↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
High-quality image super-resolution (SR) is crucial, but existing advanced diffusion models are computationally expensive, hindering real-world applications. This is particularly true for deployment on resource-constrained devices like mobile phones and IoT devices. Previous attempts to binarize diffusion models for efficiency resulted in significant performance loss.
This paper introduces BI-DiffSR, a novel binarized diffusion model that achieves impressive SR results while dramatically reducing computational costs. This was made possible by designing a UNet architecture optimized for binarization, incorporating consistent-pixel downsampling/upsampling and channel-shuffle fusion, and dynamically adjusting activation distributions across timesteps using timestep-aware redistribution and activation functions. The model’s impressive results demonstrate its potential for efficient deployment on limited hardware platforms.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and image processing due to its focus on binarized diffusion models, addressing the limitations of high computational costs in diffusion-based super-resolution. It presents a novel architecture and training strategies that improve efficiency without significant performance loss, opening new avenues for deploying advanced SR techniques on resource-constrained devices and broadening the applications of DMs.
Visual Insights#

This figure compares the super-resolution results of different binarization methods on the image Urban100: img_074. It shows that while some methods fail to produce usable results for diffusion models, or produce blurry/artifact-filled results, the authors’ proposed method (BI-DiffSR) achieves superior performance.
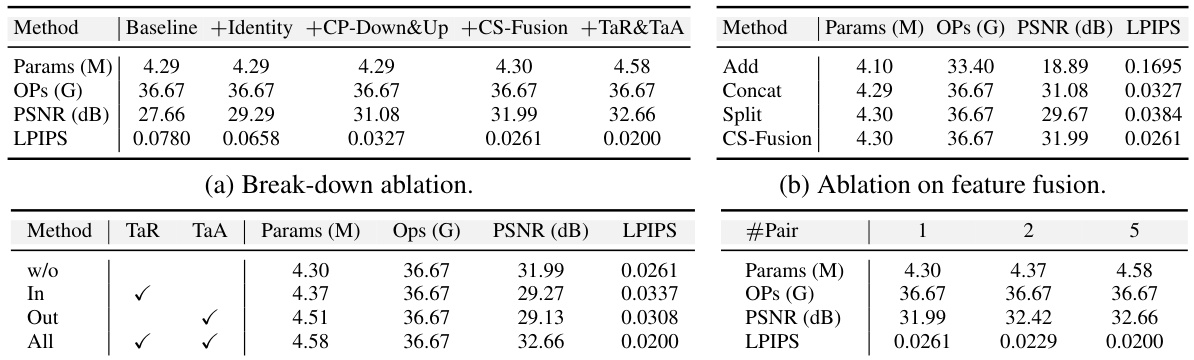
This table presents the ablation study of the proposed BI-DiffSR model. It shows the impact of different components on the performance, including adding an identity shortcut, using consistent-pixel downsampling/upsampling, incorporating channel-shuffle fusion, and applying timestep-aware redistribution and activation functions. The results are evaluated on the Manga109 dataset using a 2x upscaling factor, after training the models on DIV2K and Flickr2K datasets. The table demonstrates a gradual improvement in performance with the addition of each component.
In-depth insights#
Binarized Diffusion SR#
Binarized Diffusion SR represents a significant advancement in image super-resolution. By applying binarization techniques to diffusion models, it offers substantial improvements in computational efficiency and memory usage, crucial for deploying SR on resource-constrained devices. The core innovation lies in addressing the challenges posed by binarization on the intricate architecture and iterative process of diffusion models. This is achieved through a carefully designed UNet structure optimized for binarization, maintaining dimensional consistency and effective feature fusion even with 1-bit quantization. Furthermore, timestep-aware adjustments to activation distributions are incorporated to enhance the model’s flexibility and representation ability. The result is a binarized model that achieves comparable perceptual performance to its full-precision counterparts, while offering significantly reduced computational costs, opening the door for high-quality SR in applications previously inaccessible due to resource limitations.
UNet Architecture#
The UNet architecture is a popular choice for image segmentation tasks due to its symmetrical encoder-decoder structure, which efficiently captures both contextual and detailed information. The encoder progressively downsamples the input image to learn increasingly abstract features, while the decoder upsamples these features to reconstruct a high-resolution segmentation map. Skip connections between corresponding encoder and decoder layers are crucial, enabling the flow of fine-grained details from the encoder to the decoder, thereby improving the accuracy and resolution of the segmentation. The U-Net’s design is particularly well-suited for medical image analysis, where the ability to preserve fine details is important for accurate diagnosis. Variations of UNet exist, such as the use of different convolutional layers, attention mechanisms, or residual connections to optimize performance for specific tasks. The choice of architecture is crucial to the success of the model and needs to be carefully considered to ensure that it is appropriate for the specific image segmentation task.
CP-Down & CP-Up#
The consistent-pixel downsample (CP-Down) and consistent-pixel upsample (CP-Up) modules are crucial for maintaining dimensional consistency within the binarized UNet architecture. CP-Down elegantly addresses the challenge of dimension mismatch during downsampling by ensuring that the dimensions of the main residual block remain consistent. This is achieved through a strategic split of input features, processing them through binarized convolutions, and employing a Pixel-UnShuffle operation to manage feature resolution. CP-Up mirrors this approach for upsampling, using consistent-dimension convolutions and a Pixel-Shuffle operation to restore high-resolution representation. This carefully designed process facilitates the full-precision information transfer, compensating for the information loss introduced by binarization and enhancing overall model performance. The synergy of CP-Down and CP-Up ensures a smooth, dimensionally consistent flow of information, crucial for the success of the binarized diffusion model in image super-resolution.
Activation Distribution#
The section on activation distribution is crucial because it addresses a core challenge in binarizing diffusion models for image super-resolution: the significant changes in activation distributions across timesteps. Standard binarization techniques struggle with this dynamic behavior, leading to performance degradation. The authors astutely recognize this and propose two key mechanisms: Timestep-aware Redistribution (TaR) and Timestep-aware Activation Function (TaA). TaR dynamically adjusts the input activation distribution based on the timestep, while TaA modifies the output distribution accordingly. This approach, inspired by mixture-of-experts, cleverly uses multiple bias terms and activation functions to handle the varying distributions effectively. This is a significant contribution, as it directly tackles a key limitation of applying binary neural networks to the iterative process of diffusion models, enabling more robust feature representations despite the heavy compression.
Future of BI-DiffSR#
The future of BI-DiffSR lies in several key directions. Firstly, exploring more advanced binarization techniques beyond simple 1-bit quantization could significantly boost performance. Secondly, integrating BI-DiffSR with other efficient SR techniques (e.g., attention mechanisms, recursive modules) could improve efficiency and accuracy. Thirdly, investigating more sophisticated activation functions tailored for binarized models and adapting them to the dynamic nature of diffusion models will be essential. Fourthly, extending the model’s capabilities to handle higher-resolution images and video SR is a promising avenue. Lastly, thorough evaluation across a wider range of datasets with diverse image characteristics is necessary to assess the true robustness and generalization power of BI-DiffSR. Addressing these areas will solidify BI-DiffSR’s position as a leading contender in efficient image super-resolution.
More visual insights#
More on figures
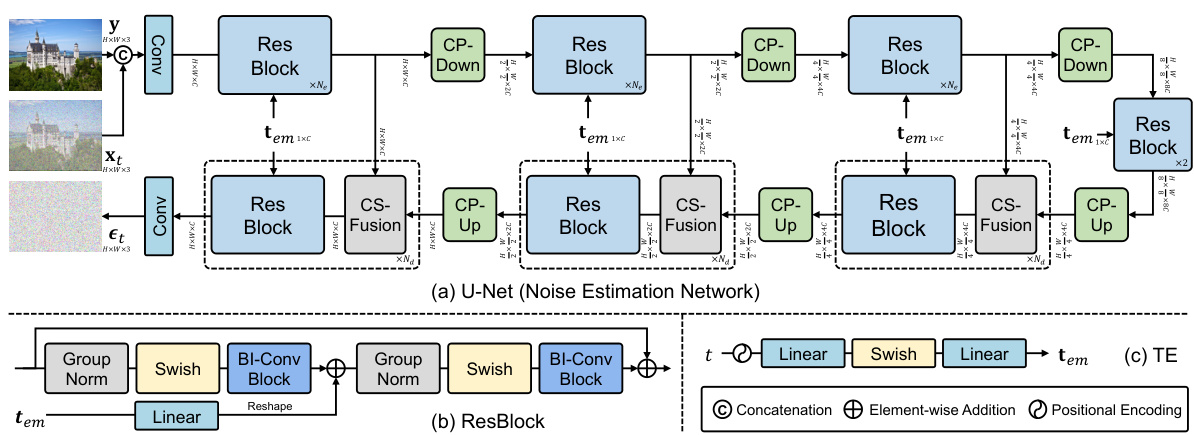
This figure shows the architecture of the noise estimation network used in the BI-DiffSR model. It details the UNet structure (a), which consists of residual blocks (ResBlocks), consistent-pixel downsampling (CP-Down), consistent-pixel upsampling (CP-Up), and channel-shuffle fusion (CS-Fusion) modules. The ResBlock (b) is highlighted, showcasing its use of binarized convolutions (BI-Conv) to maintain consistent input/output dimensions suitable for binarization. Finally, the timestep encoding (TE) process (c) is shown, which converts the timestep into a timestep embedding used in the network.
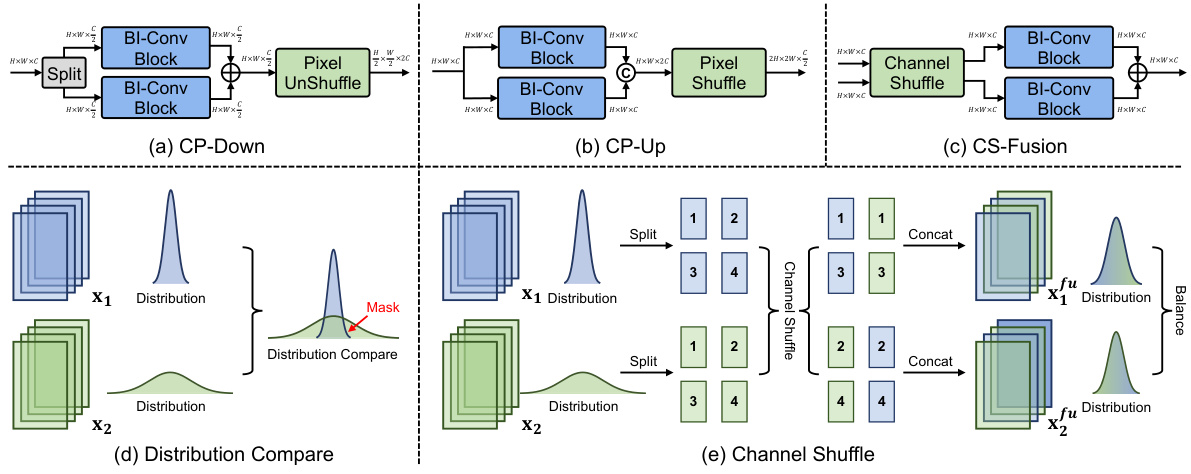
This figure details the architecture of the proposed BI-DiffSR model’s components for efficient binarization. (a), (b), and (c) show the consistent-pixel downsample (CP-Down), consistent-pixel upsample (CP-Up), and channel-shuffle fusion (CS-Fusion) modules respectively. These modules maintain dimensional consistency during feature scaling and facilitate effective fusion in skip connections, crucial for handling the information loss inherent in binarization. (d) illustrates the challenge of typical fusion methods (e.g., concatenation) in the presence of significantly different value ranges in skip connections. (e) demonstrates how the channel shuffle operation in CS-Fusion mitigates this issue by balancing activation ranges before fusion, improving the effectiveness of binarization.

This figure visualizes how activation distributions change across 50 timesteps in two different modules (ups.8.res_block.block2.block.3 and ups.13.res_block.block2.block.3) of a neural network. Each subplot shows a box plot representing the distribution of activation values at a given timestep. The figure demonstrates that the activation distributions change significantly across the 50 timesteps, shifting in both shape and range. This visualization is used to illustrate the challenge of maintaining consistency in the activation distributions throughout the diffusion model’s iterative process, especially for binarized modules.

This figure illustrates the architecture of the basic binarized convolutional block and the timestep-aware version. The basic block (a) uses a learnable bias and RPReLU activation function to adjust the activations before and after a 1-bit convolution. The timestep-aware version (b) extends this by using multiple pairs of bias and RPReLU, where only one pair is active at each timestep, adapting to the changing activation distributions throughout the diffusion process.
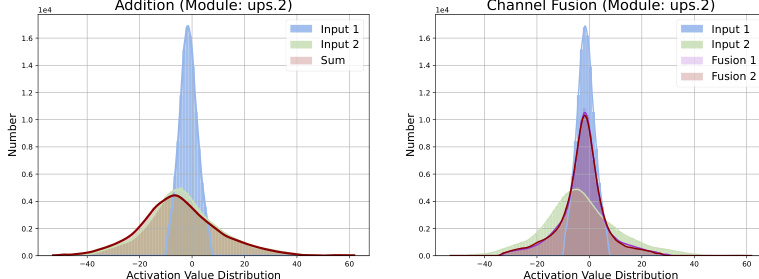
This figure compares the activation distributions before and after fusion in a skip connection within the UNet architecture of the BI-DiffSR model. It visually demonstrates the limitations of using simple addition for feature fusion in a binarized network. The left panel shows that direct addition of features (x1 and x2) leads to a skewed distribution where one input dominates, while the right panel illustrates how the proposed Channel-Shuffle Fusion (CS-Fusion) balances these distributions, resulting in more effective feature integration before being fed into the subsequent binarized convolutional layers.
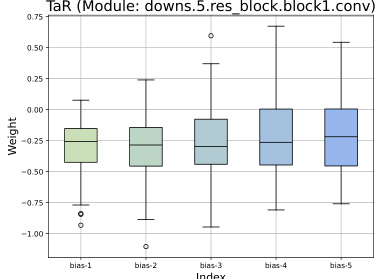
This box plot visualizes the distribution of weights for the five learnable biases (b(i)) used in the Timestep-aware Redistribution (TaR) module. Each bias corresponds to one of the five groups of timesteps, showing how the bias values vary across different timesteps. The distribution of bias weights suggests how TaR adapts its functionality to effectively handle variations in activation distributions over the course of the diffusion process.

This figure presents a visual comparison of different image super-resolution methods using binarization techniques. It shows that many existing binarization methods struggle to generate high-quality results when applied to diffusion models, producing blurry images or artifacts. In contrast, the proposed BI-DiffSR method produces significantly sharper and more accurate results compared to the other techniques.
Full paper#


















