↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Open vocabulary 3D semantic segmentation struggles with accurately identifying fine-grained boundaries, especially for novel object categories unseen during training. Existing methods, relying on global feature alignment or model distillation, often produce coarse results. This is due to the difficulty in establishing precise correspondence between 3D and 2D-text embedding spaces.
XMask3D tackles this problem by introducing a cross-modal mask reasoning framework that meticulously aligns 3D features with 2D-text embeddings at the mask level. It utilizes a denoising UNet from a pre-trained diffusion model as a 2D mask generator, enabling precise textual control and enhancing open-world adaptability. The model incorporates 3D global features as implicit conditions in the UNet to generate geometry-aware masks, further enhancing 3D-2D-text alignment. Finally, it fuses complementary 2D and 3D mask features for improved accuracy. The results on multiple benchmarks demonstrate XMask3D’s superior performance in open vocabulary 3D semantic segmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D semantic segmentation because it presents a novel approach to address the challenges of open vocabulary scenarios. By introducing cross-modal mask reasoning, it improves accuracy and detail in segmenting objects, especially novel ones. This innovative method opens avenues for improving virtual and augmented reality interactions, autonomous driving, and robotics applications.
Visual Insights#
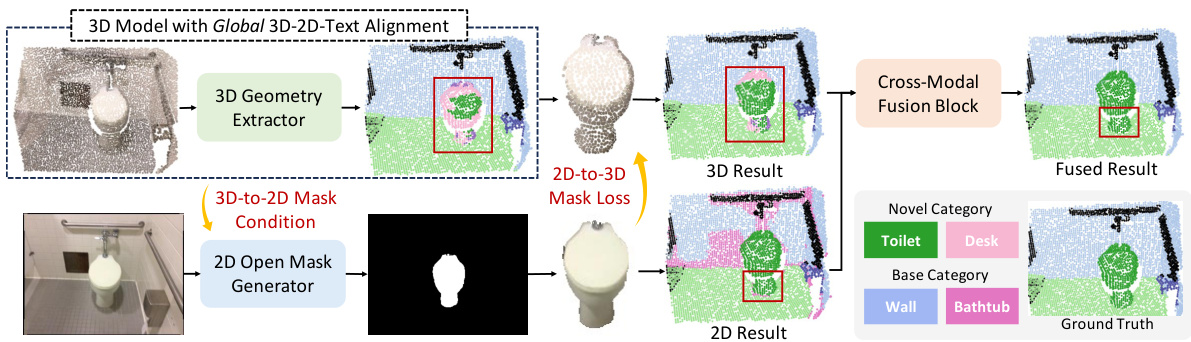
This figure illustrates the overall framework of the XMask3D model, which uses a cross-modal mask reasoning approach for open vocabulary 3D semantic segmentation. It highlights the limitations of traditional methods that rely on global feature alignment, and showcases the XMask3D’s approach of incorporating a 2D open mask generator conditioned on 3D geometry features to generate geometry-aware segmentation masks of novel categories. This is followed by mask-level regularization on 3D features and a cross-modal fusion block that combines the strengths of the 2D and 3D branches.
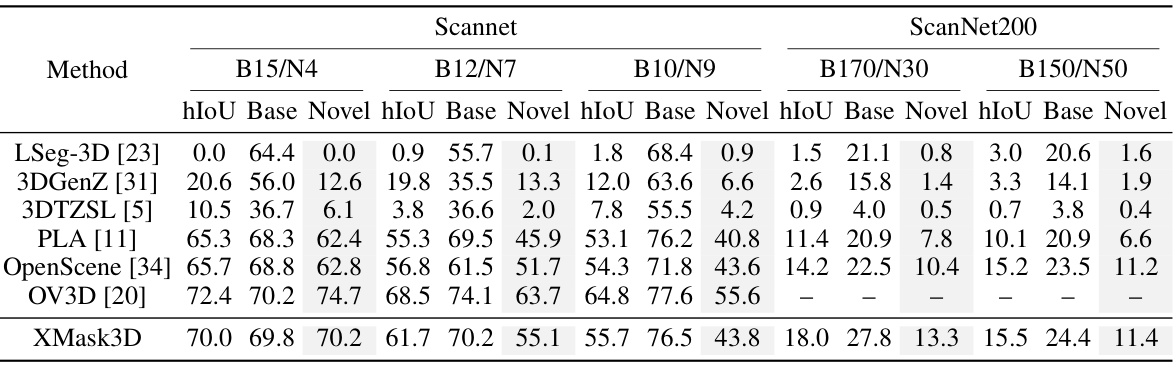
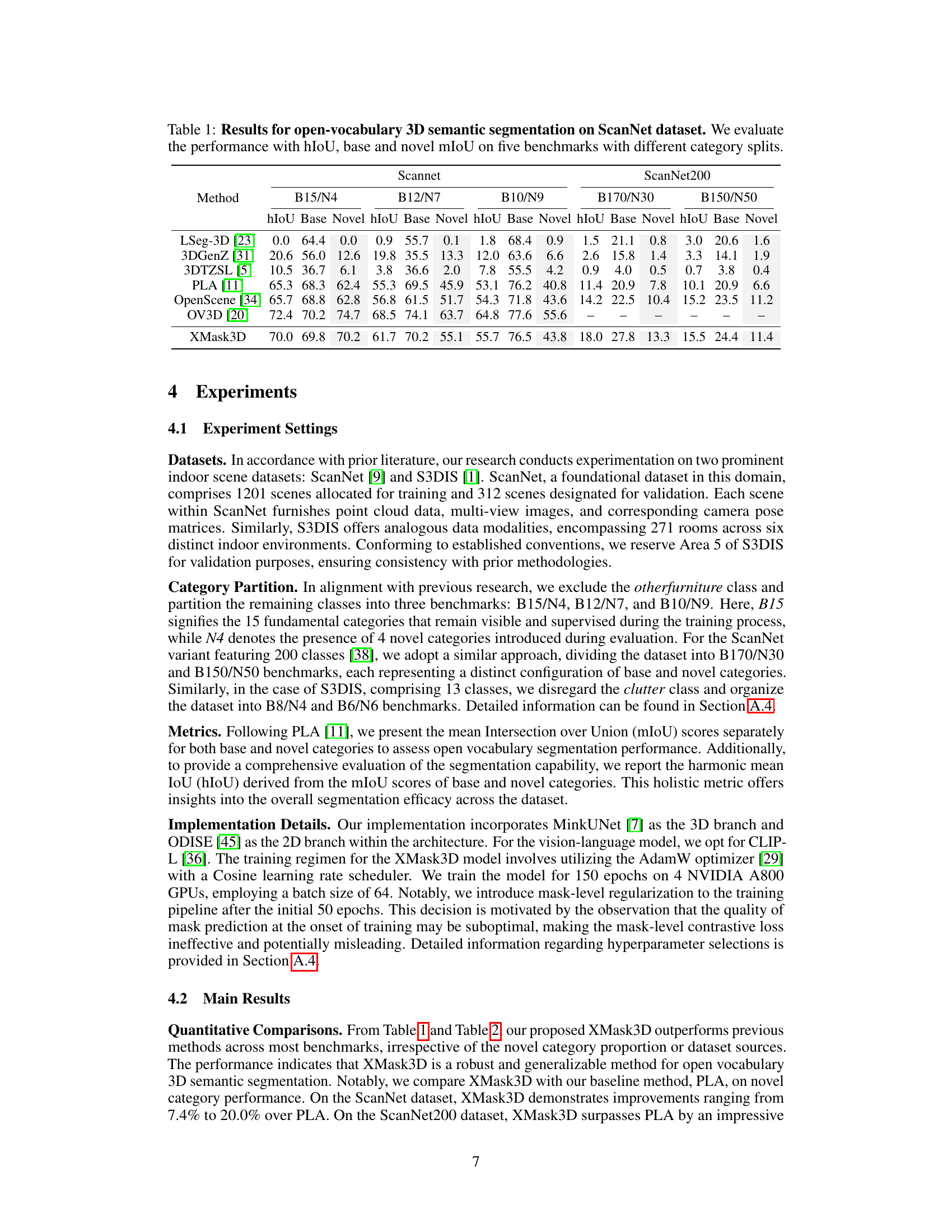
This table presents the quantitative results of the proposed XMask3D model and several other state-of-the-art methods on the ScanNet dataset for open vocabulary 3D semantic segmentation. The performance is measured using three metrics: harmonic mean Intersection over Union (hIoU), mean IoU (mIoU) for base categories, and mean IoU for novel categories. Five different benchmark settings are used, each with varying numbers of base and novel categories, offering a comprehensive evaluation across different levels of difficulty.
In-depth insights#
Cross-modal Masking#
Cross-modal masking, in the context of this research paper, likely refers to a technique that integrates information from multiple modalities (e.g., images, text, 3D point clouds) using masks to align and reason about corresponding features. Masks act as bridges, highlighting relevant regions across modalities, which aids in tasks such as semantic segmentation. The approach likely involves generating masks from one modality (like text descriptions) and applying them to guide feature extraction or prediction in another modality (like 3D point clouds). This enables a more precise alignment than global feature matching, allowing for finer-grained segmentation boundaries. It leverages the strengths of each modality: text’s semantic understanding and 3D data’s geometric detail. The effectiveness of cross-modal masking likely depends on the quality of mask generation and the ability to establish meaningful correspondences across modalities. Key challenges might include handling inconsistencies or ambiguities across modalities, and ensuring computational efficiency given the potential complexity of the approach.
3D-aware UNet#
A hypothetical ‘3D-aware UNet’ would represent a significant advancement in 3D semantic segmentation. It would likely build upon the standard U-Net architecture, renowned for its effectiveness in 2D image segmentation, but adapt it to handle the complexities of three-dimensional data. Key modifications would include using 3D convolutional layers instead of 2D ones to capture spatial relationships across all three axes. Efficient 3D convolution methods would be critical to manage computational cost, possibly employing techniques like sparse convolutions or octrees to process point clouds or volumetric data efficiently. The architecture’s encoding and decoding paths would learn increasingly abstract and then increasingly detailed 3D features. Incorporating skip connections would maintain fine-grained details, crucial for accurate segmentation boundaries. The network would likely be trained on 3D datasets such as ScanNet or S3DIS, potentially pre-trained on large 2D image datasets to leverage transferable knowledge. Careful consideration of loss functions tailored to 3D segmentation (e.g., incorporating geometric constraints) would be necessary to guide the learning process, and techniques to address class imbalance would be particularly important given the diversity of object types in 3D scenes. The success of a ‘3D-aware UNet’ hinges on the careful balance between architectural design, computational efficiency, and training methodologies to achieve precise and robust 3D semantic segmentation.
Open-Vocab 3D Seg#
Open-vocabulary 3D semantic segmentation (Open-Vocab 3D Seg) presents a significant challenge in computer vision, demanding robust models capable of recognizing and segmenting objects from unseen categories during training. Existing approaches often struggle with precise boundary delineation, relying on techniques like global feature alignment or vision-language model distillation which provide only approximate correspondences. The core difficulty lies in bridging the gap between the 3D geometry, 2D image representations, and textual descriptions of objects in a unified feature space. A key focus is on enhancing the model’s capacity to extrapolate from known to unknown object classes, a crucial aspect for real-world applications. Successful methods require careful consideration of how to effectively leverage the strengths of different modalities, accurately capturing fine-grained details in 3D point clouds while ensuring alignment with vision-language embeddings. The integration of deep learning architectures with advanced techniques like diffusion models and cross-modal reasoning is critical for future advancements in this field. Addressing challenges like noise in point cloud data, inconsistent 2D-3D correspondences, and limited training data remain crucial research directions to fully realize the potential of Open-Vocab 3D Seg.
Ablation Studies#
Ablation studies systematically evaluate the contribution of individual components within a machine learning model. In the context of this research paper, ablation studies likely investigated the impact of different modules, such as the 3D-to-2D mask generation, 2D-to-3D mask regularization, and 3D-2D mask feature fusion on overall performance. By removing or modifying these components one at a time, the researchers could isolate their individual effects and understand their relative importance. The results of these experiments would be crucial in validating the design choices made and justifying the overall architecture. A successful ablation study provides strong evidence for the design decisions, demonstrating that each module contributes meaningfully to the improved performance. The ablation study likely examined the impact on metrics such as mIoU (mean Intersection over Union) for both base and novel categories to demonstrate the effectiveness of each component, thereby supporting the claim of improved accuracy and robustness of the proposed model.
Future Work#
The paper’s conclusion mentions several promising avenues for future work. Extending XMask3D to instance and panoptic segmentation is a key direction, leveraging the current framework’s strengths for finer-grained scene understanding. This would involve integrating a suitable 3D instance or panoptic segmentation model into the existing pipeline. Another important direction involves improving computational efficiency, which might include replacing the computationally expensive 2D branch with a faster open-vocabulary mask generation method. Exploring different 3D backbones and comparing their performance with XMask3D also presents a valuable research opportunity to uncover potential performance gains from architecture improvements. Finally, investigating the effects of XMask3D on a broader range of tasks in 3D perception is warranted, expanding beyond semantic segmentation to other related areas such as object detection, tracking, and more comprehensive scene understanding.
More visual insights#
More on figures

This figure shows the detailed architecture of the XMask3D model. It consists of three main components: a 3D geometry extraction branch, a 2D mask generation branch, and a 3D-2D feature fusion module. The 3D branch extracts geometric features from a point cloud. The 2D branch uses a diffusion model to generate open vocabulary masks, conditioned on global 3D features. These masks are then used for mask-level regularization on the 3D features to ensure fine-grained alignment between 3D and 2D feature spaces. Finally, a fusion block merges the features from both branches to leverage their respective strengths and produce a more accurate result. The CLIP text and image encoders are used in conjunction with the mask generator and the fusion block.

This figure compares the performance of XMask3D against two other state-of-the-art methods, PLA and OpenScene, on four novel object categories (table, bookshelf, chair, and bed). For each category, it shows the view image, the ground truth segmentation, and the segmentation results produced by each of the three methods. Red boxes highlight the regions of interest (i.e., the novel categories). The visual comparison aims to demonstrate that XMask3D achieves more accurate and precise segmentation boundaries compared to the other two methods.

This figure compares the performance of XMask3D against two other methods (PLA and OpenScene) on the task of segmenting novel object categories in 3D scenes. It shows several example scenes with ground truth segmentations and the corresponding segmentations generated by each of the three methods. The red boxes highlight the regions of the images containing the novel object categories. The figure demonstrates that XMask3D achieves better segmentation accuracy and more precise boundary delineation compared to the other methods, particularly for fine-grained objects.

This figure presents a visual comparison of the segmentation results obtained by XMask3D, PLA [11], and OpenScene [34] on four novel categories (table, bookshelf, chair, and bed). Each row shows a different scene, with the leftmost image displaying the original view image, followed by the ground truth segmentation, and then the results from PLA, OpenScene, and finally XMask3D (with its three individual branches and their fusion results). The red boxes highlight the regions corresponding to the four novel categories. The comparison aims to showcase XMask3D’s superior accuracy and more refined segmentation boundaries in comparison to the other methods.
This figure compares the segmentation results of XMask3D with two other methods (PLA and OpenScene) on four novel categories: table, bookshelf, chair, and bed. The comparison highlights the superior accuracy and finer segmentation boundaries achieved by XMask3D, particularly in correctly identifying the novel categories. The red boxes clearly show the areas where the novel categories are located, making it easy to compare the performance of the different methods.

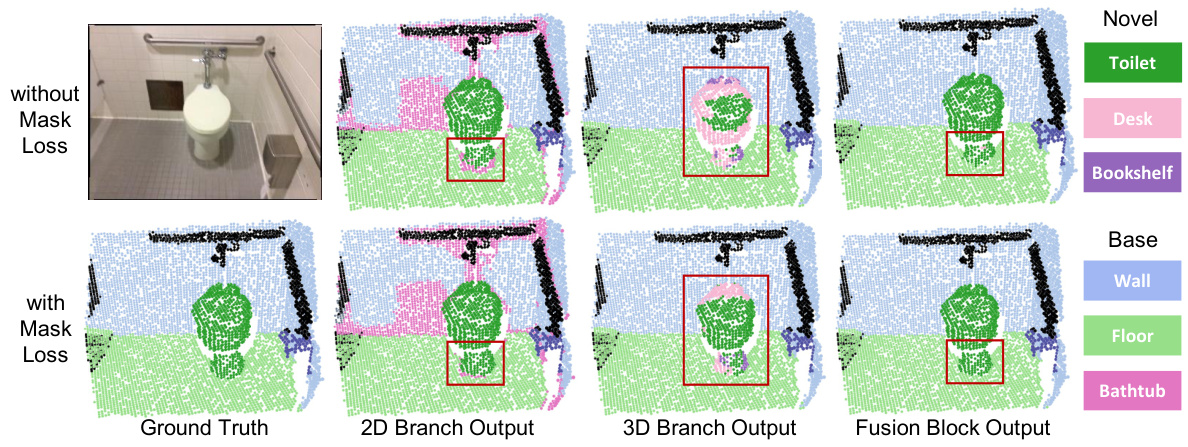
This figure showcases three failure cases of the XMask3D model in identifying novel categories (shower curtain, picture, sink). Each row displays the input image, the ground truth segmentation, the segmentation results from the 2D branch, the 3D branch, and the final fused output. The model struggles in these cases due to various factors, such as similar object shapes and textures, occlusions, and incomplete point clouds.
More on tables
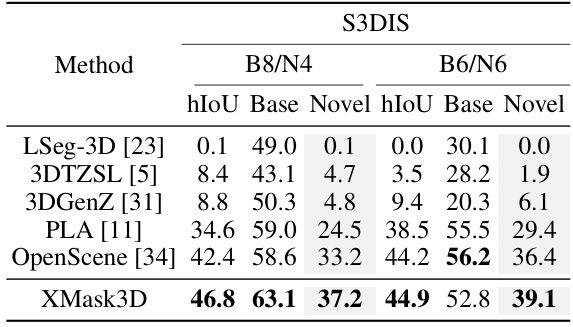
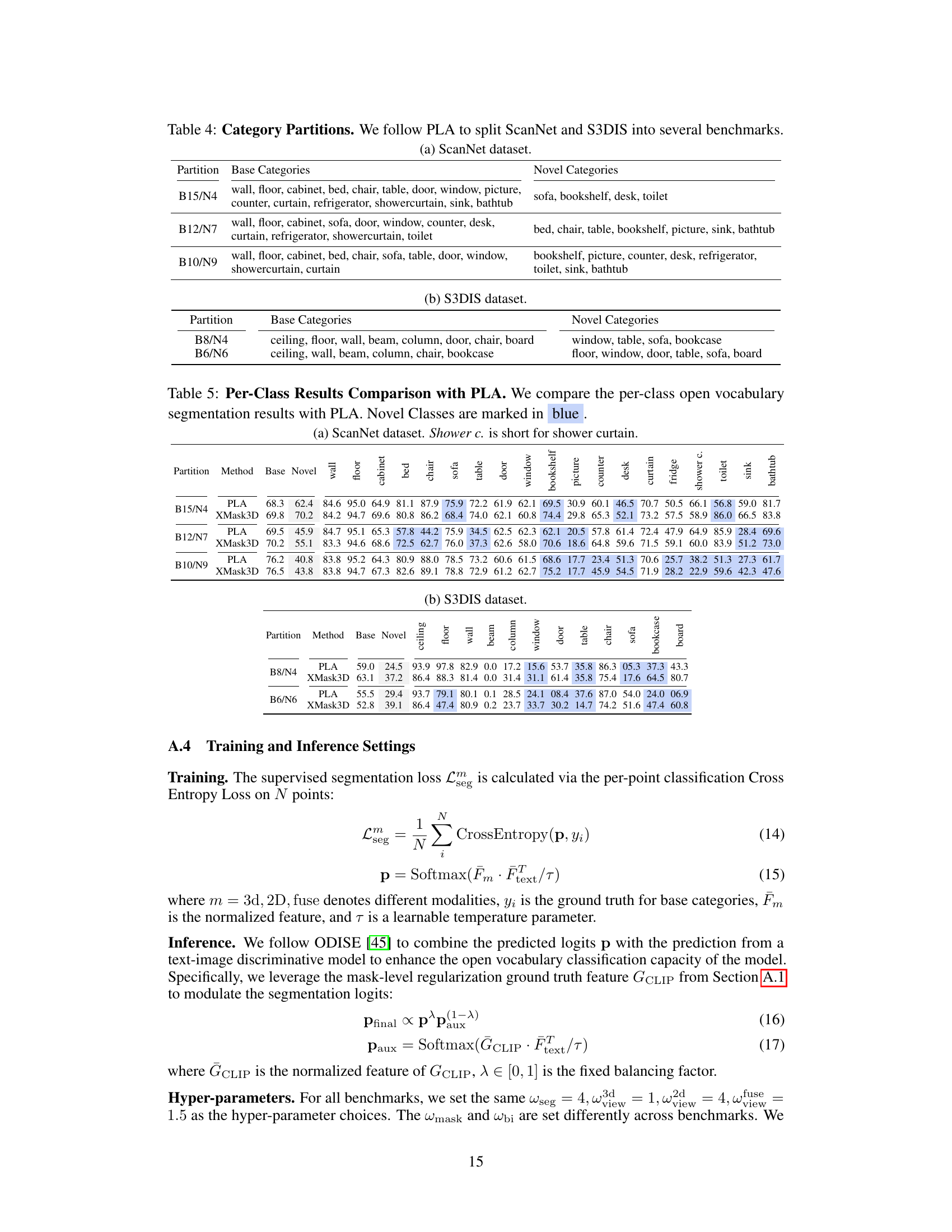
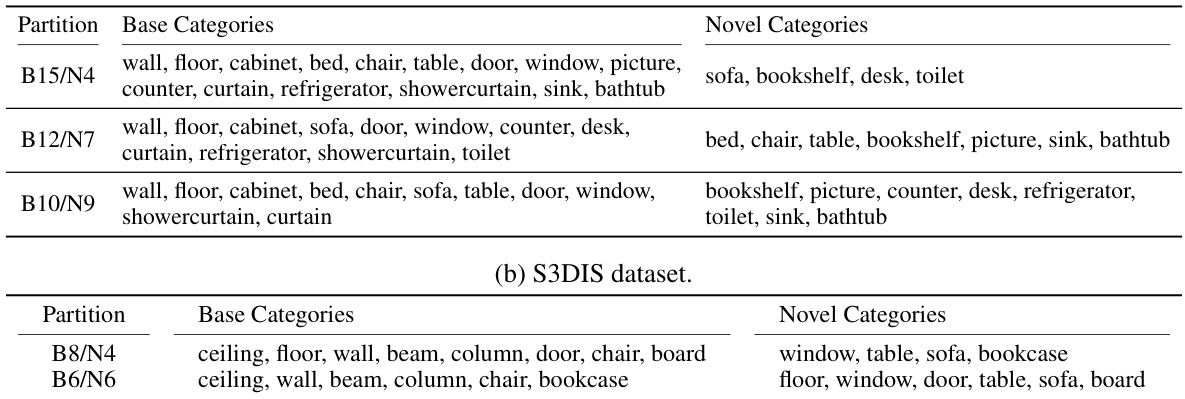
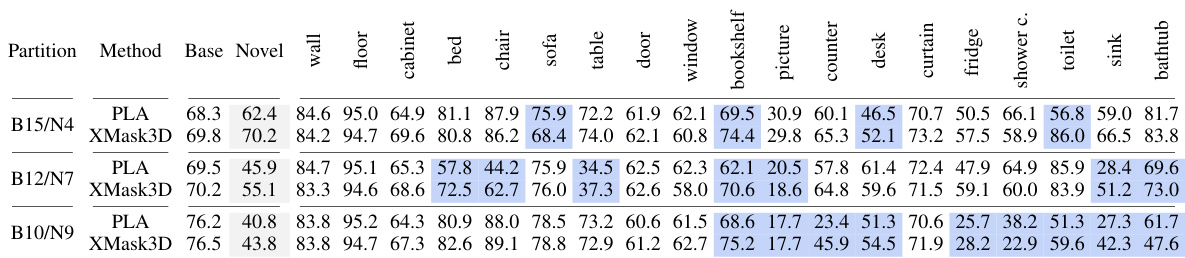
This table presents the results of the XMask3D model and other state-of-the-art methods on the S3DIS dataset. It evaluates the performance on two different category splits (B8/N4 and B6/N6). The metrics used are the harmonic mean Intersection over Union (hIoU), mean Intersection over Union (mIoU) for base categories, and mean IoU for novel categories. The best performing model for each metric in each category split is highlighted in bold, showing XMask3D’s competitive performance on this dataset.

This ablation study analyzes the impact of different components within the XMask3D framework on the B12/N7 benchmark of the ScanNet dataset. It investigates the effects of using different conditional inputs for the diffusion model (text, 2D, or 3D features), the impact of mask regularization, and the contribution of the fusion block by comparing performance metrics (Base and Novel mIoU) across various configurations.
This table presents the quantitative results of the proposed XMask3D model and several baseline models on the ScanNet dataset for open vocabulary 3D semantic segmentation. The performance is measured using three metrics: hIoU (harmonic mean Intersection over Union), base mIoU (mean IoU for base categories), and novel mIoU (mean IoU for novel categories). Five different benchmarks are used, each characterized by a specific split of categories into base and novel sets (B15/N4, B12/N7, B10/N9, B170/N30, and B150/N50). The results show a comparison of XMask3D’s performance against other state-of-the-art methods in this domain.
This table presents the quantitative results of open vocabulary 3D semantic segmentation on the ScanNet dataset. It shows the performance of XMask3D and several other methods across five different benchmark settings. Each setting varies the number of base and novel categories used for evaluation. The performance metrics used are harmonic mean IoU (hIoU), mean IoU for base categories, and mean IoU for novel categories.

This table presents the performance comparison of different methods on the S3DIS dataset for open vocabulary 3D semantic segmentation. It shows the harmonic mean Intersection over Union (hIoU), mean IoU (mIoU) for base categories, and mIoU for novel categories. The best performing method for each metric is highlighted in bold. This allows for a direct comparison of the proposed XMask3D method against existing state-of-the-art techniques for this task.
Full paper#