↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multimodal Variational Autoencoders (VAEs) are used to analyze data from multiple sources, but current methods struggle with balancing shared and modality-specific information. Existing architectures either force a shared representation among all modalities or treat them entirely separately, leading to suboptimal results. This limitation is particularly pronounced in scenarios where the modalities have varying levels of quality or when some are missing.
The researchers propose a novel method called the Multimodal Variational Mixture-of-Experts (MMVM) VAE. This model uses a “soft constraint” to guide the latent representations from different modalities toward a shared representation without forcing them into a single joint representation. Experiments on multiple datasets demonstrated that MMVM VAE significantly outperforms previous methods in both representation learning and the imputation of missing data, showcasing the effectiveness of the proposed method in handling multimodal data with varying qualities and missing values.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with multimodal data, as it offers a novel approach to improve representation learning in VAEs. The soft constraint method and the MMVM VAE architecture are significant contributions that can be applied broadly. The improved results on various benchmark datasets and real-world applications demonstrate the approach’s effectiveness and opens avenues for further research in generative models and multimodal learning.
Visual Insights#

This figure compares three different approaches for handling multiple modalities in a variational autoencoder (VAE). (a) shows independent VAEs, where each modality is processed separately. (b) illustrates an aggregated VAE that attempts to combine information from all modalities into a single joint representation, but this can negatively impact reconstruction quality. (c) presents the proposed MMVM VAE, which uses a data-dependent prior to softly guide the individual modality representations towards a shared aggregate posterior, aiming to balance individual information preservation and shared representation learning.
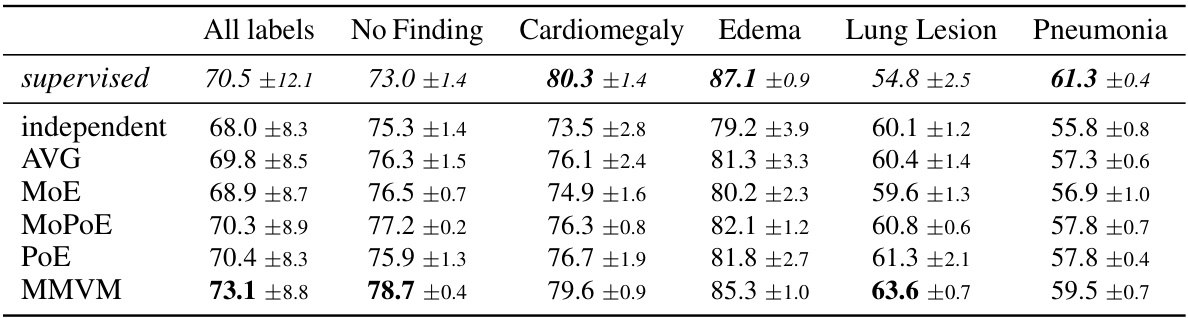
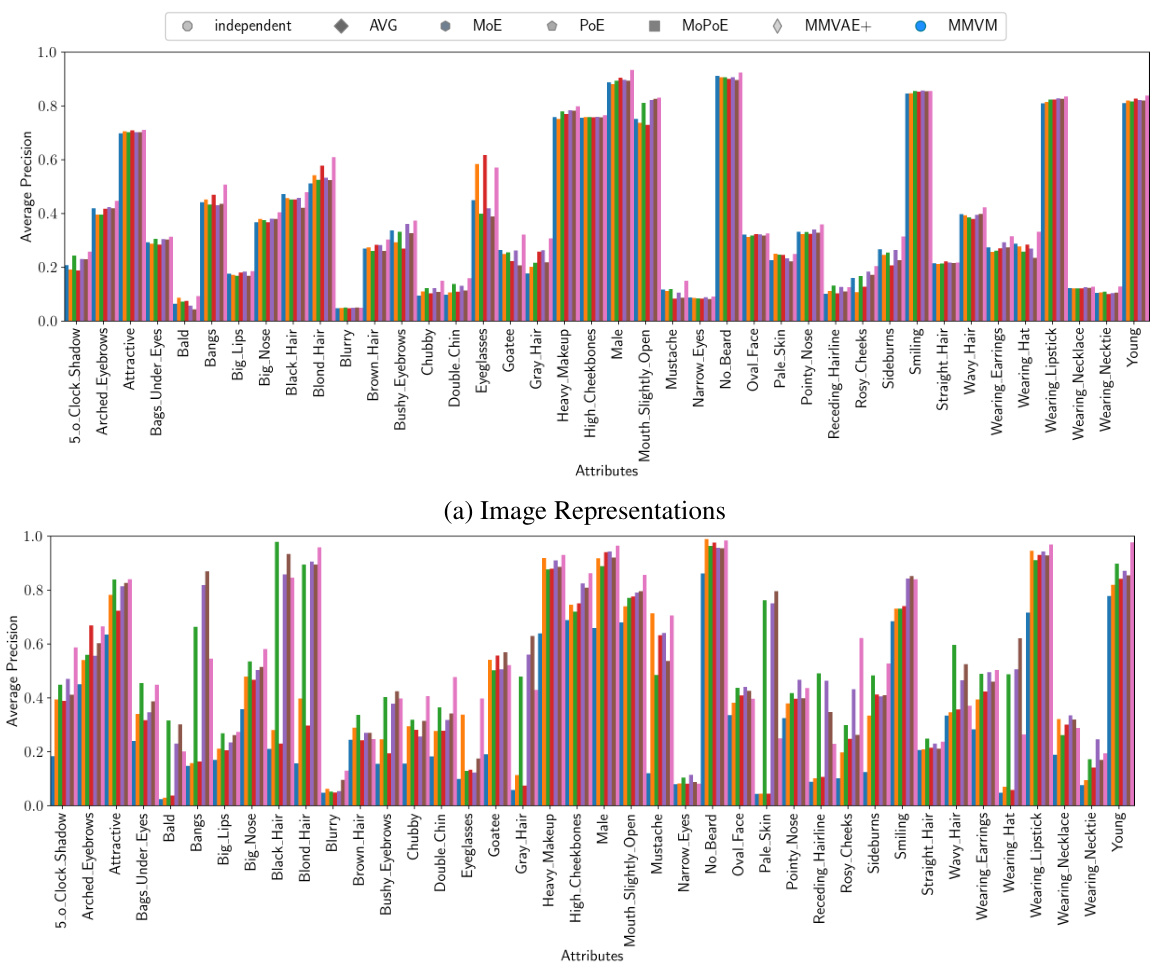
This table presents the results of a classification experiment using latent representations learned by different Variational Autoencoders (VAEs) on the MIMIC-CXR dataset. The Area Under the Receiver Operating Characteristic curve (AUROC) is reported for several different chest X-ray findings, showing the classification accuracy of the VAEs’ latent space representations. The MMVM VAE demonstrates better performance than other VAEs and approaches the performance of a fully supervised model.
In-depth insights#
Multimodal VAE#
Multimodal Variational Autoencoders (VAEs) aim to learn a joint representation from multiple data modalities, enabling tasks like imputation and generation. Early approaches often used hard constraints, sharing encoder outputs or decoder inputs across modalities, which can limit the model’s ability to capture modality-specific information. A key challenge is finding an effective balance between shared and modality-specific information in the latent space. Improved methods leverage soft constraints, such as the mixture-of-experts prior, to guide each modality towards a shared representation but still allow for individual characteristics to be preserved. This offers better reconstruction quality and more nuanced latent representations. These advancements are particularly important for real-world scenarios where data is often incomplete or from heterogeneous sources. The soft constraint approach enables more effective fusion of multimodal data, providing better performance in several challenging applications like neuroscience and medical diagnosis.
MMVM Prior#
The MMVM (Multimodal Variational Mixture-of-Experts) prior is a novel approach to representation learning in multimodal VAEs. Instead of enforcing hard constraints through shared latent spaces or aggregating individual modality representations, MMVM uses a soft constraint via a data-dependent prior. This prior, a mixture-of-experts distribution formed from the individual modality posteriors, gently guides each modality’s latent representation toward a shared aggregate posterior. This soft-sharing mechanism allows each modality to retain its unique information while still benefiting from interactions with other modalities. The resulting latent space is more coherent, leading to improved generative capabilities and better imputation of missing modalities. Key to MMVM’s success is its ability to balance modality-specific and shared information in the latent space, a challenge faced by previous approaches. Minimizing the Jensen-Shannon divergence between unimodal posteriors acts as a soft-alignment, improving the quality of the learned latent representations. The MMVM prior represents a significant advancement in multimodal VAE design.
Benchmark Tests#
Benchmark tests in a research paper are crucial for validating the proposed method against existing state-of-the-art techniques. A robust benchmark should include a diverse set of datasets representing various characteristics and complexities. The selection of these datasets directly impacts the generalizability of the findings, as a method performing well only on specific datasets might not be as effective in real-world applications. The choice of evaluation metrics is equally important and should align with the paper’s objectives. Using a range of metrics, such as precision, recall, F1-score, and AUC, provides a more holistic assessment. It’s crucial to report results statistically significantly, incorporating error bars or confidence intervals. Furthermore, clear documentation of experimental setup (hyperparameters, training procedures, etc.) enables reproducibility and facilitates comparison with future works. Qualitative analysis complementing the quantitative results enhances the understanding of the method’s strengths and weaknesses in various scenarios. Finally, a strong benchmark section should discuss any limitations and potential biases, providing a balanced view of the proposed method’s performance and its applicability to broader contexts.
Real-world Use#
A research paper’s ‘Real-world Use’ section would ideally demonstrate the practical applicability of the presented method beyond simulations or benchmark datasets. Concrete examples showcasing the technique’s effectiveness in solving real-world problems are essential. This could involve case studies from diverse domains, highlighting the method’s advantages over existing solutions. Quantitative results comparing performance against existing methods or baselines in these real-world scenarios are critical. The discussion should also address the method’s scalability and robustness when confronted with challenges such as noisy data, missing values, or variations in data quality inherent in real-world settings. Finally, attention should be given to ethical considerations and potential limitations when deploying such a method in practical contexts, especially in sensitive domains like healthcare or finance.
Future Work#
Future research directions stemming from this work on multimodal VAEs could explore several promising avenues. Improving the scalability of the model for handling a truly massive number of modalities is crucial, perhaps through hierarchical or clustered approaches. Investigating alternative prior distributions beyond the mixture-of-experts prior, particularly those that better account for complex relationships between modalities, warrants investigation. Applying the MMVM framework to other generative models, such as diffusion models or GANs, could unlock new capabilities in multimodal generation. Finally, a deeper theoretical analysis of the MMVM objective function, including its convergence properties and relationship to other contrastive learning methods, would solidify its foundation and inform future improvements. This would involve formally characterizing the relationship between the soft-alignment induced by the prior and the quality of the learned representations.
More visual insights#
More on figures

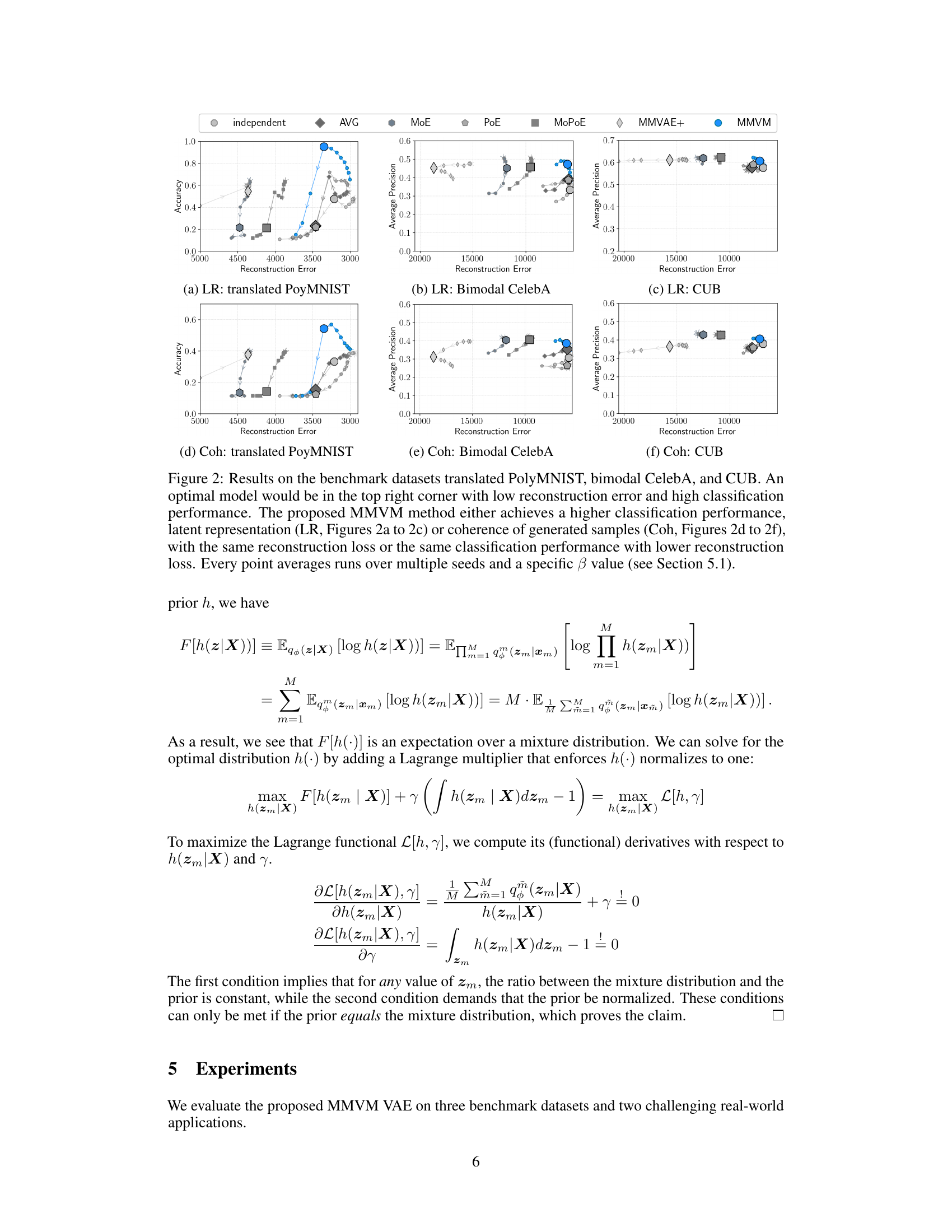
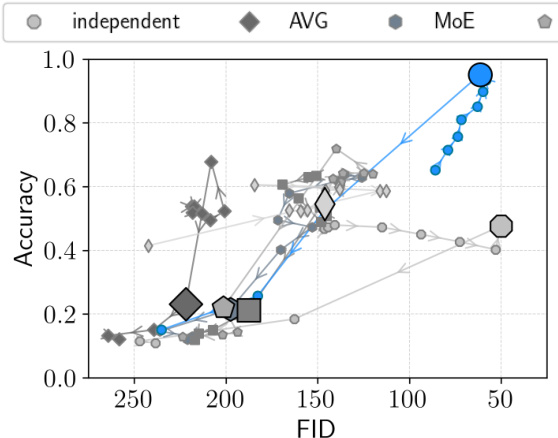
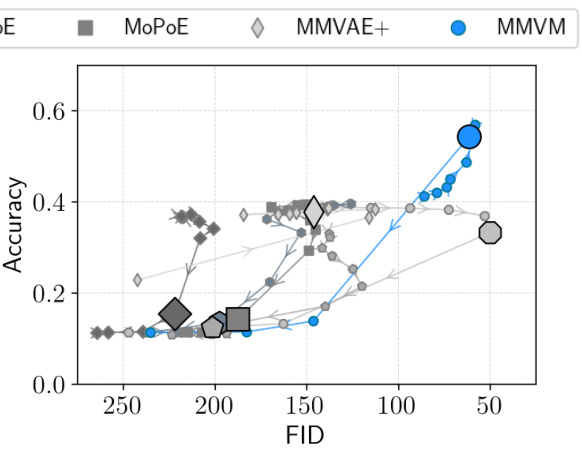
This figure compares the performance of different VAE models on three benchmark datasets (translated PolyMNIST, bimodal CelebA, and CUB) in terms of reconstruction error, classification accuracy, and sample coherence. The MMVM model consistently outperforms other methods, showing improvements in either classification accuracy or sample coherence while maintaining similar or better reconstruction error.
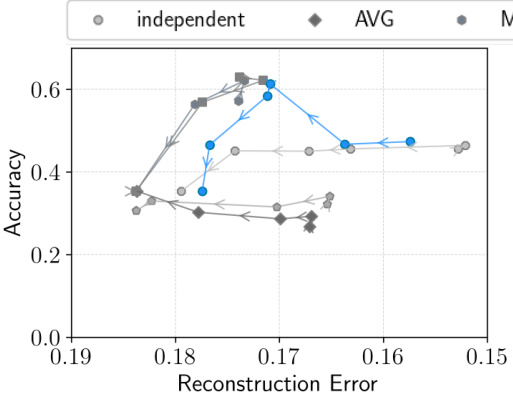
This figure compares the performance of different VAE models (independent, AVG, MoE, PoE, MoPoE, MMVAE+, and MMVM) on three benchmark datasets: translated PolyMNIST, bimodal CelebA, and CUB. The results are presented as scatter plots, with the x-axis representing reconstruction error and the y-axis representing either latent representation classification accuracy or coherence of generated samples. Each point represents the average performance over multiple random seeds and a specific beta value. The ideal model would have both low reconstruction error and high classification accuracy/coherence, indicated by a position in the top right corner of each plot. The MMVM model consistently shows superior performance compared to the other methods.
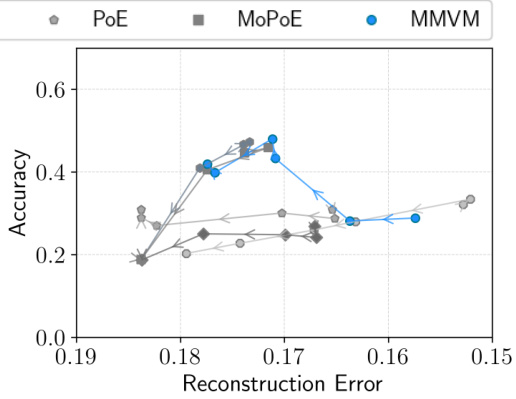
This figure displays the results of three benchmark datasets: translated PolyMNIST, bimodal CelebA, and CUB, comparing different VAE methods (independent, AVG, MoE, PoE, MoPoE, MMVAE+, and MMVM). The results are plotted as average precision against reconstruction error. Higher average precision and lower reconstruction error indicate better performance. The MMVM method shows superior performance compared to others, showing higher average precision or lower reconstruction error in both latent representation and coherence of samples.
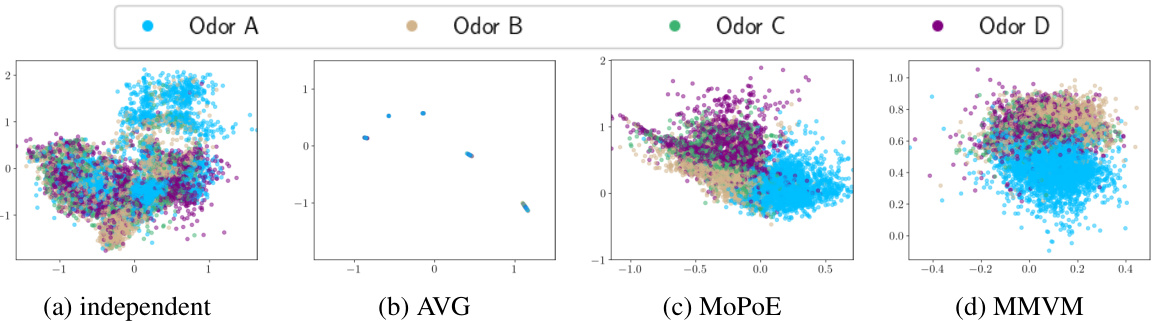
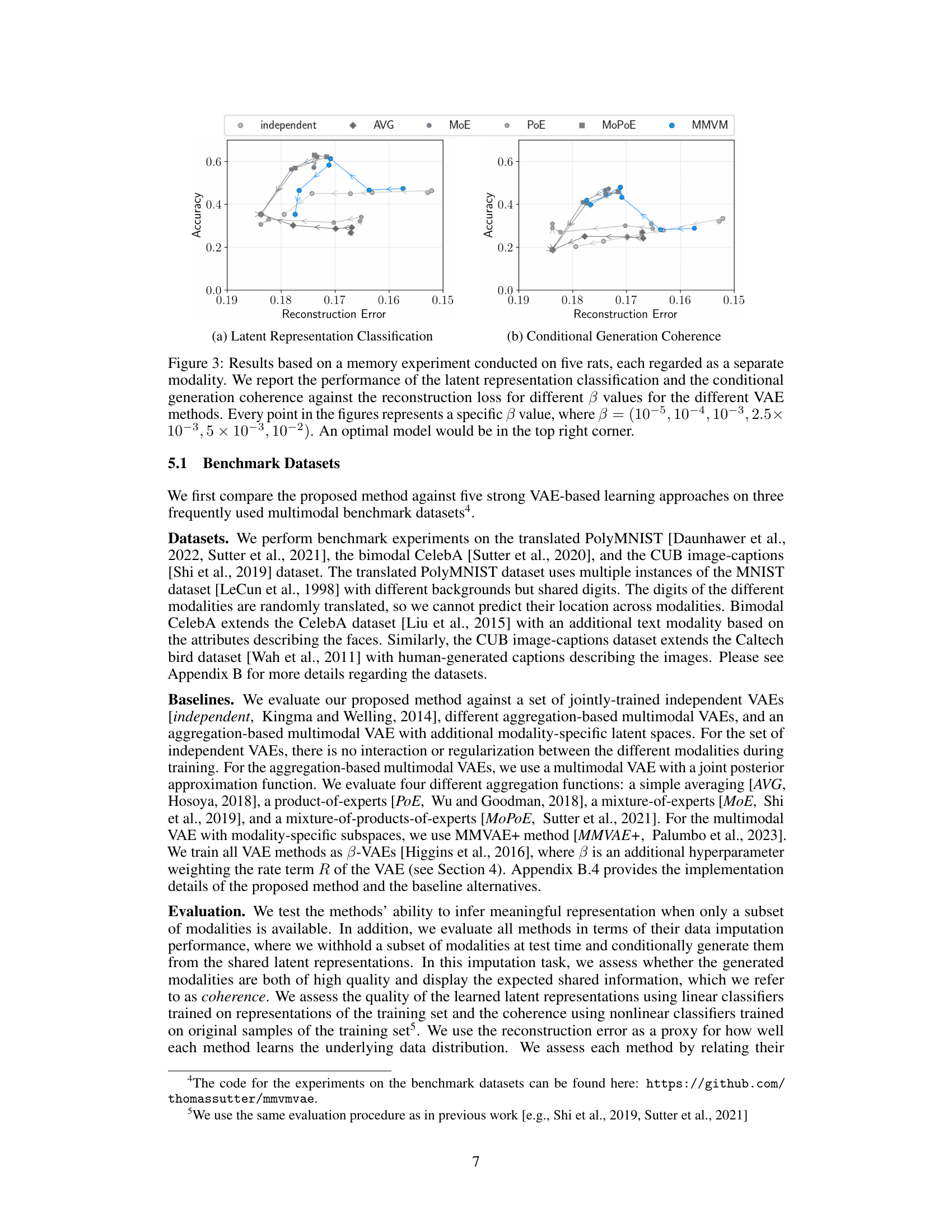
This figure compares the latent neural representations learned by four different VAE models (independent, AVG, MoPoE, and MMVM) during a memory experiment involving odor stimuli. The models’ performance is assessed based on their ability to classify odor stimuli within the learned latent space, using a classification accuracy metric as described in Figure 3a. The MMVM model achieves a clear separation of the four odors in the latent space, demonstrating its effectiveness at capturing and distinguishing odor information. In contrast, both the independent and AVG models fail to integrate information from multiple views (rats), resulting in odor separation confined to individual views. The MoPoE model demonstrates a similar performance to MMVM in terms of odor separation.

The figure shows a plot of the objective function (\mathcal{E}) against the logarithm of the hyperparameter (\beta). It demonstrates that the negative mean squared error (MSE) of a standard autoencoder provides an upper bound for the proposed MMVM VAE objective function. As (\beta) decreases, the objective function approaches the MSE bound, suggesting a connection between the two and validating the theoretical findings of the paper.

This figure shows examples from the translated PolyMNIST dataset. Each column represents a multimodal data point with multiple modalities (images of the same digit with different backgrounds). Each row displays samples from a single modality, illustrating the random translation of the digit within each image.
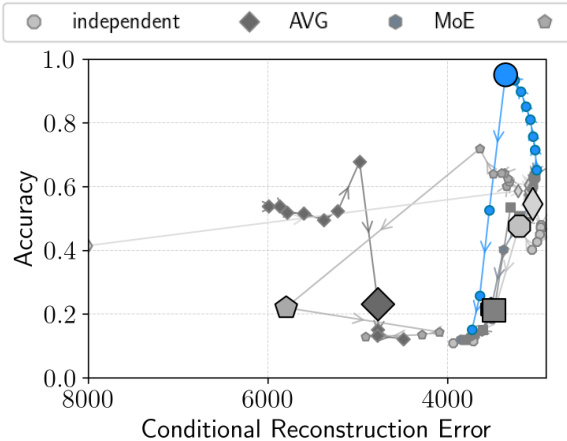
This figure presents the results of experiments conducted on three benchmark datasets: translated PolyMNIST, bimodal CelebA, and CUB. The results compare various VAE methods, including the proposed MMVM VAE, across two key metrics: latent representation quality and coherence of generated samples. The plots show a trade-off between reconstruction error and classification accuracy. The MMVM VAE consistently demonstrates superior performance, achieving higher classification accuracy or lower reconstruction error than existing methods in most scenarios.

This figure shows the results of three benchmark datasets (translated PolyMNIST, bimodal CelebA, and CUB) comparing different VAE methods (independent, AVG, MoE, PoE, MoPoE, MMVAE+, and MMVM) based on their latent representation classification accuracy and sample coherence against reconstruction error. The MMVM method shows improvements compared to other methods, achieving either higher classification/coherence with similar reconstruction error or similar classification/coherence with lower reconstruction error.
This figure presents the results of experiments on three benchmark datasets: translated PolyMNIST, bimodal CelebA, and CUB. The results are presented as scatter plots, showing the trade-off between reconstruction error and either classification accuracy (latent representation) or sample coherence. Each point represents the average of multiple runs with different random seeds and a specific β value. The MMVM method generally achieves superior performance compared to alternative methods.
This figure displays the results of experiments on three benchmark datasets: translated PolyMNIST, bimodal CelebA, and CUB. The results are shown in terms of reconstruction error (lower is better) and classification accuracy or sample coherence (higher is better). The MMVM method consistently outperforms other methods, demonstrating its ability to improve latent representation learning in multimodal VAEs.

This figure shows the qualitative results of the conditional generation task performed on the unimodal VAEs. The results visualize the conditional generation of one modality given another modality. Each subfigure represents the conditional generation of a specific modality (m0, m1, m2) given another specific modality (m0, m1, m2). The images are arranged in a grid to compare the generated samples across different modalities.

This figure compares three different approaches to handling multiple modalities in a Variational Autoencoder (VAE). (a) shows independent VAEs, where each modality is processed separately, lacking information sharing. (b) shows an aggregated VAE, attempting to combine modalities into a single shared representation, but potentially losing detail or leading to poor reconstruction. (c) presents the proposed MMVM VAE, which uses a data-dependent prior to allow for soft information sharing between modalities, aiming to retain individual modality detail while improving the shared representation.

This figure shows the qualitative results of applying unimodal VAEs to the conditional generation task. The results are presented in a grid format, where each cell shows a generated sample. The rows represent the input modality (m0), while the columns represent the generated modality (m0, m1, m2). This visualization helps in assessing the quality and coherence of the generated samples in each modality. Each modality is treated independently, therefore showing the limitations of this approach.

This figure compares the performance of different VAE models on three benchmark datasets (translated PolyMNIST, bimodal CelebA, and CUB). The results are presented as scatter plots, where the x-axis represents the reconstruction error and the y-axis represents either classification accuracy (latent representation) or sample coherence. The MMVM model generally outperforms other methods, achieving better classification performance or lower reconstruction error for a given level of coherence or accuracy. The plot indicates that the ideal VAE model would have both low reconstruction error and high classification performance.

This figure displays the performance of various models (Independent, AVG, MoE, PoE, MoPoE, MMVAE+, and MMVM) on three benchmark datasets: translated PolyMNIST, bimodal CelebA, and CUB. The results are shown in terms of reconstruction error and classification accuracy (for latent representation learning) and coherence (for generated sample quality). The ideal model would minimize reconstruction error and maximize classification accuracy/coherence. The MMVM model consistently achieves superior results in at least one of these metrics across all three datasets. The multiple points for each method represent results for different hyperparameter (β) values.

This figure compares three different approaches for handling multiple modalities in a Variational Autoencoder (VAE): independent VAEs, aggregated VAEs, and the proposed MMVM VAE. Independent VAEs process each modality separately, lacking information sharing. Aggregated VAEs combine modality information into a joint representation, potentially sacrificing individual modality detail. The MMVM VAE offers a compromise, softly integrating information across modalities via a data-dependent prior while preserving individual modality reconstructions.
This figure presents the results of the MMVM VAE and five comparative methods on three benchmark datasets: translated PolyMNIST, bimodal CelebA, and CUB. The results are shown using scatter plots, where each point represents the average performance across multiple trials with a specific value of the hyperparameter β. The x-axis of each plot represents the reconstruction error, while the y-axis displays either the classification accuracy of a learned latent representation or the coherence of generated samples (depending on the subplot). An ideal model would show a low reconstruction error and high values for both classification accuracy and coherence, residing in the top-right corner of each plot. The figure demonstrates the superior performance of the MMVM VAE in multiple scenarios by achieving either better classification or coherence scores at the same level of reconstruction error, or achieving similar classification and coherence scores with lower reconstruction error compared to the other methods.
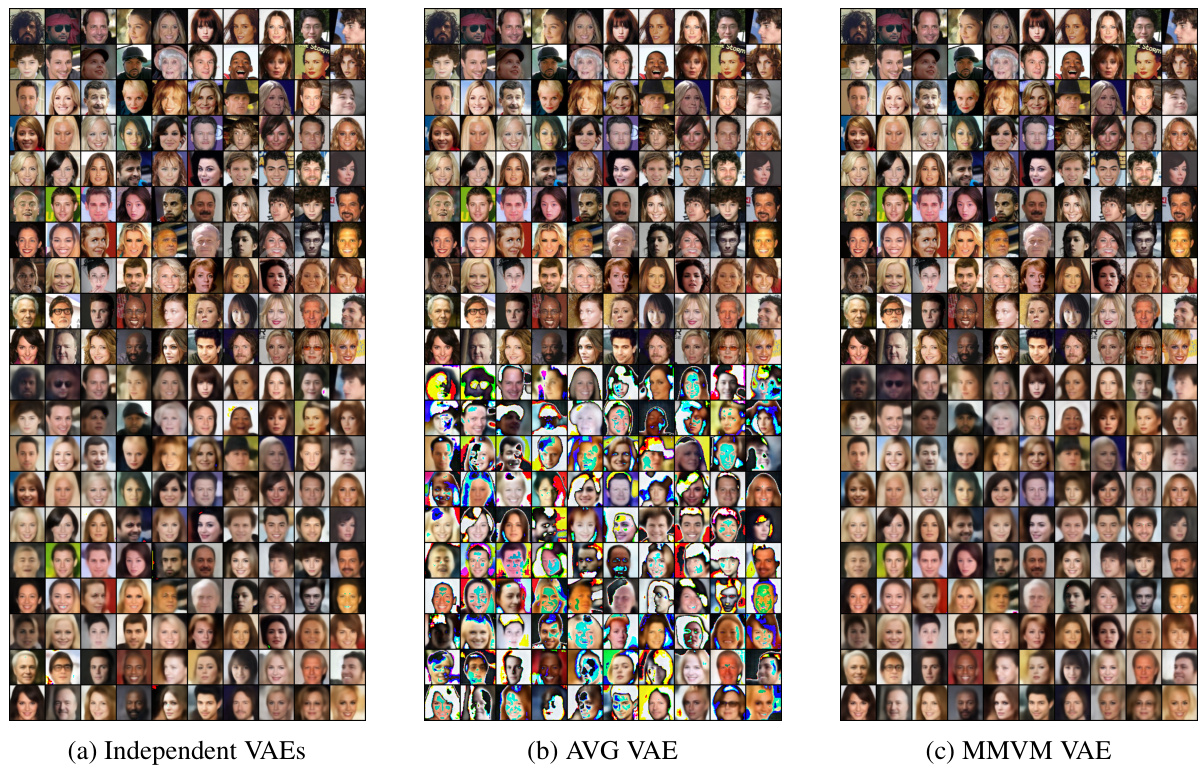
This figure compares three different approaches to handling multimodal data with VAEs. (a) shows independent VAEs, where each modality is processed separately. (b) illustrates an aggregated VAE, combining modality information into a single joint posterior, but potentially leading to poorer reconstruction quality. (c) presents the proposed MMVM VAE, which uses a data-dependent prior to softly guide each modality’s latent representation towards a shared representation, combining the benefits of independent processing with information sharing.
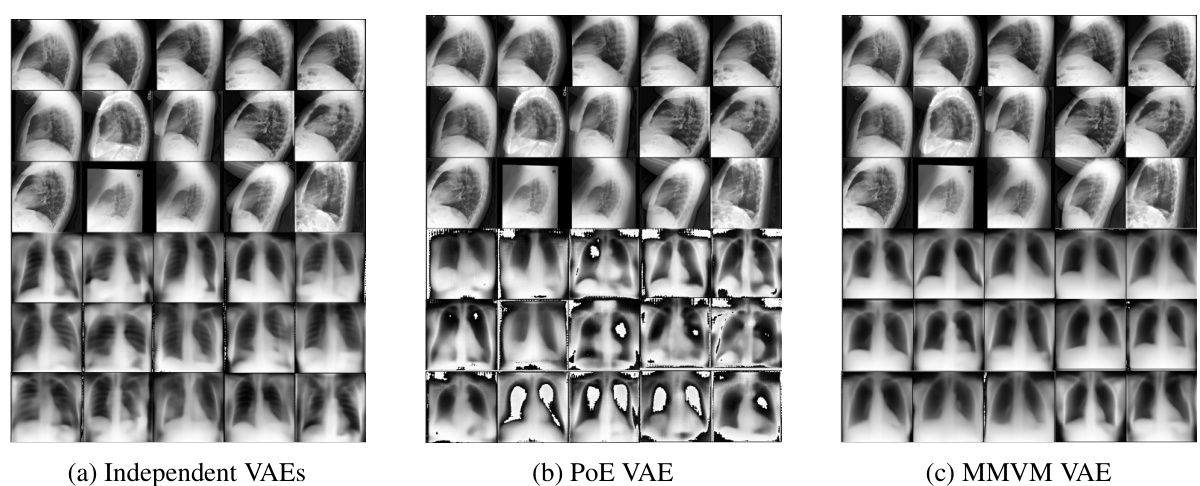
This figure compares three different approaches to handling multiple modalities in a variational autoencoder (VAE): independent VAEs, aggregated VAEs, and the proposed MMVM VAE. Independent VAEs process each modality separately, lacking information sharing. Aggregated VAEs combine modality information into a joint posterior, potentially leading to poor reconstruction. The MMVM VAE introduces a soft constraint, allowing for information sharing while maintaining modality-specific reconstructions.
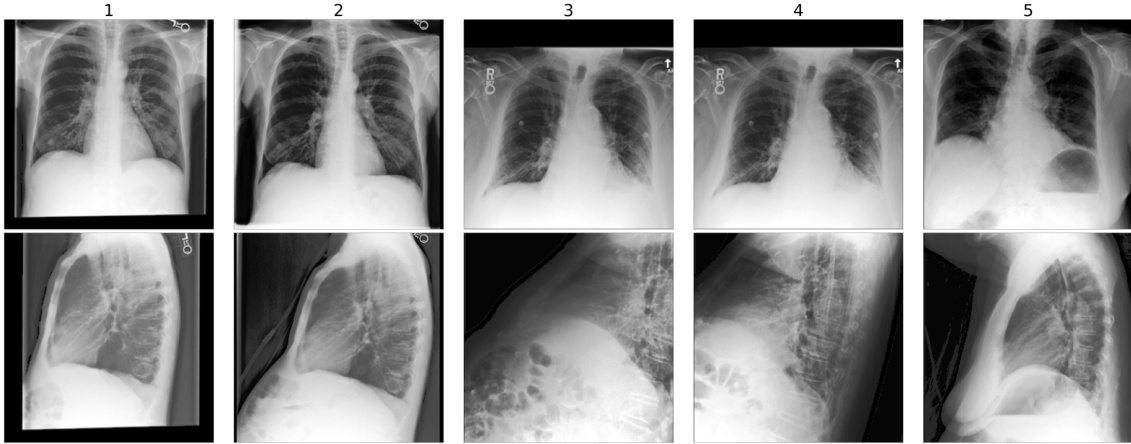
This figure shows examples from the MIMIC-CXR dataset used in the paper. Each column represents a single study with paired frontal and lateral X-ray images. The caption highlights that the first two examples are labeled as ‘No Findings’, indicating healthy patients, while subsequent examples illustrate patients with ‘Consolidation’ and ‘Atelectasis’ conditions. The figure emphasizes that although some frontal views may be the same across multiple studies, the paired lateral views are distinct.

The figure shows the performance of latent representation classification for the MIMIC-CXR dataset. The mean AUROC (area under the receiver operating characteristic curve) is calculated across all labels and averaged over three different seeds. This provides an aggregate measure of classification performance, taking into account variation across different random initializations of the models. The x-axis represents the reconstruction error, indicating a trade-off between reconstruction quality and classification accuracy.
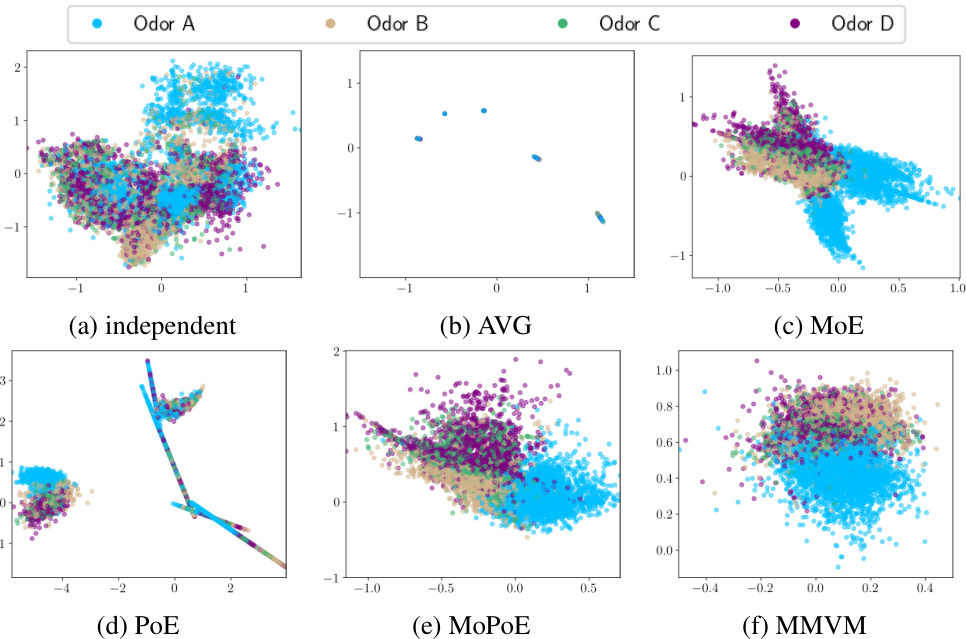
The figure displays the latent neural representations learned by four different VAE models (independent, AVG, MoPoE, and MMVM) during a memory experiment involving odor stimuli. The performance of each model is assessed based on its unimodal latent representation classification accuracy. The MMVM model effectively separates the odor stimuli in the latent space, demonstrating its ability to integrate information from multiple views (rats). In contrast, the independent and AVG models fail to integrate multi-view information, resulting in less distinct odor separation.
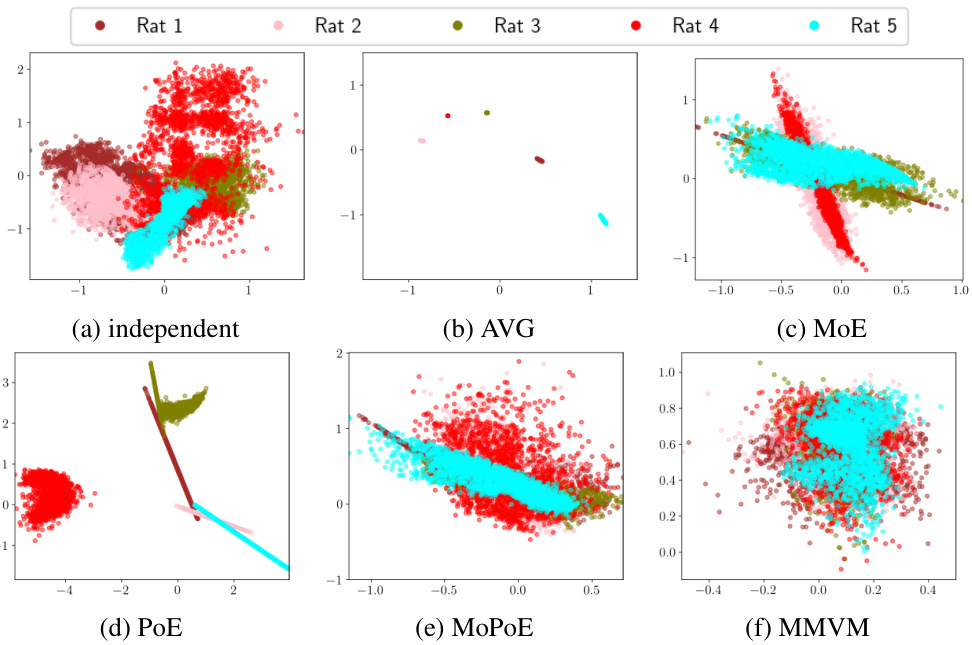
This figure shows the 2D latent representations generated by four different VAE models (independent, AVG, MoPoE, and MMVM) for a hippocampal neural activity memory experiment. Each point represents a 100ms sub-window of neural activity data, colored by odor stimulus. The MMVM model shows clear separation of odors, indicating better representation learning compared to other models, which struggle to separate odors effectively across modalities.
More on tables

This table presents the results of evaluating the quality of latent representations learned by various variational autoencoders (VAEs) on the MIMIC-CXR dataset. The Area Under the Receiver Operating Characteristic curve (AUROC) is used as a metric to evaluate the performance of classifying different chest X-ray conditions using the learned representations. The MMVM VAE demonstrates superior performance in most cases compared to other VAEs and achieves results comparable to a fully-supervised approach. The table shows average AUROC over three random seeds for frontal and lateral views.
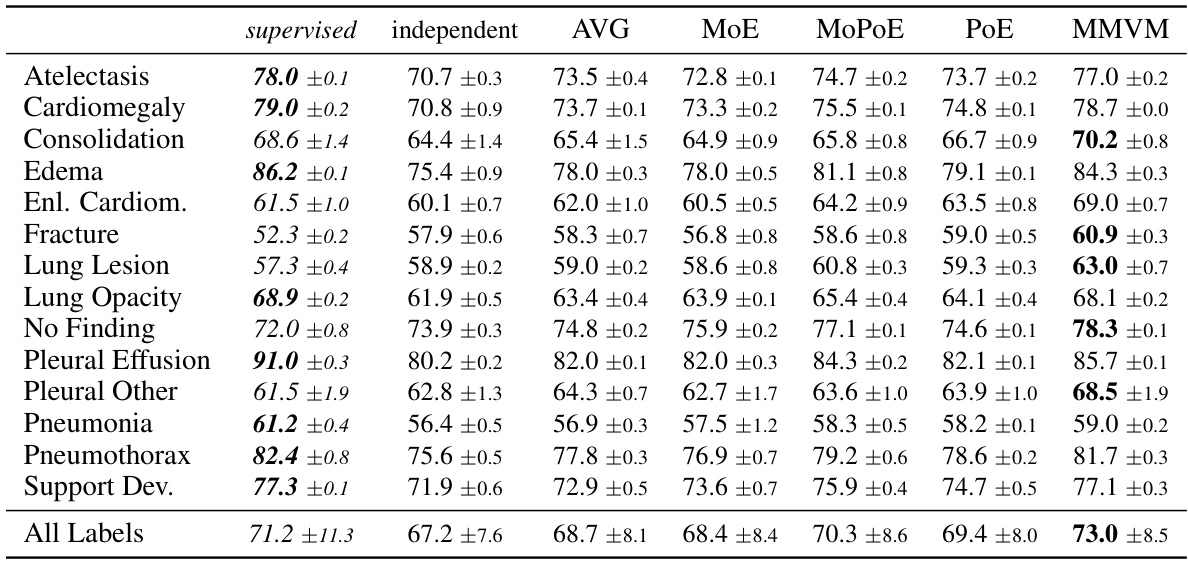
This table presents the results of the classification performance on the test set, using the lateral latent representation (zl) learned by different VAE models. It shows the average Area Under the Receiver Operating Characteristic curve (AUROC) and standard deviation across three random seeds for each model and label. A fully supervised model’s performance is provided for comparison. Abbreviations include Enl. Cardiom. (Enlarged Cardiomediastinum) and Support Dev. (Support Device).
Full paper#