↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
High-definition (HD) map construction is vital for autonomous driving, but existing methods struggle with occlusions and inconsistent predictions across frames. Current approaches often rely on single-frame inference or simple streaming methods that fail to fully exploit the temporal relationship between adjacent frames, leading to suboptimal results. This often results in inconsistent and suboptimal prediction results, particularly in scenarios with frequent occlusions.
To address these limitations, this paper proposes MapUnveiler, a novel clip-level approach that incorporates efficient clip tokens to represent dense image information and long-term temporal relationships. MapUnveiler explicitly addresses occlusions by relating dense image representations within clips and associating inter-clip information through clip token propagation. This method significantly improves accuracy and outperforms existing state-of-the-art techniques on standard benchmarks, especially in challenging, heavily occluded scenes.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving and computer vision due to its significant advancement in online vectorized HD map construction. MapUnveiler’s clip-level approach offers a novel solution to the long-standing challenge of handling occlusions and improving temporal consistency in HD map creation. Its state-of-the-art performance and efficient design make it highly relevant to current research and open up new avenues for exploration in both fields. The efficient design and state-of-the-art performance make it highly relevant to current research and open up new avenues for exploration in both fields.
Visual Insights#

This figure compares three different approaches for vectorized HD map construction: (a) single-frame inference, (b) streaming inference, and (c) clip-level inference (the proposed method). It highlights the limitations of single-frame and streaming approaches in handling occlusions and temporal inconsistencies, showcasing how the proposed clip-level method utilizes clip tokens to effectively unveil hidden map information and propagate temporal context for more accurate and robust map construction. The visualization of BEV features via 1D PCA projection further illustrates the improvements achieved by the proposed approach.
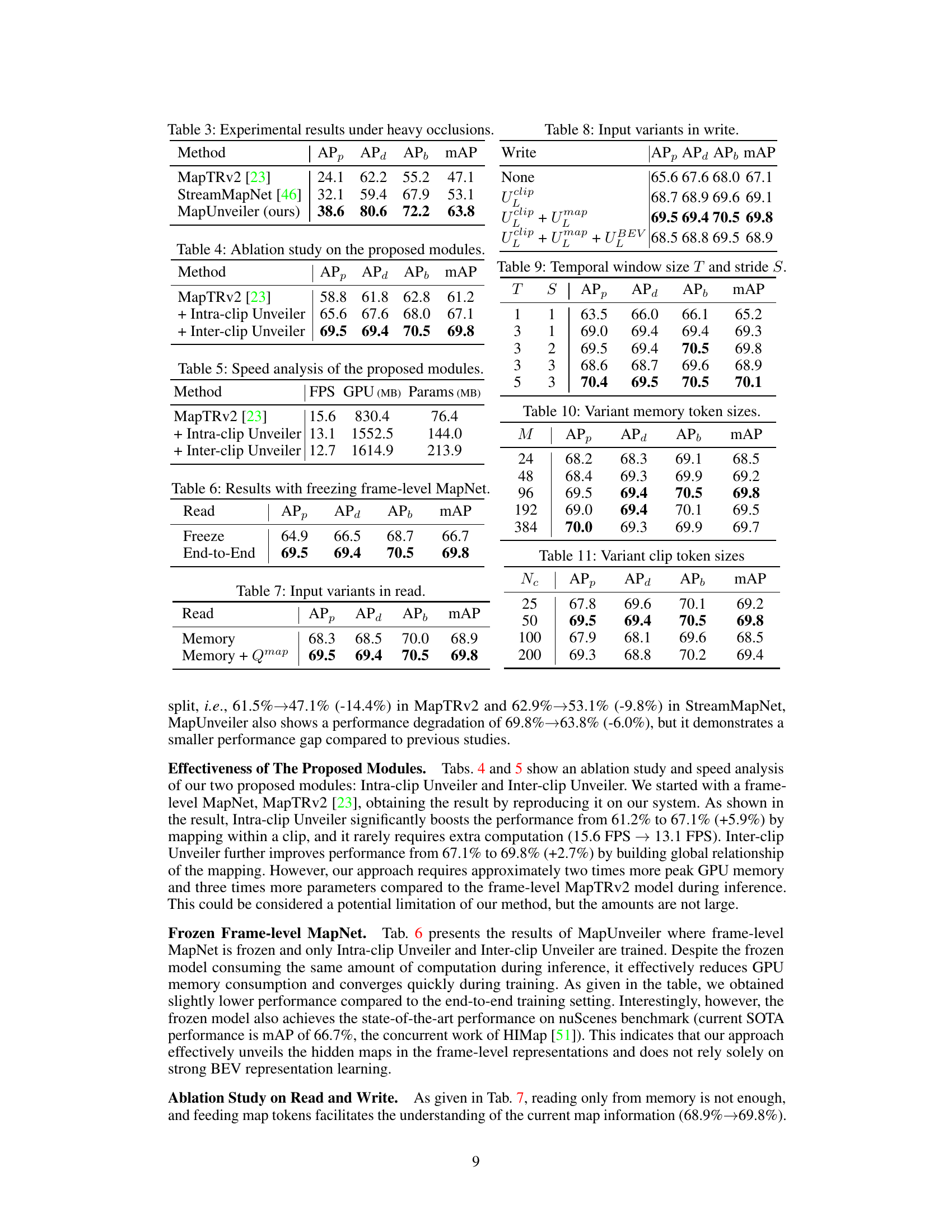
This table presents a comparison of the proposed MapUnveiler model with other state-of-the-art methods on two standard benchmarks: nuScenes and Argoverse2. The comparison includes average precision (AP) for pedestrian crossings, dividers, and boundaries at different Chamfer distances, as well as Frames Per Second (FPS) for performance comparison. The FPS values marked with asterisks (*) are taken from the original papers and adjusted for fair comparison based on MapTRv2’s FPS.
In-depth insights#
Hidden Map Unveiling#
The concept of “Hidden Map Unveiling” in the context of autonomous driving signifies the challenge of reconstructing a complete and accurate high-definition (HD) map from sensor data that is often partially or completely occluded. Traditional methods struggle with dynamic objects obstructing the view of static map elements like lane markings and road boundaries. The core idea behind “Hidden Map Unveiling” is to leverage advanced techniques to infer these hidden map features by cleverly integrating multiple data points and employing sophisticated algorithms. This involves a shift from relying solely on immediately visible information to a more holistic approach that incorporates temporal context and predictions. By intelligently stitching together data from various sources and perspectives and leveraging powerful deep learning models, the system aims to unveil a comprehensive HD map representation that goes beyond the limitations of direct observation. This represents a significant step towards building more reliable and robust autonomous navigation systems, capable of functioning effectively even in complex and challenging environments with frequent occlusions.
Clip-Level Fusion#
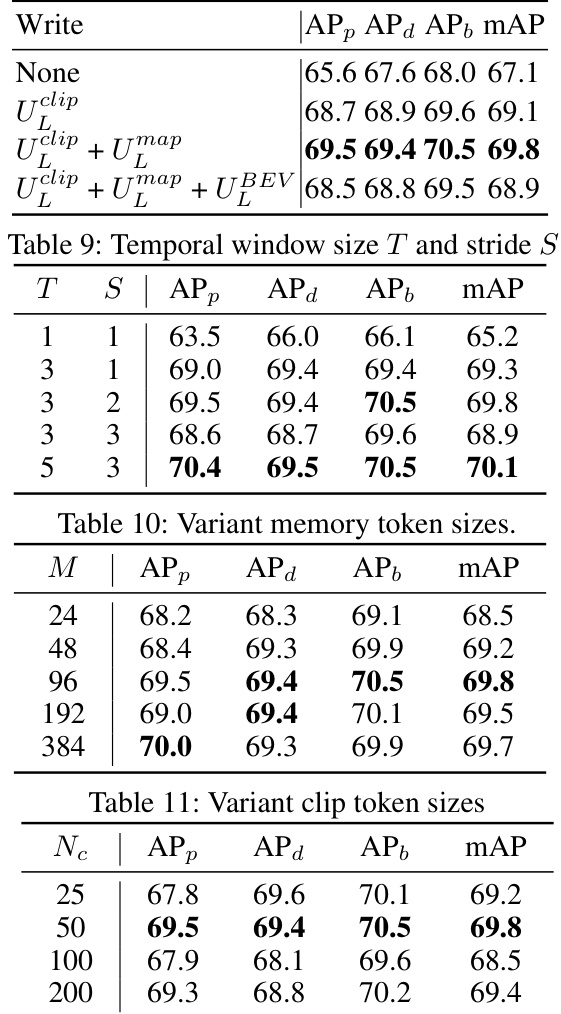
Clip-level fusion, in the context of high-definition (HD) map construction from visual data, represents a significant advancement over frame-by-frame processing. Instead of treating each image frame independently, clip-level fusion aggregates information across a short sequence of frames (a ‘clip’) to improve the robustness and accuracy of HD map predictions. This approach directly addresses the inherent challenges of visual occlusion and noisy data, common in real-world driving scenarios. By incorporating temporal context, clip-level fusion can effectively unveil hidden map elements that may be temporarily obscured in individual frames. This leads to more complete and consistent HD maps, especially in complex, dynamic environments. The key is to design effective mechanisms for combining information from multiple frames within a clip, and to propagate map information between consecutive clips to build a globally coherent representation. The success of clip-level fusion hinges on carefully balancing the temporal window size and the computational cost, ensuring that the benefits of temporal context outweigh the increased processing demands.
Temporal Propagation#
Temporal propagation, in the context of online vectorized HD map construction, refers to the methods used to effectively integrate information from past frames into the current map prediction. This is crucial because road scenes are dynamic; objects frequently occlude map elements, leading to incomplete or inconsistent observations in individual frames. Effective temporal propagation is key to unveiling hidden map elements and ensuring temporal consistency in the constructed map. Naive approaches simply concatenate or average features from past frames, which may propagate noise and errors. More sophisticated techniques employ recurrent neural networks (RNNs) or transformers to model the temporal dependencies. However, challenges remain in balancing the computational cost of processing long temporal sequences with the need for real-time performance. Clip-level token interaction, as described in many papers, offers a promising approach: instead of processing dense feature representations from all past frames, it leverages compact clip-level tokens to capture the relevant temporal context, leading to improved efficiency. This method is particularly important in scenarios with heavy occlusions where simply relying on single-frame information is insufficient. The design and implementation of the temporal propagation mechanism directly impact the accuracy, robustness, and efficiency of the overall HD map construction system. A well-designed approach would not only accurately predict map elements but also maintain smooth and consistent representations over time, even when dealing with significant occlusions or changes in the environment.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper provides crucial evidence of the proposed method’s effectiveness. It should present a rigorous comparison against existing state-of-the-art techniques, ideally using established benchmarks with publicly available datasets. The metrics employed must be clearly defined and appropriate for the task, providing a nuanced evaluation beyond simple accuracy rates. The results should be presented clearly, likely using tables and figures, enabling easy comparison of performance across different methods and datasets. A thorough error analysis helps assess reliability, especially if statistical measures of significance are included. Crucially, limitations of the benchmarks themselves (e.g., dataset biases, task restrictions) should be acknowledged to avoid overstating the results’ generalizability. Transparency is key; the methodology should be well documented, allowing reproducibility and validation by other researchers. Strong benchmark results are fundamental for establishing the significance and impact of a research contribution.
Occlusion Robustness#
Occlusion robustness in HD map construction is crucial for reliable autonomous driving. The challenge lies in accurately predicting and constructing road geometric information (lane lines, road markers, etc.) that are frequently obscured by dynamic objects. Existing methods often struggle in these scenarios, leading to incomplete or inaccurate maps. A key aspect of improving occlusion robustness involves leveraging temporal information across multiple frames. By considering the context of adjacent frames, it becomes possible to infer the location and properties of occluded elements using temporal consistency. Efficient token-based approaches can play a vital role in managing temporal data, enabling compact representations and efficient processing. Additionally, multi-view fusion strategies can further enhance robustness by combining information from multiple cameras to reduce the impact of individual occlusions. Advanced techniques may incorporate data association and prediction uncertainty estimations to improve the reliability of the constructed HD maps in the presence of occlusions.
More visual insights#
More on figures
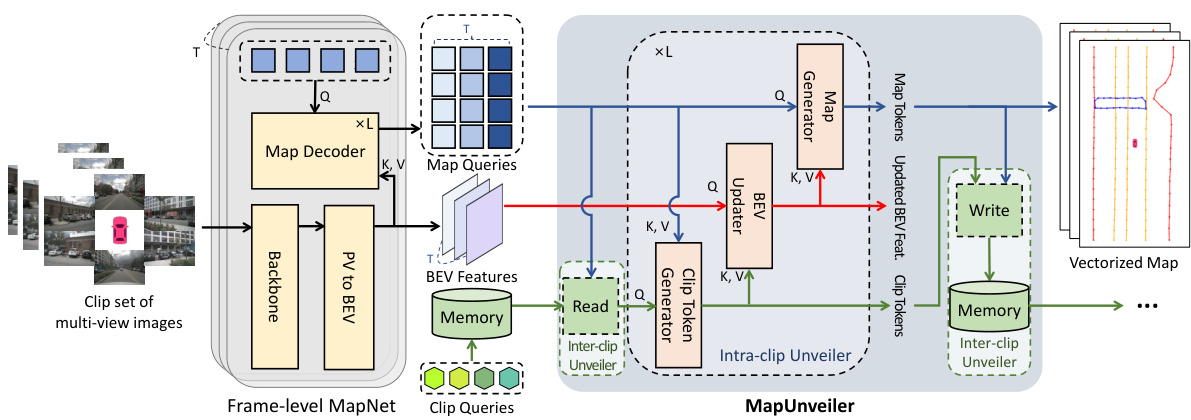
This figure illustrates the overall architecture of the proposed MapUnveiler framework for online vectorized HD map construction. It shows how the framework takes clip-level multi-view images as input and processes them through several key modules: a frame-level MapNet (based on MapTRv2), an Intra-clip Unveiler, and an Inter-clip Unveiler. The frame-level MapNet extracts BEV features and map queries. The Intra-clip Unveiler generates clip tokens, updates BEV features, and generates map tokens. The Inter-clip Unveiler manages long-term temporal information via memory, updating BEV features across clips. Finally, the system outputs high-quality vectorized HD maps. The figure highlights the interaction between BEV features, clip tokens, and map tokens within the MapUnveiler module, showcasing the key elements that enable the system to unveil hidden map information.
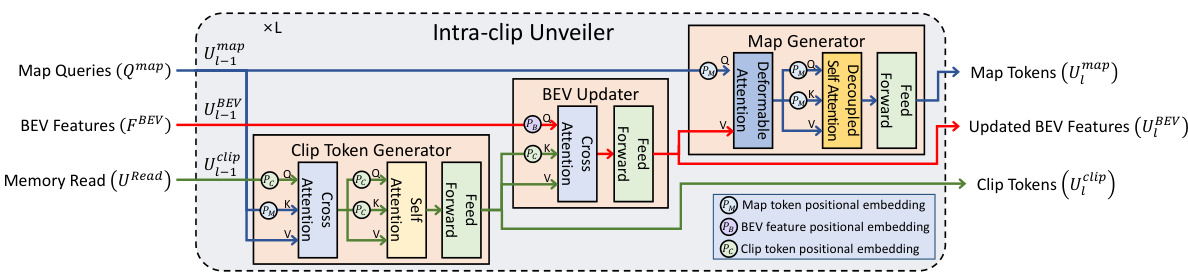
This figure shows a detailed architecture of the Intra-clip Unveiler module. The Intra-clip Unveiler module is a core component of the MapUnveiler framework proposed in the paper. It takes frame-level map queries, BEV features, and memory reads as input and generates clip-level map tokens. It consists of three main steps: Clip Token Generator, BEV Updater, and Map Generator. The Clip Token Generator generates compact clip tokens, which are then used by the BEV Updater to update BEV features to unveil hidden map elements. Finally, the Map Generator generates clip-level map tokens from the updated BEV features. The figure also shows positional embeddings used for the map tokens, BEV features, and clip tokens.

This figure shows a qualitative comparison of the map construction results between MapUnveiler, MapTRv2, and StreamMapNet on the nuScenes validation set. Two different perception ranges are considered: 60x30m and 100x50m. Green boxes highlight the areas where MapUnveiler shows significant improvement over the other two methods.

This figure displays a qualitative comparison of the proposed MapUnveiler model with two other models, MapTRv2 and StreamMapNet, on the nuScenes validation set. The perception range is set to 60x30 meters. Each row represents a sequence of frames from a driving scene. The leftmost column shows the input images from multiple cameras. The subsequent columns visualize the ground truth map (GT) and the predictions from each model. The color coding of the map elements likely represents different map element types (e.g., lane lines, road boundaries). The figure aims to showcase the visual differences in map construction accuracy between the models.

This figure displays a qualitative comparison of the proposed MapUnveiler model with two other models, MapTRv2 and StreamMapNet, on the nuScenes validation set using a 60x30m perception range. Each row shows a sequence of input images from a driving scene and corresponding vectorized HD map predictions from each method. Ground truth (GT) maps are also provided for reference. The visualization highlights the strengths and weaknesses of each model in accurately reconstructing various map elements such as lane lines, road boundaries, and crosswalks in different scenarios. By comparing the predictions against the ground truth, one can visually assess the performance of each model in terms of accuracy, completeness, and robustness to occlusions and challenging driving conditions.

This figure shows a qualitative comparison of the proposed MapUnveiler model with two other state-of-the-art methods (MapTRv2 and StreamMapNet) on the nuScenes validation set using a 60x30m perception range. It displays several time steps, showing the input images from multiple cameras, the ground truth map, and the predictions from each of the three methods. The results highlight the improved accuracy and completeness of the MapUnveiler model in reconstructing the vectorized HD map, especially for complex road layouts and in scenarios with partial occlusions.

This figure presents a qualitative comparison of the proposed MapUnveiler model against two other state-of-the-art models, MapTRv2 and StreamMapNet, on the nuScenes validation set using a 60x30m perception range. The figure shows several sequences of images from the dataset along with the ground truth map and the results produced by each model. Each row represents a different time step (or a short sequence of steps), and the columns show the input images, the ground truth map (GT), the MapTRv2 predictions, the StreamMapNet predictions, and finally the MapUnveiler predictions. This visual comparison allows one to assess the relative accuracy and robustness of each method in handling different scenarios and levels of occlusion.

This figure compares the ground truth map with the maps generated by MapTRv2, StreamMapNet, and the proposed MapUnveiler method on the nuScenes validation set using a 60x30m perception range. Each row shows a sequence of input images and the corresponding map predictions for each method. The results visually demonstrate MapUnveiler’s improved accuracy in map construction compared to the other methods, especially in terms of correctly identifying and representing lane lines and other road elements.
More on tables
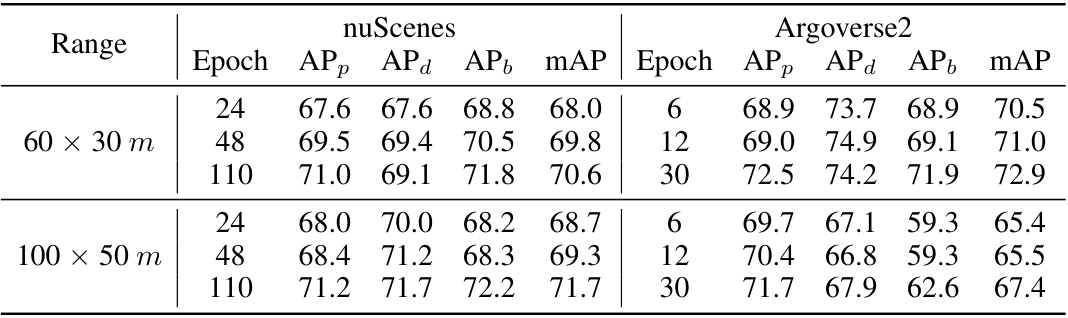
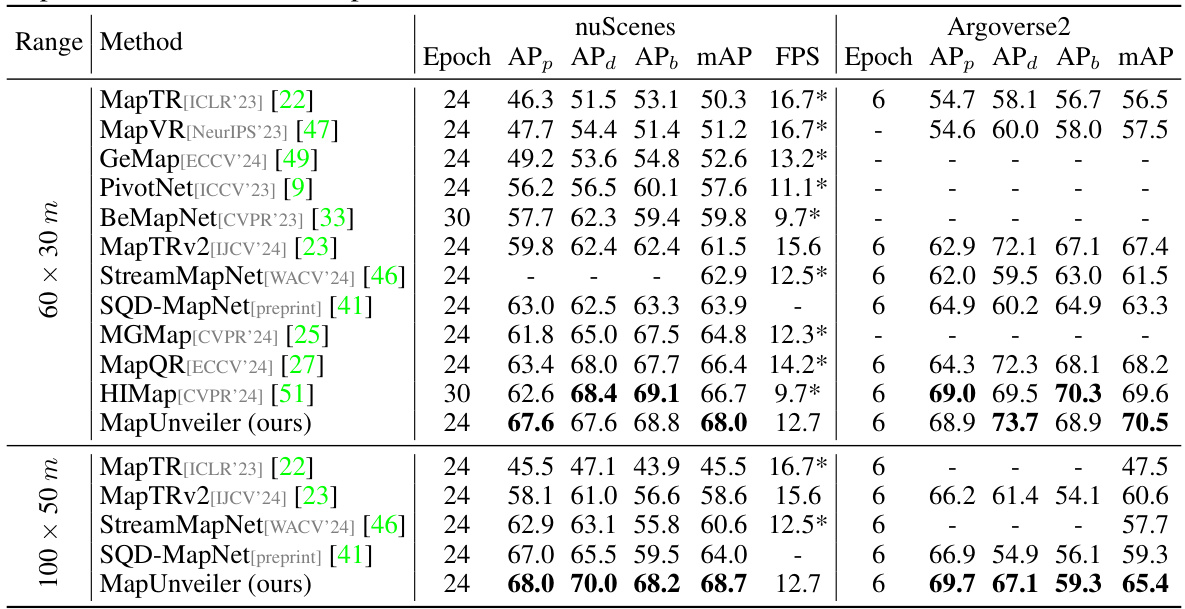
This table presents a comparison of MapUnveiler’s performance against other state-of-the-art methods on the nuScenes and Argoverse2 validation sets. The results are shown for two perception ranges (30m and 100x50m) and include average precision (AP) for pedestrian crossings, dividers, and boundaries, as well as frames per second (FPS). The FPS values from other papers have been scaled based on MapTRv2’s FPS for fair comparison.
This table compares the performance of MapUnveiler with other state-of-the-art methods on the nuScenes and Argoverse2 datasets. The comparison is done using average precision (AP) for pedestrian crossing, lane dividers, and road boundaries, calculated at different Chamfer distances (thresholds). It also shows the frames per second (FPS) achieved by each method using a single NVIDIA A100 GPU. FPS values marked with an asterisk (*) are taken from the original papers and scaled relative to MapTRv2’s FPS for a more fair comparison.
This table presents a comparison of the proposed MapUnveiler model with other state-of-the-art methods on the nuScenes and Argoverse2 datasets. The performance is evaluated using Average Precision (AP) for pedestrian crossings, dividers, and boundaries, considering different perception ranges (30m and 100x50m). The table also includes the Frames Per Second (FPS) for each method, helping to assess computational efficiency. Note that some FPS values are estimates based on scaling against MapTRv2.

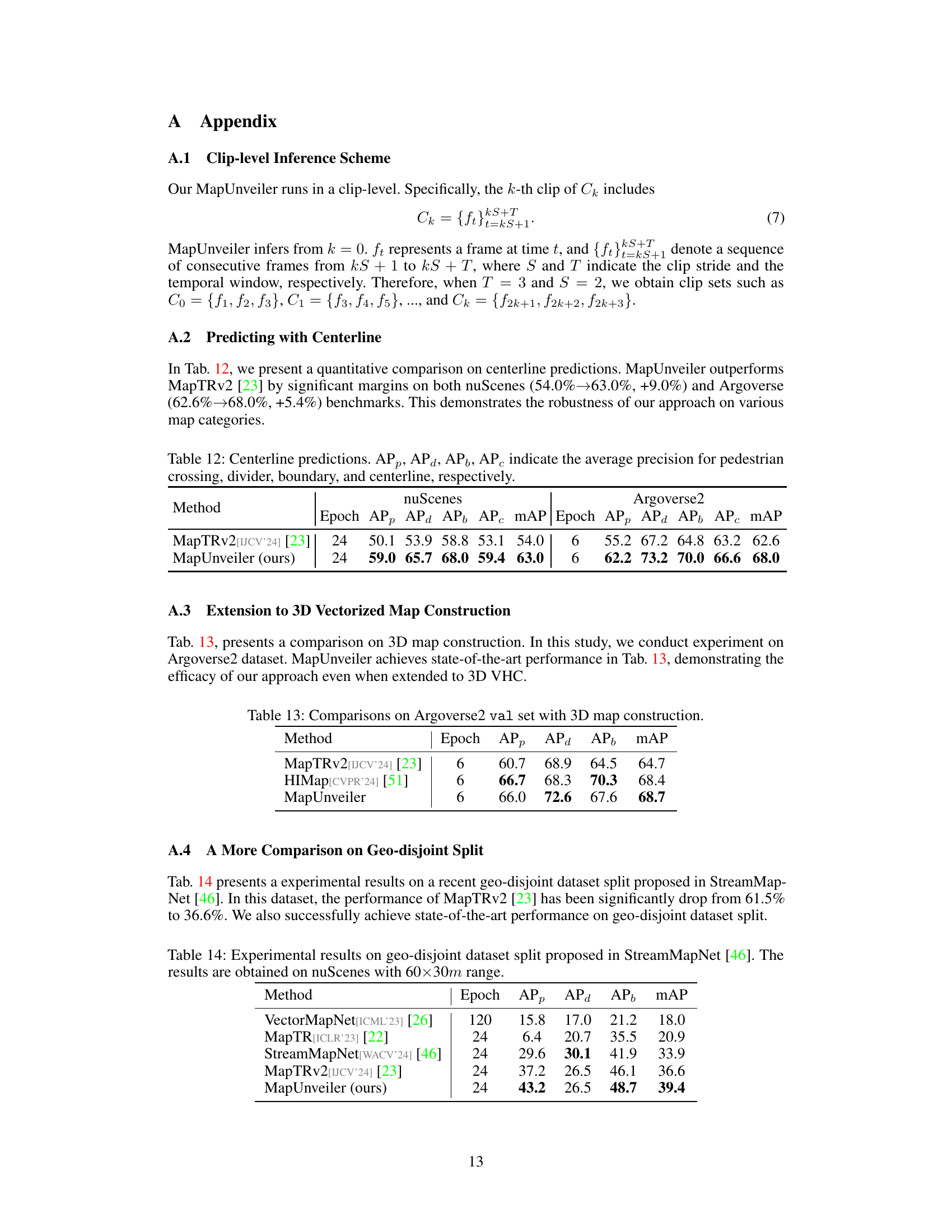
This table presents a quantitative comparison of centerline prediction performance using MapTRv2 and the proposed MapUnveiler method. The results are shown for both the nuScenes and Argoverse2 datasets. The average precision (AP) is reported for each semantic category (pedestrian crossing, divider, boundary, centerline). The table highlights the improvement in performance achieved by MapUnveiler compared to MapTRv2.

This table compares the performance of MapUnveiler with other state-of-the-art methods on the nuScenes and Argoverse2 validation sets. The metrics used are average precision (AP) for pedestrian crossings (APp), dividers (APd), and boundaries (APb), calculated across three Chamfer distance thresholds (0.5m, 1.0m, 1.5m). The mean average precision (mAP) is also reported, along with the frames per second (FPS) achieved using a single NVIDIA A100 GPU. Results from other papers are included for comparison, with FPS values scaled relative to MapTRv2 to account for differences in hardware.

This table presents a comparison of different methods on a geo-disjoint dataset split. The results show the average precision (AP) for pedestrian crossings (APp), dividers (APd), boundaries (APb), and the mean average precision (mAP). The methods compared are VectorMapNet, MapTR, StreamMapNet, MapTRv2, and the proposed MapUnveiler. The table highlights the improved performance of MapUnveiler on this challenging dataset split.

This table presents a comparison of the proposed MapUnveiler model with other state-of-the-art methods on the nuScenes and Argoverse2 validation datasets. The metrics used are average precision (AP) for pedestrian crossings, lane dividers, and road boundaries, calculated at different Chamfer distances. The table also includes Frames Per Second (FPS) to compare the efficiency of the models. Note that some FPS values are marked with an asterisk (*) indicating that they were taken from the original papers and scaled relative to MapTRv2 for a consistent comparison.

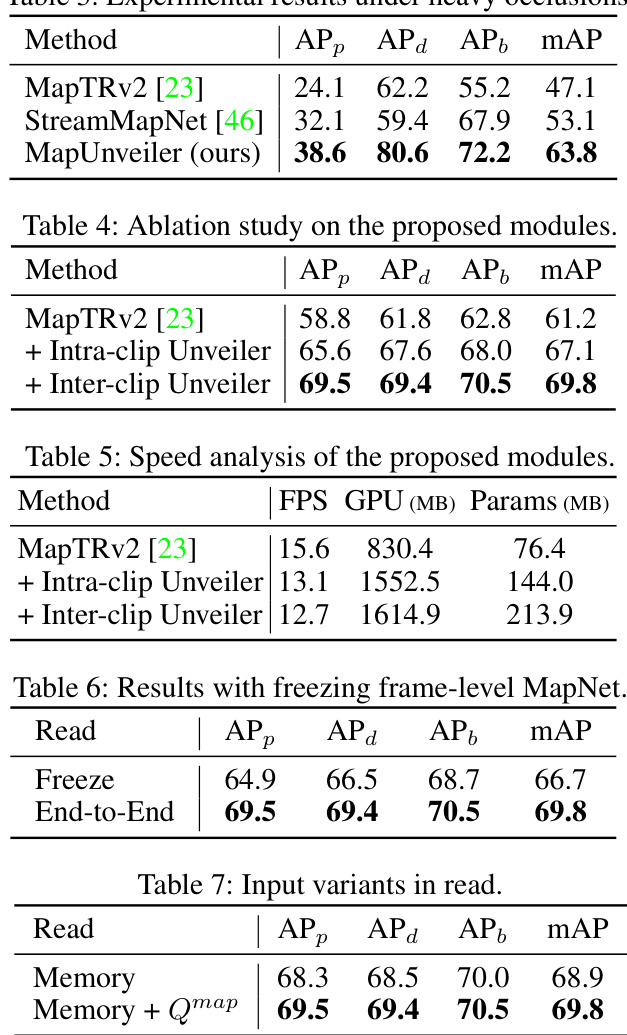
This table presents the results of experiments conducted on the nuScenes dataset with a 60x30m perception range. The experiments involved randomly dropping intermediate frames at various rates (5%, 10%, and 20%) to simulate real-world scenarios where data might be lost or corrupted. The table compares the performance of the MapTRv2 and MapUnveiler methods under these conditions, showing the impact of missing frames on the accuracy of each model in terms of average precision (AP) for pedestrian crossings (APp), dividers (APd), boundaries (APb), and the mean average precision (mAP).
Full paper#