↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many vision-language models struggle with specialized domains or fine-grained tasks due to limited training data in those areas. Prompt learning offers a solution by adapting the model efficiently with limited annotations; however, current methods may rely on expensive Large Language Models (LLMs) for generating effective prompts, causing high computational costs.
This research proposes Aggregate-and-Adapt Prompt Embedding (AAPE) to address this. AAPE distills textual knowledge from natural language prompts to improve prompt learning, generating an embedding that remains close to an aggregated prompt summary and minimizes task loss. This clever technique is trained in two stages: a prompt aggregator and a prompt generator. During testing, only the generator is used, eliminating the need for LLMs at inference time and thus reducing costs. Experiments showed improved performance on various tasks and better generalization to different data distributions and challenging scenarios.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on vision-language models and prompt learning. It introduces a novel method to improve the generalization capabilities of these models, particularly in low-data and specialized domains, which is a significant challenge in the field. The efficient approach presented, avoiding reliance on costly LLMs during inference, offers practical benefits and opens avenues for more data-efficient and scalable solutions. This has implications for various downstream tasks and could help advance progress in areas like few-shot learning and OOD generalization.
Visual Insights#
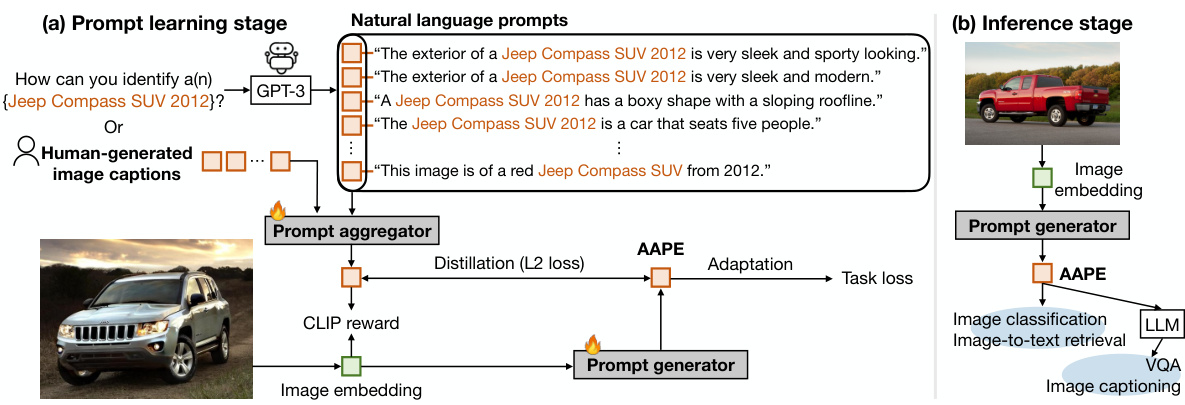
This figure illustrates the Aggregate-and-Adapt Prompt Embedding (AAPE) method. The (a) part shows the prompt learning stage where a prompt aggregator summarizes multiple natural language prompts (either human-generated or from GPT-3) into a single image-aligned prompt embedding. A prompt generator then learns to create an AAPE embedding that’s close to the summary while minimizing the task loss. (b) shows the inference stage, where only the prompt generator is used, making the process efficient at test time. AAPE is shown to work well for various downstream vision-language tasks.
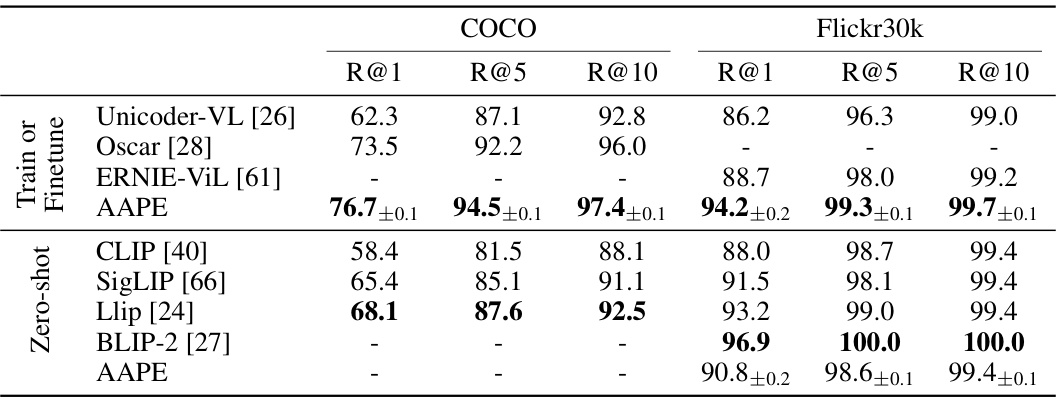
This table presents the results of image-to-text retrieval experiments using the Aggregate-and-Adapt Prompt Embedding (AAPE) method. The model was first trained on the COCO dataset and then evaluated in zero-shot and finetuned settings on the Flickr30k dataset. The results are reported in terms of Recall@K, a metric that measures the percentage of times the correct text caption is retrieved among the top K results. The table compares the performance of AAPE against several state-of-the-art methods in the zero-shot and finetuned settings.
In-depth insights#
CLIP’s Limits#
CLIP, while a powerful vision-language model, exhibits limitations in handling specialized domains and fine-grained tasks. Its web-scale pretraining, while beneficial for general understanding, may under-represent niche visual concepts. This leads to poor generalization when applied to downstream tasks involving satellite imagery, or the fine-grained classification of car models or flower species. The domain gap between pretraining and downstream tasks further exacerbates the issue. Addressing these limitations necessitates strategies beyond simply finetuning, such as exploring techniques like prompt learning to adapt CLIP effectively to specialized domains with limited data. Distilling textual knowledge from natural language prompts offers a parameter-efficient approach that leverages rich linguistic priors to enhance CLIP’s performance on under-represented concepts. Therefore, overcoming CLIP’s limitations requires focusing on robust and efficient adaptation methods.
AAPE Method#
The Aggregate-and-Adapt Prompt Embedding (AAPE) method is a novel prompt learning technique designed to enhance the downstream generalization capabilities of CLIP-like vision-language models. AAPE addresses the challenge of limited data in specialized domains by distilling textual knowledge from natural language prompts (either human-generated or LLM-generated). This distillation process leverages a learned prompt aggregator to create an image-aligned summary of the input prompts, effectively filtering out redundant or irrelevant information. A prompt generator, trained jointly with the aggregator, then produces the AAPE, optimizing for both proximity to the summary and minimization of task loss. The core advantage lies in its ability to generalize across various downstream tasks and data distributions, while eliminating the computational cost associated with LLM inference at test time. This efficiency is a significant improvement over existing LLM-based prompt learning methods. AAPE’s efficacy is particularly noteworthy in few-shot and out-of-distribution scenarios, demonstrating the value of its learned, input-adapted prompt embeddings. The method’s data efficiency and scalability, outperforming LLM-based baselines, further solidify its potential as a valuable technique in the field of vision-language model adaptation.
LLM Prompt Use#
The utilization of Large Language Models (LLMs) for prompt generation in the research paper represents a significant advancement in adapting CLIP for downstream tasks. The approach leverages the rich textual knowledge embedded within LLMs to generate diverse and descriptive prompts, addressing the limitations of hand-crafted or simpler prompts which often lack nuance. Prompt aggregation is a key step, summarizing multiple LLM-generated prompts into a concise, image-aligned embedding. This crucial step enhances efficiency and filters out redundant or irrelevant information, resulting in a more effective supervisory signal for prompt learning. The overall methodology demonstrates parameter efficiency and strong generalization to diverse downstream datasets and vision-language tasks. However, a limitation is the potential for inheriting biases present in the LLM-generated prompts, emphasizing the importance of careful consideration in the design and application of this approach.
Downstream Tasks#
The concept of “Downstream Tasks” in the context of a vision-language model research paper refers to the application of a pre-trained model to specific tasks after its initial training. These tasks usually involve a more focused dataset and objective than the general web-scale data used for pre-training. The performance on these downstream tasks is a crucial metric for evaluating the model’s generalization ability and practical usefulness. The paper likely explores several downstream tasks, perhaps including image classification (especially fine-grained classification), visual question answering (VQA), and image captioning. Success in these diverse areas would demonstrate the model’s adaptability and robustness. A key area of focus would be how effectively the model transfers knowledge learned during pre-training to these specialized scenarios, especially in low-data regimes. The results section of the paper would analyze the performance, emphasizing the model’s strengths and weaknesses in different downstream tasks and datasets. Analysis might include comparisons against existing state-of-the-art models to establish the novelty and competitive edge of the proposed model. Furthermore, the paper would likely delve into the challenges posed by the downstream tasks, such as class imbalance, out-of-distribution samples, and noisy annotations, providing crucial insights into practical applications and future research directions.
Future Work#
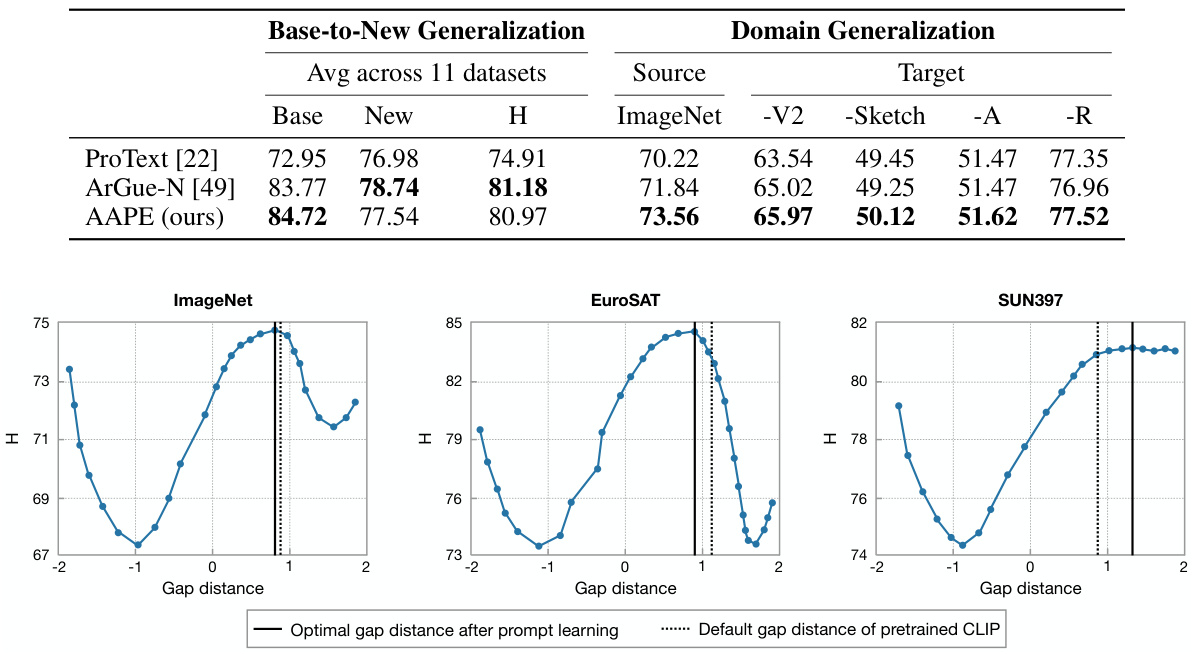
The authors acknowledge several avenues for future research. Scaling up the number of aggregated prompt embeddings to better capture text diversity is a crucial next step, although this presents challenges in data-deficient scenarios. Exploring the application of AAPE to other vision-language models beyond CLIP, including those based on contrastive or generative learning paradigms, is another key area. Further investigation into the relationship between modality gap, as defined in prior work, and downstream generalization performance is warranted, considering the AAPE method’s unexpected success despite not always reducing modality gap. Finally, a more in-depth analysis of the influence of biases potentially present in LLM-generated or human-written prompts and the mitigation of those biases within the AAPE framework is essential for responsible application and broader societal impact.
More visual insights#
More on figures

This figure illustrates the Aggregate-and-Adapt Prompt Embedding (AAPE) method. Panel (a) shows the prompt learning stage, where natural language prompts (either from GPT-3 or human-generated) are aggregated into an image-aligned summary using a learned prompt aggregator. A prompt generator then creates an AAPE embedding that balances closeness to the summary with minimization of task loss. Panel (b) shows the inference stage, where only the trained prompt generator is used, removing the need for LLMs at test time. AAPE is applied to various downstream vision-language tasks.

Figure 3 shows the architecture of the input-adapted prompt aggregator and the overall prompt learning framework for image classification. The aggregator uses an attention mechanism to combine reference prompts into a single, image-aligned embedding (p ). This is then used to supervise a prompt generator (h) that creates the final Aggregate-and-Adapted Prompt Embedding (AAPE). The CLIP model itself remains frozen during this learning process. The classification process involves combining the AAPE with a class template, and then projecting to obtain final classification weights.
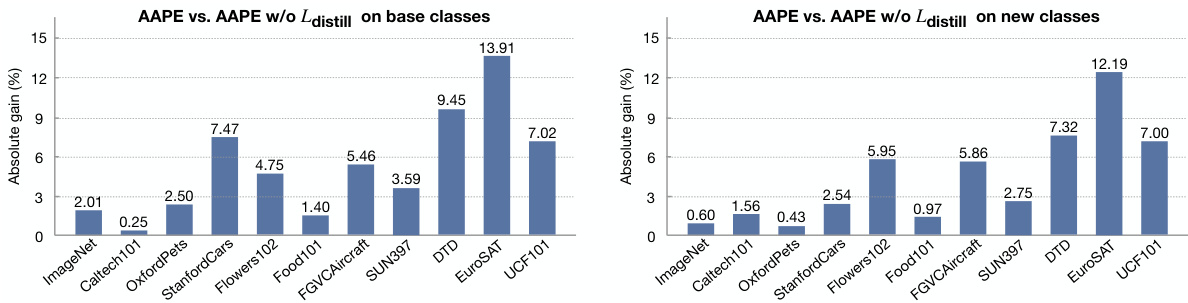
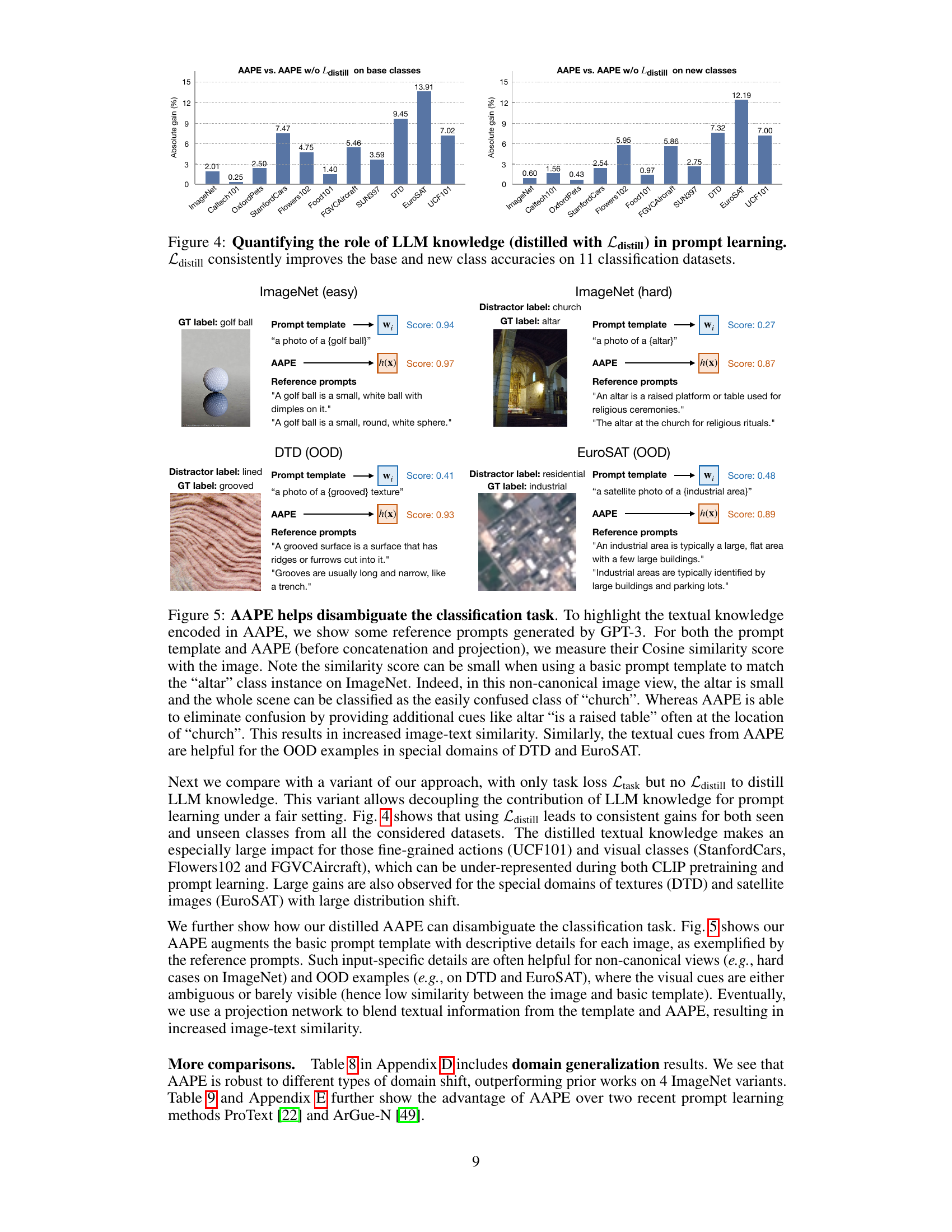
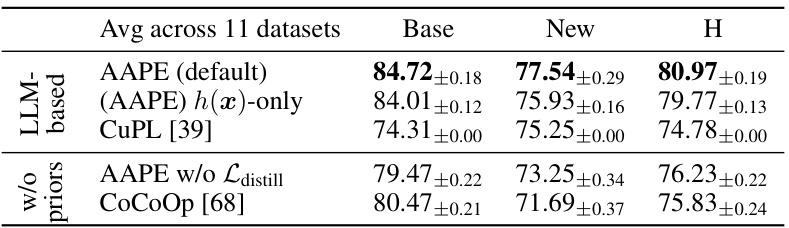
This figure shows two bar charts visualizing the absolute gain in accuracy achieved by using the distillation loss (Ldistill) in the AAPE (Aggregate-and-Adapt Prompt Embedding) method compared to not using it. The left chart displays the results for base classes, while the right chart shows the results for new classes across 11 different datasets used in the few-shot image classification task. The results consistently demonstrate that incorporating LLM knowledge through distillation significantly boosts performance for both base and new classes in various datasets.

This figure demonstrates how AAPE leverages textual knowledge from LLM-generated prompts to improve classification accuracy, especially in cases with non-canonical views or out-of-distribution (OOD) examples. It highlights how AAPE’s additional textual cues help disambiguate similar classes and improve image-text similarity scores.

This figure shows the scaling performance of AAPE compared to other methods in few-shot image classification. It demonstrates that AAPE performs better with more data and larger language models. The experiments use the base-to-new class generalization setting, and the harmonic mean of base and new class accuracies is used as the performance metric. The number of shots per class, the number of prompts per LLM prompt and the size of the LLM are varied to show the effect of these factors on the performance.

This figure illustrates the proposed Aggregate-and-Adapt Prompt Embedding (AAPE) method. Panel (a) shows the prompt learning stage, where natural language prompts (either from GPT-3 or human-generated) are aggregated into a concise summary embedding for each image using a learned prompt aggregator. A prompt generator is then trained to produce an AAPE embedding that is close to the summary while minimizing the task loss. Panel (b) depicts the inference stage where only the trained prompt generator is used to generate AAPE embeddings for downstream tasks, eliminating the need for LLM inference at test time. The method adapts to various vision-language tasks.
This figure shows two bar charts visualizing the absolute gain in accuracy achieved by using the distillation loss (Ldistill) compared to not using it, for both base classes and new classes across 11 image classification datasets. The results demonstrate a consistent improvement in accuracy when Ldistill is included in the training process, highlighting the importance of distilling knowledge from large language models (LLMs) for improved prompt learning and downstream generalization.

This figure shows a comparison of image captioning results on the NoCaps dataset between the LiMBeR model and the LiMBeR model enhanced with AAPE (Aggregate-and-Adapted Prompt Embedding). For each of six example images, the ground truth caption is provided, along with captions generated by LiMBeR and LiMBeR+AAPE. The examples highlight how adding AAPE to LiMBeR improves the quality and accuracy of the generated captions, especially in cases where the visual information is ambiguous or complex. The improved results are especially noticeable in images where visual cues are difficult to interpret; this demonstrates AAPE’s capability in improving caption quality when faced with difficult or ambiguous images.

This figure shows examples of LLM-generated image prompts for ImageNet, compared to human-written captions for COCO and Flickr30k. It highlights the difference in image complexity and prompt style. ImageNet prompts focus on object-centric descriptions, while COCO and Flickr30k captions describe multi-object scenes with more complex relationships.

This figure shows examples of LLM-generated image prompts for ImageNet, and hand-constructed image captions for COCO and Flickr30k datasets. It highlights the difference in image characteristics between the datasets. ImageNet images are mainly object-centric with clean backgrounds, allowing for concise, descriptive prompts focusing on object features. In contrast, COCO and Flickr30k images feature multiple objects and cluttered backgrounds, necessitating more complex captions that capture the relationships between objects.

This figure illustrates the Aggregate-and-Adapt Prompt Embedding (AAPE) method. Panel (a) shows the prompt learning stage, where GPT-3 or human-generated captions provide multiple prompts per image. These prompts are aggregated into a single, image-aligned summary embedding using CLIP reward. A prompt generator then creates the AAPE, aiming to minimize both the distance to the aggregated summary and the task loss. Panel (b) shows the inference stage, where only the prompt generator is used, making the process efficient by eliminating LLM inference costs at test time. AAPE is applied to various vision-language tasks, demonstrating strong generalization.

This figure shows example prompts generated by LLMs (Large Language Models) for ImageNet, and hand-constructed captions for COCO and Flickr30k datasets. It highlights the differences in image characteristics and caption styles across these datasets. ImageNet images are primarily object-centric with clean backgrounds, allowing for concise, object-focused prompts. In contrast, COCO and Flickr30k contain multi-object images with cluttered backgrounds, necessitating more detailed and context-rich captions that describe relationships between objects.

This figure shows example prompts generated by LLMs for ImageNet, and hand-constructed captions for COCO and Flickr30k datasets. It highlights the difference in image characteristics and caption styles. ImageNet images are mostly object-centric with clean backgrounds, and LLMs generate prompts focusing on single object characteristics. In contrast, COCO and Flickr30k images are more complex, containing multiple objects and cluttered backgrounds, with captions describing object relationships.

This figure illustrates the Aggregate-and-Adapt method for prompt learning. Panel (a) shows the prompt learning stage, where a prompt aggregator summarizes natural language prompts (either from GPT-3 or human-generated) into an image-aligned summary (prompt embedding). A prompt generator then creates an Aggregate-and-Adapted Prompt Embedding (AAPE) that balances closeness to the summary with minimization of task loss. Panel (b) details the inference stage, where only the prompt generator is used, making it efficient at test time. The AAPE is applied across various vision-language tasks.
More on tables
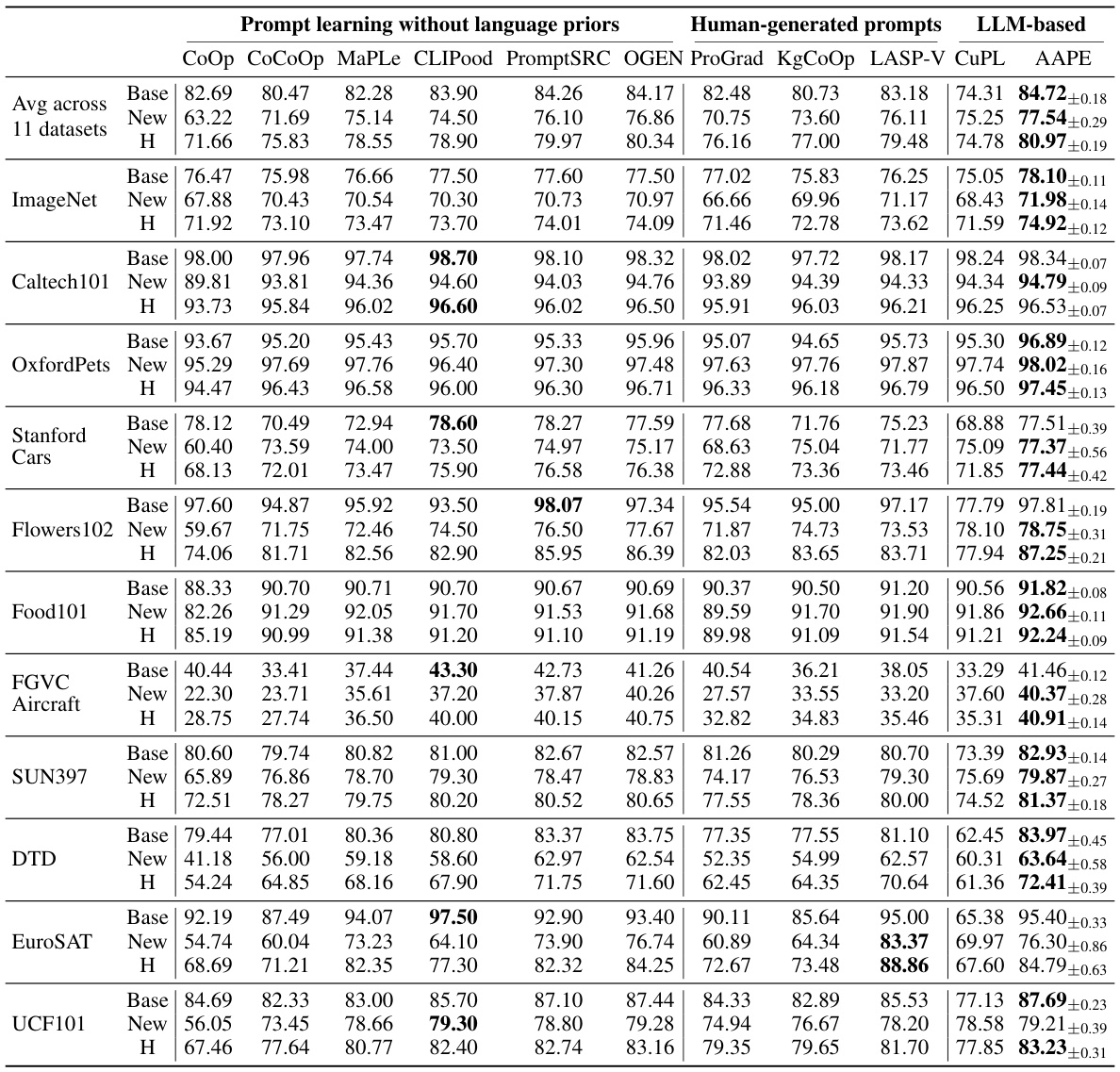
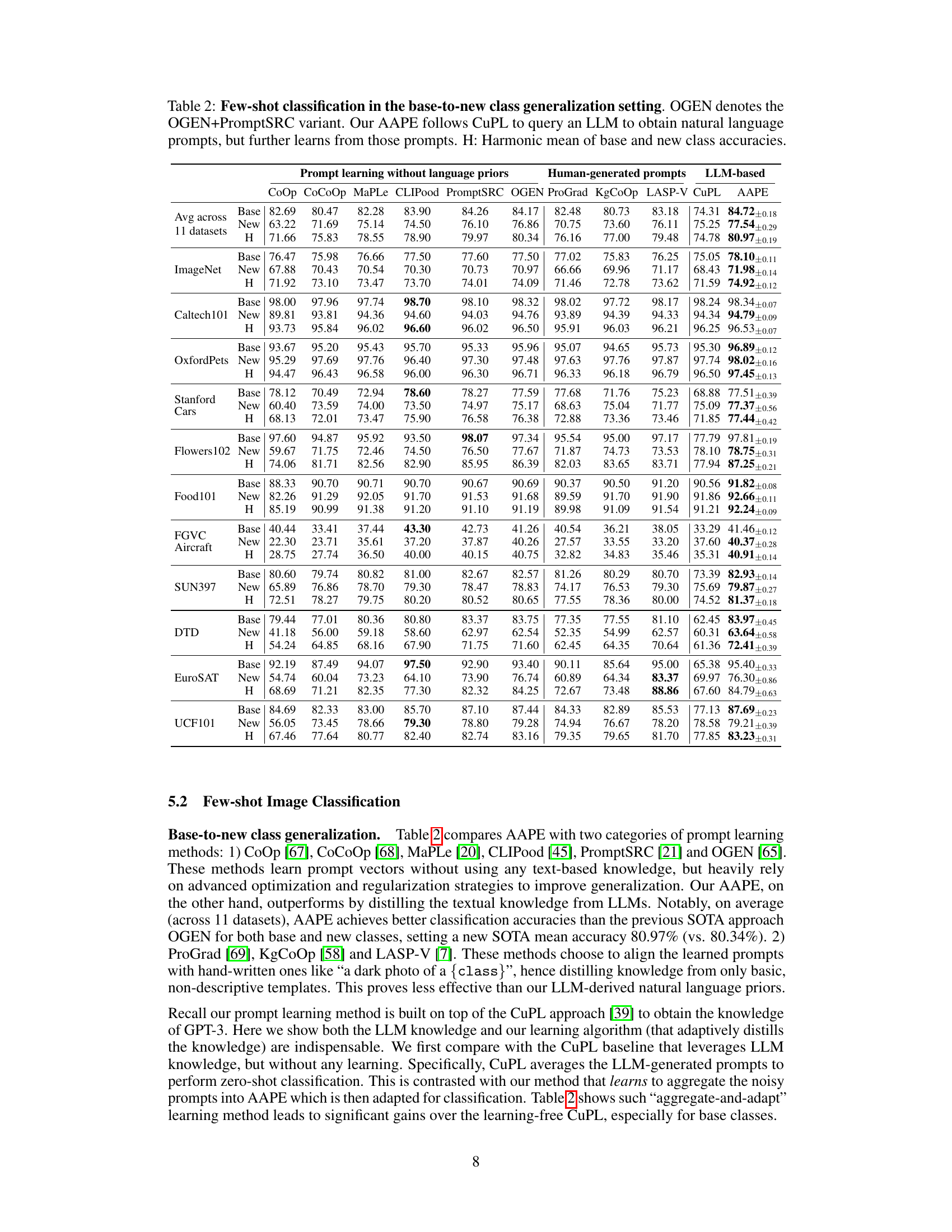
This table compares the performance of AAPE with other prompt learning methods in few-shot image classification. It specifically focuses on the base-to-new class generalization setting, where the model is trained on a subset of classes and tested on both seen (base) and unseen (new) classes. The table shows the average accuracy across 11 datasets, highlighting the harmonic mean of base and new class accuracies (H) as a performance metric. The comparison includes methods that utilize LLMs and those that don’t, showcasing AAPE’s ability to leverage LLM-generated prompts effectively.

This table presents the results of image captioning and visual question answering (VQA) tasks. The AAPE model, trained on the COCO dataset, is evaluated on both tasks using zero-shot and fine-tuned approaches. It shows performance metrics such as CIDEr-D, CLIP Score, and Ref-CLIP Score for image captioning and accuracy for VQA with varying numbers of training shots. The results highlight AAPE’s ability to generalize across different vision-language tasks and data distributions.
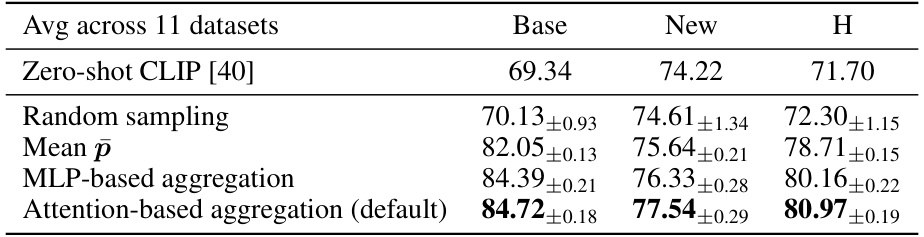
This table presents an ablation study on the prompt aggregator used in the Aggregate-and-Adapt Prompt Embedding (AAPE) method. It compares the performance of four different prompt aggregation methods: random sampling, simple averaging, MLP-based aggregation, and attention-based aggregation (the default method). The results are reported as the harmonic mean (H) of base and new class accuracies across 11 datasets, with zero-shot CLIP results serving as a baseline for comparison. The table shows that the attention-based aggregation method significantly outperforms other methods.
This table compares the performance of AAPE with other prompt learning methods on 11 datasets in a few-shot image classification setting. It contrasts methods that learn prompt vectors without using textual knowledge (CoOp, CoCoOp, MaPLe, CLIPood, PromptSRC, OGEN) against those that align learned prompts with hand-written ones (ProGrad, KgCoOp, LASP-V, CuPL) and AAPE, which distills textual knowledge from LLMs. The harmonic mean (H) of base and new class accuracies is reported as a key performance metric, showing AAPE’s superior generalization performance. The table highlights that AAPE effectively learns from natural language prompts obtained from LLMs, outperforming other methods, especially in generalizing to new classes.

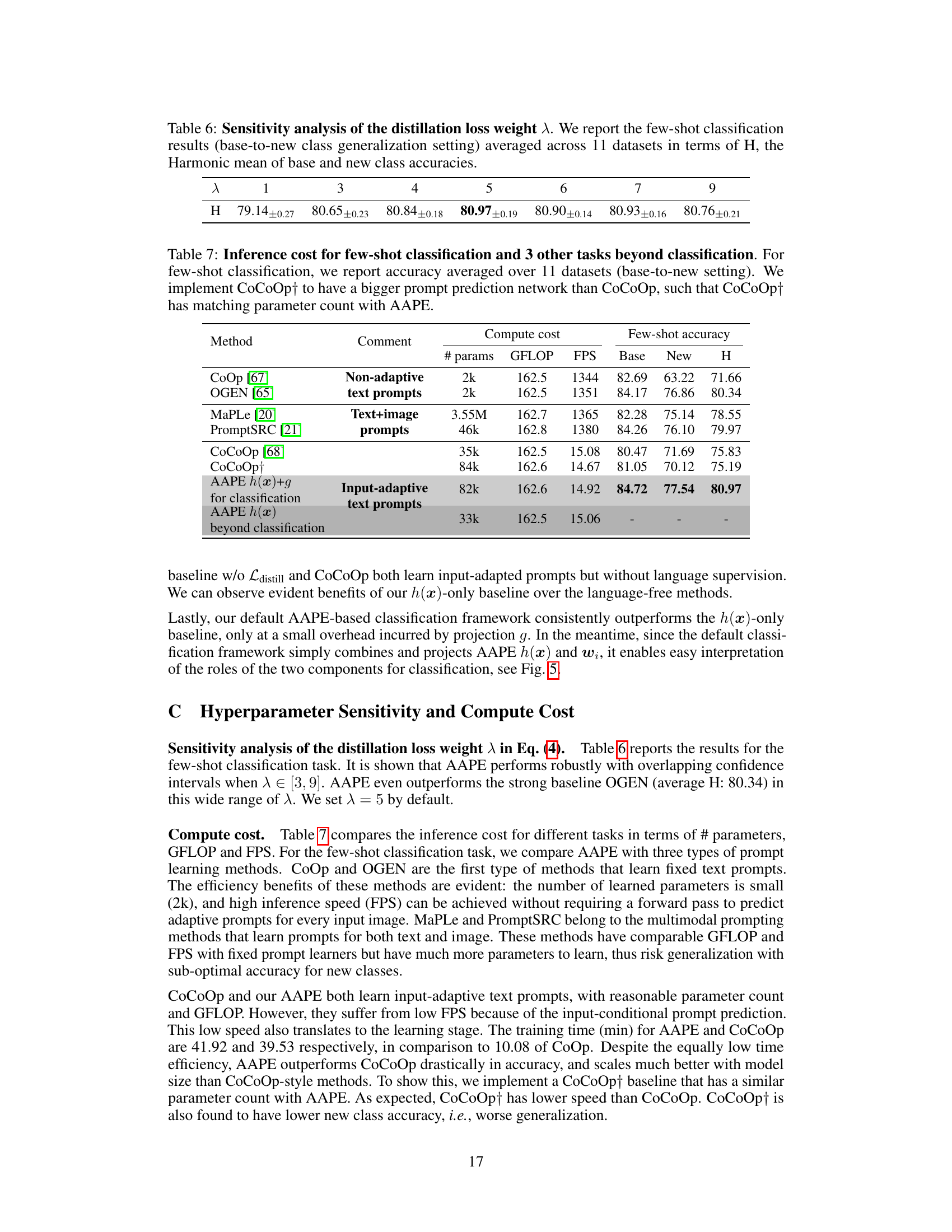
This table shows the results of a sensitivity analysis performed to determine the optimal value for the hyperparameter λ (lambda), which controls the weight of the distillation loss in the model’s training process. The analysis was conducted across 11 different datasets using a base-to-new class generalization setting for few-shot classification. The table presents the harmonic mean (H) of base and new class accuracies for different values of λ. The results show the robustness of the model’s performance across a range of λ values.
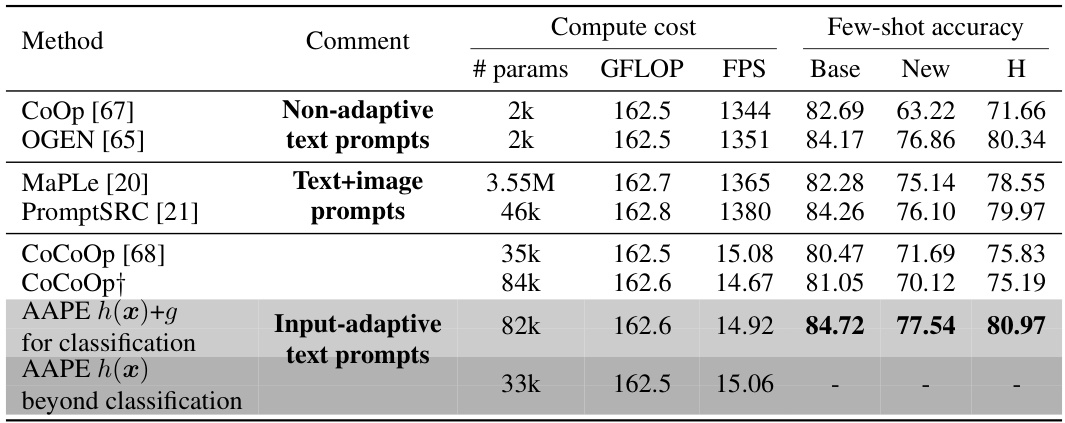
This table compares the inference cost and few-shot accuracy of different prompt learning methods for image classification and other vision-language tasks. It shows the number of parameters, GFLOPS, frames per second (FPS), and accuracy (base, new, and harmonic mean) for each method. The table highlights the efficiency of AAPE compared to other methods, especially those that use large language models.
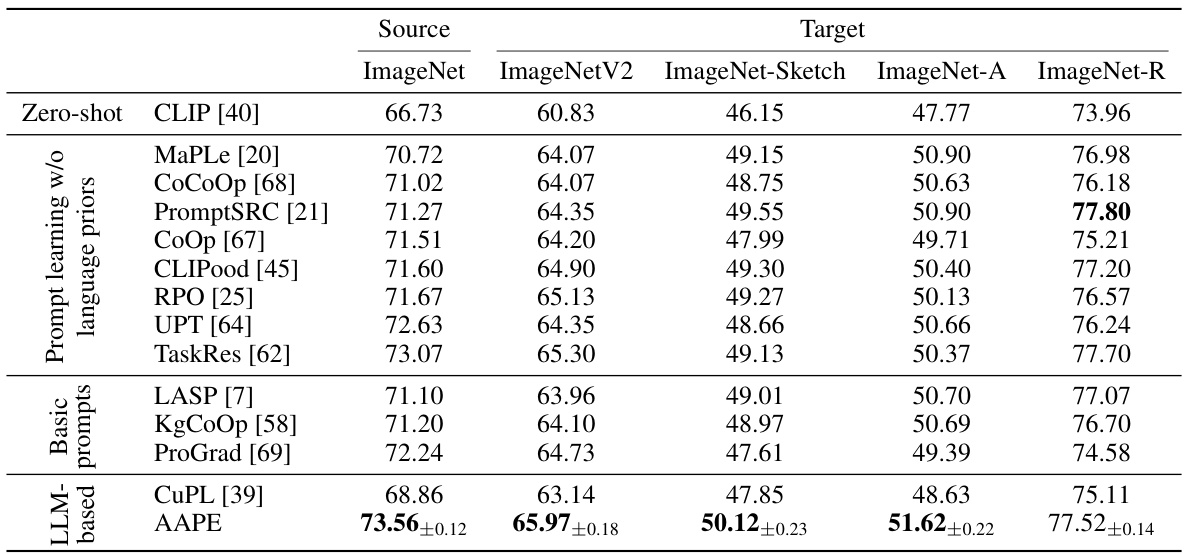
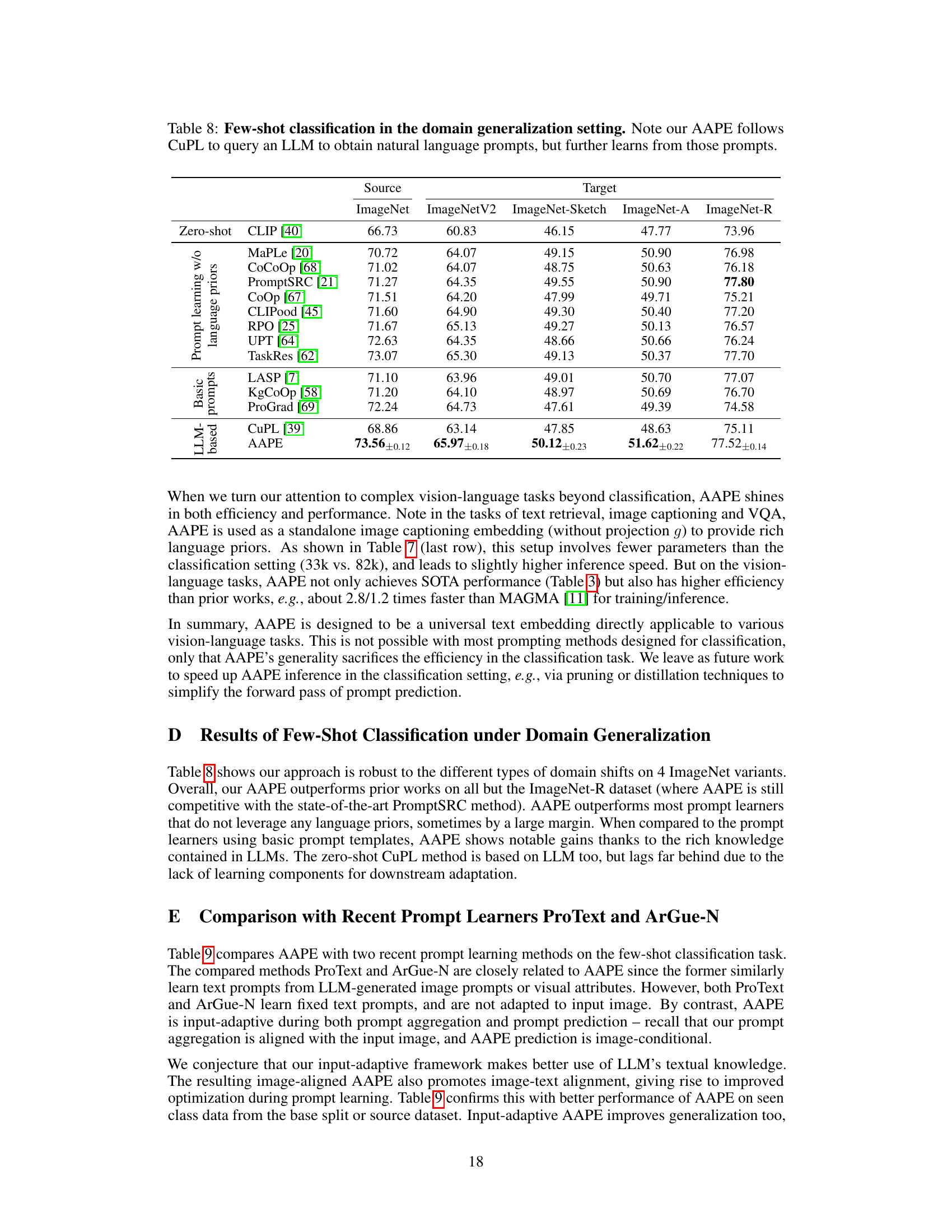
This table presents the results of few-shot image classification experiments conducted in a domain generalization setting. The ‘source’ dataset is ImageNet, and the target datasets are ImageNetV2, ImageNet-Sketch, ImageNet-A, and ImageNet-R, which represent different types of domain shifts from the source. The table compares the performance of AAPE against various baseline methods including CLIP, MaPLe, CoCoOp, PromptSRC, CoOp, CLIPood, RPO, UPT, TaskRes, LASP, KgCoOp, ProGrad, and CuPL. The results are reported as accuracy percentages for each target dataset. AAPE utilizes natural language prompts obtained using an LLM, which are aggregated and adapted during prompt learning.
Full paper#