↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current vision model pre-training heavily relies on paired image-text data, limiting accessibility due to high annotation costs. This paper tackles this challenge by focusing on interleaved image-text data, a more readily available format found on the web. This prevalent, unstructured format poses challenges for existing methods, highlighting the need for novel pre-training approaches that can effectively leverage its richness.
The authors propose Latent Compression Learning (LCL), a novel method that performs latent compression by maximizing mutual information between inputs and outputs of a causal attention model. LCL is decomposed into contrastive learning between visual representation and preceding context, and generating subsequent text based on visual representation. Experimental results show that LCL matches the performance of existing methods on paired data and outperforms them on interleaved data. This demonstrates the potential of utilizing readily available interleaved image-text data for efficient and robust visual representation learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel approach to vision model pre-training using easily accessible interleaved image-text data. This addresses a critical limitation of existing methods that heavily rely on meticulously paired data, which are expensive and time-consuming to create. The findings have significant implications for broader computer vision applications and open new avenues for research in multi-modal learning.
Visual Insights#
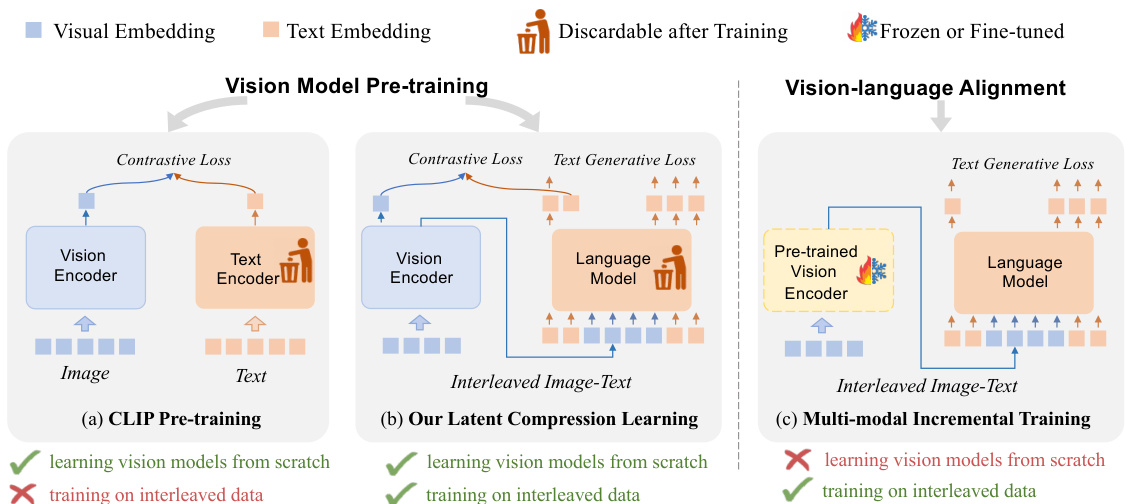
This figure compares three different vision model pre-training frameworks: CLIP, the proposed Latent Compression Learning (LCL), and multi-modal incremental training. It highlights the key differences in how each method handles image-text data (paired vs. interleaved) and whether it can train vision encoders from scratch or requires pre-trained models. CLIP uses paired data and trains from scratch, LCL also trains from scratch but uses interleaved data, while multi-modal incremental training only aligns pre-trained models and does not train from scratch. The figure illustrates that only LCL can effectively leverage interleaved data to train vision encoders from scratch.
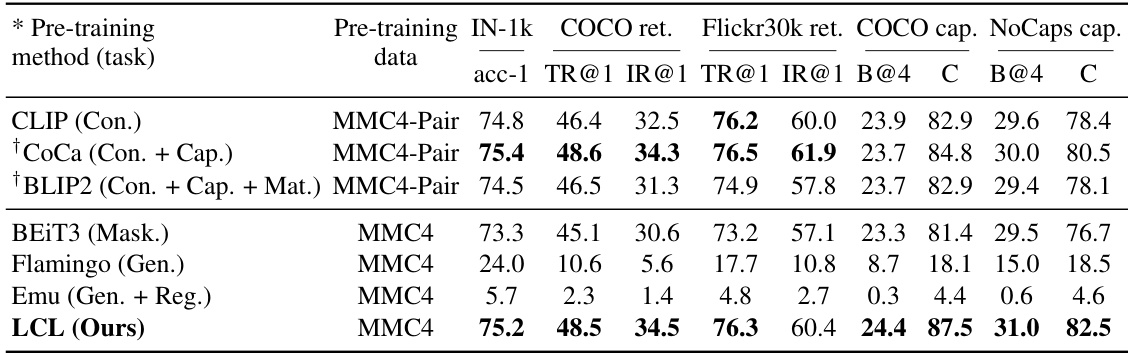
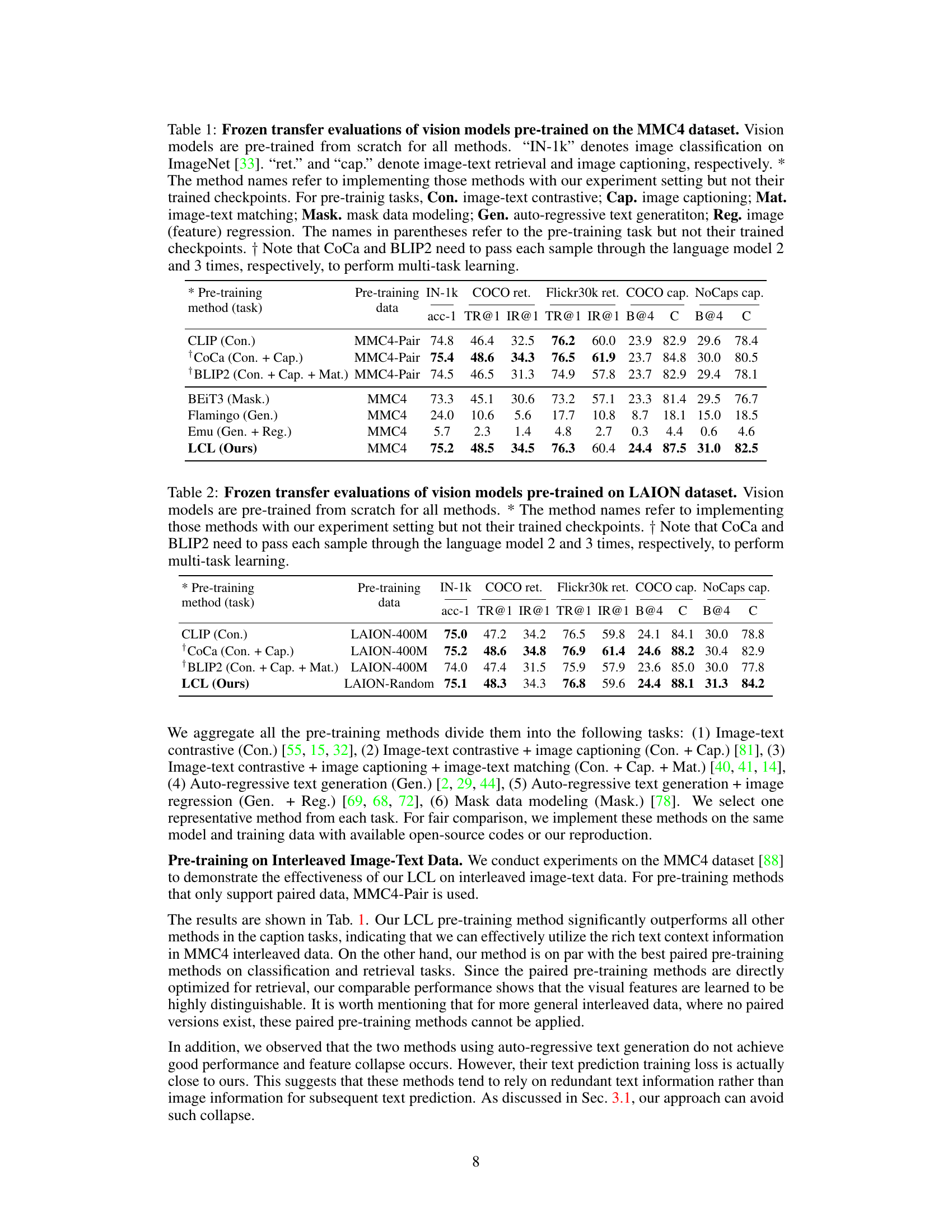
This table presents the results of a frozen transfer evaluation on the MMC4 dataset for various vision models pre-trained from scratch using different methods. It compares the performance across multiple tasks, including ImageNet-1k classification, COCO retrieval and captioning, and Flickr30k retrieval. The table highlights the performance differences among various pre-training methods, showing the effectiveness of Latent Compression Learning (LCL) on this dataset.
In-depth insights#
Latent Compression#
Latent compression, in the context of this research paper, represents a novel approach to vision model pre-training. It leverages the power of compressing interleaved image-text data, moving beyond the limitations of solely using paired data. This compression isn’t directly on raw pixels but rather on latent visual representations, extracted via a visual encoding network. This crucial step allows the model to focus on high-level semantic information while discarding less relevant details from images, leading to more robust visual representations. The method effectively combines contrastive learning (matching visual representations with preceding contexts) with auto-regressive text generation, enabling the model to effectively learn from the interleaved nature of the data, improving the efficiency of training and the quality of learned features. The theoretical underpinning relies on maximizing mutual information between input and output of the attention model, a principle also connected to compression learning in NLP, directly influencing the training objectives.
Interleaved IITD#
The concept of “Interleaved IITD” (Interleaved Image-Text Data) presents a significant challenge and opportunity in computer vision. Unlike paired image-text datasets, where each image has a corresponding caption, interleaved data mixes images and text in an unstructured, more realistic way, mirroring real-world internet content. This presents a key advantage: it allows for leveraging a vastly larger and more diverse dataset for model training. However, the lack of direct image-caption pairings requires novel approaches. Successful methods must learn to extract meaningful visual representations and associate them with relevant text segments within the complex interleaved sequence. This may involve causal attention models, which process sequences in a temporally aware manner, or compression learning techniques, focusing on extracting high-level semantic information. The success of interleaved IITD pre-training would significantly advance computer vision, allowing models to better understand and generate diverse visual-linguistic information found in natural data.
Pre-train Vision#
Pre-training vision models involves learning general visual representations from large-scale data before fine-tuning on specific downstream tasks. Effective pre-training significantly reduces the need for labeled data in the fine-tuning phase and improves the model’s generalization ability. Different approaches exist, including supervised methods using labeled datasets and self-supervised methods that leverage unlabeled data, creating pretext tasks like image in-painting or contrastive learning. Recent research focuses on incorporating text information along with image data for multi-modal pre-training, allowing the model to learn richer visual representations grounded in semantic understanding. The choice of pre-training method significantly impacts the model’s performance and efficiency, and the optimal approach may depend on the available data and target tasks. Advancements in pre-training are key drivers in improving the performance and scalability of computer vision systems.
Ablation Study#
An ablation study systematically removes components of a model or system to assess their individual contributions. In a vision model pre-training context, this might involve removing different loss functions (e.g., contrastive loss, generative loss), comparing various vision encoders, or evaluating the impact of different training datasets. The results reveal the relative importance of each component, highlighting which aspects are crucial for strong performance and which might be redundant. For instance, an ablation study could show that contrastive learning is essential for aligning visual and textual representations, while a specific data augmentation technique offers only marginal gains. Such analysis guides future development, allowing researchers to focus on core elements and optimize resource allocation, ultimately creating more efficient and effective models. A key strength of a well-executed ablation study is its ability to isolate and understand the impact of specific design choices, which would otherwise be difficult to analyze in a holistic approach. By carefully analyzing the results, valuable insights into the model’s architecture and training process can be uncovered.
Future Work#
The ‘Future Work’ section of this research paper would ideally explore several promising avenues. Extending Latent Compression Learning (LCL) to other modalities beyond vision and language, such as audio or multi-modal data fusion, would significantly broaden its applicability. Investigating the impact of different visual encoders and language models on LCL’s performance could also refine its effectiveness. A comprehensive evaluation on a wider range of downstream tasks would provide more robust evidence of its generalization capabilities. Furthermore, a thorough analysis of LCL’s scaling properties with larger datasets and model sizes is essential for demonstrating its practical value in real-world applications. Finally, exploring the potential of incorporating other compression techniques into LCL, potentially enhancing efficiency and performance, would add further depth to this research.
More visual insights#
More on figures

This figure illustrates the Latent Compression Learning (LCL) framework. Interleaved image and text data are processed. The image undergoes a vision encoder to produce latent visual representations which are then fed, along with the text embeddings, into a causal language model. Training involves two losses: a contrastive loss comparing visual representations to preceding contexts, and an autoregressive loss predicting subsequent text based on the visual representations. This dual-loss approach aims to learn robust visual representations from interleaved image-text data, effectively compressing the high-level semantic information into model parameters.
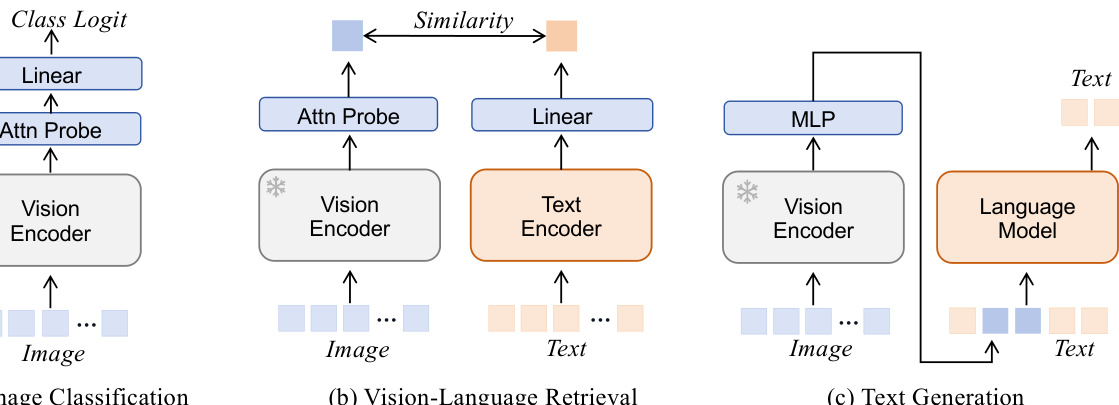
This figure illustrates the three downstream tasks used for evaluating the pre-trained vision models. The vision encoder is frozen (weights are not updated) during the transfer learning phase. (a) Image Classification: An attention pooling layer and a linear classifier are added on top of the vision encoder. Only the weights of the added layers are trained. (b) Image-text Retrieval: A global image representation is extracted using an attention pooling layer and a linear layer; a text encoder processes the text. A similarity comparison is then performed between the image and text representations. (c) Text Generation: An MLP is used to align the vision encoder’s output with the text embedding space, enabling multi-modal inputs to the language model for text generation.
More on tables
This table presents the results of a frozen transfer evaluation on the MMC4 dataset. Multiple vision models were trained from scratch using different pre-training methods. The evaluation metrics include ImageNet-1k classification accuracy, COCO retrieval performance (Top-1 and IR@1), and captioning performance (B@4 and CIDEr) on COCO and NoCaps datasets. The table compares the performance of LCL to other methods like CLIP, CoCa, BLIP2, BEIT3, Flamingo, and Emu, highlighting LCL’s effectiveness in leveraging interleaved data for pre-training.
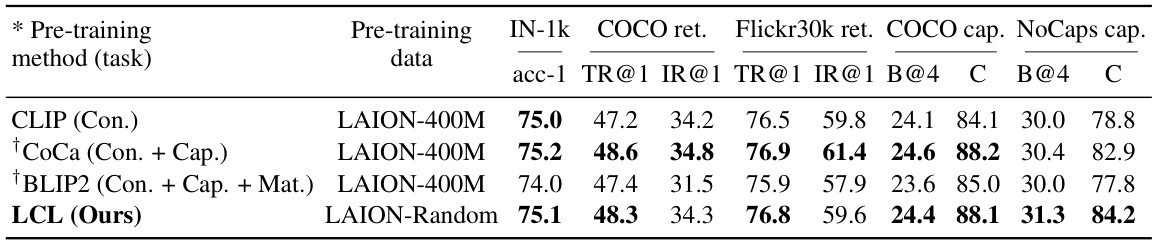
This table presents the results of a frozen transfer evaluation on the MMC4 dataset for various vision models pre-trained from scratch using different methods. It compares the performance of these models on image classification (ImageNet-1k), image-text retrieval (COCO ret., Flickr30k ret.), and image captioning (COCO cap., NoCaps cap.). The table highlights the impact of different pre-training tasks (e.g., contrastive learning, captioning, matching, masked modeling, auto-regressive generation, regression) and the use of paired versus interleaved data on model performance. It emphasizes that the reported results stem from replicating these methods under the authors’ experiment settings, not using pre-trained checkpoints of those methods.
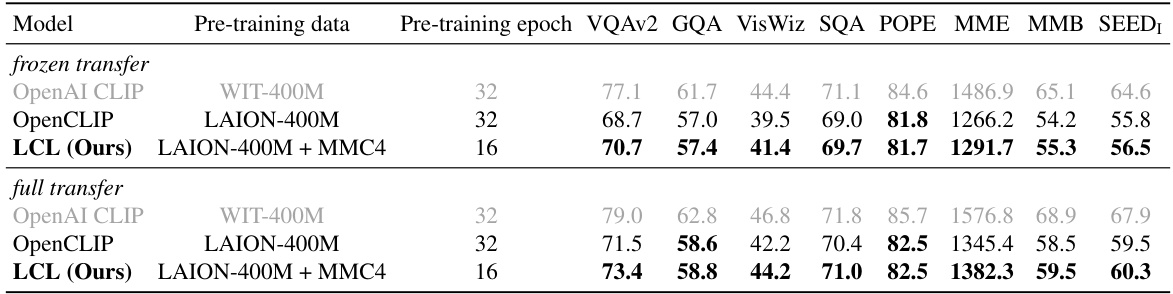
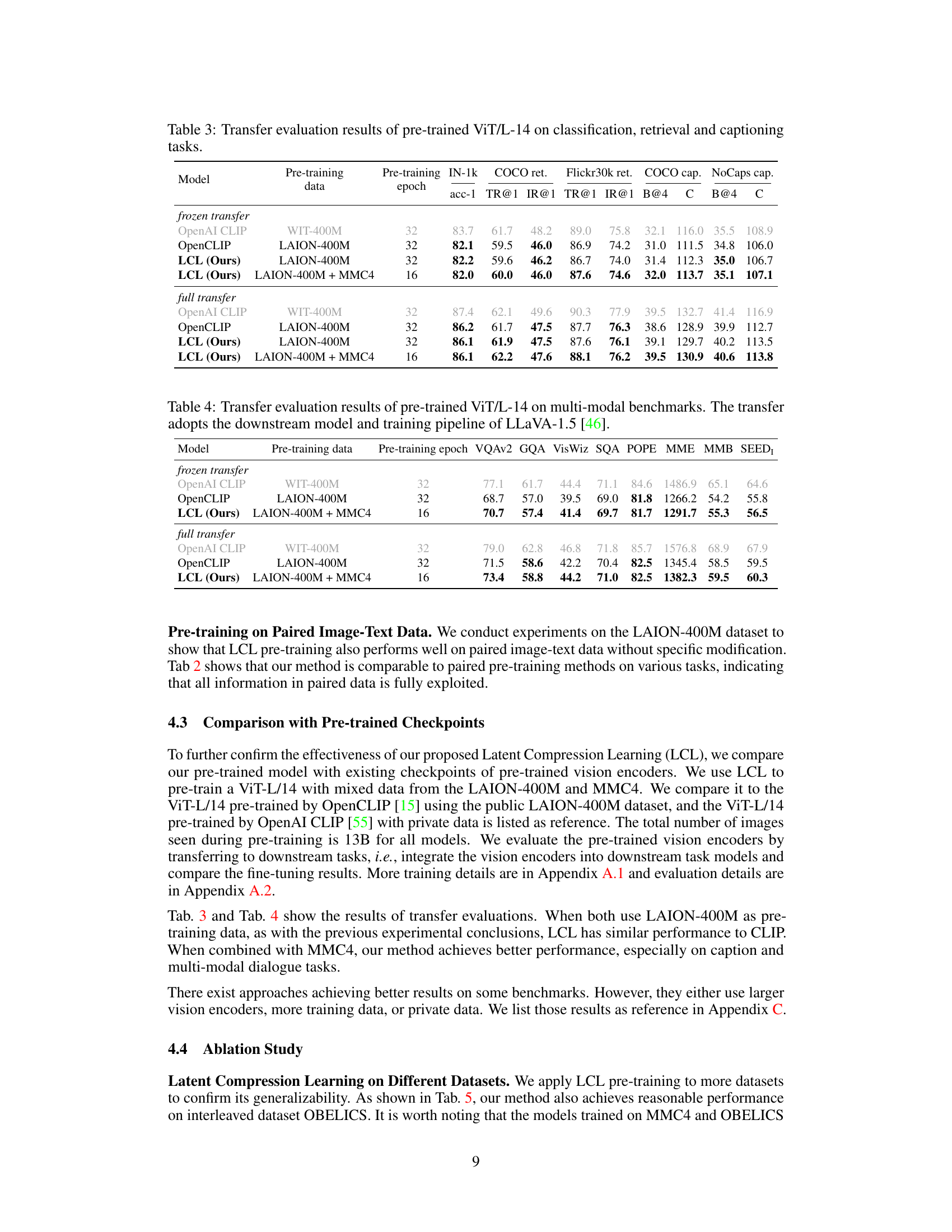
This table presents the results of transfer learning experiments using a pre-trained ViT-L-14 model on various multi-modal benchmark datasets. The experiments compare the performance of different pre-training methods, including OpenAI CLIP, OpenCLIP, and the proposed LCL method. The results are shown for both ‘frozen transfer’ (only the downstream task model is trained) and ‘full transfer’ (both the pre-trained vision model and the downstream task model are trained) settings. The benchmarks include VQAv2, GQA, VisWiz, SQA, POPE, MME, MMB, and SEEDI, evaluating the model’s performance across various multi-modal tasks.
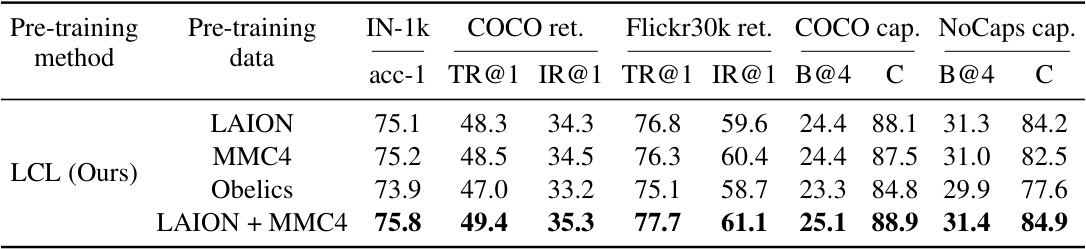
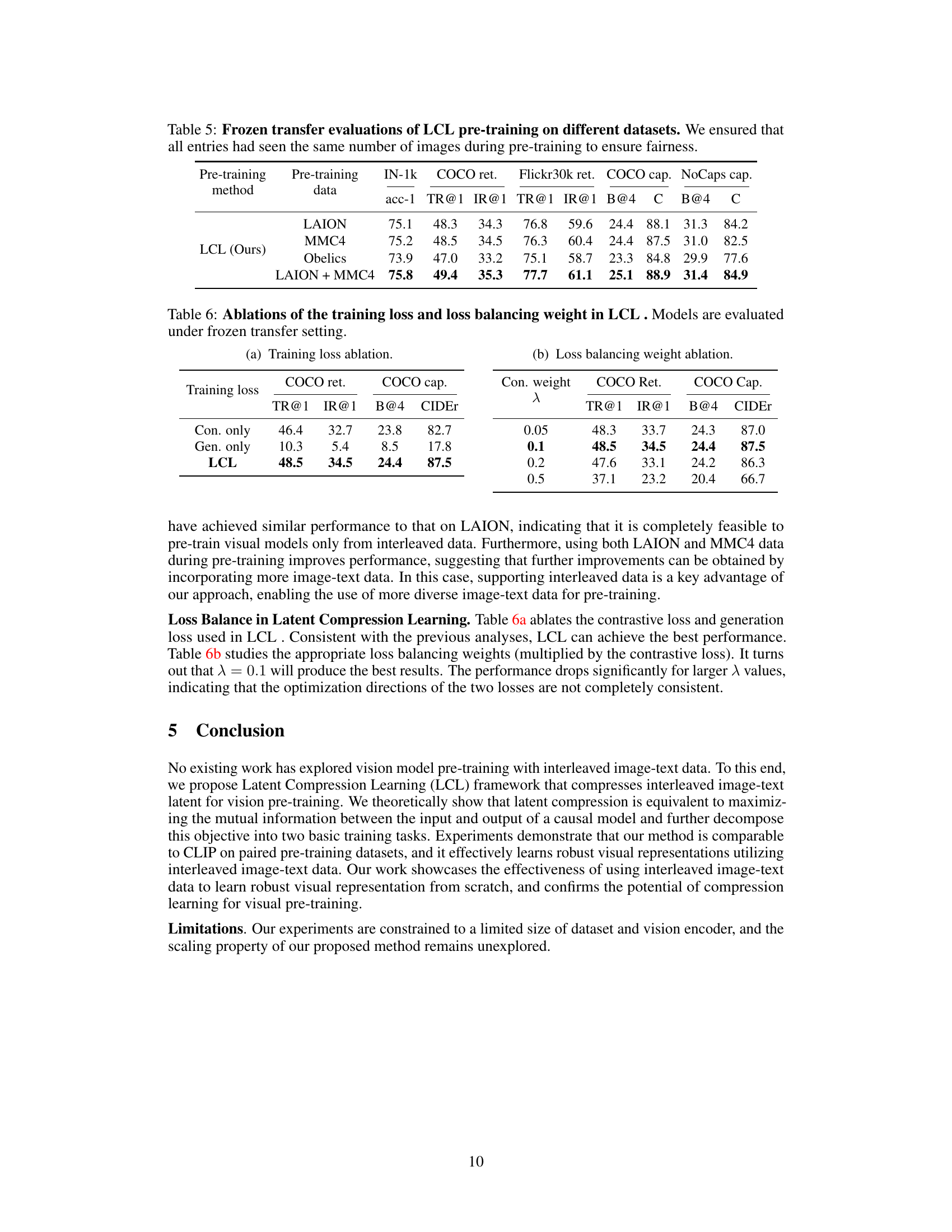
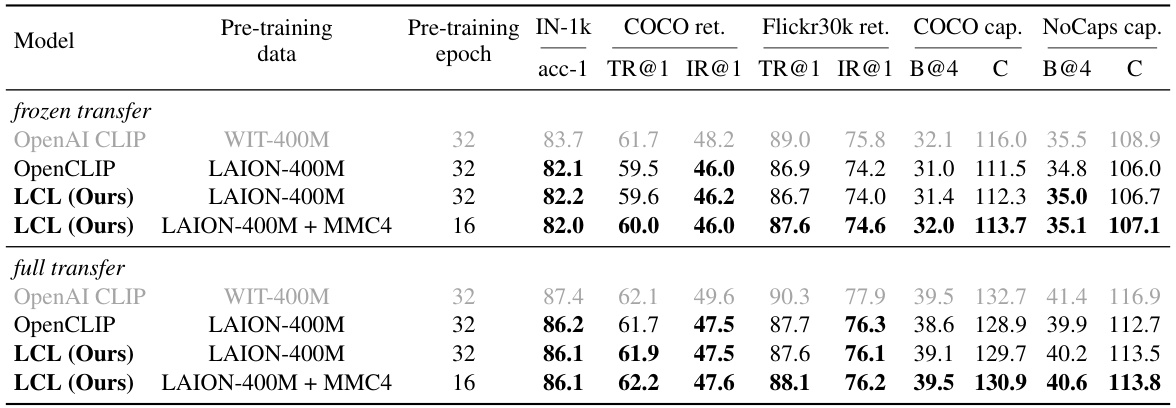
This table presents the results of the frozen transfer evaluation of the Latent Compression Learning (LCL) method on various datasets. The ‘frozen transfer’ setting means only the parameters of the added classifier were trained, not the pre-trained vision model’s parameters. The table compares the performance of LCL pre-trained on LAION, MMC4, Obelics and a combined LAION+MMC4 dataset. The performance metrics include ImageNet-1k classification accuracy (acc-1), COCO retrieval Recall@1 and Intersection over Union (IOU)@1 (COCO ret.), Flickr30k retrieval Recall@1 and IOU@1 (Flickr30k ret.), COCO captioning CIDEr score (COCO cap.), and NoCaps captioning CIDEr score (NoCaps cap). This allows for a comparison of LCL’s performance across different datasets and to evaluate the benefit of using combined training data.

This table presents the ablation study results for the Latent Compression Learning (LCL) method. It explores the impact of different training loss components (contrastive loss only, generative loss only, and the combined LCL loss) and varying loss balancing weights (λ) on the model’s performance. The performance is evaluated using the frozen transfer setting on the COCO retrieval and captioning tasks, measured by the TR@1, IR@1, B@4, and CIDEr metrics. The table allows for analysis of how different components of the training objective and the balance between them affect the final model performance.
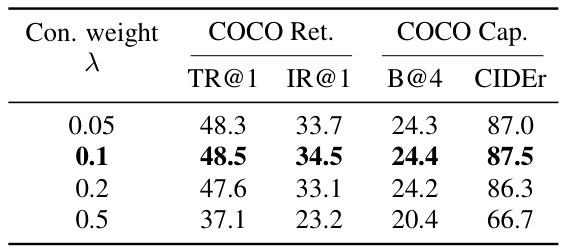
This table shows the ablation study results on the training loss and the loss balancing weight in Latent Compression Learning (LCL). The study varies the training loss by using only contrastive loss, only generation loss, and the combination of both (LCL). It also varies the balancing weight (lambda) between the contrastive loss and generation loss to find the optimal balance. The results are evaluated under the frozen transfer setting. The table demonstrates the effectiveness of the combined loss function and the optimal weight for the best performance.
This table presents the results of a frozen transfer evaluation on the MMC4 dataset for various vision models pre-trained from scratch. It compares different pre-training methods (contrastive learning, captioning, matching, masked modeling, text generation, and regression) across multiple tasks: ImageNet-1k classification, COCO retrieval, Flickr30k retrieval, COCO captioning, and NoCaps captioning. The table highlights the performance differences between models trained on paired versus interleaved data and using different pre-training objectives.
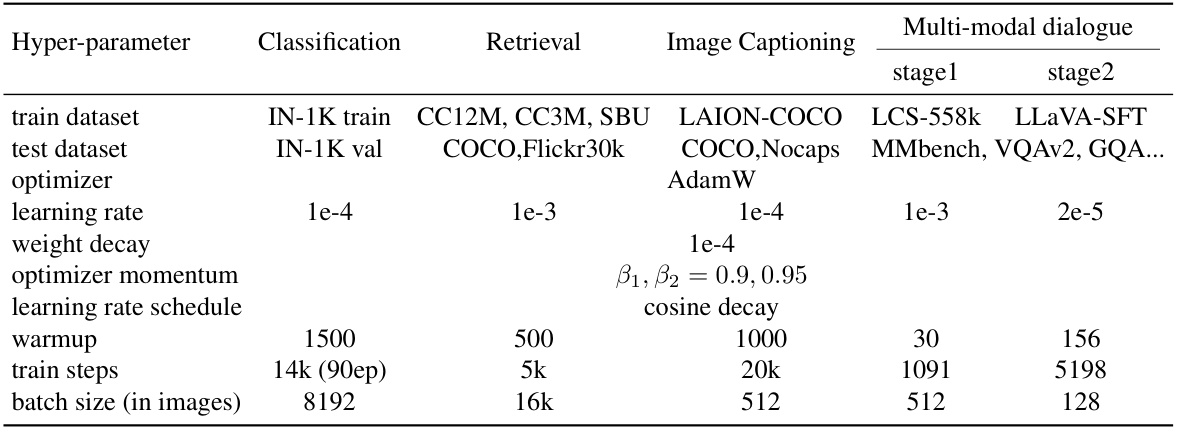
This table lists the hyperparameters used for different downstream tasks during the transfer learning phase. It specifies the optimizer, learning rate, weight decay, optimizer momentum, learning rate schedule, warmup steps, total training steps, and batch size for image classification, image-text retrieval, image captioning, and multi-modal dialogue tasks, including separate hyperparameters for the two stages of multi-modal dialogue.

This table presents the results of a frozen transfer evaluation on the MMC4 dataset for various vision models pre-trained from scratch using different methods. The table compares performance across multiple tasks (image classification, image-text retrieval, image captioning) and different pre-training approaches (contrastive learning, masked autoencoding, autoregressive text generation). It highlights the performance differences when using paired versus interleaved image-text data and notes certain implementation details for specific methods.

This table presents the results of a frozen transfer evaluation on the MMC4 dataset for various vision models pre-trained from scratch using different methods. It compares the performance of these models on image classification (ImageNet-1k), image-text retrieval (COCO ret., Flickr30k ret.), and image captioning (COCO cap., NoCaps cap.). The table highlights the performance differences based on different pre-training tasks (e.g., contrastive learning, autoregressive text generation) and whether the full models or just the vision encoders were fine-tuned during the transfer task. It also notes specific details about CoCa and BLIP2’s multiple passes through the language model.

This table presents the results of a frozen transfer evaluation of various vision models pretrained on the MMC4 dataset. The evaluation focuses on several downstream tasks: ImageNet-1k classification, COCO retrieval, Flickr30k retrieval, COCO captioning, and NoCaps captioning. The table compares the performance of different pre-training methods, highlighting the performance of the proposed LCL method against existing state-of-the-art approaches. Note that the table specifies whether the methods were pretrained from scratch or used pretrained checkpoints, and details the pre-training tasks involved (e.g., contrastive learning, captioning).
Full paper#