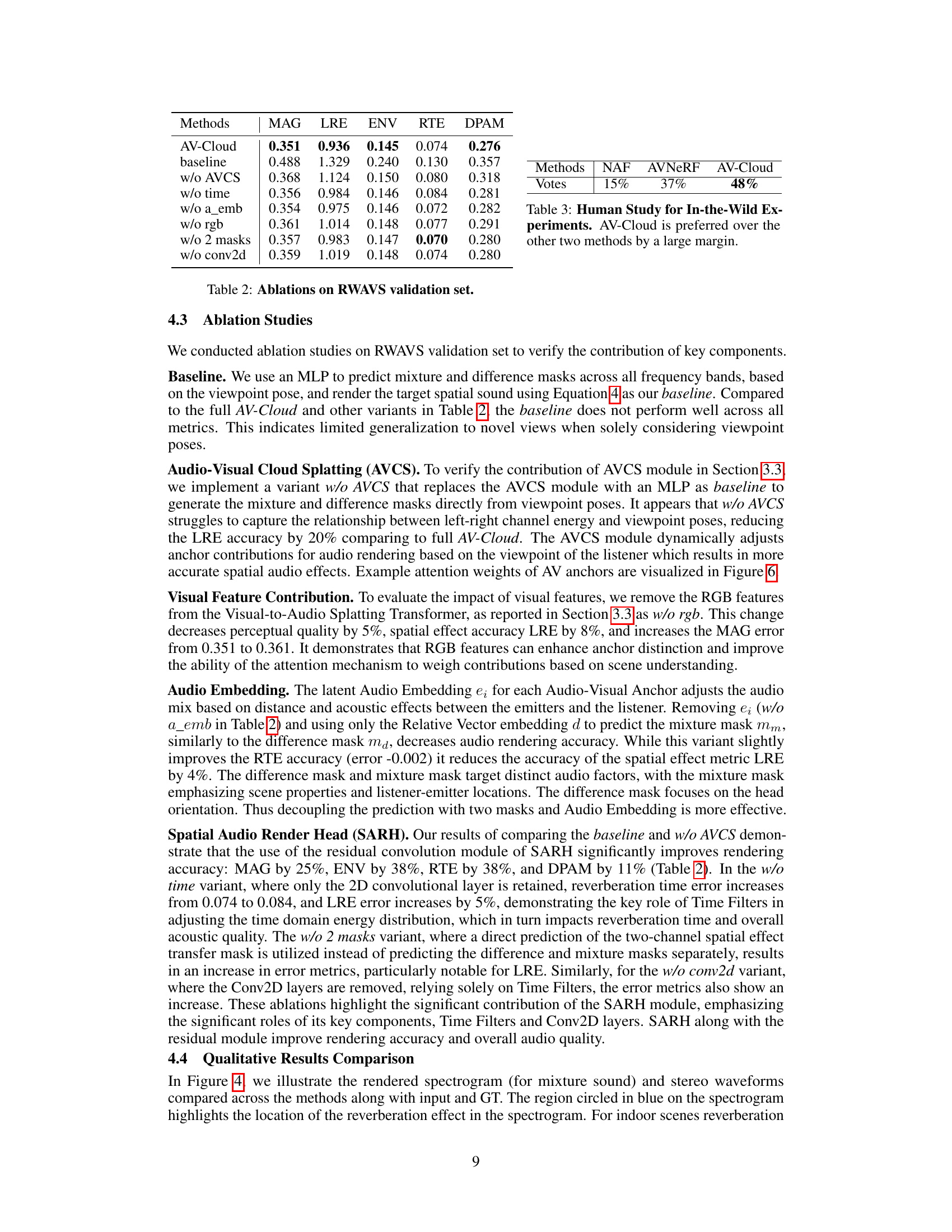
This ablation study analyzes the impact of different components of the AV-Cloud model on its performance using the RWAVS validation set. It compares the full AV-Cloud model to versions where key modules (AVCS, Time Filters, Audio Embedding, RGB features, and the two-mask structure) or layers (Conv2D layers) are removed or altered. The results show the contribution of each component to the overall accuracy, highlighting the importance of the AVCS module, the two-mask design and the Time Filters in achieving the optimal performance. The lower the value for each metric the better.

This table presents the results of a human study comparing AV-Cloud’s performance to two other methods (NAF and AVNeRF) in real-world scenarios. Participants viewed videos with spatial audio rendered by each method and selected the video whose sound best matched the visual perspective. AV-Cloud significantly outperformed the other two methods, demonstrating its effectiveness in producing realistic and synchronized audio-visual experiences.

This table compares the performance of the proposed AV-Cloud method against several state-of-the-art baselines on two real-world datasets, RWAVS and Replay-NVAS. The metrics used assess various aspects of audio reconstruction quality, including magnitude spectrogram distance, left-right energy ratio error, energy envelope error, reverberation time error, and deep perceptual audio metric. The table also shows the number of parameters and inference speed (FPS) for each method. Lower values generally indicate better performance for each metric. Different variants of the AV-Cloud model are also included for comparison.
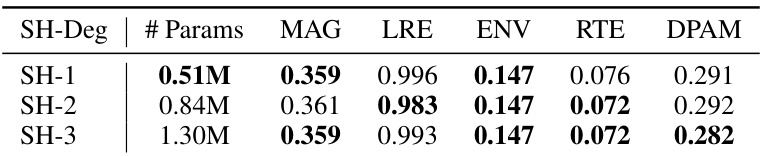
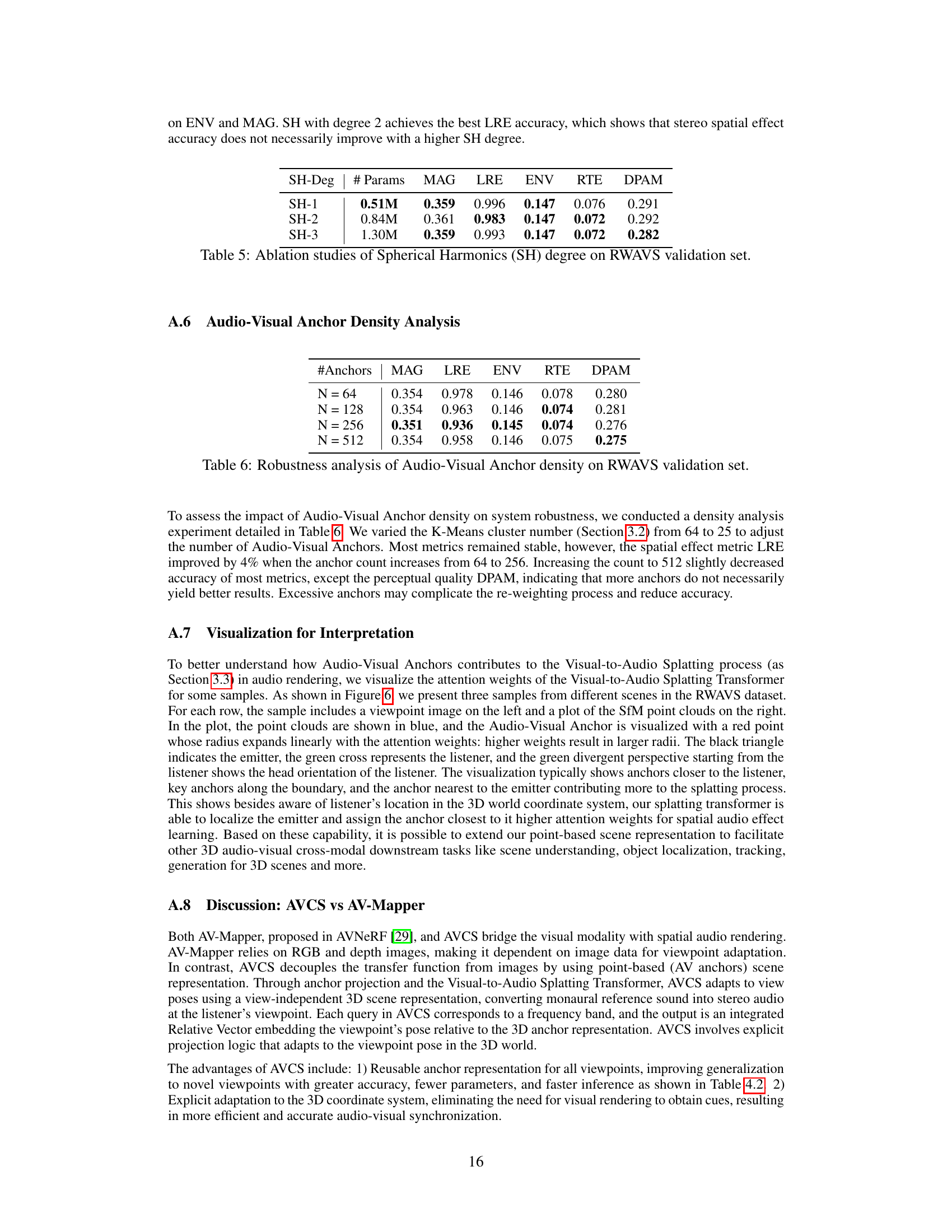
This table presents the ablation study results on the RWAVS validation set, focusing on the impact of varying the Spherical Harmonics (SH) degree in the Time Filters component of the Spatial Audio Render Head (SARH). It shows the model performance metrics (MAG, LRE, ENV, RTE, DPAM) for different SH degrees (1, 2, and 3), indicating how changes in the SH degree affect the accuracy of spatial audio rendering.
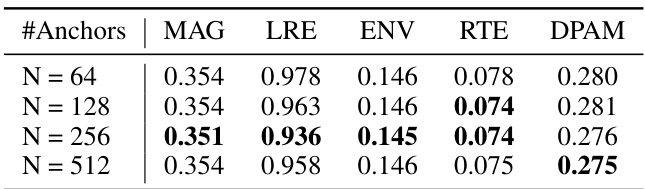
This table presents the results of an ablation study on the impact of varying the number of Audio-Visual Anchors on the performance of the AV-Cloud model. The study varied the number of anchors (N) from 64 to 512 and measured the performance using five metrics: Magnitude Spectrogram Distance (MAG), Left-Right Energy Ratio Error (LRE), Energy Envelope Error (ENV), RT60 Error (RTE), and Deep Perceptual Audio Metric (DPAM). The results show that increasing the number of anchors from 64 to 256 improves performance on several metrics, but further increasing the number of anchors does not yield consistent improvements.
Full paper#