↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Data poisoning attacks compromise machine learning models by introducing malicious examples during training. Current defenses often struggle with generalization or are attack-specific, hindering real-world applications. This necessitates more robust and efficient defensive strategies to ensure machine learning model integrity and reliability.
PUREGEN introduces a novel approach using stochastic transformations via energy-based models and diffusion probabilistic models to purify poisoned data. By leveraging the generative models’ dynamics, PUREGEN effectively removes adversarial signals while preserving natural data characteristics. The method demonstrates state-of-the-art defense against various attacks on multiple datasets, showcasing its versatility and effectiveness. Importantly, PUREGEN requires minimal tuning and no prior knowledge of the attacks, highlighting its practical value in safeguarding machine learning systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning security, offering a novel and effective train-time defense against data poisoning attacks. It addresses limitations of existing methods by achieving state-of-the-art results with minimal overhead. The introduction of a universal, preprocessing-based purification method opens up new research avenues in generative model applications for security, and its robustness to various attacks and data shifts enhances its practical applicability.
Visual Insights#
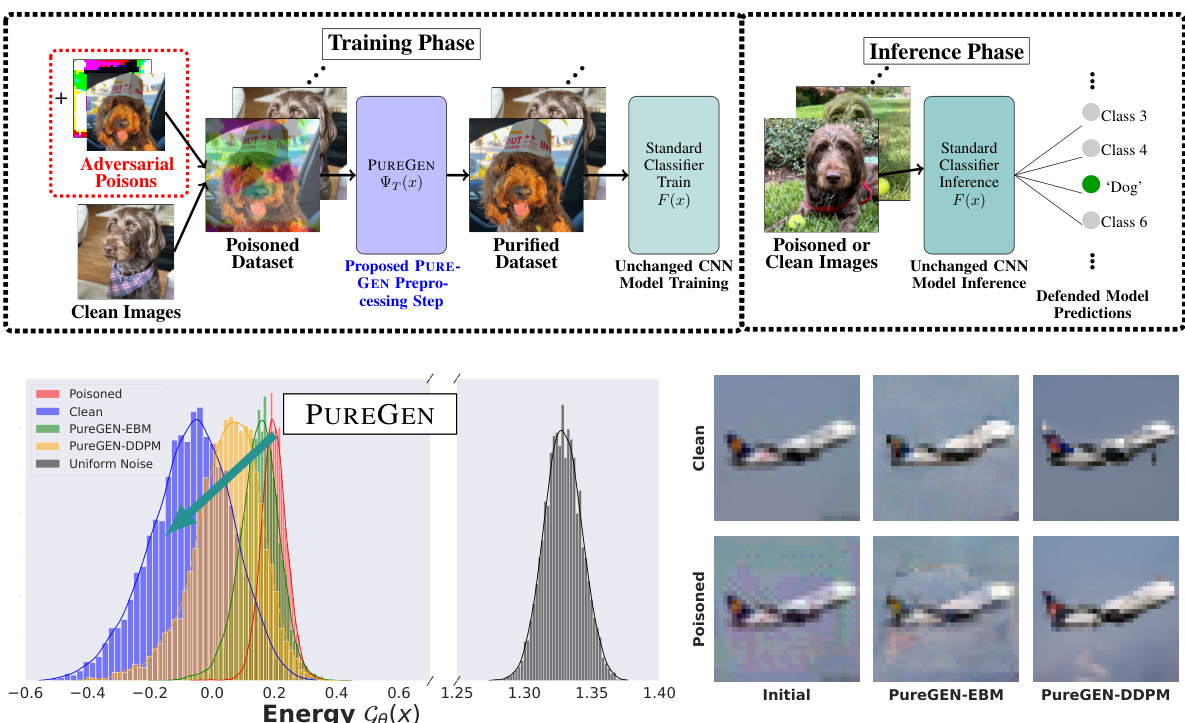
This figure illustrates the PUREGEN pipeline, showing how it’s used as a preprocessing step before standard classifier training and inference. It highlights the energy distribution differences between clean, poisoned, and purified images, demonstrating PUREGEN’s ability to move poisoned data points closer to the clean data distribution. The bottom right shows example images before and after purification, illustrating the removal of poison artifacts while maintaining image integrity.
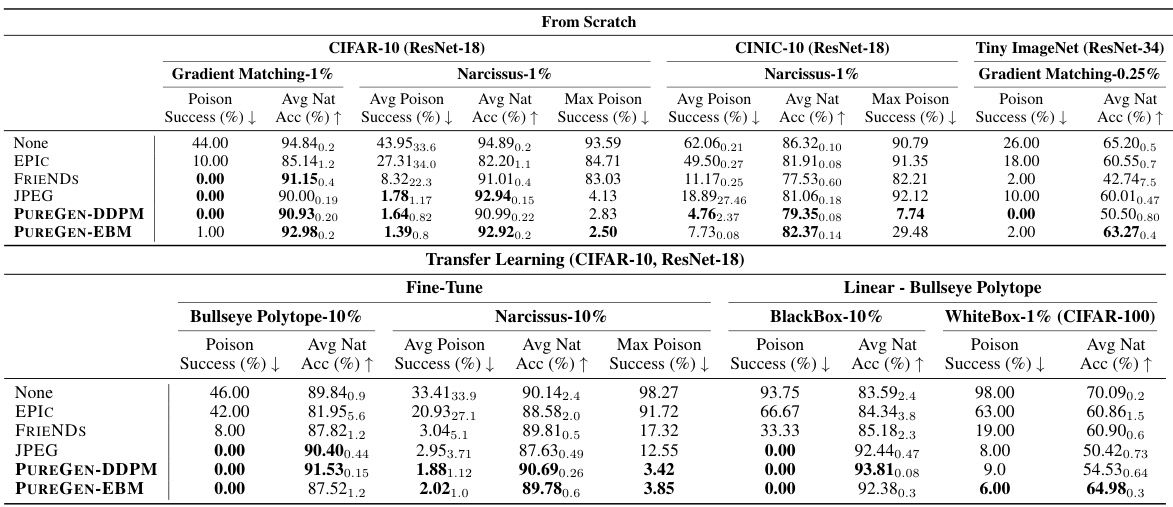
This table presents the results of poison attacks (Gradient Matching, Bullseye Polytope, and Narcissus) on ResNet-18 models trained on CIFAR-10, CINIC-10, and TinyImageNet datasets. It shows the average poison success rate (the percentage of poisoned images that caused misclassification), and the average natural accuracy (the accuracy on clean images). The table compares different defense methods, including EPIC, FRIENDS, JPEG compression, PUREGEN-DDPM, and PUREGEN-EBM, demonstrating the effectiveness of PUREGEN in mitigating data poisoning attacks. The ‘Max Poison Success’ column indicates the maximum poison success rate observed across all 10 classes for the Narcissus attack, representing the worst-case scenario.
In-depth insights#
Poison Data Purity#
The concept of “Poison Data Purity” in a machine learning context refers to the process of identifying and mitigating the impact of malicious data points (poison) introduced during the training phase of a model. Data poisoning attacks undermine the integrity and performance of machine learning models, often leading to misclassifications or backdoor vulnerabilities. Methods focusing on “Poison Data Purity” aim to purify the training data by identifying and either removing or neutralizing the adversarial examples. This often involves sophisticated techniques to distinguish between genuine and poisoned data points, while minimizing the loss of valuable information from the legitimate data. Effective data purification relies on having a thorough understanding of the poisoning attack types and utilizing techniques to reduce or eliminate the impact of poison without sacrificing model accuracy on clean data. Generative models, for example, have shown promise in identifying and correcting poisoned data points by pushing poisoned images into a more natural data distribution. The success of such methods depends on the subtlety of the poisoning attack, the effectiveness of the purification technique, and the trade-off between purity and model accuracy.
Generative Dynamics#
The concept of ‘Generative Dynamics’ in the context of a research paper likely refers to the use of generative models, such as Energy-Based Models (EBMs) or Diffusion Probabilistic Models (DDPMs), to model and manipulate data. The core idea is to leverage the inherent dynamics of these models—their ability to generate new data samples that resemble the training distribution—for a specific purpose such as data purification. This approach moves away from traditional methods, which often involve explicit filtering or robust training. The ‘dynamics’ aspect emphasizes the iterative, stochastic nature of the process, where data points are iteratively transformed or refined through MCMC or diffusion-based processes towards a desired state, often guided by an energy function or a noise schedule. Key advantages might include handling complex data distributions and achieving robustness against various attacks. However, challenges could arise from computational costs, the need for substantial training data, and potential sensitivity to hyperparameter tuning. The effectiveness and efficiency of such an approach would heavily depend on the careful design of the model architecture, training strategy, and the choice of generative model best suited to the task.
Robustness Analysis#
A robustness analysis of a data purification method for train-time poison defense would explore its resilience against various attacks and data variations. Key aspects would include evaluating performance under different poison types (targeted vs. untargeted, clean-label vs. backdoor), poison rates, and data distributions. The analysis should also consider the computational cost and the impact on the model’s generalization ability. Furthermore, a crucial evaluation would be to determine the method’s effectiveness against defense-aware attacks, which aim to adapt to the purification technique. Robustness to distributional shifts in the training data is another critical area, assessing whether the method remains effective when the model is trained on data differing from that used for purification. Finally, the analysis should investigate the method’s sensitivity to hyperparameter tuning and the level of generalization achieved across diverse datasets and models.
Defense Mechanism#
The research paper explores various defense mechanisms against train-time data poisoning attacks. A core contribution is PUREGEN, a universal data purification method leveraging generative model dynamics (EBMs and DDPMs) to cleanse poisoned data before training. This approach offers several advantages: universality (no attack-specific knowledge needed), minimal impact on model accuracy, and a reduced training overhead. The effectiveness of PUREGEN is validated against various sophisticated poisoning attacks, including Narcissus, Bullseye Polytope, and Gradient Matching, demonstrating state-of-the-art defense performance. However, the paper also discusses computational costs and data requirements of PUREGEN, highlighting a trade-off between computational efficiency and robustness. Additional experiments examine the method’s robustness against distribution shifts in training data and defense-aware poisoning attacks. Ultimately, the study’s focus on generative model dynamics for data purification represents a novel approach with considerable promise for enhancing train-time data security.
Future Directions#
Future research could explore enhancing PUREGEN’s efficiency by investigating more computationally efficient generative models or developing novel optimization techniques for the purification process. Improving robustness against more sophisticated and adaptive poisoning attacks is crucial, particularly those employing defense-aware strategies. The investigation of PUREGEN’s applicability to other data modalities beyond images, such as text and time series, would expand its practical value and impact. Understanding the theoretical limitations and developing rigorous guarantees on the purification process would strengthen the theoretical foundation of this work. Finally, extensive analysis on the trade-off between accuracy and defense performance is necessary to optimally balance the two goals for various practical scenarios. A focus on generalizability and creating a universal model that works across a wide array of datasets and classifiers is essential to achieve widespread adoption.
More visual insights#
More on figures
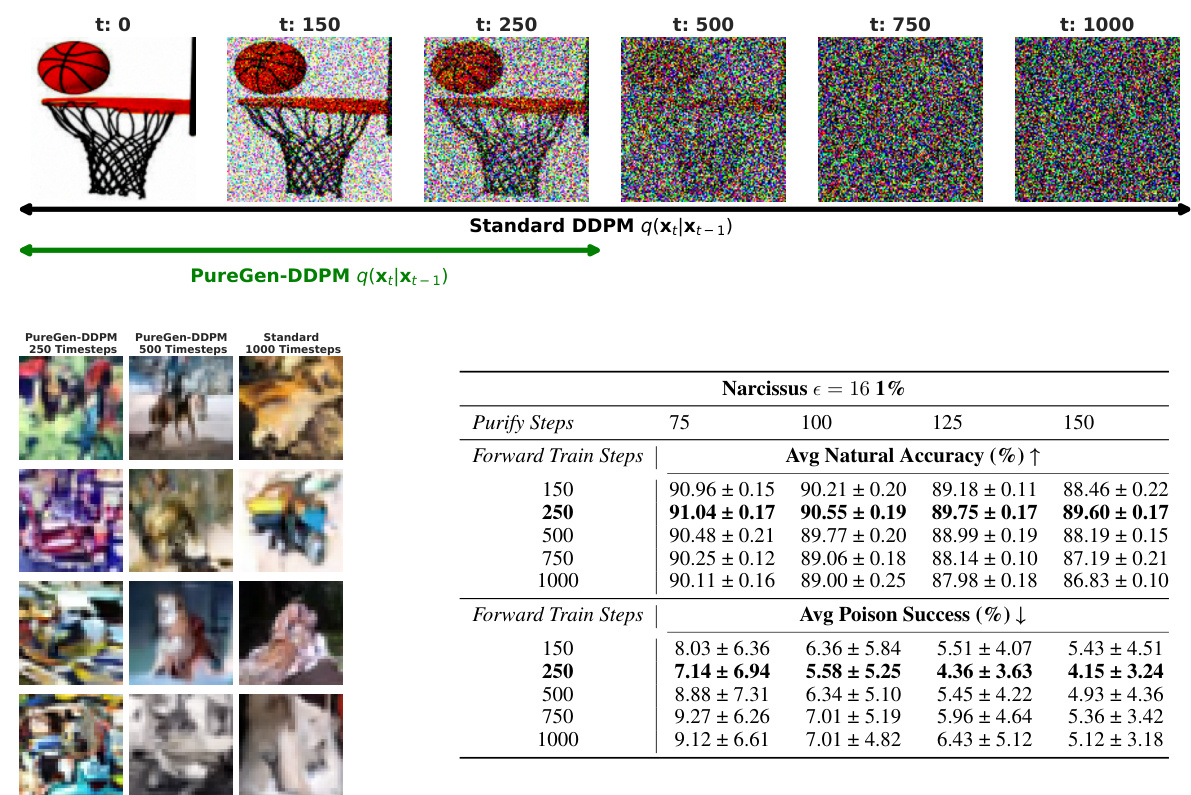
This figure shows the results of comparing PUREGEN-DDPM with the standard DDPM for image purification. The top part illustrates the forward diffusion process at different steps, showing how the image gradually degrades into noise. The bottom left shows the generated images by the models trained with different numbers of steps, highlighting that using only 250 steps in PUREGEN-DDPM, while sacrificing generative capabilities, improves purification. The bottom right provides numerical results, demonstrating that using 250 steps in PUREGEN-DDPM significantly improves poison defense performance, with minimal impact on natural accuracy.

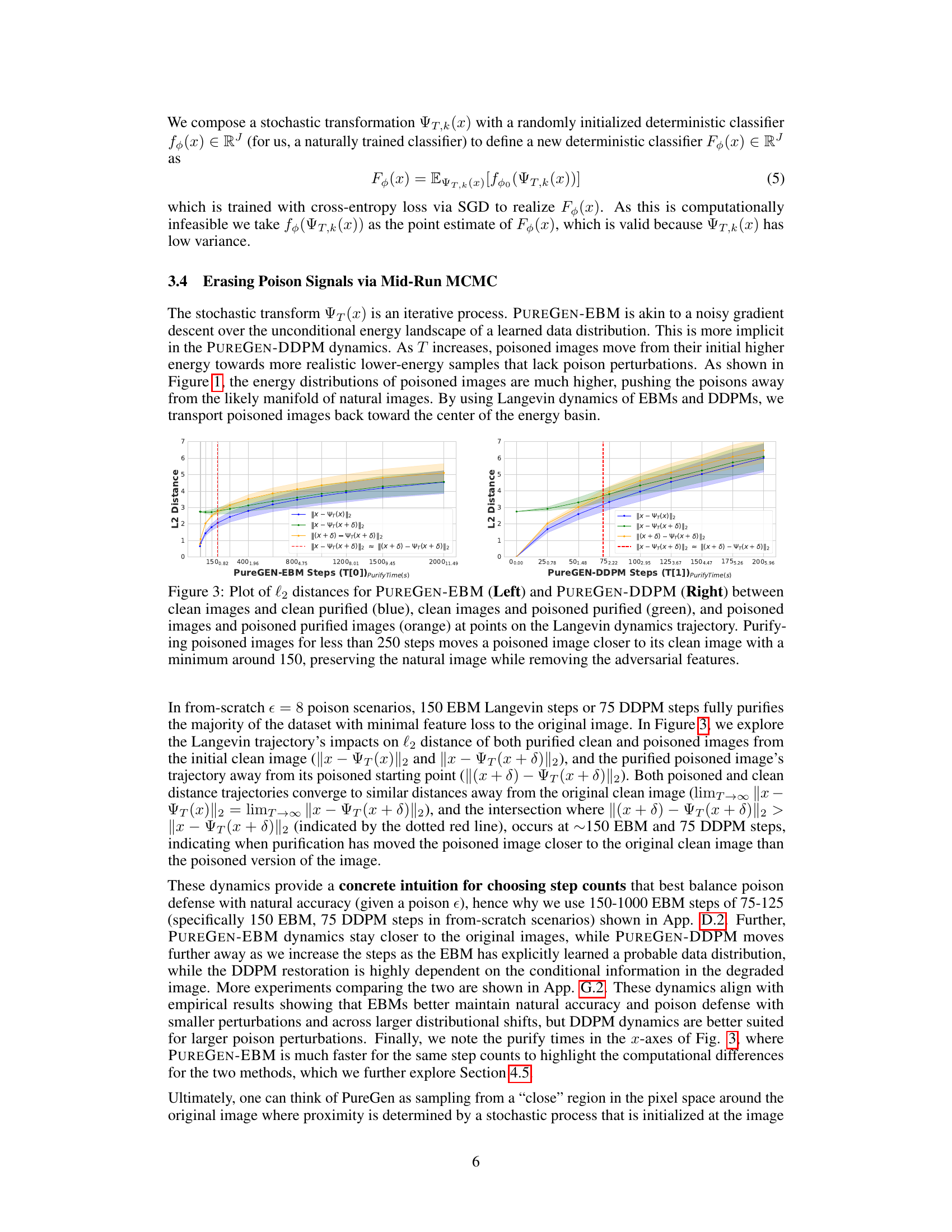
This figure shows the L2 distances between clean and poisoned images, before and after purification using PUREGEN-EBM and PUREGEN-DDPM. The x-axis represents the number of steps in the Langevin dynamics. The y-axis represents the L2 distance. The blue line represents the distance between clean images and their purified versions. The green line represents the distance between clean images and the purified versions of poisoned images. The orange line represents the distance between poisoned images and their purified versions. The red dashed line indicates the point at which the distance between a poisoned image and its purified version becomes smaller than the distance between the clean image and the purified version of the poisoned image. The figure shows that purifying poisoned images for less than 250 steps moves a poisoned image closer to its clean image, with a minimum around 150 steps. This suggests that PUREGEN-EBM and PUREGEN-DDPM are effective at removing adversarial features from poisoned images while preserving the natural image content.

This figure shows the robustness of PUREGEN-EBM and PUREGEN-DDPM to out-of-distribution training data. It plots the defended natural accuracy and poison success rate for both methods against various OOD datasets, showing that PUREGEN-EBM is more robust to distributional shift in terms of natural accuracy while both maintain state-of-the-art poison defense.

This figure illustrates the PUREGEN pipeline, showing how it’s used as a preprocessing step before standard classifier training and inference. It highlights the energy distribution differences between clean, poisoned, and purified images, demonstrating how PUREGEN pushes poisoned images towards the natural data distribution. The bottom right shows example images illustrating the purification process and its effect on both clean and poisoned samples.

This figure shows the L2 distance plots for both PUREGEN-EBM and PUREGEN-DDPM. The plots illustrate the change in L2 distance between clean images and their purified versions, clean images and purified poisoned images, and poisoned images and their purified versions throughout the Langevin dynamics trajectory. The key observation is that purifying poisoned images for fewer than 250 steps brings the poisoned image closer to its clean counterpart, minimizing image alteration while removing adversarial elements. The point of minimum distance is around 150 steps for both models.
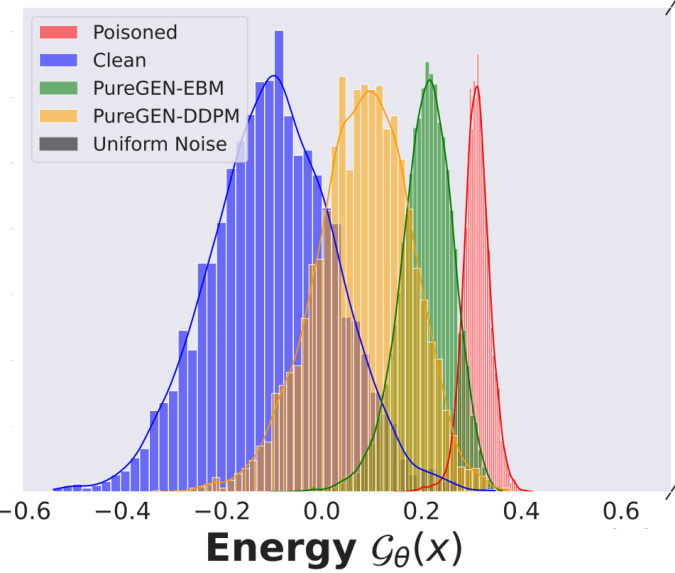
This figure illustrates the PUREGEN pipeline, showing how it’s used as a preprocessing step before standard classifier training and inference. It highlights the energy distribution differences between clean, poisoned, and purified images, emphasizing how PUREGEN moves poisoned images closer to the clean image distribution. The bottom right shows example images before and after purification, illustrating the effectiveness of the method.
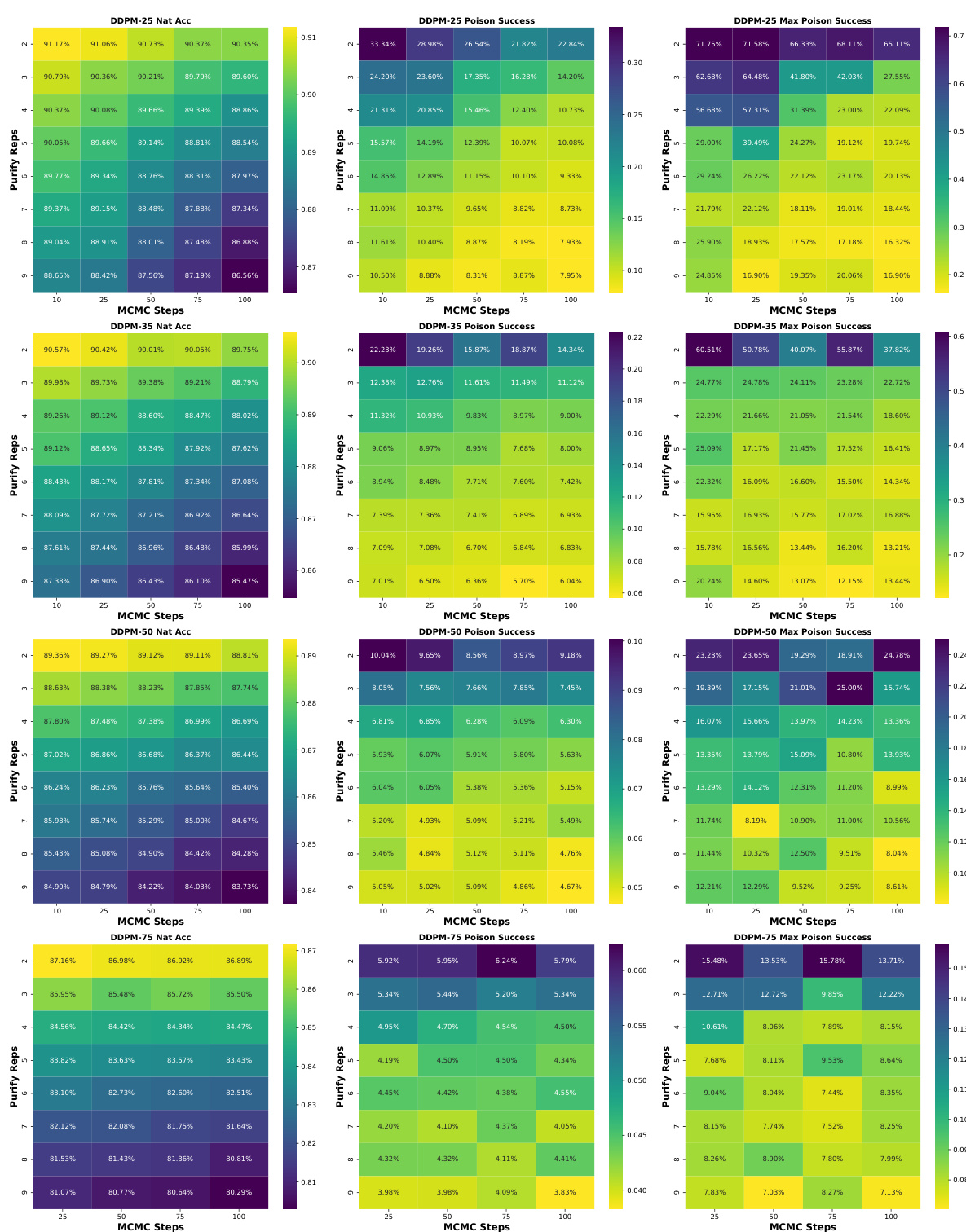
This figure demonstrates the effect of varying the number of forward diffusion steps in training the PUREGEN-DDPM model. It shows that using a limited number of steps (250) is superior for data purification compared to using the full number of steps (1000) as used in a standard DDPM. The limited-step approach sacrifices some image generation quality, but this trade-off improves poison defense. Visual examples are given demonstrating the difference in image generation across different step counts and highlighting that limiting the training to 250 steps yields better poison defense.

This figure shows the results of comparing PUREGEN-DDPM with standard DDPM models. The top part illustrates the different steps in both models’ forward processes. The bottom left shows the generated images by the models with 250, 750, and 1000 training steps. Lastly, the bottom right presents data regarding poison defense performance and average natural accuracy.

This figure illustrates the PUREGEN pipeline, showing how it’s used as a preprocessing step before standard classifier training and inference. It also displays energy distributions, highlighting how PUREGEN moves poisoned images closer to the clean image distribution. Finally, it shows examples of purified images, demonstrating the removal of poison artifacts and the improved accuracy.

This figure illustrates the PUREGEN pipeline, showing how it’s used as a preprocessing step before standard classifier training and inference. It highlights the energy distribution differences between clean, poisoned, and purified images, demonstrating how PUREGEN moves poisoned images closer to the clean image manifold. The bottom-right panel showcases the visual effect of purification, where poisoned images become more similar to clean images after processing. The overall result is improved defense against poisoning attacks and maintained classifier accuracy.

This figure compares the results of PUREGEN-DDPM with different forward steps against the standard DDPM. It shows that training the DDPM with a subset of the standard forward process improves purification capabilities. The figure also shows the generated images from models trained with different numbers of steps, highlighting the trade-off between data purification and generative capabilities.
More on tables

This table presents the results of experiments conducted on three additional models (MobileNetV2, DenseNet121, and Hyperlight Benchmark) along with the NTGA data availability attack. It demonstrates PUREGEN’s continued state-of-the-art performance against various train-time latent attacks. While not the primary focus of the paper, the results also show that PUREGEN achieves near state-of-the-art performance in defending against the NTGA data availability attack.

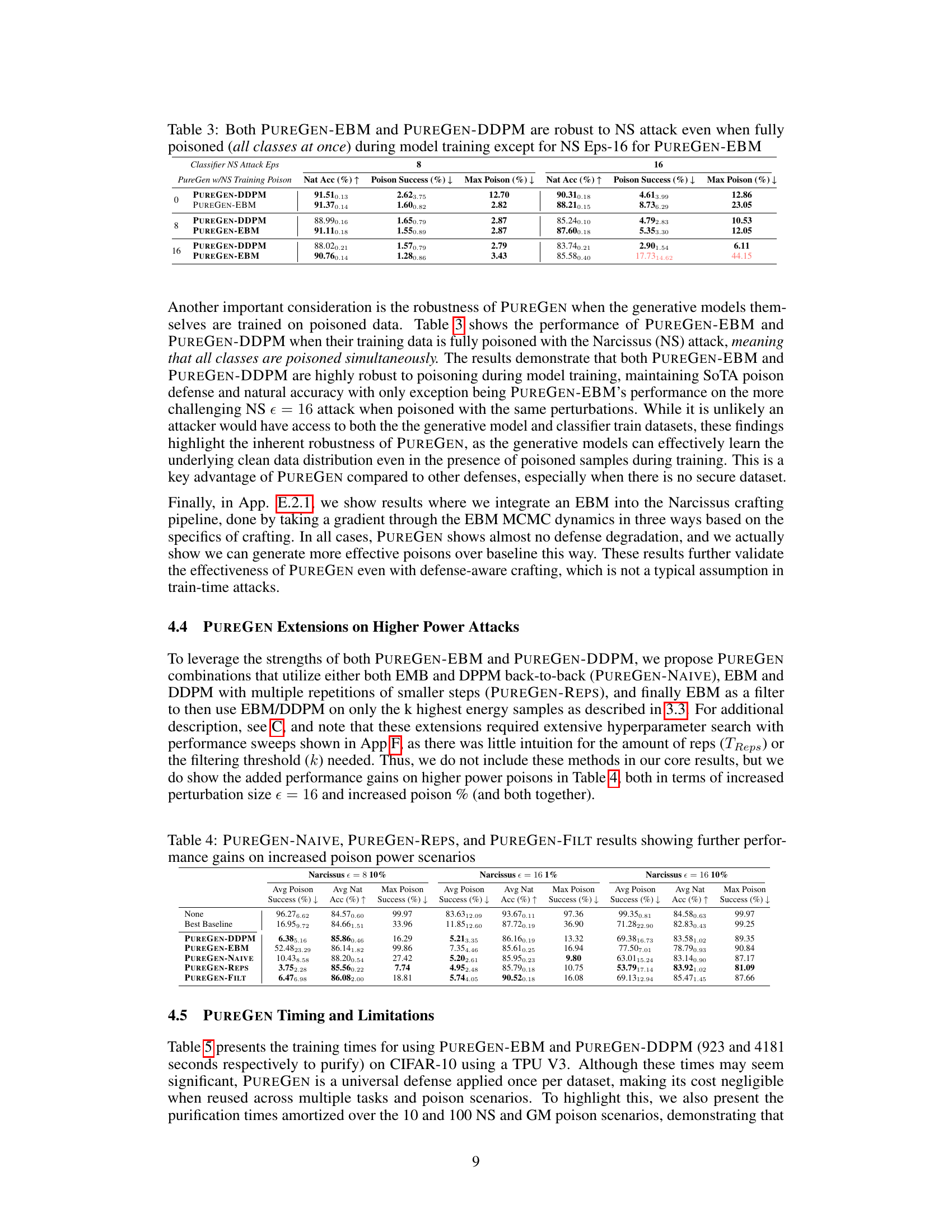
This table presents the results of experiments evaluating the robustness of PUREGEN-EBM and PUREGEN-DDPM to Narcissus (NS) attacks, where all classes are poisoned during model training. It shows the natural accuracy, poison success rate, and maximum poison success rate for different poison strengths (epsilons) and whether the generative models were trained with poisoned data or not. The results demonstrate the robustness of PUREGEN methods, even when trained on fully poisoned datasets, and highlight the trade-off between robustness and natural accuracy, particularly for higher poison strength.
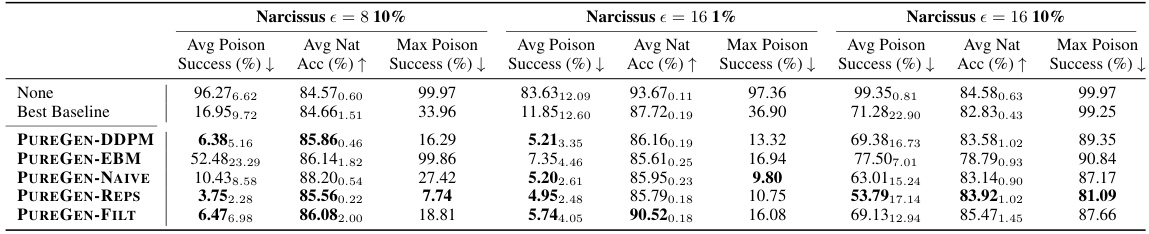
This table presents the results of poison attacks and defenses using ResNet18 models on CIFAR-10, CINIC-10, and Tiny-ImageNet datasets. It shows the average poison success rate (the percentage of poisoned images that successfully cause misclassification), natural accuracy (the accuracy on clean images), and maximum poison success rate across all classes for three types of attacks: Gradient Matching (GM), Bullseye Polytope (BP), and Narcissus (NS). The results are compared for different defense methods: no defense, EPIC, FRIENDS, JPEG compression, PUREGEN-DDPM, and PUREGEN-EBM. The table highlights the superior performance of PUREGEN methods in defending against data poisoning attacks.
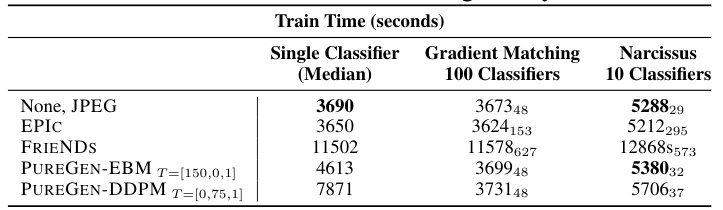
This table presents the results of poison attack experiments on CIFAR-10, CINIC-10, and TinyImageNet using ResNet-18 and ResNet-34 architectures. The table compares the performance of various defense methods, including PUREGEN-EBM and PUREGEN-DDPM, against three different types of poisoning attacks (Gradient Matching, Bullseye Polytope, and Narcissus) with varying poison percentages. For each attack and defense method, the average poison success rate (the percentage of poisoned images successfully misclassified) and the average natural accuracy (the accuracy on clean images) are reported, along with the maximum poison success rate across classes. The results are presented separately for from-scratch training (training from scratch with no pre-training) and transfer learning scenarios. Transfer learning scenarios included linear and fine-tune methods using pre-trained ResNet models.
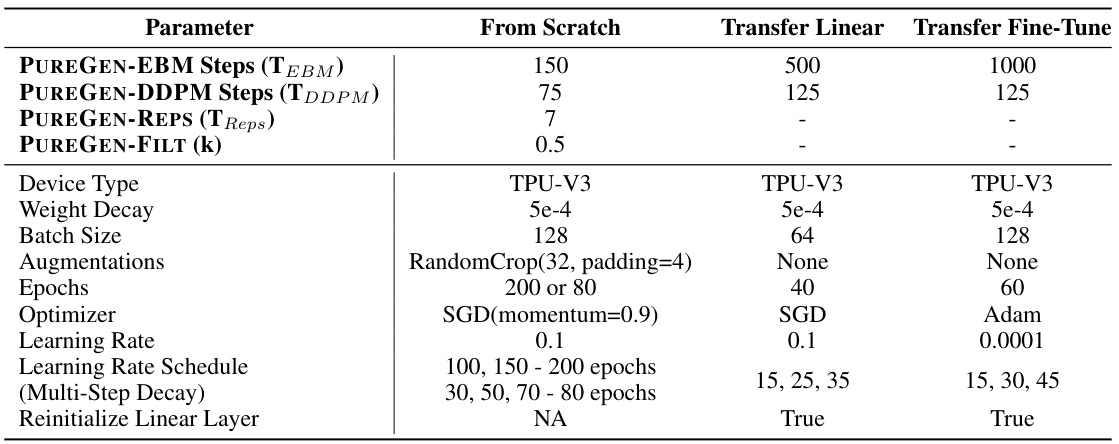
This table presents the results of poison attacks and natural accuracy using ResNet-18 for various poisoning scenarios on CIFAR-10, CINIC-10, and Tiny-ImageNet datasets. It compares the performance of different defense methods (EPIC, FRIENDS, JPEG, PUREGEN-EBM, PUREGEN-DDPM) against different types of poison attacks (Gradient Matching, Narcissus, and Bullseye Polytope) with varying poison percentages. The table shows the average poison success rate and natural accuracy for each defense method and attack type. Standard deviations are provided for the average poison success rate and natural accuracy, showing variability in results.

This table presents the results of poison attacks and defenses using ResNet18 model on three datasets (CIFAR-10, CINIC-10, and Tiny ImageNet). It compares the poison success rate (the percentage of poisoned samples that were successfully misclassified), and natural accuracy (the accuracy on clean samples) for various poisoning attack methods (Gradient Matching, Narcissus, Bullseye Polytope) and defense methods (EPIC, FRIENDS, JPEG, PUREGEN-EBM, PUREGEN-DDPM). The table shows the average and standard deviation of these metrics across multiple experimental runs.
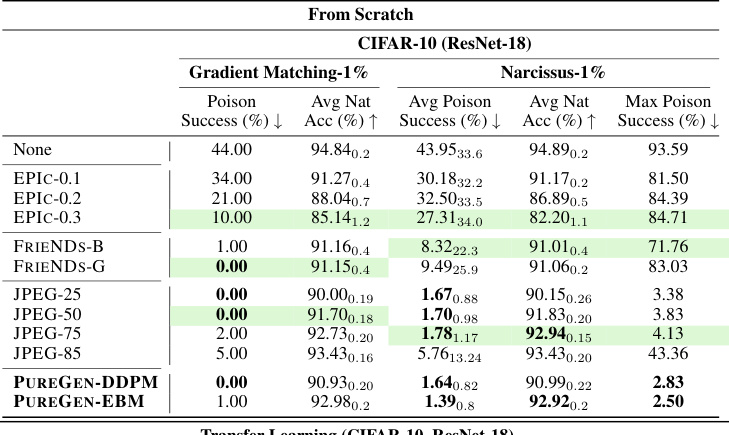
This table presents the results of poison attacks and defenses using ResNet-18 on CIFAR-10, CINIC-10, and Tiny ImageNet datasets. It compares different defense methods, including EPIC, FRIENDS, JPEG, PUREGEN-DDPM, and PUREGEN-EBM, against three types of poisoning attacks: Gradient Matching (GM), Bullseye Polytope (BP), and Narcissus (NS). For each attack and defense method, the table shows the average poison success rate (percentage of poisoned samples that were successfully misclassified), the average natural accuracy (accuracy on clean samples), and the maximum poison success rate (highest poison success rate achieved in any class). The results demonstrate the effectiveness of PUREGEN methods in improving natural accuracy while reducing poison success rates.
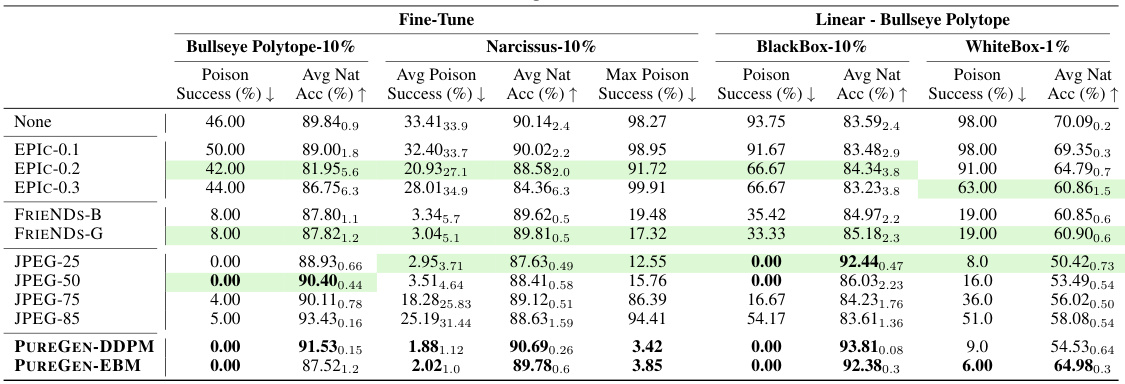
This table presents the results of poison attacks and defenses on CIFAR-10, CINIC-10, and TinyImageNet using ResNet-18 and ResNet-34 architectures. It compares the performance of different defense methods (EPIC, FRIENDS, JPEG, PUREGEN-DDPM, PUREGEN-EBM) against various poisoning attacks (Gradient Matching, Narcissus, Bullseye Polytope). The metrics reported are the average poison success rate (percentage of poisoned samples successfully misclassified) and the average natural accuracy (accuracy on clean samples) for each method. The table also includes maximum poison success rates, providing insight into the worst-case scenarios for each defense.

This table presents the results of poison attacks and defenses using ResNet-18 models on CIFAR-10, CINIC-10, and Tiny ImageNet datasets. It shows the average poison success rate (the percentage of poisoned images that caused misclassification), average natural accuracy (the accuracy on clean images), and maximum poison success rate. Different defense methods are compared: None (no defense), EPIC, FRIENDS, JPEG compression, and PUREGEN (both EBM and DDPM versions). The results are broken down by poison type (Gradient Matching, Narcissus, and Bullseye Polytope) and dataset. The table highlights PUREGEN’s superior performance in maintaining high natural accuracy while significantly reducing poison success rates.

This table presents the results of poison attacks and natural accuracy on CIFAR-10, CINIC-10 and Tiny ImageNet using ResNet-18 and ResNet-34 models. It compares the performance of several defense methods, including EPIC, FRIENDS, JPEG compression, PUREGEN-DDPM and PUREGEN-EBM against three types of poison attacks: Gradient Matching, Bullseye Polytope, and Narcissus. For each attack and defense method, the table shows the average poison success rate (the percentage of poisoned images that were successfully misclassified) and the average natural accuracy (the accuracy on clean images) with standard deviations. The ‘Max Poison Success’ column shows the maximum poison success rate achieved in any of the 10 classes for the Narcissus attack.
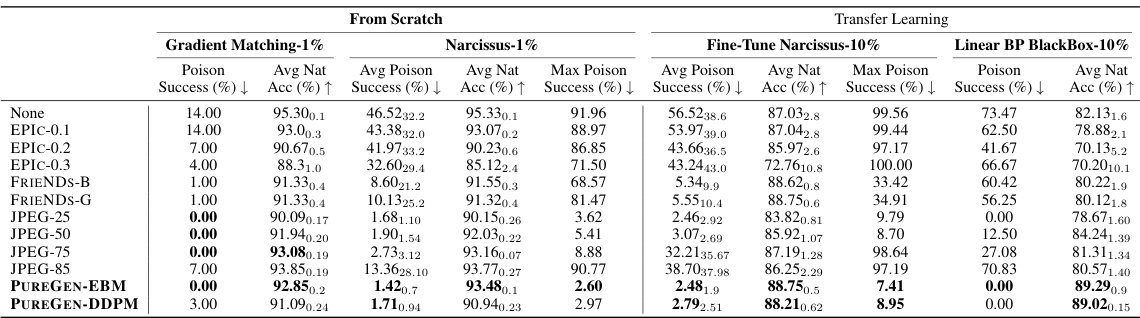
This table presents the results of poison attacks (Gradient Matching, Bullseye Polytope, and Narcissus) on ResNet-18 models trained on CIFAR-10, CINIC-10, and TinyImageNet datasets. It shows the average poison success rate (the percentage of poisoned images that were successfully misclassified), the average natural accuracy (accuracy on clean images), and the maximum poison success rate (the highest percentage of poison success achieved across all classes) for each attack and defense method. The ‘None’ row represents the baseline performance without any defense mechanism, while other rows show the impact of various defense methods (EPIC, FRIENDS, JPEG, PUREGEN-EBM, PUREGEN-DDPM) on poison success and natural accuracy.

This table presents the results of poison attacks and defenses using ResNet18 models on CIFAR-10, CINIC-10, and Tiny-ImageNet datasets. It compares the performance of several defense methods (EPIC, FRIENDS, JPEG, PUREGEN-EBM, PUREGEN-DDPM) against different types of poison attacks (Gradient Matching, Narcissus, Bullseye Polytope). The table shows the average poison success rate (percentage of poisoned samples successfully misclassified) and average natural accuracy (classification accuracy on clean data) for each method.

This table presents the results of poison attacks and natural accuracy for different defense methods on CIFAR-10, CINIC-10, and Tiny ImageNet datasets using ResNet-18 and ResNet-34 architectures. It compares the performance of several defense strategies (EPIC, FRIENDS, JPEG, PUREGEN-DDPM, PUREGEN-EBM) against three types of poisoning attacks (Gradient Matching, Bullseye Polytope, and Narcissus). The metrics presented are the average poison success rate and the average natural accuracy. The table showcases the effectiveness of PUREGEN methods in mitigating the impact of data poisoning attacks.

This table compares the performance of two pre-trained diffusion models from HuggingFace with the PUREGEN models on the Narcissus From-Scratch attack. It shows that pre-trained models can achieve similar poison defense and natural accuracy as PUREGEN models, highlighting the potential for using pre-trained models as a simpler alternative, while also acknowledging that pre-trained models may have unknown security risks.

This table presents the poison success rates for Gradient Matching (GM) and Bullseye Polytope (BP) poisoning attacks. The results are shown for a baseline, several other defense methods (EPIC, FRIENDS, JPEG), and the proposed PUREGEN methods (PUREGEN-EBM and PUREGEN-DDPM). Three different random seeds were used to train three separate classifiers for each scenario, enabling the calculation of standard deviations. This demonstrates the low variance of results despite the variation in random seed and highlights the consistent, superior performance of PUREGEN.
Full paper#