↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional deep learning deploys models with fixed parameters, leading to performance degradation when encountering unseen data during deployment. Test-time adaptation (TTA) methods address this by updating models using test data, but existing TTA methods usually operate on single devices, neglecting valuable knowledge learned by other devices. This often leads to suboptimal adaptation performance, especially for resource-limited devices.
This paper introduces CoLA (Collaborative Lifelong Adaptation), a novel framework that leverages shared knowledge among multiple devices to enhance TTA. CoLA features two key strategies: knowledge reprogramming for powerful devices and similarity-based knowledge aggregation for resource-limited devices. The results show that CoLA significantly outperforms state-of-the-art TTA methods in collaborative, lifelong, and single-domain scenarios, proving its effectiveness and efficiency. CoLA’s optimization-free approach for resource-constrained devices is a significant advancement, enabling wider AI model deployments.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on test-time adaptation and federated learning. It introduces a novel collaborative lifelong adaptation paradigm (CoLA) that significantly improves efficiency and performance, addressing limitations of existing single-device methods. The optimization-free strategy for resource-constrained devices is particularly impactful, opening avenues for broader real-world deployment of AI models.
Visual Insights#

This figure compares single-device and collaborative test-time adaptation (TTA). Single-device TTA (a) shows each device adapting independently, which can be problematic for resource-constrained devices. The proposed collaborative TTA (b) introduces a shared knowledge store, allowing devices to leverage each other’s learned knowledge. ‘Principal Agents’ use this knowledge and learn new domain-specific knowledge through backpropagation, while ‘Follower Agents’ simply aggregate the shared knowledge.

This table presents the accuracy results of different test-time adaptation (TTA) methods on ImageNet-C (level 5) over 10 rounds of lifelong adaptation. Each round involves 15 different corruptions applied to the images. The table shows the average accuracy across these 15 corruptions for each round. The method CoLA is compared against several baseline methods, demonstrating its improvement in accuracy over time. More detailed results are available in Appendix D.
In-depth insights#
CoLA Framework#
The CoLA framework, a collaborative lifelong adaptation approach for test-time adaptation (TTA), presents a novel paradigm for handling domain shifts in multi-device settings. Its core innovation is the maintenance of shared domain knowledge vectors, accumulating knowledge from all participating devices. This knowledge base enables two distinct collaboration strategies: knowledge reprogramming learning for resource-rich devices (principal agents) and similarity-based aggregation for resource-constrained devices (follower agents). The framework elegantly addresses limitations of prior TTA methods, which often adapt independently and struggle with continual learning or resource limitations. CoLA’s strength lies in its efficiency and seamless integration with existing TTA techniques, enhancing accuracy and mitigating catastrophic forgetting. The architecture’s modularity and the optimization-free option for follower agents makes it highly practical for real-world deployment across diverse device capabilities.
Reprogramming#
Reprogramming, in the context of the provided research paper, likely refers to a test-time adaptation (TTA) method where a pre-trained model’s parameters are modified to better suit a new, unseen data distribution. This isn’t simply fine-tuning; it involves selectively updating specific parts of the model based on new information. The key is the ability to dynamically adjust the model’s behavior without extensive retraining. This may involve re-weighting existing knowledge, learning new domain-specific parameters, or a combination of both. Successful reprogramming hinges on efficiently using limited computational resources and minimizing latency, making it suitable for deployment on diverse devices. Collaboration across multiple devices further enhances the process by allowing for the sharing and aggregation of learned knowledge, creating a more robust and adaptable system. The essence is efficient, targeted adjustments that maximize performance in shifting environments without the need for a complete model rebuild.
Aggregation#
Aggregation, in the context of a multi-device collaborative test-time adaptation system, presents a crucial mechanism for harmonizing and leveraging knowledge learned independently across various devices. Effective aggregation strategies are essential to mitigate the limitations of isolated, single-device adaptation, where individual models may encounter only a subset of the data distribution and fail to generalize effectively to unseen domains. The success of aggregation hinges on resolving challenges related to data heterogeneity, communication efficiency, and privacy preservation. A well-designed aggregation strategy must efficiently combine device-specific knowledge into a globally useful representation while minimizing the transmission overhead and preserving the privacy of individual devices’ data. Methods for achieving this may include optimization-free approaches such as similarity-based aggregation, which avoids the computational cost of backpropagation, and weighted averaging of shared domain vectors, where weights reflect domain similarity or device reliability. Optimization-based aggregation strategies are also feasible, potentially leveraging neural networks to learn optimal weights for combining diverse knowledge representations; however, such approaches may require careful consideration of computational resource constraints and potential biases stemming from uneven data distributions across devices.
Lifelong Adaptation#
Lifelong adaptation in machine learning focuses on creating systems that continuously learn and adapt over time, without catastrophic forgetting of previously acquired knowledge. This is crucial for real-world applications where data streams are non-stationary and environments change. A key challenge lies in efficiently managing and integrating new knowledge with existing knowledge representations without destabilizing the overall model. Effective lifelong learning often requires sophisticated mechanisms for knowledge consolidation and selective forgetting, allowing the system to prioritize relevant information and discard outdated or irrelevant data. Collaborative lifelong learning, as explored in the provided research paper, offers the potential to significantly improve adaptation performance and efficiency, by enabling knowledge sharing and accumulation across multiple devices or agents. This approach addresses the limitations of independent adaptation by exploiting the shared knowledge amongst collaborators. However, challenges remain in designing robust and privacy-preserving collaborative methods that can scale to large numbers of devices and handle heterogeneous data streams. Future research in lifelong adaptation should focus on developing more robust and efficient algorithms, exploring novel knowledge representation techniques, and addressing the challenges of data heterogeneity and privacy.
Future Works#
The ‘Future Works’ section of this research paper presents exciting avenues for extending the current CoLA framework. Improving sample efficiency is crucial, especially for resource-constrained devices. Exploring different knowledge representation methods beyond domain vectors could unlock more robust adaptation. Extending CoLA to handle more complex scenarios, such as those with concept drift or significant label noise, is a significant challenge but offers high rewards. Furthermore, investigating the interaction between CoLA and various prompt engineering techniques for different modalities (e.g., language, vision) and the integration of CoLA with continual learning methods to enable truly lifelong adaptation are important directions. Finally, thorough evaluations across a broader range of datasets and tasks is needed to demonstrate the generalizability and practical impact of CoLA. Addressing these future works promises to further refine and expand the capabilities of CoLA, making it a more powerful and versatile tool for real-world test-time adaptation.
More visual insights#
More on figures

This figure illustrates the CoLA framework. It shows how shared domain knowledge vectors (T) are maintained and used by both principal and follower agents. Principal agents use backpropagation to learn new domain-specific parameters (A) and a reweighting term (α) to reprogram the shared knowledge. Follower agents use a simpler, optimization-free method to aggregate shared knowledge based on domain similarity.
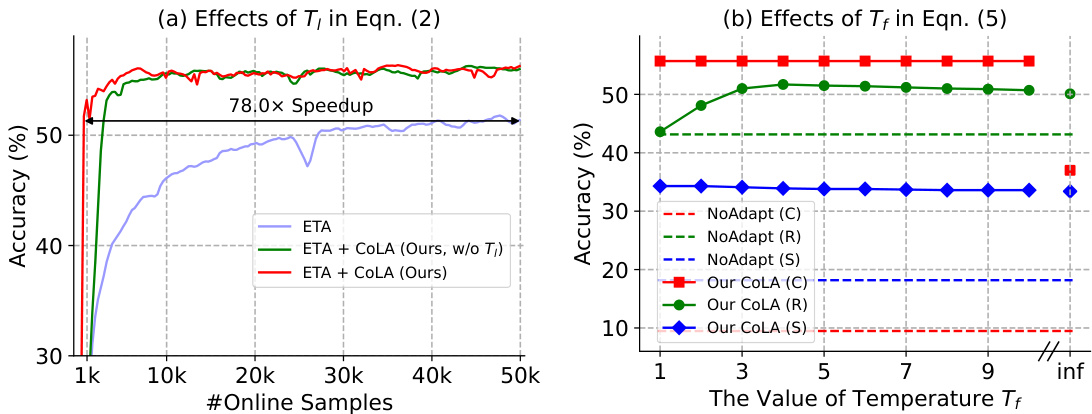
This figure presents an ablation study of the proposed CoLA method. The left subplot shows a comparison of sample efficiency on Device 2 from Table 2 using the Gaussian noise corruption type from ImageNet-C. It compares the performance of ETA with and without the proposed CoLA method, showing significant improvement with CoLA. The right subplot demonstrates the impact of the temperature scaling factor Tf (introduced in Equation 5 of the paper) on the model’s accuracy. It evaluates the accuracy of the model on seen and unseen distributions using different values of Tf, showing the robustness of the method across different distribution types.

This figure compares single-device and collaborative test-time adaptation (TTA). Single-device TTA operates independently on each device, potentially failing on resource-constrained devices. Collaborative TTA shares knowledge across devices, enabling two adaptation strategies: 1) knowledge reprogramming (principal agents with sufficient resources) and 2) similarity-based aggregation (follower agents with limited resources).
This figure presents an ablation study of the proposed CoLA method. The left subplot shows a comparison of sample efficiency on Device 2 (from Table 2) using the Gaussian noise corruption from ImageNet-C. It compares the accuracy of ETA and ETA+CoLA (with and without the temperature scaling factor Tf) as a function of the number of online samples used for adaptation. The right subplot demonstrates the impact of the temperature scaling factor Tf on the accuracy of CoLA when adapting to both seen (ImageNet-C and Gaussian noise) and unseen (ImageNet-R and ImageNet-Sketch) distributions. The results highlight CoLA’s sample efficiency and robustness across different datasets.

This figure presents an ablation study of the proposed CoLA method. The left subplot shows a comparison of sample efficiency on Device 2 from Table 2 (Gaussian noise). The accuracy of the model is evaluated on the complete test set after adapting to varying numbers of test samples, comparing the proposed method with and without the temperature scaling factor (T_f). The right subplot demonstrates the impact of the temperature scaling factor (T_f) on the accuracy of the method across seen (ImageNet-C, Gaussian noise) and unseen (ImageNet-R and ImageNet-Sketch) distributions. The results highlight the importance of T_f for achieving robustness and sample efficiency.

This figure illustrates the CoLA framework, showing how principal and follower agents utilize shared domain knowledge vectors (T). Principal agents learn new domain-specific parameters (A) and reweighting terms (α) via backpropagation, updating T. Follower agents optimize-free aggregate knowledge from T based on domain similarity.
More on tables

This table presents the accuracy results of different test-time adaptation (TTA) methods on ImageNet-C, a corrupted version of the ImageNet dataset, under a collaborative adaptation scenario. The methods are evaluated across multiple devices, leveraging shared knowledge among them. The table shows how the accuracy changes with each group of corruptions across the different devices and compares the results of the proposed collaborative approach to existing TTA methods.

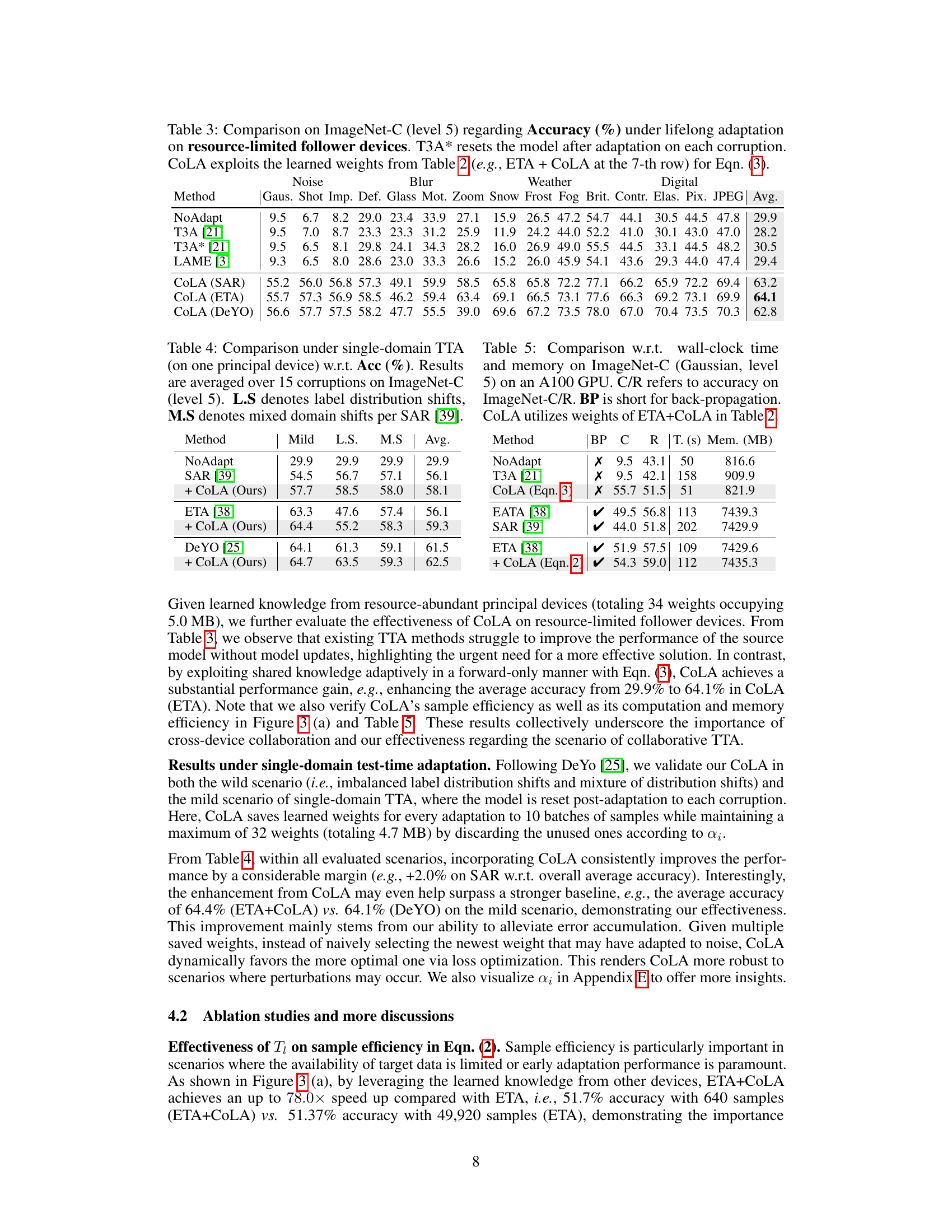
This table presents the accuracy results of different test-time adaptation methods on ImageNet-C with level 5 corruption. The methods compared include T3A, T3A* (resetting the model after each corruption), LAME, and three variants of CoLA (combined with SAR, ETA, and DeYO). The table highlights CoLA’s ability to improve accuracy on resource-limited devices by leveraging knowledge learned from resource-abundant devices.
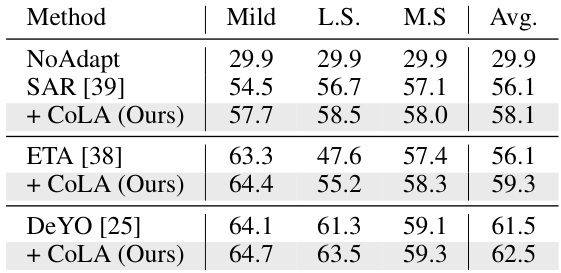
This table presents the accuracy results of different test-time adaptation (TTA) methods on ImageNet-C under single-domain scenarios. It compares the performance of several methods (NoAdapt, SAR, ETA, DeYO, and their respective CoLA versions) across three settings: mild label shift (L.S.), mixed domain shifts (M.S.), and an average across all corruption types. The results highlight the effectiveness of CoLA in improving the accuracy of baseline TTA methods.

This table compares the wall-clock time and memory usage of different test-time adaptation methods on the ImageNet-C dataset (Gaussian noise, level 5). It shows the computation time and memory requirements for each method, highlighting the efficiency gains achieved by CoLA, especially when compared to backpropagation-based methods.
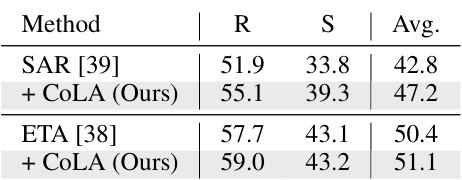
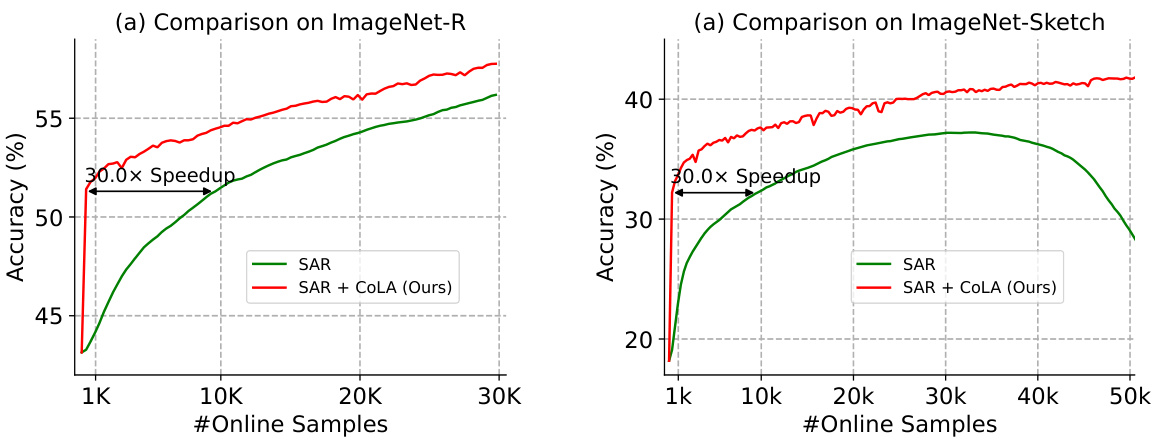
This table shows the effectiveness of the proposed CoLA method on unseen distributions (ImageNet-R and ImageNet-Sketch). It compares the average accuracy of SAR and ETA baselines with and without CoLA. The weights used for CoLA were those learned from the ImageNet-C experiments reported in Table 2. This demonstrates CoLA’s ability to generalize to unseen data and improve upon existing state-of-the-art methods.

This table shows the effectiveness of CoLA (using 78 hard prompts) on prompt tuning for image classification using the CLIP-RN50 model. The results are presented for ImageNet and four of its variants (ImageNet-A, ImageNet-V2, ImageNet-R, and ImageNet-Sketch), comparing the performance of CoLA against a baseline (NoAdapt) and another method (TPT). The average accuracy across all datasets is reported.

This table compares different test-time adaptation (TTA) methods based on several key characteristics: whether the adaptation is performed online or offline, the number of devices involved, whether knowledge is accumulated across tasks, the resource constraints of the devices, privacy considerations, and the amount of data transmitted. It highlights the differences in approaches to TTA, emphasizing the novelty of the proposed CoLA method in terms of collaborative lifelong adaptation and resource efficiency.
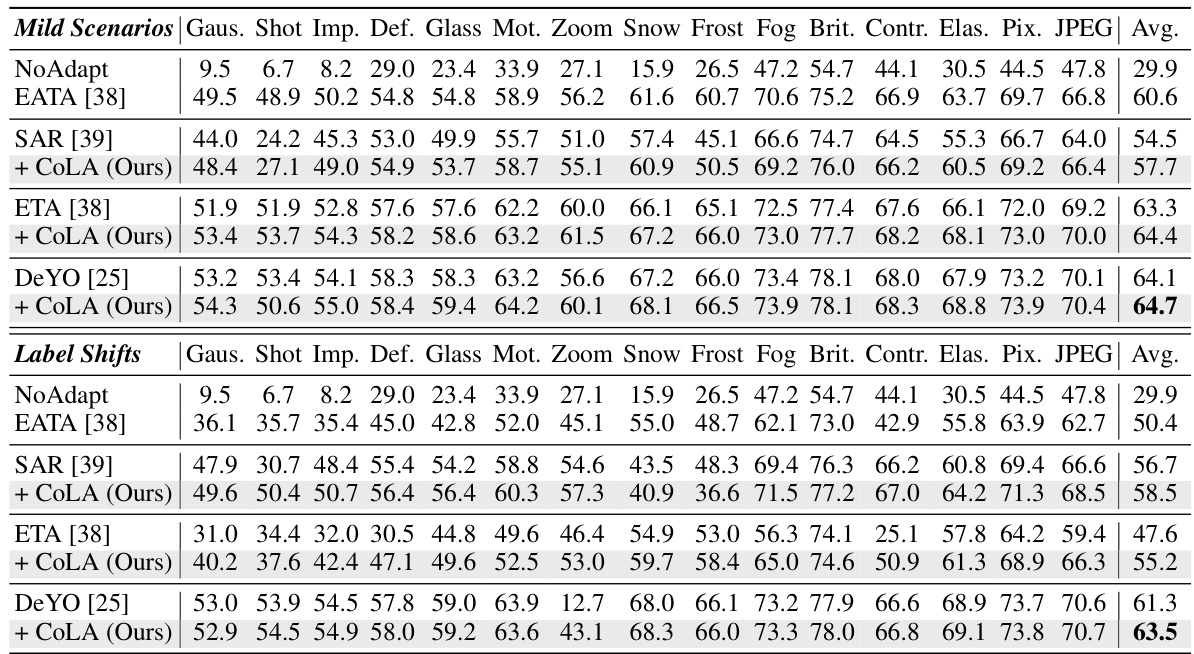
This table shows the accuracy of different test-time adaptation methods on ImageNet-C under a lifelong adaptation setting. The experiment was conducted on a single, high-resource device for 10 rounds, with each round involving 15 different corruption types. The table reports the average accuracy for each round, highlighting the performance of the proposed CoLA method compared to several baselines. Appendix D contains more detailed results.

This table presents the accuracy results of different test-time adaptation methods on ImageNet-C under a lifelong adaptation setting. The experiment involves 10 rounds with 15 different corruptions in each round for a total of 150 corruptions. The results show the average accuracy for each round and highlight the performance of CoLA in comparison to other methods.

This table shows the accuracy of different test-time adaptation methods on ImageNet-C (corruption level 5) over 10 rounds of adaptation. Each round involves 15 different corruptions. The table compares the performance of various methods, including CoLA (the proposed method), and highlights the performance of CoLA in comparison with the others. The average accuracy is reported along with the results for each individual round, demonstrating the effectiveness of CoLA in maintaining performance over many rounds of adaptation. More detailed results are available in Appendix D.

This table demonstrates the robustness of CoLA against harmful prior knowledge. It shows the accuracy results of ETA+CoLA on ImageNet-C (Gaussian, level 5) with different numbers (N) of randomly initialized domain vectors representing harmful knowledge. The results indicate that CoLA is not significantly impacted by the presence of harmful prior knowledge, maintaining high accuracy even when N is large. This highlights the stability of CoLA’s mechanism for adaptively aggregating shared knowledge.

This table demonstrates the scalability of CoLA with an increasing number of principal devices. It shows that the accuracy of both SAR+CoLA and ETA+CoLA increases as the number of devices increases, highlighting the benefits of cross-device collaboration in improving test-time adaptation performance. The results are averaged across all participating principal devices, and each device experiences 15 different ImageNet-C corruptions in various sequences.
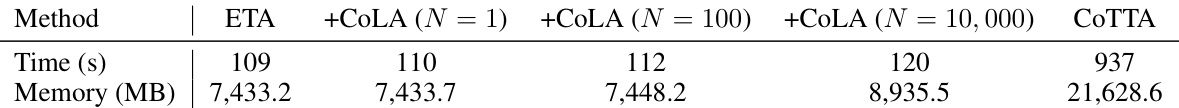
This table compares the efficiency (Time and Memory) of different methods: ETA, and ETA incorporated with CoLA using varying numbers of domain vectors (N = 1, 100, 10000), against CoTTA. It demonstrates CoLA’s efficiency in scaling with the number of domain vectors, showing minimal increase in time and memory consumption compared to CoTTA.

This table presents the accuracy results of different test-time adaptation (TTA) methods on ImageNet-C under a lifelong adaptation setting. The experiment involves 10 rounds, with a total of 150 corruptions (15 corruption types, each with 5 severity levels) applied to the images. The results show the average accuracy across all 15 corruptions for each of the 10 rounds. CoLA is compared to other baseline methods to show its effectiveness in mitigating performance degradation during continual adaptation. More detailed results are available in Appendix D.
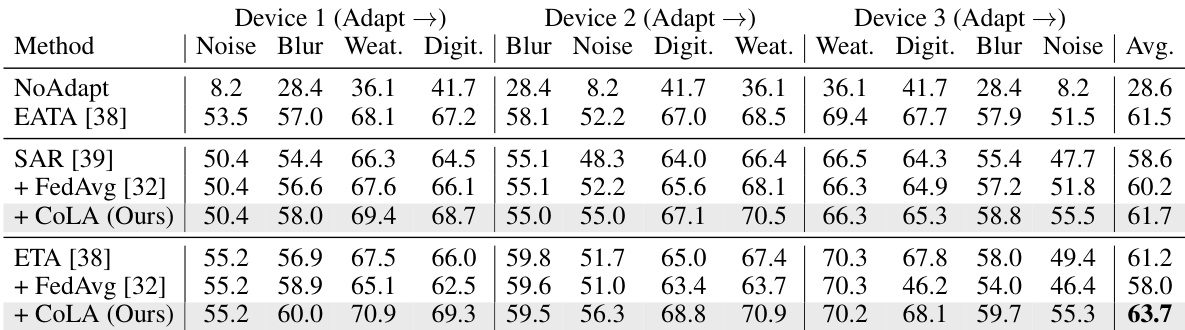
This table presents the accuracy results of different test-time adaptation methods on ImageNet-C with 15 corruption types, categorized into 4 groups. The experiment involves multiple principal (resource-abundant) devices collaborating. After each device independently adapts to a group of corruptions, the learned weights are shared among all devices. The table compares the performance of several methods including CoLA, demonstrating its effectiveness in collaborative adaptation.

This table presents the robustness of the CoLA method under different batch sizes (BS). It compares the average accuracy achieved by SAR and ETA, both with and without CoLA, across various batch sizes (64, 16, 4, and 2). The results demonstrate the stability of CoLA across varying batch sizes, showcasing its consistent performance regardless of the batch size used.
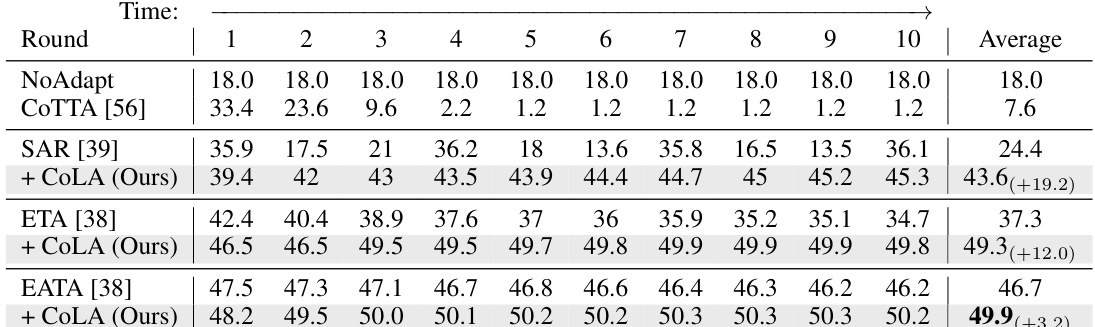
This table presents the results of a lifelong adaptation experiment conducted on ImageNet-C (level 5) using a single, resource-abundant device. The experiment lasted for 10 rounds, with a total of 150 corruptions. The table shows the average accuracy for each round, highlighting the performance of different methods, including CoLA, over time. More detailed results are available in Appendix D.
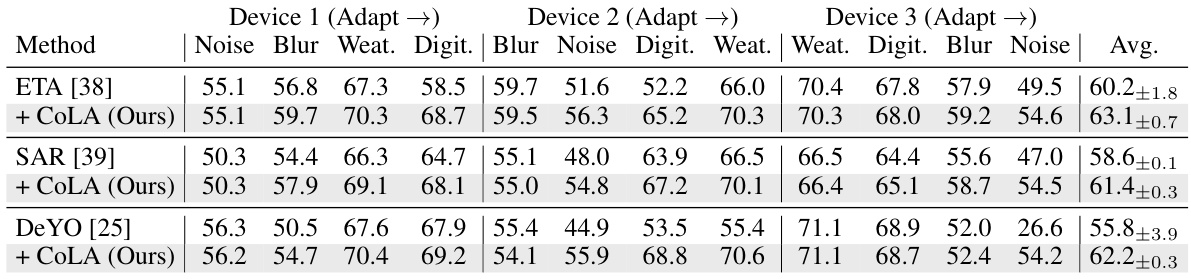
This table presents the accuracy results of different test-time adaptation methods on ImageNet-C under collaborative adaptation scenarios. It compares the performance of several methods, including CoLA, across three devices, each adapting to different groups of corruptions. Shared knowledge is leveraged, and the average accuracy across all devices is reported, highlighting the effectiveness of collaborative adaptation.
Full paper#