↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
IoT sensing models often suffer from overfitting due to data distribution shifts between training and real-world data. Traditional data augmentation methods using manual transformations are limited, often failing to capture the nuanced features of real-world IoT signal variance. Generative models offer a potential solution, but existing methods lack fine-grained control, treating them as ‘black boxes’.
This research presents a novel framework that addresses these limitations. It uses domain expertise to extract key statistical metrics from IoT sensing signals and generates new data within a defined ‘metric space’. This approach allows for fine-grained control over the generative process, enabling creation of synthetic data that more accurately reflects real-world variations and significantly outperforms existing methods in several IoT sensing tasks.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in IoT sensing and data augmentation. It addresses the critical issue of domain shift in IoT data, which often hinders the robustness of models. The proposed approach of fine-grained control over generative data augmentation, using a defined metric space, offers a significant advancement in addressing this challenge. This opens new avenues for creating more realistic and diverse synthetic data, thereby improving the performance and reliability of various IoT applications. It also provides a valuable framework for incorporating domain knowledge into data augmentation, which can be widely adopted in other research fields that face similar challenges.
Visual Insights#
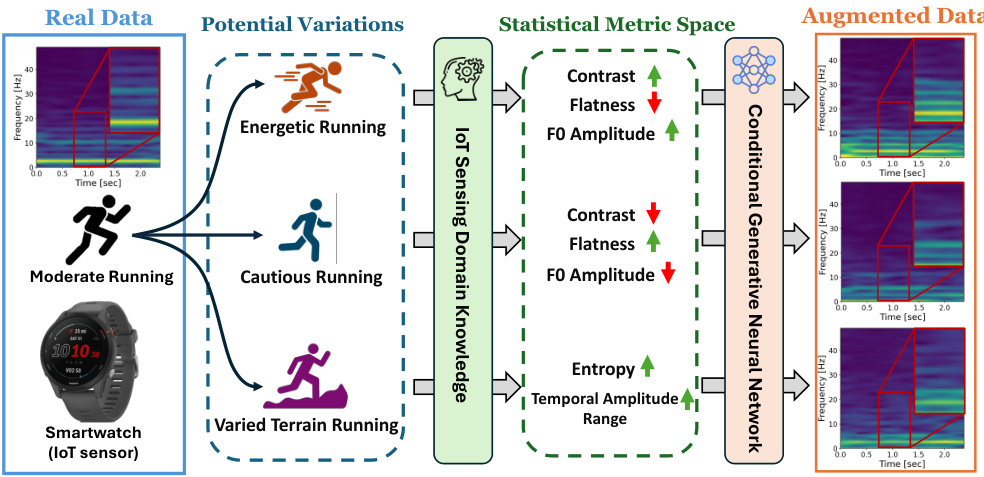
This figure illustrates the proposed data augmentation method. It shows how domain knowledge about variations in running styles (energetic, moderate, cautious, varied terrain) is used to define a statistical metric space. This metric space captures key characteristics (contrast, flatness, fundamental frequency amplitude, entropy, temporal amplitude range) of the signals’ spectrograms. These metrics are then used to guide a conditional generative neural network to create augmented data that reflects the variations in running styles. The augmented data enriches the diversity of the original dataset by adding realistic variations.
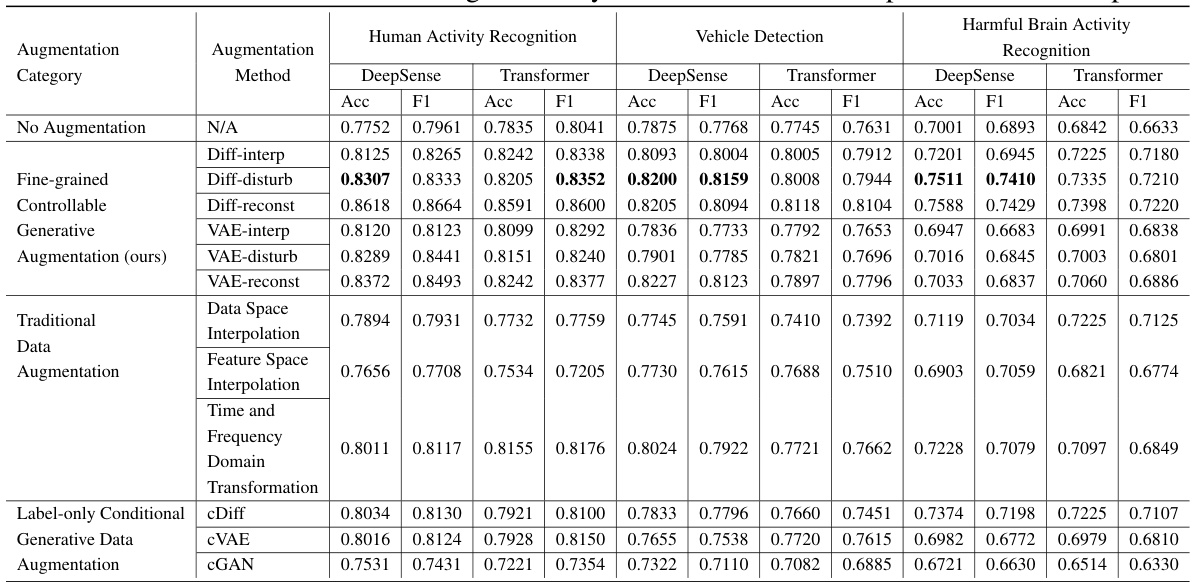
This table presents the average accuracy and F1-score achieved by different data augmentation methods across three IoT sensing applications (Human Activity Recognition, Vehicle Detection, and Harmful Brain Activity Recognition). Two downstream models (DeepSense and Transformer) were used for each application. The methods are categorized into three groups: No Augmentation, Fine-grained Controllable Generative Augmentation (the proposed method), and Traditional Data Augmentation. The results show the performance improvement obtained by using the proposed method compared to traditional methods and label-only conditional generative models.
In-depth insights#
IoT Sensing Augmentation#
IoT sensing augmentation is a crucial technique to enhance the robustness and generalizability of IoT sensing models by addressing data scarcity and distribution shifts. Traditional methods often rely on simple transformations, lacking the capacity to capture nuanced data variations. Generative models offer a powerful alternative by synthesizing new, realistic data samples. However, existing generative approaches often treat the model as a black box, lacking fine-grained control. This research proposes a novel paradigm that combines domain expertise with generative models to create fine-grained control over the data augmentation process. By defining a metric space based on statistical metrics of sensing signals, the method enables precise manipulation of data characteristics, achieving significantly improved downstream model performance compared to traditional or label-only conditional generative approaches. The approach’s versatility is demonstrated across diverse datasets and tasks, highlighting its potential to revolutionize IoT sensing model development.
Generative Model Control#
Generative model control, in the context of data augmentation for IoT sensing, presents a crucial challenge and opportunity. The goal is to move beyond simple, label-conditioned generation towards a more nuanced approach where domain expertise can guide the creation of synthetic data. This involves defining a “metric space” that captures essential signal characteristics, enabling precise control over the generative process. Instead of treating generative models as black boxes, this method leverages domain knowledge to specify desired signal variations within this metric space. This is a significant advancement over traditional methods and previous generative approaches which either fail to capture nuanced signal characteristics or rely on overly simplistic transformations. The use of a well-defined metric space is key here, ensuring both authenticity and controllability. Fine-grained control enables the creation of synthetic data reflecting plausible real-world variations, improving model robustness against domain shifts. This approach demonstrates the potential to substantially enhance model performance in various IoT sensing applications.
Metric Space Design#
The concept of a ‘Metric Space Design’ within the context of a research paper on generative data augmentation for IoT sensing signals is crucial. It suggests a paradigm shift from traditional, rule-based augmentation to a more sophisticated, controlled approach. The core idea is to define a mathematical space where the essential characteristics of IoT signals (often represented as spectrograms) are captured using a set of carefully selected metrics. These metrics might include time-domain features (e.g., amplitude range), frequency-domain features (e.g., fundamental frequency), and time-frequency domain features (e.g., contrast, entropy). The strength of this approach lies in its fine-grained control. By manipulating these metrics, researchers can generate synthetic signals with specific, desired characteristics, resulting in more realistic and relevant data augmentation. This method allows researchers to explicitly incorporate domain knowledge which is otherwise difficult to integrate into traditional augmentation techniques. Furthermore, this controlled environment offers better interpretability compared to black-box generative models. However, a careful consideration is needed in choosing which metrics to include, as this directly influences the quality and relevance of the generated data. The selection process might involve extensive domain expertise and possibly even rigorous statistical analysis to ensure the chosen metrics adequately capture the essential information present in the actual signals.
Domain Knowledge Use#
The paper cleverly leverages domain knowledge, not as a simple input but as a fine-grained control mechanism over the generative data augmentation process. Instead of relying solely on inherent labels, the authors introduce a metric space defined by statistical metrics extracted from IoT sensing signals. These metrics, derived from domain expertise, capture essential signal features in time, frequency, and time-frequency domains, offering human-interpretable control. The generative model is then conditioned on these metrics, enabling targeted data augmentation to enhance model robustness in specific applications. This approach moves beyond black-box generative models by incorporating domain knowledge directly to steer the generation process, resulting in more authentic and relevant synthetic data. The paper showcases the effectiveness of this approach by significantly outperforming prior methods across three diverse IoT sensing tasks.
Future Research#
Future research directions stemming from this work on fine-grained control of generative data augmentation in IoT sensing could focus on several key areas. Developing more sophisticated metric spaces that capture a wider range of signal characteristics and their interactions is crucial. This might involve exploring advanced signal processing techniques and incorporating domain expertise to identify more relevant and informative metrics. Automating the metric selection process would significantly enhance the practicality and scalability of this method. Machine learning techniques could be used to learn optimal metrics for different tasks and datasets, reducing the reliance on manual selection. Investigating other generative models beyond diffusion models and VAEs is another promising direction. Exploring the efficacy of this approach in other IoT domains is essential for demonstrating its broader applicability. The method’s robustness to noisy or incomplete data needs further investigation, and techniques to improve its resilience should be developed. Finally, assessing the impact of augmented data on the fairness and robustness of IoT models is vital, particularly considering that augmentations might introduce biases related to specific features or conditions.
More visual insights#
More on figures
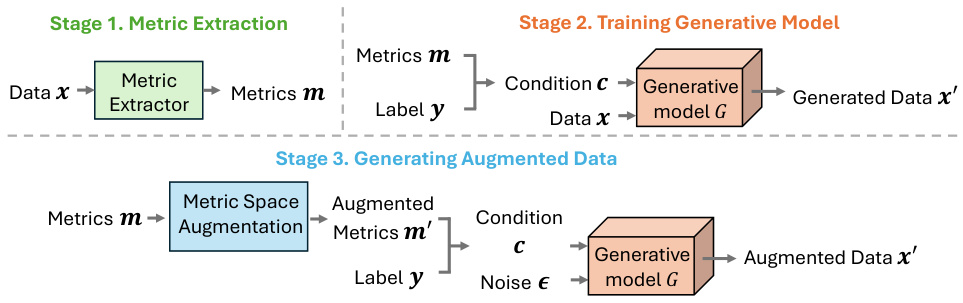
This figure illustrates the three stages of the proposed fine-grained controllable generative data augmentation method. Stage 1 extracts statistical metrics from the input data. Stage 2 trains a generative model conditioned on these metrics and the data label. Stage 3 uses the trained model to generate new data samples by manipulating the extracted metrics within a defined ‘metric space’, allowing for fine-grained control over the data augmentation process.

This figure illustrates the three data augmentation techniques used in the paper. The interpolation method generates new data points between existing data points. The disturbance method adds noise to the existing data points. The domain knowledge instruction method uses domain-specific knowledge to guide the generation of new data points. The figure shows how each method affects the distribution of data points in the metric space. The goal is to generate new data points that are both realistic and diverse.

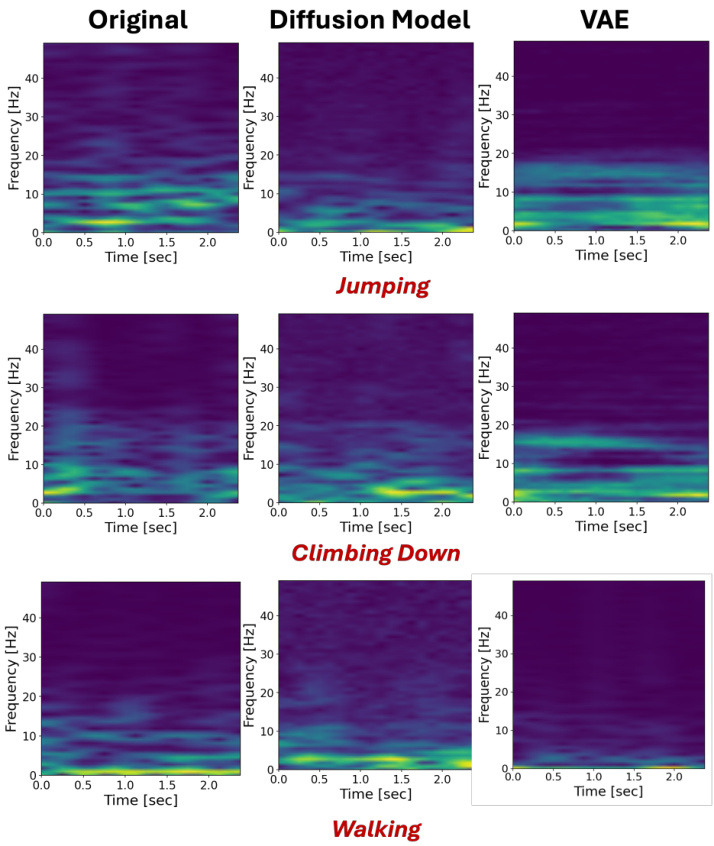
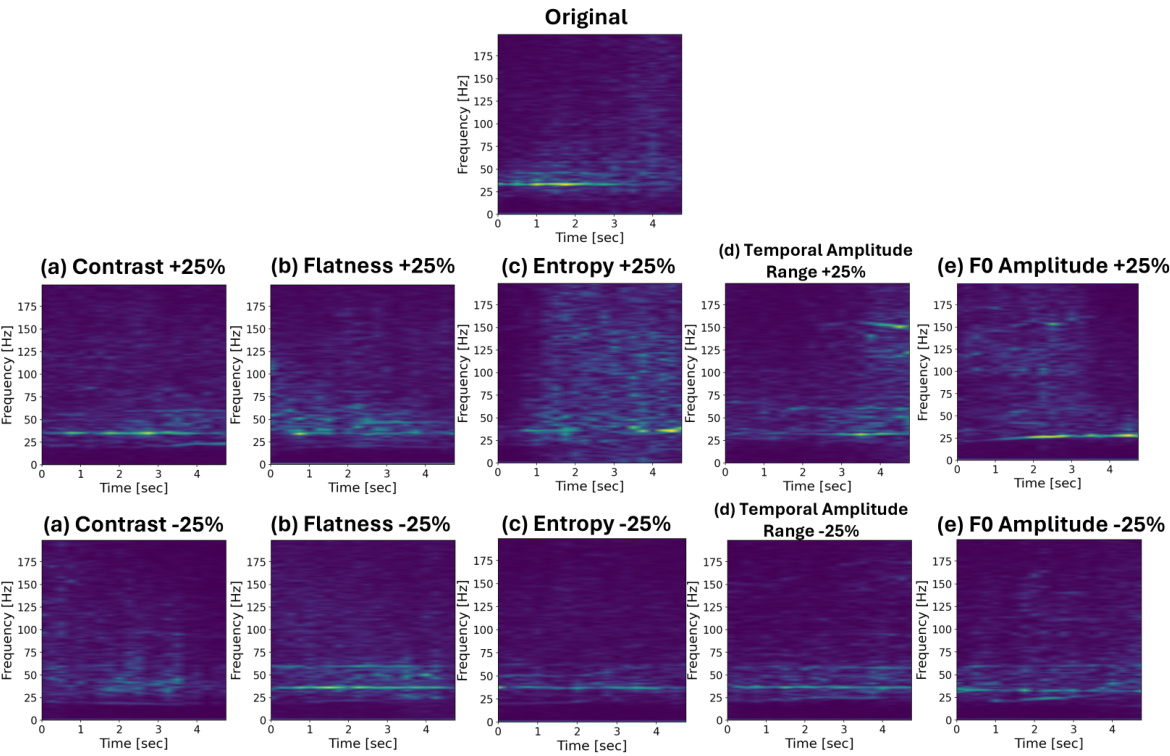
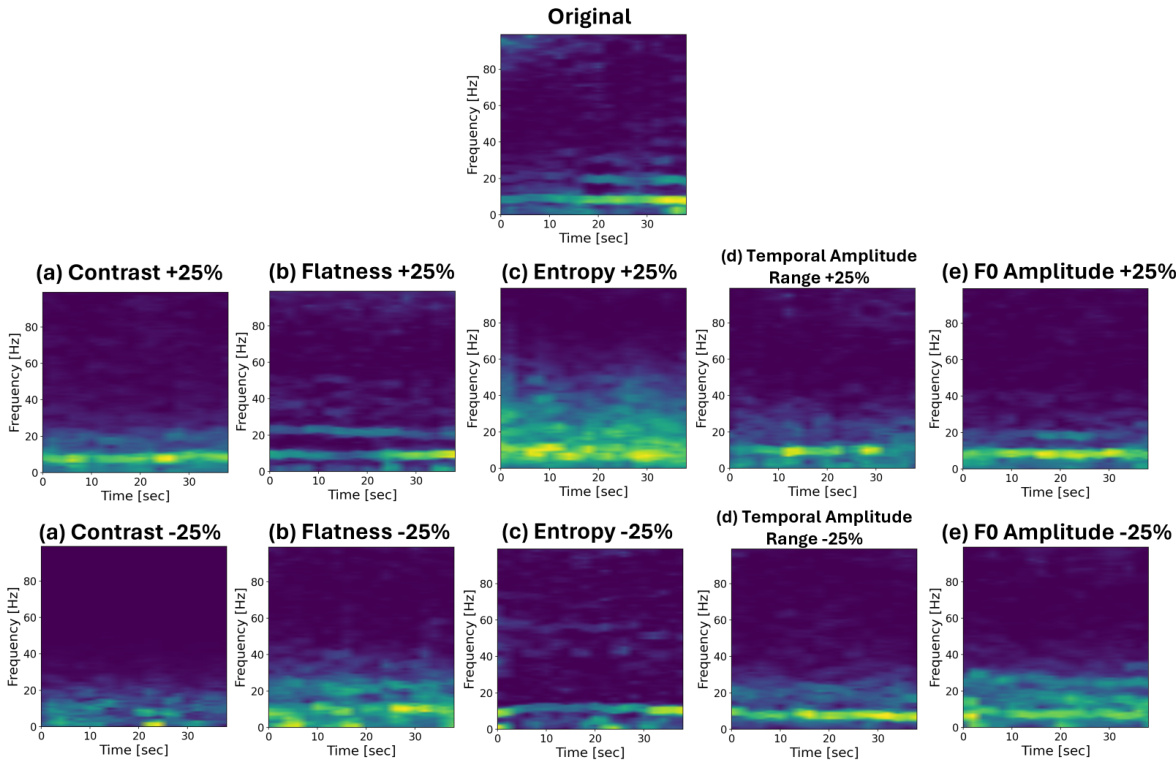
This figure visualizes the effects of manipulating individual metrics on the generated accelerometer spectrograms. Each subfigure shows how changing a specific metric (contrast, flatness, entropy, temporal amplitude range, or F0 amplitude) affects the resulting spectrogram, while keeping other metrics constant. The figure demonstrates the fine-grained control over the generation process enabled by the proposed method.

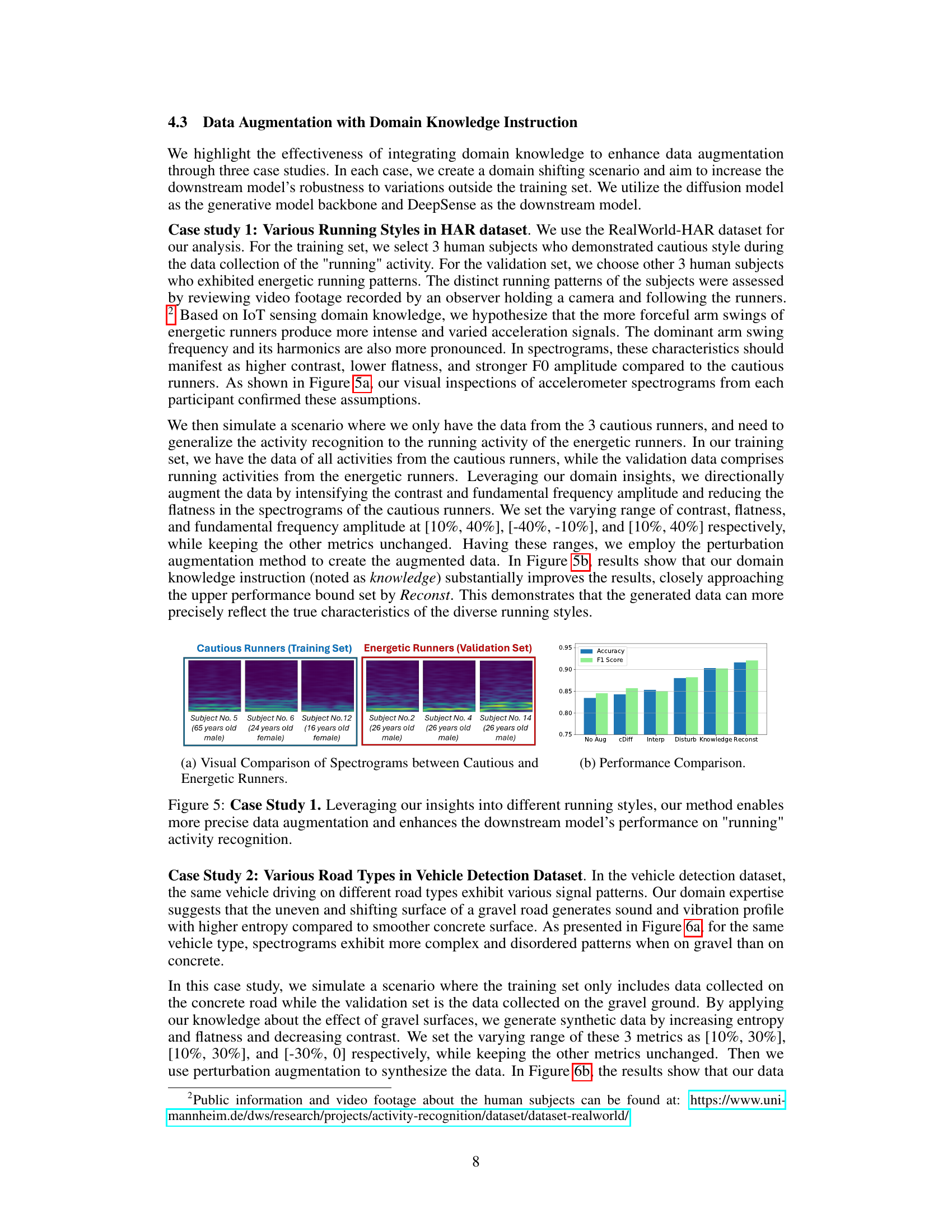
This figure shows the results of a case study on human activity recognition using the proposed data augmentation method. The left panel displays spectrograms from three subjects who exhibited a ‘cautious’ running style during data collection, while the right panel shows spectrograms from three subjects with an ’energetic’ running style. The bar chart in the right panel shows the performance of different data augmentation methods on the task of classifying these running styles. The results demonstrate that the proposed method (Knowledge), which leverages domain knowledge, significantly improves the performance of the downstream model compared to other methods.
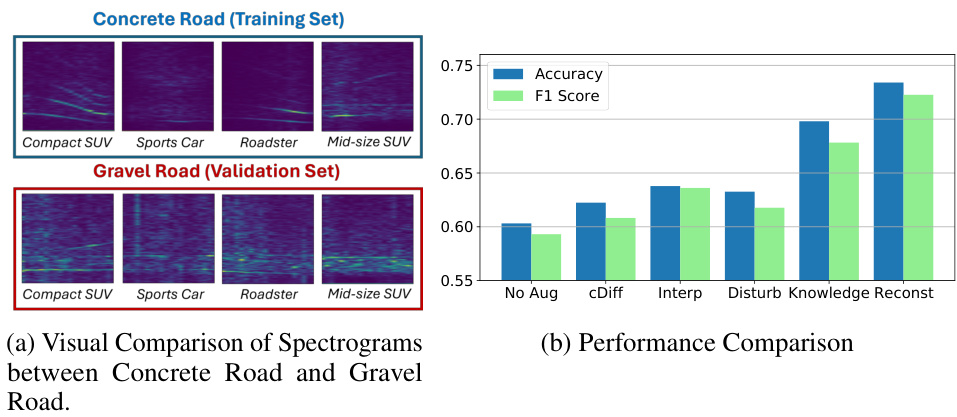
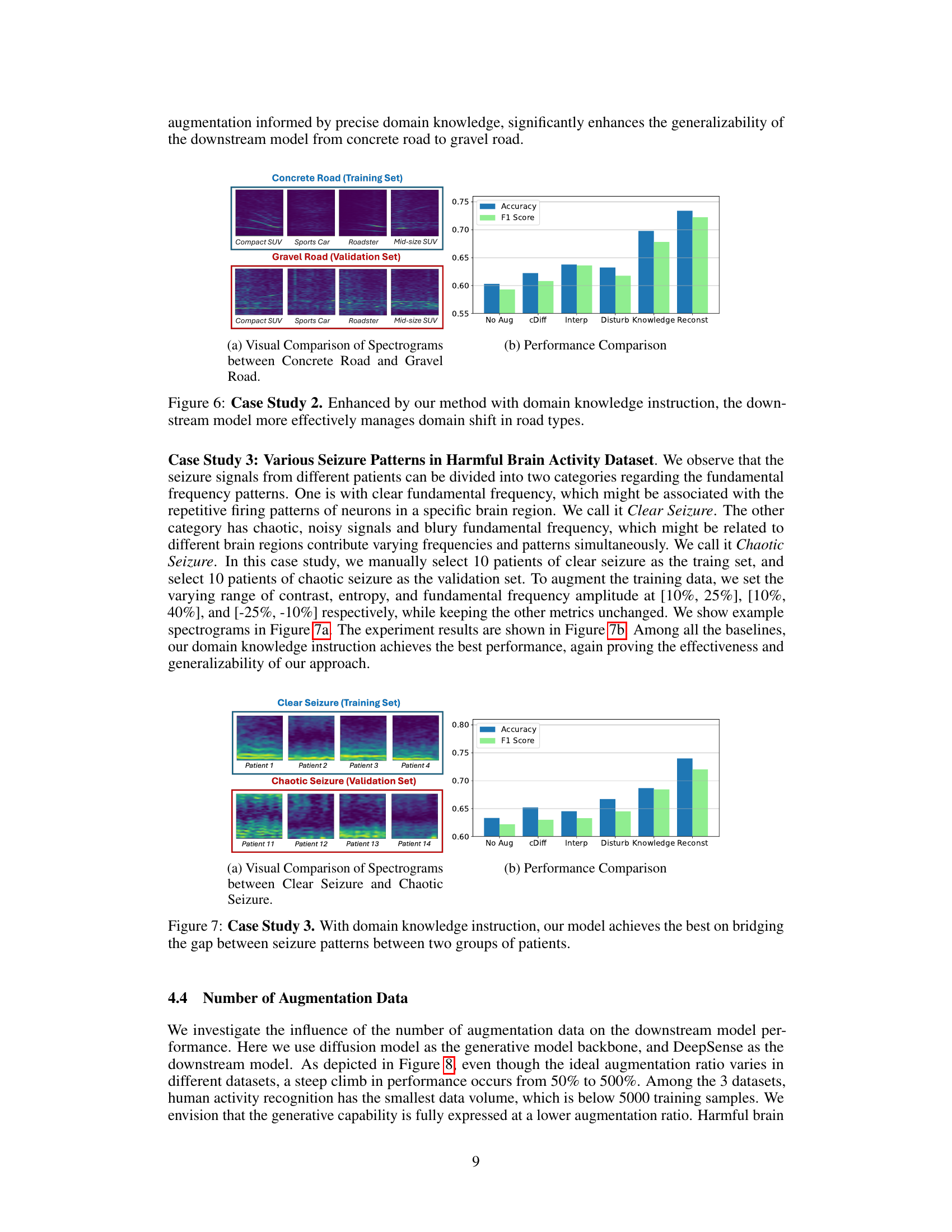
This figure shows the results of Case Study 2 in the paper, which investigates the impact of domain knowledge instruction on vehicle detection using data collected on different road types (concrete vs. gravel). The left panel (a) presents a visual comparison of spectrograms from different vehicle types on both surfaces, highlighting the differences in signal patterns. The right panel (b) shows a performance comparison of different data augmentation methods (including the proposed method) in terms of accuracy and F1-score on the downstream model. The results demonstrate that incorporating domain knowledge into the data augmentation process significantly improves the model’s ability to handle domain shifts.

This figure shows the results of applying the proposed data augmentation method to the human activity recognition task using the RealWorld-HAR dataset. The study focuses on the ‘running’ activity, specifically comparing different running styles (cautious vs. energetic). The visual comparison (Figure 5a) shows spectrograms from both types of runners to illustrate how the different running styles impact the signal. The performance comparison (Figure 5b) presents a bar chart comparing the accuracy and F1 score of various methods, highlighting the superior performance achieved using domain knowledge instructions in the data augmentation process.

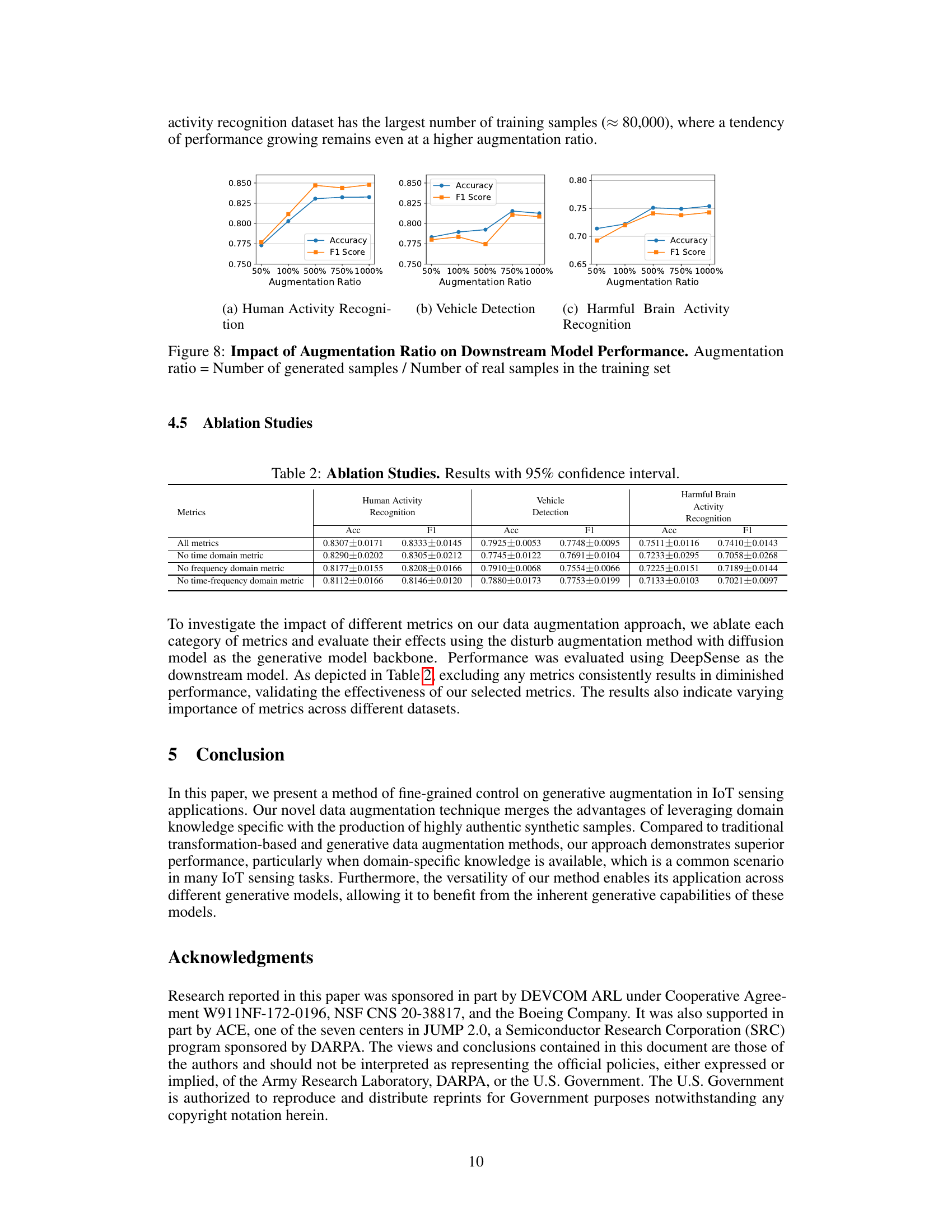
This figure visualizes the effect of varying augmentation ratios on the performance of downstream models for three different IoT sensing applications: Human Activity Recognition, Vehicle Detection, and Harmful Brain Activity Recognition. The x-axis represents the augmentation ratio (the number of generated samples divided by the number of real samples in the training set). The y-axis shows the accuracy and F1 score achieved by the DeepSense and Transformer models. The figure demonstrates the impact of using augmented data generated by the proposed fine-grained controllable generative augmentation method. The results show that increasing the augmentation ratio generally improves performance, but the optimal ratio varies depending on the application and the specific model.

This figure demonstrates an example of how the proposed method works. It uses running data as an example and shows how domain knowledge about different running styles can be used to guide the generation of synthetic data that enrich the diversity of the original dataset. The figure showcases three different types of running: Energetic Running, Moderate Running, and Cautious Running. It highlights how the proposed method uses statistical metrics derived from the spectrograms of running signals to capture the essential features and enables fine-grained control over the generation process of augmented data.
This figure shows an example of how the proposed method works. It starts with real data from a moderate running activity recorded by a smartwatch. Domain knowledge is used to identify potential variations in this activity (e.g., energetic running, cautious running, varied terrain). These variations are represented as changes in a defined ‘metric space’, which includes statistical metrics capturing essential features of the signals’ time-frequency characteristics. A conditional generative neural network uses these metrics to guide the generation of augmented data samples representing these variations. The augmented data enriches the diversity of the original dataset, improving the downstream IoT sensing model robustness.
This figure illustrates how domain knowledge about running signals can be used to guide the generation of augmented data using the proposed method. The figure shows how different running styles (energetic, moderate, cautious) result in different statistical metrics (contrast, flatness, F0 amplitude, etc.) in the metric space. This knowledge helps the generative model produce augmented data that reflects the variations in running styles, improving the diversity and realism of the training dataset for downstream applications. The visualization shows example STFT spectrograms for different running styles and the corresponding metrics values.
This figure illustrates an example of how the proposed method works. It shows how domain knowledge about running (e.g., energetic vs. cautious running) is translated into variations in the statistical metric space. These variations, which represent features extracted from short-time Fourier transforms (STFTs) of the signals, guide a generative model to produce new, synthetic data samples. The augmented data is more diverse than the original dataset, which should improve the robustness of IoT sensing models trained on it.
Full paper#