↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
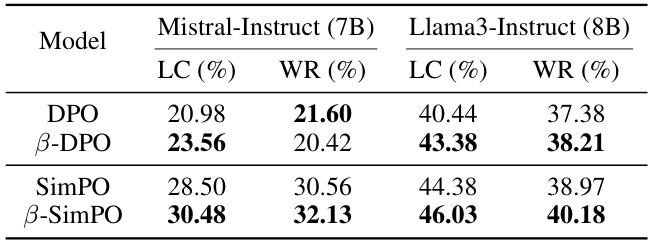
Current methods for aligning Large Language Models (LLMs) with human preferences, like Direct Preference Optimization (DPO), struggle with sensitivity to parameter tuning and data quality. Inconsistent performance arises from using a static parameter (β), which doesn’t adapt to the varying quality of preference data. This limits DPO’s effectiveness and scalability for real-world applications.
β-DPO introduces a novel framework addressing these issues. It dynamically adjusts β at the batch level, guided by data quality. A B-guided data filtering mechanism is added to handle noisy data. Experiments show that the dynamic adjustment of β consistently enhances DPO’s performance across diverse models and datasets, making it a more robust and adaptable LLM alignment technique. This approach offers a significant improvement over traditional DPO, providing a more stable and efficient solution for aligning LLMs with human preferences.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) alignment. It directly addresses the sensitivity of Direct Preference Optimization (DPO) to parameter tuning and data quality, offering a novel dynamic calibration technique to improve robustness and efficiency. This research is highly relevant to current trends in RLHF and provides a practical and easily adaptable method for improving LLM alignment.
Visual Insights#

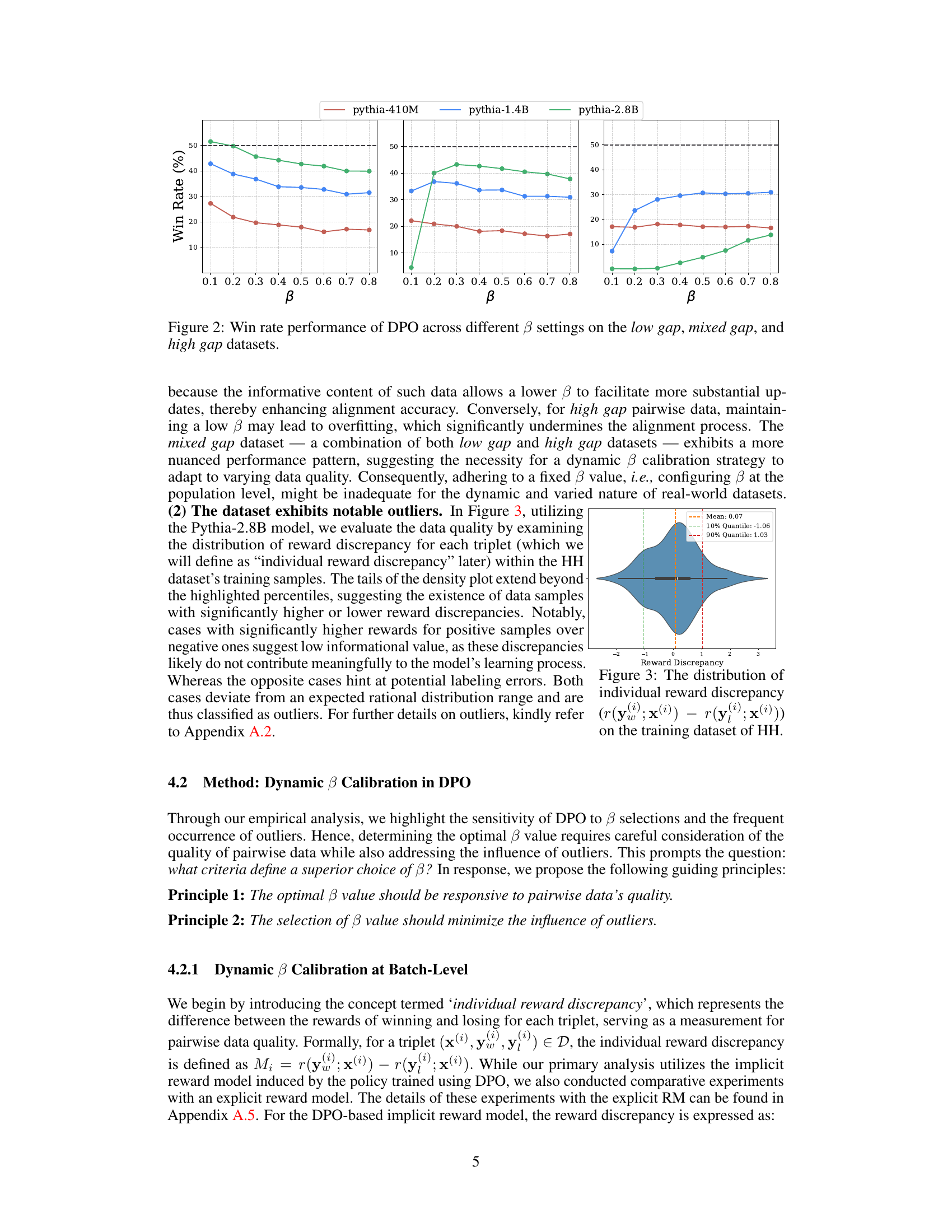
This figure shows the impact of data quality and the hyperparameter β on the performance of Direct Preference Optimization (DPO). Part (a) illustrates two types of data pairs: ’low gap’ (similar chosen and rejected responses) and ‘high gap’ (dissimilar chosen and rejected responses). Part (b) displays the win rate (model performance) for different values of β under both low and high gap conditions, demonstrating that optimal β values depend on the informativeness of the data.
This table presents the win rates achieved by different methods on the Anthropic HH dataset using GPT-4 for evaluation. The methods compared are standard DPO, DPO with dynamic beta, DPO with data filtering, and the proposed B-DPO method. The win rates are shown for three different sizes of Pythia models (410M, 1.4B, and 2.8B). Percentage improvements compared to the standard DPO are also indicated for each of the other methods. The table highlights the superior performance of B-DPO across all model sizes.
In-depth insights#
Dynamic Beta DPO#
The proposed “Dynamic Beta DPO” framework offers a significant advancement in direct preference optimization by dynamically adjusting the beta parameter, a key factor controlling the balance between model updates and adherence to initial preferences. Its adaptive nature addresses the limitations of static beta values, which often prove suboptimal when dealing with varied data quality and the presence of outliers. This dynamic adjustment, achieved at the batch level, enhances the robustness and stability of the optimization process. By incorporating beta-guided data filtering, the framework further mitigates the negative influence of outliers, improving the precision of the beta calibration and enhancing the overall DPO performance. This innovative approach demonstrates significant improvements across a range of models and datasets, suggesting its potential to become a powerful paradigm for more robust and adaptable LLM alignment.
Data Quality Effects#
Data quality significantly impacts the performance of Direct Preference Optimization (DPO). Lower-quality data, characterized by smaller differences between preferred and unpreferred responses (low gap), necessitates a higher beta (β) value in DPO to prevent aggressive updates that might overfit to noisy data. Conversely, high-quality data (high gap) allows for a lower β, enabling more substantial updates and improved alignment. The optimal β value is not static but rather dynamically depends on the informativeness of the data. Outliers also negatively influence DPO’s performance, requiring mechanisms to filter unreliable samples. A dynamic β calibration strategy addresses this by adjusting β at the batch level based on the quality of the data in that batch, thus ensuring stability while incorporating new preferences efficiently. This adaptive approach improves DPO’s robustness and alignment accuracy across different model sizes and datasets.
Batch-Level Tuning#
Batch-level tuning, as opposed to instance-level or global tuning, presents a compelling compromise in the context of hyperparameter optimization. It offers a balance between the responsiveness of instance-level adjustments and the stability of globally fixed parameters. By dynamically adjusting hyperparameters at the batch level, the method adapts to the characteristics of each mini-batch, allowing for more responsive optimization while mitigating the risk of instability and overfitting that can arise from frequent, individual updates. This approach is particularly valuable when dealing with datasets exhibiting significant variability or when outliers may exert a disproportionate influence. The computational cost is relatively low compared to instance-level tuning, since fewer computations are required, making it a practical and efficient solution for large-scale machine learning tasks. However, careful consideration must be given to the choice of the aggregation method for batch-level adjustments, as the selected approach can influence the algorithm’s overall performance and stability.
Filtering Strategies#
The effectiveness of Direct Preference Optimization (DPO) hinges significantly on the quality of the preference data used for training. Low-quality data, including outliers or noisy comparisons, can lead to suboptimal model performance. Therefore, employing robust filtering strategies is crucial for improving the reliability and effectiveness of DPO. These strategies could involve various techniques, such as statistical outlier detection, which identifies data points with unusually high or low reward discrepancies. Another method could be threshold-based filtering, eliminating pairs with minimal differences between preferred and dispreferred options. Guided data filtering, informed by model confidence or other quality metrics, offers a more sophisticated approach. Finally, dynamic filtering, adapting the filtering criteria based on training progress or data characteristics, provides a more adaptive and robust solution. The optimal filtering strategy will depend on the specific dataset and the desired trade-off between data quantity and quality. An in-depth analysis of various filtering techniques and their impact on DPO performance is needed to determine the most suitable approach for different scenarios.
Future Directions#
Future research directions stemming from this paper could explore several key areas. Extending the dynamic beta (β) framework to self-play scenarios would be particularly valuable, as this would require the system to adapt β iteratively and create a more robust and adaptable training paradigm. Investigating alternative methods for addressing the challenges of data quality, particularly the presence of outliers, warrants further exploration. Developing more sophisticated evaluation metrics beyond the current win rate is necessary to fully assess the quality of alignment achieved by LLMs. Improving the scalability of the approach for ultra-large language models (LLMs) exceeding 7B parameters is critical for real-world applications. Finally, automating the process of parameter tuning, particularly the selection of β, would significantly enhance the usability and accessibility of the method. This research laid a solid foundation for future advancements in improving LLM alignment through a more robust and adaptable framework.
More visual insights#
More on figures
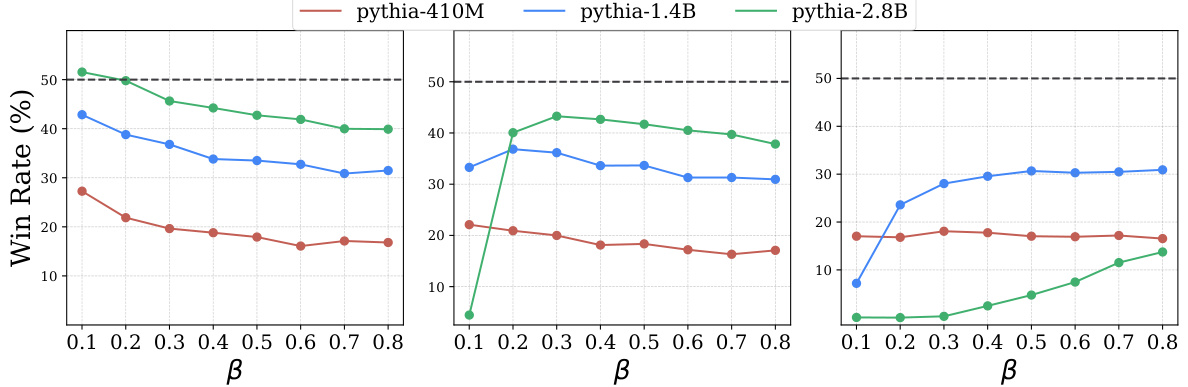
This figure shows the results of an experiment evaluating the effect of different beta values on the win rate of Direct Preference Optimization (DPO) across three different types of datasets: low gap, mixed gap, and high gap. The low gap dataset contains pairs of similar responses where a subtle difference is present, whereas the high gap contains pairs of greatly dissimilar responses. The mixed gap is a combination of both. Each line represents the win rate of a specific DPO model (Pythia-410M, Pythia-1.4B, and Pythia-2.8B) at various beta values. The results show that the optimal beta value depends on the type of dataset, highlighting the importance of adapting beta based on data quality.

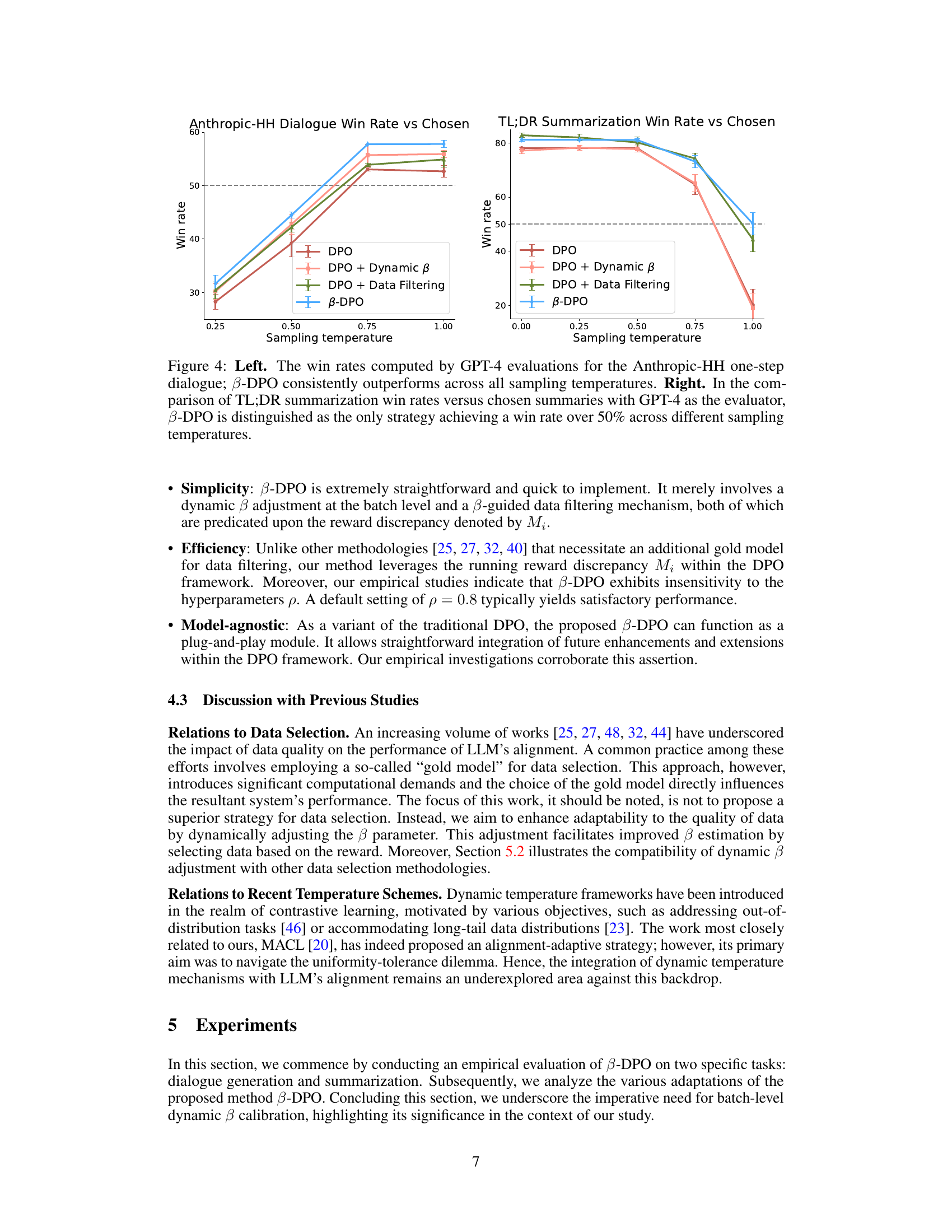
This figure shows the distribution of reward discrepancies for each data point in the Anthropic HH dataset. The reward discrepancy is calculated as the difference between the reward for the preferred response (yw) and the reward for the rejected response (yι) for a given prompt (x). The distribution is shown as a violin plot, with the central black bar representing the median and quartiles, and the shape of the violin showing the probability density of the discrepancies. The plot also includes dashed lines indicating the mean and the 10th and 90th percentiles of the distribution. This visualization highlights the presence of outliers in the dataset, indicated by the tails of the distribution extending beyond the 10th and 90th percentiles, suggesting some samples have significantly higher or lower reward discrepancies than most.

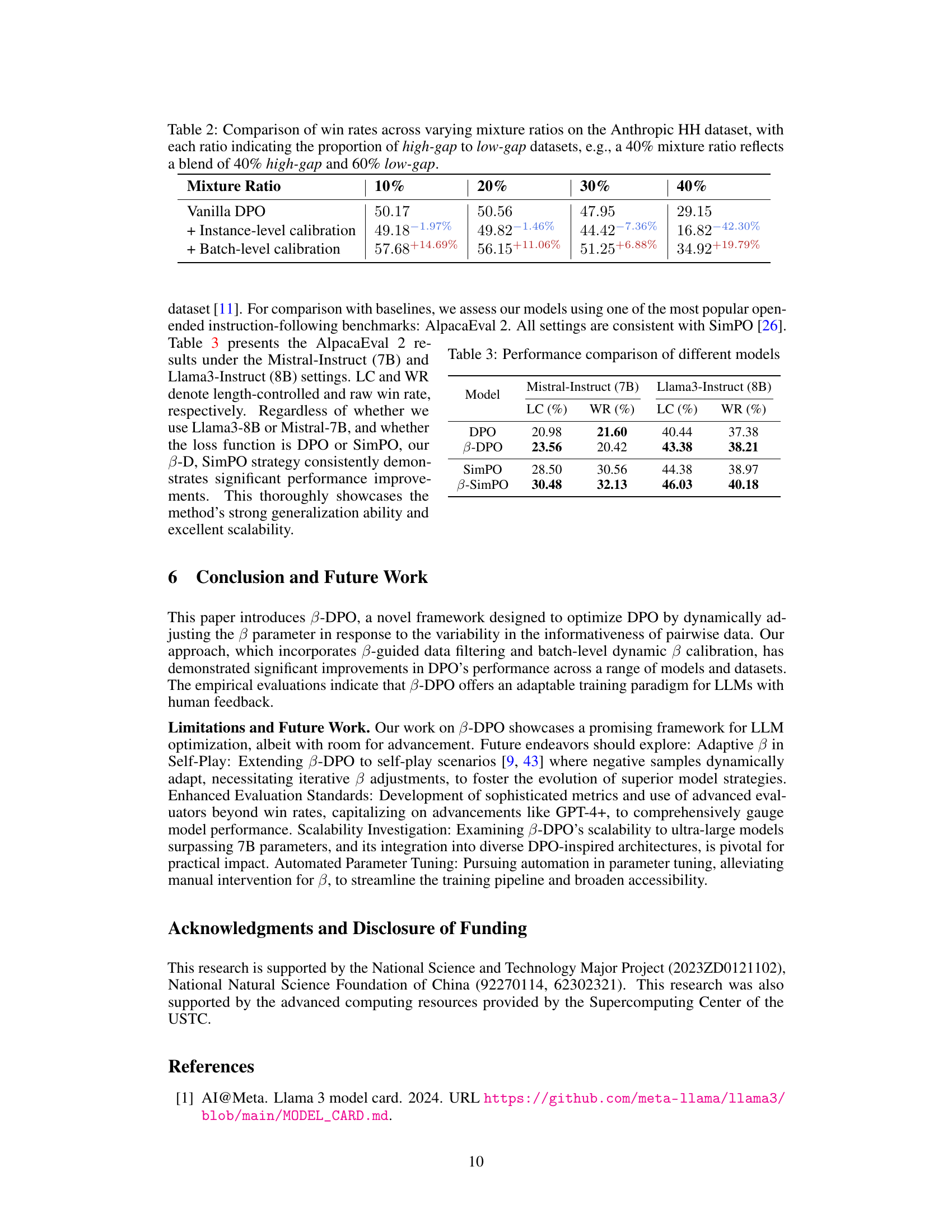
This figure displays the results of comparing different DPO methods across two tasks: Anthropic HH dialogue and TL;DR summarization. The left panel shows that β-DPO consistently achieves higher win rates compared to other methods for the dialogue task across various sampling temperatures. The right panel shows that β-DPO outperforms other methods, being the only method with a win rate above 50% for the summarization task across various sampling temperatures.

This figure presents a comparison of the performance of the proposed β-DPO method against several baselines across three different aspects: filtering strategies, DPO variants, and calibration methods. The left panel shows win rates for different filtering methods (Filter Tail, Filter Head, Filter Tail & Head). The middle panel shows win rates for different DPO variants (DPO, IPO, KTO, SPPO) with and without the dynamic β adjustment. The right panel displays the distribution of reward discrepancies obtained using batch-level and instance-level calibration, highlighting the impact of outlier handling.

This violin plot shows the distribution of individual reward discrepancies for different mixture ratios of low-gap and high-gap datasets using the Pythia-2.8B model. The x-axis represents the mixture ratio (proportion of high-gap data), ranging from 0.1 to 1.0. The y-axis represents the individual reward discrepancy, which reflects the difference in reward scores between the preferred and dispreferred responses in a pair. The plot reveals that as the mixture ratio increases (more high-gap data), the distribution of reward discrepancies becomes wider, indicating greater variability in the data quality. Conversely, a lower mixture ratio results in a more concentrated distribution, suggesting higher quality and more consistent data.

This figure displays the win rates achieved by three different sized language models (Pythia 410M, Pythia 1.4B, and Pythia 2.8B) on the Anthropic HH dataset when varying two hyperparameters: β and ρ. The plots show how the win rate changes depending on the values of β (a trade-off parameter in the DPO algorithm) and ρ (the filtering ratio). Each subplot shows the performance for a specific model size. Exponential smoothing is applied to the win rates.
More on tables

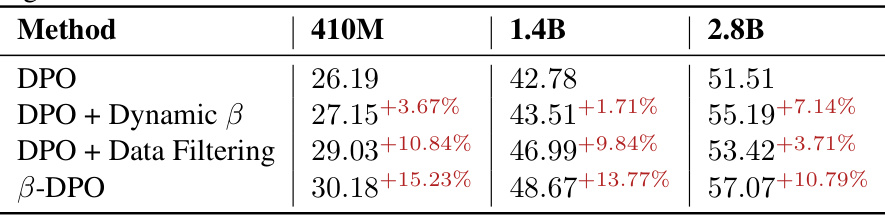
This table presents the win rates achieved by three different DPO methods across different ratios of high-gap and low-gap data in the Anthropic HH dataset. The ‘Vanilla DPO’ row shows the performance of the standard DPO method. The next row shows the performance when instance-level beta calibration is used, and the final row shows the performance when batch-level beta calibration is applied. The percentage changes compared to the Vanilla DPO are shown in parentheses, with positive values representing improvements and negative values representing decreases in performance.
This table presents the win rates achieved by four different methods (DPO, DPO with dynamic beta, DPO with data filtering, and beta-DPO) on three different sized language models (Pythia-410M, Pythia-1.4B, and Pythia-2.8B) when evaluated using GPT-4 on the Anthropic HH dataset. The win rate represents the percentage of times the model’s response was preferred to the baseline response by GPT-4.

This table presents the win rates achieved by different methods on the Anthropic HH dataset using the GPT-4 model for evaluation. The methods compared include the standard DPO, DPO with dynamic beta, DPO with data filtering, and the proposed B-DPO. Win rate is a metric indicating how often GPT-4 prefers the model’s response over the default response. The table shows the win rates for three different sizes of Pythia models (410M, 1.4B, and 2.8B parameters) to demonstrate performance across different model scales.

This table presents the win rates achieved by the β-DPO method across different values of the hyperparameter Mo. Mo is a threshold used in the dynamic β calibration strategy. The results show that using a moving average to update Mo (last column) leads to the highest win rate, indicating that this approach is superior to using a fixed value of Mo.

This table presents the win rates achieved by different methods (DPO, DPO with dynamic beta, DPO with data filtering, and Beta-DPO) on the Anthropic HH dataset using three different sizes of Pythia models (410M, 1.4B, and 2.8B). The win rate is a measure of how often GPT-4 prefers the response generated by the model over the default chosen response. The table shows the improvement in win rate achieved by Beta-DPO compared to the other methods across different model sizes.
Full paper#