↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world datasets consist of multiple interconnected tables, unlike the single-table focus of most existing synthetic data generation methods. Generating realistic synthetic data for such multi-relational databases is challenging due to the complexity of capturing intricate dependencies across multiple tables and the need for scalability to handle large datasets. Existing techniques often struggle with these challenges, leading to synthetic data that is less realistic or suffers from scalability issues.
ClavaDDPM, a novel approach, tackles these challenges by using cluster-guided diffusion probabilistic models. It leverages clustering labels to model relationships between tables, effectively capturing long-range dependencies. Experimental results demonstrate that ClavaDDPM significantly outperforms existing methods on multi-table datasets while maintaining competitive performance on single-table data. The authors also introduce a new metric focusing on long-range dependencies to better evaluate synthetic data quality for multi-relational datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to synthesizing multi-relational data, a significant challenge in many real-world applications. The proposed method, ClavaDDPM, addresses limitations of existing methods by effectively capturing long-range dependencies across multiple tables. This opens up new avenues for research in synthetic data generation and its applications, particularly in fields with complex, interconnected datasets.
Visual Insights#
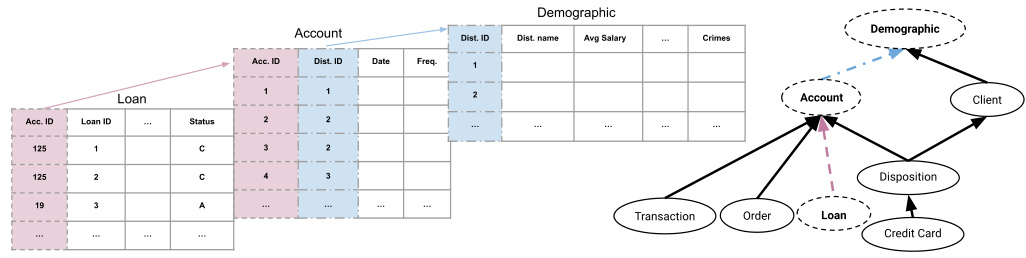
This figure shows two sample tables from the Berka dataset, ‘Loan’ and ‘Account’, illustrating the relationship between them through a foreign key constraint. The left side displays the tables’ structure with their respective attributes and sample data. The right side illustrates the foreign key relationships between tables in the Berka dataset as a graph, where nodes represent tables and edges represent foreign key constraints. This graph visualization helps understand the multi-relational structure of the dataset.
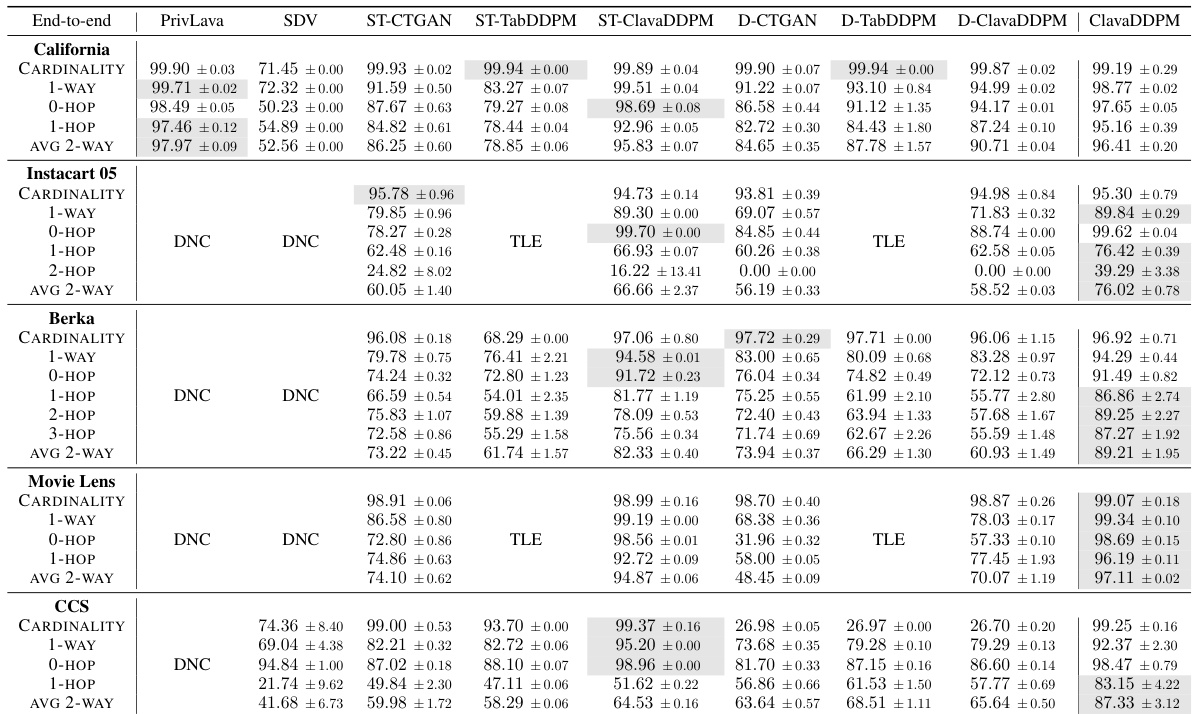
This table presents the end-to-end evaluation results of ClavaDDPM and several baseline models on five real-world multi-relational datasets. It shows the performance of each method across various metrics including cardinality, column-wise density estimation, pair-wise column correlations (at various hops), and an average of these correlations. The results demonstrate ClavaDDPM’s overall superiority, particularly in capturing long-range dependencies. Abbreviations such as DNC (Did Not Converge) and TLE (Time Limit Exceeded) are also explained.
In-depth insights#
Multi-Relational Synthesis#
Multi-relational data synthesis presents a significant challenge in generating realistic synthetic datasets that accurately reflect the complexities of interconnected real-world data. Existing methods often struggle with scalability and capturing long-range dependencies across multiple tables. The core problem lies in effectively modeling relationships between tables, particularly foreign key constraints, while maintaining data fidelity and utility. A promising approach involves leveraging the strengths of diffusion models to generate data conditioned on these relationships. The key idea is to use latent variables to represent the relationships between tables as intermediaries, allowing the model to capture intricate correlations. This approach may be more robust in handling datasets with multiple parent-child relationships, a common characteristic of complex databases. Effective algorithms are crucial for propagating latent variables across tables and efficiently managing the resulting high-dimensional data. Careful consideration of the challenges posed by multi-parent relationships is critical for developing practical methods. Evaluation metrics should incorporate assessment of both local and long-range relationships to assess the overall data quality. This presents an active area of research with substantial potential impact on diverse applications.
ClavaDDPM Model#
The ClavaDDPM model is a novel approach to multi-relational data synthesis that leverages the strengths of diffusion models while addressing their limitations in handling complex, multi-table datasets. Its core innovation lies in using clustering labels as intermediaries to model relationships between tables, specifically focusing on foreign key constraints. This approach enables ClavaDDPM to effectively capture long-range dependencies between attributes across different tables, which is a significant improvement over existing methods. By incorporating efficient algorithms to propagate learned latent variables across tables, ClavaDDPM achieves scalability for larger datasets that has been an issue for other multi-relational synthesis models. The model’s effectiveness is demonstrated through extensive evaluations on diverse multi-table datasets, showing significant outperformance of existing methods in capturing long-range dependencies while remaining competitive on single-table utility metrics. Relationship-aware clustering and controlled generation capabilities within the diffusion framework are key components enabling this performance.
Cluster-guided DDPM#
The proposed method, Cluster-guided DDPM, presents a novel approach to multi-relational data synthesis by integrating clustering techniques with Denoising Diffusion Probabilistic Models (DDPMs). The core idea is to leverage clustering labels as intermediaries to effectively model complex relationships between tables, particularly focusing on foreign key constraints. This strategy addresses limitations of existing methods in scaling to larger datasets and capturing long-range dependencies across multiple tables. By employing clustering, the model efficiently propagates learned latent variables across tables, enabling the capture of intricate correlations. This approach combines the robust generation capabilities of diffusion models with the efficiency of clustering algorithms. The resulting framework significantly improves the synthesis of data with long-range dependencies while maintaining competitive performance on standard single-table metrics. The innovative use of clustering as a bridge between tables is a key contribution, offering a notable advancement in multi-relational data synthesis.
Experimental Results#
The ‘Experimental Results’ section of a research paper is crucial for demonstrating the validity and impact of the study’s claims. A strong section will present results clearly and concisely, using appropriate visualizations like graphs and tables. Statistical significance should be explicitly stated, accompanied by error bars or confidence intervals to showcase the reliability of findings. The discussion should compare results against existing benchmarks or baselines, highlighting any significant improvements or novel contributions. A thoughtful analysis of results, going beyond simply reporting numbers, is vital; exploring unexpected results, limitations, and potential biases are all part of a thorough evaluation. The overall presentation should be well-organized and easy to follow, building a compelling narrative that supports the paper’s core argument. Reproducibility is paramount—sufficient detail on data, methods, and parameters must be included to allow others to replicate the study. Ultimately, the goal is to demonstrate that the research has produced meaningful, credible, and impactful findings.
Future Work#
The ‘Future Work’ section of this research paper on ClavaDDPM, a multi-relational data synthesis model, presents several promising avenues. Extending ClavaDDPM to handle more complex relational structures and data types beyond foreign keys is crucial. The model’s current assumptions could be relaxed, allowing for a more robust and widely applicable approach. Investigating different latent variable modeling techniques, potentially beyond Gaussian Mixture Models, would be beneficial. Furthermore, exploring the trade-off between data utility and privacy is vital, especially given the application of ClavaDDPM to sensitive data. Finally, the authors rightly suggest a focus on evaluating fairness and bias in the generated data, ensuring that ClavaDDPM doesn’t perpetuate existing biases. Addressing these research areas would significantly enhance the model’s capabilities and real-world applicability.
More visual insights#
More on figures
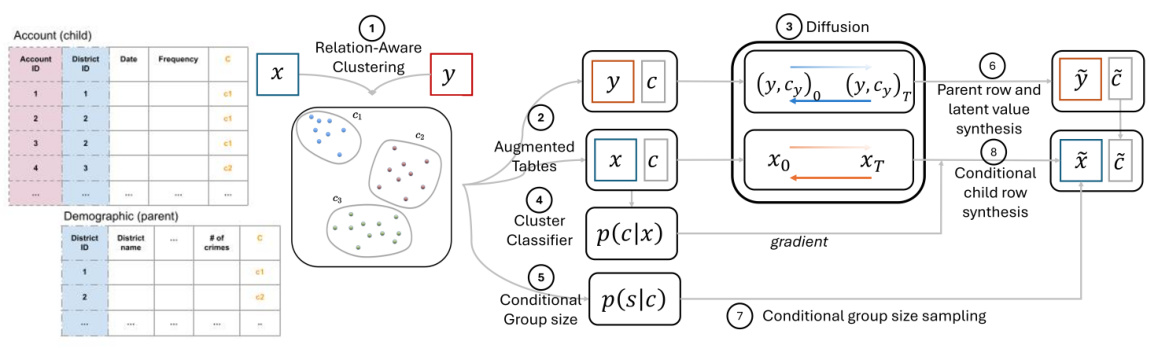
This figure illustrates the ClavaDDPM process for a two-table relational database. It starts with relation-aware clustering to model relationships between the child and parent tables. Augmented tables are created by incorporating latent variables from the clustering. A cluster classifier and a conditional group size distribution are used to model the relationship between the latent variables and child table rows. The diffusion process synthesizes both parent rows and child rows. The final output is the generation of synthetic data for both tables.
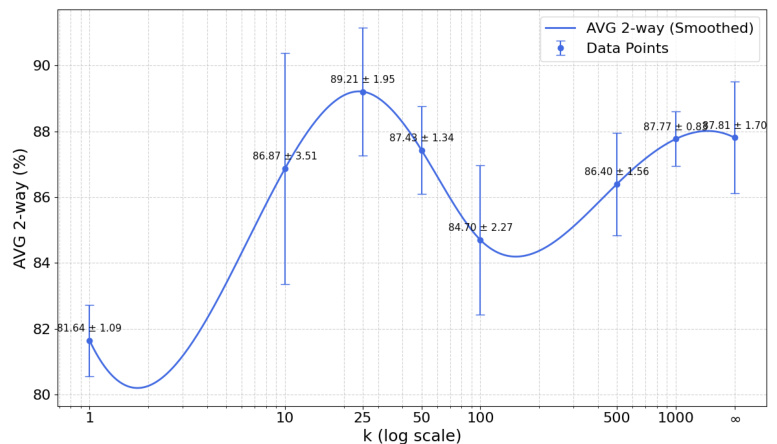
This figure displays the results of an ablation study on the number of clusters (k) used in the ClavaDDPM model. The x-axis represents the number of clusters (k) on a logarithmic scale, ranging from 1 to infinity (where each row is assigned a unique cluster). The y-axis shows the average 2-way correlation, a metric used to assess the quality of the synthetic data generated by the model. The blue line represents a smoothed version of the data points, which provides a better visualization of the trend. The error bars indicate the standard deviation of the results. This plot helps illustrate the optimal number of clusters for the ClavaDDPM model based on maximizing the average 2-way correlation.

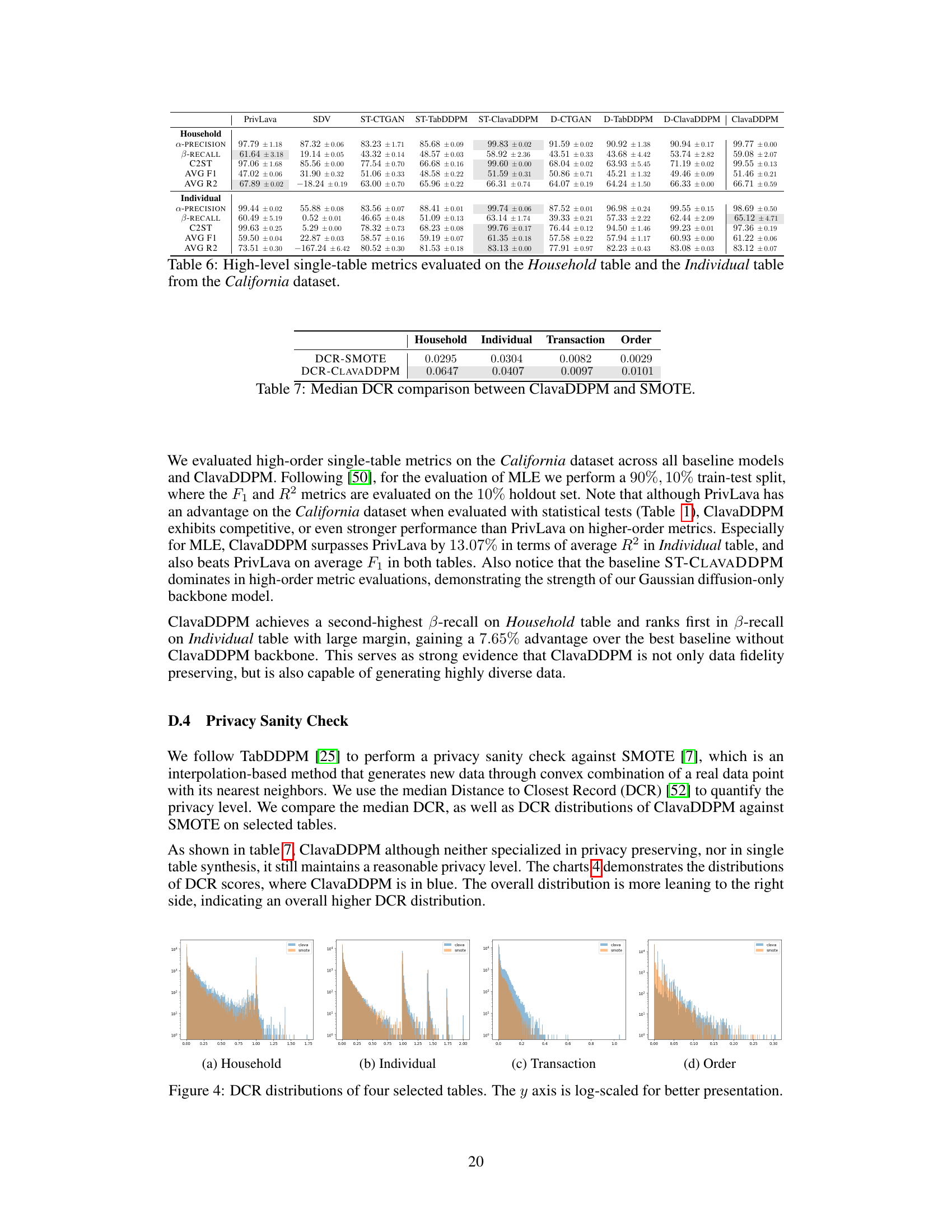
This figure shows the distribution of the Distance to Closest Record (DCR) for four tables (Household, Individual, Transaction, Order) from the California dataset. The distributions are compared for ClavaDDPM (blue) and SMOTE (orange), illustrating the privacy properties of the synthetic data generated by each method. A higher DCR value indicates better privacy, and this figure helps to visualize the differences in privacy preservation between the two methods.
More on tables

This table presents the end-to-end evaluation results of ClavaDDPM and several baseline models on five real-world multi-relational datasets. The evaluation metrics used include cardinality, column-wise density estimation (1-way), pair-wise column correlation (k-hop), and average 2-way correlation. The results show the performance of each model in terms of capturing both single-table data characteristics and multi-table relationships (long-range dependencies). DNC and TLE indicate that some baselines did not converge or exceeded the time limit.

This table presents the end-to-end evaluation results of ClavaDDPM and its baselines on five real-world multi-relational datasets. It shows the performance of each method across various metrics: cardinality, column-wise density estimation (1-way), pair-wise column correlation (k-hop), and average 2-way correlation. The results are reported as the complement of the Kolmogorov-Smirnov (KS) statistic and total variation (TV) distance, which range from 0 (worst) to 1 (best). The table also indicates cases where methods did not converge (DNC) or exceeded the time limit (TLE).

This table compares the performance of ClavaDDPM against several baseline models on five real-world multi-relational datasets. The models are evaluated using metrics such as cardinality, column-wise density estimation, pair-wise column correlations, and average 2-way correlation. The results show ClavaDDPM’s overall superiority in correlation modeling, particularly for long-range dependencies, while remaining competitive in other metrics.

This table presents the characteristics of five real-world multi-relational datasets used in the paper’s evaluation. For each dataset, it lists the number of tables, the number of foreign key pairs, the maximum depth of the relationship graph, the total number of attributes, and the number of rows in the largest table. These datasets vary significantly in size and complexity, allowing for a comprehensive evaluation of ClavaDDPM’s performance across diverse scenarios.

This table shows the hyperparameters used for ClavaDDPM on each of the five datasets used in the paper’s evaluation. The hyperparameters include the number of clusters (k), the parent scale (λ), and the classifier scale (η). These parameters were chosen based on empirical observations and are detailed in Appendix C.3.2 of the paper.

This table presents the end-to-end evaluation results of ClavaDDPM and several baseline models on five real-world multi-relational datasets. It compares the performance using both single-table and multi-table utility metrics. The metrics include cardinality, column-wise density estimation, pair-wise column correlation (at varying hops), and average 2-way correlation, which is an average of all k-hop column-pair correlations. Results are averaged over three randomly generated synthetic datasets. Abbreviations include DNC (Did Not Converge) and TLE (Time Limit Exceeded), while ST represents Single-Table and D represents Denorm.

This table presents a comparison of the median Distance to Closest Record (DCR) between ClavaDDPM and SMOTE, across four different tables from the California dataset. The DCR metric is used as a measure of privacy. Lower values indicate better privacy.
Full paper#