↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current vision-language models like CLIP struggle with compositional reasoning, often failing to understand nuanced relationships between objects in images and their textual descriptions. This is mainly due to a lack of compositional diversity in existing datasets, which hinders the model’s ability to learn complex relationships. Existing approaches have tried to solve this issue by augmenting datasets with negative captions or rule-based generated captions. However, augmenting images with hard negatives remains an open challenge.
TripletCLIP tackles this limitation by introducing a novel contrastive pre-training strategy that leverages synthetically generated hard negative image-text pairs. The authors utilize LLMs to generate realistic negative captions and then employ text-to-image models to create corresponding negative images. These hard negative pairs are incorporated into a triplet contrastive loss function, which enhances the model’s ability to differentiate between semantically similar but visually distinct inputs. Their experiments demonstrate that this approach significantly improves CLIP’s performance on compositional reasoning benchmarks and other downstream tasks, showing the effectiveness of the proposed approach. Furthermore, they release TripletData, a 13M image-text dataset that includes these hard negatives, to benefit the wider research community.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models and contrastive learning. It introduces a novel approach to improve compositional reasoning, a significant challenge in the field. The TripletCLIP method and the released dataset are valuable resources for advancing the state-of-the-art, and the findings inspire further research into synthetic data augmentation for multimodal learning.
Visual Insights#
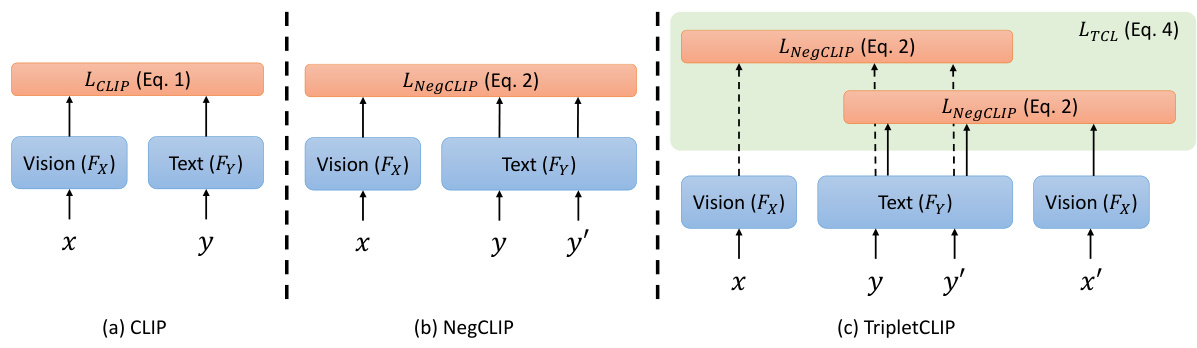
This figure compares the training workflows of three different models: CLIP, NegCLIP, and TripletCLIP. CLIP uses only positive image-text pairs (x, y) for training. NegCLIP adds hard negative text captions (y’) to the training process, enhancing the contrast. TripletCLIP builds upon NegCLIP by further introducing hard negative images (x’) corresponding to the hard negative captions (y’), creating a triplet (x, y, (x’,y’)) for more robust contrastive learning. The figure visually demonstrates how the negative samples are incorporated into each model’s training objective, showcasing the progression of complexity and potential for improved compositional reasoning.
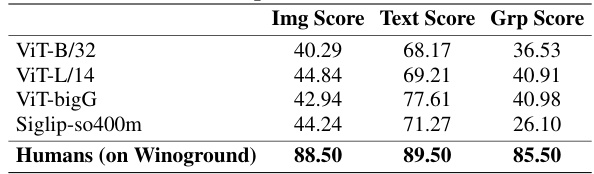
This table presents the results of a Winoground-style evaluation performed on the TripletData dataset using several pretrained CLIP models. Winoground is a benchmark designed to evaluate the compositional reasoning capabilities of vision-language models. The evaluation assesses the model’s ability to correctly match image-text pairs that share similar meanings, even when semantic perturbations have been made to the caption. The table shows the Image Score, Text Score, and Group Score for each model. These scores represent the accuracy of the models in selecting the correct image-text pairs based on image features, textual features, and a combination of both, respectively. The table also includes the human performance on the Winoground benchmark, providing a baseline for comparison.
In-depth insights#
Compositional CLIP#
Compositional CLIP, a concept extending the capabilities of CLIP (Contrastive Language-Image Pretraining), addresses CLIP’s limitations in understanding compositions. CLIP struggles with nuanced relationships between objects in images, often exhibiting a ‘bag-of-words’ approach. Compositional CLIP aims to resolve this by enhancing the model’s ability to reason about the relationships and arrangements within an image, improving its understanding of complex scenes. This usually involves innovative training techniques, such as incorporating synthetically generated data or employing new loss functions that explicitly encourage compositional reasoning. The core aim is to move beyond simple feature matching towards a more sophisticated understanding of scene composition, improving accuracy in tasks like zero-shot image classification and image retrieval involving complex scenarios.
Synthetic Negatives#
The concept of “Synthetic Negatives” in the context of contrastive learning for vision-language models is a powerful technique to enhance model performance. By generating artificial negative examples—images paired with captions that are semantically different but visually similar to positive pairs—we address the limitations of real-world datasets which often lack sufficient diversity in negative examples. The creation of synthetic negatives allows us to control the difficulty of negative samples, leading to more effective contrastive learning and improved model ability to discern subtle semantic differences. This is particularly crucial for compositional reasoning, where a model’s ability to understand the relationships between multiple elements in an image is tested. The quality and realism of synthetic negatives are critical, requiring advanced techniques like text-to-image generation models and careful design of the negative caption generation process. The success of this method hinges on the balance between introducing sufficiently difficult negatives to aid learning and avoiding generating unrealistic or nonsensical examples that hinder model training. The approach also opens possibilities in scenarios with limited real-world data, making it a valuable tool for improving various vision-language tasks, including image classification, retrieval and especially compositional reasoning.
Triplet Contrastive Loss#
The triplet contrastive loss function is a powerful technique used in machine learning to improve the performance of models by considering the relationship between three data points: an anchor, a positive example, and a negative example. The core idea is to pull the anchor and positive example closer together in the embedding space while simultaneously pushing the anchor and the negative example further apart. This is achieved by defining a loss function that penalizes instances where the distance between the anchor and positive is larger than the distance between the anchor and negative. This approach is particularly useful when dealing with high-dimensional data, where traditional contrastive loss functions might struggle to effectively capture subtle differences between examples. Triplet loss is often used in scenarios involving similarity learning, where the goal is to learn a representation that captures the similarity between data points. For example, it is well suited for tasks such as face recognition or image retrieval, where the model must learn to discriminate between similar-looking individuals or images. Key advantages of triplet loss include its ability to handle hard negatives effectively and its flexibility in accommodating various distance metrics. However, challenges exist in selecting appropriate triplets and dealing with the computational cost of evaluating triplet distances, especially when training very deep neural networks. Optimizing triplet loss requires careful considerations regarding the selection of data points, the sampling strategy, and the computational resources available. Careful consideration is needed to address the issue of imbalance in the distribution of positive and negative samples, which can lead to suboptimal learning.
Concept Diversity#
Concept diversity in vision-language models is crucial for robust generalization and compositional reasoning. A model trained on a diverse range of concepts is less likely to exhibit naive ‘bag-of-words’ behavior, where it fails to understand the nuanced relationships between words. Increasing concept diversity during training can lead to significant improvements in performance on downstream tasks, especially those involving complex reasoning or unseen combinations of visual and textual elements. However, simply increasing the volume of training data does not guarantee increased concept diversity; the data must be carefully curated to ensure a wide range of concepts are represented, and that these concepts are adequately sampled. Synthesizing high-quality, hard negative samples is a promising technique for enhancing concept diversity, particularly in situations where existing datasets have limited compositional variety. The effectiveness of different strategies for improving concept diversity should be carefully evaluated using benchmarks that specifically target compositional reasoning, and thorough analysis is needed to understand how the diversity of concepts actually impacts model performance in zero-shot and few-shot scenarios.
Future Directions#
Future research could explore several promising avenues. Extending TripletCLIP to larger-scale datasets and models would be crucial to further validate its effectiveness and explore its limitations at a massive scale. Investigating the impact of different LLM and T2I models on the quality of synthetic negatives is vital, as the choice of these models significantly influences results. Further exploration of the loss function’s role in balancing positive and negative samples warrants attention. Finally, applying TripletCLIP’s principles to other vision-language tasks beyond compositionality (e.g., image captioning, visual question answering) could demonstrate its broader applicability and potential for improving various multimodal learning models. This may uncover potential synergies with recent advances in multimodal architectures and further drive innovations in vision-language understanding.
More visual insights#
More on figures

This figure compares the training workflows of three different models: CLIP, NegCLIP, and TripletCLIP. It illustrates how each model uses positive and negative image-text pairs during training. CLIP uses a simple positive-negative pair. NegCLIP adds a negative text caption to the positive image-text pair. TripletCLIP adds both negative text and image to the positive pair for a more robust training process.
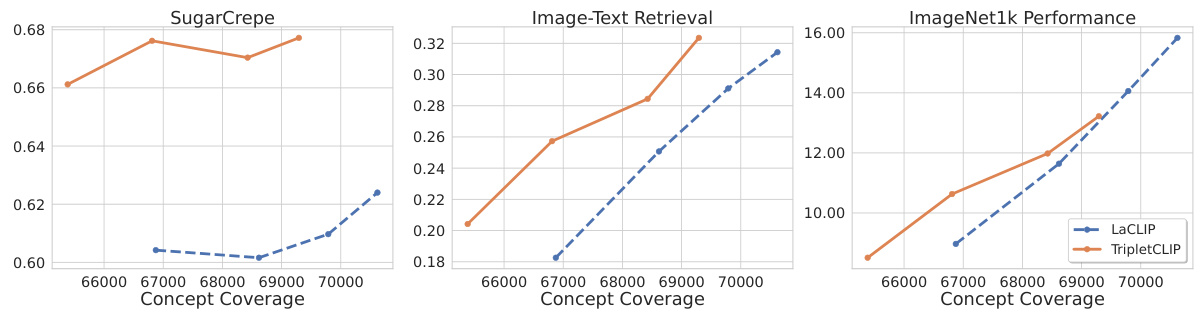
This figure shows the performance of LaCLIP and TripletCLIP models across three different evaluation metrics: SugarCrepe (compositional reasoning), Image-Text Retrieval, and ImageNet1k (zero-shot classification). The x-axis represents increasing concept coverage during training, indicating the amount of unique concepts the model has learned. The y-axis shows the corresponding performance scores for each metric. The plot demonstrates that TripletCLIP consistently outperforms LaCLIP across all three metrics as concept coverage increases, highlighting the effectiveness of the proposed TripletCLIP training strategy in improving the model’s compositional reasoning and generalization capabilities.

This figure compares the training workflows of three different models: CLIP, NegCLIP, and TripletCLIP. CLIP uses a standard contrastive learning approach with positive image-text pairs. NegCLIP augments this by adding hard negative text captions. TripletCLIP extends this further by incorporating both hard negative text captions and synthetically generated hard negative images, creating a triplet of (positive image-text pair, negative image, negative text). The figure visually represents how each model incorporates positive and negative samples during training to learn robust image-text representations.

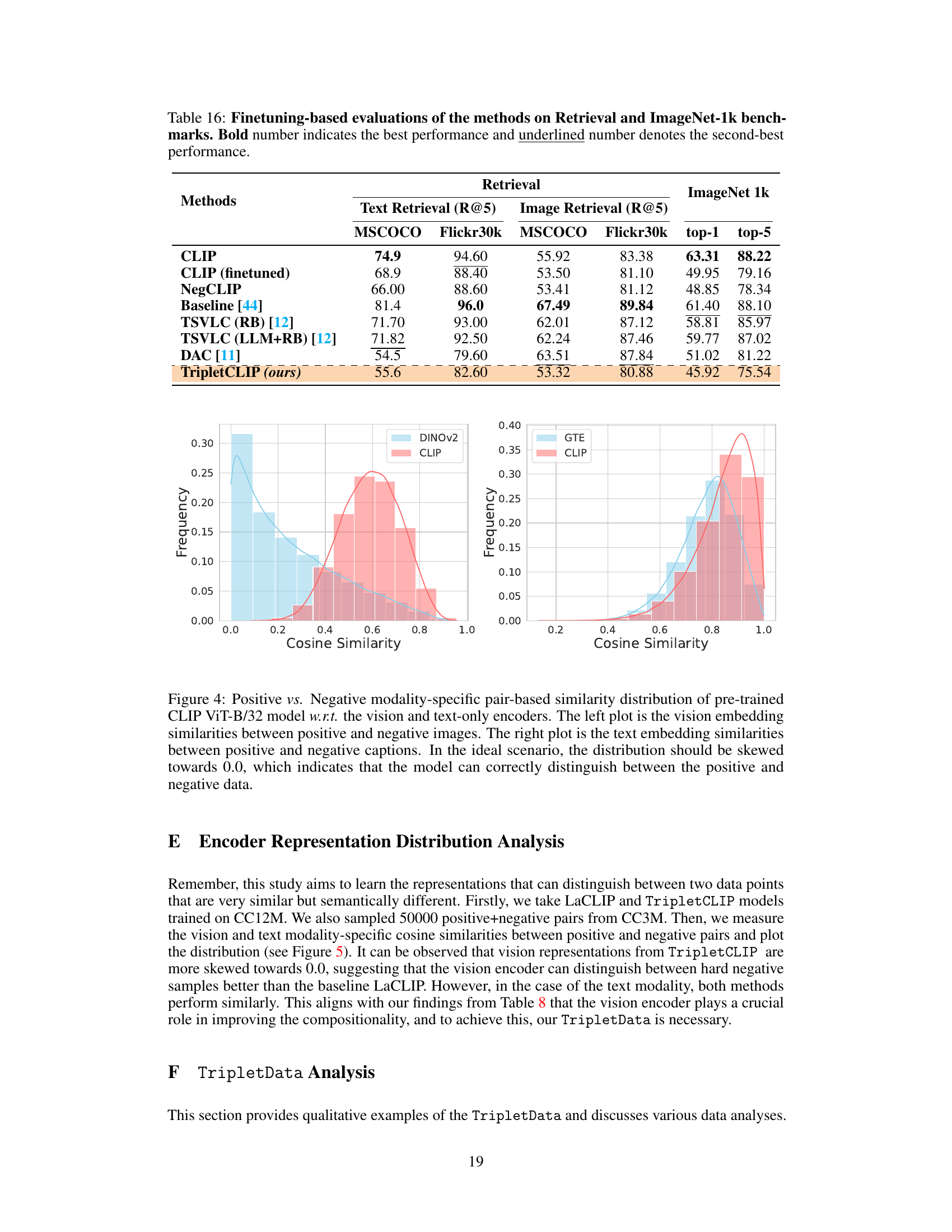
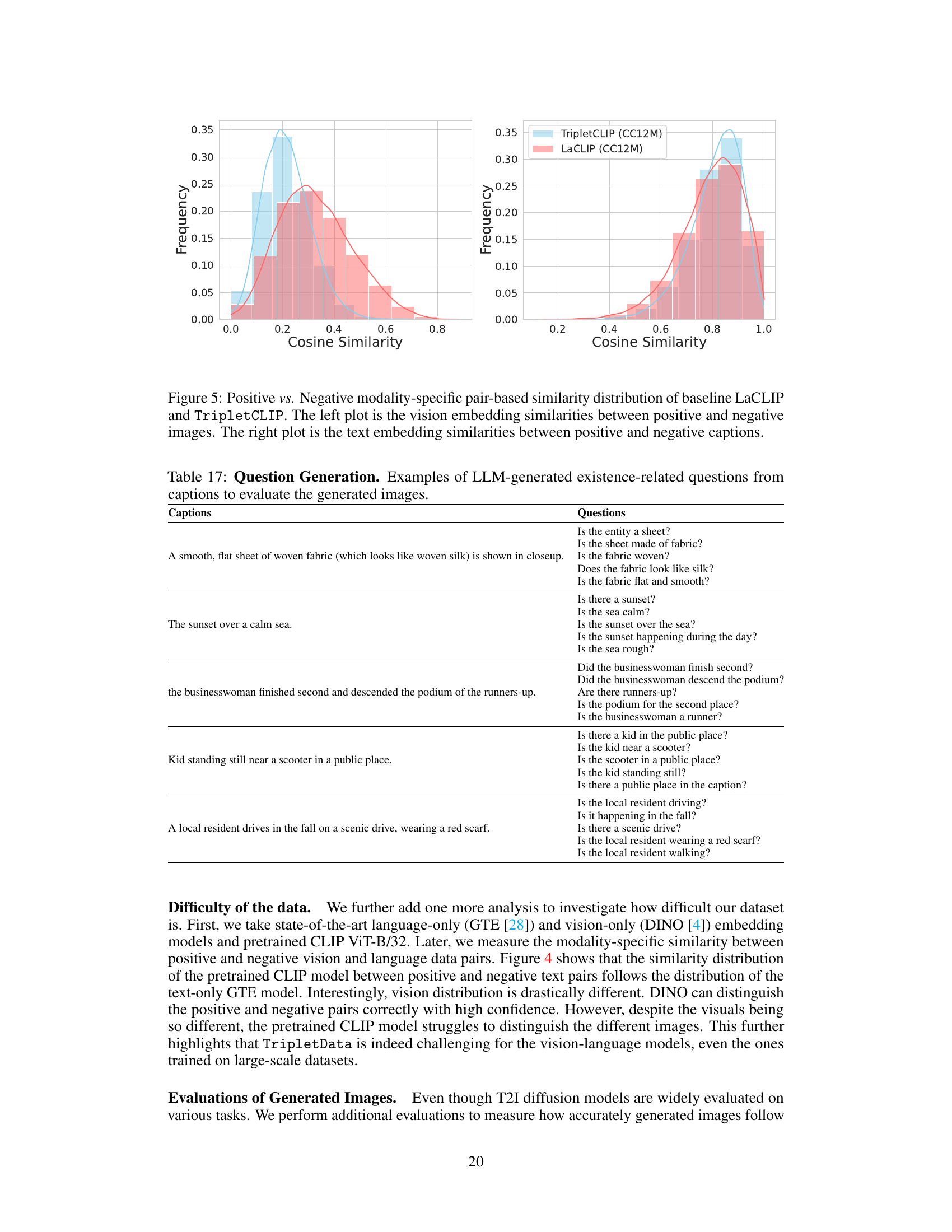
This figure shows the distribution of cosine similarity scores between positive and negative image-text pairs for both vision and text modalities. The left plot shows the distribution for vision embeddings (images) and the right plot for text embeddings (captions). The distributions are compared between baseline LaCLIP and the proposed TripletCLIP method. A more skewed distribution towards lower similarity scores (closer to 0.0) indicates better discrimination between positive and negative pairs; hence, better performance. Ideally, one would expect a distribution skewed sharply towards 0.0, representing perfect discrimination. The plots illustrate how the TripletCLIP model improves this discrimination, especially for the vision modality.
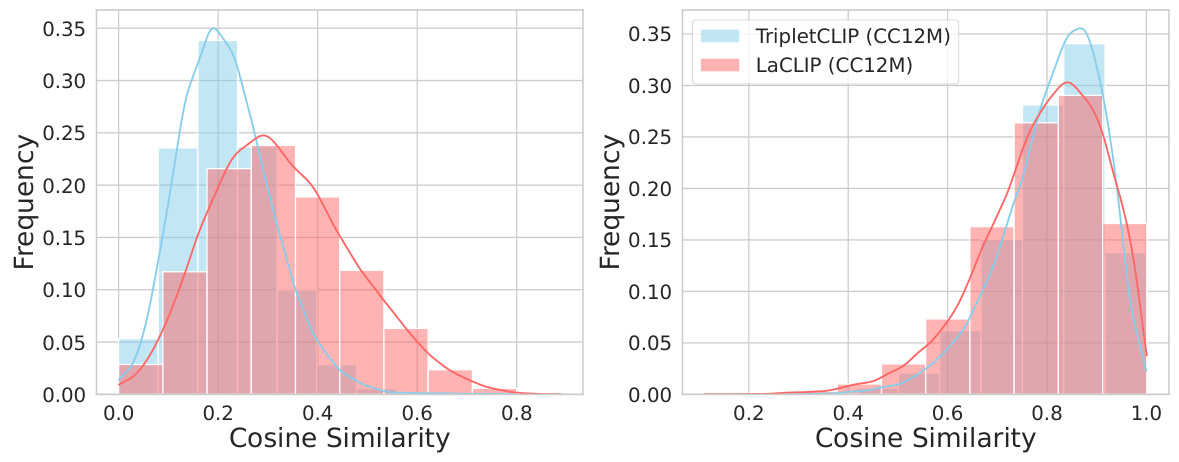
This figure shows the cosine similarity distributions for both vision and text modalities between positive and negative pairs using LaCLIP and TripletCLIP models trained on CC12M dataset. The x-axis represents the cosine similarity, ranging from 0 to 1, where 1 indicates high similarity and 0 indicates low similarity. The y-axis represents the frequency of pairs with a given cosine similarity. Separate distributions are shown for the vision and text modalities in the left and right panels, respectively. The left plot shows cosine similarity between vision embeddings of positive and negative image pairs. The right plot shows the cosine similarity between text embeddings of positive and negative text pairs.

This figure compares the training workflows of three different models: CLIP, NegCLIP, and TripletCLIP. CLIP uses only positive image-text pairs. NegCLIP incorporates negative text pairs alongside positive pairs. TripletCLIP, the proposed method, uses both hard negative image and text pairs, in an alternating fashion, alongside positive image-text pairs, to enhance the compositional reasoning of the model.

This figure compares the training workflows of three different models: CLIP, NegCLIP, and TripletCLIP. CLIP uses only positive image-text pairs for training. NegCLIP incorporates negative text captions to enhance the contrastive learning process. TripletCLIP extends this further by additionally using synthetically generated negative images and their corresponding hard negative captions, creating triplets for contrastive learning.
More on tables

This table presents a quantitative analysis comparing the concept coverage of the CC3M dataset and the TripletData dataset (considering only the negative captions). It shows the number of unique WordNet synsets (semantic concepts) and the total number of synsets in each dataset. The ‘TripletData Intersection’ column shows the overlap in synsets between the CC3M dataset and the negative captions in TripletData. This analysis helps to understand the extent to which TripletData introduces new concepts or enhances existing ones in comparison to the original dataset.

This table presents the results of experiments evaluating the impact of using different types of negative samples (captions only, images only, both captions and images) during the training of CLIP models. The performance is evaluated on three different tasks: SugarCrepe (a benchmark dataset for compositional reasoning), image-text retrieval, and ImageNet1k (zero-shot image classification). The results show that using both negative captions and negative images (TripletCLIP) leads to the best performance across all three tasks. The bold numbers highlight the best performing model for each task.
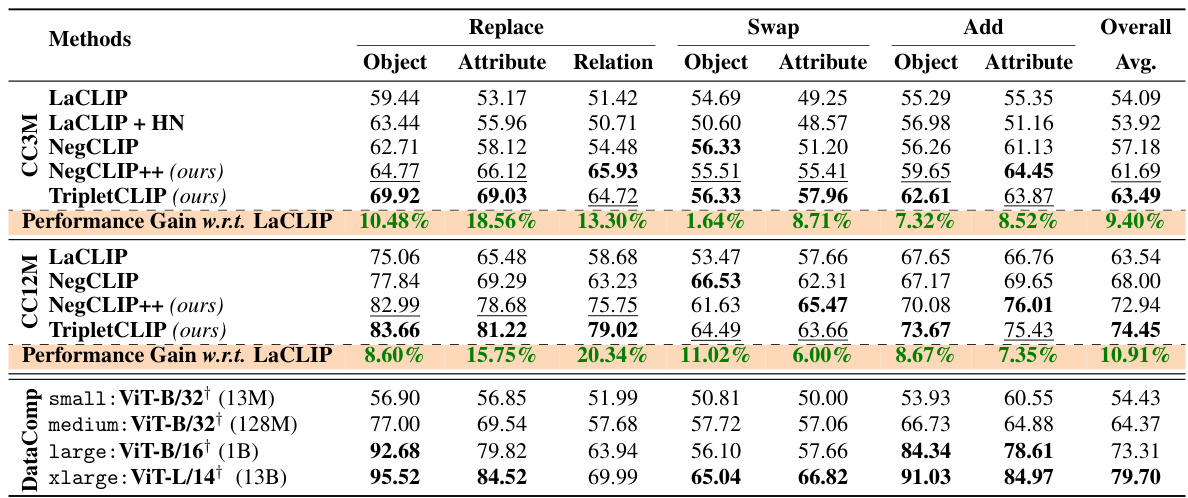
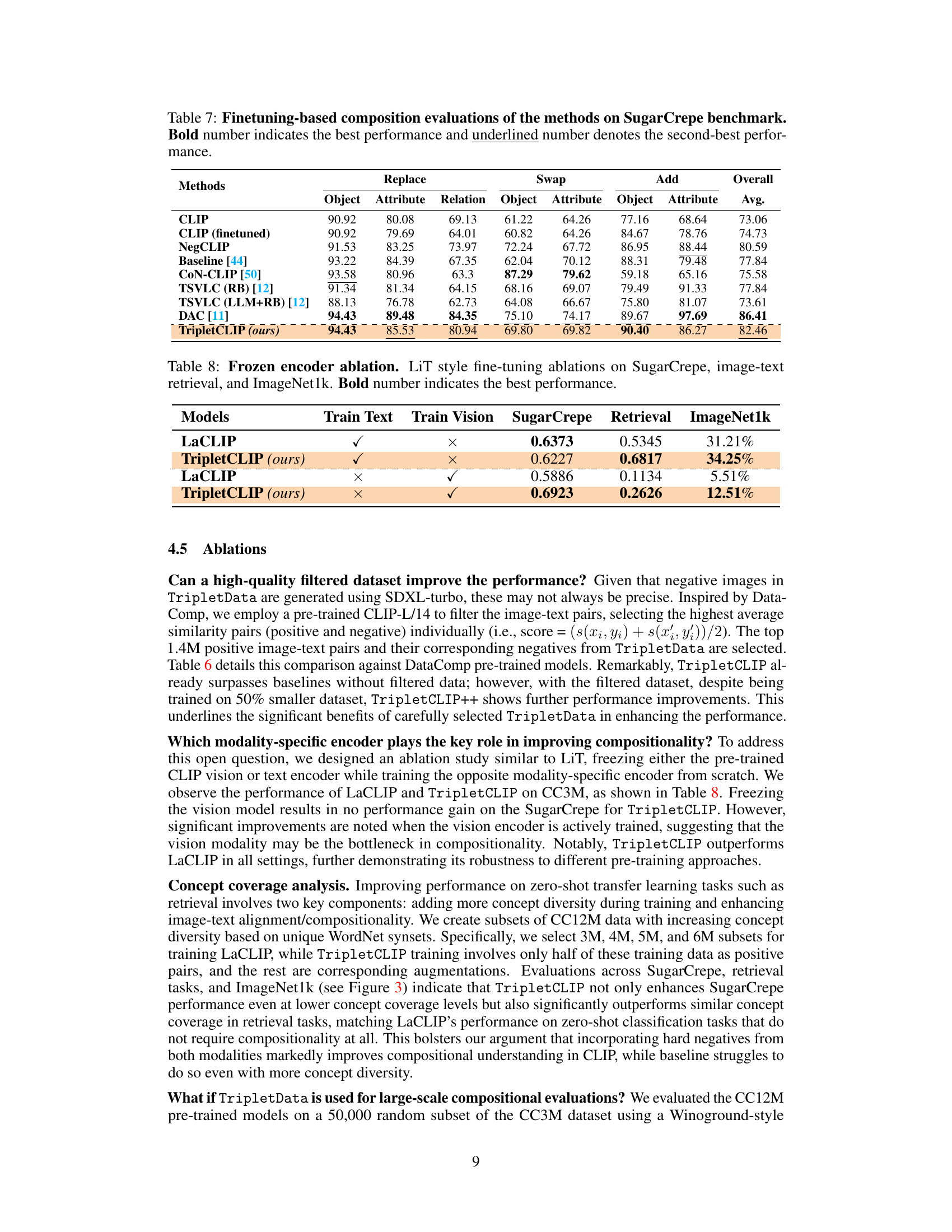
This table presents a comprehensive comparison of different methods (LaCLIP, LaCLIP+HN, NegCLIP, NegCLIP++, and TripletCLIP) for compositional reasoning on the SugarCrepe benchmark. It shows the performance of each method across various sub-tasks within the benchmark (Replace, Swap, Add), focusing on object, attribute, and relation aspects. The ‘Overall Avg.’ column provides the average performance across all sub-tasks. Bold numbers highlight the best performance for each category, while underlined numbers indicate the second-best performance. The results are broken down by two datasets (CC3M and CC12M). The † symbol indicates results obtained directly from the SugarCrepe benchmark paper, not from the authors’ experiments.
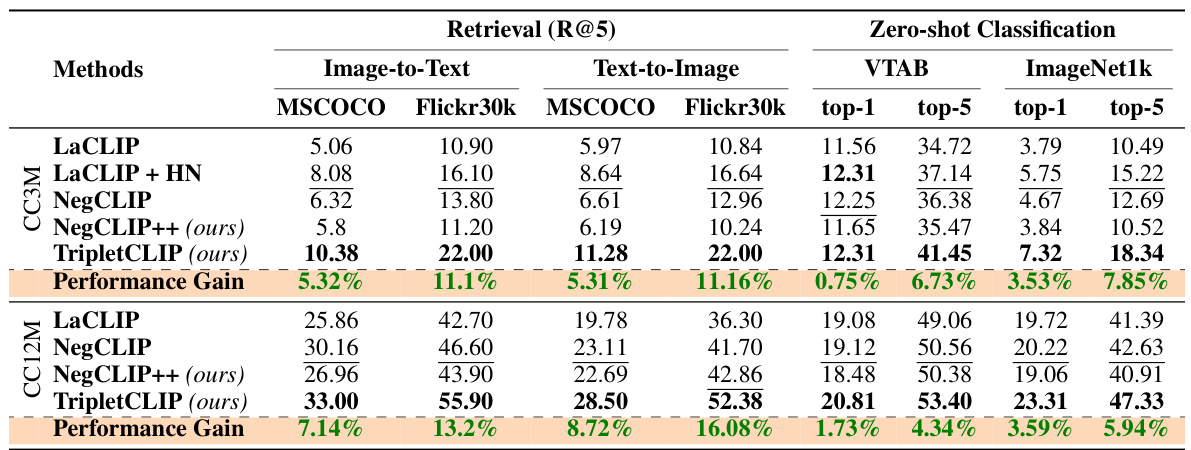
This table presents the zero-shot performance of different models on image-text retrieval tasks (using MSCOCO and Flickr30k datasets) and zero-shot image classification (using VTAB and ImageNet1k datasets). The metrics reported include recall at 5 (R@5) for retrieval and top-1 and top-5 accuracy for classification. The table highlights the significant performance improvements achieved by TripletCLIP compared to the baseline models (LaCLIP, LaCLIP+HN, NegCLIP, and NegCLIP++) in both retrieval and classification tasks.

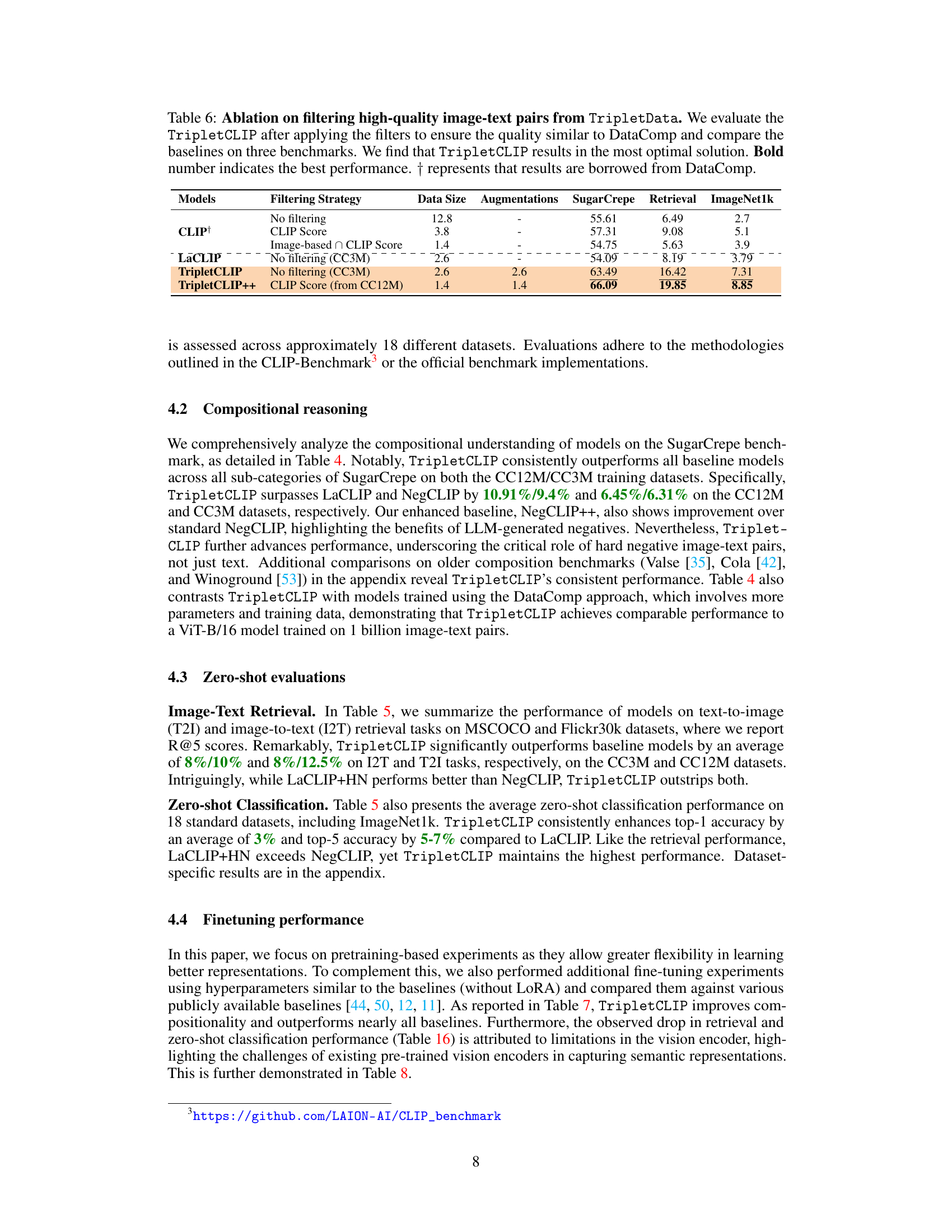
This ablation study investigates the effect of filtering the TripletData to improve data quality. It compares the performance of TripletCLIP (with and without filtering) against baselines (CLIP and LaCLIP) across three benchmarks: SugarCrepe, Retrieval, and ImageNet1k. The filtering methods use CLIP scores and image-based CLIP scores to select high-quality image-text pairs. The results demonstrate that even with a reduced dataset size after filtering, TripletCLIP maintains superior performance compared to the baselines, suggesting that the quality of the negative samples is more important than quantity.
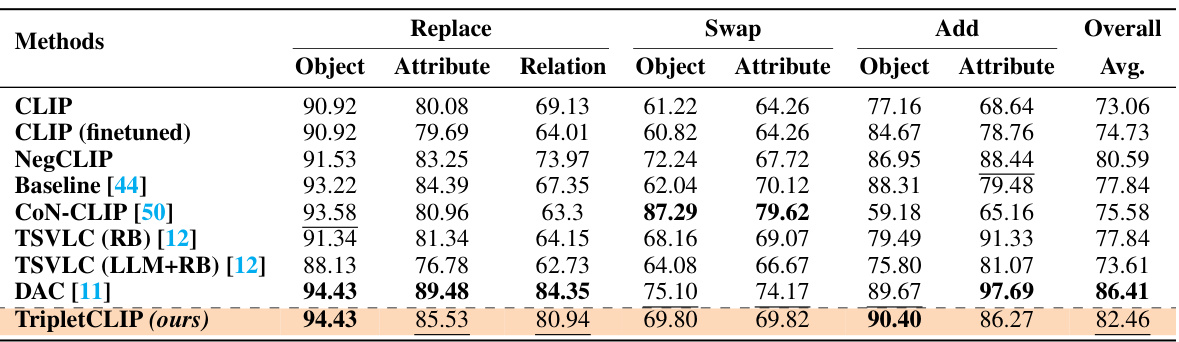
This table presents the results of finetuning various vision-language models on the SugarCrepe benchmark. The models evaluated include CLIP, CLIP (finetuned), NegCLIP, a baseline model [44], CON-CLIP [50], TSVLC (RB) [12], TSVLC (LLM+RB) [12], DAC [11], and TripletCLIP. The performance is broken down by several compositionality sub-categories (Replace Object, Replace Attribute, Replace Relation, Swap Object, etc.) allowing for a detailed comparison of each model’s ability to handle different aspects of compositional reasoning. Bold numbers indicate the best performance in each subcategory and underlined numbers highlight the second-best performance. The ‘Overall Avg.’ column shows the average performance across all sub-categories.

This table presents the results of ablation experiments on TripletCLIP, specifically focusing on the impact of freezing either the vision or text encoder during fine-tuning. It compares the performance of LaCLIP and TripletCLIP under different training scenarios: training only the text encoder, training only the vision encoder, and training both. The metrics evaluated include SugarCrepe (a compositional reasoning benchmark), image-text retrieval performance, and ImageNet1k zero-shot classification accuracy. The bold numbers highlight the best performance achieved in each scenario.
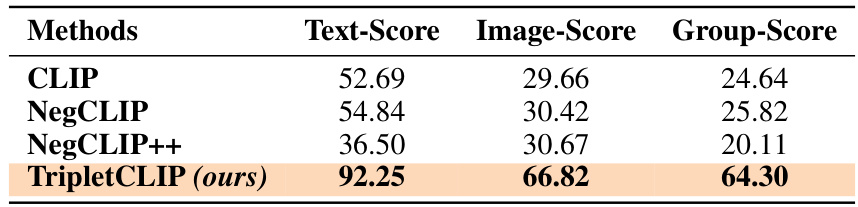
This table presents the results of evaluating the TripletData dataset on a large-scale composition task, comparing it against several baselines (CLIP, NegCLIP, and NegCLIP++). The results show the performance across three metrics: Text-Score, Image-Score, and Group-Score. Importantly, TripletCLIP significantly outperforms all baselines across all metrics. This indicates that TripletData provides a valuable resource for evaluating compositional reasoning capabilities in vision-language models.
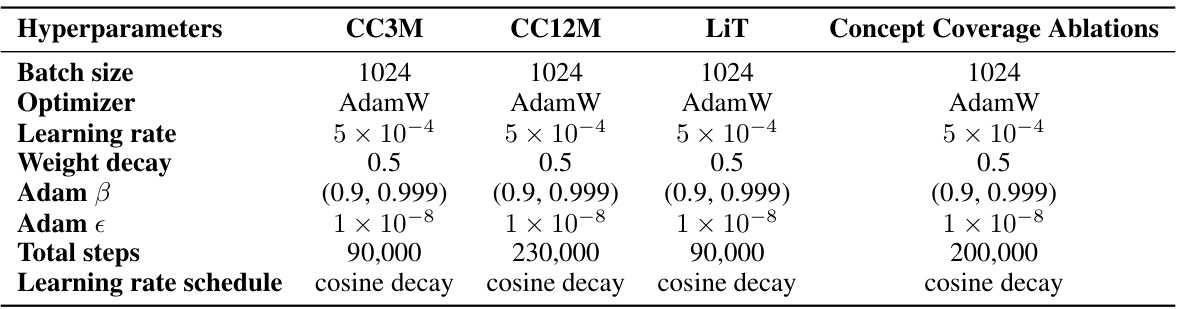
This table lists the hyperparameters used for pre-training CLIP models in various experimental setups described in the paper. The hyperparameters are consistent across different datasets (CC3M, CC12M) and training strategies (LiT, Concept Coverage Ablations), enabling a fair comparison of results. The listed parameters include batch size, optimizer, learning rate, weight decay, Adam β and ε, total training steps, and learning rate schedule. This level of detail allows for reproducibility of the experiments.
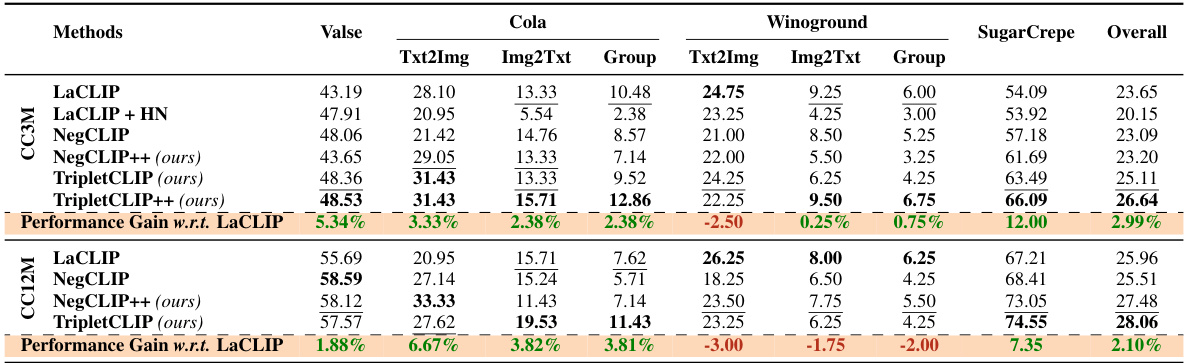
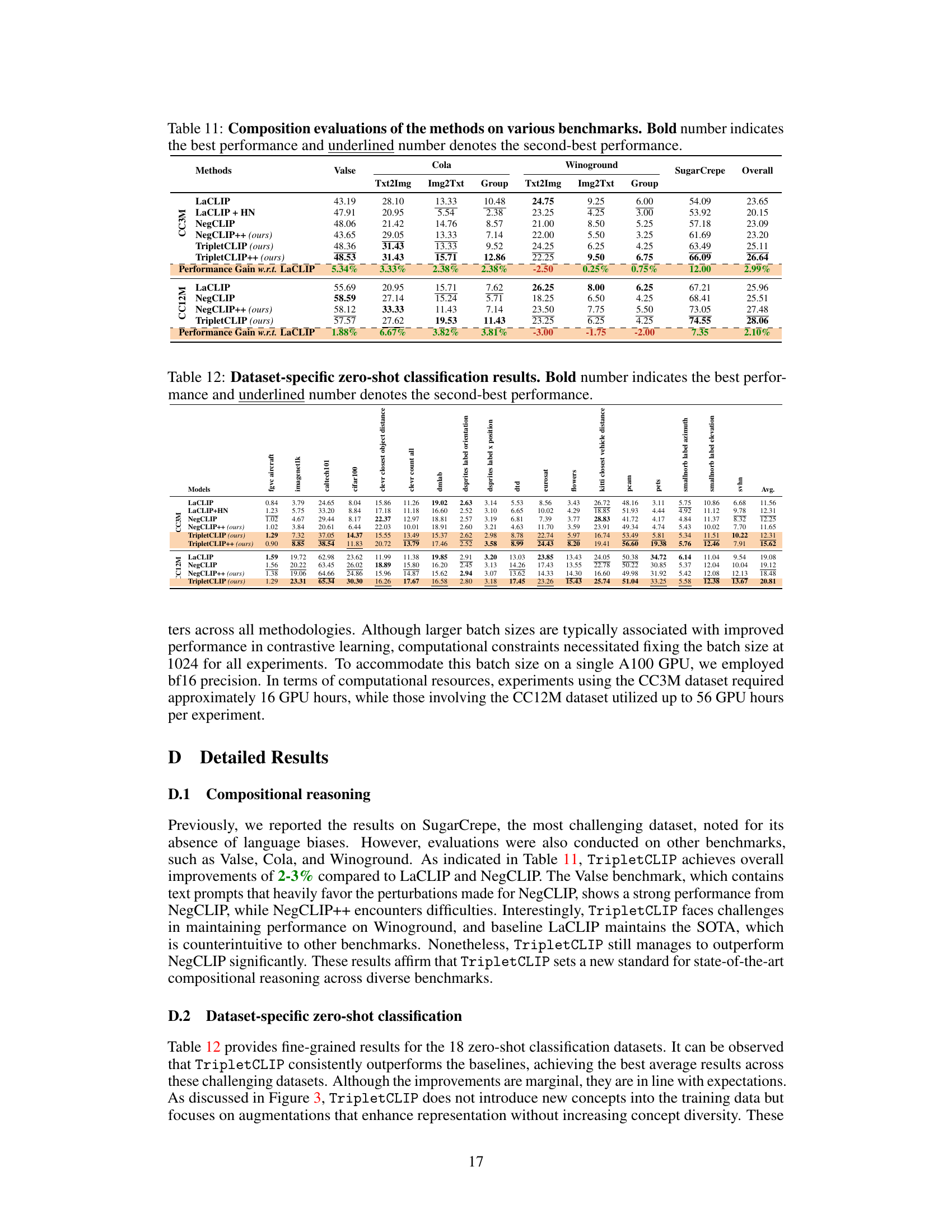
This table presents a comparison of different methods (LaCLIP, LaCLIP+HN, NegCLIP, NegCLIP++, and TripletCLIP) on the SugarCrepe benchmark for compositional reasoning. The benchmark evaluates the ability of vision-language models to understand and generate responses to various compositional queries. The table shows the performance of each method across different compositional aspects (Replace, Swap, Add) and reports the average performance. Bold numbers highlight the best performing method for each aspect and overall, while underlined numbers indicate the second-best performance. Results for a comparison method (DataComp) are also included. The results demonstrate the significant improvement achieved by the TripletCLIP method over other baselines, particularly in terms of compositional reasoning ability.

This table presents the results of an ablation study comparing the performance of different models on three benchmark tasks: SugarCrepe, image retrieval, and ImageNet-1k classification. Each model was trained with different combinations of hard negative captions and hard negative images, illustrating the impact of each modality on the overall performance. The results show that TripletCLIP, using both modalities, outperforms all other models.
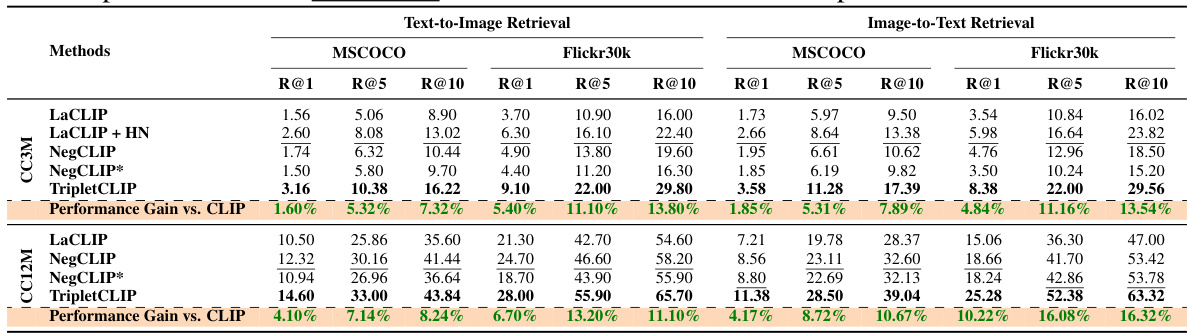
This table presents the zero-shot performance results of different models on image-text retrieval tasks (using MSCOCO and Flickr30k datasets) and zero-shot image classification (using 18 standard datasets, including ImageNet-1k). The metrics used are Recall@5 (R@5) for retrieval and top-1 and top-5 accuracy for classification. The table highlights the superior performance of TripletCLIP compared to various baseline models (LaCLIP, LaCLIP+HN, NegCLIP, NegCLIP++) across all tasks.

This table presents the results of an ablation study on the choice of pre-trained large language models (LLMs) used for generating negative captions in the NegCLIP++ model. Three different LLMs were used: Gemma-2b-it, Phi-3-mini-4k-instruct, and Mistral-7b-instruct-v0.2. The table shows the performance of NegCLIP++ trained with negative captions generated by each LLM on three different benchmarks: SugarCrepe (a compositional reasoning benchmark), Flickr30k Retrieval (R@5) (an image-text retrieval task), and ImageNet-top5 (zero-shot classification). The goal is to determine which LLM produces the most effective negative captions for improving the overall performance of the model.

This table presents an ablation study evaluating the effectiveness of combining the TripletLoss with the CyCLIP model. The experiment trains a ViT-B/32 model on the CC3M dataset using a batch size of 512. The results show the performance on three different metrics: SugarCrepe (a compositional reasoning benchmark), Flickr30k Retrieval (R@5) (image-text retrieval at rank 5), and ImageNet1k (top-5) (zero-shot image classification in top 5). It helps determine if adding the TripletLoss improves the CyCLIP model’s performance on these tasks.

This table presents the results of finetuning various models on image retrieval tasks (using MSCOCO and Flickr30k datasets) and ImageNet-1k zero-shot classification. The models compared include CLIP (with and without finetuning), NegCLIP, a baseline model from another study [44], TSVLC (with and without LLM-based rule rewriting) [12], DAC [11], and TripletCLIP. The metrics used are Recall@5 for retrieval tasks and top-1 and top-5 accuracy for ImageNet-1k. The table highlights the performance of TripletCLIP in comparison to other methods after finetuning.

This table presents examples of questions automatically generated by a large language model (LLM) to assess the quality of images generated by a text-to-image (T2I) model. For each image caption, five binary yes/no questions are created. The goal is to determine whether the generated images accurately reflect the information contained in the original captions.
Full paper#