↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Training embodied agents to perform diverse tasks remains a challenge due to the difficulty and expense of designing reward functions for each specific task. Existing approaches often struggle with generalizing to new tasks and frequently require large amounts of fine-tuned data. This paper introduces GenRL, which utilizes multimodal-foundation world models. This innovative architecture cleverly connects the powerful representation capabilities of vision-language models with the efficiency of generative world models for RL. This connection allows tasks to be specified through visual or language prompts, which are then translated into latent targets within the world model. The agent learns to match these targets through reinforcement learning in imagination, effectively learning the desired behaviors without needing explicit rewards.
GenRL offers several key advantages. Firstly, it dramatically reduces the need for complex reward engineering. Secondly, its ability to align the representation of foundation models with the latent space of generative world models enables tasks to be specified naturally through vision and/or language. This alignment allows the agent to generalize effectively to unseen tasks. Thirdly, and most significantly, GenRL demonstrates data-free policy learning. After the initial training phase, the agent can learn new tasks without any additional data, making the approach highly scalable and efficient.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in embodied AI and reinforcement learning. It addresses the significant challenge of scaling RL to complex tasks by introducing multimodal-foundation world models. This innovative approach allows agents to generalize to new tasks with minimal data, paving the way for foundational policy learning and opening up exciting new avenues of research. The data-free policy learning aspect is especially groundbreaking, reducing data dependency and improving scalability.
Visual Insights#
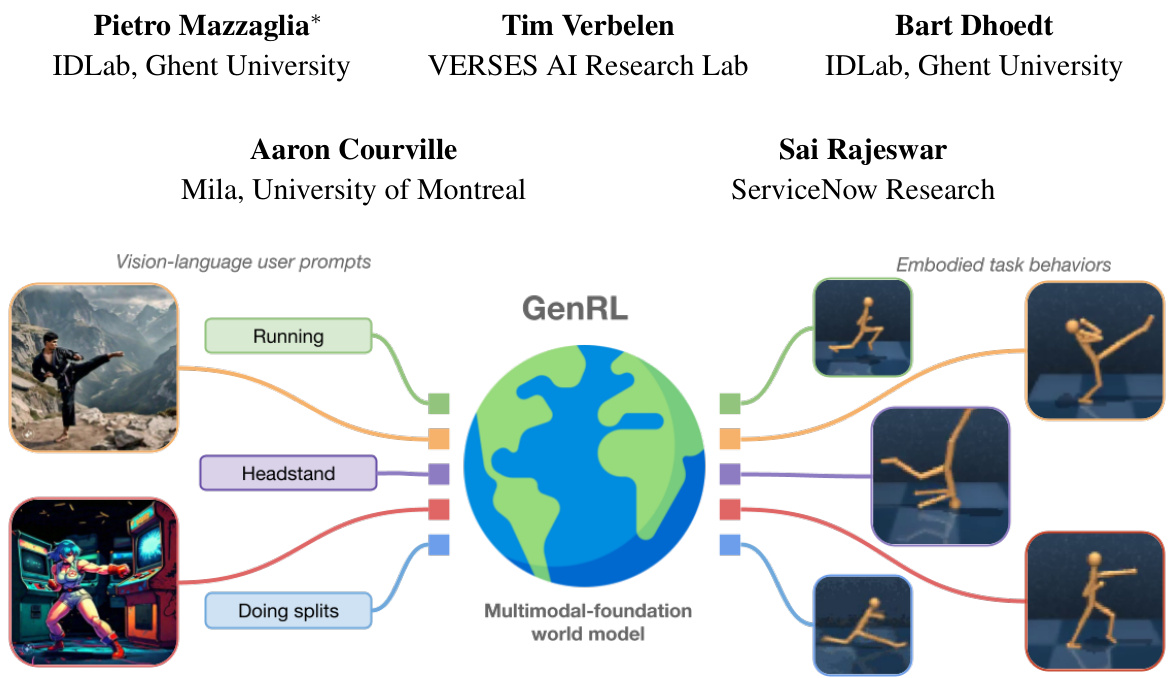
This figure illustrates the core concept of GenRL. It shows how multimodal foundation world models bridge the gap between video-language prompts and embodied agent behavior. Vision-language prompts (like images of actions and text descriptions) are processed by a foundation model, which is then linked to a generative world model. The generative world model learns to map those prompts into corresponding latent states, allowing an embodied agent to learn the behaviors associated with those prompts purely through training within the imagined world of the generative model (without interacting with the real world).

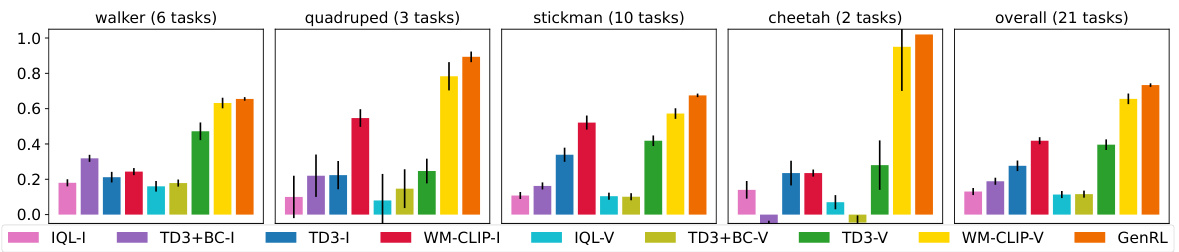
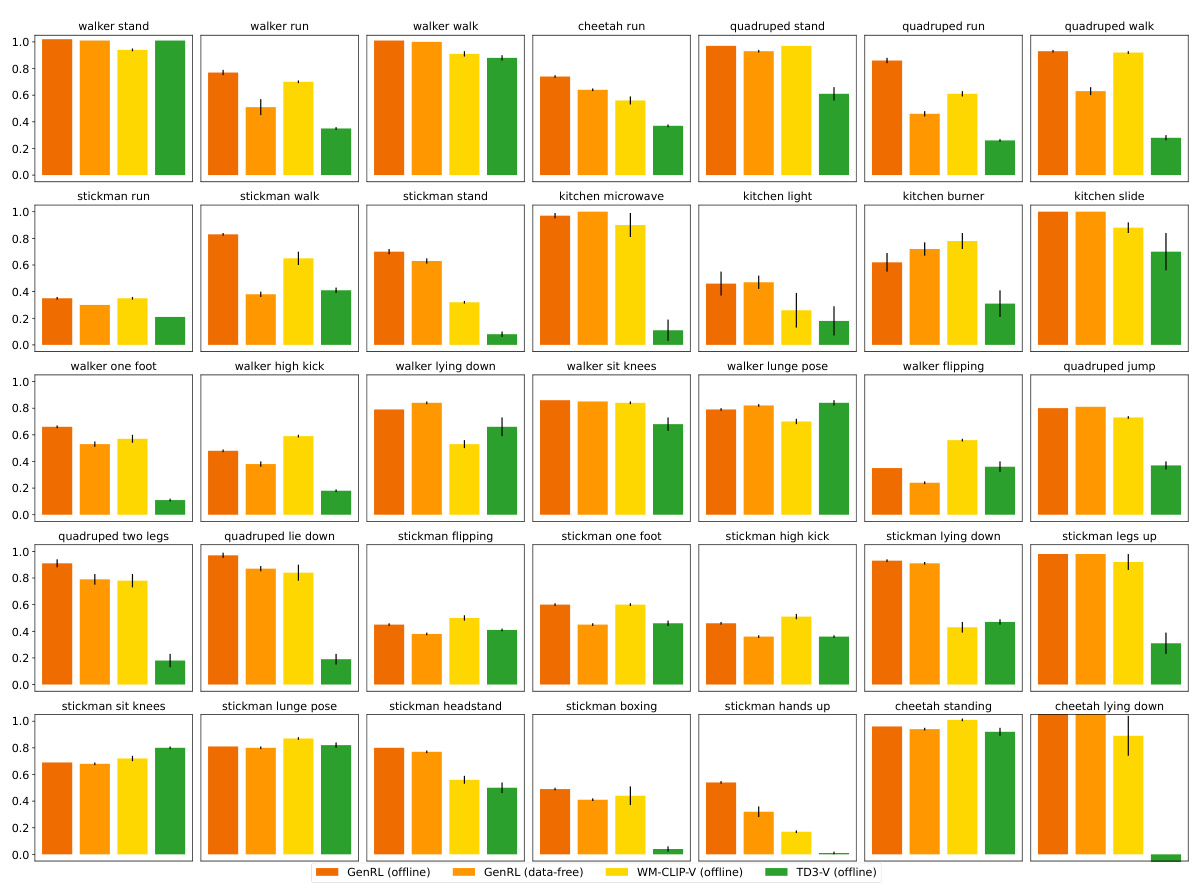
This table presents the results of offline reinforcement learning experiments using language prompts for tasks included in the training dataset. The scores are episodic rewards, averaged over ten trials, and rescaled to a range between 0 (random policy) and 1 (expert policy) for easier comparison across tasks and agents. The table compares several offline reinforcement learning methods (IQL, TD3+BC, TD3) using both image-language and video-language visual language models (VLMs) as well as GenRL, the proposed method, showcasing its performance relative to other approaches on various locomotion and manipulation tasks.
In-depth insights#
Multimodal-RL#
Multimodal-RL, a field at the intersection of artificial intelligence and robotics, aims to enhance reinforcement learning (RL) agents by equipping them with the capacity to process and integrate multiple sensory modalities. This contrasts with traditional RL, which often relies on a single input stream, such as visual data. The key advantage of multimodal-RL lies in its ability to better represent the complexity of real-world environments, which inherently involve diverse sensory inputs, including vision, language, proprioception (body awareness), and more. This richer input representation enables agents to learn more robust and adaptable policies, leading to improved generalization and performance in diverse and unpredictable settings. A core challenge in multimodal-RL involves effectively fusing information from heterogeneous sources, requiring novel architectures and algorithms capable of handling differing data types and temporal dependencies. Further research is needed to explore more efficient and scalable multimodal RL algorithms, including those that can leverage advances in large language models and other foundation models. The potential applications of multimodal-RL are vast, ranging from robotics and autonomous driving to advanced human-computer interaction and other AI-driven systems where understanding and responding to a rich sensory landscape is paramount.
GenRL Framework#
The GenRL framework presents a novel approach to training embodied agents by leveraging multimodal foundation world models. It uniquely connects the representation of a foundation vision-language model (VLM) with the latent space of a generative world model for reinforcement learning (RL), requiring only vision data. This connection bypasses the need for language annotations in training, a significant advantage over existing methods. The framework enables task specification through visual and/or language prompts, which are grounded in the embodied domain’s dynamics and learned in the world model’s imagination. GenRL’s data-free policy learning strategy further distinguishes it, enabling multi-task generalization from language and visual prompts without additional data. This contributes significantly to developing foundation models for embodied RL, analogous to foundation models for vision and language. The framework demonstrates impressive multi-task generalization capabilities in locomotion and manipulation domains, showcasing the potential of generative world models for solving complex tasks in embodied AI.
Data-Free Learning#
The concept of “Data-Free Learning” in the context of embodied AI agents presents a significant advancement. It challenges the conventional reliance on extensive datasets for training agents, proposing instead a method where agents learn in a model’s simulated environment using only pre-trained foundation models and task prompts. This approach, particularly relevant for domains with scarce multimodal data, is achieved by embedding task specifications (either visual or textual) into the latent space of a generative world model. The agent then learns to execute the task within this simulated world, effectively eliminating the need for real-world interaction during the learning phase. This reduces data collection costs and enables generalization to unseen tasks, requiring only the ability to interpret new prompts. The success of this approach hinges on the power of pre-trained models to provide robust priors about the environment and dynamics and the ability of the model to effectively translate prompts into actionable representations within its latent space. However, the inherent limitations of the foundation models themselves (such as sensitivity to prompt tuning and the potential for inaccurate simulations) would affect the system’s performance. While showing promise, this direction needs further exploration to fully realize its potential.
Imagination RL#
Imagination RL harnesses the power of generative world models to train embodied agents. Instead of relying solely on real-world interactions, which can be expensive and time-consuming, Imagination RL allows agents to learn by simulating experiences within a learned model of the environment. This significantly speeds up the learning process and enables the exploration of a much wider range of potential behaviors. By training in this simulated environment, agents can safely experiment with different actions and strategies, optimizing their policies without the risk of damaging equipment or encountering dangerous situations in the real world. The key to Imagination RL lies in the accuracy and completeness of the world model. A high-fidelity model allows for effective training, while an inadequate model will lead to suboptimal or unsafe behaviors. The technique’s success is heavily reliant on effectively grounding language or visual prompts within the latent space of the generative model, allowing the agent to translate high-level goals into actionable sequences. Further research into improving the fidelity and efficiency of generative world models is crucial for advancing the capabilities of Imagination RL. This approach opens up new avenues for tackling complex and challenging embodied AI tasks, making it a promising area of future study. Challenges remain, however, in handling long horizons and complex scenarios; the effectiveness of the approach depends greatly on the sophistication of the underlying world model.
Future of GenRL#
The future of GenRL hinges on addressing its current limitations and exploring new avenues for improvement. Scaling to more complex environments and handling more nuanced tasks are crucial next steps. This necessitates improved world model architectures capable of representing intricate dynamics and incorporating richer contextual information. Further research should focus on improving the robustness of the VLM integration, potentially by exploring alternative multimodal fusion techniques. Addressing the multimodality gap remains vital to enabling more seamless task specification. Finally, developing data-efficient and data-free learning strategies is key to broader adoption of GenRL, enabling generalization without extensive data collection. This may involve incorporating techniques like meta-learning or transfer learning to accelerate adaptation to new tasks.
More visual insights#
More on figures
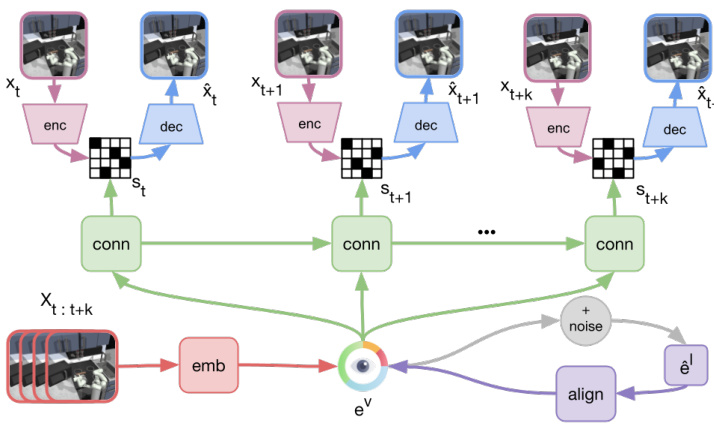
This figure illustrates the GenRL framework. Panel (a) shows how a multimodal-foundation world model connects and aligns the representation of a foundation vision-language model (VLM) with the latent states of a generative world model. Panel (b) demonstrates how a task prompt (visual or language) is embedded and translated into target latent states within the generative world model. The agent then learns to achieve these targets using reinforcement learning in the world model’s simulated environment.
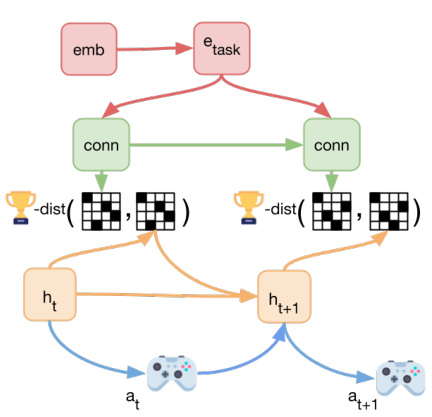
This figure illustrates the GenRL framework. Panel (a) shows how a multimodal foundation world model connects the representation of a foundation Vision-Language Model (VLM) with the latent states of a generative world model. This alignment is crucial for grounding tasks in the embodied domain. Panel (b) demonstrates how a task prompt (visual or language) is embedded and translated into target latent states within the generative world model. The agent then learns to achieve these targets using reinforcement learning within the simulated environment of the world model.

This figure illustrates the GenRL framework. Panel (a) shows how the agent learns a multimodal-foundation world model which connects the representation of a Vision-Language Model (VLM) with the latent states of a generative world model. The key is the alignment of the VLM and world model representations. Panel (b) shows how a task prompt is embedded and translated into targets in the latent space of the world model. The agent then learns to achieve these targets by performing reinforcement learning (RL) in the imagination of the world model.
This figure illustrates the GenRL framework. Panel (a) shows how GenRL connects and aligns the representation of a foundation Vision-Language Model (VLM) with the latent states of a generative world model. Panel (b) depicts how a task prompt is embedded and translated into target latent dynamics, enabling the agent to learn the corresponding behaviors through reinforcement learning (RL) within the world model’s imagination.
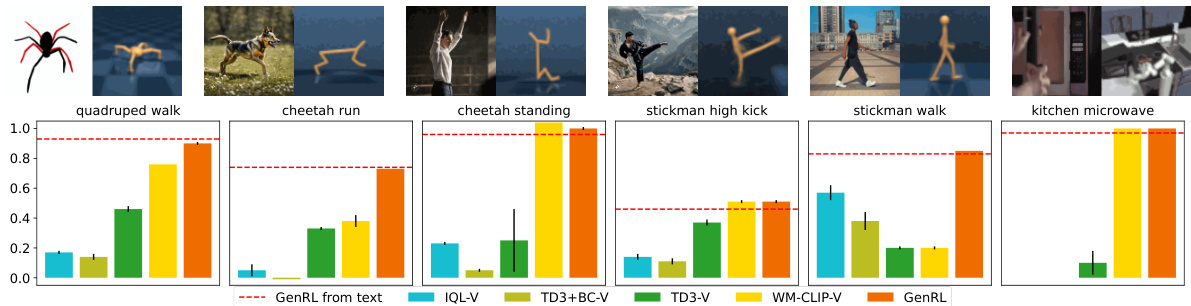
This figure demonstrates the video-to-action capability of GenRL. The top row shows example video prompts provided to the agent. The bottom row displays bar charts comparing the performance of GenRL with other baselines (IQL-V, TD3+BC-V, TD3-V, and WM-CLIP-V) across different tasks. The results highlight GenRL’s superior performance in translating video prompts into actions compared to other methods.

This figure illustrates the GenRL framework. Panel (a) shows how GenRL connects a foundation vision-language model (VLM) with a generative world model. The VLM’s representations are aligned with the generative world model’s latent space. Panel (b) demonstrates how the framework uses language or visual prompts to generate latent targets within the generative world model. The agent then learns to achieve these targets through reinforcement learning (RL) within the imagined world of the model. This process enables task learning based on only vision data without language annotations.
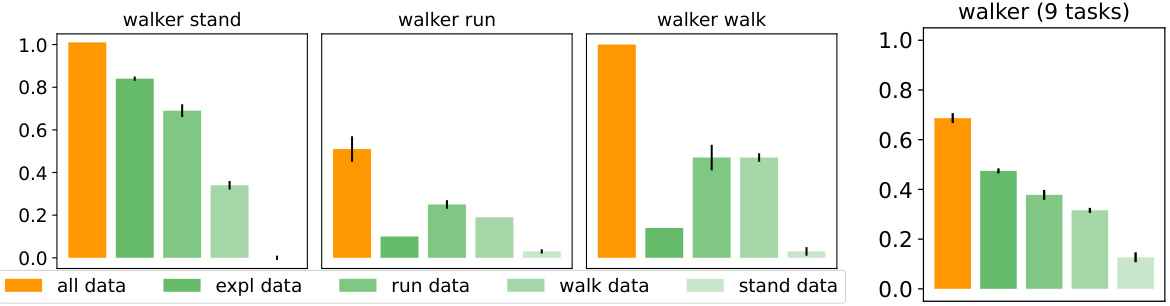
This figure analyzes how different training data compositions affect GenRL’s performance. GenRL is trained with various subsets of the full training data (all data, exploration data, run data, walk data, and stand data), then tested in a data-free setting. The bar chart displays average performance across 10 random seeds, showing the impact of training data composition on the model’s ability to generalize to unseen tasks.
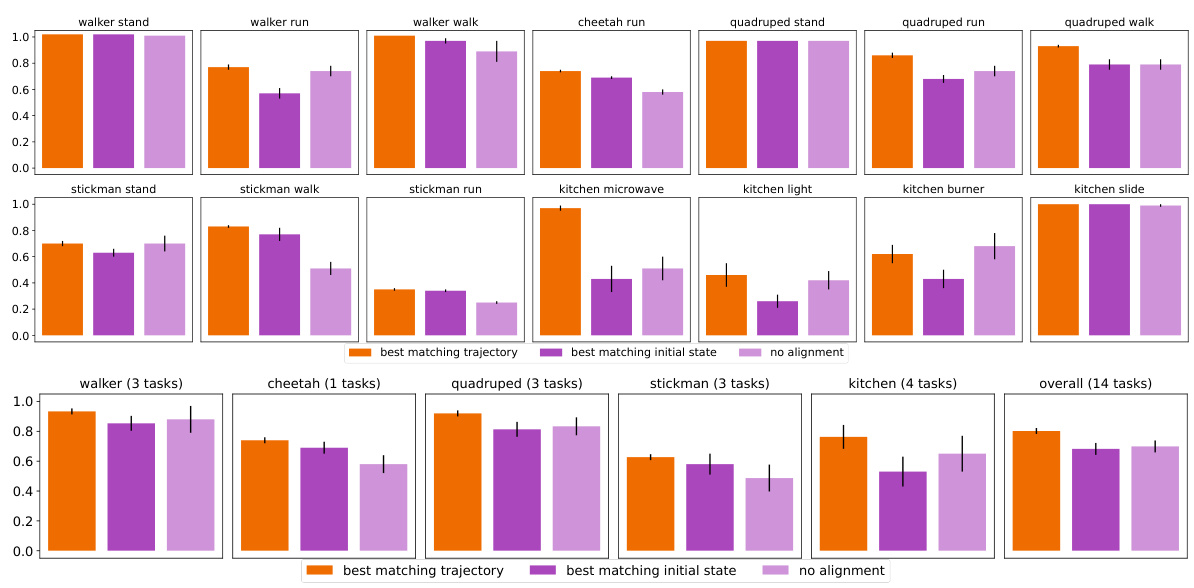
This figure presents the ablation study on the temporal alignment method used in GenRL. Three different methods for aligning the agent’s imagined trajectory with the target trajectory from the user prompt are compared: best matching trajectory (using a sliding window to find the best alignment), best matching initial state (assuming the initial state is the same), and no alignment (no special alignment). The results are shown in terms of episodic rewards averaged over 10 seeds for a range of tasks from various locomotion and manipulation environments. The figure demonstrates that using a best-matching trajectory approach significantly improves the performance of the model.
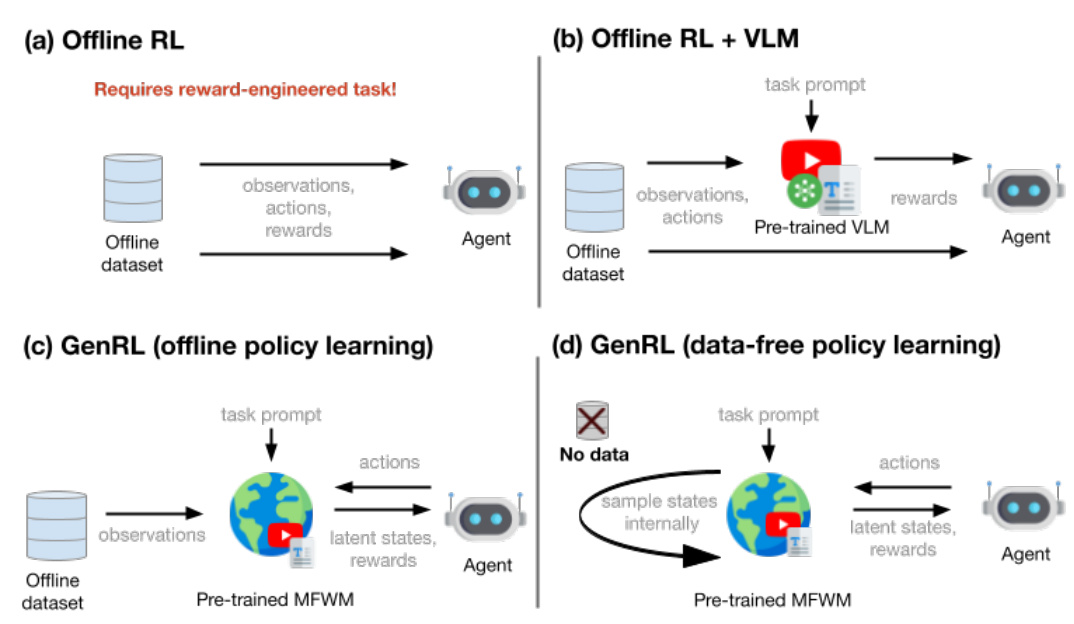
This figure illustrates the GenRL framework. It shows how the agent learns a multimodal-foundation world model by connecting and aligning the representation of a foundation Vision-Language Model (VLM) with the latent states of a generative world model. Panel (a) depicts the connection and alignment process, while panel (b) shows how the model embeds a task prompt and translates it into targets within the latent dynamics space, enabling the agent to learn the corresponding behaviors through reinforcement learning in imagination.

This figure shows the results of decoding language prompts in the Minecraft environment using GenRL with two different model sizes (1x and 8x). The images represent the model’s interpretation of the prompts, illustrating its ability to generate corresponding visual representations for different biomes. This showcases GenRL’s capacity for grounding language into the target environment’s dynamics, even with a limited dataset.
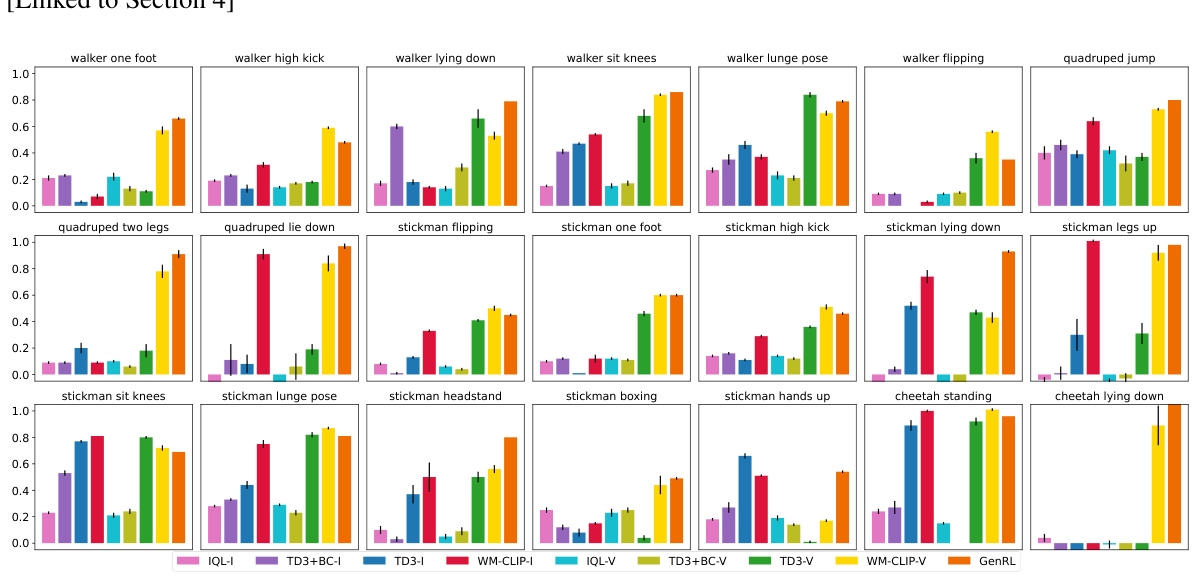
This figure presents a detailed breakdown of the multi-task generalization performance of GenRL and several baseline methods across various locomotion and manipulation tasks. Each bar represents the average episodic reward over 10 different seeds for a specific task and method. The figure allows for a granular comparison of GenRL’s performance against other offline RL approaches (IQL, TD3, TD3+BC, WM-CLIP) using both image-language (I) and video-language (V) prompts, providing insights into its generalization capabilities across different task types and input modalities.
The figure illustrates the core concept of the GenRL framework. It shows how multimodal foundation world models (MFWMs) connect and align the video-language space of a foundation model (like InternVideo2) with the latent space of a generative world model (used for reinforcement learning). Instead of relying on language annotations for task specification, GenRL uses visual and/or language prompts as input. These prompts are converted into latent targets within the world model, which the agent then learns to achieve through training within the model’s ‘imagination’. This approach eliminates the need for complex reward design and allows for generalization across various tasks.

This figure displays a detailed breakdown of the impact of training data distribution on the performance of GenRL across various tasks. It shows results for different subsets of the training data: all data, exploration data, run data, walk data, and stand data. The results are presented as bar charts, showing the average performance (likely reward or success rate) across ten seeds for each task and data subset, allowing for a comparison of the effectiveness of different training data compositions on GenRL’s ability to learn a wide range of locomotion behaviours.
More on tables

This table presents the in-distribution performance of different offline reinforcement learning methods on various locomotion and manipulation tasks. The tasks’ language prompts were included in the training dataset. Results are reported as average episodic rewards, normalized to a 0-1 range where 0 corresponds to a random policy and 1 to an expert policy. The standard error is also given.

This table presents the in-distribution performance of different offline reinforcement learning methods on various tasks. The tasks are all included in the training data, and the performance is measured by episodic reward, averaged over 10 seeds and normalized using min-max scaling (against random and expert policies). The table compares GenRL against several other baselines and shows the performance for multiple locomotion (walking, running, standing) and manipulation (kitchen tasks) using vision and/or language prompts.

The table shows the composition of the datasets used in the experiments. Each row represents a domain (walker, cheetah, quadruped, kitchen, stickman, minecraft), the total number of observations in that domain, and the number of observations in each subset of the data used for training (expl, run, walk, stand).

This table presents the results of offline reinforcement learning experiments using language prompts for tasks included in the training dataset. It compares GenRL’s performance against several baseline methods (IQL, TD3, TD3+BC, WM-CLIP) using two types of vision-language models (image-language and video-language). The scores represent the average episodic reward over 10 different runs, normalized to a range between 0 (random policy) and 1 (expert policy), allowing for easier comparison across tasks and methods. Standard errors are also provided to show the variability of the results.

This table presents the in-distribution performance results of different offline reinforcement learning methods on various locomotion and manipulation tasks. The tasks are all included in the training dataset, and the performance is measured by episodic rewards. The scores are averaged over 10 seeds and normalized using min-max scaling, where the minimum score corresponds to a random policy and the maximum score corresponds to an expert policy. The table allows for comparing the effectiveness of different reward design approaches (using image-language, video-language VLMs or GenRL’s multimodal foundation model) and offline RL algorithms (IQL, TD3+BC, TD3, and WM-CLIP).
Full paper#